mirror of
https://github.com/kubesphere/website.git
synced 2025-12-26 00:12:48 +00:00
Merge branch 'kubesphere:master' into master
This commit is contained in:
commit
7f4d425c37
|
|
@ -44,7 +44,7 @@ Give a title first before you write a paragraph. It can be grouped into differen
|
|||
- When you submit your md files to GitHub, make sure you add related image files that appear in md files in the pull request as well. Please save your image files in static/images/docs. You can create a folder in the directory to save your images.
|
||||
- If you want to add remarks (for example, put a box on a UI button), use the color **green**. As some screenshot apps does not support the color picking function for a specific color code, as long as the color is **similar** to #09F709, #00FF00, #09F709 or #09F738, it is acceptable.
|
||||
- Image format: PNG.
|
||||
- Make sure images in your guide match the content. For example, you mention that users need to log in to KubeSphere using an account of a role; this means the account that displays in your image is expected to be the one you are talking about. It confuses your readers if the content you are describing is not consistent with the image used.
|
||||
- Make sure images in your guide match the content. For example, you mention that users need to log in to KubeSphere using a user of a role; this means the account that displays in your image is expected to be the one you are talking about. It confuses your readers if the content you are describing is not consistent with the image used.
|
||||
- Recommended: [Xnip](https://xnipapp.com/) for Mac and [Sniptool](https://www.reasyze.com/sniptool/) for Windows.
|
||||
|
||||
|
||||
|
|
@ -184,7 +184,7 @@ When describing the UI, you can use the following prepositions.
|
|||
|
||||
```bash
|
||||
# Assume your original Kubernetes cluster is v1.17.9
|
||||
./kk create config --with-kubesphere --with-kubernetes v1.17.9
|
||||
./kk create config --with-kubesphere --with-kubernetes v1.20.4
|
||||
```
|
||||
|
||||
- If the comment is used for all the code (for example, serving as a header for explanations), put the comment at the beginning above the code. For example:
|
||||
|
|
|
|||
3
OWNERS
3
OWNERS
|
|
@ -1,7 +1,10 @@
|
|||
approvers:
|
||||
- Felixnoo #oncall
|
||||
- Patrick-LuoYu #oncall
|
||||
- zryfish
|
||||
- rayzhou2017
|
||||
- faweizhao26
|
||||
- yangchuansheng
|
||||
- FeynmanZhou
|
||||
|
||||
reviewers:
|
||||
|
|
|
|||
|
|
@ -15,18 +15,6 @@
|
|||
|
||||
& > ul {
|
||||
|
||||
li:nth-child(1) {
|
||||
.top-div {
|
||||
background-image: linear-gradient(270deg, rgb(101, 193, 148), rgb(76, 169, 134))
|
||||
}
|
||||
}
|
||||
|
||||
li:nth-child(2) {
|
||||
.top-div {
|
||||
background-image: linear-gradient(to left, rgb(52, 197, 209), rgb(95, 182, 216))
|
||||
}
|
||||
}
|
||||
|
||||
& > li {
|
||||
.top-div {
|
||||
position: relative;
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
}
|
||||
|
||||
.main-section {
|
||||
& > div {
|
||||
&>div {
|
||||
position: relative;
|
||||
padding-top: 93px;
|
||||
|
||||
|
|
@ -50,7 +50,7 @@
|
|||
h1 {
|
||||
margin-top: 20px;
|
||||
margin-bottom: 40px;
|
||||
text-shadow: 0 8px 16px rgba(35,45,65,.1);
|
||||
text-shadow: 0 8px 16px rgba(35, 45, 65, .1);
|
||||
font-size: 40px;
|
||||
font-weight: 500;
|
||||
line-height: 1.4;
|
||||
|
|
@ -80,7 +80,7 @@
|
|||
line-height: 2.29;
|
||||
color: #36435c;
|
||||
}
|
||||
|
||||
|
||||
.md-body h2 {
|
||||
font-weight: 500;
|
||||
line-height: 64px;
|
||||
|
|
@ -90,13 +90,13 @@
|
|||
margin-bottom: 20px;
|
||||
border-bottom: 1px solid #ccd3db;
|
||||
}
|
||||
|
||||
|
||||
.md-body h3 {
|
||||
font-weight: 600;
|
||||
line-height: 1.5;
|
||||
color: #171c34;
|
||||
}
|
||||
|
||||
|
||||
.md-body img {
|
||||
max-width: 100%;
|
||||
box-sizing: content-box;
|
||||
|
|
@ -104,30 +104,30 @@
|
|||
border-radius: 5px;
|
||||
box-shadow: none;
|
||||
}
|
||||
|
||||
|
||||
.md-body blockquote {
|
||||
padding: 4px 20px 4px 12px;
|
||||
border-radius: 4px;
|
||||
background-color: #ecf0f2;
|
||||
}
|
||||
|
||||
|
||||
&-metadata {
|
||||
margin-bottom: 28px;
|
||||
|
||||
|
||||
&-title {
|
||||
font-size: 16px;
|
||||
font-weight: 500;
|
||||
line-height: 1.5;
|
||||
color: #171c34;
|
||||
}
|
||||
|
||||
|
||||
&-time {
|
||||
font-size: 14px;
|
||||
line-height: 1.43;
|
||||
color: #919aa3;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
&-title {
|
||||
text-shadow: 0 8px 16px rgba(35, 45, 65, 0.1);
|
||||
font-size: 40px;
|
||||
|
|
@ -135,7 +135,7 @@
|
|||
line-height: 1.4;
|
||||
color: #171c34;
|
||||
margin-bottom: 40px;
|
||||
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
font-size: 28px;
|
||||
}
|
||||
|
|
@ -150,6 +150,7 @@
|
|||
bottom: 10px;
|
||||
transform: translateX(350px);
|
||||
width: 230px;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
display: none;
|
||||
}
|
||||
|
|
@ -158,7 +159,7 @@
|
|||
max-height: 100%;
|
||||
position: relative;
|
||||
overflow-y: auto;
|
||||
}
|
||||
}
|
||||
|
||||
.title {
|
||||
height: 32px;
|
||||
|
|
@ -166,13 +167,14 @@
|
|||
line-height: 1.33;
|
||||
color: #36435c;
|
||||
padding-bottom: 10px;
|
||||
border-bottom: solid 1px #ccd3db;;
|
||||
border-bottom: solid 1px #ccd3db;
|
||||
}
|
||||
|
||||
.tabs {
|
||||
#TableOfContents > ul > li > a {
|
||||
#TableOfContents>ul>li>a {
|
||||
font-weight: 500;
|
||||
}
|
||||
|
||||
li {
|
||||
margin: 10px 0;
|
||||
font-size: 16px;
|
||||
|
|
@ -195,6 +197,7 @@
|
|||
color: #55bc8a;
|
||||
}
|
||||
}
|
||||
|
||||
li li {
|
||||
padding-left: 20px;
|
||||
}
|
||||
|
|
@ -202,121 +205,137 @@
|
|||
}
|
||||
}
|
||||
}
|
||||
.SubscribeForm {
|
||||
position: fixed;
|
||||
right: 49px;
|
||||
bottom: 32px;
|
||||
box-shadow: 0px 8px 16px rgba(36, 46, 66, 0.05), 0px 4px 8px rgba(36, 46, 66, 0.06);
|
||||
|
||||
.innerBox {
|
||||
width: 440px;
|
||||
height: 246px;
|
||||
overflow: hidden;
|
||||
background: url('/images/home/modal-noText.svg');
|
||||
position: relative;
|
||||
padding: -8px -16px;
|
||||
background-position: -16px -8px;
|
||||
@media only screen and (min-width: $mobile-max-width) {
|
||||
.SubscribeForm {
|
||||
position: fixed;
|
||||
right: 49px;
|
||||
bottom: 32px;
|
||||
|
||||
.close {
|
||||
position: absolute;
|
||||
top: 24px;
|
||||
right: 24px;
|
||||
cursor: pointer;
|
||||
}
|
||||
box-shadow: 0px 8px 16px rgba(36, 46, 66, 0.05),
|
||||
0px 4px 8px rgba(36, 46, 66, 0.06);
|
||||
|
||||
p {
|
||||
width: 360px;
|
||||
height: 44px;
|
||||
left: 40px;
|
||||
top: 103px;
|
||||
right: 40px;
|
||||
position: absolute;
|
||||
font-family: ProximaNova;
|
||||
font-size: 16px;
|
||||
line-height: 22px;
|
||||
color: #919AA3;
|
||||
.innerBox {
|
||||
width: 440px;
|
||||
height: 246px;
|
||||
overflow: hidden;
|
||||
background: url('/images/home/modal-noText.svg');
|
||||
position: relative;
|
||||
padding: -8px -16px;
|
||||
background-position: -16px -8px;
|
||||
|
||||
}
|
||||
|
||||
div {
|
||||
bottom: 32px;
|
||||
left: 40px;
|
||||
position: absolute;
|
||||
width: 358px;
|
||||
height: 48px;
|
||||
margin-top: 20px;
|
||||
border-radius: 24px;
|
||||
border: solid 1px #ccd3db;
|
||||
background-color: #f5f8f9;
|
||||
|
||||
@mixin placeholder {
|
||||
font-family: PingFangSC;
|
||||
font-size: 14px;
|
||||
line-height: 16px;
|
||||
text-align: right;
|
||||
color: #CCD3DB;
|
||||
.close {
|
||||
position: absolute;
|
||||
top: 24px;
|
||||
right: 24px;
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
input {
|
||||
width: 207px;
|
||||
height: 20px;
|
||||
font-size: 14px;
|
||||
margin-left: 16px;
|
||||
color: #ccd3db;
|
||||
border: none;
|
||||
outline: none;
|
||||
p {
|
||||
width: 360px;
|
||||
height: 44px;
|
||||
left: 40px;
|
||||
top: 103px;
|
||||
right: 40px;
|
||||
position: absolute;
|
||||
font-family: ProximaNova;
|
||||
font-size: 16px;
|
||||
line-height: 22px;
|
||||
color: #919AA3;
|
||||
|
||||
}
|
||||
|
||||
div {
|
||||
bottom: 32px;
|
||||
left: 40px;
|
||||
position: absolute;
|
||||
width: 358px;
|
||||
height: 48px;
|
||||
margin-top: 20px;
|
||||
border-radius: 24px;
|
||||
border: solid 1px #ccd3db;
|
||||
background-color: #f5f8f9;
|
||||
|
||||
&:-webkit-input-placeholder {
|
||||
@include placeholder();
|
||||
@mixin placeholder {
|
||||
font-family: PingFangSC;
|
||||
font-size: 14px;
|
||||
line-height: 16px;
|
||||
text-align: right;
|
||||
color: #CCD3DB;
|
||||
}
|
||||
|
||||
&:-ms-input-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
|
||||
&:-moz-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
|
||||
&:-moz-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
}
|
||||
|
||||
button {
|
||||
width: 111px;
|
||||
height: 40px;
|
||||
margin: 4px 5px 4px 14px;
|
||||
border-radius: 20px;
|
||||
border: none;
|
||||
font-size: 14px;
|
||||
color: #ffffff;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2);
|
||||
background-image: linear-gradient(to bottom, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.1) 97%), linear-gradient(to bottom, #55bc8a, #55bc8a);
|
||||
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 326px;
|
||||
|
||||
input {
|
||||
width: 196px;
|
||||
width: 207px;
|
||||
height: 20px;
|
||||
font-size: 14px;
|
||||
margin-left: 16px;
|
||||
color: #ccd3db;
|
||||
border: none;
|
||||
outline: none;
|
||||
background-color: #f5f8f9;
|
||||
|
||||
&:-webkit-input-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
|
||||
&:-ms-input-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
|
||||
&:-moz-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
|
||||
&:-moz-placeholder {
|
||||
@include placeholder();
|
||||
}
|
||||
}
|
||||
|
||||
button {
|
||||
width: 90px;
|
||||
width: 111px;
|
||||
height: 40px;
|
||||
margin: 4px 5px 4px 14px;
|
||||
border-radius: 20px;
|
||||
border: none;
|
||||
font-size: 14px;
|
||||
color: #ffffff;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2);
|
||||
background-image: linear-gradient(to bottom, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.1) 97%), linear-gradient(to bottom, #55bc8a, #55bc8a);
|
||||
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 326px;
|
||||
|
||||
input {
|
||||
width: 196px;
|
||||
}
|
||||
|
||||
button {
|
||||
width: 90px;
|
||||
}
|
||||
}
|
||||
|
||||
span {
|
||||
color: red;
|
||||
}
|
||||
}
|
||||
|
||||
span {
|
||||
color: red;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
|
||||
.SubscribeForm {
|
||||
display: none !important;
|
||||
}
|
||||
}
|
||||
|
||||
#videoPlayer {
|
||||
width: 100%;
|
||||
}
|
||||
|
|
@ -853,7 +853,7 @@ footer {
|
|||
|
||||
p {
|
||||
width: 360px;
|
||||
font-family: ProximaNova;
|
||||
font-family: 'Proxima Nova';
|
||||
font-size: 16px;
|
||||
line-height: 22px;
|
||||
color: #919AA3;
|
||||
|
|
|
|||
|
|
@ -1,5 +1,40 @@
|
|||
@import "variables";
|
||||
|
||||
@mixin tooltip {
|
||||
.tooltip {
|
||||
visibility: hidden;
|
||||
width: 80px;
|
||||
padding: 8px 12px;
|
||||
background: #242E42;
|
||||
box-shadow: 0px 4px 8px rgba(36, 46, 66, 0.2);
|
||||
border-radius: 4px;
|
||||
transform: translateX(-50%);
|
||||
box-sizing: border-box;
|
||||
/* 定位 */
|
||||
position: absolute;
|
||||
z-index: 1;
|
||||
|
||||
font-family: PingFang SC;
|
||||
font-style: normal;
|
||||
font-size: 12px;
|
||||
line-height: 20px;
|
||||
color: #fff;
|
||||
text-align: center;
|
||||
|
||||
&::after {
|
||||
content: " ";
|
||||
position: absolute;
|
||||
top: 100%;
|
||||
/* 提示工具底部 */
|
||||
left: 50%;
|
||||
margin-left: -5px;
|
||||
border-width: 5px;
|
||||
border-style: solid;
|
||||
border-color: #242E42 transparent transparent;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.navigation {
|
||||
box-shadow: 0 4px 8px 0 rgba(36, 46, 66, 0.06), 0 8px 16px 0 rgba(36, 46, 66, 0.05);
|
||||
background-image: linear-gradient(to bottom, rgba(134, 219, 162, 0.9), rgba(0, 170, 114, 0.9));
|
||||
|
|
@ -88,7 +123,8 @@
|
|||
.right {
|
||||
box-sizing: border-box;
|
||||
width: 368px;
|
||||
padding: 24px;
|
||||
padding: 24px 20px 0 20px;
|
||||
min-height: 488px;
|
||||
max-height: 600px;
|
||||
margin-left: 15px;
|
||||
overflow: auto;
|
||||
|
|
@ -98,163 +134,200 @@
|
|||
display: none;
|
||||
}
|
||||
|
||||
.lesson-div {
|
||||
margin-top: 20px;
|
||||
.sections {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
margin-bottom: 12px;
|
||||
|
||||
&:first-child {
|
||||
margin-top: 0;
|
||||
}
|
||||
|
||||
& > p {
|
||||
.sectionFolder {
|
||||
box-sizing: border-box;
|
||||
width: 328px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
flex-direction: row;
|
||||
padding: 9px 16px;
|
||||
background: #F9FBFD;
|
||||
border-radius: 4px;
|
||||
position: relative;
|
||||
padding-left: 9px;
|
||||
font-size: 16px;
|
||||
font-weight: 500;
|
||||
line-height: 1.5;
|
||||
letter-spacing: -0.04px;
|
||||
|
||||
&::before {
|
||||
position: absolute;
|
||||
top: 10px;
|
||||
left: 0;
|
||||
content: "";
|
||||
width: 4px;
|
||||
height: 4px;
|
||||
border-radius: 50%;
|
||||
background-color: #36435c;
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
background: #EFF4F9;
|
||||
}
|
||||
|
||||
a {
|
||||
color: #36435c;
|
||||
&:hover {
|
||||
color: #55bc8a;
|
||||
}
|
||||
.text {
|
||||
font-weight: 500;
|
||||
font-size: 16px;
|
||||
line-height: 22px;
|
||||
width: 264px;
|
||||
text-overflow: ellipsis;
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
}
|
||||
|
||||
.icon {
|
||||
display: inline-block;
|
||||
margin-left: 6px;
|
||||
width: 12px;
|
||||
height: 12px;
|
||||
background-image: url("/images/learn/video.svg");
|
||||
}
|
||||
|
||||
.play-span {
|
||||
display: none;
|
||||
height: 12px;
|
||||
font-size: 0;
|
||||
span {
|
||||
display: inline-block;
|
||||
width: 2px;
|
||||
height: 100%;
|
||||
margin-right: 2px;
|
||||
background-color: #55bc8a;
|
||||
}
|
||||
}
|
||||
|
||||
.playing {
|
||||
display: inline-block;
|
||||
span {
|
||||
animation-name: playing;
|
||||
animation-duration: 1s;
|
||||
animation-timing-function: ease;
|
||||
animation-delay: 0s;
|
||||
animation-iteration-count: infinite;
|
||||
|
||||
&:first-child {
|
||||
animation-delay: 0.3s;
|
||||
}
|
||||
&:last-child {
|
||||
animation-delay: 0.5s;
|
||||
}
|
||||
}
|
||||
display: block;
|
||||
height: 10px;
|
||||
width: 10px;
|
||||
background-image: url('/images/learn/icon-setion-close.svg');
|
||||
background-repeat: no-repeat;
|
||||
position: absolute;
|
||||
right: 17px;
|
||||
}
|
||||
}
|
||||
& > p.active {
|
||||
a {
|
||||
color: #55bc8a;
|
||||
}
|
||||
|
||||
&::before {
|
||||
background-color: #55bc8a;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.lesson-link-div {
|
||||
margin-top: 10px;
|
||||
display: flex;
|
||||
a {
|
||||
display: block;
|
||||
box-sizing: border-box;
|
||||
width: 100px;
|
||||
height: 72px;
|
||||
padding: 11px 20px 10px;
|
||||
margin-left: 10px;
|
||||
margin-right: 0;
|
||||
font-size: 14px;
|
||||
line-height: 24px;
|
||||
text-align: center;
|
||||
color: #8f94a1;
|
||||
border-radius: 4px;
|
||||
background-color: #f5f9fa;
|
||||
border: solid 1px transparent;
|
||||
|
||||
&:first-child {
|
||||
margin-left: 0;
|
||||
}
|
||||
|
||||
&:hover {
|
||||
border: solid 1px #4ca986;
|
||||
}
|
||||
|
||||
span {
|
||||
display: inline-block;
|
||||
width: 24px;
|
||||
height: 24px;
|
||||
}
|
||||
}
|
||||
|
||||
.active {
|
||||
color: #00a971;
|
||||
border: solid 1px #55bc8a;
|
||||
background-color: #cdf6d5;
|
||||
}
|
||||
background: linear-gradient(180deg, #242E42 0%, #36435C 100%) !important;
|
||||
color: #ffffff;
|
||||
|
||||
.lesson {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-image.svg");
|
||||
&>.icon {
|
||||
background-image: url('/images/learn/icon-setion-open.svg');
|
||||
}
|
||||
}
|
||||
|
||||
.lesson.active {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-image-active.svg");
|
||||
ul {
|
||||
transition: 1.2s;
|
||||
|
||||
li {
|
||||
width: 320px;
|
||||
height: 24px;
|
||||
margin: 16px 0px;
|
||||
list-style: none;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
position: relative;
|
||||
cursor: pointer;
|
||||
|
||||
.textLink {
|
||||
width: 252px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
|
||||
.videoIcon {
|
||||
display: block;
|
||||
width: 12px;
|
||||
height: 12px;
|
||||
margin-right: 8px;
|
||||
background-image: url('/images/learn/lesson-video.svg');
|
||||
}
|
||||
|
||||
.text {
|
||||
flex: 1;
|
||||
font-family: PingFang SC;
|
||||
font-style: normal;
|
||||
font-weight: normal;
|
||||
font-size: 14px;
|
||||
line-height: 24px;
|
||||
display: block;
|
||||
overflow: hidden;
|
||||
white-space: nowrap;
|
||||
text-overflow: ellipsis;
|
||||
}
|
||||
}
|
||||
|
||||
.actions {
|
||||
width: 68px;
|
||||
height: 24px;
|
||||
display: flex;
|
||||
flex-direction: row;
|
||||
align-items: center;
|
||||
justify-content: flex-end;
|
||||
|
||||
.picture {
|
||||
width: 16px;
|
||||
height: 12px;
|
||||
background-image: url('/images/learn/actions-picture.svg');
|
||||
background-repeat: no-repeat;
|
||||
position: relative;
|
||||
|
||||
@include tooltip();
|
||||
|
||||
&:hover {
|
||||
background-image: url('/images/learn/actions-picture-active.svg');
|
||||
|
||||
.tooltip {
|
||||
visibility: visible;
|
||||
bottom: 20px;
|
||||
left: 8px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.activePicture {
|
||||
background-image: url('/images/learn/actions-picture-open.svg') !important;
|
||||
}
|
||||
|
||||
.ppt {
|
||||
width: 16px;
|
||||
height: 16px;
|
||||
background-image: url('/images/learn/actions-ppt.svg');
|
||||
background-repeat: no-repeat;
|
||||
position: relative;
|
||||
margin: 0 10px;
|
||||
@include tooltip();
|
||||
|
||||
&:hover {
|
||||
.tooltip {
|
||||
visibility: visible;
|
||||
bottom: 20px;
|
||||
left: 8px;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.download {
|
||||
width: 16px;
|
||||
height: 16px;
|
||||
background-image: url('/images/learn/actions-download.svg');
|
||||
background-repeat: no-repeat;
|
||||
position: relative;
|
||||
@include tooltip();
|
||||
|
||||
&:hover {
|
||||
.tooltip {
|
||||
visibility: visible;
|
||||
bottom: 20px;
|
||||
left: 8px;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
&:hover {
|
||||
.textLink {
|
||||
.videoIcon {
|
||||
background-image: url('/images/learn/lesson-video-hover.svg');
|
||||
}
|
||||
}
|
||||
|
||||
.text {
|
||||
color: #4CA986;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.pptActive{
|
||||
.text {
|
||||
color: #4CA986;
|
||||
}
|
||||
}
|
||||
|
||||
.activeLine {
|
||||
.textLink {
|
||||
.videoIcon {
|
||||
background-image: url('/images/learn/lesson-video-play.svg') !important;
|
||||
}
|
||||
|
||||
.text {
|
||||
color: #4CA986;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.courseware {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-ppt.svg");
|
||||
}
|
||||
}
|
||||
|
||||
.courseware.active {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-ppt-active.svg");
|
||||
}
|
||||
}
|
||||
|
||||
.examination {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-download.svg");
|
||||
}
|
||||
}
|
||||
|
||||
.examination.active {
|
||||
span {
|
||||
background-image: url("/images/learn/icon-download-active.svg");
|
||||
}
|
||||
.hideLesson {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -144,14 +144,15 @@ h2 {
|
|||
font-size: 0;
|
||||
overflow-x: auto;
|
||||
white-space: nowrap;
|
||||
display: flex;
|
||||
|
||||
li {
|
||||
position: relative;
|
||||
display: inline-block;
|
||||
box-sizing: border-box;
|
||||
white-space: normal;
|
||||
width: 323px;
|
||||
height: 237px;
|
||||
min-width: 323px;
|
||||
min-height: 237px;
|
||||
padding: 30px 20px 30px 62px;
|
||||
margin-left: 70px;
|
||||
font-size: 14px;
|
||||
|
|
@ -169,6 +170,7 @@ h2 {
|
|||
left: -50px;
|
||||
width: 100px;
|
||||
height: 100px;
|
||||
object-fit: cover;
|
||||
border-radius: 50%;
|
||||
}
|
||||
|
||||
|
|
@ -250,7 +252,7 @@ h2 {
|
|||
margin-top: 68px;
|
||||
& > li {
|
||||
position: relative;
|
||||
padding: 50px 39px 20px 40px;
|
||||
padding: 50px 39px 40px 40px;
|
||||
margin-bottom: 58px;
|
||||
border-radius: 8px;
|
||||
background-color: #ffffff;
|
||||
|
|
@ -276,6 +278,10 @@ h2 {
|
|||
top: -20px;
|
||||
left: 30px;
|
||||
border-radius: 5px;
|
||||
white-space: nowrap;
|
||||
text-overflow: ellipsis;
|
||||
max-width: 75%;
|
||||
overflow: hidden;
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -371,6 +377,46 @@ h2 {
|
|||
}
|
||||
}
|
||||
}
|
||||
|
||||
.button{
|
||||
position: absolute;
|
||||
height: 48px;
|
||||
width: 100%;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
background: linear-gradient(360deg, rgba(85, 188, 138, 0.25) 0%, rgba(85, 188, 138, 0) 100%);
|
||||
border: none;
|
||||
font-weight: 600;
|
||||
font-size: 14px;
|
||||
line-height: 20px;
|
||||
color: #0F8049;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
cursor: pointer;
|
||||
|
||||
#close{
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
|
||||
.hideButton{
|
||||
display: none;
|
||||
}
|
||||
|
||||
.active{
|
||||
#open{
|
||||
display: none;
|
||||
}
|
||||
|
||||
#close{
|
||||
display: block;
|
||||
}
|
||||
|
||||
svg{
|
||||
transform: rotateX(180deg);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
@import 'variables';
|
||||
@import 'mixin';
|
||||
|
||||
.btn-a {
|
||||
display: inline-block;
|
||||
padding: 0 53px;
|
||||
|
|
@ -10,10 +11,12 @@
|
|||
color: #ffffff;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2), 0 10px 50px 0 rgba(34, 43, 62, 0.1);
|
||||
background-image: linear-gradient(to bottom, rgba(85, 188, 138, 0), rgba(85, 188, 138, 0.1) 97%), linear-gradient(to bottom, #55bc8a, #55bc8a);
|
||||
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
}
|
||||
}
|
||||
|
||||
.section-1 {
|
||||
position: relative;
|
||||
padding-top: 124px;
|
||||
|
|
@ -40,16 +43,19 @@
|
|||
position: relative;
|
||||
width: 840px;
|
||||
height: 400px;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 100%;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
img {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
min-height: 200px;
|
||||
object-fit: cover;
|
||||
}
|
||||
|
||||
button {
|
||||
position: absolute;
|
||||
right: 20px;
|
||||
|
|
@ -62,6 +68,7 @@
|
|||
cursor: pointer;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2), 0 10px 50px 0 rgba(34, 43, 62, 0.1);
|
||||
background-image: linear-gradient(to bottom, rgba(85, 188, 138, 0), rgba(85, 188, 138, 0.1) 97%), linear-gradient(to bottom, #55bc8a, #55bc8a);
|
||||
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
}
|
||||
|
|
@ -73,12 +80,14 @@
|
|||
width: 320px;
|
||||
height: 400px;
|
||||
padding: 10px;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
max-width: 320px;
|
||||
width: auto;
|
||||
height: auto;
|
||||
margin: 0 auto;
|
||||
}
|
||||
|
||||
h2 {
|
||||
margin-bottom: 10px;
|
||||
font-size: 18px;
|
||||
|
|
@ -116,8 +125,8 @@
|
|||
font-size: 16px;
|
||||
line-height: 28px;
|
||||
letter-spacing: -0.04px;
|
||||
color: #919aa3;
|
||||
|
||||
color: #919aa3;
|
||||
|
||||
img {
|
||||
vertical-align: middle;
|
||||
margin-right: 4px;
|
||||
|
|
@ -127,8 +136,8 @@
|
|||
a {
|
||||
margin: 34px auto 0;
|
||||
height: 40px;
|
||||
padding: 0 28px;
|
||||
line-height: 40px;
|
||||
padding: 0 28px;
|
||||
line-height: 40px;
|
||||
}
|
||||
|
||||
.tag {
|
||||
|
|
@ -165,12 +174,12 @@
|
|||
padding-bottom: 40px;
|
||||
}
|
||||
|
||||
& > div {
|
||||
&>div {
|
||||
|
||||
& > .video-tab-ul {
|
||||
&>.video-tab-ul {
|
||||
padding: 0 34px;
|
||||
border-radius: 5px;
|
||||
box-shadow: 0 4px 16px 0 rgba(7,42,68,.1);
|
||||
box-shadow: 0 4px 16px 0 rgba(7, 42, 68, .1);
|
||||
background-color: #fff;
|
||||
|
||||
li {
|
||||
|
|
@ -188,18 +197,19 @@
|
|||
text-align: center;
|
||||
|
||||
&:hover {
|
||||
box-shadow: 0 8px 16px 0 rgba(101,193,148,.2),0 0 50px 0 rgba(101,193,148,.1);
|
||||
box-shadow: 0 8px 16px 0 rgba(101, 193, 148, .2), 0 0 50px 0 rgba(101, 193, 148, .1);
|
||||
background-color: #55bc8a;
|
||||
color: #fff;
|
||||
}
|
||||
}
|
||||
|
||||
.active {
|
||||
box-shadow: 0 8px 16px 0 rgba(101,193,148,.2),0 0 50px 0 rgba(101,193,148,.1);
|
||||
box-shadow: 0 8px 16px 0 rgba(101, 193, 148, .2), 0 0 50px 0 rgba(101, 193, 148, .1);
|
||||
background-color: #55bc8a;
|
||||
color: #fff;
|
||||
}
|
||||
|
||||
li + li {
|
||||
li+li {
|
||||
margin-left: 12px;
|
||||
}
|
||||
}
|
||||
|
|
@ -207,11 +217,12 @@
|
|||
.video-ul {
|
||||
margin-top: 20px;
|
||||
font-size: 0;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
& > li {
|
||||
&>li {
|
||||
position: relative;
|
||||
display: inline-block;
|
||||
width: 360px;
|
||||
|
|
@ -225,18 +236,18 @@
|
|||
text-align: left;
|
||||
cursor: pointer;
|
||||
|
||||
& > img {
|
||||
&>img {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
}
|
||||
|
||||
&:hover {
|
||||
& > div {
|
||||
&>div {
|
||||
height: 202px;
|
||||
}
|
||||
}
|
||||
|
||||
& > div {
|
||||
&>div {
|
||||
position: absolute;
|
||||
left: 0;
|
||||
right: 0;
|
||||
|
|
@ -247,14 +258,14 @@
|
|||
transition: all .2s ease-in-out;
|
||||
overflow: hidden;
|
||||
|
||||
& > .btn {
|
||||
&>.btn {
|
||||
position: absolute;
|
||||
left: 50%;
|
||||
bottom: 120px;
|
||||
transform: translateX(-50%);
|
||||
}
|
||||
|
||||
& > div {
|
||||
&>div {
|
||||
position: absolute;
|
||||
left: 0;
|
||||
right: 0;
|
||||
|
|
@ -269,7 +280,7 @@
|
|||
color: #fff;
|
||||
padding: 8px 0;
|
||||
margin-bottom: 6px;
|
||||
border-bottom: 1px solid hsla(0,0%,100%,.1);
|
||||
border-bottom: 1px solid hsla(0, 0%, 100%, .1);
|
||||
text-overflow: ellipsis;
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
|
|
@ -306,7 +317,7 @@
|
|||
}
|
||||
}
|
||||
|
||||
& > div {
|
||||
&>div {
|
||||
margin-top: 20px;
|
||||
text-align: center;
|
||||
|
||||
|
|
@ -342,7 +353,7 @@
|
|||
padding: 0;
|
||||
border-radius: 0;
|
||||
font-size: 0;
|
||||
|
||||
|
||||
.video-div {
|
||||
height: 100%;
|
||||
}
|
||||
|
|
@ -363,7 +374,7 @@
|
|||
width: 100%;
|
||||
max-width: 100%;
|
||||
height: auto;
|
||||
|
||||
|
||||
iframe {
|
||||
width: 100%;
|
||||
height: 300px;
|
||||
|
|
@ -371,99 +382,270 @@
|
|||
}
|
||||
}
|
||||
|
||||
.section-4 {
|
||||
background-image: linear-gradient(113deg, #4a499a 27%, #8552c3 81%);
|
||||
.common-layout {
|
||||
white-space: nowrap;
|
||||
overflow: auto;
|
||||
& > div {
|
||||
box-sizing: border-box;
|
||||
display: inline-block;
|
||||
vertical-align: top;
|
||||
white-space: normal;
|
||||
width: 140px;
|
||||
height: 225px;
|
||||
margin: 80px 40px;
|
||||
padding-top: 20px;
|
||||
border-top: 1px solid #a1b3c4;
|
||||
|
||||
.time-div {
|
||||
.common-layout-special {
|
||||
white-space: nowrap;
|
||||
overflow: auto;
|
||||
height: 535px;
|
||||
background-image: linear-gradient(147.87deg, #4A499A 16%, #8552C3 85.01%);
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 100%;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
.meetup-box {
|
||||
max-width: 1320px;
|
||||
margin: 0 auto;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.meetup-title {
|
||||
font-size: 32px;
|
||||
line-height: 45px;
|
||||
color: #fff;
|
||||
text-align: center;
|
||||
padding-top: 56px;
|
||||
}
|
||||
|
||||
.innerBox {
|
||||
padding: 0px 80px;
|
||||
position: relative;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 100%;
|
||||
box-sizing: border-box;
|
||||
padding: 0 20px;
|
||||
}
|
||||
|
||||
&>ul {
|
||||
margin-top: 16px;
|
||||
display: flex;
|
||||
overflow: scroll;
|
||||
background: linear-gradient(to top, rgba(255, 255, 255, 0.08) 5%, transparent 5%) no-repeat;
|
||||
|
||||
.right {
|
||||
margin-left: 4px;
|
||||
font-weight: bold;
|
||||
line-height: 1;
|
||||
color: #ffffff;
|
||||
.date {
|
||||
margin-bottom: 4px;
|
||||
font-size: 24px;
|
||||
}
|
||||
.time {
|
||||
font-size: 14px;
|
||||
}
|
||||
li {
|
||||
width: 80px;
|
||||
height: 40px;
|
||||
line-height: 24px;
|
||||
color: rgba(255, 255, 255, 0.15);
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
align-items: center;
|
||||
flex-shrink: 0;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
|
||||
.tab_active {
|
||||
color: rgba(255, 255, 255, 0.7);
|
||||
border-bottom: solid 2px rgba(255, 255, 255, 0.7);
|
||||
}
|
||||
}
|
||||
|
||||
h3 {
|
||||
height: 60px;
|
||||
margin: 21px 0 47px;
|
||||
font-size: 14px;
|
||||
font-weight: 500;
|
||||
line-height: 1.43;
|
||||
color: #d5dee7;
|
||||
a {
|
||||
color: #d5dee7;
|
||||
.yearBox {
|
||||
display: flex;
|
||||
align-items: center;
|
||||
min-height: 377px;
|
||||
|
||||
.hiddenUl {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.autoMeetUp {
|
||||
width: 100%;
|
||||
height: 260px;
|
||||
margin: 0 auto;
|
||||
display: flex;
|
||||
position: relative;
|
||||
|
||||
.swiper-slide {
|
||||
display: flex;
|
||||
overflow: hidden;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
li {
|
||||
height: 258px;
|
||||
|
||||
.imgBox {
|
||||
position: relative;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
flex-direction: column;
|
||||
|
||||
p {
|
||||
text-align: center;
|
||||
font-weight: 500;
|
||||
font-size: 20px;
|
||||
line-height: 28px;
|
||||
color: #FFFFFF;
|
||||
}
|
||||
|
||||
img {
|
||||
margin-top: 20px;
|
||||
width: 373px;
|
||||
height: 210px;
|
||||
}
|
||||
|
||||
.button {
|
||||
position: absolute;
|
||||
right: 10px;
|
||||
bottom: 10px;
|
||||
padding: 10px 20px;
|
||||
border-radius: 28px;
|
||||
font-size: 16px;
|
||||
color: #fff;
|
||||
border: none;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2), 0 10px 50px 0 rgba(34, 43, 62, 0.1);
|
||||
background-image: linear-gradient(to bottom, rgba(85, 188, 138, 0), rgba(85, 188, 138, 0.1) 97%), linear-gradient(to bottom, #55bc8a, #55bc8a);
|
||||
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@media only screen and (max-width: 375px) {
|
||||
.swiper-slide {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
li {
|
||||
|
||||
&:nth-child(2) {
|
||||
margin: 0 0;
|
||||
}
|
||||
|
||||
img {
|
||||
width: 100% !important;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (min-width: 376px) and (max-width: $mobile-max-width) {
|
||||
|
||||
.swiper-slide {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
}
|
||||
|
||||
li {
|
||||
&:nth-child(2) {
|
||||
margin: 0 0;
|
||||
}
|
||||
|
||||
img {
|
||||
width: 373px !important;
|
||||
}
|
||||
|
||||
.button {
|
||||
right: 15px !important;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@media only screen and (min-width: 769px) and (max-width: 1160px) {
|
||||
|
||||
li {
|
||||
flex-direction: column;
|
||||
align-items: center;
|
||||
|
||||
img {
|
||||
width: 320px !important;
|
||||
height: 180px !important;
|
||||
}
|
||||
|
||||
.button {
|
||||
right: 10px;
|
||||
bottom: 40px;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.prev-button {
|
||||
display: block;
|
||||
background: url('/images/live/arrow.svg');
|
||||
width: 40px;
|
||||
height: 40px;
|
||||
position: absolute;
|
||||
bottom: 153.5px;
|
||||
left: 0px;
|
||||
transform: rotate(180deg);
|
||||
cursor: pointer;
|
||||
|
||||
@media only screen and (max-width: 767px) {
|
||||
display: none;
|
||||
}
|
||||
|
||||
@media only screen and (min-width: $mobile-max-width) and (max-width: 1160px) {
|
||||
left: 20px;
|
||||
z-index: 200;
|
||||
}
|
||||
|
||||
&:hover {
|
||||
color: #008a5c;
|
||||
background: url('/images/live/arrow-hover.svg');
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
button {
|
||||
font-size: 12px;
|
||||
font-weight: 600;
|
||||
line-height: 2;
|
||||
border: none;
|
||||
padding: 5px 28px;
|
||||
border-radius: 17px;
|
||||
cursor: pointer;
|
||||
box-shadow: 0 10px 50px 0 rgba(34, 43, 62, 0.1), 0 8px 16px 0 rgba(33, 43, 61, 0.2);
|
||||
&:hover {
|
||||
box-shadow: none;
|
||||
.next-button {
|
||||
display: block;
|
||||
background: url('/images/live/arrow.svg');
|
||||
width: 40px;
|
||||
height: 40px;
|
||||
position: absolute;
|
||||
bottom: 153.5px;
|
||||
right: 0px;
|
||||
cursor: pointer;
|
||||
|
||||
@media only screen and (max-width: 767px) {
|
||||
display: none;
|
||||
}
|
||||
|
||||
@media only screen and (min-width: $mobile-max-width) and (max-width: 1160px) {
|
||||
right: 20px;
|
||||
z-index: 200;
|
||||
}
|
||||
|
||||
&:hover {
|
||||
background: url('/images/live/arrow-hover.svg');
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
.over-btn {
|
||||
color: #ffffff;
|
||||
background-image: linear-gradient(to bottom, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.1) 97%), linear-gradient(to bottom, #242e42, #242e42);
|
||||
}
|
||||
|
||||
.notive-btn {
|
||||
color: #3d3e49;
|
||||
background-image: linear-gradient(to bottom, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.1) 97%), linear-gradient(to bottom, #ffffff, #ffffff);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
.section-5 {
|
||||
.common-layout {
|
||||
position: relative;
|
||||
padding-top: 100px;
|
||||
padding-left: 60px;
|
||||
padding-bottom: 30px;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
padding-left: 20px;
|
||||
}
|
||||
|
||||
.left-div {
|
||||
position: relative;
|
||||
width: 600px;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
width: 100%;
|
||||
z-index: 2;
|
||||
}
|
||||
|
||||
h2 {
|
||||
font-size: 32px;
|
||||
font-weight: 600;
|
||||
|
|
@ -485,13 +667,28 @@
|
|||
}
|
||||
}
|
||||
|
||||
& > img {
|
||||
&>img {
|
||||
position: absolute;
|
||||
top: 88px;
|
||||
right: 0;
|
||||
|
||||
@media only screen and (max-width: $mobile-max-width) {
|
||||
opacity: 0.3;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
.my-bullet-active {
|
||||
background: #55bc8a;
|
||||
opacity: 1;
|
||||
}
|
||||
|
||||
.swiper-horizontal>.swiper-pagination-bullets,
|
||||
.swiper-pagination-bullets.swiper-pagination-horizontal,
|
||||
.swiper-pagination-custom,
|
||||
.swiper-pagination-fraction {
|
||||
bottom: 5px;
|
||||
left: 0;
|
||||
width: 100%;
|
||||
}
|
||||
|
|
@ -180,3 +180,19 @@
|
|||
padding-top: 20px;
|
||||
}
|
||||
}
|
||||
|
||||
@mixin common-layout-special {
|
||||
position: relative;
|
||||
width: 1300px;
|
||||
margin: 0 auto;
|
||||
padding-left: 260px;
|
||||
|
||||
@media only screen and (max-width: $width-01) {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
@media only screen and (max-width: $width-02) {
|
||||
padding: 10px;
|
||||
padding-top: 20px;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -3,6 +3,8 @@ baseURL = "https://kubesphere-v3.netlify.app"
|
|||
enableRobotsTXT = true
|
||||
|
||||
[markup]
|
||||
[markup.goldmark.extensions]
|
||||
typographer = false
|
||||
[markup.tableOfContents]
|
||||
endLevel = 3
|
||||
ordered = false
|
||||
|
|
@ -10,6 +12,7 @@ enableRobotsTXT = true
|
|||
[markup.goldmark.renderer]
|
||||
unsafe= true
|
||||
|
||||
|
||||
[Taxonomies]
|
||||
|
||||
[params]
|
||||
|
|
@ -21,8 +24,6 @@ githubBlobUrl = "https://github.com/kubesphere/website/blob/master/content"
|
|||
|
||||
githubEditUrl = "https://github.com/kubesphere/website/edit/master/content"
|
||||
|
||||
mailchimpSubscribeUrl = "https://kubesphere.us10.list-manage.com/subscribe/post?u=c85ea2b944b08b951f607bdd4&id=83f673a2d9"
|
||||
|
||||
gcs_engine_id = "018068616810858123755%3Apb1pt8sx6ve"
|
||||
|
||||
githubLink = "https://github.com/kubesphere/kubesphere"
|
||||
|
|
@ -34,6 +35,7 @@ twitterLink = "https://twitter.com/KubeSphere"
|
|||
mediumLink = "https://itnext.io/@kubesphere"
|
||||
linkedinLink = "https://www.linkedin.com/company/kubesphere/"
|
||||
|
||||
|
||||
[languages.en]
|
||||
contentDir = "content/en"
|
||||
weight = 1
|
||||
|
|
@ -45,6 +47,7 @@ title = "KubeSphere | The Kubernetes platform tailored for hybrid multicloud"
|
|||
description = "KubeSphere is a distributed operating system managing cloud native applications with Kubernetes as its kernel, and provides plug-and-play architecture for the seamless integration of third-party applications to boost its ecosystem."
|
||||
keywords = "KubeSphere, Kubernetes, container platform, DevOps, hybrid cloud, cloud native"
|
||||
snapshot = "/images/common/snapshot-en.png"
|
||||
mailchimpSubscribeUrl = "https://kubesphere.us10.list-manage.com/subscribe/post?u=c85ea2b944b08b951f607bdd4&id=83f673a2d9"
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
weight = 2
|
||||
|
|
@ -105,33 +108,39 @@ hasChildren = true
|
|||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v3.1.x <img src='/images/header/star.svg' alt='star'>"
|
||||
URL = "docs/"
|
||||
name = "v3.2.x <img src='/images/header/star.svg' alt='star'>"
|
||||
URL = "/docs"
|
||||
weight = 1
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v3.1.x"
|
||||
URL = "https://v3-1.docs.kubesphere.io/docs"
|
||||
weight = 2
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v3.0.0"
|
||||
URL = "https://v3-0.docs.kubesphere.io/docs"
|
||||
weight = 2
|
||||
weight = 3
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v2.1.x"
|
||||
URL = "https://v2-1.docs.kubesphere.io/docs"
|
||||
weight = 3
|
||||
weight = 4
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v2.0.x"
|
||||
URL = "https://v2-0.docs.kubesphere.io/docs/"
|
||||
weight = 4
|
||||
weight = 5
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
parent = "Documentation"
|
||||
name = "v1.0.0"
|
||||
URL = "https://v1-0.docs.kubesphere.io/docs/"
|
||||
weight = 5
|
||||
weight = 6
|
||||
|
||||
[[languages.en.menu.main]]
|
||||
weight = 5
|
||||
|
|
@ -185,6 +194,7 @@ title = "KubeSphere | 面向云原生应用的容器混合云"
|
|||
description = "KubeSphere 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。"
|
||||
keywords = "KubeSphere, Kubernetes, 容器平台, DevOps, 混合云"
|
||||
snapshot = "/images/common/snapshot-zh.png"
|
||||
mailchimpSubscribeUrl = "https://yunify.us2.list-manage.com/subscribe/post?u=f29f08cef80223b46bad069b5&id=4838e610c2"
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
weight = 2
|
||||
|
|
@ -244,33 +254,39 @@ hasChildren = true
|
|||
name = "文档中心"
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v3.1.x <img src='/images/header/star.svg' alt='star'>"
|
||||
URL = "docs/"
|
||||
name = "v3.2.x <img src='/images/header/star.svg' alt='star'>"
|
||||
URL = "/docs/"
|
||||
weight = 1
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v3.1.x"
|
||||
URL = "https://v3-1.docs.kubesphere.io/zh/docs/"
|
||||
weight = 2
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v3.0.0"
|
||||
URL = "https://v3-0.docs.kubesphere.io/zh/docs/"
|
||||
weight = 2
|
||||
weight = 3
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v2.1.x"
|
||||
URL = "https://v2-1.docs.kubesphere.io/docs/zh-CN/"
|
||||
weight = 3
|
||||
weight = 4
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v2.0.x"
|
||||
URL = "https://v2-0.docs.kubesphere.io/docs/zh-CN/"
|
||||
weight = 4
|
||||
weight = 5
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
parent = "文档中心"
|
||||
name = "v1.0.0"
|
||||
URL = "https://v1-0.docs.kubesphere.io/docs/zh-CN/"
|
||||
weight = 5
|
||||
weight = 6
|
||||
|
||||
[[languages.zh.menu.main]]
|
||||
weight = 5
|
||||
|
|
|
|||
|
|
@ -4,5 +4,12 @@ defaultContentLanguage = "zh"
|
|||
[params]
|
||||
showCaseNumber = true
|
||||
|
||||
addBaiduAnalytics = true
|
||||
|
||||
bilibiliLink = "https://space.bilibili.com/438908638"
|
||||
mailchimpSubscribeUrl = "https://yunify.us2.list-manage.com/subscribe/post?u=f29f08cef80223b46bad069b5&id=4838e610c2"
|
||||
|
||||
[languages.en.params]
|
||||
mailchimpSubscribeUrl = "https://yunify.us2.list-manage.com/subscribe/post?u=f29f08cef80223b46bad069b5&id=4838e610c2"
|
||||
|
||||
[languages.zh.params]
|
||||
mailchimpSubscribeUrl = "https://yunify.us2.list-manage.com/subscribe/post?u=f29f08cef80223b46bad069b5&id=4838e610c2"
|
||||
|
|
|
|||
|
|
@ -90,7 +90,7 @@ section4:
|
|||
|
||||
- name: Multiple Storage and Networking Solutions
|
||||
icon: /images/home/multi-tenant-management.svg
|
||||
content: Support GlusterFS, CephRBD, NFS, LocalPV solutions, and provide CSI plugins to consume storage from multiple cloud providers. Provide a <a class='inner-a' target='_blank' href='https://porterlb.io'>load balancer Porter</a> for bare metal Kubernetes, and offers network policy management, support Calico and Flannel CNI
|
||||
content: Support GlusterFS, CephRBD, NFS, LocalPV solutions, and provide CSI plugins to consume storage from multiple cloud providers. Provide a <a class='inner-a' target='_blank' href='https://porterlb.io'>load balancer OpenELB</a> for bare metal Kubernetes, and offers network policy management, support Calico and Flannel CNI
|
||||
|
||||
features:
|
||||
|
||||
|
|
|
|||
|
|
@ -20,9 +20,9 @@ In this article, we will introduce the deployment of Kasten K10 on KubeSphere.
|
|||
|
||||
## Provision a KubeSphere Cluster
|
||||
|
||||
This article will introduce how to deploy Kasten on on KubeSphere Container Platform. You can install KubeSphere on any Kubernetes cluster or Linux system, refer to [KubeSphere documentation](https://kubesphere.io/docs/quick-start/all-in-one-on-linux/) for more details or vist the [Github]( https://github.com/kubesphere/website) of KubeSphere.
|
||||
This article will introduce how to deploy Kasten on KubeSphere Container Platform. You can install KubeSphere on any Kubernetes cluster or Linux system, refer to [KubeSphere documentation](https://kubesphere.io/docs/quick-start/all-in-one-on-linux/) for more details or vist the [Github]( https://github.com/kubesphere/website) of KubeSphere.
|
||||
|
||||
After the creation of KubeSphere cluster, you can log in to KubeSphere web console:
|
||||
After the creation of KubeSphere cluster, you can log in to the KubeSphere web console:
|
||||
|
||||

|
||||
Click the button "Platform" in the upper left corner and then select "Access Control"; Create a new workspace called Kasten-Workspace.
|
||||
|
|
@ -34,7 +34,7 @@ Enter "Kasten-workspace" and select "App Repositoties"; Add an application repos
|
|||
Add the official Helm Repository of Kasten to KubeSphere. **Helm repository address**[2]:`https://charts.kasten.io/`
|
||||
|
||||

|
||||
Once completed, the repository will find its status be "successful".
|
||||
Once completed, the repository will find its status to be "successful".
|
||||
|
||||

|
||||
## Deploy Kasten K10 on Kubernetes to Backup and Restore Cluster
|
||||
|
|
@ -76,7 +76,7 @@ global:
|
|||
create: "true"
|
||||
class: "nginx"
|
||||
```
|
||||
Click "Deploy" and wait the status to turn into "running".
|
||||
Click "Deploy" and wait for the status to turn into "running".
|
||||

|
||||
Click "Deployment" to check if Kasten has deployed workload and is in running status.
|
||||
|
||||
|
|
@ -93,7 +93,7 @@ In “Application Workloads” - “Routes” page, we can find the Gateway of I
|
|||
Input `https://192.168.99.100/k10/#` to the browser for the following log-in interface; Input the company and e-mail address to sign up.
|
||||

|
||||
|
||||
Set the locations for storing our backup data. In this case S3 compatible storage is selected.
|
||||
Set the locations for storing our backup data. In this case, S3 compatible storage is selected.
|
||||
|
||||

|
||||
|
||||
|
|
@ -105,7 +105,7 @@ Finally, start "K10 Disaster Recovery" and we can start to set "Disaster Recover
|
|||
|
||||
## Deploy Cloud Native Applications on Kubernetes
|
||||
|
||||
Kasten Dashboard holds 16 applications, which are shown as follows. We can create a Wordpress application with a Wordpress Pod and Mysql Pod, a typical application that is partly stateful and partly stateless. Here are the steps.
|
||||
Kasten Dashboard holds 16 applications, which are shown as follows. We can create a WordPress application with a WordPress Pod and Mysql Pod, a typical application that is partly stateful and partly stateless. Here are the steps.
|
||||
|
||||

|
||||
|
||||
|
|
@ -149,7 +149,7 @@ In addition, applications of the WordPress can also be find in "Applications".
|
|||
|
||||
## Back Up Cloud Native Applications
|
||||
|
||||
Click "Create Policy" and create a data backup strategy. In such case, Kasten can protect applications by creating local snapshot, and back up the application data to cloud, thus to realize the long-term retention of data.
|
||||
Click "Create Policy" and create a data backup strategy. In such a case, Kasten can protect applications by creating local snapshot, and back up the application data to cloud, thus to realize the long-term retention of data.
|
||||

|
||||
|
||||
Click "Run Once" to start backup.
|
||||
|
|
@ -183,7 +183,7 @@ In KubeSphere Dashboard, we can find these applications recovered are running.
|
|||
|
||||
## Summary
|
||||
|
||||
As a container platform, KubeSphere excels in cloud native application deployment. For application developers who are not familiar with Kubernetes and hope to make simple configuration to deploy Kasten, it is easy to follow the above steps and deploy Kasten with KubeSphere. KubeSphere helps to directly deploy the official Helm repository of Kasten K10, which performs well in data management, including backup, migration and disaster recovery.
|
||||
As a container platform, KubeSphere excels in cloud native application deployment. For application developers who are not familiar with Kubernetes and hope to make simple configurations to deploy Kasten, it is easy to follow the above steps and deploy Kasten with KubeSphere. KubeSphere helps to directly deploy the official Helm repository of Kasten K10, which performs well in data management, including backup, migration and disaster recovery.
|
||||
|
||||
|
||||
### Reference
|
||||
|
|
|
|||
|
|
@ -0,0 +1,147 @@
|
|||
---
|
||||
title: 'Kubernetes Multi-cluster Management and Application Deployment in Hybrid Cloud'
|
||||
tag: 'KubeSphere, Kubernetes, Multi-cluster Management'
|
||||
keywords: 'KubeSphere, Kubernetes, Multi-cluster Management, KubeFed'
|
||||
description: 'This post introduces Kubernetes multi-cluster management and shares how KubeSphere distributes and deploys applications in a unified manner using KubeFed in hybrid cloud.'
|
||||
createTime: '2021-12-26'
|
||||
author: 'Li Yu, Bettygogo'
|
||||
snapshot: '/images/blogs/en/Kubernetes-multicluster-KubeSphere/00-federation-control-plane.png'
|
||||
---
|
||||
|
||||
> This post introduces the development of Kubernetes multi-cluster management and existing multi-cluster solutions. It also shares how KubeSphere distributes and deploys applications in a unified manner using KubeFed in hybrid cloud for the purpose of achieving cross-region high availability and disaster recovery. Finally, it discusses the possibility of decentralized multi-cluster architecture.
|
||||
|
||||
Before initiating KubeSphere v3.0, we made a survey in the community and found that most of the users called for multi-cluster management and application deployment in different cloud environments. To meet users' needs, we added the multi-cluster management feature in KubeSphere v3.0.
|
||||
|
||||
## Kubernetes Architecture in a Single Cluster
|
||||
|
||||
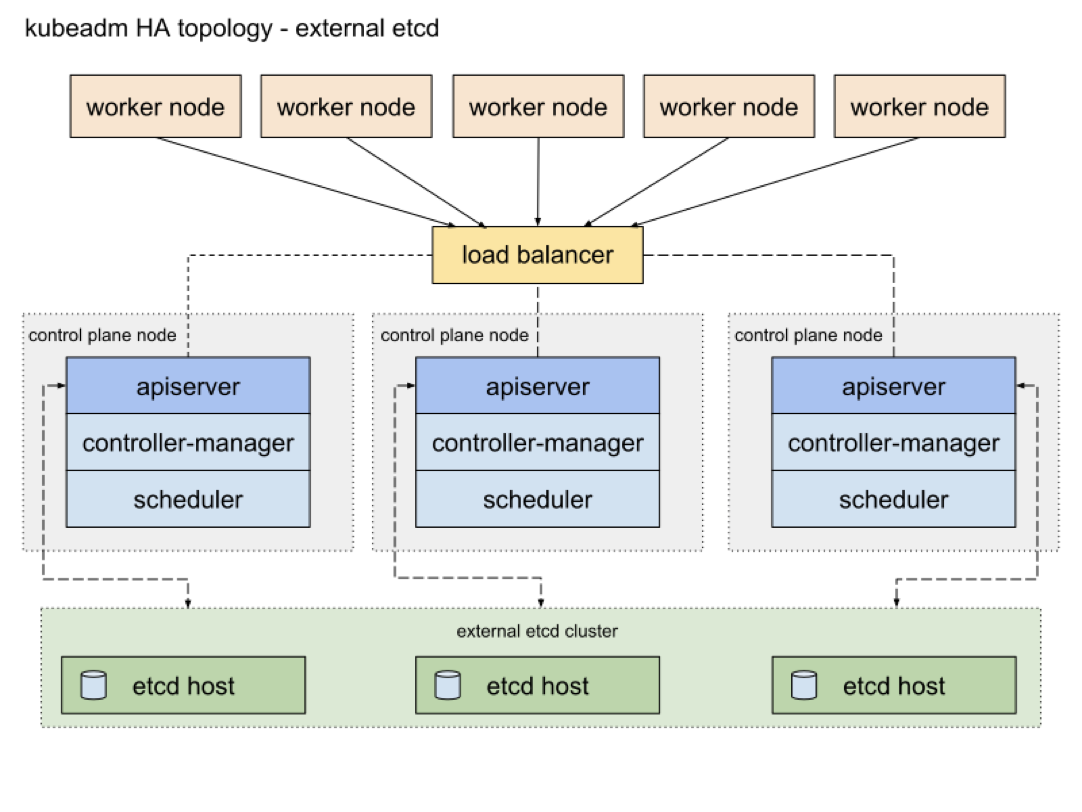
|
||||
|
||||
Kubernetes consists of the master and worker nodes. On the master node, the API server processes API requests, Controller Manager takes charge of starting multiple controllers and consistently coordinating the transition of declarative APIs from spec to status, Scheduler is used to schedule Pods, and etcd stores data of clusters. The worker nodes are mainly responsible for starting Pods.
|
||||
|
||||
Enterprises have the following expectations, which cannot be met by a single cluster:
|
||||
|
||||
- Physical isolation: Despite the fact that Kubernetes supports isolation by namespace, and you can set the CPU and memory usage of each namespace, and also use the network policy to configure network connectivity among namespaces, enterprises still need a completely isolated physical environment to make sure that services are independent from each other.
|
||||
|
||||
- Hybrid cloud: To reduce the cost, enterprises expect a package of public cloud providers and private cloud solutions to prevent vendor lock-in.
|
||||
|
||||
- Multi-site high availability for applications: To make sure that applications still work properly even though an electricity power outage occurs in a region, enterprises expect to deploy multiple replicas in clusters in different regions.
|
||||
|
||||
- Independent development, test, and production environment: Enterprises want to separately deploy the development, test, and production environments in different clusters.
|
||||
|
||||
- Scalability: A single cluster has a limited number of nodes, while multiple clusters are more scalable.
|
||||
|
||||
The most common practice is to manage different clusters using multiple Kubeconfig files, and the frontend makes multiple API calls to simultaneously deploy services. However, KubeSphere manages clusters in a more cloud native way.
|
||||
|
||||
We researched existing solutions, which mainly focus on the following:
|
||||
|
||||
- Resource distribution on the control plane, such as Federation v1 and Federation v2 launched by the Kubernetes community and Argo CD/Flux CD (distributed application pipelines).
|
||||
|
||||
- Network connectivity between Pods in different clusters, such as Cilium Mesh, Istio Multi-Cluster, and Linkerd Service Mirroring. As these projects are bound to specific CNI and service governance components, I'll only detail Federation v1 and Federation v2 in the following sections.
|
||||
|
||||
## Federation v1
|
||||
|
||||
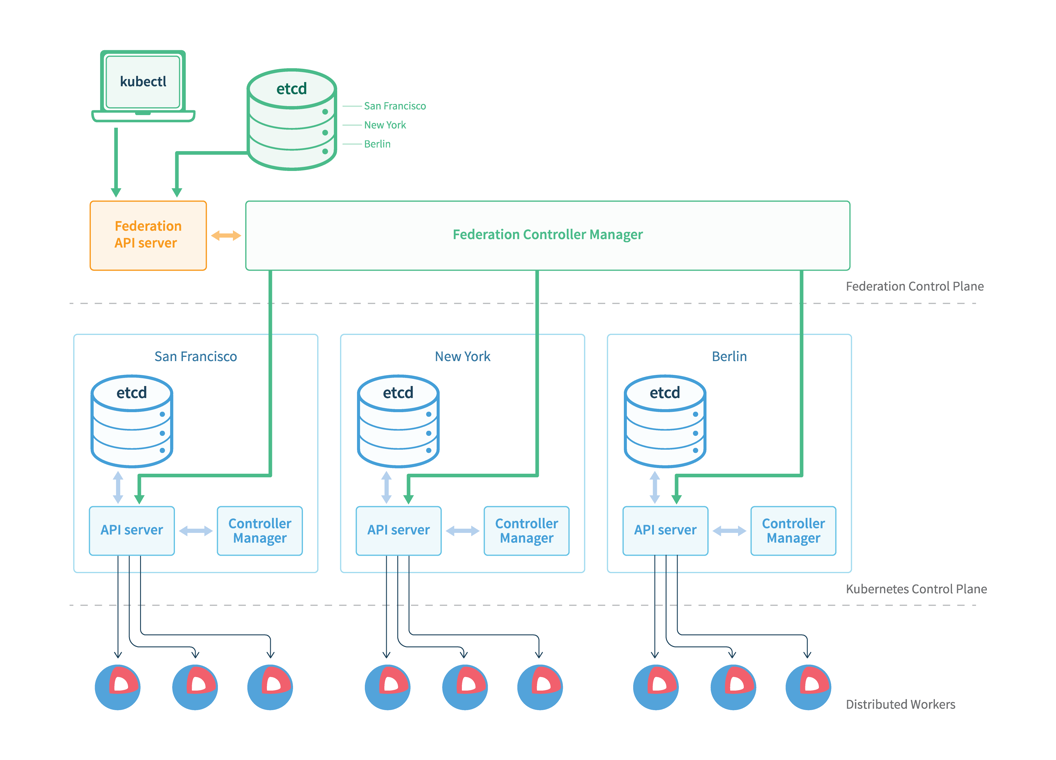
|
||||
|
||||
In the architecture of Federation v1, we can find that more than one API server (developed based on Kube-Apiserver) and Controller Manager (similar to Kube-Controller-Manager) exist. The master node is responsible for creating resource distribution tasks and distributing the resources to the worker nodes.
|
||||
|
||||
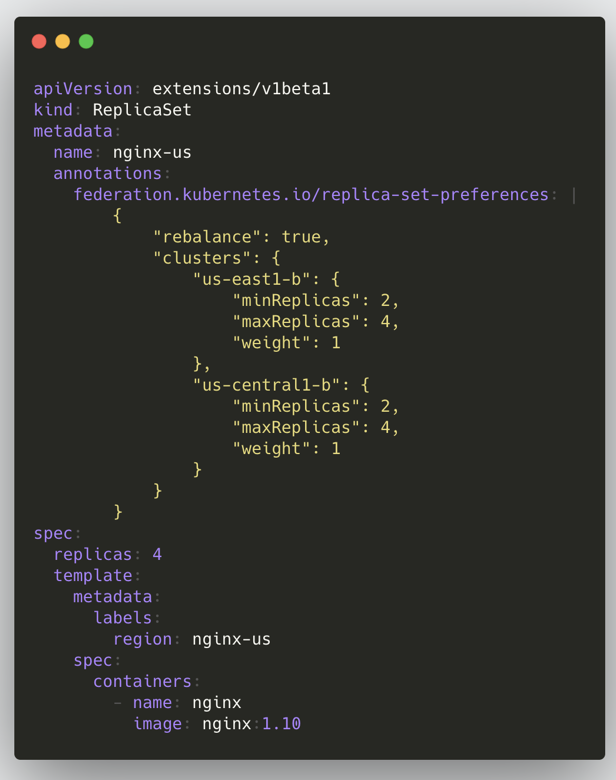
|
||||
|
||||
The previous figure shows configurations of creating ReplicaSets in Federation v1, and it can be seen that there are more annotations, which store logics of distributed resources. Federation v1 has the following drawbacks:
|
||||
|
||||
- It introduces independently developed API servers, requiring extra maintenance.
|
||||
|
||||
- In Kubernetes, an API is defined by Group/Version/Kind (GVK). Federation v1 only supports specific native Kubernetes APIs and GVKs, resulting in poor compatibility among clusters with different API versions.
|
||||
|
||||
- Federation v1 does not support role-based access control (RBAC), making it unable to provide cross-cluster permission control.
|
||||
|
||||
- Annotations-based resource distribution makes APIs too cumbersome.
|
||||
|
||||
## Federation v2
|
||||
|
||||
The Kubernetes community developed Federation v2 (KubeFed) on the basis of Federation v1. KubeFed adopts the CRD + Controller solution, which does not introduce extra API sever and does not break into native Kubernetes APIs.
|
||||
|
||||
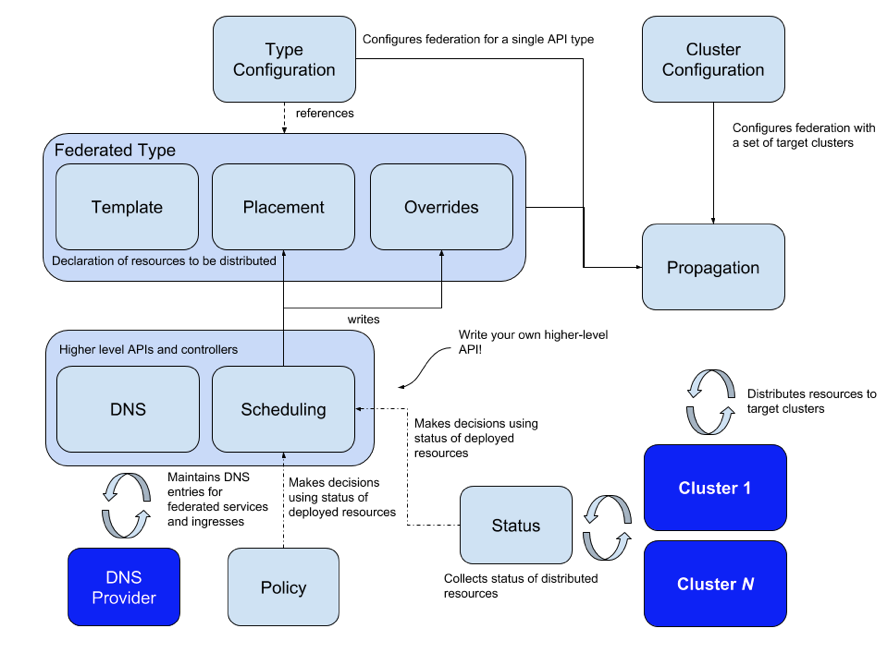
|
||||
|
||||
In the architecture of KubeFed, we can find that a custom resource definition (CRD) consists of Template, Override, and Placement. With Type Configuration, it supports APIs with different versions, which improves cluster compatibility. Moreover, it supports federation of all resources, including CRDs, service discovery, and scheduling.
|
||||
|
||||
The following exemplifies federated resources. Deployment in KubeSphere corresponds to FederatedDeployment in KubeFed. `template` in `spec` refers to the original Deployment resource, and `placement` refers to clusters where the federated resources need to be placed. In `overrides`, you can set parameters for different clusters, for example, you can set the image tag of each deployment and replicas in each cluster.
|
||||
|
||||
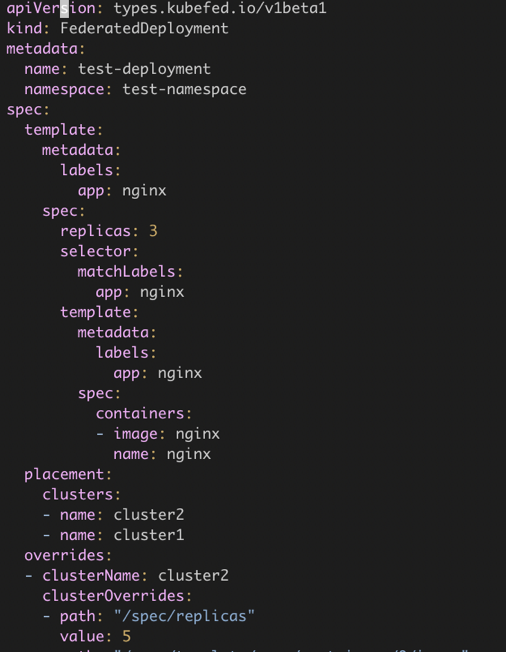
|
||||
|
||||
However, KubeFed also has the following limitations:
|
||||
|
||||
- Its APIs are complex and error-prone.
|
||||
|
||||
- No independent SDKs are provided, and binding and unbinding clusters rely on kubefedctl.
|
||||
|
||||
- It requires the network connectivity between the control plane cluster and the managed clusters, which means that APIs must be reconstructed in a multi-cluster scenario.
|
||||
|
||||
- The earlier versions cannot collect status information about federated resources.
|
||||
|
||||
## KubeSphere on KubeFed
|
||||
|
||||
Next, I'll show you how KubeSphere implements and simplifies multi-cluster management on the basis of KubeFed.
|
||||
|
||||

|
||||
|
||||
In the previous figure, the host cluster refers to the cluster with KubeFed installed, and it acts as the control plane; and the member cluster refers to the managed cluster. The host and member clusters are federated.
|
||||
|
||||

|
||||
|
||||
It can be seen that users can manage multiple clusters in a unified manner. KubeSphere defines a Cluster Object, which extends Cluster Objects of KubeFed, for example, the region zone provider.
|
||||
|
||||

|
||||
|
||||
KubeSphere allows you to import clusters in the following ways:
|
||||
|
||||
- Direct connection
|
||||
|
||||
In this case, the network between the host cluster and member clusters must be accessible. All you have to do is to use a Kubeconfig file to add the target clusters without using the complex kubefedctl.
|
||||
|
||||
- Agent connection
|
||||
|
||||
If the network between the host cluster and member clusters is not accessible, KubeFed cannot support federation. Based on Chisel, KubeSphere makes Tower open source, so that users only need to create an agent to federate clusters on private cloud.
|
||||
|
||||
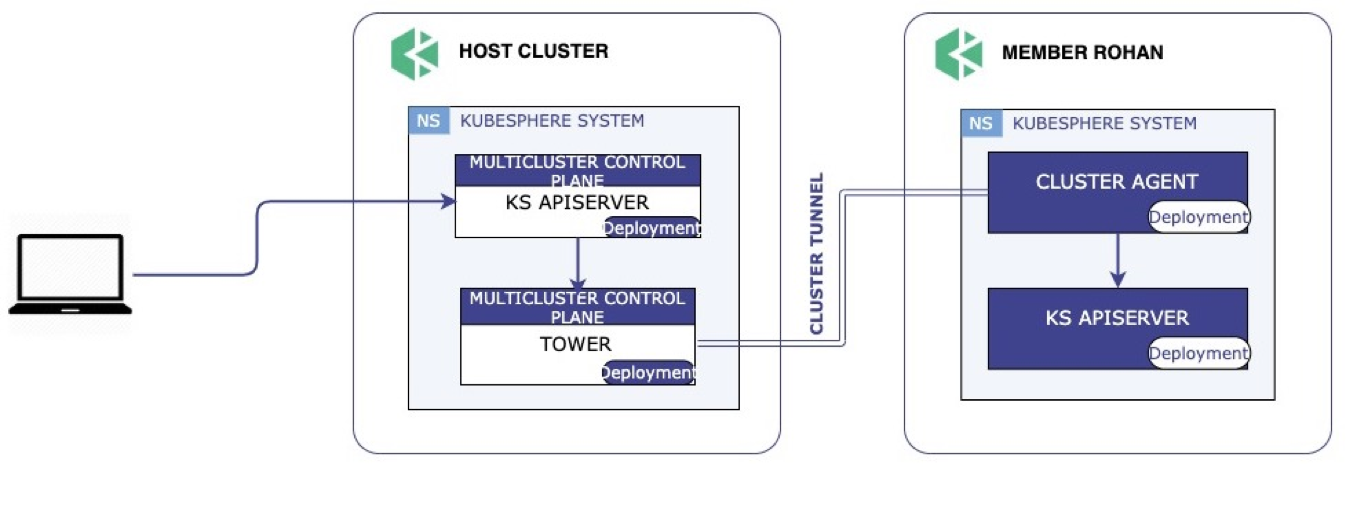
|
||||
|
||||
The workflow of Tower is as follows: (1) After you create an agent in a member cluster, the member cluster will connect to the Tower server of the host cluster; (2) The Tower server then listens to the port previously assigned by Controller and establishes a tunnel to distribute resources from the host cluster to the member cluster.
|
||||
|
||||
### Support Multi-tenant in Multi-cluster Scenarios
|
||||
|
||||

|
||||
|
||||
In KubeSphere, a tenant is a workspace, and CRDs are used to implement authorization and authentication of tenants. To make KubeFed to be less dependent on the control plane, KubeSphere delegates CRDs through the federation layer. After the host cluster receives an API request, it directly forwards the request to member clusters. Even the host cluster fails, the original tenant information is stored on the member clusters, and users can still log in to the console of the member clusters to deploy their services.
|
||||
|
||||
### Deploy Applications in Multi-cluster Scenarios
|
||||
|
||||

|
||||
|
||||
It is complex and error-prone if we manually define KubeFed APIs. When we deploy applications on KubeSphere, we can directly select the cluster where the application is to be deployed and specify replicas, and configure image address and environment variables of different clusters in **Cluster Differences**. For example, if cluster A cannot pull the gcr.io image, you can use the DockerHub address.
|
||||
|
||||
### Collect Status Information About Federated Resources
|
||||
|
||||

|
||||
|
||||
As we mentioned before, KubeFed cannot collect status information about federated resources. But don't worry, KubeSphere is always ready to help you. With our self-developed status collection tool, you can easily locate the event information and troubleshoot the failure, for example, when Pod creation fails. Moreover, KubeSphere can also monitor federated resources, which enhances observability.
|
||||
|
||||
### Planned Improvements of KubeSphere
|
||||
|
||||
Although KubeSphere simplifies federation among clusters on the basis of KubeFed, it also needs improvements.
|
||||
|
||||
- On the centralized control plane, resources can only be distributed using the push strategy, which requires that the host cluster must be highly available. Kubefed community is exploring a new possibility, that is, pulling resources from the member cluster to the host cluster.
|
||||
|
||||
- KubeSphere is an open community, and we hope that more users can join us. However, multi-cluster development needs developers to define a series of Types CRDs, which is not developer-friendly.
|
||||
|
||||
- No ideal service discovery solutions are available in multi-cluster scenarios.
|
||||
|
||||
- Currently, KubeSphere does not support Pod replica scheduling in multi-cluster scenarios. In the next version, we plan to introduce Replica Scheduling Preference.
|
||||
|
||||
If you ask me whether it is possible to avoid introducing a centralized control plane and reducing the number of APIs in a multi-cluster scenario, my answer is definitely Liqo. But before we dig into Liqo, I'd like to introduce Virtual Kubelet first.
|
||||
|
||||
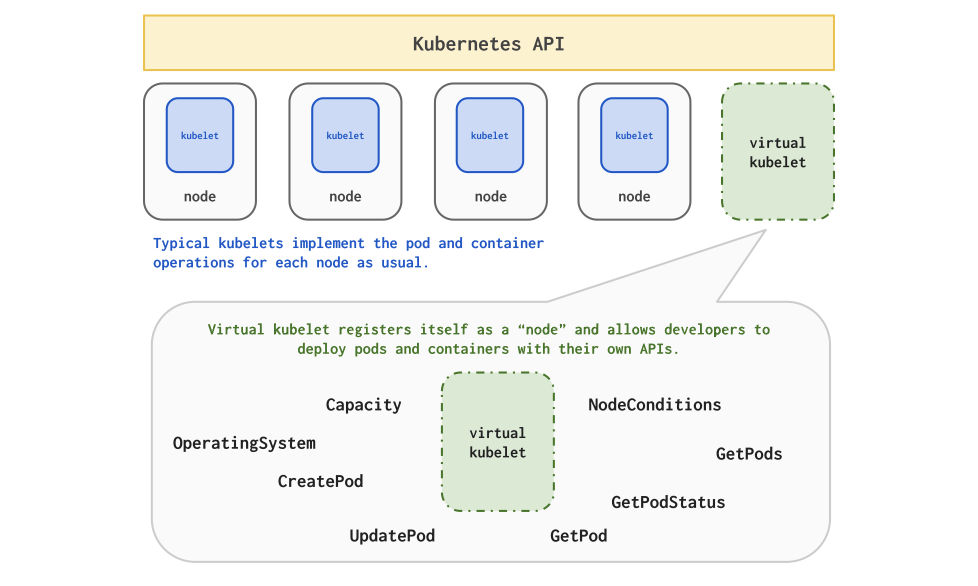
|
||||
|
||||
Virtual Kubelet allows you to simulate a Kubelet in your service as a Kubernetes node to join a Kubernetes cluster, making Kubernetes clusters more scalable.
|
||||
|
||||
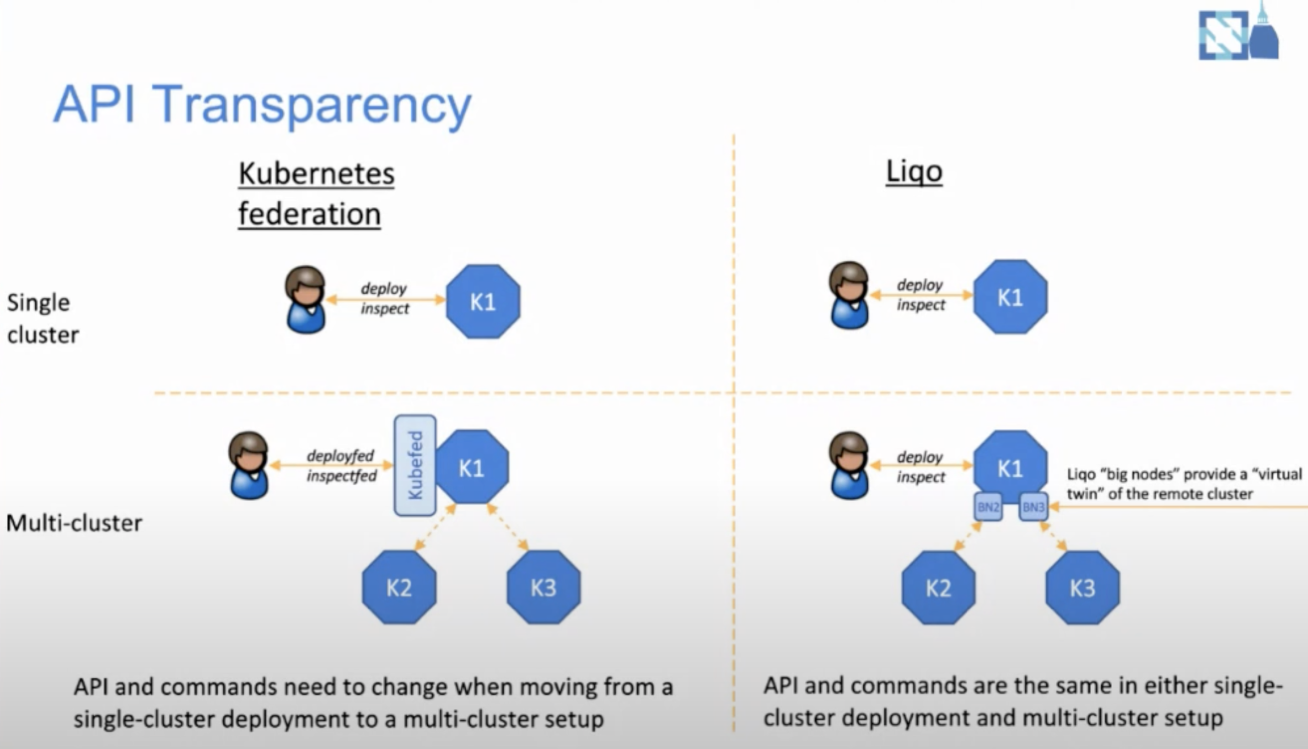
|
||||
|
||||
In Liqo, clusters are not federated. In the figure on the left, K2 and K3 clusters are the member clusters of K1 under the Kubefed architecture, and the resources distribution needs to be pushed by K1. In the figure on the right, K2 and K3 are just a node of K1. In this case, when we deploy applications, we don't need to introduce any API, K2 and K3 seem to be nodes of K1, and the services can be smoothly deployed to different clusters, which greatly reduces the complexity of transforming from a single cluster to multiple clusters. However, Liqo is still at its early stage and currently does not support topologies with more than two clusters. KubeSphere will continuously follow other open-source multi-cluster management solutions to better satisfy your needs.
|
||||
|
|
@ -115,7 +115,7 @@ You can release apps you have uploaded to KubeSphere to the public repository, a
|
|||
|
||||

|
||||
|
||||
4. On the detail page, click the version number to expand the menu where you can delete the version, deploy the app to test it, or submit it for review. KubeSphere allows you to manage an app across its entire lifecycle. For an enterprise, this is very useful when different tenants need to be isolated from each other and are only responsible for their own part as they manage an app version. For demonstration purposes, I will use the account `admin` to perform all the operations. As we do not need to test the app, click **Submit Review** directly.
|
||||
4. On the detail page, click the version number to expand the menu where you can delete the version, deploy the app to test it, or submit it for review. KubeSphere allows you to manage an app across its entire lifecycle. For an enterprise, this is very useful when different tenants need to be isolated from each other and are only responsible for their own part as they manage an app version. For demonstration purposes, I will use the user `admin` to perform all the operations. As we do not need to test the app, click **Submit Review** directly.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -60,7 +60,7 @@ Therefore, I select QingCloud Kubernetes Engine (QKE) to prepare the environment
|
|||
|
||||
5. Now, let's get back to the **Access Control** page where all the workspaces are listed. Before I proceed, first I need to create a new workspace (e.g. `dev-workspace`).
|
||||
|
||||
In a workspace, different users have different permissions to perform varied tasks in projects. Usually, a department-wide project requires a multi-tenant system so that everyone is responsible for their own part. For demonstration purposes, I use the account `admin` in this example. You can [see the official documentation of KubeSphere](https://kubesphere.io/docs/quick-start/create-workspace-and-project/) to know more about how the multi-tenant system works.
|
||||
In a workspace, different users have different permissions to perform varied tasks in projects. Usually, a department-wide project requires a multi-tenant system so that everyone is responsible for their own part. For demonstration purposes, I use the user `admin` in this example. You can [see the official documentation of KubeSphere](https://kubesphere.io/docs/quick-start/create-workspace-and-project/) to know more about how the multi-tenant system works.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,81 @@
|
|||
---
|
||||
title: 'KubeSphere Recommendations for Responding to Apache Log4j 2 Vulnerabilities'
|
||||
tag: 'CVE vulnerability'
|
||||
keywords: 'Elasticsearch, Apache Log4j, security vulnerability, KubeSphere'
|
||||
description: 'Apache Log4j 2 is an open-source logging tool that is used in a wide range of frameworks. Recently, Apache Log4j 2 vulnerabilities have been reported. This article provides KubeSphere users with recommendations for fixing the vulnerabilities.'
|
||||
createTime: '2021-12-21'
|
||||
author: 'KubeSphere Team'
|
||||
snapshot: '../../../images/blogs/log4j/log4j.jpeg'
|
||||
---
|
||||
|
||||
Apache Log4j 2 is an open-source logging tool that is used in a wide range of frameworks. Recently, Apache Log4j 2 vulnerabilities have been reported. This article provides KubeSphere users with recommendations for fixing the vulnerabilities.
|
||||
|
||||
In Log4j 2, the lookup functionality allows developers to read specific environment configurations by using some protocols. However, it does not scrutinize the input during implementation, and this is where the vulnerabilities come in. A large number of Java-based applications have been affected, including Apache Solr, srping-boot-strater-log4j2, Apache Struts2, ElasticSearch, Dubbo, Redis, Logstash, Kafka, and so on. For more information, see [Log4j 2 Documentation](https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core/usages?p=1).
|
||||
|
||||
Apache Log4j versions 2.x to 2.15.0-rc2 are affected. Currently, Apache has released Apache 2.15.0-rc2 to fix the vulnerabilities. However, this release is not stable. If you plan to upgrade to Apache 2.15.0-rc2, we recommend that you back up your data first.
|
||||
|
||||
The KubeSphere team provides the following three workarounds to fix the vulnerabilities.
|
||||
|
||||
- Set the value of environment variable `FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS` to `true`.
|
||||
- Add `log4j2.formatMsgNoLookups=True` to the configmap file.
|
||||
- Set the `-Dlog4j2.formatMsgNoLookups=true` JVM option.
|
||||
|
||||
## Workaround 1: Change the value of the environment variable
|
||||
|
||||
KubeSphere uses Elasticsearch to collect logs by default, so it's necessary to fix the vulnerabilities on KubeSphere. The following describes how to fix Elasticsearch.
|
||||
|
||||
Run the following commands to edit the Elasticsearch YAML files.
|
||||
|
||||
```yaml
|
||||
kubectl edit statefulset elasticsearch-logging-data -n kubesphere-logging-system
|
||||
kubectl edit statefulset elasticsearch-logging-discovery -n kubesphere-logging-system
|
||||
```
|
||||
|
||||
Set the value of `FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS` to `true`.
|
||||
|
||||
```yaml
|
||||
env:
|
||||
- name: FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS
|
||||
value: "true"
|
||||
```
|
||||
|
||||
## Workaround 2: Change Log4j 2 configurations
|
||||
|
||||
Run the following command to edit the configmap file.
|
||||
|
||||
```yaml
|
||||
kubectl edit configmaps elasticsearch-logging -n kubesphere-logging-system
|
||||
```
|
||||
|
||||
Add `log4j2.formatMsgNoLookups=True` to the `log4j2.properties` section.
|
||||
|
||||
```yaml
|
||||
log4j2.properties: |-
|
||||
status=error
|
||||
appender.console.type=Console
|
||||
appender.console.name=console
|
||||
appender.console.layout.type=PatternLayout
|
||||
appender.console.layout.pattern=[%d{ISO8601}][%-5p][%-25c{1.}] %marker%m%n
|
||||
rootLogger.level=info
|
||||
rootLogger.appenderRef.console.ref=console
|
||||
logger.searchguard.name=com.floragunn
|
||||
logger.searchguard.level=info
|
||||
# Add the parameter here.
|
||||
log4j2.formatMsgNoLookups=true
|
||||
```
|
||||
|
||||
|
||||
|
||||
> Note:
|
||||
>
|
||||
> 1. After you add the parameter, check whether it has been mounted successfully. If not, restart the pod.
|
||||
>
|
||||
> 2. If you have re-installed the KubeSphere logging component, configmap configurations may be reset. In this case, add the parameter again according to Workaround 2, or you can use Workaround 1.
|
||||
|
||||
## Workaround 3: Change the JVM parameter of Elasticsearch
|
||||
|
||||
You can also set the JVM option `-Dlog4j2.formatMsgNoLookups=true`. For more information, see the [Elasticsearch announcement](https://discuss.elastic.co/t/apache-log4j2-remote-code-execution-rce-vulnerability-cve-2021-44228-esa-2021-31/291476).
|
||||
|
||||
## Reference
|
||||
|
||||
Artifacts using Apache Log4j Core: https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core/usages?p=1
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 'How to Deploy an HA Kubernetes Cluster on AWS | KubeSphere KubeKey'
|
||||
title: 'How to Deploy Kubernetes on AWS'
|
||||
tag: 'Kubernetes, HA, High Availability, AWS, KubeKey'
|
||||
keywords: 'Kubernetes, HA, High Availability, AWS, KubeKey, KubeSphere'
|
||||
description: 'The KubeKey tool can be used to quickly and efficiently deploy an HA Kubernetes cluster. This article demonstrates how to deploy an HA Kubernetes cluster on AWS.'
|
||||
|
|
@ -17,7 +17,7 @@ To meet the HA service requirements of Kubernetes in AWS, we need to ensure the
|
|||
|
||||
This article uses the AWS ELB service as an example.
|
||||
|
||||
## Prerequisites
|
||||
## Prerequisites for Deployment on AWS
|
||||
|
||||
- You need to create a storage system based on NFS, GlusterFS, or Ceph. In consideration of data persistence, we do not recommend OpenEBS for production environments. This article uses OpenEBS to configure LocalPV as the default storage service only for testing.
|
||||
- All nodes can be accessed over SSH.
|
||||
|
|
@ -136,7 +136,7 @@ sudo systemctl restart sshd
|
|||
Download KubeKey from the [Github Release Page](https://github.com/kubesphere/kubekey/releases) or run the following command:
|
||||
|
||||
```
|
||||
curl -sfL https://get-kk.kubesphere.io | VERSION=v1.1.1 sh -
|
||||
curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.0 sh -
|
||||
```
|
||||
|
||||
## Use KubeKey to Deploy a Kubernetes Cluster
|
||||
|
|
@ -252,4 +252,4 @@ Run the following commands to check the deployment result:
|
|||
kubernetes 192.168.0.10:6443,192.168.0.11:6443,192.168.0.12:6443 5m10s
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -93,6 +93,8 @@ As KubeSphere supports any implementation of the Kubernetes CRI, you can easily
|
|||
```bash
|
||||
systemctl enable containerd && systemctl restart containerd
|
||||
```
|
||||
|
||||
> If `containerd config dump |grep sandbox_image` still shows `k8s.gcr.io/pause:xxx`, please add `version = 2` to the beginning of `/etc/containerd/config.toml` and run `systemctl restart containerd`.
|
||||
|
||||
4. Install crictl.
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,109 @@
|
|||
---
|
||||
title: 'How to Use KubeSphere Project Gateways and Routes'
|
||||
tag: 'KubeSphere, Kubernetes'
|
||||
keywords: 'KubeSphere, Kubernetes, Gateway, Spring Cloud'
|
||||
description: 'This article introduces the architecture of Routes, compares Routes with Kubernetes Services and other gateways, and uses SockShop as an example to demonstrate how to configure Routes.'
|
||||
createTime: '2021-11-15'
|
||||
author: 'Roland Ma, Patrick Luo'
|
||||
snapshot: '/images/blogs/how-to-use-kubernetes-project-gateways-and-routes/snapshot.png'
|
||||
---
|
||||
|
||||
KubeSphere project gateways and Routes provide a method for aggregating Services, which allows you to expose multiple Services by using a single IP address in HTTP or HTTPS mode. You can configure routing rules by using a domain name and multiple paths in a Route. The routing rules map different paths to different Services. You can also configure options such as HTTPS offloading in a Route. Project gateways forward external requests to Services according to routing rules configured in Routes.
|
||||
|
||||
## Overall Architecture
|
||||
|
||||
Project gateways are used to aggregate Services. Therefore, we can understand the project gateway architecture from the perspective of Services. The following figure shows the architecture of a project gateway in a typical production environment.
|
||||
|
||||

|
||||
|
||||
The architecture contains four parts:
|
||||
|
||||
* Nginx Ingress Controller, which is the core component of the project gateway architecture. Nginx Ingress Controller functions as a reverse proxy and obtains reverse proxy rules (routing rules) from Routes. A Route in KubeSphere is the same as an Ingress in Kubernetes. A project gateway is in effect an Nginx reverse proxy exposed by using a Service. In a production environment, the Service is usually a LoadBalancer Service, which uses a public IP address and an external load balancer provided by a cloud vendor to ensure high availability.
|
||||
* External load balancer, which is generated according to the Service settings and is usually provided by a cloud vendor. Features such as SLA, bandwidth, and IP configuration of different load balancers may vary. You can usually use annotations to configure the load balancer. Different cloud vendors may support different annotations.
|
||||
* Domain name resolution service, which is usually provided by a DNS provider. You can configure DNS records to map a domain name to the public IP address of the load balancer. If the IP address is also used by subdomain names, you can also use wildcard characters to map multiple subdomain names to the same IP address.
|
||||
* Services and Routes. You need to create Services to expose applications, and create Routes to aggregate multiple Services. Note that Nginx Ingress Controller does not use kube-proxy to forward traffic to Services. It obtains Endpoints corresponding to Pods from Services and set them as upstream targets of Nginx. Therefore, Nginx is directly connected to Pods, which avoids extra network overheads caused by Services.
|
||||
|
||||
### Compare Routes with LoadBalancer Services
|
||||
|
||||
In practice, people might be confused about the application scenarios of Routes and Services. Both of them are used to expose applications to outside the Kubernetes cluster and provide load balancing. In addition, Routes seem to depend on Services. So what are their differences? We can discuss this issue from the following perspectives:
|
||||
|
||||
* Services are originally designed to abstract application back-ends (Pods) for access over the network. All back-ends of an application are the same and are exposed using the same Service. By contrast, Routes are designed to manage API objects. Although a Route can also be used to expose a single Service, its more powerful feature is that it can aggregate multiple Services and provide a unified IP address and domain name for external access.
|
||||
* Services work at layer 4 of the OSI model and use combinations of IP addresses, ports, and protocols as unique identifiers. Therefore, IP addresses of different Services on the same network cannot be the same. For example, HTTP/HTTPS-based Services typically use ports 80 and 443. When using these Services to expose applications, you need to assign different IP addresses to different Services to avoid port conflicts, which is a waste of resources. Routes work at layer 7 of the OSI model, and all Services exposed by using Routes can share the IP address and ports 80 and 443 of the same project gateway. Each Route uses a domain name and multiple paths as unique identifiers of different Services. The project gateway forwards HTTP requests to different Services based on the domain name and paths configured in Routes.
|
||||
* Services support both TCP and UDP and do not restrict upper-layer protocols, while Routes support only HTTP, HTTPS and HTTP2 and cannot forward TCP-based or UDP-based requests.
|
||||
|
||||
From the preceding analysis, we can draw a conclusion that Routes are ideal for HTTP-based microservice architectures while Services support more protocols, though Services are not the best choice for HTTP-based applications.
|
||||
|
||||
### Compare Routes with Spring Cloud Gateway and Ocelot
|
||||
|
||||
Java and .NET Core developers must be familiar with Spring Cloud Gateway and Ocelot, which are most frequently used API gateways in Java and .NET Core respectively. So can we use these gateways directly instead of Routes and Services? To discuss this issue, we need to first have a basic understanding of API gateways:
|
||||
|
||||
> An API gateway is the sole entrance for clients to access back-end services. It functions as a reverse proxy for aggregating back-end services, routes client requests to back-end services, and returns service responses to clients. An API gateway also provides advanced features such as authentication, monitoring, load balancing, and HTTPS offloading.
|
||||
|
||||
Therefore, Routes and API gateways such as Spring Cloud Gateway and Ocelot provide similar functions. For example, you can use a Service to expose Spring Cloud Gateway to outside the cluster to achieve certain features of a Route. The following briefly analyzes their pros and cons:
|
||||
|
||||
* As application gateways, all of them can be used to forward traffic. In addition, all of them support routing rules based on domain names and paths.
|
||||
* In terms of service registration and discovery, all-in-one solutions such as Spring Cloud Gateway provide rich features and are more friendly to Java developers. Services can be seamlessly integrated by using a registration center. Ocelot does not provide a built-in service discovery and registration scheme, but you can achieve this feature by using both Ocelot and Consul. Applications deployed in a Kubernetes cluster typically use DNS-based service discovery, but no unified service registration and discovery scheme is available for clients. You need to explicitly define routing rules in a Route to expose Services. By contrast, Spring Cloud Gateway fits well into the technology stack of the development language, which makes learning much easier for developers.
|
||||
* In terms of universality, Routes (Ingresses) are the cloud-native API management standard defined by the Kubernetes community. KubeSphere uses Nginx Ingress Controller to implement the functionality of Routes by default. Meanwhile, KubeSphere is also compatible with other Ingress controllers. Routes provides only common features, while project gateways provide more operations and maintenance (O\&M) tools such as logging, monitoring, and security. By contrast, API gateways are tightly coupled with programming languages and development platforms. Usually API gateways cannot be used across different languages without the introduction of more technology stacks or client support. API gateways usually provide relatively stable features and support rich interfaces for plugins, allowing developers to extend the features by using languages they are familiar with.
|
||||
* In terms of performance, Routes based on Nginx Ingress Controller evidently outperform Spring Cloud Gateway and Ocelot.
|
||||
|
||||
Overall, each type of gateway has its own advantages and disadvantages. In the initial phase of a project, the gateway architecture should be considered. In cloud-native scenarios, Routes are an ideal choice. If your team depends on a specific technology stack, the API gateway of the technology stack is preferred. However, this does not necessarily mean you can only use one type of gateway. In some complex scenarios, you can use different types of gateways to utilize their advantages. For example, developers can use API gateways that they are familiar with to implement features such as service aggregation and authentication, and use Routes to expose these API gateways to implement features such as logging, monitoring, load balancing, and HTTPS offloading. For example, Microsoft's microservice architecture demo [eShopOnContainers](https://docs.microsoft.com/en-us/dotnet/architecture/cloud-native/introduce-eshoponcontainers-reference-app "eShopOnContainers") uses this hybrid architecture.
|
||||
|
||||
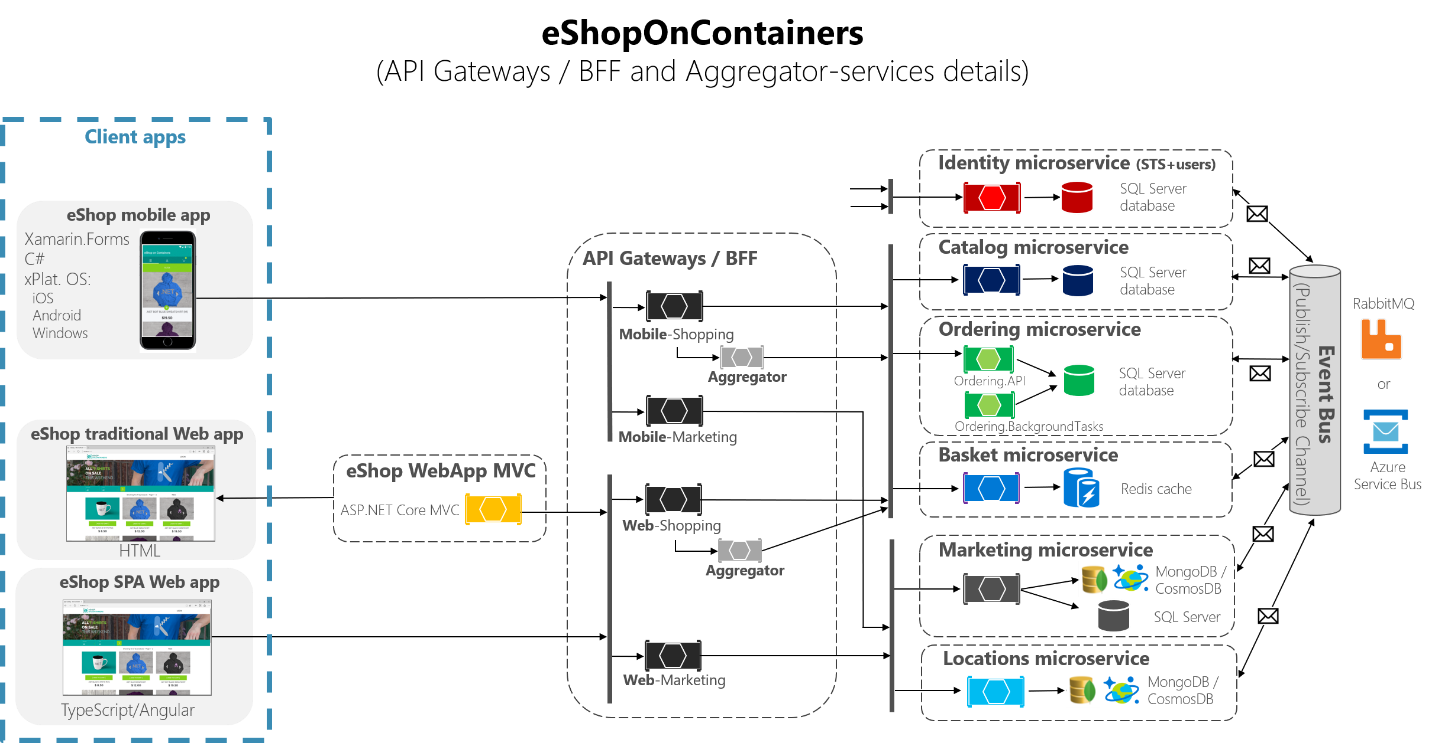
|
||||
|
||||
## Hands-on Practice
|
||||
|
||||
So far we have discussed the application scenarios and overall architecture of Routes. In the following we will demonstrate how to configure a project gateway and Route in KubeSphere. The following uses SockShop as an example, which is a microservice demo project of Weaveworks. SockShop uses an architecture where the front-end and back-end are separated. It consists of the `front-end` Service and back-end Services such as `catalogue`, `carts`, and `orders`. In the architecture, the `front-end` Service not only provides static pages, but also functions as a proxy that forwards traffic to back-end APIs. Assume that asynchronous service blocking occurs when Node.js forwards traffic to APIs, which deteriorates page performance. To address this problem, we can use Routes to directly forward traffic to the `catalogue` Service. The following describes the configuration procedure.
|
||||
|
||||
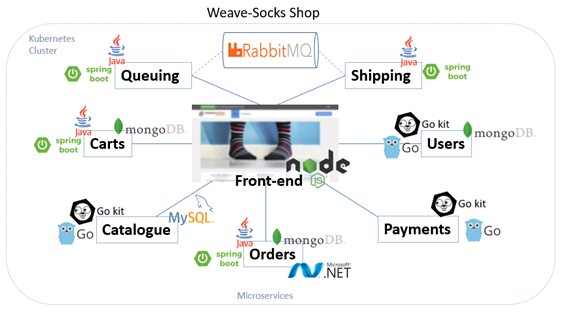
|
||||
|
||||
### Preparations
|
||||
|
||||
* Before deploying SockShop, you need to create a workspace and a project (for example, `workspace-demo` and `sock-shop`). For details, please refer to [Create Workspaces, Projects, Users, and Roles](https://kubesphere.com.cn/docs/quick-start/create-workspace-and-project/ "Create Workspaces, Projects, Users, and Roles").[](https://kubesphere.io/docs/quick-start/create-workspace-and-project/)
|
||||
|
||||
* After the `sock-shop` project is created, you need to use kubectl to deploy Services related to SockShop. You can use your local CLI console or kubectl provided by the KubeSphere toolbox to run the following command.
|
||||
|
||||
```
|
||||
kubectl -n sock-shop apply -f https://github.com/microservices-demo/microservices-demo/raw/master/deploy/kubernetes/complete-demo.yaml
|
||||
```
|
||||
|
||||
After the preceding preparations are complete, go to the **Workloads** page of the `sock-shop` project to check the workload status, and wait until all Deployments are running properly before proceeding to the next step.
|
||||
|
||||

|
||||
|
||||
### Enable the Project Gateway
|
||||
|
||||
1. Go to the `sock-shop` project, select **Project Settings** > **Advanced Settings** on the left navigation pane, and click **Enable Gateway**.
|
||||
|
||||
2. In the displayed dialog box, set parameters based on the KubeSphere installation environment. If you are using a local development environment or a private environment, you can set the gateway access mode to `NodePort`. If you are using a managed Kubernetes environment, you can set the gateway access mode to `LoadBalancer` for high availability.
|
||||
|
||||
### Create a Route
|
||||
|
||||
1. In the left navigation pane, select **Application Workloads** > **Routes**, and click **Create** on the right. On the **Basic Information** tab, set **Name** to `front-end`. On the **Routing Rules** tab, add a routing rule. This example uses the **Auto Generate** mode. The system will automatically generate a domain name in the `<Service name>.<Project name>.<Gateway IP address>.nip.io` format, and the domain name will be resolved by nip.io into the gateway IP address. Set the path, Service, and port to `/`, `front-end`, and `80` respectively. Click **Next**, and then click **Create**.
|
||||
|
||||

|
||||
|
||||
2. After the Route is created, click `front-end` in the Route list to view its details. On the **Resource Status** tab, click **Access Service**. If the Route functions properly, the following web page will be displayed.
|
||||
|
||||

|
||||
|
||||
3. Open the debugging console of your web browser (for example, press **F12** for Chrome) to check the network requests of the SockShop web page. The following figure shows an API request sent to `catalogue`.
|
||||
|
||||
|
||||
|
||||
`X-Powered-By: Express` in `Response Headers` shows that the request is forwarded by the `front-end` Node.js application.
|
||||
|
||||
4. On the details page of `front-end`, select **More** > **Edit Routing Rules**. In the displayed **Edit Routing Rules** dialog box, select the routing rule created in step 1, and click the edit icon on the right. Click **Add** to add a new path, and set the path, Service, and port to `/catalogue`, `catalogue`, and `80` respectively. Click **Save** to save the settings. The following figure shows the edited rule.
|
||||
|
||||

|
||||
|
||||
5. Refresh the SockShop web page (the page shows no changes) and check the network requests in the debugging console, as shown in the following figure.
|
||||
|
||||
|
||||
|
||||
`X-Powered-By: Express` does not exist in `Response Headers`, which means that the API request is directly sent to the `catalogue` Service according to the new routing rule without being forwarded by the `front-end` Service. In this example, two routing rules are configured in the Route. The `/catalogue` routing rule is preferred to the `/` routing rule because the path of the former is longer and therefore more accurate.
|
||||
|
||||
For more information about the Route settings, please refer to [Routes](https://kubesphere.io/docs/project-user-guide/application-workloads/routes/ "Routes").
|
||||
|
||||
## Summary
|
||||
|
||||
This article briefly introduces the architecture of Routes, and compares Routes with Kubernetes Services and other application gateways. The SockShop example shows how to configure a project gateway and a Route. We would be delighted if this article can help you better understand Routes and choose the most appropriate method to expose applications based on their characteristics.
|
||||
|
|
@ -0,0 +1,259 @@
|
|||
---
|
||||
title: 'Install Kubernetes 1.23, containerd, and Multus CNI the Easy Way'
|
||||
tag: 'Kubernetes, KubeKey'
|
||||
keywords: 'Kubernetes, containerd, docker, Multus CNI, '
|
||||
description: 'Install Kubernetes 1.23, containerd, and Multus CNI in a Linux machine within minutes.'
|
||||
createTime: '2021-12-26'
|
||||
author: 'Feynman'
|
||||
snapshot: '/images/blogs/en/kubekey-containerd/kubernetes-containerd-banner.png'
|
||||
---
|
||||
|
||||

|
||||
|
||||
[KubeKey](https://github.com/kubesphere/kubekey) is a lightweight and turn-key installer that supports the installation of Kubernetes, KubeSphere and related add-ons. Writtent in Go, KubeKey enables you to set up a Kubernetes cluster within minutes.
|
||||
|
||||
Kubernetes 1.23 [was released on Dec 7](https://kubernetes.io/blog/2021/12/07/kubernetes-1-23-release-announcement/). KubeKey has supported the installation of the latest version Kubernetes in its v2.0.0 alpha release, and also brought some new features such as support for Multus CNI, Feature Gates, and easy-to-use air-gapped installation, etc.
|
||||
|
||||
This blog will demonstrate how to install Kubernetes 1.23.0, [containerd](https://containerd.io/), and [Multus CNI](https://github.com/k8snetworkplumbingwg/multus-cni) the easy way using KubeKey.
|
||||
|
||||
## Step 1: Prepare a Linux Machine
|
||||
|
||||
You need to prepare one or more hosts according to the following requirements for hardware and operating system. This blog uses a Linux server to start the all-in-one installation.
|
||||
|
||||
### Hardware Recommendations
|
||||
|
||||
<table>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th width='320'>OS</th>
|
||||
<th>Minimum Requirements</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>Ubuntu</b> <i>16.04</i>, <i>18.04</i></td>
|
||||
<td>2 CPU cores, 2 GB memory, and 40 GB disk space</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><b>Debian</b> <i>Buster</i>, <i>Stretch</i></td>
|
||||
<td>2 CPU cores, 2 GB memory, and 40 GB disk space</td>
|
||||
</tr><tr>
|
||||
<td><b>CentOS</b> <i>7.x</i></td>
|
||||
<td>2 CPU cores, 2 GB memory, and 40 GB disk space</td>
|
||||
</tr><tr>
|
||||
<td><b>Red Hat Enterprise Linux 7</b></td>
|
||||
<td>2 CPU cores, 2 GB memory, and 40 GB disk space</td>
|
||||
</tr><tr>
|
||||
<td><b>SUSE Linux Enterprise Server 15/openSUSE Leap 15.2</b></td>
|
||||
<td>2 CPU cores, 2 GB memory, and 40 GB disk space</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Node requirements
|
||||
|
||||
- The node can be accessed through `SSH`.
|
||||
- `sudo`/`curl`/`openssl` should be used.
|
||||
|
||||
### Dependency requirements
|
||||
|
||||
The dependency that needs to be installed may be different based on the Kubernetes version to be installed. You can refer to the following list to see if you need to install relevant dependencies on your node in advance.
|
||||
|
||||
<table>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>Dependency</th>
|
||||
<th>Kubernetes Version ≥ 1.18</th>
|
||||
<th>Kubernetes Version < 1.18</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>socat</code></td>
|
||||
<td>Required</td>
|
||||
<td>Optional but recommended</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>conntrack</code></td>
|
||||
<td>Required</td>
|
||||
<td>Optional but recommended</td>
|
||||
</tr><tr>
|
||||
<td><code>ebtables</code></td>
|
||||
<td>Optional but recommended</td>
|
||||
<td>Optional but recommended</td>
|
||||
</tr><tr>
|
||||
<td><code>ipset</code></td>
|
||||
<td>Optional but recommended</td>
|
||||
<td>Optional but recommended</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
In case you use a CentOS 7.7 server, you could install socat and conntrack using the following commands:
|
||||
|
||||
```
|
||||
yum install socat
|
||||
yum install conntrack-tool
|
||||
```
|
||||
|
||||
### Network and DNS requirements
|
||||
|
||||
- Make sure the DNS address in `/etc/resolv.conf` is available. Otherwise, it may cause some issues of DNS in the cluster.
|
||||
- If your network configuration uses firewall rules or security groups, you must ensure infrastructure components can communicate with each other through specific ports. It is recommended that you turn off the firewall. For more information, see [Port Requirements](../../docs/installing-on-linux/introduction/port-firewall/).
|
||||
- Supported CNI plugins: Calico, Flannel, Cilium, Kube-OVN, and Multus CNI
|
||||
|
||||
## Step 2: Download KubeKey
|
||||
|
||||
Perform the following steps to download KubeKey.
|
||||
|
||||
{{< tabs >}}
|
||||
|
||||
{{< tab "Good network connections to GitHub/Googleapis" >}}
|
||||
|
||||
Download KubeKey from its [GitHub Release Page](https://github.com/kubesphere/kubekey/releases) or run the following command:
|
||||
|
||||
```bash
|
||||
curl -L https://github.com/kubesphere/kubekey/releases/download/v2.0.0-alpha.4/kubekey-v2.0.0-alpha.4-linux-amd64.tar.gz > installer.tar.gz && tar -zxf installer.tar.gz
|
||||
```
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "Poor network connections to GitHub/Googleapis" >}}
|
||||
|
||||
Run the following command first to make sure you download KubeKey from the correct zone.
|
||||
|
||||
```bash
|
||||
export KKZONE=cn
|
||||
```
|
||||
|
||||
Run the following command to download KubeKey:
|
||||
|
||||
```bash
|
||||
curl -L https://github.com/kubesphere/kubekey/releases/download/v2.0.0-alpha.4/kubekey-v2.0.0-alpha.4-linux-amd64.tar.gz > installer.tar.gz && tar -zxf installer.tar.gz
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
After you download KubeKey, if you transfer it to a new machine also with poor network connections to Googleapis, you must run `export KKZONE=cn` again before you proceed with the following steps.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{</ tabs >}}
|
||||
|
||||
Make `kk` executable:
|
||||
|
||||
```bash
|
||||
chmod +x kk
|
||||
```
|
||||
|
||||
## Step 3: Enable the Multus CNI installation (Optional)
|
||||
|
||||
If you want to customize the installation, for example, enable the Multus CNI installation, you can create an example configuration file with default configurations.
|
||||
Otherwise, you can skip this step.
|
||||
|
||||
```
|
||||
./kk create config --with-kubernetes v1.23.0
|
||||
```
|
||||
|
||||
A default file `config-sample.yaml` will be created if you do not change the name. Edit the file and here is an example of the configuration file of a Kubernetes cluster with one master node. You need to update the host information and enable Multus CNI. We use a single node for this demo, and you can also configure a multi-node Kubernetes cluster as you want. See [Multi-node installation](../../docs/installing-on-linux/introduction/multioverview/) for details.
|
||||
|
||||
```
|
||||
apiVersion: kubekey.kubesphere.io/v1alpha2
|
||||
kind: Cluster
|
||||
metadata:
|
||||
name: sample
|
||||
spec:
|
||||
hosts: // updated the host template refer to this example
|
||||
- {name: master1, address: 192.168.0.5, internalAddress: 192.168.0.5, password: Qcloud@123}
|
||||
roleGroups:
|
||||
etcd:
|
||||
- master1
|
||||
master:
|
||||
- master1
|
||||
worker:
|
||||
- master1
|
||||
controlPlaneEndpoint:
|
||||
##Internal loadbalancer for apiservers
|
||||
#internalLoadbalancer: haproxy
|
||||
|
||||
domain: lb.kubesphere.local
|
||||
address: ""
|
||||
port: 6443
|
||||
kubernetes:
|
||||
version: v1.23.0
|
||||
clusterName: cluster.local
|
||||
network:
|
||||
plugin: calico
|
||||
kubePodsCIDR: 10.233.64.0/18
|
||||
kubeServiceCIDR: 10.233.0.0/18
|
||||
# multus support. https://github.com/k8snetworkplumbingwg/multus-cni
|
||||
enableMultusCNI: true // Change false to true to enable Multus CNI
|
||||
```
|
||||
|
||||
## Step 4: Get Started with Installation
|
||||
|
||||
{{< tabs >}}
|
||||
|
||||
{{< tab "If you have enabled Multus CNI" >}}
|
||||
|
||||
You can run the following command to create a cluster using the configuration file.
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml --container-manager containerd
|
||||
```
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "If you skiped Multus CNI above" >}}
|
||||
|
||||
You only need to run one command for all-in-one installation.
|
||||
|
||||
```bash
|
||||
./kk create cluster --with-kubernetes v1.23.0 --container-manager containerd
|
||||
```
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{</ tabs >}}
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- Supported Kubernetes versions: v1.19.8, v1.20.4, v1.21.4, v1.22.1, v1.23.0. If you do not specify a Kubernetes version, KubeKey installs Kubernetes v1.21.5 by default. For more information about supported Kubernetes versions, see [Support Matrix](https://github.com/kubesphere/kubekey/blob/master/docs/kubernetes-versions.md).
|
||||
- KubeKey supports AMD64 and ARM64.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
After you run the command, you will see a table for environment check. For details, see [Node requirements](#node-requirements) and [Dependency requirements](#dependency-requirements). Type `yes` to continue.
|
||||
|
||||
## Step 5: Verify the Installation
|
||||
|
||||
If the following information is displayed, Kubernetes is successfully installed.
|
||||
|
||||
```bash
|
||||
INFO[00:40:00 CST] Congratulations! Installation is successful.
|
||||
```
|
||||
|
||||
Run the following command to check the container runtime and Kubernetes version.
|
||||
|
||||
```bash
|
||||
$ kubectl get node -o wide
|
||||
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
|
||||
i-a26jzcsm Ready control-plane,master,worker 7h56m v1.23.0 192.168.0.5 <none> CentOS Linux 7 (Core) 3.10.0-1160.el7.x86_64 containerd://1.4.9
|
||||
```
|
||||
|
||||
Run the following command to check the Pod status.
|
||||
|
||||
```bash
|
||||
kubectl get pod -A
|
||||
NAMESPACE NAME READY STATUS RESTARTS AGE
|
||||
kube-system calico-kube-controllers-64d69886fd-c5qd9 1/1 Running 0 7h57m
|
||||
kube-system calico-node-lc4fg 1/1 Running 0 7h57m
|
||||
kube-system coredns-7c94484977-nvrdf 1/1 Running 0 7h57m
|
||||
kube-system coredns-7c94484977-rtc24 1/1 Running 0 7h57m
|
||||
kube-system kube-apiserver-i-a26jzcsm 1/1 Running 0 7h57m
|
||||
kube-system kube-controller-manager-i-a26jzcsm 1/1 Running 0 7h57m
|
||||
kube-system kube-multus-ds-btb42 1/1 Running 0 7h30m
|
||||
kube-system kube-proxy-bntt9 1/1 Running 0 7h57m
|
||||
kube-system kube-scheduler-i-a26jzcsm 1/1 Running 0 7h57m
|
||||
kube-system nodelocaldns-zmx9t 1/1 Running 0 7h57m
|
||||
```
|
||||
|
||||
Congratulations! You have installed a sing-node Kubernetes 1.23.0 cluster with containerd and Multus CNI. For advanced usage of KubeKey, see [Installing on Linux — Overview](https://kubesphere.io/docs/installing-on-linux/introduction/intro/) for more information.
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: 'Install Kubernetes 1.22 and containerd the Easy Way'
|
||||
tag: 'Kubernetes, containerd'
|
||||
tag: 'Kubernetes, KubeKey'
|
||||
keywords: 'Kubernetes, containerd, docker, installation'
|
||||
description: 'Install Kubernetes and containerd in a Linux machine within minutes.'
|
||||
createTime: '2021-09-29'
|
||||
|
|
@ -51,7 +51,7 @@ To get started with all-in-one installation, you only need to prepare one host a
|
|||
|
||||
### Dependency requirements
|
||||
|
||||
KubeKey can install Kubernetes and KubeSphere together. The dependency that needs to be installed may be different based on the Kubernetes version to be installed. You can refer to the following list to see if you need to install relevant dependencies on your node in advance.
|
||||
The dependency that needs to be installed may be different based on the Kubernetes version to be installed. You can refer to the following list to see if you need to install relevant dependencies on your node in advance.
|
||||
|
||||
<table>
|
||||
<tbody>
|
||||
|
|
@ -84,7 +84,7 @@ KubeKey can install Kubernetes and KubeSphere together. The dependency that need
|
|||
### Network and DNS requirements
|
||||
|
||||
- Make sure the DNS address in `/etc/resolv.conf` is available. Otherwise, it may cause some issues of DNS in the cluster.
|
||||
- If your network configuration uses firewall rules or security groups, you must ensure infrastructure components can communicate with each other through specific ports. It is recommended that you turn off the firewall. For more information, see [Port Requirements](../../installing-on-linux/introduction/port-firewall/).
|
||||
- If your network configuration uses firewall rules or security groups, you must ensure infrastructure components can communicate with each other through specific ports. It is recommended that you turn off the firewall. For more information, see [Port Requirements](../../docs/installing-on-linux/introduction/port-firewall/).
|
||||
- Supported CNI plugins: Calico and Flannel. Others (such as Cilium and Kube-OVN) may also work but note that they have not been fully tested.
|
||||
|
||||
## Step 2: Download KubeKey
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 'KubeKey: A Lightweight Installer for Kubernetes and Cloud Native Addons'
|
||||
title: 'How to Install Kubernetes the Easy Way Using KubeKey'
|
||||
keywords: Kubernetes, KubeSphere, KubeKey, addons, installer
|
||||
description: KubeKey allows you to deploy a Kubernetes cluster in the most graceful and efficient way.
|
||||
tag: 'KubeSphere, Kubernetes, KubeKey, addons, installer'
|
||||
|
|
@ -26,7 +26,7 @@ The general steps of installing Kubernetes using KubeKey:
|
|||
|
||||
## Prepare Hosts
|
||||
|
||||
I am going to create a cluster with three nodes on cloud. Here is my machine configuration for your reference:
|
||||
I am going to create a Kubernetes cluster with three nodes on cloud. Here is my machine configuration for your reference:
|
||||
|
||||
| Host IP | Host Name | Role | System |
|
||||
| ----------- | --------- | ------------ | ----------------------------------------- |
|
||||
|
|
@ -93,7 +93,7 @@ You can use KubeKey to install a specified Kubernetes version. The dependency th
|
|||
The default Kubernetes version is v1.17.9. For more information about supported Kubernetes versions, see this [file](https://github.com/kubesphere/kubekey/blob/master/docs/kubernetes-versions.md). Execute the following command as an example:
|
||||
|
||||
```bash
|
||||
./kk create config --with-kubernetes v1.17.9
|
||||
./kk create config --with-kubernetes v1.20.4
|
||||
```
|
||||
|
||||
4. A default file `config-sample.yaml` will be created if you do not customize the name. Edit the file.
|
||||
|
|
@ -161,7 +161,7 @@ You can use KubeKey to install a specified Kubernetes version. The dependency th
|
|||
|
||||
- `worker`: worker node names.
|
||||
|
||||
You can provide more values in this configuration file, such as `addons`. KubeKey can install all [addons](https://github.com/kubesphere/kubekey/blob/release-1.0/docs/addons.md) that can be installed as a YAML file or Chart file. For example, KubeKey does not install any storage plugin for Kubernetes by default, but you can [add your own storage systems](https://kubesphere.io/docs/installing-on-linux/persistent-storage-configurations/understand-persistent-storage/), including NFS Client, Ceph, and Glusterfs. For more information about the configuration file, see [Kubernetes Cluster Configurations](https://kubesphere.io/docs/installing-on-linux/introduction/vars/) and [this file](https://github.com/kubesphere/kubekey/blob/release-1.0/docs/config-example.md).
|
||||
You can provide more values in this configuration file, such as `addons`. KubeKey can install all [addons](https://github.com/kubesphere/kubekey/blob/release-1.0/docs/addons.md) that can be installed as a YAML file or Chart file. For example, KubeKey does not install any storage plugin for Kubernetes by default, but you can [add your own storage systems](https://kubesphere.io/docs/installing-on-linux/persistent-storage-configurations/understand-persistent-storage/), including NFS Client, Ceph, and GlusterFS. For more information about the configuration file, see [Kubernetes Cluster Configurations](https://kubesphere.io/docs/installing-on-linux/introduction/vars/) and [this file](https://github.com/kubesphere/kubekey/blob/release-1.0/docs/config-example.md).
|
||||
|
||||
6. Save the file when you finish editing and execute the following command to install Kubernetes:
|
||||
|
||||
|
|
|
|||
|
|
@ -190,7 +190,7 @@ Now that we have our server machine ready, we need to install `nfs-common` on al
|
|||
3. Specify a Kubernetes version and a KubeSphere version that you want to install. For more information about supported Kubernetes versions, see [this list](https://github.com/kubesphere/kubekey/blob/master/docs/kubernetes-versions.md).
|
||||
|
||||
```bash
|
||||
./kk create config --with-kubernetes v1.17.9 --with-kubesphere v3.0.0
|
||||
./kk create config --with-kubernetes v1.20.4 --with-kubesphere v3.0.0
|
||||
```
|
||||
|
||||
4. A default file `config-sample.yaml` will be created if you do not customize the name. Edit the file.
|
||||
|
|
|
|||
|
|
@ -0,0 +1,134 @@
|
|||
---
|
||||
title: 'Integrate KubeSphere with Okta Authentication'
|
||||
keywords: Kubernetes, KubeSphere, Okta, OIDC, Authentication
|
||||
description: Explore third-party authentication integration with KubeSphere.
|
||||
tag: 'Kubernetes, KubeSphere, Okta, OIDC, Authentication'
|
||||
createTime: '2021-12-01'
|
||||
author: 'Roland Ma, Felix'
|
||||
snapshot: '/images/blogs/en/okta/oidc.png'
|
||||
---
|
||||
|
||||
KubeSphere, with [its latest release of 3.2.0](../kubesphere-3.2.0-ga-announcement/), provides a built-in authentication service based on [OpenID Connect](https://openid.net/connect/) (OIDC) in addition to its support for AD/LDAP and OAuth 2.0 identity authentication systems. You can easily integrate your existing identify providers that support the OIDC standard.
|
||||
|
||||
This article uses [Okta](https://www.okta.com/) as an example to look into the process of how to integrate KubeSphere with an OIDC identity provider.
|
||||
|
||||
## What is OpenID Connect?
|
||||
|
||||
OpenID Connect (OIDC) is an identity layer built on top of the OAuth 2.0 framework. As an open authentication protocol, OIDC allows clients to verify the identity of an end user and to obtain basic user profile information.
|
||||
|
||||
Curious about the major characteristics of OIDC?
|
||||
|
||||
- **Use of identity tokens**. OIDC extends the authentication capabilities of OAuth by using components such as an "ID token" issued as a JSON Web Token (JWT).
|
||||
- **Based on the OAuth 2.0 framework**. The ID token is obtained through a standard OAuth 2.0 flow, which also means having one protocol for authentication and authorization.
|
||||
- **Simplicity**. OIDC is simple enough to integrate with basic applications, but it also has the features and security options to match demanding enterprise requirements.
|
||||
|
||||
## What is Okta?
|
||||
|
||||
Okta is a customizable, secure, and drop-in solution to add authentication and authorization services to your applications. It uses cloud software which helps organizations in managing and securing user authentications into applications.
|
||||
|
||||
Okta provides you with a variety of advantages. I'll just name a few here.
|
||||
|
||||
- **Single Sign-On (SSO)**. Okta’s SSO solution can quickly connect to and sync from any number of identity stores including AD, LDAP, HR systems, and other third-party identity providers.
|
||||
- **Adaptive multifactor authentication**. Okta secures accounts and applications with a strong multifactor authentication solution.
|
||||
- **Personalized user experience**. Okta provides ease of use for end users to access applications.
|
||||
|
||||
## Practice: Integrate KubeSphere with Okta
|
||||
|
||||
### Preparations
|
||||
|
||||
As mentioned above, this article explains how to integrate KubeSphere with Okta. Therefore, you have to prepare a KubeSphere cluster in advance. You can take a look at [this tutorial](https://kubesphere.io/docs/quick-start/all-in-one-on-linux/) to quickly set up your own KubeSphere cluster.
|
||||
|
||||
### (Optional) Step 1: Enable HTTPS for KubeSphere web console
|
||||
|
||||
For production environment, HTTPS is recommended as it provides better security. If you don't need HTTPS in your environment, you can skip this step.
|
||||
|
||||
1. To enable HTTPS for your KubeSphere web console, you need to get a certificate from a Certificate Authority (CA). For example, you can apply a certificate from [Let's Encrypt](https://letsencrypt.org/).
|
||||
2. [cert-manager](https://github.com/jetstack/cert-manager/) is a Kubernetes add-on to automate the management and issuance of TLS certificates from various issuing sources. To set up your cert-manager, you can take a look at [this example](https://cert-manager.io/docs/tutorials/acme/ingress/#step-5-deploy-cert-manager). I won't go into details here.
|
||||
|
||||
In this article, let's use the URL https://console.kubesphere.io for accessing the KubeSphere web console.
|
||||
|
||||
### (Optional) Step 2: Create an Okta account
|
||||
|
||||
If you already have an Okta account, you can skip this step, but you need to make sure your existing Okta account has the admin permission. If not, go to the [Okta Workforce Identity Trial](https://www.okta.com/free-trial/) page to create an account.
|
||||
|
||||
1. Enter your information in the required fields and click **Get Started**.
|
||||
|
||||

|
||||
|
||||
2. After you receive the activation email from Okta and activate your account, you can log in to Okta using the registered domain.
|
||||
|
||||
3. When you log in Okta for the first time, you will be asked to set up multifactor authentication. For more information, you can refer to [Okta documentation](https://help.okta.com/en/prod/Content/Topics/Security/mfa/mfa-home.htm).
|
||||
|
||||
### Step 3: Create an Okta application
|
||||
|
||||
1. On the Okta admin console, select **Applications > Applications** on the left navigation pane and click **Create App Integration**.
|
||||
|
||||

|
||||
|
||||
2. In the displayed dialog box, select **OIDC - OpenID Connect**, select **Web Application**, and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. For **General Settings**, you need to configure the following settings:
|
||||
|
||||
- **App integration name**. Specify a name for your application integration.
|
||||
|
||||
- **Logo (Optional)**. Add a logo for your application integration.
|
||||
|
||||
- **Grant type**. Select **Authorization Code** and **Refresh Token**.
|
||||
|
||||
- **Sign-in redirect URIs**. The sign-in redirect URI is where Okta sends the authentication response and ID token for a sign-in request. In this example, I won't use the wildcard `*` in the sign-in redirect URI, which needs to be set in the format of `http(s)://<Domain or IP address:port>/oauth/redirect/<Provider name>`. `<Provider name>` can be set based on your needs, but it has to be consistent with the `name` specified under the `identityProviders` section in the CRD `ClusterConfiguration`.
|
||||
|
||||
- **Sign-out redirect URIs (Optional)**. When KubeSphere contacts Okta to close a user session, Okta redirects the user to this URI.
|
||||
|
||||
- (Optional) **Controlled access**. The default access option assigns and grants access to everyone in your Okta organization for this new app integration. Besides, you can choose to limit access to selected groups and use the field to enter the names of specific groups in your organization, or skip group assignment for now and create the app without assigning a group.
|
||||
|
||||

|
||||
|
||||
When you finish configuring your settings, click **Save** to commit your application.
|
||||
|
||||
4. On the Okta application page, you can click your application to go to its details page. On the General tab, you can see the **Client ID** and **Client secret**. We will need them later on when configuring the CRD `ClusterConfiguration` on KubeSphere.
|
||||
|
||||

|
||||
|
||||
### Step 4: Make configurations on KubeSphere
|
||||
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/common-icons/hammer.png" width="20" /> in the lower-right corner, click **kubectl**, and run the following command to edit `ks-installer` of the CRD `ClusterConfiguration`:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit cc ks-installer
|
||||
```
|
||||
|
||||
2. Add the following fields under `spec.authentication.jwtSecret`.
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
authentication:
|
||||
jwtSecret: ''
|
||||
oauthOptions:
|
||||
identityProviders:
|
||||
- mappingMethod: auto
|
||||
name: Okta
|
||||
provider:
|
||||
clientID: **** # Get from Otka
|
||||
clientSecret: **** # Get from Otka
|
||||
issuer: https://kubesphere.Okta.com # Your Okta domain
|
||||
redirectURL: https://console.kubesphere.io/oauth/redirect/Okta
|
||||
scopes:
|
||||
- openid
|
||||
- email
|
||||
- profile
|
||||
type: OIDCIdentityProvider
|
||||
```
|
||||
|
||||
3. After the fields are configured, save your changes, and wait until the restart of ks-installer is complete. Okta login button is shown on the **Login** page of KubeSphere and you are redirected to Okta login page when clicking it. You will be required to register a valid username when log in to KubeSphere for the first time.
|
||||
|
||||

|
||||
|
||||
4. After you successfully log in to KubeSphere, you can assign roles for the users.
|
||||
|
||||
## Recap
|
||||
|
||||
KubeSphere provides various ways to integrate with your existing identity providers. I believe OIDC is one of the easiest methods, which also enjoys support from many identity providers. Hope you can get a better understanding of how to integrate KubeSphere with Okta by following the steps in this article.
|
||||
|
||||
Last but not the least, enjoy exploring KubeSphere!
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
---
|
||||
title: 'Kubernetes Fundamental 1: Pods, Nodes, Deployments and Ingress'
|
||||
tag: 'Kubernetes, fundamentals, beginners, guide'
|
||||
keywords: 'Kubernetes, fundamentals, beginners, guide'
|
||||
description: 'Kubernetes was born out of the necessity to make our sophisticated software more available, scalable, transportable, and deployable in small, independent modules.'
|
||||
createTime: '2021-10-14'
|
||||
author: 'Pulkit Singh'
|
||||
snapshot: '/images/blogs/en/kubernetes-fundamentals-part-1/main-poster.png'
|
||||
---
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Hi! Today we'll discuss something that everyone is familiar with if they've heard the term "Containers." Yes, It's "Kubernetes"!!
|
||||
|
||||
“Kubernetes was born out of the necessity to make our sophisticated software more available, scalable, transportable, and deployable in small, independent modules.”
|
||||
|
||||
Kubernetes is gaining popularity as the future cloud software deployment and management standard. However, Kubernetes has a steep learning curve that comes with all of its capabilities. As a rookie, it can be tough to comprehend the concepts and core principles. There are a lot of pieces that make up the system, and determining which ones are vital for your scenario might be tough.
|
||||
|
||||
So, what’s the need for it??
|
||||
|
||||
|
||||
## Do we need Kubernetes?
|
||||
|
||||

|
||||
|
||||
Kubernetes is a platform for container-based application orchestration control resource allocation, and traffic management for applications and microservices in the Kubernetes ecosystem.
|
||||
|
||||
As a result, many aspects of maintaining a service-oriented application infrastructure have been made easier. Kubernetes, when combined with modern continuous integration and continuous deployment (CI/CD) systems, provides the foundation for scaling these apps with minimal technical work.
|
||||
|
||||
So now it's time to talk about Kubernetes' fundamental notions!
|
||||
|
||||
Some concepts to understand:
|
||||
|
||||
## Containers
|
||||

|
||||
|
||||
Containers solve a significant issue in application development. Programmers work in a development environment when they write code. When they're ready to put the code into production, this is where problems arise. The code that worked on their machine does not work in production. Differences in operating systems, dependencies, and libraries are only a few of the reasons for this.
|
||||
Containers solved this fundamental problem of portability by separating code from the infrastructure it operates on. Developers may choose to package their application into a small container image that contains all of the binaries and libraries it needs to run.
|
||||
Any computer with a containerization platform such as Docker or containerd can run that container in production.
|
||||
|
||||
## Pods
|
||||

|
||||
|
||||
A Pod (as in a pod of whales or a pod of peas) is a group of one or more containers that share storage and network resources and operate according to a set of rules. A Pod's content is always co-located, scheduled, and executed in the same environment. A Pod is a "logical host" for an application that incorporates one or more tightly coupled application containers.
|
||||
In a non-cloud context, applications running on the same physical or virtual computer are analogous to cloud applications running on the same logical host.
|
||||
|
||||
## Nodes
|
||||

|
||||
|
||||
A node is the smallest unit of computer hardware in Kubernetes. It's a representation of one of the computers in your cluster. Most production systems will have a node that is either a physical machine in a data center or a virtual machine housed on a cloud provider like Google Cloud Platform. Don't let traditions limit you; in theory, you can make a node out of almost anything.
|
||||
Thinking of a machine as a "node" adds another degree of abstraction. Instead of worrying about each machine's characteristics, we can now just see it as a collection of CPU and RAM resources that can be utilized. Any machine in a Kubernetes cluster can be used to replace any other machine in this approach
|
||||
In this, we have two terms known as:
|
||||

|
||||
|
||||
|
||||
- Nodes ( Master )
|
||||
The master node controls the state of the cluster; for example, which applications are running and their corresponding container images.
|
||||
|
||||
- Nodes ( Worker )
|
||||
Workloads execute in a container on physical or virtual servers.
|
||||
|
||||
## Cluster
|
||||

|
||||
|
||||
A cluster is a collection of machines on which containerized applications are run. Containerizing apps encapsulates an app's dependencies as well as some essential services. They are lighter and more adaptable than virtual machines. In this approach, clusters make it easier to design, move, and maintain applications.
|
||||
Containers may run on numerous computers and environments, including virtual, physical, cloud-based, and on-premises, thanks to clusters. Unlike virtual machines, containers are not limited to a single operating system. Instead, they can share operating systems and execute from any location.
|
||||
clusters are comprised of one master node and several worker nodes.
|
||||
|
||||
## Persistent Volumes
|
||||

|
||||
|
||||
Data can't be stored to any arbitrary location in the file system since programs operating on your cluster aren't guaranteed to run on a certain node. If a program attempts to store data to a file for later use but is then moved to a different node, the file will no longer be where the program expects it to be. As a result, each node's typical local storage is viewed as a temporary cache for holding programs, but any data saved locally cannot be expected to last.
|
||||
Persistent Volumes are used by Kubernetes to store data indefinitely. While the cluster successfully pools and manages the CPU and RAM resources of all nodes, persistent file storage is not. As a Persistent Volume, local or cloud disks can be linked to the cluster. This is similar to connecting an external hard disk to the cluster. Persistent Volumes are a file system that can be mounted on the cluster without being tied to a specific node. A user's request for storage is called a PersistentVolumeClaim (PVC). It looks like a Pod. Node resources are consumed by pods, and PV resources are consumed by PVCs. Pods can request specified resource levels (CPU and Memory). The specific size and access modes might be requested in claims.
|
||||
|
||||
## Deployments
|
||||

|
||||
|
||||
The basic function of a deployment is to specify how many clones of a pod should be running at any given time. When you add deployment to the cluster, it will automatically start up the necessary number of Pods and monitor them. If a pod dies, the deployment will recreate it automatically.
|
||||
You don't have to deal with pods manually if you use a deployment. Simply describe the system's desired state, and it will be managed for you automatically.
|
||||
|
||||
## Ingress
|
||||

|
||||
|
||||
Ingress offers HTTP and HTTPS routes to services within the cluster from outside the cluster. Rules established on the Ingress resource control traffic routing. An Ingress can be set up to provide Services with externally accessible URLs, load balance traffic, terminate SSL/TLS, and provide name-based virtual hosting. An Ingress controller is in charge of completing the Ingress, usually with a load balancer, but it may also configure your edge router or additional front ends to assist in traffic handling. An Ingress does not disclose any ports or protocols to the public. A service of type Service is often used to expose services other than HTTP and HTTPS to the internet.
|
||||
|
||||
## Interactive hands-on tutorials
|
||||
So we have talked a lot about basic concepts, so now if you want to learn Kubernetes from scratch do take a look at these interactive tutorials, you can run Kubernetes and practice it in your browser.
|
||||
|
||||
- [Learn Kubernetes using Interactive Browser-Based Scenarios](https://www.katacoda.com/courses/kubernetes)
|
||||
|
||||
- [Install KubeSphere on Kubernetes cluster](https://www.katacoda.com/kubesphere/scenarios/install-kubesphere-on-kubernetes)
|
||||
|
||||
|
||||
|
||||
## Conclusion
|
||||
So at last, we have discussed all the basic concepts you need to get started to work with Kubernetes. If you want to start experimenting with it, then do take a look at [Kubernetes getting started docs.](https://kubernetes.io/docs/setup/)
|
||||
|
||||
so get started with it and stay tuned for more such content!
|
||||
|
|
@ -0,0 +1,145 @@
|
|||
---
|
||||
title: 'KubeSphere 3.2.0 GA: Bringing AI-oriented GPU Scheduling and Flexible Gateway'
|
||||
tag: 'KubeSphere, release'
|
||||
keyword: 'Kubernetes, KubeSphere, release, AI, GPU'
|
||||
description: 'KubeSphere 3.2.0 supports GPU resource scheduling and management and GPU usage monitoring, which further improves user experience in cloud-native AI scenarios. Moreover, enhanced features such as multi-cluster management, multi-tenant management, observability, DevOps, app store, and service mesh further perfect the interactive design for better user experience.'
|
||||
createTime: '2021-11-03'
|
||||
author: 'KubeSphere'
|
||||
snapshot: '/images/blogs/en/release-announcement3.2.0/v3.2.0-GA-cover.png'
|
||||
---
|
||||
|
||||

|
||||
|
||||
No one would ever doubt that **Cloud Native** has become the most popular service technology. KubeSphere, a distributed operating system for cloud-native application management with Kubernetes as its kernel, is definitely one of the tide riders surfing the cloud-native currents. KubeSphere has always been upholding the commitment of 100% open source. Owing to support from the open-source community, KubeSphere has rapidly established a worldwide presence.
|
||||
|
||||
On November 2, 2021, we are excited to announce KubeSphere 3.2.0 is generally available!
|
||||
|
||||
In KubeSphere 3.2.0, **GPU resource scheduling and management** and GPU usage monitoring further improve user experience in cloud-native AI scenarios. Moreover, enhanced features such as **multi-cluster management**, **multi-tenant management** , **observability**, **DevOps**, **app store, and service mesh** further perfect the interactive design for better user experience.
|
||||
|
||||
It's also worth pointing out that KubeSphere 3.2.0 would not be possible without participation and contribution from enterprises and users outside QingCloud. You are everywhere, from feature development, test, defect report, proposal, best practice collection, bug fixing, internationalization to documentation. We appreciate your help and will give an acknowledgement at the end of the article.
|
||||
|
||||
## **What's New in KubeSphere 3.2.0**
|
||||
|
||||
### **GPU scheduling and quota management**
|
||||
|
||||
With the rapid development of artificial intelligence (AI) and machine learning, more and more AI companies are calling for GPU resource scheduling and management features for server clusters, especially monitoring of GPU usage and management of GPU resource quotas. To address users' pain points, KubeSphere 3.2.0 makes our original GPU management even easier.
|
||||
|
||||
KubeSphere 3.2.0 allows you to create GPU workloads on the GUI, schedule GPU resources, and manage GPU resource quotas by tenant. Specifically, it can be used for NVIDIA GPU and vGPU solutions.
|
||||
|
||||

|
||||
|
||||
### **Enhanced Kubernetes observability**
|
||||
|
||||
Growing container and microservice technologies make it more complex to call components between systems, and the number of processes running in the system is also surging. With thousands of processes running in a distributed system, it is clear that conventional monitoring techniques are incapable of tracking the dependencies and calling paths between these processes, and this is where observability within the system becomes particularly important.
|
||||
|
||||
***Observability is the ability to measure the internal states of a system by examining its outputs.*** A system is considered "observable" if the current state can be estimated by only using information from outputs, namely telemetry data collected by the three pillars of observability: logging, tracing and metrics.
|
||||
|
||||
1. More powerful custom monitoring dashboards
|
||||
|
||||
KubeSphere 3.1.0 has added the cluster-level custom monitoring feature, which allows you to generate custom Kubernetes monitoring dashboards by selecting a default template, uploading a template, or customizing a template. KubeSphere 3.2.0 provides a default template for creating a Grafana monitoring dashboard. You can import a Grafana monitoring dashboard by specifying the URL or uploading the JSON file of the dashboard, and then KubeSphere will automatically convert the Grafana monitoring dashboard into a custom monitoring dashboard.
|
||||
|
||||

|
||||
|
||||
For GPU resources, KubeSphere 3.2.0 also provides a default monitoring template with a wealth of metrics, so that you don't need to customize a template or edit a YAML file.
|
||||
|
||||

|
||||
|
||||
2. Alerting and logging
|
||||
|
||||
- KubeSphere 3.2.0 supports communication with Elasticsearch through HTTPS.
|
||||
|
||||
- In addition to the various notification channels such as email, DingTalk, WeCom, webhook, and Slack, KubeSphere 3.2.0 now also allows you to test and validate the notification channels you configure.
|
||||
|
||||

|
||||
|
||||
3. On the etcd monitoring page, the system automatically adds the `Leader` tag to the etcd leader.
|
||||
|
||||
### **Multi-cloud and multi-cluster management**
|
||||
|
||||
CNCF Survey 2020 shows that over 80% of users run more than two Kubernetes clusters in their production environment. KubeSphere aims at addressing multi-cluster and multi-cloud challenges. It provides a unified control plane and supports distributing applications and replicas to multiple Kubernetes clusters deployed across public cloud and on-premises environments. Moreover, KubeSphere supports observability across clusters, including features such as multi-dimensional monitoring, logging, events, and auditing logs.
|
||||
|
||||

|
||||
|
||||
KubeSphere 3.2.0 performs better in cross-cluster scheduling. When you are creating a federated Deployment across clusters, you can directly specify the number of replicas scheduled to each cluster. In addition, you can also specify the total number of replicas and weight of each cluster, and allow the system to automatically schedule replicas to each cluster according its weight. This feature is pretty helpful when you want to flexibly scale your Deployment and proportionally distribute replicas to multiple clusters.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### **Operations-and-maintenance-friendly storage management**
|
||||
|
||||
Enterprises running Kubernetes in production focus on persistent storage, as stable and reliable storage underpin their core data. On the KubeSphere 3.2.0 web console, the **Volumes** feature allows the administrator to decide whether to enable volume cloning, snapshot capturing, and volume expansion, making persistent storage operations and maintenance for stateful apps more convenient.
|
||||
|
||||

|
||||
|
||||
The default immediate binding mode binds a volume to a backend storage device immediately when the volume is created. This mode does not apply to storage devices with topology limits and may cause Pod scheduling failures. KubeSphere 3.2.0 provides the delayed binding mode to address this issue, which guarantees that a volume (PVC) is bound to a volume instance (PV) only after the volume is mounted to a Pod. This feature ensures that resources are properly scheduled based on Pod resource requests.
|
||||
|
||||

|
||||
|
||||
In addition to volume management, KubeSphere 3.2.0 now also supports Persistent Volume management, and you can view Persistent Volume information, edit Persistent Volumes, and delete Persistent Volumes on the web console.
|
||||
|
||||

|
||||
|
||||
When you create a volume snapshot, you can specify the snapshot type (`VolumeSnapshotClass`) to use a specific storage backend.
|
||||
|
||||
### **Cluster gateway**
|
||||
|
||||
KubeSphere 3.1 supports only project gateways, which require multiple IP addresses when there are multiple projects. Additionally, gateways in different workspaces are independent.
|
||||
|
||||
KubeSphere 3.2.0 provides a cluster gateway, which means that all projects can share the same gateway. Existing project gateways are not affected by the cluster gateway.
|
||||
|
||||

|
||||
|
||||
The administrator can directly manage and configure all project gateways on the cluster gateway settings page without having to go to each workspace. The Kubernetes ecosystem provides many ingress controllers that can be used as the gateway solution. In KubeSphere 3.2.0, the gateway backend is refactored, which allows you to use any ingress controllers that support v1\\ingress as the gateway solution.
|
||||
|
||||

|
||||
|
||||
### **Authentication and authorization**
|
||||
|
||||
A unified and all-round identity management and authentication system is indispensable for logical isolation in a multi-tenant system. Apart from support for AD/LDAP and OAuth 2.0 identity authentication systems, KubeSphere 3.2.0 also provides a built-in authentication service based on OpenID Connect to provide authentication capability for other components. OpenID Connect is a simple user identity authentication protocol based on OAuth 2.0 with a bunch of features and security options to meet enterprise-grade business requirements.
|
||||
|
||||
### **App Store open to community partners**
|
||||
|
||||
The App Store and application lifecycle management are unique features of KubeSphere, which are based on self-developed and open-source [OpenPitrix](https://github.com/openpitrix/openpitrix).
|
||||
|
||||
KubeSphere 3.2.0 adds the feature of **dynamically loading community-developed Helm charts into the KubeSphere App Store.** You can send a pull request containing the Helm chart of a new app to the App Store chart repository. After the pull request is merged, the app is automatically loaded to the App Store regardless of the KubeSphere version. Welcome to submit your Helm charts to https://github.com/kubesphere/helm-charts. Nocalhost and Chaos Mesh have integrated their Helms charts into KubeSphere 3.2.0 by using this method, and you can easily install them to your Kubernetes clusters by one click.
|
||||
|
||||

|
||||
|
||||
### **More independent Kubernetes DevOps (on KubeSphere)**
|
||||
|
||||
Kubernetes DevOps (on KubeSphere) has developed into an independent project [ks-devops](https://github.com/kubesphere/ks-devops) in KubeSphere v3.2.0, which is intended to allow users to run Kubernetes DevOps (on KubeSphere) in any Kubernetes clusters. Currently, you can use a Helm chart to install the backend components of ks-devops.
|
||||
|
||||
Jenkins is a CI engine with a large user base and a rich plug-in ecosystem. In KubeSphere 3.2.0, we will let Jenkins do what it is good at—functioning only as an engine in the backend to provide stable pipeline management capability. A newly added CRD PipelineRun encapsulates run records of pipelines, which reduces the number of APIs required for directly interacting with Jenkins and boosts performance of CI pipelines.
|
||||
|
||||
Starting from KubeSphere v3.2.0, Kubernetes DevOps (on KubeSphere) allows you to build images by using pipelines based on containerd. As an independent project, Kubernetes DevOps (on KubeSphere) will support independent deployment of the backend and frontend, introduce GitOps tools such as Tekton and ArgoCD, as well as integrate project management and test management platforms.
|
||||
|
||||
### **Flexible Kubernetes cluster deployment**
|
||||
|
||||
If you do not have a Kubernetes cluster, you can use KubeKey to install both Kubernetes and KubeSphere; if you already have a Kubernetes cluster, you can use ks-installer to install KubeSphere only.
|
||||
|
||||
[KubeKey](https://github.com/kubesphere/kubekey) is an efficient open-source installer, which uses Docker as the default container runtime. It can also use CRI runtimes such as containerd, CRI-O, and iSula. You can use KubeKey to deploy an etcd cluster independent of Kubernetes for better flexibility.
|
||||
|
||||
KubeKey provides the following new features:
|
||||
|
||||
- Supports the latest Kubernetes version 1.22.1 (backward compatible with 4 earlier versions); supports deployment of K3s (experimental).
|
||||
|
||||
- Supports automatic renewal of Kubernetes cluster certificates.
|
||||
|
||||
- Supports a high availability deployment mode that uses an internal load balancer to reduce the complexity of cluster deployment.
|
||||
|
||||
- Most of the integrated components such as Istio, Jaeger, Prometheus Operator, Fluent Bit, KubeEdge, and Nginx ingress controller have been updated to the latest. For more information, refer to [Release Notes 3.2.0](https://kubesphere.io/docs/release/release-v320/).
|
||||
|
||||
### **Better user experience**
|
||||
|
||||
To provide a user-friendly web console for global users, our SIG Docs members have refactored and optimized the UI text on the web console to deliver more professional and accurate UI text and terms. Hard-coded and concatenated UI strings are removed for better UI localization and internationalization support.
|
||||
|
||||
Some heavy users in the KubeSphere community have participated in enhancing some frontend features. For example, KubeSphere now supports searching for images in a Harbor registry and mounting volumes to init containers, and the feature of automatic workload restart during volume expansion is removed.
|
||||
|
||||
For more information about user experience optimization, enhanced features, and fixed bugs, please refer to [Release Notes 3.2.0](https://kubesphere.io/docs/release/release-v320/). You can download and install KubeSphere 3.2.0 by referring to [All-in-One on Linux](https://kubesphere.io/docs/quick-start/all-in-one-on-linux/ ) and [Minimal KubeSphere on Kubernetes](https://kubesphere.io/docs/quick-start/minimal-kubesphere-on-k8s/), and we will offer an offline installation solution in the KubeSphere community in one week.
|
||||
|
||||
## **Acknowledgements**
|
||||
|
||||
The KubeSphere team would like to acknowledge contributions from the people who make KubeSphere 3.2.0 possible. The following GitHub IDs are not listed in order. If you are not listed, please contact us.
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,85 @@
|
|||
---
|
||||
title: 'OpenELB Joins the CNCF Sandbox, Making Service Exposure in Private Environments Easier'
|
||||
tag: 'CNCF'
|
||||
keyword: 'OpenELB, Kubernetes, LoadBalancer, Bare metal server'
|
||||
description: 'CNCF accepted OpenELB, a load balancer plugin open sourced by KubeSphere, into the CNCF Sandbox'
|
||||
createTime: '2021-11-24'
|
||||
author: 'KubeSphere'
|
||||
snapshot: 'https://kubesphere-community.pek3b.qingstor.com/images/4761636694917_.pic_hd.jpg'
|
||||
---
|
||||
|
||||

|
||||
|
||||
On November 10, the Cloud Native Computing Foundation (CNCF) accepted OpenELB, a load balancer plugin open sourced by KubeSphere, into the CNCF Sandbox.
|
||||
|
||||

|
||||
|
||||
OpenELB, formerly known as "PorterLB", is a load balancer plugin designed for bare metal servers, edge devices, and private environments. It serves as an LB plugin for Kubernetes, K3s, and KubeSphere to expose LoadBalancer services to outside the cluster. OpenELB provides the following core functions:
|
||||
- Load balancing in BGP mode and Layer 2 mode
|
||||
- ECMP-based load balancing
|
||||
- IP address pool management
|
||||
- BGP configurations using CRDs
|
||||
|
||||
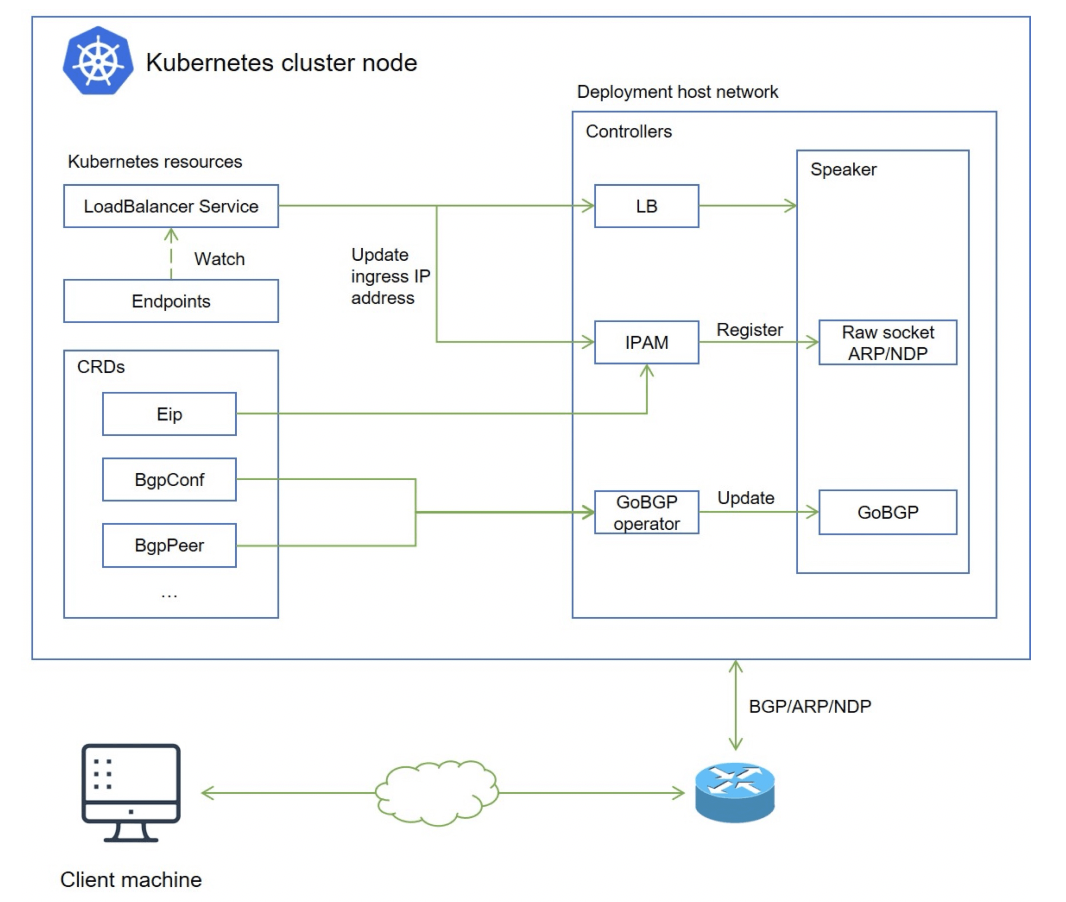
|
||||
|
||||
## Why Did We Initiate OpenELB
|
||||
In the KubeSphere community, we surveyed over 5,000 users to find out environments that they use to deploy Kubernetes, and the result shows that nearly 36% of the users deploy Kubernetes on bare metal servers, and many users install and use Kubernetes or K3s on air-gapped data centers or edge devices. In private environments, exposing LoadBalancer services is difficult.
|
||||
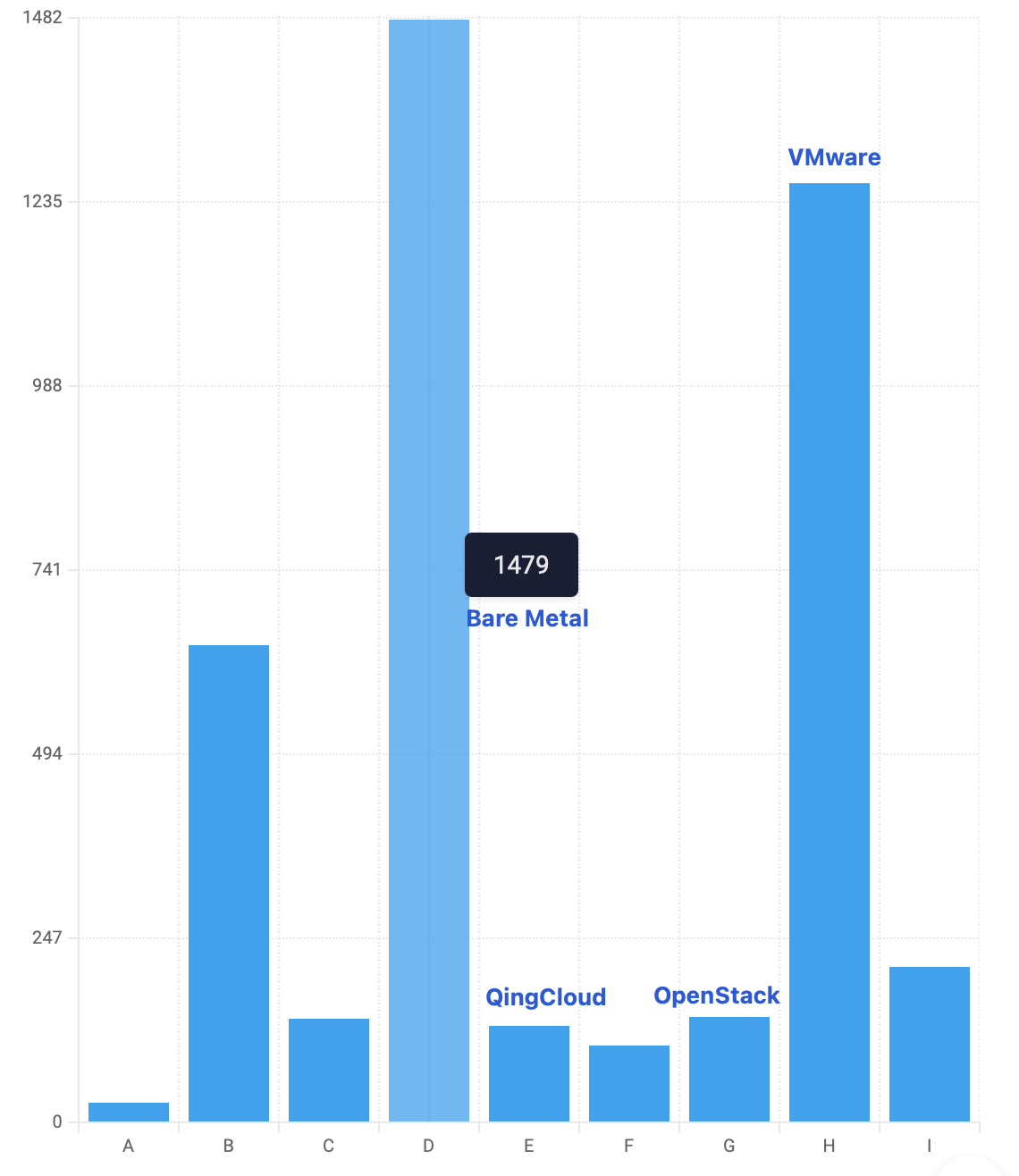
|
||||
|
||||
In Kubernetes clusters, LoadBalancer services can be used to expose backend workloads to outside the cluster. Cloud vendors usually provide cloud-based LB plugins, which requires users to deploy their clusters on specific IaaS platforms. However, most enterprise users deploy Kubernetes clusters on bare metal servers, especially when these clusters are used in production. For private environments with bare metal servers and edge clusters, Kubernetes does not provide a LoadBalancer solution.
|
||||
|
||||
OpenELB is designed to expose LoadBalancer services in non-public-cloud Kubernetes clusters. It provides easy-to-use EIPs and makes IP address pool management easier for users in private environments.
|
||||
## OpenELB Adopters and Contributors
|
||||
Currently, OpenELB has been used in production environments by many enterprises, such as BENLAI, Suzhou TV, CVTE, Wisdom World, Jollychic, QingCloud, BAIWANG, Rocketbyte, and more. At the end of 2019, BENLAI has used an earlier version of OpenELB in production. Now, OpenELB has attracted 13 contributors and more than 100 community members.
|
||||

|
||||
|
||||
## Differences Between OpenELB and MetalLB
|
||||
MetalLB is also a CNCF Sandbox project. It was launched at the end of 2017, and has been widely accepted by the community up to now. As a relatively young project, OpenELB is more Kubernetes-native. Thanks to contributions from the community, OpenELB has released eight versions and supported multiple routing methods. The following describes differences between OpenELB and MetalLB.
|
||||
### Cloud-native architecture
|
||||
In OpenELB, you can use CRDs to manage IP addresses and BGP settings. OpenELB is user-friendly for those who are familiar with kubectl. You can also directly use Kubernetes APIs to further customize OpenELB. In MetalLB, you can only manage IP addresses and BGP settings by using configmaps and obtain their status from logs.
|
||||
### Flexible IP address management
|
||||
|
||||
OpenELB manages IP addresses by using the Eip CRD. It defines the status sub-resource to store the assignment status of IP addresses, which prevents conflicts among replicas and simplifies the programming logic.
|
||||
|
||||
### Advertise routes using GoBGP
|
||||
|
||||
MetalLB implements BGP by itself, while OpenELB implements BGP by using GoBGP, which has the following advantages:
|
||||
|
||||
- Low development cost and robust support from the GoBGP community
|
||||
- Rich features of GoBGP
|
||||
- Dynamic configuration of GoBGP by using the BgpConf and BgpPeer CRDs, and the latest configurations are automatically loaded without OpenELB restart
|
||||
- When GoBGP is used as a library, the community provides Protocol Buffers (Protobuf) APIs. OpenELB references these APIs when implementing the BgpConf and BgpPeer CRD and remains compatible with GoBGP
|
||||
- OpenELB also provides status to view configurations of the BGP neighbor, which provides rich status information
|
||||
|
||||
### Simple architecture and less resources occupied
|
||||
|
||||
You can create an OpenELB deployment of multiple pod replicas to ensure high availability. Established connections still work well even though some replicas crash.
|
||||
|
||||
In BGP mode, all replicas advertise equal-cost routes to the router and usually two replicas are sufficient. In Layer 2 mode, a leader is elected among the replicas by using the leader election mechanism of Kubernetes to respond to ARP/NDP requests.
|
||||
|
||||
## Installation and Use of OpenELB
|
||||
|
||||
You can deploy OpenELB on any standard Kubernetes and K3s verions and their distributions by using a YAML file or Helm chart. Alternatively, you can deploy it from the App Store or an app repository on the KubeSphere web console. For more information, see [OpenELB Documentation](https://openelb.github.io/docs/getting-started/installation/).
|
||||
|
||||
## Future Plan
|
||||
|
||||
Backed by CNCF, OpenELB will maintain its commitment as an open-source project driven completely by the community. The following features are planned and you are always welcome to contribute and send feedbacks.
|
||||
|
||||
- VIP mode that supports Kubernetes high availability based on Keepalived
|
||||
- Load balancing for kube-apiserver
|
||||
- BGP policy configuration
|
||||
- VIP Group
|
||||
- Support for IPv6
|
||||
- GUI for EIP and IP pool management
|
||||
- Integration to the KubeSphere web console and support for Prometheus metrics
|
||||
|
||||
To make service exposure and IP address management in private environments easier, we will continuously launch a variety of community activities to attract more developers and users.
|
||||
|
||||
## Commitment to Open Source
|
||||
|
||||
The KubeSphere team has always been upholding the "Upstream first" principle. In July, 2021, the KubeSphere team donated Fluentbit Operator as a CNCF sub-project to the Fluent community. Now OpenELB, which was initiated by the KubeSphere team, also joins the CNCF sandbox. In the future, the KubeSphere team will serve as one of participants of the OpenELB project and maintain its commitment to open source. We will continue to work closely with all partners in the containerization field to build a vendor-neutral and open-source OpenELB community and ecosystem. Join the OpenELB community, tell us your experience when using OpenELB, and contribute to the OpenELB project!
|
||||
|
||||
- ✨ GitHub: [https://github.com/kubesphere/openelb/](https://github.com/kubesphere/openelb/)
|
||||
- 💻 Official website: [https://openelb.github.io/](https://openelb.github.io/)
|
||||
- 🙋 Slack channel: kubesphere.slack.com
|
||||
|
||||
|
|
@ -0,0 +1,428 @@
|
|||
---
|
||||
title: 'Serverless Use Case: Elastic Kubernetes Log Alerts with OpenFunction and Kafka'
|
||||
tag: 'OpenFunction, KubeSphere, Kubernetes'
|
||||
keywords: 'OpenFunction, Serverless, KubeSphere, Kubernetes, Kafka, FaaS'
|
||||
description: 'This blog post offers ideas for serverless log processing, which reduces the link cost while improving flexibility.'
|
||||
createTime: '2021-08-26'
|
||||
author: 'Fang Tian, Bettygogo'
|
||||
snapshot: '/images/blogs/en/Serverless-way-for-Kubernetes-Log-Alerting/kubesphere snapshot.png'
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
How do you handle container logs collected by the message server? You may face a dilemma: Deploying a dedicated log processing workload can be costly, and it is difficult to assess the number of standby log processing workloads required when the quantity of logs fluctuates sharply. This blog post offers ideas for serverless log processing, which reduces the link cost while improving flexibility.
|
||||
|
||||
Our general design idea is to add a Kafka server as a log receiver, and then use the log input to the Kafka server as an event to drive the serverless workloads to handle logs. Roughly, the following steps are involved:
|
||||
|
||||
1. Set up a Kafka server as the log receiver for Kubernetes clusters.
|
||||
2. Deploy OpenFunction to provide serverless capabilities for log processing workloads.
|
||||
3. Write log processing functions to grab specific logs to generate alerting messages.
|
||||
4. Configure [Notification Manager](https://github.com/kubesphere/notification-manager/) to send alerts to Slack.
|
||||
|
||||
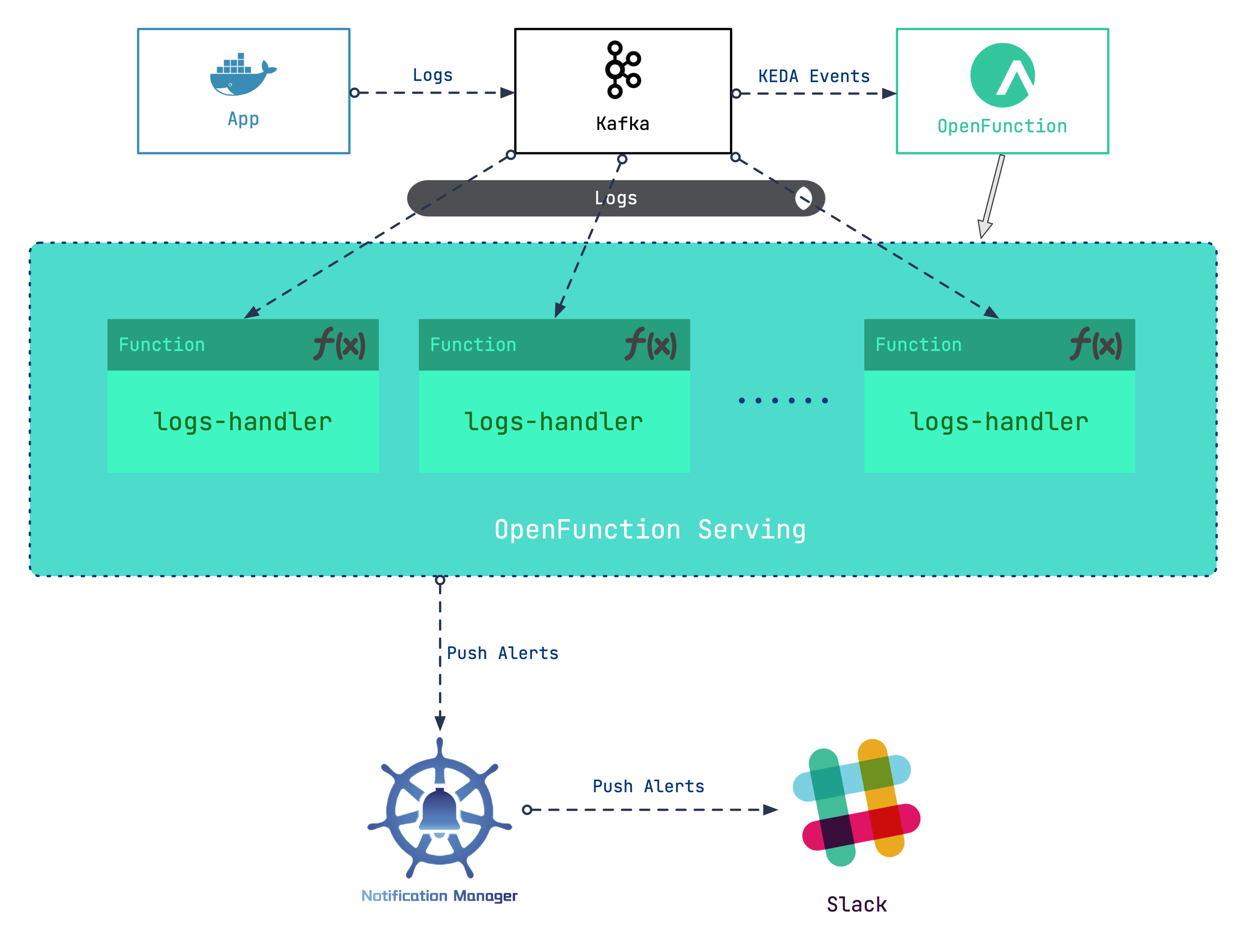
|
||||
|
||||
In this scenario, we will make use of the serverless capabilities of[ OpenFunction](https://github.com/OpenFunction/OpenFunction).
|
||||
|
||||
> [OpenFunction](https://github.com/OpenFunction/OpenFunction) is an open-source FaaS (serverless) project initiated by the KubeSphere community. It is designed to allow users to focus on their business logic without the hassle of caring about the underlying operating environment and infrastructure. Currently, the project provides the following key capabilities:
|
||||
>
|
||||
> - Builds OCI images from Dockerfile or Buildpacks.
|
||||
> - Runs serverless workloads using Knative Serving or OpenFunctionAsync (backed by KEDA + Dapr) as a runtime.
|
||||
> - Equipped with a built-in event-driven framework.
|
||||
|
||||
## Use Kafka as a Log Receiver
|
||||
|
||||
First, enable the **logging** component for the KubeSphere platform (For more information, please refer to[ Enable Pluggable Components](https://kubesphere.io/docs/pluggable-components/). Next, we can use [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) to build a minimal Kafka server.
|
||||
|
||||
1. In the `default` namespace, install [strimzi-kafka-operator.](https://github.com/strimzi/strimzi-kafka-operator)
|
||||
|
||||
```shell
|
||||
helm repo add strimzi https://strimzi.io/charts/
|
||||
helm install kafka-operator -n default strimzi/strimzi-kafka-operator
|
||||
```
|
||||
|
||||
2. Run the following commands to create a Kafka cluster and a Kafka topic in the `default` namespace. The storage type of the created Kafka and ZooKeeper clusters is **ephemeral**. Here, we use `emptyDir` for demonstration.
|
||||
|
||||
> Note that we have created a topic named `logs` for follow-up use.
|
||||
|
||||
```shell
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: kafka.strimzi.io/v1beta2
|
||||
kind: Kafka
|
||||
metadata:
|
||||
name: kafka-logs-receiver
|
||||
namespace: default
|
||||
spec:
|
||||
kafka:
|
||||
version: 2.8.0
|
||||
replicas: 1
|
||||
listeners:
|
||||
- name: plain
|
||||
port: 9092
|
||||
type: internal
|
||||
tls: false
|
||||
- name: tls
|
||||
port: 9093
|
||||
type: internal
|
||||
tls: true
|
||||
config:
|
||||
offsets.topic.replication.factor: 1
|
||||
transaction.state.log.replication.factor: 1
|
||||
transaction.state.log.min.isr: 1
|
||||
log.message.format.version: '2.8'
|
||||
inter.broker.protocol.version: "2.8"
|
||||
storage:
|
||||
type: ephemeral
|
||||
zookeeper:
|
||||
replicas: 1
|
||||
storage:
|
||||
type: ephemeral
|
||||
entityOperator:
|
||||
topicOperator: {}
|
||||
userOperator: {}
|
||||
---
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: KafkaTopic
|
||||
metadata:
|
||||
name: logs
|
||||
namespace: default
|
||||
labels:
|
||||
strimzi.io/cluster: kafka-logs-receiver
|
||||
spec:
|
||||
partitions: 10
|
||||
replicas: 3
|
||||
config:
|
||||
retention.ms: 7200000
|
||||
segment.bytes: 1073741824
|
||||
EOF
|
||||
```
|
||||
|
||||
3. Run the following command to check the Pod's status and wait until Kafka and ZooKeeper runs and starts.
|
||||
|
||||
```shell
|
||||
$ kubectl get po
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
kafka-logs-receiver-entity-operator-568957ff84-nmtlw 3/3 Running 0 8m42s
|
||||
kafka-logs-receiver-kafka-0 1/1 Running 0 9m13s
|
||||
kafka-logs-receiver-zookeeper-0 1/1 Running 0 9m46s
|
||||
strimzi-cluster-operator-687fdd6f77-cwmgm 1/1 Running 0 11m
|
||||
```
|
||||
|
||||
Run the following command to view metadata of the Kafka cluster:
|
||||
|
||||
```shell
|
||||
# Starts a utility pod.
|
||||
$ kubectl run utils --image=arunvelsriram/utils -i --tty --rm
|
||||
# Checks metadata of the Kafka cluster.
|
||||
$ kafkacat -L -b kafka-logs-receiver-kafka-brokers:9092
|
||||
```
|
||||
|
||||
Add this Kafka server as a log receiver.
|
||||
|
||||
1. Log in to the web console of KubeSphere as **admin**. In the upper-left corner, choose **Platform** > ****Cluster Management****.
|
||||
|
||||
> If you have enabled the [multi-cluster feature](https://kubesphere.io/docs/multicluster-management/), you need to select a cluster.
|
||||
|
||||
2. On the ****Cluster Management**** page, click **Log Collections** under ****Cluster Settings****.
|
||||
|
||||
3. Click **Add Log Receiver,** and then click **Kafka**. Enter the service address and port number of Kafka, and then click ****OK****.
|
||||
|
||||

|
||||
|
||||
4. Run the following commands to verify that Kafka clusters can collect logs from Fluent Bit.
|
||||
|
||||
```shell
|
||||
# Starts a utility pod.
|
||||
$ kubectl run utils --image=arunvelsriram/utils -i --tty --rm
|
||||
# Checks logs in the `logs` topic
|
||||
$ kafkacat -C -b kafka-logs-receiver-kafka-0.kafka-logs-receiver-kafka-brokers.default.svc:9092 -t logs
|
||||
```
|
||||
|
||||
## Deploy OpenFunction
|
||||
|
||||
According to the design in Overview, we need to deploy OpenFunction first. As OpenFunction has referenced multiple third-party projects, such as Knative, Tekton, ShipWright, Dapr, and KEDA, it is cumbersome if you manually deploy it. It is recommended that you refer to [Prerequisites](https://github.com/OpenFunction/OpenFunction#prerequisites) to quickly deploy dependencies of OpenFunction.
|
||||
|
||||
> In the command, `--with-shipwright` means that Shipwright is deployed as the build driver for the function; `--with-openFuncAsync` means that OpenFuncAsync Runtime is deployed as the load driver for the function. When you have limited access to GitHub and Google, you can add the `--poor-network` parameter to download related components.
|
||||
|
||||
```shell
|
||||
sh hack/deploy.sh --with-shipwright --with-openFuncAsync --poor-network
|
||||
```
|
||||
|
||||
Deploy OpenFunction.
|
||||
|
||||
> We install the latest stable version here. Alternatively, you can use the development version. For more information, please refer to the[ Install OpenFunction](https://github.com/OpenFunction/OpenFunction#install) section.
|
||||
>
|
||||
> To make sure that Shipwright works properly, we provide a default build policy, and you can run the following commands to set the policy.
|
||||
>
|
||||
> ```shell
|
||||
> kubectl apply -f https://raw.githubusercontent.com/OpenFunction/OpenFunction/main/config/strategy/openfunction.yaml
|
||||
> ```
|
||||
|
||||
```shell
|
||||
kubectl apply -f https://github.com/OpenFunction/OpenFunction/releases/download/v0.3.0/bundle.yaml
|
||||
```
|
||||
|
||||
## Write a Log Processing Function
|
||||
|
||||
In this example, we install WordPress as the log producer. The application's workload resides in the `demo-project` namespace and the Pod's name is `wordpress-v1-f54f697c5-hdn2z`.
|
||||
|
||||
When a request returns **404**, the log content is as follows:
|
||||
|
||||
```json
|
||||
{"@timestamp":1629856477.226758,"log":"*.*.*.* - - [25/Aug/2021:01:54:36 +0000] \"GET /notfound HTTP/1.1\" 404 49923 \"-\" \"curl/7.58.0\"\n","time":"2021-08-25T01:54:37.226757612Z","kubernetes":{"pod_name":"wordpress-v1-f54f697c5-hdn2z","namespace_name":"demo-project","container_name":"container-nrdsp1","docker_id":"bb7b48e2883be0c05b22c04b1d1573729dd06223ae0b1676e33a4fac655958a5","container_image":"wordpress:4.8-apache"}}
|
||||
|
||||
```
|
||||
|
||||
Here are our needs: When a request returns **404**, the Notification Manager sends a notification to the receiver (Configure a Slack alert receiver according to [Configure Slack Notifications](https://kubesphere.io/docs/cluster-administration/platform-settings/notification-management/configure-slack/), and records the namespace, Pod name, request path, request method, and other information. Therefore, we write a simple function:
|
||||
|
||||
> You can learn how to use `openfunction-context` from [OpenFunction Context Spec,](https://github.com/OpenFunction/functions-framework/blob/main/docs/OpenFunction-context-specs.md) which is a tool library provided by OpenFunction for writing functions. You can learn more about OpenFunction functions from [OpenFunction Samples.](https://github.com/OpenFunction/samples)
|
||||
|
||||
```go
|
||||
package logshandler
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"log"
|
||||
"regexp"
|
||||
"time"
|
||||
|
||||
ofctx "github.com/OpenFunction/functions-framework-go/openfunction-context"
|
||||
alert "github.com/prometheus/alertmanager/template"
|
||||
)
|
||||
|
||||
const (
|
||||
HTTPCodeNotFound = "404"
|
||||
Namespace = "demo-project"
|
||||
PodName = "wordpress-v1-[A-Za-z0-9]{9}-[A-Za-z0-9]{5}"
|
||||
AlertName = "404 Request"
|
||||
Severity = "warning"
|
||||
)
|
||||
|
||||
// The ctx parameter of the LogHandler function provides a context handle for user functions in the cluster. For example, ctx.SendTo is used to send data to a specified destination.
|
||||
// The in parameter in the LogsHandle function is used to pass byte data (if any) from the input to the function.
|
||||
func LogsHandler(ctx *ofctx.OpenFunctionContext, in []byte) int {
|
||||
content := string(in)
|
||||
// We set three regular expressions here for matching the HTTP status code, resource namespace, and Pod name of resources, respectively.
|
||||
matchHTTPCode, _ := regexp.MatchString(fmt.Sprintf(" %s ", HTTPCodeNotFound), content)
|
||||
matchNamespace, _ := regexp.MatchString(fmt.Sprintf("namespace_name\":\"%s", Namespace), content)
|
||||
matchPodName := regexp.MustCompile(fmt.Sprintf(`(%s)`, PodName)).FindStringSubmatch(content)
|
||||
|
||||
if matchHTTPCode && matchNamespace && matchPodName != nil {
|
||||
log.Printf("Match log - Content: %s", content)
|
||||
|
||||
// If the input data matches all three regular expressions above, we need to extract some log information to be used in the alert.
|
||||
// The alert contains the following information: HTTP method of the 404 request, HTTP path, and Pod name.
|
||||
match := regexp.MustCompile(`([A-Z]+) (/\S*) HTTP`).FindStringSubmatch(content)
|
||||
if match == nil {
|
||||
return 500
|
||||
}
|
||||
path := match[len(match)-1]
|
||||
method := match[len(match)-2]
|
||||
podName := matchPodName[len(matchPodName)-1]
|
||||
|
||||
// After we collect major information, we can use the data struct of altermanager to compose an alert.
|
||||
notify := &alert.Data{
|
||||
Receiver: "notification_manager",
|
||||
Status: "firing",
|
||||
Alerts: alert.Alerts{},
|
||||
GroupLabels: alert.KV{"alertname": AlertName, "namespace": Namespace},
|
||||
CommonLabels: alert.KV{"alertname": AlertName, "namespace": Namespace, "severity": Severity},
|
||||
CommonAnnotations: alert.KV{},
|
||||
ExternalURL: "",
|
||||
}
|
||||
alt := alert.Alert{
|
||||
Status: "firing",
|
||||
Labels: alert.KV{
|
||||
"alertname": AlertName,
|
||||
"namespace": Namespace,
|
||||
"severity": Severity,
|
||||
"pod": podName,
|
||||
"path": path,
|
||||
"method": method,
|
||||
},
|
||||
Annotations: alert.KV{},
|
||||
StartsAt: time.Now(),
|
||||
EndsAt: time.Time{},
|
||||
GeneratorURL: "",
|
||||
Fingerprint: "",
|
||||
}
|
||||
notify.Alerts = append(notify.Alerts, alt)
|
||||
notifyBytes, _ := json.Marshal(notify)
|
||||
|
||||
// Use ctx.SendTo to send the content to the "notification-manager" output (you can find its definition in the following logs-handler-function.yaml function configuration file.
|
||||
if err := ctx.SendTo(notifyBytes, "notification-manager"); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
log.Printf("Send log to notification manager.")
|
||||
}
|
||||
return 200
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Upload this function to the code repository and record the ****URL of the code repository**** and the **path of the code in the repository**, which will be used in the **Create a function** step.
|
||||
|
||||
> You can find this case in [OpenFunction Samples](https://github.com/OpenFunction/samples/tree/main/functions/OpenFuncAsync/logs-handler-function).
|
||||
|
||||
## Create a Function
|
||||
|
||||
Use OpenFunction to build the above function. First, set up a key file `push-secret` to access the image repository (After the OCI image is constructed using the code, OpenFunction will upload the image to the image repository for subsequent load startup.):
|
||||
|
||||
```shell
|
||||
REGISTRY_SERVER=https://index.docker.io/v1/ REGISTRY_USER=<your username> REGISTRY_PASSWORD=<your password>
|
||||
kubectl create secret docker-registry push-secret \
|
||||
--docker-server=$REGISTRY_SERVER \
|
||||
--docker-username=$REGISTRY_USER \
|
||||
--docker-password=$REGISTRY_PASSWORD
|
||||
```
|
||||
|
||||
Apply the function configuration file `logs-handler-function.yaml`.
|
||||
|
||||
> The function definition explains the use of two key components:
|
||||
>
|
||||
> [Dapr](https://dapr.io/) shields complex middleware from applications, making it easy for the `logs-handler` function to handle Kafka events.
|
||||
>
|
||||
> [KEDA](https://keda.sh/) drives the startup of the `logs-handler` function by monitoring event traffic in the message server, and dynamically extends the `logs-handler` instance based on the consumption delay of Kafka messages.
|
||||
|
||||
```yaml
|
||||
apiVersion: core.openfunction.io/v1alpha1
|
||||
kind: Function
|
||||
metadata:
|
||||
name: logs-handler
|
||||
spec:
|
||||
version: "v1.0.0"
|
||||
# Defines the upload path for the built image.
|
||||
image: openfunctiondev/logs-async-handler:v1
|
||||
imageCredentials:
|
||||
name: push-secret
|
||||
build:
|
||||
builder: openfunctiondev/go115-builder:v0.2.0
|
||||
env:
|
||||
FUNC_NAME: "LogsHandler"
|
||||
# Defines the path of the source code.
|
||||
# url specifies the URL of the above-mentioned code repository.
|
||||
# sourceSubPath specifies the path of the code in the repository.
|
||||
srcRepo:
|
||||
url: "https://github.com/OpenFunction/samples.git"
|
||||
sourceSubPath: "functions/OpenFuncAsync/logs-handler-function/"
|
||||
serving:
|
||||
# OpenFuncAsync is an event-driven, asynchronous runtime implemented in OpenFunction by using KEDA_Dapr.
|
||||
runtime: "OpenFuncAsync"
|
||||
openFuncAsync:
|
||||
# This section defines the function input (kafka-receiver) and the output (notification-manager), which correspond to definitions in the components section.
|
||||
dapr:
|
||||
inputs:
|
||||
- name: kafka-receiver
|
||||
type: bindings
|
||||
outputs:
|
||||
- name: notification-manager
|
||||
type: bindings
|
||||
params:
|
||||
operation: "post"
|
||||
type: "bindings"
|
||||
annotations:
|
||||
dapr.io/log-level: "debug"
|
||||
# This section defines the above-mentioned input and output (that is, Dapr Components).
|
||||
components:
|
||||
- name: kafka-receiver
|
||||
type: bindings.kafka
|
||||
version: v1
|
||||
metadata:
|
||||
- name: brokers
|
||||
value: "kafka-logs-receiver-kafka-brokers:9092"
|
||||
- name: authRequired
|
||||
value: "false"
|
||||
- name: publishTopic
|
||||
value: "logs"
|
||||
- name: topics
|
||||
value: "logs"
|
||||
- name: consumerGroup
|
||||
value: "logs-handler"
|
||||
# This is the URL of KubeSphere notification-manager.
|
||||
- name: notification-manager
|
||||
type: bindings.http
|
||||
version: v1
|
||||
metadata:
|
||||
- name: url
|
||||
value: http://notification-manager-svc.kubesphere-monitoring-system.svc.cluster.local:19093/api/v2/alerts
|
||||
keda:
|
||||
scaledObject:
|
||||
pollingInterval: 15
|
||||
minReplicaCount: 0
|
||||
maxReplicaCount: 10
|
||||
cooldownPeriod: 30
|
||||
# This section defines the trigger of the function, that is, the log topic of the Kafka server.
|
||||
# This section also defines the message lag threshold (the value is 10), which means that when the number of lagged messages exceeds 10, the number of logs-handler instances will automatically scale out.
|
||||
triggers:
|
||||
- type: kafka
|
||||
metadata:
|
||||
topic: logs
|
||||
bootstrapServers: kafka-logs-receiver-kafka-brokers.default.svc.cluster.local:9092
|
||||
consumerGroup: logs-handler
|
||||
lagThreshold: "10"
|
||||
```
|
||||
|
||||
## Demonstrate the Result
|
||||
|
||||
Disable the Kafka log receiver first: On the ****Log Collections**** page, click **Kafka** to go to the details page, and choose **More** > **Change Status** > **Close**.
|
||||
|
||||
Wait for a while, and then it can be observed that number of instances of the `logs-handler` function has reduced to 0.
|
||||
|
||||
Then set the status of the Kafka log receiver to **Collecting**, and `logs-handler` also starts.
|
||||
|
||||
```shell
|
||||
~# kubectl get po --watch
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
kafka-logs-receiver-entity-operator-568957ff84-tdrrx 3/3 Running 0 7m27s
|
||||
kafka-logs-receiver-kafka-0 1/1 Running 0 7m48s
|
||||
kafka-logs-receiver-zookeeper-0 1/1 Running 0 8m12s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-b9d6f 2/2 Terminating 0 34s
|
||||
strimzi-cluster-operator-687fdd6f77-kc8cv 1/1 Running 0 10m
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-b9d6f 2/2 Terminating 0 36s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-b9d6f 0/2 Terminating 0 37s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-b9d6f 0/2 Terminating 0 38s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-b9d6f 0/2 Terminating 0 38s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 0/2 Pending 0 0s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 0/2 Pending 0 0s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 0/2 ContainerCreating 0 0s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 0/2 ContainerCreating 0 2s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 1/2 Running 0 4s
|
||||
logs-handler-serving-kpngc-v100-zcj4q-5f46996f8c-9kj2c 2/2 Running 0 11s
|
||||
```
|
||||
|
||||
Next, initialize a request for a non-existent path of the WordPress application:
|
||||
|
||||
```shell
|
||||
curl http://<wp-svc-address>/notfound
|
||||
```
|
||||
|
||||
You can see that Slack has received this message (Slack will not receive an alert message when we visit the WordPress site properly).
|
||||
|
||||

|
||||
|
||||
### Explore More Possibilities
|
||||
|
||||
We can further discuss a solution using synchronous functions:
|
||||
|
||||
To use Knative Serving properly, we need to set the load balancer address of its gateway. (You can use the local address as a workaround.)
|
||||
|
||||
```bash
|
||||
# Repalce the following "1.2.3.4" with the actual values.
|
||||
$ kubectl patch svc -n kourier-system kourier \
|
||||
-p '{"spec": {"type": "LoadBalancer", "externalIPs": ["1.2.3.4"]}}'
|
||||
|
||||
$ kubectl patch configmap/config-domain -n knative-serving \
|
||||
-type merge --patch '{"data":{"1.2.3.4.sslip.io":""}}'
|
||||
```
|
||||
|
||||
OpenFunction drives the running of the `Knative` function in two ways: (1) Use the Kafka server in asynchronous mode; (2) Use its own event framework to connect to the Kafka server, and then operate in Sink mode. You can refer to the case in [OpenFunction Samples](https://github.com/OpenFunction/samples/tree/main/functions/Knative/logs-handler-function).
|
||||
|
||||
In this solution, the processing speed of synchronous functions is lower than that of asynchronous functions. We can also use KEDA to trigger the concurrency mechanism of Knative Serving, but it is not as convenient as asynchronous functions. (In the future, we will optimize the OpenFunction event framework to make up for the shortcomings of synchronous functions.)
|
||||
|
||||
It can be seen that different types of serverless functions have their unique advantages depending on task scenarios. For example, when it comes to handling an orderly control flow function, a synchronous function outperforms an asynchronous function.
|
||||
|
||||
## Summary
|
||||
|
||||
Serverless matches our expectations for rapid disassembly and reconstruction of business scenarios.
|
||||
|
||||
As you can see in this case, OpenFunction not only increases flexibility of log processing and alert notification links by using the serverless technology, but also uses a function framework to simplify complex setups typically required to connect to Kafka into semantically clear code. Moreover, we are also continuously developing OpenFunction so that components can be powered by our own serverless capabilities in follow-up releases.
|
||||
|
|
@ -279,7 +279,7 @@ Before you start to create your Kubernetes cluster, make sure you have tested th
|
|||
3. Create a configuration file to specify cluster information. The Kubernetes version I am going to install is `v1.17.9`.
|
||||
|
||||
```bash
|
||||
./kk create config --with-kubernetes v1.17.9
|
||||
./kk create config --with-kubernetes v1.20.4
|
||||
```
|
||||
|
||||
4. A default file `config-sample.yaml` will be created. Edit the file and here is my configuration for your reference:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,227 @@
|
|||
---
|
||||
title: 'Transform Traditional Applications to Microservices into Enable the Traffic Monitoring Feature'
|
||||
tag: 'KubeSphere, Kubernetes, Microservices'
|
||||
keywords: 'KubeSphere, Kubernetes, Microservices, Traffic Monitoring, Service Mesh'
|
||||
description: 'This article describes how to transform a traditional application into microservices to use service mesh features, such as grayscale release, traffic monitoring, and tracing.'
|
||||
createTime: '2021-12-21'
|
||||
author: 'Zackzhang, Bettygogo'
|
||||
snapshot: '/images/blogs/transform-traditional-applications-into-microservices/traffic-monitoring-cover.png'
|
||||
---
|
||||
|
||||
## Challenges
|
||||
|
||||
When trying to use service mesh of Kubernetes, most of KubeSphere users only manage to deploy a Bookinfo sample on KubeSphere. They are also struggling in understanding how to explore the full capabilities of service mesh, let alone transform traditional applications into microservices.
|
||||
|
||||
This article describes how to transform a traditional application into microservices to use service mesh features, such as grayscale release, traffic monitoring, and tracing.
|
||||
|
||||
## KubeSphere Microservices
|
||||
|
||||
KubeSphere microservices use the application CRD to abstract associated resources into a concrete application, and provide traffic monitoring, grayscale release, and tracing features with the help of Istio's application features. Moreover, KubeSphere microservices shield complex DestinationRule and VirtualService of Istio and automatically update resources according to traffic monitoring settings and grayscale release policies.
|
||||
|
||||
Prerequisites for using KubeSphere microservices are as follows:
|
||||
|
||||
1. A deployment must contain labels `app` and `version`, and a service must contain the `app` label. The app labels (equivalent to a service name) of the deployment and the service must be the same (required by Istio).
|
||||
|
||||
2. All resources of an application must contain labels app.kubernetes.io/name=<applicationName> and app.kubernetes.io/version=<Version> (required by the application).
|
||||
|
||||
3. A deployment name must consist of a service name followed by v1. For example, when the service name is nginx, the deployment name is nginx-v1.
|
||||
|
||||
4. The deployment template must contain annotations (required during automatic sidecar injection of Istio).
|
||||
|
||||
```bash
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "true"
|
||||
```
|
||||
|
||||
5. The service and deployment contain annotations. The KubeSphere CRD Controller automatically matches VirtualService and DestinationRules to the service.
|
||||
|
||||
```bash
|
||||
# Service
|
||||
kind: Service
|
||||
metadata:
|
||||
annotations:
|
||||
servicemesh.kubesphere.io/enabled: "true"
|
||||
|
||||
# Deployment
|
||||
kind: Deployment
|
||||
metadata:
|
||||
annotations:
|
||||
servicemesh.kubesphere.io/enabled: "true"
|
||||
```
|
||||
|
||||
## Example
|
||||
|
||||
To implement traffic monitoring, two independent applications are required (for example, WordPress and MySQL). After the two applications work properly, we then transform them into KubeSphere microservices and inject the sidecar.
|
||||
|
||||
Open the [MySQL Docker Hub](https://hub.docker.com/_/mysql "mysql dockerhub") page, and you can see explanation of the `MYSQL_ROOT_PASSWORD` variable. On the KubeSphere web console, set the default MySQL password.
|
||||
|
||||
Open the [WordPress Docker Hub](https://hub.docker.com/_/wordpress "wordpress dockerhub") page, and you can see three database variables `WORDPRESS_DB_PASSWORD` `WORDPRESS_DB_USER` `WORDPRESS_DB_HOST`. On the KubeSphere web console, set values of the three variables to connect Wordpress to MySQL.
|
||||
|
||||
## Create a Traditional Application
|
||||
|
||||
First, create a workspace and a project with the gateway and tracing features enabled.
|
||||
|
||||

|
||||
|
||||
Select **Application Workloads** > **Service**. On the **Service** page, click **Create**. On the **Create Service** page, click **Stateful Service** to create a MySQL service.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
In **Environment Variables**, set the default password.
|
||||
|
||||

|
||||
|
||||
Likewise, create a stateless WordPress service.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
The following variables are for demonstration only. In production, select **Use ConfigMap or Secret**.
|
||||
|
||||

|
||||
|
||||
Select **Edit External Access**, and then change the access mode to **NodePort**.
|
||||
|
||||

|
||||
|
||||
After the pods run properly, access the service page at `<Service IP address>:<Node port>`. It can be seen that the application runs properly.
|
||||
|
||||
|
||||
|
||||
Check the pods. It is found that the sidecar is not enabled, and each pod contains only one container.
|
||||
|
||||

|
||||
|
||||
The traffic topology is not displayed because service mesh is not enabled. The following describes how to enable service mesh.
|
||||
|
||||
## Deploy an Application
|
||||
|
||||
1. Apply the following YAML file to deploy an application.
|
||||
|
||||
```bash
|
||||
# wordpress.yaml
|
||||
apiVersion: app.k8s.io/v1beta1
|
||||
kind: Application
|
||||
metadata:
|
||||
annotations:
|
||||
kubesphere.io/creator: admin
|
||||
servicemesh.kubesphere.io/enabled: "true"
|
||||
labels:
|
||||
app.kubernetes.io/name: wordpress-app
|
||||
app.kubernetes.io/version: v1
|
||||
name: wordpress-app # The name of the application must be the same as that defined in label app.kubernetes.io/name.
|
||||
spec:
|
||||
addOwnerRef: true
|
||||
componentKinds:
|
||||
- group: ""
|
||||
kind: Service
|
||||
- group: apps
|
||||
kind: Deployment
|
||||
- group: apps
|
||||
kind: StatefulSet
|
||||
- group: extensions
|
||||
kind: Ingress
|
||||
- group: servicemesh.kubesphere.io
|
||||
kind: Strategy
|
||||
- group: servicemesh.kubesphere.io
|
||||
kind: ServicePolicy
|
||||
selector:
|
||||
matchLabels:
|
||||
# Tag resources with the following two labels to specify their relationships.
|
||||
app.kubernetes.io/name: wordpress-app
|
||||
app.kubernetes.io/version: v1
|
||||
```
|
||||
|
||||

|
||||
|
||||
The application state is 0/0, which indicates that no applications are associated.
|
||||
|
||||
> If the application state is not displayed and running the `kubectl get app` command does not work, it indicates that the CRD of your application is legacy. Run the following command to update the CRD:
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://raw.githubusercontent.com/kubesphere/ks-installer/master/roles/common/files/ks-crds/app.k8s.io_applications.yaml
|
||||
```
|
||||
|
||||
2. Add labels for the target application to declare services that belong to the application.
|
||||
|
||||
```bash
|
||||
kubectl -n sample label deploy/wordpress-v1 app.kubernetes.io/name=wordpress-app app.kubernetes.io/version=v1
|
||||
kubectl -n sample label svc/wordpress app.kubernetes.io/name=wordpress-app app.kubernetes.io/version=v1
|
||||
|
||||
kubectl -n sample label sts/mysql-v1 app.kubernetes.io/name=wordpress-app app.kubernetes.io/version=v1
|
||||
kubectl -n sample label svc/wordpress app.kubernetes.io/name=wordpress-app app.kubernetes.io/version=v1
|
||||
```
|
||||
|
||||
Then, check the application, and you can find that the number of services associated with the application is no longer 0.
|
||||
|
||||

|
||||
|
||||
3. Add annotations to the target deployment and service.
|
||||
|
||||
```bash
|
||||
kubectl -n sample annotate svc/wordpress servicemesh.kubesphere.io/enabled="true"
|
||||
kubectl -n sample annotate deploy/wordpress-v1 servicemesh.kubesphere.io/enabled="true"
|
||||
kubectl -n sample annotate svc/mysql servicemesh.kubesphere.io/enabled="true"
|
||||
kubectl -n sample annotate sts/mysql-v1 servicemesh.kubesphere.io/enabled="true"
|
||||
```
|
||||
|
||||
4. Add annotations to the deploy and sts templates to enable the sidecar.
|
||||
|
||||
```bash
|
||||
kubectl -n sample edit deploy/wordpress-v1
|
||||
...
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "true" # Add the row.
|
||||
|
||||
kubectl -n sample edit sts/mysql-v1
|
||||
...
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "true" # Add the row.
|
||||
```
|
||||
|
||||
> Note: You can inject the sidebar by simply adding annotations to the template.
|
||||
|
||||
Check whether the sidecar has been injected.
|
||||
|
||||

|
||||
|
||||
5. Istio-relevant labels and naming rules must meet the requirements. If you create the service on KubeSphere, you don't need to modify the labels and naming rules.
|
||||
|
||||
For labels relevant to the app version, if you create the service on KubeSphere, labels in the following red boxes are added by default.
|
||||
|
||||

|
||||
|
||||
## Check the Transformation Result
|
||||
|
||||
After the transformation is completed, check the application page.
|
||||
|
||||

|
||||
|
||||
Expose the WordPress service.
|
||||
|
||||

|
||||
|
||||
Access the service, and it can be found that the application works properly.
|
||||
|
||||
|
||||
|
||||
It can be found that the traffic has been visualized, and the data shows that the traffic flows properly.
|
||||
|
||||

|
||||
|
||||
Also, the grayscale release and tracing features function well.
|
||||
|
||||
Note that you need to enable the route feature before using the tracing feature.
|
||||
|
||||
## Summary
|
||||
|
||||
We can successfully transform the application into microservices by performing the previous steps. As the transformation process is tedious, the KubeSphere team will continuously optimize this feature to make transformation easier.
|
||||
|
|
@ -90,11 +90,11 @@ As stated above, requests and limits are two important building blocks for clust
|
|||
|
||||
### Before You Begin
|
||||
|
||||
KubeSphere features a highly functional multi-tenant system for fine-grained access control of different users. In KubeSphere 3.0, you can set requests and limits for namespaces (ResourceQuotas) and containers (LimitRanges) respectively. To perform these operations, you need to create a workspace, a project (i.e. namespace) and an account (`ws-admin`). For more information, see [Create Workspaces, Projects, Accounts and Roles](https://kubesphere.io/docs/quick-start/create-workspace-and-project/).
|
||||
KubeSphere features a highly functional multi-tenant system for fine-grained access control of different users. In KubeSphere 3.0, you can set requests and limits for namespaces (ResourceQuotas) and containers (LimitRanges) respectively. To perform these operations, you need to create a workspace, a project (i.e. namespace) and a user (`ws-admin`). For more information, see [Create Workspaces, Projects, Users and Roles](https://kubesphere.io/docs/quick-start/create-workspace-and-project/).
|
||||
|
||||
### Set Resource Quotas
|
||||
|
||||
1. Go to the **Overview** page of your project, navigate to **Basic Information** in **Project Settings**, and select **Edit Quota** from the **Manage Project** drop-down menu.
|
||||
1. Go to the **Overview** page of your project, navigate to **Basic Information** in **Project Settings**, and select **Edit Quotas** from the **Manage Project** drop-down menu.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,287 @@
|
|||
---
|
||||
title: 'Monitoring X.509 Certificates Expiration in Kubernetes Clusters with a Prometheus Exporter'
|
||||
keywords: x509-certificate-exporter, Prometheus, Kubernetes, Helm, KubeSphere, Certificate Monitoring
|
||||
description: This article details how to deploy x509-certificate-exporter in Kubernetes and monitor component certificates of a Kubernetes cluster using a custom alerting policy on KubeSphere.
|
||||
createTime: '2021-11-01'
|
||||
author: 'Yang Chuansheng, Bettygogo'
|
||||
snapshot: '/images/blogs/en/x509-certificate-exporter/x509-certificate-exporter-cover-image.png'
|
||||
---
|
||||
|
||||
KubeSphere offers a developer-friendly wizard that simplifies the operations & maintenance of Kubernetes, but it is essentially built on Kubernetes. Kubernetes' TLS certificates are valid for only one year, so we need to update the certificates every year, which is unavoidable even though the cluster is installed by the powerful and lightweight installation tool [KubeKey](https://github.com/kubesphere/kubekey). To prevent possible risks arising from certificate expiration, we need to find a way to monitor certificate validity of Kubernetes components.
|
||||
|
||||
Some of you may have heard of [ssl-exporter](https://github.com/ribbybibby/ssl_exporter), which exports metrics for SSL certificates collected from various sources, such as the HTTPS certificate, file certificate, Kubernetes Secret, and kubeconfig file. Basically, ssl-exporter can meet our needs, but it does not have a wealth of metrics. Here, I will share a more powerful Prometheus Exporter: [x509-certificate-exporter](https://github.com/enix/x509-certificate-exporter) with you.
|
||||
|
||||
Unlike ssl-exporter, x509-certificate-exporter only focuses on expiration monitoring of certificates of Kubernetes clusters, such as the file certificates of each component, Kubernetes TLS Secret, and kubeconfig file. Moreover, it provides more metrics. Next, I'll show you how to deploy x509-certificate-exporter on KubeSphere to monitor all certificates of the cluster.
|
||||
|
||||
## Prepare a KubeSphere App Template
|
||||
|
||||
With [OpenPitrix](https://github.com/openpitrix/openpitrix), a multicloud application management platform, [KubeSphere](https://kubesphere.io/) is capable of managing the full lifecycle of apps and allowing you to intuitively deploy and manage apps using the App Store and app templates. For an app that has not been published in the App Store, you can import its Helm chart to the public repository of KubeSphere, or import it to a private app repository to provide an app template.
|
||||
|
||||
Here, we use a KubeSphere app template to deploy x509-certificate-exporter.
|
||||
|
||||
To deploy an app using an app template, you need to create a workspace, a project, and two users (`ws-admin` and `project-regular`), and assign platform role `workspace-admin` in the workspace to `ws-admin`, and role `operator` in the project to `project-regular`. To begin with, let's review the multi-tenant architecture of KubeSphere.
|
||||
|
||||
### Multi-tenant Kubernetes Architecture
|
||||
|
||||
KubeSphere's multi-tenant system is divided into three levels: cluster, workspace, and project (equivalent to [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/) of Kubernetes).
|
||||
|
||||
As the system workspace runs system resources, most of which are viewable only, it is suggested that you create a new [workspace](https://kubesphere.com.cn/en/docs/workspace-administration/what-is-workspace/). For security reasons, we strongly recommend you granting different permissions to different tenants when they are collaborating in a workspace.
|
||||
|
||||
You can create multiple workspaces in a KubeSphere cluster. In each workspace, you can create multiple projects. By default, KubeSphere has several built-in roles for each level. Additionally, KubeSphere allows you to create roles with customized permissions. Overall speaking, KubeSphere's multi-tenant architecture is ideal for enterprises and organizations who are yearning for role-based management.
|
||||
|
||||
### Create a User
|
||||
|
||||
After you have installed KubeSphere, you need to create users with different roles so that they can work within the authorized scope. Initially, the system has a default user `admin`, which has been assigned role `platform-admin`. In the following, we will create a user named `user-manager`, which will be used to create new users.
|
||||
|
||||
1. Log in to the KubeSphere web console as user `admin` and the default password is `P@88w0rd`.
|
||||
|
||||
> For account security, it is highly recommended that you change your password the first time you log in to the console. To change your password, click **User Settings** in the drop-down list in the upper-right corner. In **Password Settings**, set a new password. You also can change the language of the console in **User Settings**.
|
||||
|
||||
2. Click **Platform** in the upper-left corner, and then click **Access Control**.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
In the left navigation pane, click **Platform Roles**, and you will find four available built-in roles. Assign role `users-manager` to the first user you create.
|
||||
|
||||
| Built-in Roles| Description|
|
||||
|----------|----------|
|
||||
| `workspaces-manager`| Workspace manager who can manage all workspaces on the KubeSphere platform.|
|
||||
| `users-manager`| User manager who can manage all users on the KubeSphere platform.|
|
||||
| `platform-regular`| Regular user who has no access to any resources before joining a workspace.|
|
||||
| `platform-admin`| Administrator who can manage all resources on the KubeSphere platform.|
|
||||
|
||||
|
||||
3. In **Users**, click **Create**. In the displayed dialog box, provide all the necessary information (marked with *) and select `users-manager` for **Platform Role**.
|
||||
|
||||

|
||||
|
||||
Click ****OK****. In **Users**, you can find the newly created user in the user list.
|
||||
|
||||
4. Log out of the console and log back as user `user-manager` to create another three users listed in the following table.
|
||||
|
||||
| User| Role| Description|
|
||||
|----------|----------|----------|
|
||||
| `ws-manager`| `workspaces-manager`| Creates and manages all workspaces.|
|
||||
| `ws-admin`| `platform-regular`| Manages all resources in a specified workspace (used to invite the `project-regular` user to the workspace).|
|
||||
| `project-regular`| `platform-regular`| Creates workloads, pipelines, and other resources in a specified project.|
|
||||
|
||||
|
||||
5. In **Users**, you can view the three users you just created.
|
||||
|
||||

|
||||
|
||||
### Create a Workspace
|
||||
|
||||
In this section, you need to use user `ws-manager` created in the previous step to create a workspace. As a basic logic unit for the management of projects, workload creation, and organization members, workspaces underpin the multi-tenant system of KubeSphere.
|
||||
|
||||
1. Log in to KubeSphere as `ws-manager`, who has the permission to manage all workspaces on the platform. Click **Platform** in the upper-left corner and select **Access Control**. In **Workspaces**, you can see there is only one default workspace `system-workspace`, where system-related components and services run. You are not allowed to delete this workspace.
|
||||
|
||||

|
||||
|
||||
2. Click **Create** on the right, set a name for the new workspace (for example, `demo-workspace`) and set user `ws-admin` as the workspace administrator.
|
||||
|
||||

|
||||
|
||||
Click **Create** after you finish.
|
||||
|
||||
3. Log out of the console, and log back in as `ws-admin`. In **Workspace Settings**, select **Workspace Members**, and then click **Invite**.
|
||||
|
||||

|
||||
|
||||
4. Invite `project-regular` to the workspace, assign it role `workspace-viewer`, and then click **OK**.
|
||||
|
||||
> The actual role name follows a naming convention: \<workspace name>-\<role name>. For example, in workspace `demo-workspace`, the actual role name of role `viewer` is `demo-workspace-viewer`.
|
||||
|
||||

|
||||
|
||||
5. After you add `project-regular` to the workspace, click ****OK****. In **Workspace Members**, you can see two members listed.
|
||||
|
||||
| User| Role| Description|
|
||||
|----------|----------|----------|
|
||||
| `ws-admin`| `workspace-admin`| Manages all resources under a workspace (Here, it is used to invite new members to the workspace and create a project).|
|
||||
| `project-regular`| `workspace-viewer`| Creates workloads and other resources in a specified project.|
|
||||
|
||||
|
||||
|
||||
### Create a Project
|
||||
|
||||
In this section, you need to use the previously created user `ws-admin` to create a project. A project in KubeSphere is the same as a namespace in Kubernetes, which provides virtual isolation for resources. For more information, see [Namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/).
|
||||
|
||||
1. Log in to the KubeSphere web console as `ws-admin`. In **Projects**, click **Create**.
|
||||
|
||||

|
||||
|
||||
2. Enter a project name (for example, `exporter`) and click **OK**. You can also add an alias and description for the project.
|
||||
|
||||

|
||||
|
||||
3. In **Projects**, click the project name to view its details.
|
||||
|
||||

|
||||
|
||||
4. In **Project Settings**, select **Project Members**, click **Invite** to invite `project-regular` to the project, and assign role `operator` to `project regular`.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> Users with role `operator` are project maintainers who can manage resources other than users and roles in the project.
|
||||
|
||||
### Add an App Repository
|
||||
|
||||
1. Log in to the web console of KubeSphere as user `ws-admin`. In your workspace, go to **App Repositories** under **App Management**, and then click **Add**.
|
||||
|
||||

|
||||
|
||||
2. In the displayed dialog box, specify an app repository name (for example, `enix`) and add your repository URL (for example, `https://charts.enix.io`). Click **Validate** to validate the URL, and then click **OK**.
|
||||
|
||||

|
||||
|
||||
3. In **App Repositories**, you can view the created app repository.
|
||||
|
||||

|
||||
|
||||
## Deploy x509-certificate-exporter
|
||||
|
||||
After importing the app repository of x509-certificate-exporter, you can use the app template to deploy x509-certificate-exporter.
|
||||
|
||||
1. Log out of the KubeSphere web console and log in to the console as user `project-regular`. Click the project you created to go to the project page. Go to **Apps** under **Application Workloads**, and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. In the displayed dialog box, select **From App Template**.
|
||||
|
||||

|
||||
|
||||
**From App Store**: Chooses a built-in app or app uploaded as Helm charts.
|
||||
|
||||
**From App Template**: Chooses an app from a private app repository or the current workspace.
|
||||
|
||||
4. In the drop-down list, select private app repository `enix` you just uploaded.
|
||||
|
||||

|
||||
|
||||
5. Select x509-certificate-exporter for deployment.
|
||||
|
||||

|
||||
|
||||
6. In the drop-down list of **Version**, select an app version, and then click **Deploy**. Meantime, you can view the app information and manifest.
|
||||
|
||||

|
||||
|
||||
7. Set an app name, confirm the app version and deployment location, and click **Next**.
|
||||
|
||||

|
||||
|
||||
8. In **App Settings**, you need to manually edit the manifest and specify the path to the certificate file.
|
||||
|
||||

|
||||
|
||||
```yaml
|
||||
daemonSets:
|
||||
master:
|
||||
nodeSelector:
|
||||
node-role.kubernetes.io/master: ''
|
||||
tolerations:
|
||||
- effect: NoSchedule
|
||||
key: node-role.kubernetes.io/master
|
||||
operator: Exists
|
||||
watchFiles:
|
||||
- /var/lib/kubelet/pki/kubelet-client-current.pem
|
||||
- /etc/kubernetes/pki/apiserver.crt
|
||||
- /etc/kubernetes/pki/apiserver-kubelet-client.crt
|
||||
- /etc/kubernetes/pki/ca.crt
|
||||
- /etc/kubernetes/pki/front-proxy-ca.crt
|
||||
- /etc/kubernetes/pki/front-proxy-client.crt
|
||||
watchKubeconfFiles:
|
||||
- /etc/kubernetes/admin.conf
|
||||
- /etc/kubernetes/controller-manager.conf
|
||||
- /etc/kubernetes/scheduler.conf
|
||||
nodes:
|
||||
tolerations:
|
||||
- effect: NoSchedule
|
||||
key: node-role.kubernetes.io/ingress
|
||||
operator: Exists
|
||||
watchFiles:
|
||||
- /var/lib/kubelet/pki/kubelet-client-current.pem
|
||||
- /etc/kubernetes/pki/ca.crt
|
||||
```
|
||||
|
||||
Two `DaemonSets` are created, where the master runs on the controller node and the nodes run on the compute node.
|
||||
|
||||
```bash
|
||||
$ kubectl -n exporter get ds
|
||||
|
||||
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
|
||||
x509-x509-certificate-exporter-master 1 1 1 1 1 node-role.kubernetes.io/master= 3d14h
|
||||
x509-x509-certificate-exporter-nodes 3 3 3 3 3 <none> 3d14h
|
||||
```
|
||||
|
||||
Here are how the parameters are defined:
|
||||
|
||||
+ **watchFiles:** Specifies the path to the certificate file.
|
||||
+ **watchKubeconfFiles:** Specifies the path to the kubeconfig file.
|
||||
|
||||

|
||||
|
||||
10. Click **Install** and wait until the app is created successfully and runs.
|
||||
|
||||

|
||||
|
||||
## Integrate the Monitoring System
|
||||
|
||||
After you deploy the app using the app template, a `ServiceMonitor` will also be created along with two DaemonSets.
|
||||
|
||||
```bash
|
||||
$ kubectl -n exporter get servicemonitor
|
||||
NAME AGE
|
||||
x509-x509-certificate-exporter 3d15h
|
||||
```
|
||||
|
||||
Open the web UI of Prometheus, and you can see that the corresponding `Targets` are ready.
|
||||
|
||||
|
||||
|
||||
x509-certificate-exporter officially provides a [Grafana Dashboard](https://grafana.com/grafana/dashboards/13922), as shown in the following figure.[](https://grafana.com/grafana/dashboards/13922)
|
||||
|
||||
|
||||
|
||||
It can be seen that all metrics are crystal clear. Generally, we only need to focus on certificates that have expired and are about to expire. Suppose you want to know validity of a certificate, use the `(x509_cert_not_after{filepath!=""} - time()) / 3600 / 24` expression.
|
||||
|
||||
|
||||
|
||||
Additionally, you can create alerting policies so that the O\&M personnel can receive notifications when a certificate is about to expire and update the certificate in time. To create an alerting policy, perform the following steps:
|
||||
|
||||
1. Go to **Alerting Policies** under **Monitoring & Alerting**, and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. Enter a name for the alerting policy, set the severity, and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. Click the **Custom Rule** tab, and enter `(x509_cert_not_after{filepath!=""} - time()) / 3600 / 24 < 30` for **Rule Expression**.
|
||||
|
||||

|
||||
|
||||
4. Click **Next**. On the **Message Settings** page, fill in the summary and details of the alert.
|
||||
|
||||

|
||||
|
||||
5. Click **Create**, and the alerting policy is created.
|
||||
|
||||

|
||||
|
||||
## Summary
|
||||
|
||||
KubeSphere 3.1 has supported the built-in alerting policies for certificate expiration. To view the policies, go to **Alerting Policies**, click **Bulit-in Policies**, and enter `expir` in the search box.
|
||||
|
||||

|
||||
|
||||
Click the alerting policy name to view its rule expression.
|
||||
|
||||

|
||||
|
||||
Metrics in the rule expression is exposed by the API Server component, and does not contain certificates of all components of the cluster. To monitor certificates of all components, it is recommended that you create a custom alerting policy on KubeSphere while deploying x509-certificate-exporter. Trust me, you will be hassle-free from certificate expiration.
|
||||
|
|
@ -0,0 +1,113 @@
|
|||
---
|
||||
title: ZTO Express
|
||||
description:
|
||||
|
||||
css: scss/case-detail.scss
|
||||
|
||||
section1:
|
||||
title: ZTO Express
|
||||
content: Shared by Yang Xiaofei, head of R&D of ZTO Express’s Cloud Platform, this article mainly introduces the development and deployment of KubeSphere on production environment, as well as application scenarios of ZTO Express.
|
||||
|
||||
section2:
|
||||
listLeft:
|
||||
- title: 'Company Introduction'
|
||||
contentList:
|
||||
- content: ZTO is both a key enabler and a direct beneficiary of China’s fast-growing e-commerce market, and has established itself as one of the largest express delivery service providers for millions of online merchants and consumers transacting on leading Chinese e-commerce platforms, such as Alibaba and JD.com. Globally, ZTO provides delivery services in key overseas markets through its business partners as it expands coverage of international express delivery by collaborating with international industry players.
|
||||
image: '/images/case/ZTO/ZTO1.jpg'
|
||||
|
||||
- title: 'Background'
|
||||
contentList:
|
||||
- content: For further development, five prominent challenges were waiting to be addressed.
|
||||
- content: First, different versions were required to adapt to different environments. However, as multiple versions were carried out, we could not effectively respond to resources through virtual machines.
|
||||
- content: Second, frequent upgrading called for quick environment initialization, and new versions were proposed frequently even every week.
|
||||
- content: Third, resource application and environment initialization were over-complex. We used conventional approaches for resource application in 2019, when trouble tickets were required for environment initialization delivery. It was troublesome and low efficient for testers as they needed to apply for resources first and release those resources after testing.
|
||||
- content: Fourth, low utilization of existing virtual resource was another problem. Staff turnovers and changes in positions sent abundant resources into zombies, especially on development and testing environment.
|
||||
- content: Fifth, we lacked horizontal extension capacity. Resources were scarce on important shopping days such as “6.18” and “double 11”. To address this problem, we used to prepare resources in advance and take them back after the events. This proved to be outdated.
|
||||
- content: Confronting all those challenges, we discussed with developers and decided to embark on cloudification.
|
||||
|
||||
- title: 'Cloudification on Production Environment'
|
||||
contentList:
|
||||
- content: Our cloudification includes three steps, namely, cloud-based, cloud-ready and cloud-native.
|
||||
image: /images/case/ZTO/ZTO2.jpg
|
||||
|
||||
- title:
|
||||
contentList:
|
||||
- content: Based on Dubbo framework, our micro-service completed transformation in an early date. However, the micro-service was carried out through virtual machine, when the emergence of Salts led to troubles. Therefore, we needed to make transformations on IaaS and container.
|
||||
image: /images/case/ZTO/ZTO3.jpg
|
||||
|
||||
- title: 'KubeSphere Development and Deployment'
|
||||
contentList:
|
||||
- content: We decided to apply KubeSphere as the construction scheme of our container management platform, ZKE, and as an upper container PaaS platform for running micro-services.
|
||||
image: /images/case/ZTO/ZTO4.jpg
|
||||
|
||||
- title: 'Construction Direction'
|
||||
contentList:
|
||||
- content: In line with the reality, we took KubeSphere as the container platform for running our stateless service, Kubernetes observability, and infrastructure resource monitoring, while stateful service like middlewares are provided in Iaas.
|
||||
image: /images/case/ZTO/ZTO5.jpg
|
||||
|
||||
- title: 'Small Clusters with a Single Tenant'
|
||||
contentList:
|
||||
- content: After the selection of KubeSphere, we encountered another problem——Should we choose small clusters with a single tenant or a large cluster with multi-tenants? After consulting the KubeSphere team and evaluating our own demands, we picked up small clusters with single tenant. In accordance with business scenarios (such as middle desk business, and scanning business) and resource applications (such as big data, edge), we created different clusters.
|
||||
- content: Based on multi-cluster design, we made cloud transformation in line with KubeSphere v2.0. Each cluster on development, testing and production environment were deployed with a set of KubeSphere, while public components are drawn out, such as monitor and log.
|
||||
|
||||
- title: 'Secondary Development Based on KubeSphere'
|
||||
contentList:
|
||||
- content: For realizing some customized features to meet our demand, we integrated our business scenarios to KubeSphere. Here is the integration took place between the summer of 2019 and October of 2020.
|
||||
|
||||
- title: 'Super-Resolution'
|
||||
contentList:
|
||||
- content: We applied super-resolution. Hence, once the limit is set, requests could be quickly computed and integrated. On production environment, the super-resolution ratio for CPU is 10 and memory 1.5.
|
||||
|
||||
- title: 'CPU Cluster Monitoring'
|
||||
contentList:
|
||||
- content: In this part, we merely applied CPU cluster monitoring for demonstrating the data we monitored.
|
||||
|
||||
- title: 'HPA Horizontal Scaling'
|
||||
contentList:
|
||||
- content: We held high expectation in HPA Horizontal Scaling. As KubeSphere resource allocation supports horizontal scaling, we set the horizontal scaling independently and integrated it with super-resolution, thus to facilitate the measurement of the super-resolution ratio.
|
||||
- content: Based on HPA and clear interface of KubeSphere, we have almost been free from operation and maintenance of some core businesses. In addition, demand in emergency scenarios can be quickly responded. For example, when it comes to upstream consumption backlogs, we can quickly increase replication and give a instant response.
|
||||
|
||||
- title: 'Batch Restart'
|
||||
contentList:
|
||||
- content: As abundant deployments might be restarted under extreme conditions, we set an exclusive module in particular. Hence, what we need is only one click to get instant restart and quick response of clusters or deployments under one Namespace.
|
||||
|
||||
- title: 'Affinity of Container'
|
||||
contentList:
|
||||
- content: In terms of affinity of container, we applied the soft anti-affinity, as some applications found their resource usage mutually exclusive. In addition, we also added some features and affinity settings in this part.
|
||||
|
||||
- title: 'Scheduling Strategy'
|
||||
contentList:
|
||||
- content: In terms of scheduling strategy, the features of specifying a host group and exclusive host stood out. As some of our businesses needed to access to the internet port, we put all those businesses within one host group and provided it with access to the internet. We also applied exclusive host to run big data applications in the early hours of morning, because the service was idle at that moment.
|
||||
|
||||
- title: 'Gateway'
|
||||
contentList:
|
||||
- content: Each Namespace in KubeSphere held an independent gateway. Independent gateway met our production requirement, while we also needed pan-gateway in development and testing, thus to achieve quicker responses to servers. Hence, we set both pan-gateway and independent gateway, and had access to all development and testing through pan-domain name. After configuration, our services could be directly accessed through KubeSphere interface.
|
||||
|
||||
- title: 'Log Collection'
|
||||
contentList:
|
||||
- content: We used to apply Fluent-Bit for log collection, while since there were some mistakes made in resources upgrading or parameters, it always failed as businesses kept increasing. Therefore, we turned to Sidecar. Services based on Java all set an independent Sidecar, and pushed logs to centers like ElasticSearch through Logkit, a small agent. We continued to use Fluent-agent to collect logs under development and testing environment, while for production scenarios that require complete logs, we took further steps to ensure that logs were persistently stored at disks. All logs of containers were collected through four approaches, including console log, Fluent-agent console log, /data Sldercar-logkit and /data NFS.
|
||||
|
||||
- title: 'Event Tracing'
|
||||
contentList:
|
||||
- content: In term of Event Tracing, we made transformation on the basis of Kube-eventer, and added event tracing to KubeSphere, where configurated information could be sent to Ding Talk. As for changes in businesses that were highly concerned under production environment, we could send them to work group of Ding Talk through customized configuration.
|
||||
|
||||
- title: 'Future Planning'
|
||||
contentList:
|
||||
- content: In the future, we would like to make some improvements in several aspects. First of all, service plate will ensure that all individuals, including operators, maintainers as well as developers, can understand the framework of the services provided, the middlewares and data bases relied on,as well as the running status. Second, it is expected that status quo of all PODS, including changes in color and resources allocation can be seen from the perspective of the whole cluster. Third, we hope that edge computing can be applied for uploading scanned statistics of transferred expresses, automatic recognition of violate practice of operator, the wisdom park project and other purposes.
|
||||
- content: In addition, we also encounter some difficulties in the management of abundant edge nodes, stability and high availability of KubeEdge, and deployment and automatic operation and maintenance of edge nodes. We are exploring more uncharted areas with the pursuit of breakthroughs.
|
||||
|
||||
rightPart:
|
||||
icon: /images/case/ZTO/ZTO6.jpg
|
||||
list:
|
||||
- title: INDUSTRY
|
||||
content: Delivery
|
||||
- title: LOCATION
|
||||
content: China
|
||||
- title: CLOUD TYPE
|
||||
content: On-premises
|
||||
- title: CHALLENGES
|
||||
content: Multi-clusters, HA, Microservice Migration, Unifying Container and VM Networking
|
||||
- title: ADOPTED FEATURES
|
||||
content: HPA, DevOps, Grayscale Release, Monitoring and Alerting
|
||||
|
||||
---
|
||||
|
|
@ -35,6 +35,10 @@ section2:
|
|||
- icon: "images/case/vng.jpg"
|
||||
content: "VNG has seen 14 years of continuous development and expansion to become one of the leading IT companies in Vietnam and Southeast Asia."
|
||||
link: "vng/"
|
||||
|
||||
- icon: "images/case/ZTO/ZTO6.jpg"
|
||||
content: "ZTO is both a key enabler and a direct beneficiary of China’s fast-growing e-commerce market, and has established itself as one of the largest express delivery service providers for millions of online merchants and consumers transacting on leading Chinese e-commerce platforms, such as Alibaba and JD.com."
|
||||
link: "ZTO/"
|
||||
|
||||
section3:
|
||||
title: 'Various Industries are Powered by KubeSphere'
|
||||
|
|
|
|||
|
|
@ -5,6 +5,6 @@ _build:
|
|||
|
||||
| Installation Tool | KubeSphere version | Supported Kubernetes versions |
|
||||
| ----------------- | ------------------ | ------------------------------------------------------------ |
|
||||
| KubeKey | v3.1.1 | v1.17.0, v1.17.4, v1.17.5, v1.17.6, v1.17.7, v1.17.8, v1.17.9, v1.18.3, v1.18.5, v1.18.6, v1.18.8, v1.19.0, v1.19.8, v1.19.9, v1.20.4, v1.20.6 |
|
||||
| ks-installer | v3.1.1 | v1.17.x, v1.18.x, v1.19.x, v1.20.x |
|
||||
| KubeKey | 3.2.0 | v1.19.x, v1.20.x, v1.21.x, v1.22.x (experimental) |
|
||||
| ks-installer | 3.2.0 | v1.19.x, v1.20.x, v1.21.x, v1.22.x (experimental) |
|
||||
|
||||
|
|
|
|||
|
|
@ -1,54 +1,62 @@
|
|||
---
|
||||
title: "OIDC identity provider"
|
||||
title: "OIDC Identity Provider"
|
||||
keywords: "OIDC, identity provider"
|
||||
description: "How to configure authentication"
|
||||
description: "How to use an external OIDC identity provider."
|
||||
|
||||
linkTitle: "OIDC identity provider"
|
||||
linkTitle: "OIDC Identity Provider"
|
||||
weight: 12221
|
||||
---
|
||||
|
||||
## OIDC Identity Provider
|
||||
|
||||
[OpenID Connect](https://openid.net/connect/) is an interoperable authentication protocol based on the OAuth 2.0 family of specifications. It uses straightforward REST/JSON message flows with a design goal of “making simple things simple and complicated things possible”. It’s uniquely easy for developers to integrate, compared to any preceding Identity protocol, such as Keycloak, Okta, Dex, Auth0, Gluu, and many more.
|
||||
[OpenID Connect](https://openid.net/connect/) is an interoperable authentication protocol based on the OAuth 2.0 family of specifications. It uses straightforward REST/JSON message flows with a design goal of “making simple things simple and complicated things possible”. It’s uniquely easy for developers to integrate, compared to any preceding Identity protocol, such as Keycloak, Okta, Dex, Auth0, Gluu, Casdoor and many more.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need to deploy a Kubernetes cluster and install KubeSphere in the cluster. For details, see [Installing on Linux](/docs/installing-on-linux/) and [Installing on Kubernetes](/docs/installing-on-kubernetes/).
|
||||
|
||||
*Example of using [Google Identity Platform](https://developers.google.com/identity/protocols/oauth2/openid-connect)*:
|
||||
## Procedure
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
kubesphere.yaml: |
|
||||
authentication:
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
jwtSecret: "********"
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: google
|
||||
type: OIDCIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
clientID: '********'
|
||||
clientSecret: '********'
|
||||
issuer: https://accounts.google.com
|
||||
redirectURL: 'https://ks-console/oauth/redirect/google'
|
||||
kind: ConfigMap
|
||||
name: kubesphere-config
|
||||
namespace: kubesphere-system
|
||||
```
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/set-up-external-authentication/toolbox.png" width="20px" height="20px"> in the lower-right corner, click **kubectl**, and run the following command to edit `ks-installer` of the CRD `ClusterConfiguration`:
|
||||
|
||||
For the above example:
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit cc ks-installer
|
||||
```
|
||||
|
||||
2. Add the following fields under `spec.authentication.jwtSecret`.
|
||||
|
||||
*Example of using [Google Identity Platform](https://developers.google.com/identity/protocols/oauth2/openid-connect)*:
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
authentication:
|
||||
jwtSecret: ''
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: google
|
||||
type: OIDCIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
clientID: '********'
|
||||
clientSecret: '********'
|
||||
issuer: https://accounts.google.com
|
||||
redirectURL: 'https://ks-console/oauth/redirect/google'
|
||||
```
|
||||
|
||||
See description of parameters as below:
|
||||
|
||||
| Parameter | Description |
|
||||
| -------------------- | ------------------------------------------------------------ |
|
||||
| clientID | The OAuth2 client ID. |
|
||||
| clientSecret | The OAuth2 client secret. |
|
||||
| redirectURL | The redirected URL to ks-console in the following format: `https://<Domain name>/oauth/redirect/<Provider name>`. The `<Provider name>` in the URL corresponds to the value of `oauthOptions:identityProviders:name`. |
|
||||
| issuer | Defines how Clients dynamically discover information about OpenID Providers. |
|
||||
| preferredUsernameKey | Configurable key which contains the preferred username claims. This parameter is optional. |
|
||||
| emailKey | Configurable key which contains the email claims. This parameter is optional. |
|
||||
| getUserInfo | GetUserInfo uses the userinfo endpoint to get additional claims for the token. This is especially useful where upstreams return "thin" ID tokens. This parameter is optional. |
|
||||
| insecureSkipVerify | Used to turn off TLS certificate verification. |
|
||||
|
||||
| Parameter | Description |
|
||||
| ----------| ----------- |
|
||||
| clientID | The OAuth2 client ID. |
|
||||
| clientSecret | The OAuth2 client secret. |
|
||||
| redirectURL | The redirected URL to ks-console. |
|
||||
| issuer | Defines how Clients dynamically discover information about OpenID Providers. |
|
||||
| preferredUsernameKey | Configurable key which contains the preferred username claims. |
|
||||
| emailKey | Configurable key which contains the email claims. |
|
||||
| getUserInfo | GetUserInfo uses the userinfo endpoint to get additional claims for the token. This is especially useful where upstreams return "thin" id tokens. |
|
||||
| insecureSkipVerify | Used to turn off TLS certificate verify. |
|
||||
|
|
@ -9,7 +9,7 @@ weight: 12210
|
|||
|
||||
This document describes how to use an external identity provider such as an LDAP service or Active Directory service on KubeSphere.
|
||||
|
||||
KubeSphere provides a built-in OAuth server. Users can obtain OAuth access tokens to authenticate themselves to the KubeSphere API. As a KubeSphere administrator, you can edit the `kubesphere-config` ConfigMap to configure OAuth and specify identity providers.
|
||||
KubeSphere provides a built-in OAuth server. Users can obtain OAuth access tokens to authenticate themselves to the KubeSphere API. As a KubeSphere administrator, you can edit `ks-installer` of the CRD `ClusterConfiguration` to configure OAuth and specify identity providers.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
|
@ -18,57 +18,49 @@ You need to deploy a Kubernetes cluster and install KubeSphere in the cluster. F
|
|||
|
||||
## Procedure
|
||||
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/set-up-external-authentication/toolbox.png" width="20px" height="20px"> in the bottom-right corner, click **Kubectl**, and run the following command to edit the `kubesphere-config` ConfigMap:
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/set-up-external-authentication/toolbox.png" width="20px" height="20px"> in the lower-right corner, click **kubectl**, and run the following command to edit `ks-installer` of the CRD `ClusterConfiguration`:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit cm kubesphere-config
|
||||
kubectl -n kubesphere-system edit cc ks-installer
|
||||
```
|
||||
|
||||
2. Configure fields in the `data:kubesphere.yaml:authentication` section.
|
||||
2. Add the following fields under `spec.authentication.jwtSecret`.
|
||||
|
||||
Example:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
kubesphere.yaml: |
|
||||
authentication:
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
loginHistoryRetentionPeriod: 168h
|
||||
maximumClockSkew: 10s
|
||||
multipleLogin: true
|
||||
jwtSecret: "********"
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: ldap
|
||||
type: LDAPIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
host: 192.168.0.2:389
|
||||
managerDN: uid=root,cn=users,dc=nas
|
||||
managerPassword: ********
|
||||
userSearchBase: cn=users,dc=nas
|
||||
loginAttribute: uid
|
||||
mailAttribute: mail
|
||||
spec:
|
||||
authentication:
|
||||
jwtSecret: ''
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
loginHistoryRetentionPeriod: 168h
|
||||
maximumClockSkew: 10s
|
||||
multipleLogin: true
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: LDAP
|
||||
type: LDAPIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
host: 192.168.0.2:389
|
||||
managerDN: uid=root,cn=users,dc=nas
|
||||
managerPassword: ********
|
||||
userSearchBase: cn=users,dc=nas
|
||||
loginAttribute: uid
|
||||
mailAttribute: mail
|
||||
```
|
||||
|
||||
|
||||
The fields are described as follows:
|
||||
|
||||
* `authenticateRateLimiterMaxTries`: Maximum number of consecutive login failures allowed during a period specified by `authenticateRateLimiterDuration`. If the number of consecutive login failures of a user reaches the limit, the user will be blocked.
|
||||
|
||||
* `authenticateRateLimiterDuration`: Period during which `authenticateRateLimiterMaxTries` applies.
|
||||
|
||||
* `loginHistoryRetentionPeriod`: Retention period of login records. Outdated login records are automatically deleted.
|
||||
|
||||
* `maximumClockSkew`: Maximum clock skew for time-sensitive operations such as token expiration validation. The default value is `10s`.
|
||||
|
||||
* `multipleLogin`: Whether multiple users are allowed to log in from different locations. The default value is `true`.
|
||||
|
||||
* `jwtSecret`: Secret used to sign user tokens. In a multi-cluster environment, all clusters must [use the same Secret](../../../multicluster-management/enable-multicluster/direct-connection/#prepare-a-member-cluster).
|
||||
|
||||
* `authenticateRateLimiterMaxTries`: Maximum number of consecutive login failures allowed during a period specified by `authenticateRateLimiterDuration`. If the number of consecutive login failures of a user reaches the limit, the user will be blocked.
|
||||
* `authenticateRateLimiterDuration`: Period during which `authenticateRateLimiterMaxTries` applies.
|
||||
* `loginHistoryRetentionPeriod`: Retention period of login records. Outdated login records are automatically deleted.
|
||||
* `maximumClockSkew`: Maximum clock skew for time-sensitive operations such as token expiration validation. The default value is `10s`.
|
||||
* `multipleLogin`: Whether multiple users are allowed to log in from different locations. The default value is `true`.
|
||||
* `oauthOptions`: OAuth settings.
|
||||
* `accessTokenMaxAge`: Access token lifetime. For member clusters in a multi-cluster environment, the default value is `0h`, which means access tokens never expire. For other clusters, the default value is `2h`.
|
||||
* `accessTokenInactivityTimeout`: Access token inactivity timeout period. An access token becomes invalid after it is idle for a period specified by this field. After an access token times out, the user needs to obtain a new access token to regain access.
|
||||
|
|
@ -76,10 +68,10 @@ You need to deploy a Kubernetes cluster and install KubeSphere in the cluster. F
|
|||
* `name`: Identity provider name.
|
||||
* `type`: Identity provider type.
|
||||
* `mappingMethod`: Account mapping method. The value can be `auto` or `lookup`.
|
||||
* If the value is `auto` (default), you need to specify a new username. KubeSphere automatically creates a user according to the username and maps the user to a third-party account.
|
||||
* If the value is `auto` (default), you need to specify a new username. KubeSphere automatically creates a user according to the username and maps the user to a third-party account.
|
||||
* If the value is `lookup`, you need to perform step 3 to manually map an existing KubeSphere user to a third-party account.
|
||||
* `provider`: Identity provider information. Fields in this section vary according to the identity provider type.
|
||||
|
||||
|
||||
3. If `mappingMethod` is set to `lookup`, run the following command and add the labels to map a KubeSphere user to a third-party account. Skip this step if `mappingMethod` is set to `auto`.
|
||||
|
||||
```bash
|
||||
|
|
@ -92,17 +84,13 @@ You need to deploy a Kubernetes cluster and install KubeSphere in the cluster. F
|
|||
iam.kubesphere.io/origin-uid: <Third-party username>
|
||||
```
|
||||
|
||||
4. After the fields are configured, run the following command to restart ks-apiserver.
|
||||
4. After the fields are configured, save your changes, and wait until the restart of ks-installer is complete.
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system rollout restart deploy/ks-apiserver
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
In a multi-cluster environment, you only need to configure the Host Cluster.
|
||||
|
||||
{{</ notice >}}
|
||||
{{< notice note >}}
|
||||
|
||||
In a multi-cluster environment, you only need to configure the host cluster.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
||||
## Identity provider
|
||||
|
|
@ -111,14 +99,14 @@ You can configure multiple identity providers (IdPs) in the 'identityProviders'
|
|||
|
||||
Kubesphere provides the following types of identity providers by default:
|
||||
|
||||
* [LDAPIdentityProvider](../use-an-ldap-service)
|
||||
* [LDAP Identity Provider](../use-an-ldap-service)
|
||||
|
||||
* [OIDCIdentityProvider](../oidc-identity-provider)
|
||||
* [OIDC Identity Provider](../oidc-identity-provider)
|
||||
|
||||
* [GitHubIdentityProvider]()
|
||||
* [GitHub Identity Provider]()
|
||||
|
||||
* [CASIdentityProvider]()
|
||||
* [CAS Identity Provider]()
|
||||
|
||||
* [AliyunIDaaSProvider]()
|
||||
* [Aliyun IDaaS Provider]()
|
||||
|
||||
You can also expand the kubesphere [OAuth2 authentication plug-in](../use-an-oauth2-identity-provider) to integrate with your account system.
|
||||
|
|
|
|||
|
|
@ -14,44 +14,39 @@ This document describes how to use an LDAP service as an external identity provi
|
|||
* You need to deploy a Kubernetes cluster and install KubeSphere in the cluster. For details, see [Installing on Linux](/docs/installing-on-linux/) and [Installing on Kubernetes](/docs/installing-on-kubernetes/).
|
||||
* You need to obtain the manager distinguished name (DN) and manager password of an LDAP service.
|
||||
|
||||
### Procedure
|
||||
## Procedure
|
||||
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/use-an-ldap-service/toolbox.png" width="20px" height="20px"> in the bottom-right corner, click **Kubectl**, and run the following command to edit the `kubesphere-config` ConfigMap:
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/set-up-external-authentication/toolbox.png" width="20px" height="20px"> in the lower-right corner, click **kubectl**, and run the following command to edit `ks-installer` of the CRD `ClusterConfiguration`:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit cm kubesphere-config
|
||||
kubectl -n kubesphere-system edit cc ks-installer
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
kubesphere.yaml: |
|
||||
authentication:
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
loginHistoryRetentionPeriod: 168h
|
||||
maximumClockSkew: 10s
|
||||
multipleLogin: true
|
||||
jwtSecret: "********"
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: LDAP
|
||||
type: LDAPIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
host: 192.168.0.2:389
|
||||
managerDN: uid=root,cn=users,dc=nas
|
||||
managerPassword: ********
|
||||
userSearchBase: cn=users,dc=nas
|
||||
loginAttribute: uid
|
||||
mailAttribute: mail
|
||||
spec:
|
||||
authentication:
|
||||
jwtSecret: ''
|
||||
maximumClockSkew: 10s
|
||||
multipleLogin: true
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: LDAP
|
||||
type: LDAPIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
host: 192.168.0.2:389
|
||||
managerDN: uid=root,cn=users,dc=nas
|
||||
managerPassword: ********
|
||||
userSearchBase: cn=users,dc=nas
|
||||
loginAttribute: uid
|
||||
mailAttribute: mail
|
||||
```
|
||||
|
||||
2. Configure fields other than `oauthOptions:identityProviders` in the `data:kubesphere.yaml:authentication` section. For details, see [Set Up External Authentication](../set-up-external-authentication/).
|
||||
|
||||
2. Configure fields other than `oauthOptions:identityProviders` in the `spec:authentication` section. For details, see [Set Up External Authentication](../set-up-external-authentication/).
|
||||
|
||||
3. Configure fields in `oauthOptions:identityProviders` section.
|
||||
|
||||
|
|
@ -80,19 +75,27 @@ This document describes how to use an LDAP service as an external identity provi
|
|||
iam.kubesphere.io/origin-uid: <LDAP username>
|
||||
```
|
||||
|
||||
5. After the fields are configured, run the following command to restart ks-apiserver.
|
||||
5. After the fields are configured, save your changes, and wait until the restart of ks-installer is complete.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The KubeSphere web console is unavailable during the restart of ks-installer. Please wait until the restart is complete.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. If you are using KubeSphere 3.2.0, run the following command after configuring LDAP and wait until `ks-installer` is up and running:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system rollout restart deploy/ks-apiserver
|
||||
kubectl -n kubesphere-system set image deployment/ks-apiserver *=kubesphere/ks-apiserver:v3.2.1
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The KubeSphere web console is unavailable during the restart of ks-apiserver. Please wait until the restart is complete.
|
||||
If you are using KubeSphere 3.2.1, skip this step.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. Go to the KubeSphere login page and enter the username and password of an LDAP user to log in.
|
||||
7. Go to the KubeSphere login page and enter the username and password of an LDAP user to log in.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -81,57 +81,49 @@ KubeSphere provides two built-in OAuth 2.0 plugins: [GitHubIdentityProvider](htt
|
|||
|
||||
## Integrate an Identity Provider with KubeSphere
|
||||
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/use-an-oauth2-identity-provider/toolbox.png" width="20px" height="20px"> in the bottom-right corner, click **Kubectl**, and run the following command to edit the `kubesphere-config` ConfigMap:
|
||||
1. Log in to KubeSphere as `admin`, move the cursor to <img src="/images/docs/access-control-and-account-management/external-authentication/set-up-external-authentication/toolbox.png" width="20px" height="20px"> in the lower-right corner, click **kubectl**, and run the following command to edit `ks-installer` of the CRD `ClusterConfiguration`:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit cm kubesphere-config
|
||||
kubectl -n kubesphere-system edit cc ks-installer
|
||||
```
|
||||
|
||||
2. Configure fields other than `oauthOptions:identityProviders` in the `data:kubesphere.yaml:authentication` section. For details, see [Set Up External Authentication](../set-up-external-authentication/).
|
||||
2. Configure fields other than `oauthOptions:identityProviders` in the `spec:authentication` section. For details, see [Set Up External Authentication](../set-up-external-authentication/).
|
||||
|
||||
3. Configure fields in `oauthOptions:identityProviders` section according to the identity provider plugin you have developed.
|
||||
|
||||
The following is a configuration example that uses GitHub as an external identity provider. For details, see the [official GitHub documentation](https://docs.github.com/en/developers/apps/building-oauth-apps) and the [source code of the GitHubIdentityProvider](https://github.com/kubesphere/kubesphere/blob/release-3.1/pkg/apiserver/authentication/identityprovider/github/github.go) plugin.
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
kubesphere.yaml: |
|
||||
authentication:
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
jwtSecret: '******'
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: github
|
||||
type: GitHubIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
clientID: '******'
|
||||
clientSecret: '******'
|
||||
redirectURL: 'https://ks-console/oauth/redirect/github'
|
||||
spec:
|
||||
authentication:
|
||||
jwtSecret: ''
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: github
|
||||
type: GitHubIdentityProvider
|
||||
mappingMethod: auto
|
||||
provider:
|
||||
clientID: '******'
|
||||
clientSecret: '******'
|
||||
redirectURL: 'https://ks-console/oauth/redirect/github'
|
||||
```
|
||||
|
||||
|
||||
Similarly, you can also use Alibaba Cloud IDaaS as an external identity provider. For details, see the official [Alibaba IDaaS documentation](https://www.alibabacloud.com/help/product/111120.htm?spm=a3c0i.14898238.2766395700.1.62081da1NlxYV0) and the [source code of the AliyunIDaasProvider](https://github.com/kubesphere/kubesphere/blob/release-3.1/pkg/apiserver/authentication/identityprovider/github/github.go) plugin.
|
||||
|
||||
4. After the `kubesphere-config` ConfigMap is modified, run the following command to restart ks-apiserver.
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system rollout restart deploy/ks-apiserver
|
||||
```
|
||||
4. After the fields are configured, save your changes, and wait until the restart of ks-installer is complete.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The KubeSphere web console is unavailable during the restart of ks-apiserver. Please wait until the restart is complete.
|
||||
|
||||
The KubeSphere web console is unavailable during the restart of ks-installer. Please wait until the restart is complete.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Go to the KubeSphere login page, click **Log In with XXX** (for example, **Log In with GitHub**).
|
||||
|
||||

|
||||
|
||||
6. On the login page of the external identity provider, enter the username and password of a user configured at the identity provider to log in to KubeSphere.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: "Kubernetes Multi-tenancy in KubeSphere"
|
||||
keywords: "Kubernetes, Kubesphere, multi-tenancy"
|
||||
keywords: "Kubernetes, KubeSphere, multi-tenancy"
|
||||
description: "Understand the multi-tenant architecture in KubeSphere."
|
||||
linkTitle: "Multi-tenancy in KubeSphere"
|
||||
weight: 12100
|
||||
|
|
@ -36,8 +36,6 @@ Multi-level access control and resource quota limits underlie resource isolation
|
|||
|
||||
Similar to Kubernetes, KubeSphere uses RBAC to manage permissions granted to users, thus logically implementing resource isolation.
|
||||
|
||||

|
||||
|
||||
The access control in KubeSphere is divided into three levels: platform, workspace and project. You use roles to control what permissions users have at different levels for different resources.
|
||||
|
||||
1. [Platform roles](/docs/quick-start/create-workspace-and-project/): Control what permissions platform users have for platform resources, such as clusters, workspaces and platform members.
|
||||
|
|
|
|||
|
|
@ -8,93 +8,67 @@ weight: 14100
|
|||
|
||||
KubeSphere integrates [OpenPitrix](https://github.com/openpitrix/openpitrix), an open-source multi-cloud application management platform, to set up the App Store, managing Kubernetes applications throughout their entire lifecycle. The App Store supports two kinds of application deployment:
|
||||
|
||||
- **App templates** provide a way for developers and independent software vendors (ISVs) to share applications with users in a workspace. You can also import third-party app repositories within a workspace.
|
||||
- **Composing apps** help users quickly build a complete application using multiple microservices to compose it. KubeSphere allows users to select existing services or create new services to create a composing app on the one-stop console.
|
||||
|
||||

|
||||
- **Template-Based Apps** provide a way for developers and independent software vendors (ISVs) to share applications with users in a workspace. You can also import third-party app repositories within a workspace.
|
||||
- **Composed Apps** help users quickly build a complete application using multiple microservices to compose it. KubeSphere allows users to select existing services or create new services to create a composed app on the one-stop console.
|
||||
|
||||
Using [Redis](https://redis.io/) as an example application, this tutorial demonstrates how to manage the Kubernetes app throughout the entire lifecycle, including submission, review, test, release, upgrade and removal.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to enable the [KubeSphere App Store (OpenPitrix)](../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project and an account (`project-regular`). For more information, see [Create Workspaces, Projects, Accounts and Roles](../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project and a user (`project-regular`). For more information, see [Create Workspaces, Projects, Users and Roles](../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create a customized role and account
|
||||
### Step 1: Create a customized role and two users
|
||||
|
||||
You need to create two accounts first, one for ISVs (`isv`) and the other (`reviewer`) for app technical reviewers.
|
||||
You need to create two users first, one for ISVs (`isv`) and the other (`reviewer`) for app technical reviewers.
|
||||
|
||||
1. Log in to the KubeSphere console with the account `admin`. Click **Platform** in the top-left corner and select **Access Control**. In **Account Roles**, click **Create**.
|
||||
|
||||

|
||||
1. Log in to the KubeSphere console with the user `admin`. Click **Platform** in the upper-left corner and select **Access Control**. In **Platform Roles**, click **Create**.
|
||||
|
||||
2. Set a name for the role, such as `app-review`, and click **Edit Permissions**.
|
||||
|
||||

|
||||
|
||||
3. In **App Management**, choose **App Template Management** and **App Template Viewing** in the permission list, then click **OK**.
|
||||
|
||||

|
||||
3. In **App Management**, choose **App Template Management** and **App Template Viewing** in the permission list, and then click **OK**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The account granted the role `app-review` is able to view the App Store on the platform and manage apps, including review and removal.
|
||||
The user who is granted the role `app-review` has the permission to view the App Store on the platform and manage apps, including review and removal.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. As the role is ready now, you need to create an account and grant the role of `app-review` to it. In **Accounts**, click **Create**. Provide the required information and click **OK**.
|
||||
4. As the role is ready now, you need to create a user and grant the role `app-review` to it. In **Users**, click **Create**. Provide the required information and click **OK**.
|
||||
|
||||

|
||||
5. Similarly, create another user `isv`, and grant the role of `platform-regular` to it.
|
||||
|
||||
5. Similarly, create another account `isv`, and grant the role of `platform-regular` to it.
|
||||
|
||||

|
||||
|
||||
6. Invite both accounts created above to an existing workspace such as `demo-workspace`, and grant them the role of `workspace-admin`.
|
||||
6. Invite both users created above to an existing workspace such as `demo-workspace`, and grant them the role of `workspace-admin`.
|
||||
|
||||
### Step 2: Upload and submit an application
|
||||
|
||||
1. Log in to KubeSphere as `isv` and go to your workspace. You need to upload the example app Redis to this workspace so that it can be used later. First, download the app [Redis 11.3.4](https://github.com/kubesphere/tutorial/raw/master/tutorial%205%20-%20app-store/redis-11.3.4.tgz) and click **Upload Template** in **App Templates**.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
In this example, a new version of Redis will be uploaded later to demonstrate the upgrade feature.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
2. In the dialog that appears, click **Upload Helm Chart Package** to upload the chart file. Click **OK** to continue.
|
||||
2. In the dialog that appears, click **Upload Helm Chart** to upload the chart file. Click **OK** to continue.
|
||||
|
||||

|
||||
|
||||
3. Basic information of the app displays under **App Information**. To upload an icon for the app, click **Upload icon**. You can also skip it and click **OK** directly.
|
||||
3. Basic information of the app displays under **App Information**. To upload an icon for the app, click **Upload Icon**. You can also skip it and click **OK** directly.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
Maximum accepted resolutions of the app icon: 96 x 96 pixels.
|
||||
The maximum accepted resolution of the app icon is 96 x 96 pixels.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
4. The app displays in the template list with the status **Developing** after it is successfully uploaded, which means this app is under development. The uploaded app is visible to all members in the same workspace.
|
||||
|
||||
4. The app displays in the template list with the status **Draft** after successfully uploaded, which means this app is under development. The uploaded app is visible to all members in the same workspace.
|
||||
|
||||

|
||||
|
||||
5. Go to the detail page of the app template by clicking Redis from the list. You can edit the basic information of this app by clicking **Edit Information**.
|
||||
|
||||

|
||||
5. Go to the detail page of the app template by clicking Redis from the list. You can edit the basic information of this app by clicking **Edit**.
|
||||
|
||||
6. You can customize the app's basic information by specifying the fields in the pop-up window.
|
||||
|
||||

|
||||
|
||||
7. Click **OK** to save your changes, then you can test this application by deploying it to Kubernetes. Click the draft version to expand the menu and select **Test Deployment**.
|
||||
|
||||

|
||||
7. Click **OK** to save your changes, then you can test this application by deploying it to Kubernetes. Click the draft version to expand the menu and click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -102,11 +76,7 @@ You need to create two accounts first, one for ISVs (`isv`) and the other (`revi
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
8. Select the cluster and project to which you want to deploy the app, set up different configurations for the app, and then click **Deploy**.
|
||||
|
||||

|
||||
|
||||

|
||||
8. Select the cluster and project to which you want to deploy the app, set up different configurations for the app, and then click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -114,13 +84,9 @@ You need to create two accounts first, one for ISVs (`isv`) and the other (`revi
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
9. Wait for a few minutes, then switch to the tab **Deployed Instances**. You will find that Redis has been deployed successfully.
|
||||
9. Wait for a few minutes, then switch to the tab **App Instances**. You will find that Redis has been deployed successfully.
|
||||
|
||||

|
||||
|
||||
10. After you test the app with no issues found, you can click **Submit for Review** to submit this application for review.
|
||||
|
||||

|
||||
10. After you test the app with no issues found, you can click **Submit for Release** to submit this application for release.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -128,37 +94,25 @@ The version number must start with a number and contain decimal points.
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
11. After the app is submitted, the app status will change to **Submitted**. Now app reviewers can review it.
|
||||
11. After the app is submitted, the app status will change to **Submitted**. Now app reviewers can release it.
|
||||
|
||||

|
||||
### Step 3: Release the application
|
||||
|
||||
### Step 3: Review the application
|
||||
1. Log out of KubeSphere and log back in as `app-reviewer`. Click **Platform** in the upper-left corner and select **App Store Management**. On the **App Release** page, the app submitted in the previous step displays under the tab **Unreleased**.
|
||||
|
||||
1. Log out of KubeSphere and log back in as `reviewer`. Click **Platform** in the top-left corner and select **App Store Management**. On the **App Review** page, the app submitted in the previous step displays under the tab **Unprocessed**.
|
||||
2. To release this app, click it to inspect the app information, introduction, chart file and update logs from the pop-up window.
|
||||
|
||||

|
||||
|
||||
2. To review this app, click it to inspect the app information, introduction, chart file and update logs from the pop-up window.
|
||||
|
||||

|
||||
|
||||
3. It is the responsibility of the reviewer to decide whether the app meets the criteria to be released to the App Store. Click **Pass** to approve it or **Reject** to deny an app submission.
|
||||
3. The reviewer needs to decide whether the app meets the release criteria on the App Store. Click **Pass** to approve it or **Reject** to deny an app submission.
|
||||
|
||||
### Step 4: Release the application to the App Store
|
||||
|
||||
After the app is approved, `isv` can release the Redis application to the App Store, allowing all users on the platform to find and deploy this application.
|
||||
|
||||
1. Log out of KubeSphere and log back in as `isv`. Go to your workspace and click Redis on the **App Templates** page. On its detail page, expand the version menu, then click **Release to Store**. In the pop-up prompt, click **OK** to confirm.
|
||||
1. Log out of KubeSphere and log back in as `isv`. Go to your workspace and click Redis on the **Template-Based Apps** page. On its details page, expand the version menu, then click **Release to Store**. In the pop-up prompt, click **OK** to confirm.
|
||||
|
||||

|
||||
2. Under **App Release**, you can see the app status. **Activated** means it is available in the App Store.
|
||||
|
||||
2. Under **App Review**, you can see the app status. **Active** means it is available in the App Store.
|
||||
|
||||

|
||||
|
||||
3. Click **View in Store** to go to its **App Information** page in the App Store. Alternatively, click **App Store** in the top-left corner and you can also see the app.
|
||||
|
||||

|
||||
3. Click **View in Store** to go to its **Versions** page in the App Store. Alternatively, click **App Store** in the upper-left corner, and you can also see the app.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -166,27 +120,21 @@ After the app is approved, `isv` can release the Redis application to the App St
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
4. Now, users in the workspace can deploy Redis from the App Store. To deploy the app to Kubernetes, click the app to go to its **App Information** page, and click **Deploy**.
|
||||
|
||||

|
||||
4. Now, users in the workspace can install Redis from the App Store. To install the app to Kubernetes, click the app to go to its **App Information** page, and click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you have trouble deploying an application and the **Status** column shows **Failed**, you can hover your cursor over the **Failed** icon to see the error message.
|
||||
If you have trouble installing an application and the **Status** column shows **Failed**, you can hover your cursor over the **Failed** icon to see the error message.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Step 5: Create an app category
|
||||
### Step 5: Create an application category
|
||||
|
||||
`reviewer` can create multiple categories for different types of applications based on their function and usage. It is similar to setting tags and categories can be used in the App Store as filters, such as Big Data, Middleware, and IoT.
|
||||
`app-reviewer` can create multiple categories for different types of applications based on their function and usage. It is similar to setting tags and categories can be used in the App Store as filters, such as Big Data, Middleware, and IoT.
|
||||
|
||||
1. Log in to KubeSphere as `reviewer`. To create a category, go to the **App Store Management** page and click <img src="/images/docs/appstore/application-lifecycle-management/plus.png" height="20px"> in **App Categories**.
|
||||
1. Log in to KubeSphere as `app-reviewer`. To create a category, go to the **App Store Management** page and click <img src="/images/docs/appstore/application-lifecycle-management/plus.png" height="20px"> in **App Categories**.
|
||||
|
||||

|
||||
|
||||
2. Set a name and icon for the category in the dialog, then click **OK**. For Redis, you can enter `Database` for the field **Category Name**.
|
||||
|
||||

|
||||
2. Set a name and icon for the category in the dialog, then click **OK**. For Redis, you can enter `Database` for the field **Name**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -196,37 +144,23 @@ After the app is approved, `isv` can release the Redis application to the App St
|
|||
|
||||
3. As the category is created, you can assign the category to your app. In **Uncategorized**, select Redis and click **Change Category**.
|
||||
|
||||

|
||||
|
||||
4. In the dialog, select the category (**Database**) from the drop-down list and click **OK**.
|
||||
|
||||

|
||||
|
||||
5. The app displays in the category as expected.
|
||||
|
||||

|
||||
|
||||
### Step 6: Add a new version
|
||||
|
||||
To allow workspace users to upgrade apps, you need to add new app versions to KubeSphere first. Follow the steps below to add a new version for the example app.
|
||||
|
||||
1. Log in to KubeSphere as `isv` again and navigate to **App Templates**. Click the app Redis in the list.
|
||||
1. Log in to KubeSphere as `isv` again and navigate to **Template-Based Apps**. Click the app Redis in the list.
|
||||
|
||||
2. Download [Redis 12.0.0](https://github.com/kubesphere/tutorial/raw/master/tutorial%205%20-%20app-store/redis-12.0.0.tgz), which is a new version of Redis for demonstration in this tutorial. On the tab **Versions**, click **New Version** on the right to upload the package you just downloaded.
|
||||
|
||||

|
||||
|
||||
3. Click **Upload Helm Chart Package** and click **OK** after it is uploaded.
|
||||
|
||||

|
||||
3. Click **Upload Helm Chart** and click **OK** after it is uploaded.
|
||||
|
||||
4. The new app version displays in the version list. You can click it to expand the menu and test the new version. Besides, you can also submit it for review and release it to the App Store, which is the same as the steps shown above.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Step 7: Upgrade
|
||||
### Step 7: Upgrade an application
|
||||
|
||||
After a new version is released to the App Store, all users can upgrade this application to the new version.
|
||||
|
||||
|
|
@ -236,18 +170,12 @@ To follow the steps below, you must deploy an app of one of its old versions fir
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
1. Log in to KubeSphere as `project-regular`, navigate to the **Apps** page of the project, and click the app to be upgraded.
|
||||
1. Log in to KubeSphere as `project-regular`, navigate to the **Apps** page of the project, and click the app to upgrade.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Template** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit Settings** from the drop-down list.
|
||||
|
||||
3. In the window that appears, you can see the YAML file of application configurations. Select the new version from the drop-down list on the right. You can customize the YAML file of the new version. In this tutorial, click **Update** to use the default configurations directly.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can select the same version from the drop-down list on the right as that on the left to customize current application configurations through the YAML file.
|
||||
|
|
@ -256,22 +184,14 @@ To follow the steps below, you must deploy an app of one of its old versions fir
|
|||
|
||||
4. On the **Apps** page, you can see that the app is being upgraded. The status will change to **Running** when the upgrade finishes.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Step 8: Suspend the application
|
||||
### Step 8: Suspend an application
|
||||
|
||||
You can choose to remove an app entirely from the App Store or suspend a specific app version.
|
||||
|
||||
1. Log in to KubeSphere as `reviewer`. Click **Platform** in the top-left corner and select **App Store Management**. On the **App Store** page, click Redis.
|
||||
|
||||

|
||||
1. Log in to KubeSphere as `app-reviewer`. Click **Platform** in the upper-left corner and select **App Store Management**. On the **App Store** page, click Redis.
|
||||
|
||||
2. On the detail page, click **Suspend App** and select **OK** in the dialog to confirm the operation to remove the app from the App Store.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
Removing an app from the App Store does not affect tenants who are using the app.
|
||||
|
|
@ -280,12 +200,8 @@ You can choose to remove an app entirely from the App Store or suspend a specifi
|
|||
|
||||
3. To make the app available in the App Store again, click **Activate App**.
|
||||
|
||||

|
||||
|
||||
4. To suspend a specific app version, expand the version menu and click **Suspend Version**. In the dialog that appears, click **OK** to confirm.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
After an app version is suspended, this version is not available in the App Store. Suspending an app version does not affect tenants who are using this version.
|
||||
|
|
@ -294,8 +210,6 @@ You can choose to remove an app entirely from the App Store or suspend a specifi
|
|||
|
||||
5. To make the app version available in the App Store again, click **Activate Version**.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -13,29 +13,19 @@ This tutorial walks you through an example of deploying etcd from the App Store
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy etcd from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find etcd and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find etcd and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure etcd is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. On the **App Configurations** page, specify the size of the persistent volume for etcd and click **Deploy**.
|
||||
|
||||

|
||||
4. On the **App Settings** page, specify the size of the persistent volume for etcd and click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -43,22 +33,16 @@ This tutorial walks you through an example of deploying etcd from the App Store
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
5. In **App Templates** of the **Apps** page, wait until etcd is up and running.
|
||||
5. In **Template-Based Apps** of the **Apps** page, wait until etcd is up and running.
|
||||
|
||||

|
||||
### Step 2: Access the etcd service
|
||||
|
||||
### Step 2: Access the etcd Service
|
||||
|
||||
After the app is deployed, you can use etcdctl, a command-line tool for interacting with etcd server, to access etcd on the KubeSphere console directly.
|
||||
After the app is deployed, you can use etcdctl, a command-line tool for interacting with the etcd server, to access etcd on the KubeSphere console directly.
|
||||
|
||||
1. Navigate to **StatefulSets** in **Workloads**, and click the service name of etcd.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the terminal, you can read and write data directly. For example, execute the following two commands respectively.
|
||||
|
||||
```bash
|
||||
|
|
@ -69,8 +53,6 @@ After the app is deployed, you can use etcdctl, a command-line tool for interact
|
|||
etcdctl get /name
|
||||
```
|
||||
|
||||

|
||||
|
||||
4. For clients within the KubeSphere cluster, the etcd service can be accessed through `<app name>.<project name>.svc.<K8s domain>:2379` (for example, `etcd-bqe0g4.demo-project.svc.cluster.local:2379` in this guide).
|
||||
|
||||
5. For more information, see [the official documentation of etcd](https://etcd.io/docs/v3.4.0/).
|
||||
|
|
@ -12,27 +12,19 @@ This tutorial walks you through an example of deploying [Harbor](https://goharbo
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Harbor from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find Harbor and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find Harbor and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure Harbor is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. On the **App Configurations** page, edit the configuration file of Harbor. Pay attention to the following fields.
|
||||
4. On the **App Settings** page, edit the configuration file of Harbor. Pay attention to the following fields.
|
||||
|
||||
`type`: The method you use to access the Harbor Service. This example uses `nodePort`.
|
||||
|
||||
|
|
@ -40,8 +32,6 @@ This tutorial walks you through an example of deploying [Harbor](https://goharbo
|
|||
|
||||
`externalURL`: The URL exposed to tenants.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- Don't forget to specify `externalURL`. This field can be very helpful if you have trouble accessing Harbor.
|
||||
|
|
@ -50,12 +40,10 @@ This tutorial walks you through an example of deploying [Harbor](https://goharbo
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
When you finish editing the configuration, click **Deploy** to continue.
|
||||
When you finish editing the configuration, click **Install** to continue.
|
||||
|
||||
5. Wait until Harbor is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access Harbor
|
||||
|
||||
1. Based on the field `expose.type` you set in the configuration file, the access method may be different. As this example uses `nodePort` to access Harbor, visit `http://<NodeIP>:30002` as set in the previous step.
|
||||
|
|
|
|||
|
|
@ -12,43 +12,27 @@ This tutorial walks you through an example of deploying Memcached from the App S
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Memcached from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find Memcached and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find Memcached and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure Memcached is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. In **App Settings**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Install** to continue.
|
||||
|
||||
5. Wait until Memcached is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access Memcached
|
||||
|
||||
1. Navigate to **Services**, and click the service name of Memcached.
|
||||
|
||||

|
||||
|
||||
2. On the detail page, you can find the port number and Pod IP under **Service Ports** and **Pods** respectively.
|
||||
|
||||

|
||||
2. On the detail page, you can find the port number and Pod's IP address under **Ports** and **Pods** respectively.
|
||||
|
||||
3. As the Memcached service is headless, access it inside the cluster through the Pod IP and port number. The basic syntax of Memcached `telnet` command is `telnet HOST PORT`. For example:
|
||||
|
||||
|
|
|
|||
|
|
@ -12,59 +12,35 @@ This tutorial walks you through an example of deploying MinIO from the App Store
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy MinIO from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find MinIO and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find MinIO and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure MinIO is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. In **App Settings**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Install** to continue.
|
||||
|
||||
5. Wait until MinIO is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the MinIO Browser
|
||||
### Step 2: Access the MinIO browser
|
||||
|
||||
To access MinIO outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of MinIO.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit External Access** from the drop-down menu.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
4. On the **Services** page, click **MinIO**. On the page that appears, under **Ports**, you can see the port is exposed.
|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed.
|
||||
|
||||

|
||||
|
||||
5. To access the MinIO browser, you need `accessKey` and `secretKey`, which are specified in the configuration file of MinIO. Go to **App Templates** in **Apps**, click MinIO, and you can find the value of these two fields under the tab **Configuration Files**.
|
||||
|
||||

|
||||
|
||||

|
||||
5. To access the MinIO browser, you need `accessKey` and `secretKey`, which are specified in the configuration file of MinIO. Go to **Template-Based Apps** in **Apps**, click MinIO, and you can find the value of these two fields under the tab **Chart Files**.
|
||||
|
||||
6. Access the MinIO browser through `<NodeIP>:<NodePort>` using `accessKey` and `secretKey`.
|
||||
|
||||
|
|
@ -74,7 +50,7 @@ To access MinIO outside the cluster, you need to expose the app through a NodePo
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,57 +13,41 @@ This tutorial walks you through an example of deploying MongoDB from the App Sto
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy MongoDB from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find MongoDB and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find MongoDB and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure MongoDB is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, specify persistent volumes for the app and record the username and the password which will be used to access the app. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
4. In **App Settings**, specify persistent volumes for the app and record the username and the password which will be used to access the app. When you finish, click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
To specify more values for MongoDB, use the toggle switch to see the app’s manifest in YAML format and edit its configurations.
|
||||
To specify more values for MongoDB, use the toggle switch to see the app's manifest in YAML format and edit its configurations.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Wait until MongoDB is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the MongoDB Terminal
|
||||
|
||||
1. Go to **Services** and click the service name of MongoDB.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the pop-up window, enter commands in the terminal directly to use the app.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you want to access MongoDB outside the cluster, click **More** and select **Edit Internet Access**. In the dialog that appears, select **NodePort** as the access mode. Use the port number to access MongoDB after it is exposed. You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
If you want to access MongoDB outside the cluster, click **More** and select **Edit External Access**. In the dialog that appears, select **NodePort** as the access mode. Use the port number to access MongoDB after it is exposed. You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -6,74 +6,50 @@ description: 'Learn how to deploy MySQL from the App Store of KubeSphere and acc
|
|||
link title: "Deploy MySQL"
|
||||
weight: 14260
|
||||
---
|
||||
[MySQL](https://www.mysql.com/) is an open-source relational database management system (RDBMS), which uses the most commonly used database management language - Structured Query Language (SQL) for database management. It provides a fully managed database service to deploy cloud-native applications using the world’s most popular open-source database.
|
||||
[MySQL](https://www.mysql.com/) is an open-source relational database management system (RDBMS), which uses the most commonly used database management language - Structured Query Language (SQL) for database management. It provides a fully managed database service to deploy cloud-native applications using the world's most popular open-source database.
|
||||
|
||||
This tutorial walks you through an example of deploying MySQL from the App Store of KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy MySQL from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find MySQL and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find MySQL and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure MySQL is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, uncomment the `mysqlRootPassword` field and customize the password. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. In **App Settings**, uncomment the `mysqlRootPassword` field and customize the password. Click **Install** to continue.
|
||||
|
||||
5. Wait until MySQL is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the MySQL Terminal
|
||||
### Step 2: Access the MySQL terminal
|
||||
|
||||
1. Go to **Workloads** and click the workload name of MySQL.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the terminal, execute `mysql -uroot -ptesting` to log in to MySQL as the root user.
|
||||
|
||||

|
||||
|
||||
### Step 3: Access the MySQL Database outside the Cluster
|
||||
### Step 3: Access the MySQL database outside the cluster
|
||||
|
||||
To access MySQL outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of MySQL.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit External Access** from the drop-down list.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed. The port and public IP will be used in the next step to access the MySQL database.
|
||||
|
||||

|
||||
4. Under **Ports**, you can see the port is exposed. The port and public IP address will be used in the next step to access the MySQL database.
|
||||
|
||||
5. To access your MySQL database, you need to use the MySQL client or install a third-party application such as SQLPro Studio for the connection. The following example demonstrates how to access the MySQL database through SQLPro Studio.
|
||||
|
||||
|
|
@ -83,7 +59,7 @@ To access MySQL outside the cluster, you need to expose the app through a NodePo
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,31 +13,19 @@ This tutorial walks you through an example of deploying NGINX from the App Store
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy NGINX from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find NGINX and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find NGINX and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure NGINX is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, specify the number of replicas to deploy for the app and enable Ingress based on your needs. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
|
||||

|
||||
4. In **App Settings**, specify the number of replicas to deploy for the app and enable Ingress based on your needs. When you finish, click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -47,27 +35,17 @@ This tutorial walks you through an example of deploying NGINX from the App Store
|
|||
|
||||
5. Wait until NGINX is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access NGINX
|
||||
|
||||
To access NGINX outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of NGINX.
|
||||
|
||||

|
||||
|
||||
2. On the service detail page, click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. On the service details page, click **More** and select **Edit External Access** from the drop-down list.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed.
|
||||
|
||||

|
||||
4. Under **Ports**, you can see the port is exposed.
|
||||
|
||||
5. Access NGINX through `<NodeIP>:<NodePort>`.
|
||||
|
||||
|
|
@ -75,7 +53,7 @@ To access NGINX outside the cluster, you need to expose the app through a NodePo
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -6,76 +6,54 @@ linkTitle: "Deploy PostgreSQL on KubeSphere"
|
|||
weight: 14280
|
||||
---
|
||||
|
||||
[PostgreSQL](https://www.postgresql.org/) is a powerful, open-source object-relational database system which is famous for reliability, feature robustness, and performance.
|
||||
[PostgreSQL](https://www.postgresql.org/) is a powerful, open-source object-relational database system, which is famous for reliability, feature robustness, and performance.
|
||||
|
||||
This tutorial walks you through an example of how to deploy PostgreSQL from the App Store of KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy PostgreSQL from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find PostgreSQL and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find PostgreSQL and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure PostgreSQL is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, specify persistent volumes for the app and record the username and the password which will be used later to access the app. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
4. In **App Settings**, specify persistent volumes for the app and record the username and the password, which will be used later to access the app. When you finish, click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
To specify more values for PostgreSQL, use the toggle switch to see the app’s manifest in YAML format and edit its configurations.
|
||||
To specify more values for PostgreSQL, use the toggle switch to see the app's manifest in YAML format and edit its configurations.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Wait until PostgreSQL is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the PostgreSQL Database
|
||||
### Step 2: Access the PostgreSQL database
|
||||
|
||||
To access PostgreSQL outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of PostgreSQL.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit External Access** from the drop-down list.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
4. Under **Ports**, you can see the port is exposed, which will be used in the next step to access the PostgreSQL database.
|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed, which will be used in the next step to access the PostgreSQL database.
|
||||
|
||||

|
||||
|
||||
5. Expand the Pod menu under **Pods** and click the Terminal icon. In the pop-up window, enter commands directly to access the database.
|
||||
|
||||

|
||||
5. Expand the Pod menu under **Pods** and click the **Terminal** icon. In the pop-up window, enter commands directly to access the database.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can also use a third-party application such as SQLPro Studio to connect to the database. You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You can also use a third-party application such as SQLPro Studio to connect to the database. You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ This tutorial walks you through an example of how to deploy RabbitMQ from the Ap
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -20,62 +20,41 @@ This tutorial walks you through an example of how to deploy RabbitMQ from the Ap
|
|||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find RabbitMQ and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find RabbitMQ and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure RabbitMQ is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, you can use the default configuration directly or customize the configuration either by specifying fields in a form or editing the YAML file. Record the value of **Root Username** and the value of **Root Password**, which will be used later for login. Click **Deploy** to continue.
|
||||
|
||||

|
||||
|
||||

|
||||
4. In **App Settings**, you can use the default settings directly or customize the settings either by specifying fields in a form or editing the YAML file. Record the value of **Root Username** and the value of **Root Password**, which will be used later for login. Click **Install** to continue.
|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
To see the manifest file, toggle the **YAML** switch.
|
||||
To see the manifest file, toggle the **Edit YAML** switch.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Wait until RabbitMQ is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the RabbitMQ Dashboard
|
||||
### Step 2: Access the RabbitMQ dashboard
|
||||
|
||||
To access RabbitMQ outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of RabbitMQ.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit External Access** from the drop-down list.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
|
||||
4. Under **Service Ports**, you can see ports are exposed.
|
||||
|
||||

|
||||
4. Under **Ports**, you can see ports are exposed.
|
||||
|
||||
5. Access RabbitMQ **management** through `<NodeIP>:<NodePort>`. Note that the username and password are those you set in **Step 1**.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ This tutorial demonstrates how to deploy RadonDB MySQL from the App Store of Kub
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -21,34 +21,20 @@ This tutorial demonstrates how to deploy RadonDB MySQL from the App Store of Kub
|
|||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
|
||||
2. Find RadonDB MySQL and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find RadonDB MySQL and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure RadonDB MySQL is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, you can use the default configuration or customize the configuration by editing the YAML file directly. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
4. In **App Settings**, you can use the default settings or customize the settings by editing the YAML file directly. When you finish, click **Install**.
|
||||
|
||||
5. Wait until RadonDB MySQL is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access RadonDB MySQL
|
||||
|
||||
1. In **Services** under **Application Workloads**, click the Service name of RadonDB MySQL.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the pop-up window, enter commands in the terminal directly to use the app.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ This tutorial demonstrates how to deploy RadonDB PostgreSQL from the App Store o
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -23,49 +23,27 @@ This tutorial demonstrates how to deploy RadonDB PostgreSQL from the App Store o
|
|||
|
||||
2. Click **Database & Cache** under **Categories**.
|
||||
|
||||

|
||||
|
||||
3. Find RadonDB PostgreSQL and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
3. Find RadonDB PostgreSQL and click **Install** on the **App Information** page.
|
||||
|
||||
4. Set a name and select an app version. Make sure RadonDB PostgreSQL is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
5. In **App Configurations**, you can use the default configuration or customize the configuration by editing the YAML file. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
5. In **App Settings**, you can use the default settings or customize the settings by editing the YAML file. When you finish, click **Install**.
|
||||
|
||||
6. Wait until RadonDB PostgreSQL is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: View PostgreSQL Cluster status
|
||||
### Step 2: View PostgreSQL cluster status
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, you can see a list of resource usage in the current project.
|
||||
|
||||

|
||||
|
||||
2. In **Workloads** under **Application Workloads**, click the **StatefulSets** tab and you can see the StatefulSet is up and running.
|
||||
|
||||

|
||||
2. In **Workloads** under **Application Workloads**, click the **StatefulSets** tab, and then you can see the StatefulSet is up and running.
|
||||
|
||||
Click the StatefulSet to go to its detail page. You can see the metrics in line charts over a period of time under the **Monitoring** tab.
|
||||
|
||||

|
||||
|
||||
3. In **Pods** under **Application Workloads**, you can see all the Pods are up and running.
|
||||
|
||||

|
||||
|
||||
4. In **Volumes** under **Storage**, you can see the PostgreSQL Cluster components are using persistent volumes.
|
||||
|
||||

|
||||
|
||||
Volume usage is also monitored. Click a volume item to go to its detail page. Here is an example of one of the data nodes.
|
||||
|
||||

|
||||
Volume usage is also monitored. Click a volume item to go to its detail page.
|
||||
|
||||
### Step 3: Access RadonDB PostgreSQL
|
||||
|
||||
|
|
@ -73,8 +51,6 @@ This tutorial demonstrates how to deploy RadonDB PostgreSQL from the App Store o
|
|||
|
||||
2. On the **Resource Status** page, click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the displayed dialog box, run the following command and enter the user password in the terminal to use the app.
|
||||
|
||||
```bash
|
||||
|
|
|
|||
|
|
@ -13,50 +13,34 @@ This tutorial walks you through an example of deploying Redis from the App Store
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account (`project-regular`) for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Redis from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
|
||||
2. Find Redis and click **Deploy** on the **App Information** page.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Find Redis and click **Install** on the **App Information** page.
|
||||
|
||||
3. Set a name and select an app version. Make sure Redis is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, specify persistent volumes and a password for the app. When you finish, click **Deploy**.
|
||||
|
||||

|
||||
4. In **App Settings**, specify persistent volumes and a password for the app. When you finish, click **Install**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
To specify more values for Redis, use the toggle switch to see the app’s manifest in YAML format and edit its configurations.
|
||||
To specify more values for Redis, use the toggle switch to see the app's manifest in YAML format and edit its settings.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Wait until Redis is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the Redis Terminal
|
||||
### Step 2: Access the Redis terminal
|
||||
|
||||
1. Go to **Services** and click the service name of Redis.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. In the pop-up window, use the `redis-cli` command in the terminal to use the app.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -12,67 +12,43 @@ This tutorial walks you through an example of deploying Tomcat from the App Stor
|
|||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Tomcat from the App Store
|
||||
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top-left corner.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the upper-left corner.
|
||||
|
||||

|
||||
2. Find Tomcat and click **Install** on the **App Information** page.
|
||||
|
||||
2. Find Tomcat and click **Deploy** on the **App Information** page.
|
||||
1. Set a name and select an app version. Make sure Tomcat is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
2. In **App Settings**, you can use the default settings or customize the settings by editing the YAML file directly. Click **Install** to continue.
|
||||
|
||||

|
||||
3. Wait until Tomcat is up and running.
|
||||
|
||||
3. Set a name and select an app version. Make sure Tomcat is deployed in `demo-project` and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. In **App Configurations**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Deploy** to continue.
|
||||
|
||||

|
||||
|
||||
5. Wait until Tomcat is up and running.
|
||||
|
||||

|
||||
|
||||
### Step 2: Access the Tomcat Terminal
|
||||
### Step 2: Access the Tomcat terminal
|
||||
|
||||
1. Go to **Services** and click the service name of Tomcat.
|
||||
|
||||

|
||||
|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||

|
||||
|
||||
3. You can view deployed projects in `/usr/local/tomcat/webapps`.
|
||||
|
||||

|
||||
|
||||
### Step 3: Access a Tomcat Project from Your Browser
|
||||
### Step 3: Access a Tomcat project from your browser
|
||||
|
||||
To access a Tomcat project outside the cluster, you need to expose the app through a NodePort first.
|
||||
|
||||
1. Go to **Services** and click the service name of Tomcat.
|
||||
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
2. Click **More** and select **Edit External Access** from the drop-down list.
|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||

|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed.
|
||||
|
||||

|
||||
4. Under **Ports**, you can see the port is exposed.
|
||||
|
||||
5. Access the sample Tomcat project through `<NodeIP>:<NodePort>/sample` in your browser.
|
||||
|
||||
|
|
@ -80,7 +56,7 @@ To access a Tomcat project outside the cluster, you need to expose the app throu
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,17 +13,17 @@ This tutorial demonstrates how to deploy ClickHouse Operator and a ClickHouse Cl
|
|||
## Prerequisites
|
||||
|
||||
- You need to enable [the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. This tutorial uses `demo-workspace` and `demo-project` for demonstration. If they are not ready, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. This tutorial uses `demo-workspace` and `demo-project` for demonstration. If they are not ready, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to enable the gateway in your project to provide external access. If they are not ready, refer to [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy ClickHouse Operator
|
||||
|
||||
1. Log in to the KubeSphere Web console as `admin`, and use **Kubectl** from the **Toolbox** in the bottom-right corner to run the following command to install ClickHouse Operator. It is recommended that you have at least two worker nodes available in your cluster.
|
||||
1. Log in to the KubeSphere Web console as `admin`, and use **Kubectl** from the **Toolbox** in the lower-right corner to run the following command to install ClickHouse Operator. It is recommended that you have at least two worker nodes available in your cluster.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://raw.githubusercontent.com/radondb/radondb-clickhouse-kubernetes/master/clickhouse-operator-install.yml
|
||||
$ kubectl apply -f https://raw.githubusercontent.com/radondb/radondb-clickhouse-kubernetes/master/clickhouse-operator-install.yml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
|
@ -34,11 +34,13 @@ This tutorial demonstrates how to deploy ClickHouse Operator and a ClickHouse Cl
|
|||
|
||||
2. You can see the expected output as below if the installation is successful.
|
||||
|
||||
```
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallations.clickhouse.qingcloud.com created
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallationtemplates.clickhouse.qingcloud.com created
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseoperatorconfigurations.clickhouse.qingcloud.com created
|
||||
```powershell
|
||||
$ kubectl apply -f https://raw.githubusercontent.com/radondb/radondb-clickhouse-kubernetes/main/clickhouse-operator-install.yml
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallations.clickhouse.radondb.com created
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallationtemplates.clickhouse.radondb.com created
|
||||
customresourcedefinition.apiextensions.k8s.io/clickhouseoperatorconfigurations.clickhouse.radondb.com created
|
||||
serviceaccount/clickhouse-operator created
|
||||
clusterrole.rbac.authorization.k8s.io/clickhouse-operator-kube-system created
|
||||
clusterrolebinding.rbac.authorization.k8s.io/clickhouse-operator-kube-system created
|
||||
configmap/etc-clickhouse-operator-files created
|
||||
configmap/etc-clickhouse-operator-confd-files created
|
||||
|
|
@ -52,7 +54,7 @@ This tutorial demonstrates how to deploy ClickHouse Operator and a ClickHouse Cl
|
|||
3. You can run the following command to view the status of ClickHouse Operator resources.
|
||||
|
||||
```bash
|
||||
kubectl get all --selector=app=clickhouse-operator -n kube-system
|
||||
$ kubectl get all --selector=app=clickhouse-operator -n kube-system
|
||||
```
|
||||
|
||||
Expected output:
|
||||
|
|
@ -75,80 +77,48 @@ This tutorial demonstrates how to deploy ClickHouse Operator and a ClickHouse Cl
|
|||
|
||||
1. Log out of KubeSphere and log back in as `ws-admin`. In `demo-workspace`, go to **App Repositories** under **App Management**, and then click **Add**.
|
||||
|
||||

|
||||
2. In the dialog that appears, enter `clickhouse` for the app repository name and `https://radondb.github.io/radondb-clickhouse-kubernetes/` for the repository URL. Click **Validate** to verify the URL, and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||
2. In the dialog that appears, enter `clickhouse` for the app repository name and `https://radondb.github.io/radondb-clickhouse-kubernetes/` for the repository URL. Click **Validate** to verify the URL and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||

|
||||
|
||||
3. Your repository displays in the list after successfully imported to KubeSphere.
|
||||
|
||||

|
||||
3. Your repository will display in the list after it is successfully imported to KubeSphere.
|
||||
|
||||
### Step 3: Deploy a ClickHouse Cluster
|
||||
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In `demo-project`, go to **Apps** under **Application Workloads** and click **Deploy New App**.
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In `demo-project`, go to **Apps** under **Application Workloads** and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, select **From App Templates**.
|
||||
|
||||

|
||||
2. In the dialog that appears, select **From App Template**.
|
||||
|
||||
3. On the new page that appears, select **clickhouse** from the drop-down list and then click **clickhouse-cluster**.
|
||||
|
||||

|
||||
|
||||
4. On the **Chart Files** tab, you can view the configuration and download the `values.yaml` file. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. On the **Chart Files** tab, you can view the configuration and download the `values.yaml` file. Click **Install** to continue.
|
||||
|
||||
5. On the **Basic Information** page, confirm the app name, app version, and deployment location. Click **Next** to continue.
|
||||
|
||||

|
||||
6. On the **App Settings** tab, you can change the YAML file to customize settings. In this tutorial, click **Install** to use the default settings.
|
||||
|
||||
6. On the **App Configurations** tab, you can change the YAML file to customize configurations. In this tutorial, click **Deploy** to use the default configurations.
|
||||
7. After a while, you can see the app is in the **Running** status.
|
||||
|
||||

|
||||
### Step 4: View ClickHouse cluster status
|
||||
|
||||
7. After a while, you can see the app status shown as **Running**.
|
||||
1. In **Workloads** under **Application Workloads**, click the **StatefulSets** tab, and you can see the StatefulSets are up and running.
|
||||
|
||||

|
||||
|
||||
### Step 4: View ClickHouse Cluster status
|
||||
|
||||
1. In **Workloads** under **Application Workloads**, click the **StatefulSets** tab and you can see the StatefulSets are up and running.
|
||||
|
||||

|
||||
|
||||
3. Click a single StatefulSet to go to its detail page. You can see the metrics in line charts over a period of time under the **Monitoring** tab.
|
||||
|
||||

|
||||
2. Click a single StatefulSet to go to its detail page. You can see the metrics in line charts over a period of time under the **Monitoring** tab.
|
||||
|
||||
3. In **Pods** under **Application Workloads**, you can see all the Pods are up and running.
|
||||
|
||||

|
||||
|
||||
4. In **Volumes** under **Storage**, you can see the ClickHouse Cluster components are using persistent volumes.
|
||||
|
||||

|
||||
|
||||
5. Volume usage is also monitored. Click a volume item to go to its detail page. Here is an example of one of the data nodes.
|
||||
|
||||

|
||||
5. Volume usage is also monitored. Click a volume item to go to its detail page.
|
||||
|
||||
6. On the **Overview** page of the project, you can see a list of resource usage in the current project.
|
||||
|
||||

|
||||
### Step 5: Access the ClickHouse cluster
|
||||
|
||||
### Step 5: Access the ClickHouse Cluster
|
||||
|
||||
1. Log out of KubeSphere and log back in as `admin`. Hover your cursor over the hammer icon in the bottom-right corner and then select **Kubectl**.
|
||||
1. Log out of KubeSphere and log back in as `admin`. Hover your cursor over the hammer icon in the lower-right corner, and then select **Kubectl**.
|
||||
|
||||
2. In the window that appears, run the following command and then navigate to the username and password of the ClickHouse cluster.
|
||||
|
||||
```bash
|
||||
kubectl edit chi clickho-749j8s -n demo-project
|
||||
$ kubectl edit chi clickho-749j8s -n demo-project
|
||||
```
|
||||
|
||||

|
||||
|
|
@ -162,14 +132,13 @@ This tutorial demonstrates how to deploy ClickHouse Operator and a ClickHouse Cl
|
|||
3. Run the following command to access the ClickHouse cluster, and then you can use command like `show databases` to interact with it.
|
||||
|
||||
```bash
|
||||
kubectl exec -it chi-clickho-749j8s-all-nodes-0-0-0 -n demo-project -- clickhouse-client --user=clickhouse --password=c1ickh0use0perator
|
||||
$ kubectl exec -it chi-clickho-749j8s-all-nodes-0-0-0 -n demo-project -- clickhouse-client --user=clickhouse --password=c1ickh0use0perator
|
||||
```
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
In the above command, `chi-clickho-749j8s-all-nodes-0-0-0` is the Pod name and you can find it in **Pods** under **Application Workloads**. Make sure you use your own Pod name, project name, username and password.
|
||||
In the above command, `chi-clickho-749j8s-all-nodes-0-0-0` is the Pod name and you can find it in **Pods** under **Application Workloads**. Make sure you use your own Pod name, project name, username, and password.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
## Prerequisites
|
||||
|
||||
- You need to enable [the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and two accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and two accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -21,39 +21,23 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
|
||||
1. Log in to KubeSphere as `ws-admin`. In your workspace, go to **App Repositories** under **App Management**, and then click **Add**.
|
||||
|
||||

|
||||
|
||||
2. In the displayed dialog box, enter `main` for the app repository name and `https://charts.kubesphere.io/main` for the app repository URL. Click **Validate** to verify the URL and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||

|
||||
|
||||
3. The repository is displayed in the list after successfully imported to KubeSphere.
|
||||
|
||||

|
||||
3. The repository displays in the list after it is successfully imported to KubeSphere.
|
||||
|
||||
### Step 2: Deploy GitLab
|
||||
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Deploy New App**.
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. In the displayed dialog box, select **From App Templates**.
|
||||
|
||||

|
||||
2. In the dialog box that appears, select **From App Template**.
|
||||
|
||||
3. Select `main` from the drop-down list, then click **gitlab**.
|
||||
|
||||

|
||||
|
||||
4. On the **App Information** tab and the **Chart Files** tab, you can view the default configuration from the console. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. On the **App Information** tab and the **Chart Files** tab, you can view the default settings on the console. Click **Install** to continue.
|
||||
|
||||
5. On the **Basic Information** page, you can view the app name, app version, and deployment location. This tutorial uses the version `4.2.3 [13.2.2]`. Click **Next** to continue.
|
||||
|
||||

|
||||
|
||||
6. On the **App Configurations** page, use the following configurations to replace the default configurations, and then click **Deploy**.
|
||||
6. On the **App Settings** page, use the following settings to replace the default ones, and then click **Install**.
|
||||
|
||||
```yaml
|
||||
global:
|
||||
|
|
@ -66,8 +50,6 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
helmTests:
|
||||
enabled: false
|
||||
```
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -77,14 +59,8 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
|
||||
7. Wait for GitLab to be up and running.
|
||||
|
||||

|
||||
|
||||
8. Go to **Workloads**, and you can see all the Deployments and StatefulSets created for GitLab.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
It may take a while before all the Deployments and StatefulSets are up and running.
|
||||
|
|
@ -93,25 +69,21 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
|
||||
### Step 3: Get the root user's password
|
||||
|
||||
1. Go to **Secrets** under **Configurations**, enter `gitlab-initial-root-password` in the search box, and then press **Enter** on your keyboard to search the Secret.
|
||||
|
||||

|
||||
1. Go to **Secrets** under **Configuration**, enter `gitlab-initial-root-password` in the search box, and then press **Enter** on your keyboard to search the Secret.
|
||||
|
||||
2. Click the Secret to go to its detail page, and then click <img src="/images/docs/appstore/external-apps/deploy-gitlab/eye-icon.png" width="20px" /> in the upper-right corner to view the password. Make sure you copy it.
|
||||
|
||||

|
||||
|
||||
### Step 4: Edit the hosts file
|
||||
|
||||
1. Find the hosts file on your local machine.
|
||||
1. Find the `hosts` file on your local machine.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The path of hosts file is `/etc/hosts` for Linux, or `c:\windows\system32\drivers\etc\hosts` for Windows.
|
||||
The path of the `hosts` file is `/etc/hosts` for Linux, or `c:\windows\system32\drivers\etc\hosts` for Windows.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
2. Add the following item into the hosts file.
|
||||
2. Add the following item into the `hosts` file.
|
||||
|
||||
```
|
||||
192.168.4.3 gitlab.demo-project.svc.cluster.local
|
||||
|
|
@ -126,9 +98,7 @@ This tutorial demonstrates how to deploy GitLab on KubeSphere.
|
|||
|
||||
### Step 5: Access GitLab
|
||||
|
||||
1. Go to **Services** under **Application Workloads**, enter `nginx-ingress-controller` in the search box, and then press **Enter** on your keyboard to search the Service. You can see the Service is being exposed through port `31246`, which you can use to access GitLab.
|
||||
|
||||

|
||||
1. Go to **Services** under **Application Workloads**, enter `nginx-ingress-controller` in the search box, and then press **Enter** on your keyboard to search the Service. You can see the Service has been exposed through port `31246`, which you can use to access GitLab.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -26,41 +26,36 @@ This tutorial demonstrates how to deploy Litmus on KubeSphere and create chaos e
|
|||
|
||||
2. In the dialog that appears, set a name for the repository (for example, `litmus`) and enter the URL `https://litmuschaos.github.io/litmus-helm/`. Click **Validate** to verify the URL. You will see <img src="/images/docs/zh-cn/appstore/external-apps/deploy-litmus/checkmark.png" width="20" /> icon if the URL is available. Click **OK** to continue.
|
||||
|
||||
3. The app repository will be displayed in the list after it is successfully imported.
|
||||
3. The app repository displays in the list after it is successfully imported.
|
||||
|
||||

|
||||
### Step 2: Deploy the Litmus portal
|
||||
1. Log out of the KubeSphere console and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads**, and then click **Create**.
|
||||
|
||||
### Step 2: Deploy Litmus Portal
|
||||
1. Log out of the KubeSphere console and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads**, and then click **Deploy New App**.
|
||||
2. In the dialog that appears, choose **From App Template**.
|
||||
|
||||
2. In the dialog that appears, choose **From App Templates**.
|
||||
- **From App Store**: Select apps from the official APP Store of Kubephere.
|
||||
|
||||
- **From App Store**: select apps from the official APP Store of Kubephere.
|
||||
|
||||
- **From App Templates**: select apps from workspace app templates and the third-party Helm app templates of App Repository.
|
||||
- **From App Template**: Select apps from workspace app templates and the third-party Helm app templates of App Repository.
|
||||
|
||||
3. In the drop-down list, choose `litmus`, and then choose `litmus-2-0-0-beta`.
|
||||
|
||||
4. You can view the app information and chart files. Under **Versions**, select a specific version and click **Deploy**.
|
||||
4. You can view the app information and chart files. Under **Versions**, select a specific version and click **Install**.
|
||||
|
||||
5. Under **Basic Information**, set a name for the app. Check the app version and the deployment location, and then click **Next**.
|
||||
|
||||
6. Under **App Configurations**, you can edit the yaml file or directly click **Deploy**.
|
||||
6. Under **App Settings**, you can edit the yaml file or directly click **Install**.
|
||||
|
||||
7. The app will be displayed in the list after you create it.
|
||||
|
||||

|
||||
7. The app displays in the list after you create it successfully.
|
||||
|
||||
{{< notice note>}}
|
||||
|
||||
It make take a while before Litmus is running. Please wait for the deployment to finish.
|
||||
It may take a while before Litmus is running. Please wait for the deployment to finish.
|
||||
|
||||
{{</ notice>}}
|
||||
|
||||
### Step 3: Access Litmus Portal
|
||||
### Step 3: Access Litmus portal
|
||||
|
||||
1. Go to **Services** under **Application Workloads**, copy the `NodePort` of `litmusportal-frontend-service`.
|
||||

|
||||
|
||||
2. You can access Litmus `Portal` through `${NodeIP}:${NODEPORT}` using the default username and password (`admin`/`litmus`).
|
||||
|
||||
|
|
@ -69,8 +64,8 @@ This tutorial demonstrates how to deploy Litmus on KubeSphere and create chaos e
|
|||

|
||||
|
||||
{{< notice note >}}
|
||||
You may need to open the port in your security groups and configure port forwarding rules depending on where your Kubernetes cluster is deployed. Make sure you use your own `NodeIP`.
|
||||
{{</ notice >}}
|
||||
You may need to open the port in your security groups and configure port forwarding rules depending on where your Kubernetes cluster is deployed. Make sure you use your own `NodeIP`.
|
||||
{{</ notice >}}
|
||||
|
||||
### Step 4: Deploy Agent (optional)
|
||||
|
||||
|
|
@ -90,7 +85,7 @@ For details about how to deploy External Agent, see [Litmus Docs](https://litmus
|
|||
$ kubectl create deployment nginx --image=nginx --replicas=2 --namespace=default
|
||||
```
|
||||
|
||||
2. Log in to Litmus `Portal`, and then click **Schedule a workflow**.
|
||||
2. Log in to Litmus `Portal`, and then click **Schedule workflow**.
|
||||
|
||||
3. Choose an `Agent` (for example, `Self-Agent`), and then click **Next**.
|
||||
|
||||
|
|
@ -110,8 +105,6 @@ For details about how to deploy External Agent, see [Litmus Docs](https://litmus
|
|||
|
||||
On the KubeSphere console, you can see that a Pod is being deleted and recreated.
|
||||
|
||||

|
||||
|
||||
On the Litmus `Portal`, you can see that the experiment is successful.
|
||||
|
||||

|
||||
|
|
@ -123,22 +116,16 @@ For details about how to deploy External Agent, see [Litmus Docs](https://litmus
|
|||
|
||||
- **Experiment 2**
|
||||
|
||||
1. Perform step 1 to 10 in **Experiment 1** to create a new chaos experiment (`pod-cpu-hog`).
|
||||
1. Perform steps 1 to 10 in **Experiment 1** to create a new chaos experiment (`pod-cpu-hog`).
|
||||
|
||||
|
||||
2. On the KubeSphere console, you can see that the pod CPU usage is close to 1 core.
|
||||
|
||||

|
||||
|
||||
- **Experiment 3**
|
||||
|
||||
1. Set the `nginx` replica to `1`. You can see there is only one pod left and view the Pod IP address.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
2. Perform step 1 to 10 in **Experiment 1** to create a new chaos experiment (`pod-network-loss`).
|
||||
2. Perform steps 1 to 10 in **Experiment 1** to create a new chaos experiment (`pod-network-loss`).
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ This tutorial demonstrates how to deploy MeterSphere on KubeSphere.
|
|||
## Prerequisites
|
||||
|
||||
- You need to enable [the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -21,51 +21,27 @@ This tutorial demonstrates how to deploy MeterSphere on KubeSphere.
|
|||
|
||||
1. Log in to KubeSphere as `ws-admin`. In your workspace, go to **App Repositories** under **App Management**, and then click **Add**.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, enter `metersphere` for the app repository name and `https://charts.kubesphere.io/test` for the MeterSphere repository URL. Click **Validate** to verify the URL and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||

|
||||
|
||||
3. Your repository displays in the list after successfully imported to KubeSphere.
|
||||
|
||||

|
||||
3. Your repository displays in the list after it is successfully imported to KubeSphere.
|
||||
|
||||
### Step 2: Deploy MeterSphere
|
||||
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Deploy New App**.
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, select **From App Templates**.
|
||||
|
||||

|
||||
2. In the dialog that appears, select **From App Template**.
|
||||
|
||||
3. Select `metersphere` from the drop-down list, then click **metersphere-chart**.
|
||||
|
||||

|
||||
|
||||
4. On the **App Information** tab and the **Chart Files** tab, you can view the default configuration from the console. Click **Deploy** to continue.
|
||||
|
||||

|
||||
4. On the **App Information** tab and the **Chart Files** tab, you can view the default configuration from the console. Click **Install** to continue.
|
||||
|
||||
5. On the **Basic Information** page, you can view the app name, app version, and deployment location. Click **Next** to continue.
|
||||
|
||||

|
||||
|
||||
6. On the **App Configurations** page, change the value of `imageTag` from `master` to `v1.6`, and then click **Deploy**.
|
||||
|
||||

|
||||
6. On the **App Settings** page, change the value of `imageTag` from `master` to `v1.6`, and then click **Install**.
|
||||
|
||||
7. Wait for MeterSphere to be up and running.
|
||||
|
||||

|
||||
|
||||
8. Go to **Workloads**, and you can see two Deployments and three StatefulSets created for MeterSphere.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -77,8 +53,6 @@ This tutorial demonstrates how to deploy MeterSphere on KubeSphere.
|
|||
|
||||
1. Go to **Services** under **Application Workloads**, and you can see the MeterSphere Service and its type is set to `NodePort` by default.
|
||||
|
||||

|
||||
|
||||
2. You can access MeterSphere through `<NodeIP>:<NodePort>` using the default account and password (`admin/metersphere`).
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ This tutorial demonstrates how to deploy TiDB Operator and a TiDB Cluster on Kub
|
|||
|
||||
- You need to have at least 3 schedulable nodes.
|
||||
- You need to enable [the OpenPitrix system](../../../pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a project, and two user accounts (`ws-admin` and `project-regular`) for this tutorial. The account `ws-admin` must be granted the role of `workspace-admin` in the workspace, and the account `project-regular` must be invited to the project with the role of `operator`. If they are not ready, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -42,78 +42,46 @@ This tutorial demonstrates how to deploy TiDB Operator and a TiDB Cluster on Kub
|
|||
|
||||
1. Log out of KubeSphere and log back in as `ws-admin`. In your workspace, go to **App Repositories** under **App Management**, and then click **Add**.
|
||||
|
||||

|
||||
2. In the displayed dialog box, enter `pingcap` for the app repository name and `https://charts.pingcap.org` for the PingCAP Helm repository URL. Click **Validate** to verify the URL, and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||
2. In the dialog that appears, enter `pingcap` for the app repository name and `https://charts.pingcap.org` for the PingCAP Helm repository URL. Click **Validate** to verify the URL and you will see a green check mark next to the URL if it is available. Click **OK** to continue.
|
||||
|
||||

|
||||
|
||||
3. Your repository displays in the list after successfully imported to KubeSphere.
|
||||
|
||||

|
||||
3. Your repository displays in the list after it is successfully imported to KubeSphere.
|
||||
|
||||
### Step 3: Deploy TiDB Operator
|
||||
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Deploy New App**.
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. In your project, go to **Apps** under **Application Workloads** and click **Create**.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, select **From App Templates**.
|
||||
|
||||

|
||||
2. In the displayed dialog box, select **From App Template**.
|
||||
|
||||
3. Select `pingcap` from the drop-down list, then click **tidb-operator**.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
This tutorial only demonstrates how to deploy TiDB Operator and a TiDB cluster. You can also deploy other tools based on your needs.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. On the **Chart Files** tab, you can view the configuration from the console directly or download the default `values.yaml` file by clicking the icon in the upper-right corner. Under **Versions**, select a version number from the drop-down list and click **Deploy**.
|
||||
|
||||

|
||||
4. On the **Chart Files** tab, you can view the configuration on the console directly or download the default `values.yaml` file by clicking the icon in the upper-right corner. Under **Versions**, select a version number from the drop-down list and click **Install**.
|
||||
|
||||
5. On the **Basic Information** page, confirm the app name, app version, and deployment location. Click **Next** to continue.
|
||||
|
||||

|
||||
|
||||
6. On the **App Configurations** page, you can either edit the `values.yaml` file, or click **Deploy** directly with the default configurations.
|
||||
|
||||

|
||||
6. On the **App Settings** page, you can either edit the `values.yaml` file, or click **Install** directly with the default configurations.
|
||||
|
||||
7. Wait for TiDB Operator to be up and running.
|
||||
|
||||

|
||||
|
||||
8. Go to **Workloads**, and you can see two Deployments created for TiDB Operator.
|
||||
|
||||

|
||||
|
||||
### Step 4: Deploy a TiDB cluster
|
||||
|
||||
The process of deploying a TiDB cluster is similar to deploying TiDB Operator.
|
||||
|
||||
1. Go to **Apps** under **Application Workloads**, click **Deploy New App**, and then select **From App Templates**.
|
||||
|
||||

|
||||
|
||||

|
||||
1. Go to **Apps** under **Application Workloads**, click **Create**, and then select **From App Template**.
|
||||
|
||||
2. From the PingCAP repository, click **tidb-cluster**.
|
||||
|
||||

|
||||
|
||||
3. On the **Chart Files** tab, you can view the configuration and download the `values.yaml` file. Click **Deploy** to continue.
|
||||
|
||||

|
||||
3. On the **Chart Files** tab, you can view the configuration and download the `values.yaml` file. Click **Install** to continue.
|
||||
|
||||
4. On the **Basic Information** page, confirm the app name, app version, and deployment location. Click **Next** to continue.
|
||||
|
||||

|
||||
|
||||
5. Some TiDB components require [persistent volumes](../../../cluster-administration/persistent-volume-and-storage-class/). You can run the following command to view your storage classes.
|
||||
|
||||
```
|
||||
|
|
@ -126,9 +94,7 @@ The process of deploying a TiDB cluster is similar to deploying TiDB Operator.
|
|||
csi-super-high-perf csi-qingcloud Delete Immediate true 71m
|
||||
```
|
||||
|
||||
6. On the **App Configurations** page, change all the default values of the field `storageClassName` from `local-storage` to the name of your storage class. For example, you can change them to `csi-standard` based on the above output.
|
||||
|
||||

|
||||
6. On the **App Settings** page, change all the default values of the field `storageClassName` from `local-storage` to the name of your storage class. For example, you can change them to `csi-standard` based on the above output.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -136,20 +102,14 @@ The process of deploying a TiDB cluster is similar to deploying TiDB Operator.
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
7. Click **Deploy** and you can see two apps in the list as shown below:
|
||||
|
||||

|
||||
7. Click **Install**, and you can see two apps in the list.
|
||||
|
||||
### Step 5: View TiDB cluster status
|
||||
|
||||
1. Go to **Workloads** under **Application Workloads**, and verify that all TiDB cluster Deployments are up and running.
|
||||
|
||||

|
||||
|
||||
2. Switch to the **StatefulSets** tab, and you can see TiDB, TiKV and PD are up and running.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
TiKV and TiDB will be created automatically and it may take a while before they display in the list.
|
||||
|
|
@ -158,43 +118,19 @@ The process of deploying a TiDB cluster is similar to deploying TiDB Operator.
|
|||
|
||||
3. Click a single StatefulSet to go to its detail page. You can see the metrics in line charts over a period of time under the **Monitoring** tab.
|
||||
|
||||
TiDB metrics:
|
||||
|
||||

|
||||
|
||||
TiKV metrics:
|
||||
|
||||

|
||||
|
||||
PD metrics:
|
||||
|
||||

|
||||
|
||||
4. In **Pods** under **Application Workloads**, you can see the TiDB cluster contains two TiDB Pods, three TiKV Pods, and three PD Pods.
|
||||
|
||||

|
||||
|
||||
5. In **Volumes** under **Storage**, you can see TiKV and PD are using persistent volumes.
|
||||
|
||||

|
||||
|
||||
6. Volume usage is also monitored. Click a volume item to go to its detail page. Here is an example of TiKV:
|
||||
|
||||

|
||||
6. Volume usage is also monitored. Click a volume item to go to its detail page.
|
||||
|
||||
7. On the **Overview** page of the project, you can see a list of resource usage in the current project.
|
||||
|
||||

|
||||
|
||||
### Step 6: Access the TiDB cluster
|
||||
|
||||
1. Go to **Services** under **Application Workloads**, and you can see detailed information of all Services. As the Service type is set to `NodePort` by default, you can access it through the Node IP address outside the cluster.
|
||||
|
||||

|
||||
|
||||
3. TiDB integrates Prometheus and Grafana to monitor performance of the database cluster. For example, you can access Grafana through `<NodeIP>:<NodePort>` to view metrics.
|
||||
|
||||

|
||||
2. TiDB integrates Prometheus and Grafana to monitor performance of the database cluster. For example, you can access Grafana through `<NodeIP>:<NodePort>` to view metrics.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -11,32 +11,20 @@ In addition to monitoring data at the physical resource level, cluster administr
|
|||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
You need a user granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to a user.
|
||||
|
||||
## Resource Usage
|
||||
|
||||
1. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
|
||||

|
||||
1. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management/) with member clusters imported, you can select a specific cluster to view its application resources. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||

|
||||
3. Choose **Application Resources** under **Monitoring & Alerting** to see the overview of application resources, including the summary of the usage of all resources in the cluster.
|
||||
|
||||
3. Choose **Application Resources** under **Monitoring & Alerting** to see the overview of application resource monitoring, including the summary of the usage of all resources in the cluster, as shown in the following figure.
|
||||
4. Among them, **Cluster Resource Usage** and **Application Resource Usage** retain the monitoring data of the last 7 days and support custom time range queries.
|
||||
|
||||

|
||||
|
||||
4. Among them, **Cluster Resources Usage** and **Application Resources Usage** retain the monitoring data of the last 7 days and support custom time range queries.
|
||||
|
||||

|
||||
|
||||
5. Click a specific resource to view detailed usage and trends of it during a certain time period, such as **CPU** under **Cluster Resources Usage**. The detail page allows you to view specific monitoring data by project. The highly-interactive dashboard enables users to customize the time range, displaying the exact resource usage at a given time point.
|
||||
|
||||

|
||||
5. Click a specific resource to view detailed usage and trends of it during a certain time period, such as **CPU** under **Cluster Resource Usage**. The detail page allows you to view specific monitoring data by project. The highly-interactive dashboard enables users to customize the time range, displaying the exact resource usage at a given time point.
|
||||
|
||||
## Usage Ranking
|
||||
|
||||
**Usage Ranking** supports the sorting of project resource usage, so that platform administrators can understand the resource usage of each project in the current cluster, including **CPU Usage**, **Memory Usage**, **Pod Count**, as well as **Outbound Traffic** and **Inbound Traffic**. You can sort projects in ascending or descending order by one of the indicators in the drop-down list. This feature is very useful for quickly locating your application (Pod) that is consuming heavy CPU or memory.
|
||||
|
||||

|
||||
**Usage Ranking** supports the sorting of project resource usage, so that platform administrators can understand the resource usage of each project in the current cluster, including **CPU usage**, **memory usage**, **Pod count**, **inbound traffic** and **outbound traffic**. You can sort projects in ascending or descending order by one of the indicators in the drop-down list. This feature is very useful for quickly locating your application (Pod) that is consuming heavy CPU or memory.
|
||||
|
|
|
|||
|
|
@ -0,0 +1,82 @@
|
|||
---
|
||||
title: "Cluster Gateway"
|
||||
keywords: 'KubeSphere, Kubernetes, Cluster, Gateway, NodePort, LoadBalancer'
|
||||
description: 'Learn how to create a cluster-scope gateway on KubeSphere.'
|
||||
linkTitle: "Cluster Gateway"
|
||||
weight: 8630
|
||||
---
|
||||
|
||||
KubeSphere 3.2.x provides cluster-scope gateways to let all projects share a global gateway. This document describes how to set a cluster gateway on KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need to prepare a user with the `platform-admin` role, for example, `admin`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Create a Cluster Gateway
|
||||
|
||||
1. Log in to the KubeSphere web console as `admin`. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. Go to **Gateway Settings** under **Cluster Settings** from the navigation pane, select the **Cluster Gateway** tab, and click **Enable Gateway**.
|
||||
|
||||
3. In the displayed dialog box, select an access mode for the gateway from the following two options:
|
||||
|
||||
- **NodePort**: Access Services with corresponding node ports through the gateway. The NodePort access mode provides the following configurations:
|
||||
- **Tracing**: Turn on the **Tracing** toggle to enable the Tracing feature on KubeSphere. Once it is enabled, check whether an annotation (`nginx.ingress.kubernetes.io/service-upstream: true`) is added for your route when the route is inaccessible. If not, add an annotation to your route.
|
||||
- **Configuration Options**: Add key-value pairs to the cluster gateway.
|
||||
- **LoadBalancer**: Access Services with a single IP address through the gateway. The LoadBalancer access mode provides the following configurations:
|
||||
- **Tracing**: Turn on the **Tracing** toggle to enable the Tracing feature on KubeSphere. Once it is enabled, check whether an annotation (`nginx.ingress.kubernetes.io/service-upstream: true`) is added for your route when the route is inaccessible. If not, add an annotation to your route.
|
||||
- **Load Balancer Provider**: Select a load balancer provider from the drop-down list.
|
||||
- **Annotations**: Add annotations to the cluster gateway.
|
||||
- **Configuration Options**: Add key-value pairs to the cluster gateway.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
- To use the Tracing feature, turn on **Application Governance** when you create composed applications.
|
||||
- For more information about how to use configuration options, see [Configuration options](https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#configuration-options).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. Click **OK** to create the cluster gateway.
|
||||
|
||||
5. The cluster gateway created is displayed and the basic information of the gateway is also shown on the page.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
A gateway named `kubesphere-router-kubesphere-system` is also created, which serves as a global gateway for all projects in your cluster.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. Click **Manage** to select an operation from the drop-down menu:
|
||||
|
||||
- **View Details**: Go to the details page of the cluster gateway.
|
||||
- **Edit**: Edit configurations of the cluster gateway.
|
||||
- **Disable**: Disable the cluster gateway.
|
||||
|
||||
7. After a cluster gateway is created, see [Routes](../../../project-user-guide/application-workloads/routes/#create-a-route) for more information about how to create a route.
|
||||
|
||||
## Cluster Gateway Details Page
|
||||
|
||||
1. Under the **Cluster Gateway** tab, click **Manage** on the right of a cluster gateway and select **View Details** to open its details page.
|
||||
2. On the details page, click **Edit** to edit configurations of the cluster gateway or click **More** to select an operation.
|
||||
3. Click the **Monitoring** tab to view the monitoring metrics of the cluster gateway.
|
||||
4. Click the **Configuration Options** tab to view configuration options of the cluster gateway.
|
||||
5. Click the **Gateway Logs** tab to view logs of the cluster gateway.
|
||||
6. Click the **Resource Status** tab to view workload status of the cluster gateway. Click <img src="/images/docs/common-icons/replica-plus-icon.png" width="15" /> or <img src="/images/docs/common-icons/replica-minus-icon.png" width="15" /> to scale up or scale down the number of replicas.
|
||||
7. Click the **Metadata** tab to view annotations of the cluster gateway.
|
||||
|
||||
## View Project Gateways
|
||||
|
||||
On the **Gateway Settings** page, click the **Project Gateway** tab to view project gateways.
|
||||
|
||||
Click <img src="/images/docs/project-administration/role-and-member-management/three-dots.png" width="20px"> on the right of a project gateway to select an operation from the drop-down menu:
|
||||
|
||||
- **Edit**: Edit configurations of the project gateway.
|
||||
- **Disable**: Disable the project gateway.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If a project gateway exists prior to the creation of a cluster gateway, the project gateway address may switch between the address of the cluster gateway and that of the project gateway. It is recommended that you should use either the cluster gateway or project gateway.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
For more information about how to create project gateways, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
|
@ -12,28 +12,22 @@ This guide demonstrates how to set cluster visibility.
|
|||
|
||||
## Prerequisites
|
||||
* You need to enable the [multi-cluster feature](../../../multicluster-management/).
|
||||
* You need to have a workspace and an account that has the permission to create workspaces, such as `ws-manager`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
* You need to have a workspace and a user that has the permission to create workspaces, such as `ws-manager`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Set Cluster Visibility
|
||||
|
||||
### Select available clusters when you create a workspace
|
||||
|
||||
1. Log in to KubeSphere with an account that has the permission to create a workspace, such as `ws-manager`.
|
||||
1. Log in to KubeSphere with a user that has the permission to create a workspace, such as `ws-manager`.
|
||||
|
||||
2. Click **Platform** in the top-left corner and select **Access Control**. In **Workspaces** from the navigation bar, click **Create**.
|
||||
|
||||

|
||||
2. Click **Platform** in the upper-left corner and select **Access Control**. In **Workspaces** from the navigation bar, click **Create**.
|
||||
|
||||
3. Provide the basic information for the workspace and click **Next**.
|
||||
|
||||
4. On the **Select Clusters** page, you can see a list of available clusters. Check the cluster that you want to allocate to the workspace and click **Create**.
|
||||
|
||||

|
||||
4. On the **Cluster Settings** page, you can see a list of available clusters. Select the clusters that you want to allocate to the workspace and click **Create**.
|
||||
|
||||
5. After the workspace is created, workspace members with necessary permissions can create resources that run on the associated cluster.
|
||||
|
||||

|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
Try not to create resources on the host cluster to avoid excessive loads, which can lead to a decrease in the stability across clusters.
|
||||
|
|
@ -44,20 +38,16 @@ Try not to create resources on the host cluster to avoid excessive loads, which
|
|||
|
||||
After a workspace is created, you can allocate additional clusters to the workspace through authorization or unbind a cluster from the workspace. Follow the steps below to adjust the visibility of a cluster.
|
||||
|
||||
1. Log in to KubeSphere with an account that has the permission to manage clusters, such as `admin`.
|
||||
1. Log in to KubeSphere with a user that has the permission to manage clusters, such as `admin`.
|
||||
|
||||
2. Click **Platform** in the top-left corner and select **Cluster Management**. Select a cluster from the list to view cluster information.
|
||||
2. Click **Platform** in the upper-left corner and select **Cluster Management**. Select a cluster from the list to view cluster information.
|
||||
|
||||
3. In **Cluster Settings** from the navigation bar, select **Cluster Visibility**.
|
||||
|
||||
4. You can see the list of authorized workspaces, which means the current cluster is available to resources in all these workspaces.
|
||||
|
||||

|
||||
|
||||
5. Click **Edit Visibility** to set the cluster authorization. You can select new workspaces that will be able to use the cluster or unbind it from a workspace.
|
||||
|
||||

|
||||
5. Click **Edit Visibility** to set the cluster visibility. You can select new workspaces that will be able to use the cluster or unbind it from a workspace.
|
||||
|
||||
### Make a cluster public
|
||||
|
||||
You can check **Set as public cluster** so that platform users can access the cluster, in which they are able to create and schedule resources.
|
||||
You can check **Set as Public Cluster** so that platform users can access the cluster, in which they are able to create and schedule resources.
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
linkTitle: "Log Collection"
|
||||
linkTitle: "Log Receivers"
|
||||
weight: 8620
|
||||
|
||||
_build:
|
||||
|
|
|
|||
|
|
@ -1,21 +1,21 @@
|
|||
---
|
||||
title: "Add Elasticsearch as a Receiver"
|
||||
keywords: 'Kubernetes, log, elasticsearch, pod, container, fluentbit, output'
|
||||
description: 'Learn how to add Elasticsearch to receive logs, events or auditing logs.'
|
||||
description: 'Learn how to add Elasticsearch to receive container logs, resource events, or audit logs.'
|
||||
linkTitle: "Add Elasticsearch as a Receiver"
|
||||
weight: 8622
|
||||
---
|
||||
You can use Elasticsearch, Kafka and Fluentd as log receivers in KubeSphere. This tutorial demonstrates how to add an Elasticsearch receiver.
|
||||
You can use Elasticsearch, Kafka, and Fluentd as log receivers in KubeSphere. This tutorial demonstrates how to add an Elasticsearch receiver.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
- You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/). `logging` is enabled as an example in this tutorial.
|
||||
|
||||
## Add Elasticsearch as a Receiver
|
||||
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -23,15 +23,13 @@ If you have enabled the [multi-cluster feature](../../../../multicluster-managem
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
2. On the **Cluster Management** page, go to **Log Collection** in **Cluster Settings**.
|
||||
2. On the **Cluster Management** page, go to **Log Receivers** in **Cluster Settings**.
|
||||
|
||||
3. Click **Add Log Receiver** and choose **Elasticsearch**.
|
||||
|
||||
4. Provide the Elasticsearch service address and port as below:
|
||||
4. Provide the Elasticsearch service address and port number.
|
||||
|
||||

|
||||
5. Elasticsearch will appear in the receiver list on the **Log Receivers** page, the status of which is **Collecting**.
|
||||
|
||||
5. Elasticsearch will appear in the receiver list on the **Log Collection** page, the status of which is **Collecting**.
|
||||
|
||||
6. To verify whether Elasticsearch is receiving logs sent from Fluent Bit, click **Log Search** in the **Toolbox** in the bottom-right corner and search logs on the console. For more information, read [Log Query](../../../../toolbox/log-query/).
|
||||
6. To verify whether Elasticsearch is receiving logs sent from Fluent Bit, click **Log Search** in the **Toolbox** in the lower-right corner and search logs on the console. For more information, read [Log Query](../../../../toolbox/log-query/).
|
||||
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
title: "Add Fluentd as a Receiver"
|
||||
keywords: 'Kubernetes, log, fluentd, pod, container, fluentbit, output'
|
||||
description: 'Learn how to add Fluentd to receive logs, events or auditing logs.'
|
||||
description: 'Learn how to add Fluentd to receive logs, events or audit logs.'
|
||||
linkTitle: "Add Fluentd as a Receiver"
|
||||
weight: 8624
|
||||
---
|
||||
|
|
@ -13,9 +13,9 @@ You can use Elasticsearch, Kafka and Fluentd as log receivers in KubeSphere. Thi
|
|||
|
||||
## Prerequisites
|
||||
|
||||
- You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
- You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/). `logging` is enabled as an example in this tutorial.
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events`, or `auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/). `logging` is enabled as an example in this tutorial.
|
||||
|
||||
## Step 1: Deploy Fluentd as a Deployment
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ Run the following commands:
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
- The following commands create the Fluentd Deployment, Service and ConfigMap in the `default` namespace and add a filter to the Fluentd ConfigMap to exclude logs from the `default` namespace to avoid Fluent Bit and Fluentd loop log collections.
|
||||
- The following commands create the Fluentd Deployment, Service, and ConfigMap in the `default` namespace and add a filter to the Fluentd ConfigMap to exclude logs from the `default` namespace to avoid Fluent Bit and Fluentd loop log collections.
|
||||
- Change the namespace if you want to deploy Fluentd into a different namespace.
|
||||
|
||||
{{</ notice >}}
|
||||
|
|
@ -122,7 +122,7 @@ EOF
|
|||
|
||||
## Step 2: Add Fluentd as a Log Receiver
|
||||
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -130,22 +130,20 @@ EOF
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
2. On the **Cluster Management** page, go to **Log Collection** in **Cluster Settings**.
|
||||
2. On the **Cluster Management** page, go to **Log Receivers** in **Cluster Settings**.
|
||||
|
||||
3. Click **Add Log Receiver** and choose **Fluentd**.
|
||||
|
||||
4. Provide the Fluentd service address and port as below:
|
||||
4. Provide the Fluentd service address and port number.
|
||||
|
||||

|
||||
|
||||
5. Fluentd will appear in the receiver list on the **Log Collection** page, the status of which is **Collecting**.
|
||||
5. Fluentd will appear in the receiver list on the **Log Receivers** page, the status of which is **Collecting**.
|
||||
|
||||
|
||||
## Step 3: Verify Fluentd is Receiving Logs Sent from Fluent Bit
|
||||
|
||||
1. Click **Application Workloads** on the **Cluster Management** page.
|
||||
|
||||
2. Select **Workloads** and then select the `default` project from the drop-down list on the **Deployments** tab.
|
||||
2. Select **Workloads** and then select the `default` project on the **Deployments** tab.
|
||||
|
||||
3. Click the **fluentd** item and then select the **fluentd-xxxxxxxxx-xxxxx** Pod.
|
||||
|
||||
|
|
@ -153,6 +151,4 @@ EOF
|
|||
|
||||
5. On the **fluentd** container page, select the **Container Logs** tab.
|
||||
|
||||
6. You can see logs begin to scroll up continuously.
|
||||
|
||||

|
||||
6. You can see logs begin to scroll up continuously.
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
title: "Add Kafka as a Receiver"
|
||||
keywords: 'Kubernetes, log, kafka, pod, container, fluentbit, output'
|
||||
description: 'Learn how to add Kafka to receive logs, events or auditing logs.'
|
||||
description: 'Learn how to add Kafka to receive container logs, resource events, or audit logs.'
|
||||
linkTitle: "Add Kafka as a Receiver"
|
||||
weight: 8623
|
||||
---
|
||||
|
|
@ -13,7 +13,7 @@ You can use Elasticsearch, Kafka and Fluentd as log receivers in KubeSphere. Thi
|
|||
|
||||
## Prerequisites
|
||||
|
||||
- You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
- You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/). `logging` is enabled as an example in this tutorial.
|
||||
|
||||
## Step 1: Create a Kafka Cluster and a Kafka Topic
|
||||
|
|
@ -101,7 +101,7 @@ You can use [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-op
|
|||
|
||||
## Step 2: Add Kafka as a Log Receiver
|
||||
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -109,18 +109,16 @@ You can use [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-op
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
2. On the **Cluster Management** page, go to **Log Collection** in **Cluster Settings**.
|
||||
2. On the **Cluster Management** page, go to **Log Receivers** in **Cluster Settings**.
|
||||
|
||||
3. Click **Add Log Receiver** and select **Kafka**. Enter the Kafka broker address and port as below, and then click **OK** to continue.
|
||||
3. Click **Add Log Receiver** and select **Kafka**. Enter the Kafka service address and port number, and then click **OK** to continue.
|
||||
|
||||
| Address | Port |
|
||||
| Service Address | Port Number |
|
||||
| ------------------------------------------------------- | ---- |
|
||||
| my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc | 9092 |
|
||||
| my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc | 9092 |
|
||||
| my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc | 9092 |
|
||||
|
||||

|
||||
|
||||
4. Run the following commands to verify whether the Kafka cluster is receiving logs sent from Fluent Bit:
|
||||
|
||||
```bash
|
||||
|
|
|
|||
|
|
@ -1,20 +1,20 @@
|
|||
---
|
||||
title: "Introduction to Log Collection"
|
||||
title: "Introduction to Log Receivers"
|
||||
keywords: 'Kubernetes, log, elasticsearch, kafka, fluentd, pod, container, fluentbit, output'
|
||||
description: 'Learn the basics of cluster log collection, including tools and general steps.'
|
||||
description: 'Learn the basics of cluster log receivers, including tools, and general steps.'
|
||||
linkTitle: "Introduction"
|
||||
weight: 8621
|
||||
---
|
||||
|
||||
KubeSphere provides a flexible log collection configuration method. Powered by [FluentBit Operator](https://github.com/kubesphere/fluentbit-operator/), users can easily add, modify, delete, enable or disable Elasticsearch, Kafka and Fluentd receivers. Once a receiver is added, logs will be sent to this receiver.
|
||||
KubeSphere provides a flexible log receiver configuration method. Powered by [FluentBit Operator](https://github.com/kubesphere/fluentbit-operator/), users can easily add, modify, delete, enable, or disable Elasticsearch, Kafka and Fluentd receivers. Once a receiver is added, logs will be sent to this receiver.
|
||||
|
||||
This tutorial gives a brief introduction about the general steps of adding log receivers in KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
- You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/).
|
||||
- Before adding a log receiver, you need to enable any of the `Logging`, `Events` or `Auditing` components. For more information, see [Enable Pluggable Components](../../../../pluggable-components/).
|
||||
|
||||
## Add a Log Receiver for Container Logs
|
||||
|
||||
|
|
@ -22,7 +22,7 @@ To add a log receiver:
|
|||
|
||||
1. Log in to the web console of KubeSphere as `admin`.
|
||||
|
||||
2. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
2. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -30,9 +30,9 @@ To add a log receiver:
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Go to **Log Collection** under **Cluster Settings** in the sidebar.
|
||||
3. Go to **Log Receivers** under **Cluster Settings** in the sidebar.
|
||||
|
||||
4. Click **Add Log Receiver** on the **Logging** tab.
|
||||
4. On the log receivers list page, click **Add Log Receiver**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -43,9 +43,9 @@ To add a log receiver:
|
|||
|
||||
### Add Elasticsearch as a log receiver
|
||||
|
||||
A default Elasticsearch receiver will be added with its service address set to an Elasticsearch cluster if `logging`, `events`, or `auditing` is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.1/docs/config-example.md).
|
||||
A default Elasticsearch receiver will be added with its service address set to an Elasticsearch cluster if `logging`, `events`, or `auditing` is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.2/docs/config-example.md).
|
||||
|
||||
An internal Elasticsearch cluster will be deployed to the Kubernetes cluster if neither `externalElasticsearchUrl` nor `externalElasticsearchPort` is specified in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.1/docs/config-example.md) when `logging`, `events` or `auditing` is enabled. The internal Elasticsearch cluster is for testing and development only. It is recommended that you configure an external Elasticsearch cluster for production.
|
||||
An internal Elasticsearch cluster will be deployed to the Kubernetes cluster if neither `externalElasticsearchHost` nor `externalElasticsearchPort` is specified in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.2/docs/config-example.md) when `logging`, `events`, or `auditing` is enabled. The internal Elasticsearch cluster is for testing and development only. It is recommended that you configure an external Elasticsearch cluster for production.
|
||||
|
||||
Log searching relies on the internal or external Elasticsearch cluster configured.
|
||||
|
||||
|
|
@ -59,33 +59,29 @@ Kafka is often used to receive logs and serves as a broker to other processing s
|
|||
|
||||
If you need to output logs to more places other than Elasticsearch or Kafka, you can add Fluentd as a log receiver. Fluentd has numerous output plugins which can forward logs to various destinations such as S3, MongoDB, Cassandra, MySQL, syslog, and Splunk. [Add Fluentd as a Receiver](../add-fluentd-as-receiver/) demonstrates how to add Fluentd to receive Kubernetes logs.
|
||||
|
||||
## Add a Log Receiver for Events or Auditing Logs
|
||||
## Add a Log Receiver for Resource Events or Audit Logs
|
||||
|
||||
Starting from KubeSphere v3.0.0, the logs of Kubernetes events and the auditing logs of Kubernetes and KubeSphere can be archived in the same way as container logs. The tab **Events** or **Auditing** on the **Log Collection** page will appear if `events` or `auditing` is enabled accordingly in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.1/docs/config-example.md). You can go to the corresponding tab to configure log receivers for Kubernetes events or Kubernetes and KubeSphere auditing logs.
|
||||
Starting from KubeSphere v3.0.0, resource events and audit logs can be archived in the same way as container logs. The tab **Resource Events** or **Audit Logs** on the **Log Receivers** page will appear if `events` or `auditing` is enabled accordingly in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/release-1.2/docs/config-example.md). You can go to the corresponding tab to configure log receivers for resource events or audit logs.
|
||||
|
||||
Container logs, Kubernetes events and Kubernetes and KubeSphere auditing logs should be stored in different Elasticsearch indices to be searched in KubeSphere. The index prefixes are:
|
||||
|
||||
- `ks-logstash-log` for container logs
|
||||
- `ks-logstash-events` for Kubernetes events
|
||||
- `ks-logstash-auditing` for Kubernetes and KubeSphere auditing logs
|
||||
Container logs, resource events, and audit logs should be stored in different Elasticsearch indices to be searched in KubeSphere. The index is automatically generated in <Index prefix>-<Year-month-date> format.
|
||||
|
||||
## Turn a Log Receiver on or Off
|
||||
|
||||
You can turn a log receiver on or off without adding or deleting it. To turn a log receiver on or off:
|
||||
|
||||
1. On the **Log Collection** page, click a log receiver and go to the receiver's detail page.
|
||||
1. On the **Log Receivers** page, click a log receiver and go to the receiver's detail page.
|
||||
2. Click **More** and select **Change Status**.
|
||||
|
||||
3. Select **Activate** or **Close** to turn the log receiver on or off.
|
||||
3. Select **Collecting** or **Disabled** to turn the log receiver on or off.
|
||||
|
||||
4. A log receiver's status will be changed to **Close** if you turn it off, otherwise the status will be **Collecting** on the **Log Collection** page.
|
||||
4. A log receiver's status will be changed to **Disabled** if you turn it off, otherwise the status will be **Collecting** on the **Log Receivers** page.
|
||||
|
||||
|
||||
## Modify or Delete a Log Receiver
|
||||
## Edit or Delete a Log Receiver
|
||||
|
||||
You can modify a log receiver or delete it:
|
||||
You can edit a log receiver or delete it:
|
||||
|
||||
1. On the **Log Collection** page, click a log receiver and go to the receiver's detail page.
|
||||
1. On the **Log Receivers** page, click a log receiver and go to the receiver's detail page.
|
||||
2. Edit a log receiver by clicking **Edit** or **Edit YAML** from the drop-down list.
|
||||
|
||||
3. Delete a log receiver by clicking **Delete Log Receiver**.
|
||||
3. Delete a log receiver by clicking **Delete**.
|
||||
|
|
|
|||
|
|
@ -1,16 +1,16 @@
|
|||
---
|
||||
title: "Cluster Status Monitoring"
|
||||
keywords: "Kubernetes, KubeSphere, status, monitoring"
|
||||
description: "Monitor how a cluster is functioning based on different metrics, including physical resources, etcd, and APIServer."
|
||||
description: "Monitor how a cluster is functioning based on different metrics, including physical resources, etcd, and API server."
|
||||
linkTitle: "Cluster Status Monitoring"
|
||||
weight: 8200
|
||||
---
|
||||
|
||||
KubeSphere provides monitoring of related metrics such as CPU, memory, network, and disk of the cluster. You can also review historical monitoring data and sort nodes by different indicators based on their usage in **Cluster Status Monitoring**.
|
||||
KubeSphere provides monitoring of related metrics such as CPU, memory, network, and disk of the cluster. You can also review historical monitoring data and sort nodes by different indicators based on their usage in **Cluster Status**.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
You need a user granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to a user.
|
||||
|
||||
## Cluster Status Monitoring
|
||||
|
||||
|
|
@ -18,143 +18,106 @@ You need an account granted a role including the authorization of **Cluster Mana
|
|||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management/) with member clusters imported, you can select a specific cluster to view its application resources. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. Choose **Cluster Status** under **Monitoring & Alerting** to see the overview of cluster status monitoring, including **Cluster Node Status**, **Components Status**, **Cluster Resources Usage**, **ETCD Monitoring**, and **Service Component Monitoring**, as shown in the following figure.
|
||||
|
||||

|
||||
3. Choose **Cluster Status** under **Monitoring & Alerting** to see the overview of cluster status monitoring, including **Cluster Node Status**, **Component Status**, **Cluster Resource Usage**, **etcd Monitoring**, and **Service Component Monitoring**.
|
||||
|
||||
### Cluster node status
|
||||
|
||||
1. **Cluster Node Status** displays the status of all nodes, separately marking the active ones. You can go to the **Cluster Nodes** page shown below to view the real-time resource usage of all nodes by clicking **Node Online Status**.
|
||||
1. **Cluster Nodes Status** displays the status of all nodes, separately marking the active ones. You can go to the **Cluster Nodes** page to view the real-time resource usage of all nodes by clicking **Node Online Status**.
|
||||
|
||||

|
||||
2. In **Cluster Nodes**, click the node name to view usage details in **Running Status**, including **Resource Usage**, **Allocated Resources**, and **Health Status**.
|
||||
|
||||
2. In **Cluster Nodes**, click the node name to view usage details in **Status**, including the information of CPU, Memory, Pod, Local Storage in the current node, and its health status.
|
||||
3. Click the **Monitoring** tab to view how the node is functioning during a certain period based on different metrics, including **CPU Usage**, **Average CPU Load**, **Memory Usage**, **Disk Usage**, **Inode Usage**, **IOPS**, **Disk Throughput**, and **Network Bandwidth**.
|
||||
|
||||

|
||||
|
||||
3. Click the tab **Monitoring** to view how the node is functioning during a certain period based on different metrics, including **CPU Utilization, CPU Load Average, Memory Utilization, Disk Utilization, inode Utilization, IOPS, Disk Throughput, and Network Bandwidth**, as shown in the following figure.
|
||||
|
||||

|
||||
|
||||
{{< notice tip >}}You can customize the time range from the drop-down list in the top-right corner to view historical data.
|
||||
{{< notice tip >}}You can customize the time range from the drop-down list in the upper-right corner to view historical data.
|
||||
{{</ notice >}}
|
||||
|
||||
### Component status
|
||||
|
||||
KubeSphere monitors the health status of various service components in the cluster. When a key component malfunctions, the system may become unavailable. The monitoring mechanism of KubeSphere ensures the platform can notify tenants of any occurring issues in case of a component failure, so that they can quickly locate the problem and take corresponding action.
|
||||
|
||||
1. On the **Cluster Status Monitoring** page, click components (the part in the green box below) under **Components Status** to view the status of service components.
|
||||
|
||||

|
||||
1. On the **Cluster Status** page, click a component under **Component Status** to view its status.
|
||||
|
||||
2. You can see all the components are listed in this part. Components marked in green are those functioning normally while those marked in orange require special attention as it signals potential issues.
|
||||
|
||||

|
||||
|
||||
{{< notice tip >}}Components marked in orange may turn to green after a period of time, the reasons of which may be different, such as image pulling retries or pod recreations. You can click the component to see its service details.
|
||||
{{</ notice >}}
|
||||
|
||||
### Cluster resources usage
|
||||
### Cluster resource usage
|
||||
|
||||
**Cluster Resources Usage** displays the information including **CPU Utilization, Memory Utilization, Disk Utilization, and Pod Quantity Trend** of all nodes in the cluster. Click the pie chart on the left to switch indicators, which shows the trend during a period in a line chart on the right.
|
||||
**Cluster Resource Usage** displays the information including **CPU Usage**, **Memory Usage**, **Disk Usage**, and **Pods** of all nodes in the cluster. Click the pie chart on the left to switch indicators, which shows the trend during a period in a line chart on the right.
|
||||
|
||||

|
||||
## Physical Resource Monitoring
|
||||
|
||||
## Physical Resources Monitoring
|
||||
Monitoring data in **Physical Resource Monitoring** help users better observe their physical resources and establish normal standards for resource and cluster performance. KubeSphere allows users to view cluster monitoring data within the last 7 days, including **CPU Usage**, **Memory Usage**, **Average CPU Load (1 minute/5 minutes/15 minutes)**, **Disk Usage**, **Inode Usage**, **Disk Throughput (read/write)**, **IOPS (read/write)**, **Network Bandwidth**, and **Pod Status**. You can customize the time range and time interval to view historical monitoring data of physical resources in KubeSphere. The following sections briefly introduce each monitoring indicator.
|
||||
|
||||
Monitoring data in **Physical Resources Monitoring** help users better observe their physical resources and establish normal standards for resource and cluster performance. KubeSphere allows users to view cluster monitoring data within the last 7 days, including **CPU Utilization**, **Memory Utilization**, **CPU Load Average** **(1 minute/5 minutes/15 minutes)**, **inode Utilization**, **Disk Throughput (read/write)**, **IOPS (read/write)**, **Network Bandwidth**, and **Pod Status**. You can customize the time range and time interval to view historical monitoring data of physical resources in KubeSphere. The following sections briefly introduce each monitoring indicator.
|
||||
### CPU usage
|
||||
|
||||

|
||||
CPU usage shows how CPU resources are used in a period. If you notice that the CPU usage of the platform during a certain period soars, you must first locate the process that is occupying CPU resources the most. For example, for Java applications, you may expect a CPU usage spike in the case of memory leaks or infinite loops in the code.
|
||||
|
||||
### CPU utilization
|
||||
### Memory usage
|
||||
|
||||
CPU utilization shows how CPU resources are used in a period. If you notice that the CPU usage of the platform during a certain period soars, you must first locate the process that is occupying CPU resources the most. For example, for Java applications, you may expect a CPU usage spike in the case of memory leaks or infinite loops in the code.
|
||||
Memory is one of the important components on a machine, serving as a bridge for communications with the CPU. Therefore, the performance of memory has a great impact on the machine. Data loading, thread concurrency and I/O buffering are all dependent on memory when a program is running. The size of available memory determines whether the program can run normally and how it is functioning. Memory usage reflects how memory resources are used within a cluster as a whole, displayed as a percentage of available memory in use at a given moment.
|
||||
|
||||

|
||||
### Average CPU load
|
||||
|
||||
### Memory utilization
|
||||
Average CPU load is the average number of processes in the system in a runnable state and an uninterruptible state per unit time. Namely, it is the average number of active processes. Note that there is no direct relation between the average CPU load and the CPU usage. Ideally, the average load should be equal to the number of CPUs. Therefore, you need to consider the number of CPUs when you look into the average load. A system is overloaded only when the average load is greater than the number of CPUs.
|
||||
|
||||
Memory is one of the important components on a machine, serving as a bridge for communications with the CPU. Therefore, the performance of memory has a great impact on the machine. Data loading, thread concurrency and I/O buffering are all dependent on memory when a program is running. The size of available memory determines whether the program can run normally and how it is functioning. Memory utilization reflects how memory resources are used within a cluster as a whole, displayed as a percentage of available memory in use at a given moment.
|
||||
|
||||

|
||||
|
||||
### CPU load average
|
||||
|
||||
CPU load average is the average number of processes in the system in a runnable state and an uninterruptible state per unit time. Namely, it is the average number of active processes. Note that there is no direct relation between the CPU load average and the CPU utilization. Ideally, the load average should be equal to the number of CPUs. Therefore, you need to consider the number of CPUs when you look into the load average. A system is overloaded only when the load average is greater than the number of CPUs.
|
||||
|
||||
KubeSphere provides users with three different time periods to view the load average: 1 minute, 5 minutes and 15 minutes. Normally, it is recommended that you review all of them to gain a comprehensive understanding of load averages:
|
||||
KubeSphere provides users with three different time periods to view the average load: 1 minute, 5 minutes, and 15 minutes. Normally, it is recommended that you review all of them to gain a comprehensive understanding of average CPU load:
|
||||
|
||||
- If the curves of 1 minute / 5 minutes / 15 minutes are similar within a certain period, it indicates that the CPU load of the cluster is relatively stable.
|
||||
- If the value of 1 minute in a certain period, or at a specific time point is much greater than that of 15 minutes, it means that the load in the last 1 minute is increasing, and you need to keep observing. Once the value of 1 minute exceeds the number of CPUs, it may mean that the system is overloaded. You need to further analyze the source of the problem.
|
||||
- Conversely, if the value of 1 minute in a certain period, or at a specific time point is much less than that of 15 minutes, it means that the load of the system is decreasing in the last 1 minute, and a high load has been generated in the previous 15 minutes.
|
||||
|
||||

|
||||
|
||||
### Disk usage
|
||||
|
||||
KubeSphere workloads such as `StatefulSets` and `DaemonSets` all rely on persistent volumes. Some components and services also require a persistent volume. Such backend storage relies on disks, such as block storage or network shared storage. In this connection, providing a real-time monitoring environment for disk usage is an important part of maintaining the high reliability of data.
|
||||
|
||||
In the daily management of the Linux system, platform administrators may encounter data loss or even system crashes due to insufficient disk space. As an essential part of cluster management, they need to pay close attention to the disk usage of the system and ensure that the file system is not filling up or abused. By monitoring the historical data of disk usage, you can evaluate how disks are used during a given period of time. In the case of high disk usage, you can free up disk space by cleaning up unnecessary images or containers.
|
||||
|
||||

|
||||
|
||||
### inode utilization
|
||||
### Inode usage
|
||||
|
||||
Each file must have an inode, which is used to store the file's meta-information, such as the file's creator and creation date. The inode will also consume hard disk space, and many small cache files can easily lead to the exhaustion of inode resources. Also, the inode may be used up, but the hard disk is not full. In this case, new files cannot be created on the hard disk.
|
||||
|
||||
In KubeSphere, the monitoring of inode utilization can help you detect such situations in advance, as you can have a clear view of cluster inode usage. The mechanism prompts users to clean up temporary files in time, preventing the cluster from being unable to work due to inode exhaustion.
|
||||
|
||||

|
||||
In KubeSphere, the monitoring of inode usage can help you detect such situations in advance, as you can have a clear view of cluster inode usage. The mechanism prompts users to clean up temporary files in time, preventing the cluster from being unable to work due to inode exhaustion.
|
||||
|
||||
### Disk throughput
|
||||
|
||||
The monitoring of disk throughput and IOPS is an indispensable part of disk monitoring, which is convenient for cluster administrators to adjust data layout and other management activities to optimize the overall performance of the cluster. Disk throughput refers to the speed of the disk transmission data stream (shown in MB/s), and the transmission data are the sum of data reading and writing. When large blocks of discontinuous data are being transmitted, this indicator is of great importance for reference.
|
||||

|
||||
|
||||
### IOPS
|
||||
|
||||
**IOPS (Input/Output Operations Per Second)** represents a performance measurement of the number of read and write operations per second. Specifically, the IOPS of a disk is the sum of the number of continuous reads and writes per second. This indicator is of great significance for reference when small blocks of discontinuous data are being transmitted.
|
||||
|
||||

|
||||
|
||||
### Network bandwidth
|
||||
|
||||
The network bandwidth is the ability of the network card to receive or send data per second, shown in Mbps (megabits per second).
|
||||
|
||||

|
||||
|
||||
### Pod status
|
||||
|
||||
Pod status displays the total number of pods in different states, including **Running**, **Completed** and **Warning**. The pod tagged **Completed** usually refers to a Job or a CronJob. The number of pods marked **Warning**, which means an abnormal state, requires special attention.
|
||||
|
||||

|
||||
## etcd Monitoring
|
||||
|
||||
## ETCD Monitoring
|
||||
|
||||
ETCD monitoring helps you to make better use of ETCD, especially to locate performance problems. The ETCD service provides metrics interfaces natively, and the KubeSphere monitoring system features a highly graphic and responsive dashboard to display its native data.
|
||||
etcd monitoring helps you to make better use of etcd, especially to locate performance problems. The etcd service provides metrics interfaces natively, and the KubeSphere monitoring system features a highly graphic and responsive dashboard to display its native data.
|
||||
|
||||
|Indicators|Description|
|
||||
|---|---|
|
||||
|ETCD Nodes | - **Is there a Leader** indicates whether the member has a Leader. If a member does not have a Leader, it is completely unavailable. If all members in the cluster do not have any Leader, the entire cluster is completely unavailable. <br>- **Leader change times** refers to the number of Leader changes seen by members of the cluster since the beginning. Frequent Leader changes will significantly affect the performance of ETCD. It also shows that the Leader is unstable, possibly due to network connection issues or excessive loads hitting the ETCD cluster. |
|
||||
|DB Size | The size of the underlying database (in MiB) of ETCD. The current graph shows the average size of each member database of ETCD. |
|
||||
|Client Traffic|It includes the total traffic sent to the grpc client and the total traffic received from the grpc client. For more information about the indicator, see [etcd Network](https://github.com/etcd-io/etcd/blob/v3.2.17/Documentation/metrics.md#network). |
|
||||
|gRPC Stream Messages|The gRPC streaming message receiving rate and sending rate on the server side, which reflects whether large-scale data read and write operations are happening in the cluster. For more information about the indicator, see [go-grpc-prometheus](https://github.com/grpc-ecosystem/go-grpc-prometheus#counters).|
|
||||
|Service Status | - **Leader exists** indicates whether the member has a Leader. If a member does not have a Leader, it is completely unavailable. If all members in the cluster do not have any Leader, the entire cluster is completely unavailable. <br>- **Leader changes in 1 h** refers to the number of Leader changes seen by members of the cluster in 1 hour. Frequent Leader changes will significantly affect the performance of etcd. It also shows that the Leader is unstable, possibly due to network connection issues or excessive loads hitting the etcd cluster. |
|
||||
|DB Size | The size of the underlying database (in MiB) of etcd. The current graph shows the average size of each member database of etcd. |
|
||||
|Client Traffic|It includes the total traffic sent to the gRPC client and the total traffic received from the gRPC client. For more information about the indicator, see [etcd Network](https://github.com/etcd-io/etcd/blob/v3.2.17/Documentation/metrics.md#network). |
|
||||
|gRPC Stream Message|The gRPC streaming message receiving rate and sending rate on the server side, which reflects whether large-scale data read and write operations are happening in the cluster. For more information about the indicator, see [go-grpc-prometheus](https://github.com/grpc-ecosystem/go-grpc-prometheus#counters).|
|
||||
|WAL Fsync|The latency of WAL calling fsync. A `wal_fsync` is called when etcd persists its log entries to disk before applying them. For more information about the indicator, see [etcd Disk](https://etcd.io/docs/v3.3.12/metrics/#grpc-requests). |
|
||||
|DB Fsync|The submission delay distribution of the backend calls. When ETCD submits its most recent incremental snapshot to disk, a `backend_commit` will be called. Note that high latency of disk operations (long WAL log synchronization time or library synchronization time) usually indicates disk problems, which may cause high request latency or make the cluster unstable. For more information about the indicator, see [etcd Disk](https://etcd.io/docs/v3.3.12/metrics/#grpc-requests). |
|
||||
|Raft Proposals|- **Proposal Commit Rate** records the rate of consensus proposals committed. If the cluster is healthy, this indicator should increase over time. Several healthy members of an ETCD cluster may have different general proposals at the same time. A continuous large lag between a single member and its leader indicates that the member is slow or unhealthy. <br>- **Proposal Apply Rate** records the total rate of consensus proposals applied. The ETCD server applies each committed proposal asynchronously. The difference between the **Proposal Commit Rate** and the **Proposal Apply Rate** should usually be small (only a few thousands even under high loads). If the difference between them continues to rise, it indicates that the ETCD server is overloaded. This can happen when using large-scale queries such as heavy range queries or large txn operations. <br>- **Proposal Failure Rate** records the total rate of failed proposals, usually related to two issues: temporary failures related to leader election or longer downtime due to a loss of quorum in the cluster. <br> - **Proposal Pending Total** records the current number of pending proposals. An increase in pending proposals indicates high client loads or members unable to submit proposals. <br> Currently, the data displayed on the dashboard is the average size of ETCD members. For more information about these indicators, see [etcd Server](https://etcd.io/docs/v3.3.12/metrics/#server). |
|
||||
|DB Fsync|The submission delay distribution of the backend calls. When etcd submits its most recent incremental snapshot to disk, a `backend_commit` will be called. Note that high latency of disk operations (long WAL log synchronization time or library synchronization time) usually indicates disk problems, which may cause high request latency or make the cluster unstable. For more information about the indicator, see [etcd Disk](https://etcd.io/docs/v3.3.12/metrics/#grpc-requests). |
|
||||
|Raft Proposal|- **Proposal Commit Rate** records the rate of consensus proposals committed. If the cluster is healthy, this indicator should increase over time. Several healthy members of an etcd cluster may have different general proposals at the same time. A continuous large lag between a single member and its leader indicates that the member is slow or unhealthy. <br>- **Proposal Apply Rate** records the total rate of consensus proposals applied. The etcd server applies each committed proposal asynchronously. The difference between the **Proposal Commit Rate** and the **Proposal Apply Rate** should usually be small (only a few thousands even under high loads). If the difference between them continues to rise, it indicates that the etcd server is overloaded. This can happen when using large-scale queries such as heavy range queries or large txn operations. <br>- **Proposal Failure Rate** records the total rate of failed proposals, usually related to two issues: temporary failures related to leader election or longer downtime due to a loss of quorum in the cluster. <br> - **Proposal Pending Total** records the current number of pending proposals. An increase in pending proposals indicates high client loads or members unable to submit proposals. <br> Currently, the data displayed on the dashboard is the average size of etcd members. For more information about these indicators, see [etcd Server](https://etcd.io/docs/v3.3.12/metrics/#server). |
|
||||
|
||||

|
||||
## API Server Monitoring
|
||||
|
||||
## APIServer Monitoring
|
||||
|
||||
[API Server](https://kubernetes.io/docs/concepts/overview/kubernetes-api/) is the hub for the interaction of all components in a Kubernetes cluster. The following table lists the main indicators monitored for the APIServer.
|
||||
[API Server](https://kubernetes.io/docs/concepts/overview/kubernetes-api/) is the hub for the interaction of all components in a Kubernetes cluster. The following table lists the main indicators monitored for the API Server.
|
||||
|
||||
|Indicators|Description|
|
||||
|---|---|
|
||||
|Request Latency|Classified by HTTP request methods, the latency of resource request response in milliseconds.|
|
||||
|Request Per Second|The number of requests accepted by kube-apiserver per second.|
|
||||
|
||||

|
||||
|Request per Second|The number of requests accepted by kube-apiserver per second.|
|
||||
|
||||
## Scheduler Monitoring
|
||||
|
||||
|
|
@ -166,10 +129,6 @@ ETCD monitoring helps you to make better use of ETCD, especially to locate perfo
|
|||
|Attempt Rate|Include the scheduling rate of successes, errors, and failures.|
|
||||
|Scheduling latency|End-to-end scheduling delay, which is the sum of scheduling algorithm delay and binding delay|
|
||||
|
||||

|
||||
## Resource Usage Ranking
|
||||
|
||||
## Node Usage Ranking
|
||||
|
||||
You can sort nodes in ascending and descending order by indicators such as CPU, Load Average, Memory, Local Storage, inode Utilization, and Pod Utilization. This enables administrators to quickly find potential problems or identify a node's insufficient resources.
|
||||
|
||||

|
||||
You can sort nodes in ascending and descending order by indicators such as CPU usage, average CPU load, memory usage, disk usage, inode usage, and Pod usage. This enables administrators to quickly find potential problems or identify a node's insufficient resources.
|
||||
|
|
|
|||
|
|
@ -11,18 +11,16 @@ Alerting messages record detailed information of alerts triggered based on the a
|
|||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere Alerting](../../../pluggable-components/alerting/).
|
||||
- You need to create an account (`cluster-admin`) and grant it the `clusters-admin` role. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-4-create-a-role).
|
||||
- You need to create a user (`cluster-admin`) and grant it the `clusters-admin` role. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-4-create-a-role).
|
||||
- You have created a node-level alerting policy and an alert has been triggered. For more information, refer to [Alerting Policies (Node Level)](../alerting-policy/).
|
||||
|
||||
## View Alerting Messages
|
||||
|
||||
1. Log in to the KubeSphere console as `cluster-admin` and navigate to **Alerting Messages** under **Monitoring & Alerting**.
|
||||
1. Log in to the KubeSphere console as `cluster-admin` and go to **Alerting Messages** under **Monitoring & Alerting**.
|
||||
|
||||
2. On the **Alerting Messages** page, you can see all alerting messages in the list. The first column displays the summary and message you have defined in the notification of the alert. To view details of an alerting message, click the name of the alerting policy and then click the **Alerting Messages** tab on the page that appears.
|
||||
2. On the **Alerting Messages** page, you can see all alerting messages in the list. The first column displays the summary and details you have defined for the alert. To view details of an alerting message, click the name of the alerting policy and then click the **Alerting History** tab on the alerting policy details page.
|
||||
|
||||

|
||||
|
||||
3. On the **Alerting Messages** tab, you can see alert severity, target resources, and alert time.
|
||||
3. On the **Alerting History** tab, you can see alert severity, monitoring target, and activation time.
|
||||
|
||||
## View Notifications
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ KubeSphere also has built-in policies which will trigger alerts if conditions de
|
|||
|
||||
- You have enabled [KubeSphere Alerting](../../../pluggable-components/alerting/).
|
||||
- To receive alert notifications, you must configure a [notification channel](../../../cluster-administration/platform-settings/notification-management/configure-email/) beforehand.
|
||||
- You need to create an account (`cluster-admin`) and grant it the `clusters-admin` role. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-4-create-a-role).
|
||||
- You need to create a user (`cluster-admin`) and grant it the `clusters-admin` role. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-4-create-a-role).
|
||||
- You have workloads in your cluster. If they are not ready, see [Deploy and Access Bookinfo](../../../quick-start/deploy-bookinfo-to-k8s/) to create a sample app.
|
||||
|
||||
## Create an Alerting Policy
|
||||
|
|
@ -27,14 +27,14 @@ KubeSphere also has built-in policies which will trigger alerts if conditions de
|
|||
|
||||
- **Name**. A concise and clear name as its unique identifier, such as `node-alert`.
|
||||
- **Alias**. Help you distinguish alerting policies better.
|
||||
- **Duration (Minutes)**. An alert will be firing when the conditions defined for an alerting policy are met at any given point in the time range.
|
||||
- **Threshold Duration (min)**. The status of the alerting policy becomes Firing when the duration of the condition configured in the alerting rule reaches the threshold.
|
||||
- **Severity**. Allowed values include **Warning**, **Error** and **Critical**, providing an indication of how serious an alert is.
|
||||
- **Description**. A brief introduction to the alerting policy.
|
||||
|
||||
4. On the **Alerting Rule** tab, you can use the rule template or create a custom rule. To use the template, fill in the following fields and click **Next** to continue.
|
||||
4. On the **Rule Settings** tab, you can use the rule template or create a custom rule. To use the template, set the following parameters and click **Next** to continue.
|
||||
|
||||
- **Monitoring Target**. Select a node in your cluster for monitoring.
|
||||
- **Alerting Rules**. Define a rule for the alerting policy. The rules provided in the drop-down list are based on Prometheus expressions and an alert will be triggered when conditions are met. You can monitor objects such as CPU and memory.
|
||||
- **Monitoring Targets**. Select at lease a node in your cluster for monitoring.
|
||||
- **Alerting Rule**. Define a rule for the alerting policy. The rules provided in the drop-down list are based on Prometheus expressions and an alert will be triggered when conditions are met. You can monitor objects such as CPU, and memory.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -42,7 +42,7 @@ KubeSphere also has built-in policies which will trigger alerts if conditions de
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
5. On the **Notification Settings** tab, enter the alert summary and message to be included in your notification, then click **Create**.
|
||||
5. On the **Message Settings** tab, enter the summary and details of the alerting message, then click **Create**.
|
||||
|
||||
6. An alerting policy will be **Inactive** when just created. If conditions in the rule expression are met, it will reach **Pending** first, and then turn to **Firing** if conditions keep to be met in the given time range.
|
||||
|
||||
|
|
@ -50,17 +50,15 @@ KubeSphere also has built-in policies which will trigger alerts if conditions de
|
|||
|
||||
To edit an alerting policy after it is created, on the **Alerting Policies** page, click <img src="/images/docs/cluster-administration/cluster-wide-alerting-and-notification/alerting-policies-node-level/edit-policy.png" height="25px"> on the right of the alerting policy.
|
||||
|
||||
1. Click **Edit** from the drop-down list and edit the alerting policy following the same steps as you create it. Click **Update** on the **Notification Settings** page to save it.
|
||||
1. Click **Edit** from the drop-down list and edit the alerting policy following the same steps as you create it. Click **OK** on the **Message Settings** page to save it.
|
||||
|
||||
2. Click **Delete** from the drop-down list to delete an alerting policy.
|
||||
|
||||
## View an Alerting Policy
|
||||
|
||||
Click the name of an alerting policy on the **Alerting Policies** page to see its detail information, including alerting rules and alerting messages. You can also see the rule expression which is based on the template you use when creating the alerting policy.
|
||||
Click the name of an alerting policy on the **Alerting Policies** page to see its detail information, including the alerting rule and alerting history. You can also see the rule expression which is based on the template you use when creating the alerting policy.
|
||||
|
||||
Under **Monitoring**, the **Alert Monitoring** chart shows the actual usage or amount of resources over time. **Notification Settings** displays the customized message you set in notifications.
|
||||
|
||||

|
||||
Under **Monitoring**, the **Alert Monitoring** chart shows the actual usage or amount of resources over time. **Alerting Message** displays the customized message you set in notifications.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,29 +13,23 @@ This tutorial demonstrates what a cluster administrator can view and do for node
|
|||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
You need a user granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to a user.
|
||||
|
||||
## Node Status
|
||||
|
||||
Cluster nodes are only accessible to cluster administrators. Some node metrics are very important to clusters. Therefore, it is the administrator's responsibility to watch over these numbers and make sure nodes are available. Follow the steps below to view node status.
|
||||
|
||||
1. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
|
||||

|
||||
1. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management/) with member clusters imported, you can select a specific cluster to view its nodes. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||

|
||||
|
||||
3. Choose **Cluster Nodes** under **Nodes**, where you can see detailed information of node status.
|
||||
|
||||

|
||||
|
||||
- **Name**: The node name and subnet IP address.
|
||||
- **Status**: The current status of a node, indicating whether a node is available or not.
|
||||
- **Role**: The role of a node, indicating whether a node is a worker or master.
|
||||
- **CPU**: The real-time CPU usage of a node.
|
||||
- **Memory**: The real-time memory usage of a node.
|
||||
- **CPU Usage**: The real-time CPU usage of a node.
|
||||
- **Memory Usage**: The real-time memory usage of a node.
|
||||
- **Pods**: The real-time usage of Pods on a node.
|
||||
- **Allocated CPU**: This metric is calculated based on the total CPU requests of Pods on a node. It represents the amount of CPU reserved for workloads on this node, even if workloads are using fewer CPU resources. This figure is vital to the Kubernetes scheduler (kube-scheduler), which favors nodes with lower allocated CPU resources when scheduling a Pod in most cases. For more details, refer to [Managing Resources for Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
|
||||
- **Allocated Memory**: This metric is calculated based on the total memory requests of Pods on a node. It represents the amount of memory reserved for workloads on this node, even if workloads are using fewer memory resources.
|
||||
|
|
@ -48,20 +42,10 @@ Cluster nodes are only accessible to cluster administrators. Some node metrics a
|
|||
|
||||
Click a node from the list and you can go to its detail page.
|
||||
|
||||

|
||||
|
||||
- **Cordon/Uncordon**: Marking a node as unschedulable is very useful during a node reboot or other maintenance. The Kubernetes scheduler will not schedule new Pods to this node if it's been marked unschedulable. Besides, this does not affect existing workloads already on the node. In KubeSphere, you mark a node as unschedulable by clicking **Cordon** on the node detail page. The node will be schedulable if you click the button (**Uncordon**) again.
|
||||
- **Labels**: Node labels can be very useful when you want to assign Pods to specific nodes. Label a node first (for example, label GPU nodes with `node-role.kubernetes.io/gpu-node`), and then add the label in **Advanced Settings** [when you create a workload](../../project-user-guide/application-workloads/deployments/#step-5-configure-advanced-settings) so that you can allow Pods to run on GPU nodes explicitly. To add node labels, click **More** and select **Edit Labels**.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
- **Taints**: Taints allow a node to repel a set of pods. You add or remove node taints on the node detail page. To add or delete taints, click **More** and select **Taint Management** from the drop-down menu.
|
||||
|
||||

|
||||
- **Taints**: Taints allow a node to repel a set of pods. You add or remove node taints on the node detail page. To add or delete taints, click **More** and select **Edit Taints** from the drop-down menu.
|
||||
|
||||
{{< notice note >}}
|
||||
Be careful when you add taints as they may cause unexpected behavior, leading to services unavailable. For more information, see [Taints and Tolerations](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/).
|
||||
|
|
|
|||
|
|
@ -1,34 +1,34 @@
|
|||
---
|
||||
title: "Persistent Volumes and Storage Classes"
|
||||
keywords: "storage, volume, pv, pvc, storage class, csi, Ceph RBD, Glusterfs, QingCloud, "
|
||||
keywords: "storage, volume, pv, pvc, storage class, csi, Ceph RBD, GlusterFS, QingCloud, "
|
||||
description: "Learn basic concepts of PVs, PVCs and storage classes, and demonstrate how to manage storage classes and PVCs in KubeSphere."
|
||||
linkTitle: "Persistent Volumes and Storage Classes"
|
||||
weight: 8400
|
||||
---
|
||||
|
||||
This tutorial describes the basic concepts of PVs, PVCs and storage classes and demonstrates how a cluster administrator can manage storage classes and persistent volumes in KubeSphere.
|
||||
This tutorial describes the basic concepts of PVs, PVCs, and storage classes and demonstrates how a cluster administrator can manage storage classes and persistent volumes in KubeSphere.
|
||||
|
||||
## Introduction
|
||||
|
||||
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. PVs are volume plugins like Volumes, but have a lifecycle independent of any individual Pod that uses the PV. PVs can be provisioned either [statically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#static) or [dynamically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#dynamic).
|
||||
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using storage classes. PVs are volume plugins like volumes, but have a lifecycle independent of any individual Pod that uses the PV. PVs can be provisioned either [statically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#static) or [dynamically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#dynamic).
|
||||
|
||||
A PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources.
|
||||
|
||||
KubeSphere supports [dynamic volume provisioning](https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/) based on storage classes to create PVs.
|
||||
|
||||
A [StorageClass](https://kubernetes.io/docs/concepts/storage/storage-classes) provides a way for administrators to describe the classes of storage they offer. Different classes might map to quality-of-service levels, or to backup policies, or to arbitrary policies determined by the cluster administrators. Each StorageClass has a provisioner that determines what volume plugin is used for provisioning PVs. This field must be specified. For which value to use, please read [the official Kubernetes documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner) or check with your storage administrator.
|
||||
A [storage class](https://kubernetes.io/docs/concepts/storage/storage-classes) provides a way for administrators to describe the classes of storage they offer. Different classes might map to quality-of-service levels, or to backup policies, or to arbitrary policies determined by the cluster administrators. Each storage class has a provisioner that determines what volume plugin is used for provisioning PVs. This field must be specified. For which value to use, please read [the official Kubernetes documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner) or check with your storage administrator.
|
||||
|
||||
The table below summarizes common volume plugins for various provisioners (storage systems).
|
||||
|
||||
| Type | Description |
|
||||
| -------------------- | ------------------------------------------------------------ |
|
||||
| In-tree | Built-in and run as part of Kubernetes, such as [RBD](https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd) and [Glusterfs](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs). For more plugins of this kind, see [Provisioner](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner). |
|
||||
| In-tree | Built-in and run as part of Kubernetes, such as [RBD](https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd) and [GlusterFS](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs). For more plugins of this kind, see [Provisioner](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner). |
|
||||
| External-provisioner | Deployed independently from Kubernetes, but works like an in-tree plugin, such as [nfs-client](https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client). For more plugins of this kind, see [External Storage](https://github.com/kubernetes-retired/external-storage). |
|
||||
| CSI | Container Storage Interface, a standard for exposing storage resources to workloads on COs (for example, Kubernetes), such as [QingCloud-csi](https://github.com/yunify/qingcloud-csi) and [Ceph-CSI](https://github.com/ceph/ceph-csi). For more plugins of this kind, see [Drivers](https://kubernetes-csi.github.io/docs/drivers.html). |
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
## Manage Storage Classes
|
||||
|
||||
|
|
@ -36,30 +36,25 @@ You need an account granted a role including the authorization of **Cluster Mana
|
|||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management/) with member clusters imported, you can select a specific cluster. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. On the **Cluster Management** page, go to **Storage Classes** under **Storage**, where you can create, update and delete a storage class.
|
||||
|
||||

|
||||
3. On the **Cluster Management** page, go to **Storage Classes** under **Storage**, where you can create, update, and delete a storage class.
|
||||
|
||||
4. To create a storage class, click **Create** and enter the basic information in the displayed dialog box. When you finish, click **Next**.
|
||||
|
||||
5. In KubeSphere, you can create storage classes for `QingCloud-CSI`, `Glusterfs`, and `Ceph RBD`. Alternatively, you can also create customized storage classes for other storage systems based on your needs. Select a type and click **Next**.
|
||||
|
||||

|
||||
|
||||

|
||||
5. In KubeSphere, you can create storage classes for `QingCloud-CSI`, `GlusterFS`, and `Ceph RBD`. Alternatively, you can also create customized storage classes for other storage systems based on your needs. Select a type and click **Next**.
|
||||
|
||||
### Common settings
|
||||
|
||||
Some settings are commonly used and shared among storage classes. You can find them as dashboard properties on the console, which are also indicated by fields or annotations in the StorageClass manifest. You can see the manifest file in YAML format by enabling **Edit Mode** in the upper-right corner.
|
||||
Some settings are commonly used and shared among storage classes. You can find them as dashboard parameters on the console, which are also indicated by fields or annotations in the StorageClass manifest. You can see the manifest file in YAML format by clicking **Edit YAML** in the upper-right corner.
|
||||
|
||||
Here are property descriptions of some commonly used fields in KubeSphere.
|
||||
Here are parameter descriptions of some commonly used fields in KubeSphere.
|
||||
|
||||
| Property | Description |
|
||||
| Parameter | Description |
|
||||
| :---- | :---- |
|
||||
| Allow Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. When it is set to `true`, PVs can be configured to be expandable. For more information, see [Allow Volume Expansion](https://kubernetes.io/docs/concepts/storage/storage-classes/#allow-volume-expansion). |
|
||||
| Reclaiming Policy | Specified by `reclaimPolicy` in the manifest. It can be set to `Delete` or `Retain` (default). For more information, see [Reclaim Policy](https://kubernetes.io/docs/concepts/storage/storage-classes/#reclaim-policy). |
|
||||
| Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. When it is set to `true`, PVs can be configured to be expandable. For more information, see [Allow Volume Expansion](https://kubernetes.io/docs/concepts/storage/storage-classes/#allow-volume-expansion). |
|
||||
| Reclaim Policy | Specified by `reclaimPolicy` in the manifest. For more information, see [Reclaim Policy](https://kubernetes.io/docs/concepts/storage/storage-classes/#reclaim-policy). |
|
||||
| Storage System | Specified by `provisioner` in the manifest. It determines what volume plugin is used for provisioning PVs. For more information, see [Provisioner](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner). |
|
||||
| Supported Access Mode | Specified by `metadata.annotations[storageclass.kubesphere.io/supported-access-modes]` in the manifest. It tells KubeSphere which [access mode](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes) is supported. |
|
||||
| Access Mode | Specified by `metadata.annotations[storageclass.kubesphere.io/supported-access-modes]` in the manifest. It tells KubeSphere which [access mode](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes) is supported. |
|
||||
| Volume Binding Mode | Specified by `volumeBindingMode` in the manifest. It determines what binding mode is used. **Delayed binding** means that a volume, after it is created, is bound to a volume instance when a Pod using this volume is created. **Immediate binding** means that a volume, after it is created, is immediately bound to a volume instance. |
|
||||
|
||||
For other settings, you need to provide different information for different storage plugins, which, in the manifest, are always indicated under the field `parameters`. They will be described in detail in the sections below. You can also refer to [Parameters](https://kubernetes.io/docs/concepts/storage/storage-classes/#parameters) in the official documentation of Kubernetes.
|
||||
|
||||
|
|
@ -74,40 +69,40 @@ QingCloud CSI is a CSI plugin on Kubernetes for the storage service of QingCloud
|
|||
|
||||
#### Settings
|
||||
|
||||

|
||||
|
||||
| Property | Description |
|
||||
| Parameter | Description |
|
||||
| :---- | :---- |
|
||||
| type | On the QingCloud platform, 0 represents high performance volumes. 2 represents high capacity volumes. 3 represents super high performance volumes. 5 represents Enterprise Server SAN. 100 represents standard volumes. 200 represents enterprise SSD. |
|
||||
| maxSize | The volume size upper limit. |
|
||||
| stepSize | The volume size increment. |
|
||||
| minSize | The volume size lower limit. |
|
||||
| fsType | Filesystem type of the volume: ext3, ext4 (default), xfs. |
|
||||
| tags | The ID of QingCloud Tag resource, split by commas. |
|
||||
| Type | On QingCloud Public Cloud Platform, 0 means high performance volume; 2 high capacity volume; 3 ultra-high performance volume; 5 enterprise server SAN (NeonSAN); 100 standard volume; 200 enterprise SSD. |
|
||||
| Maximum Size | Maximum size of the volume. |
|
||||
| Step Size | Step size of the volume. |
|
||||
| Minimum Size | Minimum size of the volume. |
|
||||
| File System Type | Supports ext3, ext4, and XFS. The default type is ext4. |
|
||||
| Tag | Add tags to the storage volume. Use commas to separate multiple tags. |
|
||||
|
||||
For more information about storage class parameters, see [QingCloud-CSI user guide](https://github.com/yunify/qingcloud-csi/blob/master/docs/user-guide.md#set-storage-class).
|
||||
|
||||
### Glusterfs
|
||||
### GlusterFS
|
||||
|
||||
Glusterfs is an in-tree storage plugin on Kubernetes, which means you don't need to install a volume plugin additionally.
|
||||
GlusterFS is an in-tree storage plugin on Kubernetes, which means you don't need to install a volume plugin additionally.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
The Glusterfs storage system has already been installed. See [GlusterFS Installation Documentation](https://www.gluster.org/install/) for more information.
|
||||
The GlusterFS storage system has already been installed. See [GlusterFS Installation Documentation](https://www.gluster.org/install/) for more information.
|
||||
|
||||
#### Settings
|
||||
|
||||
| Property | Description |
|
||||
| Parameter | Description |
|
||||
| :---- | :---- |
|
||||
| resturl | The Gluster REST service/Heketi service url which provision gluster volumes on demand. |
|
||||
| clusterid | The ID of the cluster which will be used by Heketi when provisioning the volume. |
|
||||
| restauthenabled | Gluster REST service authentication boolean that enables authentication to the REST server. |
|
||||
| restuser | The Glusterfs REST service/Heketi user who has access to create volumes in the Glusterfs Trusted Pool. |
|
||||
| secretNamespace, secretName | The Identification of Secret instance that contains user password to use when talking to Gluster REST service. |
|
||||
| gidMin, gidMax | The minimum and maximum value of GID range for the StorageClass. |
|
||||
| volumetype | The volume type and its parameters can be configured with this optional value. |
|
||||
| REST URL | Heketi REST URL that provisions volumes, for example, <Heketi Service cluster IP Address>:<Heketi Service port number>. |
|
||||
| Cluster ID | Gluster cluster ID. |
|
||||
| REST Authentication | Gluster enables authentication to the REST server. |
|
||||
| REST User | Username of Gluster REST service or Heketi service. |
|
||||
| Secret Namespace/Secret Name | Namespace of the Heketi user secret. |
|
||||
| Secret Name | Name of the Heketi user secret. |
|
||||
| Minimum GID | Minimum GID of the volume. |
|
||||
| Maximum GID | Maximum GID of the volume. |
|
||||
| Volume Type | Type of volume. The value can be none, replicate:<Replicate count>, or disperse:<Data>:<Redundancy count>. If the volume type is not set, the default volume type is replicate:3. |
|
||||
|
||||
For more information about StorageClass parameters, see [Glusterfs in Kubernetes Documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs).
|
||||
For more information about storage class parameters, see [GlusterFS in Kubernetes Documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs).
|
||||
|
||||
### Ceph RBD
|
||||
|
||||
|
|
@ -117,8 +112,6 @@ but the storage server must be installed before you create the storage class of
|
|||
As **hyperkube** images were [deprecated since 1.17](https://github.com/kubernetes/kubernetes/pull/85094), in-tree Ceph RBD may not work without **hyperkube**.
|
||||
Nevertheless, you can use [rbd provisioner](https://github.com/kubernetes-incubator/external-storage/tree/master/ceph/rbd) as a substitute, whose format is the same as in-tree Ceph RBD. The only different parameter is `provisioner` (i.e **Storage System** on the KubeSphere console). If you want to use rbd-provisioner, the value of `provisioner` must be `ceph.com/rbd` (Enter this value in **Storage System** in the image below). If you use in-tree Ceph RBD, the value must be `kubernetes.io/rbd`.
|
||||
|
||||

|
||||
|
||||
#### Prerequisites
|
||||
|
||||
- The Ceph server has already been installed. See [Ceph Installation Documentation](https://docs.ceph.com/en/latest/install/) for more information.
|
||||
|
|
@ -126,19 +119,19 @@ Nevertheless, you can use [rbd provisioner](https://github.com/kubernetes-incuba
|
|||
|
||||
#### Settings
|
||||
|
||||
| Property | Description |
|
||||
| Parameter | Description |
|
||||
| :---- | :---- |
|
||||
| monitors| The Ceph monitors, comma delimited. |
|
||||
| adminId| The Ceph client ID that is capable of creating images in the pool. |
|
||||
| adminSecretName| The Secret Name for `adminId`. |
|
||||
| adminSecretNamespace| The namespace for `adminSecretName`. |
|
||||
| pool | The Ceph RBD pool. |
|
||||
| Monitors| IP address of Ceph monitors. |
|
||||
| adminId| Ceph client ID that is capable of creating images in the pool. |
|
||||
| adminSecretName| Secret name of `adminId`. |
|
||||
| adminSecretNamespace| Namespace of `adminSecretName`. |
|
||||
| pool | Name of the Ceph RBD pool. |
|
||||
| userId | The Ceph client ID that is used to map the RBD image. |
|
||||
| userSecretName | The name of Ceph Secret for `userId` to map RBD image. |
|
||||
| userSecretNamespace | The namespace for `userSecretName`. |
|
||||
| fsType | The fsType that is supported by Kubernetes. |
|
||||
| imageFormat | The Ceph RBD image format, `1` or `2`. |
|
||||
| imageFeatures| This parameter is optional and should only be used if you set `imageFormat` to `2`. |
|
||||
| File System Type | File system type of the storage volume. |
|
||||
| imageFormat | Option of the Ceph volume. The value can be `1` or `2`. `imageFeatures` needs to be filled when you set imageFormat to `2`. |
|
||||
| imageFeatures| Additional function of the Ceph cluster. The value should only be set when you set imageFormat to `2`. |
|
||||
|
||||
For more information about StorageClass parameters, see [Ceph RBD in Kubernetes Documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd).
|
||||
|
||||
|
|
@ -164,14 +157,13 @@ It is not recommended that you use NFS storage for production (especially on Kub
|
|||
|
||||
#### Common Settings
|
||||
|
||||

|
||||
|
||||
| Property | Description |
|
||||
| Parameter | Description |
|
||||
| :---- | :---- |
|
||||
| Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. Select `No`. |
|
||||
| Reclaim Policy | Specified by `reclaimPolicy` in the manifest. The value is `Delete` by default. |
|
||||
| Storage System | Specified by `provisioner` in the manifest. If you install the storage class by [charts for nfs-client](https://github.com/kubesphere/helm-charts/tree/master/src/main/nfs-client-provisioner), it can be `cluster.local/nfs-client-nfs-client-provisioner`. |
|
||||
| Allow Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. Select `No`. |
|
||||
| Reclaiming Policy | Specified by `reclaimPolicy` in the manifest. The value is `Delete` by default. |
|
||||
| Supported Access Mode | Specified by `.metadata.annotations.storageclass.kubesphere.io/supported-access-modes` in the manifest. `ReadWriteOnce`, `ReadOnlyMany` and `ReadWriteMany` all are selected by default. |
|
||||
| Access Mode | Specified by `.metadata.annotations.storageclass.kubesphere.io/supported-access-modes` in the manifest. `ReadWriteOnce`, `ReadOnlyMany` and `ReadWriteMany` are all selected by default. |
|
||||
| Volume Binding Mode | Specified by `volumeBindingMode` in the manifest. It determines what binding mode is used. **Delayed binding** means that a volume, after it is created, is bound to a volume instance when a Pod using this volume is created. **Immediate binding** means that a volume, after it is created, is immediately bound to a volume instance. |
|
||||
|
||||
#### Parameters
|
||||
|
||||
|
|
@ -179,6 +171,55 @@ It is not recommended that you use NFS storage for production (especially on Kub
|
|||
| :---- | :---- | :----|
|
||||
| archiveOnDelete | Archive pvc when deleting | `true` |
|
||||
|
||||
### Storage class details page
|
||||
|
||||
After you create a storage class, click the name of the storage class to go to its details page. On the details page, click **Edit YAML** to edit the manifest file of the storage class, or click **More** to select an operation from the drop-down menu:
|
||||
|
||||
- **Set as Default Storage Class**: Set the storage class as the default storage class in the cluster. Only one default storage class is allowed in a KubeSphere cluster.
|
||||
- **Volume Management**: Manage volume features, including: **Volume Clone**, **Volume Snapshot**, and **Volume Expansion**. Before enabling any features, you should contact your system administrator to confirm that the features are supported by the storage system.
|
||||
- **Delete**: Delete the storage class and return to the previous page.
|
||||
|
||||
On the **Volumes** tab, view the volumes associated to the storage class.
|
||||
|
||||
## Manage Volumes
|
||||
|
||||
Once the storage class is created, you can create volumes with it. You can list, create, update and delete volumes in **Volumes** under **Storage** on the KubeSphere console. For more details, please see [Volume Management](../../project-user-guide/storage/volumes/).
|
||||
|
||||
## Manage Volume Instances
|
||||
|
||||
A volume in KubeSphere is a [persistent volume claim](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#persistentvolumeclaims) in Kubernetes, and a volume instance is a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) in Kubernetes.
|
||||
|
||||
### Volume instance list page
|
||||
|
||||
1. Log in to KubeSphere web console as `admin`. Click **Platform** in the upper-left corner, select **Cluster Management**, and click **Volumes** under **Storage**.
|
||||
2. Click the **Volume Instances** tab on the **Volumes** page to view the volume instance list page that provides the following information:
|
||||
- **Name**: Name of the volume instance. It is specified by the field `.metadata.name` in the manifest file of the volume instance.
|
||||
- **Status**: Current status of the volume instance. It is specified by the field `.status.phase` in the manifest file of the volume instance, including:
|
||||
- **Available**: The volume instance is available and not yet bound to a volume.
|
||||
- **Bound**: The volume instance is bound to a volume.
|
||||
- **Terminating**: The volume instance is being deleted.
|
||||
- **Failed**: The volume instance is unavailable.
|
||||
- **Capacity**: Capacity of the volume instance. It is specified by the field `.spec.capacity.storage` in the manifest file of the volume instance.
|
||||
- **Access Mode**: Access mode of the volume instance. It is specified by the field `.spec.accessModes` in the manifest file of the volume instance, including:
|
||||
- **RWO**: The volume instance can be mounted as read-write by a single node.
|
||||
- **ROX**: The volume instance can be mounted as read-only by multiple nodes.
|
||||
- **RWX**: The volume instance can be mounted as read-write by multiple nodes.
|
||||
- **Recycling Strategy**: Recycling strategy of the volume instance. It is specified by the field `.spec.persistentVolumeReclaimPolicy` in the manifest file of the volume instance, including:
|
||||
- **Retain**: When a volume is deleted, the volume instance still exists and requires manual reclamation.
|
||||
- **Delete**: Remove both the volume instance and the associated storage assets in the volume plugin infrastructure.
|
||||
- **Recycle**: Erase the data on the volume instance and make it available again for a new volume.
|
||||
- **Creation Time**: Time when the volume instance was created.
|
||||
3. Click <img src="/images/docs/common-icons/three-dots.png" width="15" /> on the right of a volume instance and select an operation from the drop-down menu:
|
||||
- **Edit**: Edit the YAML file of a volume instance.
|
||||
- **View YAML**: View the YAML file of the volume instance.
|
||||
- **Delete**: Delete the volume instance. A volume instance in the **Bound** status cannot be deleted.
|
||||
|
||||
### Volume instance details page
|
||||
|
||||
1. Click the name of a volume instance to go to its details page.
|
||||
2. On the details page, click **Edit Information** to edit the basic information of the volume instance. By clicking **More**, select an operation from the drop-down menu:
|
||||
- **View YAML**: View the YAML file of the volume instance.
|
||||
- **Delete**: Delete the volume instance and return to the list page. A volume instance in the **Bound** status cannot be deleted.
|
||||
3. Click the **Resource Status** tab to view the volumes to which the volume instance is bound.
|
||||
4. Click the **Metadata** tab to view the labels and annotations of the volume instance.
|
||||
5. Click the **Events** tab to view the events of the volume instance.
|
||||
|
|
|
|||
|
|
@ -1,10 +1,38 @@
|
|||
---
|
||||
title: "Configure DingTalk"
|
||||
keywords: 'KubeSphere, Kubernetes, custom, platform'
|
||||
description: ''
|
||||
linkTitle: "Configure DingTalk"
|
||||
weight: 8722
|
||||
title: "Configure DingTalk Notifications"
|
||||
keywords: 'KubeSphere, Kubernetes, DingTalk, Alerting, Notification'
|
||||
description: 'Learn how to configure a Dingtalk conversation or chatbot to receive platform notifications sent by KubeSphere.'
|
||||
linkTitle: "Configure DingTalk Notifications"
|
||||
weight: 8723
|
||||
---
|
||||
|
||||
TBD
|
||||
[DingTalk](https://www.dingtalk.com/en) is an enterprise-grade communication and collaboration platform. It integrates messaging, conference calling, task management, and other features into a single application.
|
||||
|
||||
This document describes how to configure a DingTalk conversation or chatbot to receive platform notifications sent by KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to have a user with the `platform-admin` role, for example, the `admin` user. For more information, see [Create Workspaces, Projects, Users and Roles](../../../../quick-start/create-workspace-and-project/).
|
||||
- You need to have a DingTalk account.
|
||||
- You need to create an applet on [DingTalk Admin Panel](https://oa.dingtalk.com/index.htm#/microApp/microAppList) and make necessary configurations according to [DingTalk API documentation](https://developers.dingtalk.com/document/app/create-group-session).
|
||||
|
||||
## Configure DingTalk Conversation or Chatbot
|
||||
|
||||
1. Log in to the KubeSphere console as `admin`.
|
||||
2. Click **Platform** in the upper-left corner and select **Platform Settings**.
|
||||
3. In the left navigation pane, click **Notification Configuration** under **Notification Management**.
|
||||
4. On the **DingTalk** page, select the **Conversation Settings** tab and configure the following parameters:
|
||||
- **AppKey**: The AppKey of the applet created on DingTalk.
|
||||
- **AppSecret**: The AppSecret of the applet created on DingTalk.
|
||||
- **Conversation ID**: The conversation ID obtained on DingTalk. To add a conversation ID, enter your conversation ID and click **Add** to add it.
|
||||
5. (Optional) On the **DingTalk** page, select the **DingTalk Chatbot** tab and configure the following parameters:
|
||||
- **Webhook URL**: The webhook URL of your DingTalk robot.
|
||||
- **Secret**: The secret of your DingTalk robot.
|
||||
- **Keywords**: The keywords you added to your DingTalk robot. To add a keyword, enter your keyword and click **Add** to add it.
|
||||
6. To specify notification conditions, select the **Notification Conditions** checkbox. Specify a label, an operator, and values and click **Add** to add it. You will receive only notifications that meet the conditions.
|
||||
7. After the configurations are complete, click **Send Test Message** to send a test message.
|
||||
8. If you successfully receive the test message, click **OK** to save the configurations.
|
||||
9. To enable DingTalk notifications, turn the toggle in the upper-right corner to **Enabled**.
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,46 +1,67 @@
|
|||
---
|
||||
title: "Configure Email Notifications"
|
||||
keywords: 'KubeSphere, Kubernetes, custom, platform'
|
||||
description: 'Configure your email server and add recipients to receive email notifications from alerting policies, kube-events, and kube-auditing.'
|
||||
description: 'Configure a email server and add recipients to receive email notifications.'
|
||||
linkTitle: "Configure Email Notifications"
|
||||
weight: 8721
|
||||
weight: 8722
|
||||
---
|
||||
|
||||
This tutorial demonstrates how to configure your email server and add recipients, who can receive email notifications for alerting policies.
|
||||
This tutorial demonstrates how to configure a email server and add recipients to receive email notifications of alerting policies.
|
||||
|
||||
## Configure the Email Server
|
||||
|
||||
1. Log in to the web console with an account granted the role `platform-admin`.
|
||||
1. Log in to the web console with a user granted the role `platform-admin`.
|
||||
|
||||
2. Click **Platform** in the top-left corner and select **Platform Settings**.
|
||||
2. Click **Platform** in the upper-left corner and select **Platform Settings**.
|
||||
|
||||
3. Navigate to **Email** under **Notification Management**.
|
||||
|
||||

|
||||
3. Navigate to **Notification Configuration** under **Notification Management**, and then choose **Email**.
|
||||
|
||||
4. Under **Server Settings**, configure your email server by filling in the following fields.
|
||||
|
||||
- **SMTP Server Address**: The SMTP server address that can provide email services. The port is usually `25`.
|
||||
- **SMTP Server Address**: The SMTP server address that provides email services. The port is usually `25`.
|
||||
- **Use SSL Secure Connection**: SSL can be used to encrypt emails, thereby improving the security of information transmitted by email. Usually you have to configure the certificate for the email server.
|
||||
- **SMTP User**: The SMTP account.
|
||||
- **SMTP Username**: The SMTP account.
|
||||
- **SMTP Password**: The SMTP account password.
|
||||
- **Sender Email Address**: The sender's email address. Customized email addresses are currently not supported.
|
||||
- **Sender Email Address**: The sender's email address.
|
||||
|
||||
5. Click **Save**.
|
||||
5. Click **OK**.
|
||||
|
||||
## Add Recipients
|
||||
## Recepient Settings
|
||||
|
||||
### Add recipients
|
||||
|
||||
1. Under **Recipient Settings**, enter a recipient's email address and click **Add**.
|
||||
|
||||
2. After it is added, the email address of a recipient will be listed under **Recipient Settings**. You can add up to 50 recipients and all of them will be able to receive email notifications of alerts.
|
||||
2. After it is added, the email address of a recipient will be listed under **Recipient Settings**. You can add up to 50 recipients and all of them will be able to receive email notifications.
|
||||
|
||||
3. To remove a recipient, hover over the email address you want to remove, then click the trash bin icon that appears.
|
||||
3. To remove a recipient, hover over the email address you want to remove, then click <img src="/images/docs/common-icons/trashcan.png" width="25" height="25" />.
|
||||
|
||||
4. To make sure notifications will be sent to your recipients, turn on **Receive Notifications** and click **Update**.
|
||||
### Set notification conditions
|
||||
|
||||
1. Select the checkbox on the left of **Notification Conditions** to set notification conditions.
|
||||
|
||||
- **Label**: Name, severity, or monitoring target of an alerting policy. You can select a label or customize a label.
|
||||
- **Operator**: Mapping between the label and the values. The operator includes **Includes values**, **Does not include values**, **Exists**, and **Does not exist**.
|
||||
- **Values**: Values associated with the label.
|
||||
{{< notice note >}}
|
||||
|
||||
- Operators **Includes values** and **Does not include values** require one or more label values. Use a carriage return to separate values.
|
||||
- Operators **Exists** and **Does not exist** determine whether a label exists, and do not require a label value.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
2. You can click **Add** to add notification conditions.
|
||||
|
||||
3. You can click <img src="/images/docs/common-icons/trashcan.png" width='25' height='25' /> on the right of a notification condition to delete the condition.
|
||||
|
||||
4. After the configurations are complete, you can click **Send Test Message** for verification.
|
||||
|
||||
5. On the upper-right corner, you can turn on the **Disabled** toggle to enbale notifications, or turn off the **Enabled** toggle to diable them.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you change the existing configuration, you must click **Update** to apply it.
|
||||
- After the notification conditions are set, the recepients will receive only notifications that meet the conditions.
|
||||
- If you change the existing configuration, you must click **OK** to apply it.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
@ -48,10 +69,6 @@ This tutorial demonstrates how to configure your email server and add recipients
|
|||
|
||||
After you configure the email server and add recipients, you need to enable [KubeSphere Alerting](../../../../pluggable-components/alerting/) and create an alerting policy for workloads or nodes. Once it is triggered, all the recipients can receive email notifications.
|
||||
|
||||
The image below is an email notification example:
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- If you update your email server configuration, KubeSphere will send email notifications based on the latest configuration.
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ title: "Configure Slack Notifications"
|
|||
keywords: 'KubeSphere, Kubernetes, Slack, notifications'
|
||||
description: 'Configure Slack notifications and add channels to receive notifications from alerting policies, kube-events, and kube-auditing.'
|
||||
linkTitle: "Configure Slack Notifications"
|
||||
weight: 8724
|
||||
weight: 8725
|
||||
---
|
||||
|
||||
This tutorial demonstrates how to configure Slack notifications and add channels, which can receive notifications for alerting policies.
|
||||
|
|
@ -24,24 +24,18 @@ You need to create a Slack app first so that it can help you send notifications
|
|||
|
||||
4. From the left navigation bar, select **OAuth & Permissions** under **Features**. On the **Auth & Permissions** page, scroll down to **Scopes** and click **Add an OAuth Scope** under **Bot Token Scopes** and **User Token Scopes** respectively. Select the **chart:write** permission for both scopes.
|
||||
|
||||

|
||||
|
||||
5. Scroll up to **OAuth Tokens & Redirect URLs** and click **Install to Workspace**. Grant the permission to access your workspace for the app and you can find created tokens under **OAuth Tokens for Your Team**.
|
||||
|
||||

|
||||
|
||||
## Configure Slack Notifications on the KubeSphere Console
|
||||
|
||||
You must provide the Slack token on the console for authentication so that KubeSphere can send notifications to your channel.
|
||||
|
||||
1. Log in to the web console with an account granted the role `platform-admin`.
|
||||
1. Log in to the web console with a user granted the role `platform-admin`.
|
||||
|
||||
2. Click **Platform** in the top-left corner and select **Platform Settings**.
|
||||
|
||||
3. Navigate to **Slack** under **Notification Management**.
|
||||
|
||||

|
||||
|
||||
4. For **Slack Token** under **Server Settings**, you can enter either a User OAuth Token or a Bot User OAuth Token for authentication. If you use the User OAuth Token, it is the app owner that will send notifications to your Slack channel. If you use the Bot User OAuth Token, it is the app that will send notifications.
|
||||
|
||||
5. Under **Channel Settings**, enter a Slack channel where you want to receive notifications and click **Add**.
|
||||
|
|
@ -56,26 +50,39 @@ You must provide the Slack token on the console for authentication so that KubeS
|
|||
|
||||
7. Click **Save**.
|
||||
|
||||
8. To make sure notifications will be sent to a Slack channel, turn on **Receive Notifications** and click **Update**.
|
||||
8. Select the checkbox on the left of **Notification Conditions** to set notification conditions.
|
||||
|
||||
- **Label**: Name, severity, or monitoring target of an alerting policy. You can select a label or customize a label.
|
||||
- **Operator**: Mapping between the label and the values. The operator includes **Includes values**, **Does not include values**, **Exists**, and **Does not exist**.
|
||||
- **Values**: Values associated with the label.
|
||||
{{< notice note >}}
|
||||
|
||||
- Operators **Includes values** and **Does not include values** require one or more label values. Use a carriage return to separate values.
|
||||
- Operators **Exists** and **Does not exist** determine whether a label exists, and do not require a label value.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
9. You can click **Add** to add notification conditions, or click <img src="/images/docs/common-icons/trashcan.png" width='25' height='25' /> on the right of a notification condition to delete the condition.
|
||||
|
||||
10. After the configurations are complete, you can click **Send Test Message** for verification.
|
||||
|
||||
11. To make sure notifications will be sent to a Slack channel, turn on **Receive Notifications** and click **Update**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you change the existing configuration, you must click **Update** to apply it.
|
||||
- After the notification conditions are set, the recepients will receive only notifications that meet the conditions.
|
||||
- If you change the existing configuration, you must click **OK** to apply it.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
9. If you want the app to be the notification sender, make sure it is in the channel. To add it in a Slack channel, enter `/invite @<app-name>` in your channel.
|
||||
|
||||

|
||||
|
||||
## Receive Slack Notifications
|
||||
|
||||
After you configure Slack notifications and add channels, you need to enable [KubeSphere Alerting](../../../../pluggable-components/alerting/) and create an alerting policy for workloads or nodes. Once it is triggered, all the channels in the list can receive notifications.
|
||||
|
||||
The image below is a Slack notification example:
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- If you update your Slack notification configuration, KubeSphere will send notifications based on the latest configuration.
|
||||
|
|
|
|||
|
|
@ -2,8 +2,8 @@
|
|||
title: "Configure Webhook Notifications"
|
||||
keywords: 'KubeSphere, Kubernetes, custom, platform, webhook'
|
||||
description: 'Configure a webhook server to receive platform notifications through the webhook.'
|
||||
linkTitle: "Configure Webhook notifications"
|
||||
weight: 8725
|
||||
linkTitle: "Configure Webhook Notifications"
|
||||
weight: 8726
|
||||
---
|
||||
|
||||
A webhook is a way for an app to send notifications triggered by specific events. It delivers information to other applications in real time, allowing users to receive notifications immediately.
|
||||
|
|
@ -12,7 +12,7 @@ This tutorial describes how to configure a webhook server to receive platform no
|
|||
|
||||
## Prerequisites
|
||||
|
||||
You need to prepare an account granted the `platform-admin` role. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../../quick-start/create-workspace-and-project/).
|
||||
You need to prepare a user granted the `platform-admin` role. For more information, see [Create Workspaces, Projects, Users and Roles](../../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Configure the Webhook Server
|
||||
|
||||
|
|
@ -20,21 +20,44 @@ You need to prepare an account granted the `platform-admin` role. For more infor
|
|||
|
||||
2. Click **Platform** in the upper-left corner and select **Platform Settings**.
|
||||
|
||||
3. In the left nevigation pane, click **Webhook** under **Notification Management**.
|
||||
3. In the left nevigation pane, click **Notification Configuration** under **Notification Management**, and select **Webhook**.
|
||||
|
||||
4. On the **Webhook** page, configure the following parameters:
|
||||
4. On the **Webhook** tab page, set the following parameters:
|
||||
|
||||
- **URL**: URL of the webhook server.
|
||||
- **Webhook URL**: URL of the webhook server.
|
||||
|
||||
- **Verification Type**: Webhook authentication method.
|
||||
- **No Auth**: Skips authentication. All notifications can be sent to the URL.
|
||||
- **Bearer Token**: Uses a token for authentication.
|
||||
- **Basic Auth**: Uses a username and password for authentication.
|
||||
- **No authentication**: Skips authentication. All notifications can be sent to the URL.
|
||||
- **Bearer token**: Uses a token for authentication.
|
||||
- **Basic authentication**: Uses a username and password for authentication.
|
||||
|
||||
{{< notice note>}}Currently, KubeSphere does not suppot TLS connections (HTTPS). You need to select **Skip TLS Certification** if you use an HTTPS URL.
|
||||
{{< notice note>}}Currently, KubeSphere does not suppot TLS connections (HTTPS). You need to select **Skip TLS verification (insecure)** if you use an HTTPS URL.
|
||||
|
||||
{{</notice>}}
|
||||
|
||||
5. Under **Notification Settings**, turn on/off the **Receive Notifications** toggle to start/stop sending notifications to the webhook.
|
||||
5. Select the checkbox on the left of **Notification Conditions** to set notification conditions.
|
||||
|
||||
6. Click **Save** after you finish.
|
||||
- **Label**: Name, severity, or monitoring target of an alerting policy. You can select a label or customize a label.
|
||||
- **Operator**: Mapping between the label and the values. The operator includes **Includes values**, **Does not include values**, **Exists**, and **Does not exist**.
|
||||
- **Values**: Values associated with the label.
|
||||
{{< notice note >}}
|
||||
|
||||
- Operators **Includes values** and **Does not include values** require one or more label values. Use a carriage return to separate values.
|
||||
- Operators **Exists** and **Does not exist** determine whether a label exists, and do not require a label value.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. You can click **Add** to add notification conditions, or click <img src="/images/docs/common-icons/trashcan.png" width='25' height='25' /> on the right of a notification condition to delete the condition.
|
||||
|
||||
7. After the configurations are complete, you can click **Send Test Message** for verification.
|
||||
|
||||
8. On the upper-right corner, you can turn on the **Disabled** toggle to enbale notifications, or turn off the **Enabled** toggle to diable them.
|
||||
|
||||
9. Click **OK** after you finish.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- After the notification conditions are set, the recepients will receive only notifications that meet the conditions.
|
||||
- If you change the existing configuration, you must click **OK** to apply it.
|
||||
|
||||
{{</ notice >}}
|
||||
|
|
|
|||
|
|
@ -1,10 +1,33 @@
|
|||
---
|
||||
title: "Configure WeCom"
|
||||
keywords: 'KubeSphere, Kubernetes, custom, platform'
|
||||
description: ''
|
||||
linkTitle: "Configure WeCom"
|
||||
weight: 8723
|
||||
title: "Configure WeCom Notifications"
|
||||
keywords: 'KubeSphere, Kubernetes, WeCom, Alerting, Notification'
|
||||
description: 'Learn how to configure a WeCom server to receive platform notifications sent by KubeSphere.'
|
||||
linkTitle: "Configure WeCom Notifications"
|
||||
weight: 8724
|
||||
---
|
||||
|
||||
[WeCom](https://work.weixin.qq.com/) is a communication platform for enterprises that includes convenient communication and office automation tools.
|
||||
|
||||
This document describes how to configure a WeCom server to receive platform notifications sent by KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to have a user with the `platform-admin` role, for example, the `admin` user. For more information, see [Create Workspaces, Projects, Users and Roles](../../../../quick-start/create-workspace-and-project/).
|
||||
- You need to have a [WeCom account](https://work.weixin.qq.com/wework_admin/register_wx?from=myhome).
|
||||
- You need to create a self-built application on the [WeCom Admin Console](https://work.weixin.qq.com/wework_admin/loginpage_wx) and obtain its AgentId and Secret.
|
||||
|
||||
## Configure WeCom Server
|
||||
|
||||
1. Log in to the KubeSphere console as `admin`.
|
||||
2. Click **Platform** in the upper-left corner and select **Platform Settings**.
|
||||
3. In the left navigation pane, click **Notification Configuration** under **Notification Management**.
|
||||
4. On the **WeCom** page, set the following fields under **Server Settings**:
|
||||
- **Corporation ID**: The Corporation ID of your WeCom account.
|
||||
- **App AgentId**: The AgentId of the self-built application.
|
||||
- **App Secret**: The Secret of the self-built application.
|
||||
5. To add notification recipients, select **User ID**, **Department ID**, or **Tag ID** under **Recipient Settings**, enter a corresponding ID obtained from your WeCom account, and click **Add** to add it.
|
||||
6. To specify notification conditions, select the **Notification Conditions** checkbox. Specify a label, an operator, and values and click **Add** to add it. You will receive only notifications that meet the conditions.
|
||||
7. After the configurations are complete, click **Send Test Message** to send a test message.
|
||||
8. If you successfully receive the test message, click **OK** to save the configurations.
|
||||
9. To enable WeCom notifications, turn the toggle in the upper-right corner to **Enabled**.
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,40 @@
|
|||
---
|
||||
title: "Customize Cluster Name in Notification Messages"
|
||||
keywords: 'KubeSphere, Kubernetes, Platform, Notification'
|
||||
description: 'Learn how to customize cluster name in notification messages sent by KubeSphere.'
|
||||
linkTitle: "Customize Cluster Name in Notification Messages"
|
||||
weight: 8721
|
||||
---
|
||||
|
||||
This document describes how to customize your cluster name in notification messages sent by KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need to have a user with the `platform-admin` role, for example, the `admin` user. For more information, see [Create Workspaces, Projects, Users and Roles](../../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Customize Cluster Name in Notification Messages
|
||||
|
||||
1. Log in to the KubeSphere console as `admin`.
|
||||
|
||||
2. Click <img src="/images/docs/common-icons/hammer.png" width="15" /> in the lower-right corner and select **Kubectl**.
|
||||
|
||||
3. In the displayed dialog box, run the following command:
|
||||
|
||||
```bash
|
||||
kubectl edit nm notification-manager
|
||||
```
|
||||
|
||||
4. Add a field `cluster` under `.spec.receiver.options.global` to customize your cluster name:
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
receivers:
|
||||
options:
|
||||
global:
|
||||
cluster: <Cluster name>
|
||||
```
|
||||
|
||||
5. When you finish, save the changes.
|
||||
|
||||
|
||||
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: "Build and Deploy a Maven Project"
|
||||
keywords: 'kubernetes, docker, devops, jenkins, maven'
|
||||
keywords: 'Kubernetes, Docker, DevOps, Jenkins, Maven'
|
||||
description: 'Learn how to build and deploy a Maven project using a KubeSphere pipeline.'
|
||||
linkTitle: "Build and Deploy a Maven Project"
|
||||
weight: 11430
|
||||
|
|
@ -10,7 +10,7 @@ weight: 11430
|
|||
|
||||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to have a [Docker Hub](http://www.dockerhub.com/) account.
|
||||
- You need to create a workspace, a DevOps project, and a user account, and this account needs to be invited into the DevOps project with the role of `operator`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project, and a user account, and this user needs to be invited into the DevOps project with the role of `operator`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Workflow for a Maven Project
|
||||
|
||||
|
|
@ -57,43 +57,35 @@ The Pod labeled `maven` uses the docker-in-docker network to run the pipeline. N
|
|||
### Prepare for the Maven project
|
||||
|
||||
- Ensure you build the Maven project successfully on the development device.
|
||||
- Add the Dockerfile to the project repository to build the image. For more information, refer to <https://github.com/kubesphere/devops-java-sample/blob/master/Dockerfile-online>.
|
||||
- Add the YAML file to the project repository to deploy the workload. For more information, refer to <https://github.com/kubesphere/devops-java-sample/tree/master/deploy/dev-ol>. If there are different environments, you need to prepare multiple deployment files.
|
||||
- Add the Dockerfile to the project repository to build the image. For more information, refer to <https://github.com/kubesphere/devops-maven-sample/blob/master/Dockerfile-online>.
|
||||
- Add the YAML file to the project repository to deploy the workload. For more information, refer to <https://github.com/kubesphere/devops-maven-sample/tree/master/deploy/dev-ol>. If there are different environments, you need to prepare multiple deployment files.
|
||||
|
||||
### Create credentials
|
||||
|
||||
| Credential ID | Type | Where to Use |
|
||||
| --------------- | ------------------- | ---------------------------- |
|
||||
| dockerhub-id | Account Credentials | Registry, such as Docker Hub |
|
||||
| dockerhub-id | Username and password | Registry, such as Docker Hub |
|
||||
| demo-kubeconfig | kubeconfig | Workload deployment |
|
||||
|
||||
For details, refer to the [Credential Management](../../how-to-use/credential-management/).
|
||||
|
||||

|
||||
|
||||
### Create a project for workloads
|
||||
|
||||
In this example, all workloads are deployed in `kubesphere-sample-dev`. You must create the project `kubesphere-sample-dev` in advance.
|
||||
|
||||

|
||||
|
||||
### Create a pipeline for the Maven project
|
||||
|
||||
1. Go to **Pipelines** of your DevOps project and click **Create** to create a pipeline named `maven`. For more information, see [Create a Pipeline - using Graphical Editing Panel](../../how-to-use/create-a-pipeline-using-graphical-editing-panel/).
|
||||
|
||||
2. Go to the detail page of the pipeline and click **Edit Jenkinsfile**.
|
||||
2. Go to the details page of the pipeline and click **Edit Jenkinsfile**.
|
||||
|
||||

|
||||
|
||||
3. Copy and paste the following content into the pop-up window. You must replace the value of `DOCKERHUB_NAMESPACE` with yours. When you finish editing, click **OK** to save the Jenkinsfile.
|
||||
3. Copy and paste the following content into the displayed dialog box. You must replace the value of `DOCKERHUB_NAMESPACE` with yours. When you finish editing, click **OK** to save the Jenkinsfile.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
agent {
|
||||
label 'maven'
|
||||
}
|
||||
}
|
||||
|
||||
parameters {
|
||||
string(name:'TAG_NAME',defaultValue: '',description:'')
|
||||
|
|
@ -105,21 +97,23 @@ In this example, all workloads are deployed in `kubesphere-sample-dev`. You must
|
|||
REGISTRY = 'docker.io'
|
||||
// need to replace by yourself dockerhub namespace
|
||||
DOCKERHUB_NAMESPACE = 'Docker Hub Namespace'
|
||||
APP_NAME = 'devops-java-sample'
|
||||
APP_NAME = 'devops-maven-sample'
|
||||
BRANCH_NAME = 'dev'
|
||||
PROJECT_NAME = 'kubesphere-sample-dev'
|
||||
}
|
||||
|
||||
stages {
|
||||
stage ('checkout scm') {
|
||||
steps {
|
||||
git branch: 'master', url: "https://github.com/kubesphere/devops-java-sample.git"
|
||||
// Please avoid committing your test changes to this repository
|
||||
git branch: 'master', url: "https://github.com/kubesphere/devops-maven-sample.git"
|
||||
}
|
||||
}
|
||||
|
||||
stage ('unit test') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'mvn clean -o -gs `pwd`/configuration/settings.xml test'
|
||||
sh 'mvn clean test'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -127,7 +121,7 @@ In this example, all workloads are deployed in `kubesphere-sample-dev`. You must
|
|||
stage ('build & push') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'mvn -o -Dmaven.test.skip=true -gs `pwd`/configuration/settings.xml clean package'
|
||||
sh 'mvn -Dmaven.test.skip=true clean package'
|
||||
sh 'docker build -f Dockerfile-online -t $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER .'
|
||||
withCredentials([usernamePassword(passwordVariable : 'DOCKER_PASSWORD' ,usernameVariable : 'DOCKER_USERNAME' ,credentialsId : "$DOCKER_CREDENTIAL_ID" ,)]) {
|
||||
sh 'echo "$DOCKER_PASSWORD" | docker login $REGISTRY -u "$DOCKER_USERNAME" --password-stdin'
|
||||
|
|
@ -138,9 +132,17 @@ In this example, all workloads are deployed in `kubesphere-sample-dev`. You must
|
|||
}
|
||||
|
||||
stage('deploy to dev') {
|
||||
steps {
|
||||
kubernetesDeploy(configs: 'deploy/dev-ol/**', enableConfigSubstitution: true, kubeconfigId: "$KUBECONFIG_CREDENTIAL_ID")
|
||||
}
|
||||
steps {
|
||||
container ('maven') {
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: env.KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < deploy/all-in-one/devops-sample.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -148,22 +150,12 @@ In this example, all workloads are deployed in `kubesphere-sample-dev`. You must
|
|||
|
||||
4. You can see stages and steps are automatically created on graphical editing panels.
|
||||
|
||||

|
||||
|
||||
### Run and test
|
||||
|
||||
1. Click **Run**, enter `v1` for **TAG_NAME** in the dialog that appears, and then click **OK** to run the pipeline.
|
||||
1. Click **Run**, enter `v1` for **TAG_NAME** in the displayed dialog box, and then click **OK** to run the pipeline.
|
||||
|
||||

|
||||
2. When the pipeline runs successfully, you can go to the **Run Records** tab to view its details.
|
||||
|
||||
2. When the pipeline runs successfully, you can go to the **Activity** tab to view its details.
|
||||
3. In the project of `kubesphere-sample-dev`, new workloads were created.
|
||||
|
||||

|
||||
|
||||
3. In the project of `kubesphere-sample-dev`, there are new workloads created.
|
||||
|
||||

|
||||
|
||||
4. You can view the access address of the Service as below.
|
||||
|
||||

|
||||
4. On the **Services** page, view the external access information about the Service created.
|
||||
|
|
|
|||
|
|
@ -12,11 +12,11 @@ This tutorial demonstrates how to create a multi-cluster pipeline on KubeSphere.
|
|||
|
||||
## Prerequisites
|
||||
|
||||
- You need to have three Kubernetes clusters with KubeSphere installed. Choose one cluster as your Host Cluster and the other two as your Member Clusters. For more information about cluster roles and how to build a multi-cluster environment on KubeSphere, refer to [Multi-cluster Management](../../../multicluster-management/).
|
||||
- You need to set your Member Clusters as [public clusters](../../../cluster-administration/cluster-settings/cluster-visibility-and-authorization/#make-a-cluster-public). Alternatively, you can [set cluster visibility after a workspace is created](../../../cluster-administration/cluster-settings/cluster-visibility-and-authorization/#set-cluster-visibility-after-a-workspace-is-created).
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/) on your Host Cluster.
|
||||
- You need to have three Kubernetes clusters with KubeSphere installed. Choose one cluster as your host cluster and the other two as your member clusters. For more information about cluster roles and how to build a multi-cluster environment on KubeSphere, refer to [Multi-cluster Management](../../../multicluster-management/).
|
||||
- You need to set your member clusters as [public clusters](../../../cluster-administration/cluster-settings/cluster-visibility-and-authorization/#make-a-cluster-public). Alternatively, you can [set cluster visibility after a workspace is created](../../../cluster-administration/cluster-settings/cluster-visibility-and-authorization/#set-cluster-visibility-after-a-workspace-is-created).
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/) on your host cluster.
|
||||
- You need to integrate SonarQube into your pipeline. For more information, refer to [Integrate SonarQube into Pipelines](../../how-to-integrate/sonarqube/).
|
||||
- You need to create four accounts on your Host Cluster: `ws-manager`, `ws-admin`, `project-admin`, and `project-regular`, and grant these accounts different roles. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-1-create-an-account).
|
||||
- You need to create four accounts on your host cluster: `ws-manager`, `ws-admin`, `project-admin`, and `project-regular`, and grant these accounts different roles. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-1-create-an-account).
|
||||
|
||||
## Workflow Overview
|
||||
|
||||
|
|
@ -34,39 +34,31 @@ See the table below for the role of each cluster.
|
|||
|
||||
| Cluster Name | Cluster Role | Usage |
|
||||
| ------------ | -------------- | ----------- |
|
||||
| host | Host Cluster | Testing |
|
||||
| shire | Member Cluster | Production |
|
||||
| rohan | Member Cluster | Development |
|
||||
| host | Host cluster | Testing |
|
||||
| shire | Member cluster | Production |
|
||||
| rohan | Member cluster | Development |
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
These Kubernetes clusters can be hosted across different cloud providers and their Kubernetes versions can also vary. Recommended Kubernetes versions for KubeSphere v3.1.0: v1.17.9, v1.18.8, v1.19.8 and v1.20.4.
|
||||
These Kubernetes clusters can be hosted across different cloud providers and their Kubernetes versions can also vary. Recommended Kubernetes versions for KubeSphere 3.2.1: v1.19.x, v1.20.x, v1.21.x, and v1.22.x (experimental).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Step 2: Create a workspace
|
||||
|
||||
1. Log in to the web console of the Host Cluster as `ws-manager`. On the **Workspaces** page, click **Create**.
|
||||
1. Log in to the web console of the host cluster as `ws-manager`. On the **Workspaces** page, click **Create**.
|
||||
|
||||
2. On the **Basic Information** page, name the workspace `devops-multicluster`, select `ws-admin` for **Administrator**, and click **Next**.
|
||||
|
||||

|
||||
3. On the **Cluster Settings** page, select all three clusters and click **Create**.
|
||||
|
||||
3. On the **Select Clusters** page, select all three clusters and click **Create**.
|
||||
|
||||

|
||||
|
||||
4. The workspace created will display in the list. You need to log out of the console and log back in as `ws-admin` to invite both `project-admin` and `project-regular` to the workspace and grant them the role `workspace-self-provisioner` and `workspace-viewer` respectively. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-2-create-a-workspace).
|
||||
|
||||

|
||||
4. The workspace created is displayed in the list. You need to log out of the console and log back in as `ws-admin` to invite both `project-admin` and `project-regular` to the workspace and grant them the role `workspace-self-provisioner` and `workspace-viewer` respectively. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-2-create-a-workspace).
|
||||
|
||||
### Step 3: Create a DevOps project
|
||||
|
||||
1. Log out of the console and log back in as `project-admin`. Go to the **DevOps Projects** page and click **Create**.
|
||||
|
||||
2. In the dialog that appears, enter `multicluster-demo` for **Name**, select **host** for **Cluster Settings**, and then click **OK**.
|
||||
|
||||

|
||||
2. In the displayed dialog box, enter `multicluster-demo` for **Name**, select **host** for **Cluster Settings**, and then click **OK**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -74,13 +66,11 @@ These Kubernetes clusters can be hosted across different cloud providers and the
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
3. The DevOps project created will display in the list. Make sure you invite the account `project-regular` to this project with the role `operator`. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-5-create-a-devops-project-optional).
|
||||
|
||||

|
||||
3. The DevOps project created is displayed in the list. Make sure you invite the `project-regular` user to this project and assign it the `operator` role. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-5-create-a-devops-project-optional).
|
||||
|
||||
### Step 4: Create projects on clusters
|
||||
|
||||
You must create the projects as shown in the table below in advance. Make sure you invite the account `project-regular` to these projects with the role `operator`. For more information about how to create a project, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/#step-3-create-a-project).
|
||||
You must create the projects as shown in the table below in advance. Make sure you invite the `project-regular` user to these projects and assign it the `operator` role. For more information about how to create a project, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/#step-3-create-a-project).
|
||||
|
||||
| Cluster Name | Usage | Project Name |
|
||||
| ------------ | ----------- | ---------------------- |
|
||||
|
|
@ -92,37 +82,31 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
|
||||
1. Log out of the console and log back in as `project-regular`. On the **DevOps Projects** page, click the DevOps project `multicluster-demo`.
|
||||
|
||||
2. On the **DevOps Credentials** page, you need to create the credentials as shown in the table below. For more information about how to create credentials, refer to [Credential Management](../../how-to-use/credential-management/#create-credentials) and [Create a Pipeline Using a Jenkinsfile](../../how-to-use/create-a-pipeline-using-jenkinsfile/#step-1-create-credentials).
|
||||
2. On the **Credentials** page, you need to create the credentials as shown in the table below. For more information about how to create credentials, refer to [Credential Management](../../how-to-use/credential-management/#create-credentials) and [Create a Pipeline Using a Jenkinsfile](../../how-to-use/create-a-pipeline-using-jenkinsfile/#step-1-create-credentials).
|
||||
|
||||
| Credential ID | Type | Where to Use |
|
||||
| ------------- | ------------------- | ---------------------------------- |
|
||||
| host | kubeconfig | The Host Cluster for testing |
|
||||
| shire | kubeconfig | The Member Cluster for production |
|
||||
| rohan | kubeconfig | The Member Cluster for development |
|
||||
| host | kubeconfig | The host cluster for testing |
|
||||
| shire | kubeconfig | The member cluster for production |
|
||||
| rohan | kubeconfig | The member cluster for development |
|
||||
| dockerhub-id | Account Credentials | Docker Hub |
|
||||
| sonar-token | Secret Text | SonarQube |
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You have to manually enter the kubeconfig of your Member Clusters when creating the kubeconfig credentials `shire` and `rohan`. Make sure your Host Cluster can access the APIServer addresses of your Member Clusters.
|
||||
You have to manually enter the kubeconfig of your member clusters when creating the kubeconfig credentials `shire` and `rohan`. Make sure your host cluster can access the API Server addresses of your member clusters.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. You will have five credentials in total.
|
||||
|
||||

|
||||
3. Five credentials are created in total.
|
||||
|
||||
### Step 6: Create a pipeline
|
||||
|
||||
1. Go to the **Pipelines** page and click **Create**. In the dialog that appears, enter `build-and-deploy-application` for **Name** and click **Next**.
|
||||
1. Go to the **Pipelines** page and click **Create**. In the displayed dialog box, enter `build-and-deploy-application` for **Name** and click **Next**.
|
||||
|
||||

|
||||
2. On the **Advanced Settings** tab, click **Create** to use the default settings.
|
||||
|
||||
2. In the **Advanced Settings** tab, click **Create** to use the default settings.
|
||||
|
||||
3. The pipeline created will display in the list. Click it to go to its detail page.
|
||||
|
||||

|
||||
3. The pipeline created is displayed in the list. Click its name to go to the details page.
|
||||
|
||||
4. Click **Edit Jenkinsfile** and copy and paste the following contents. Make sure you replace the value of `DOCKERHUB_NAMESPACE` with your own value, and then click **OK**.
|
||||
|
||||
|
|
@ -145,7 +129,7 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
|
||||
REGISTRY = 'docker.io'
|
||||
DOCKERHUB_NAMESPACE = 'your Docker Hub account ID'
|
||||
APP_NAME = 'devops-java-sample'
|
||||
APP_NAME = 'devops-maven-sample'
|
||||
SONAR_CREDENTIAL_ID = 'sonar-token'
|
||||
TAG_NAME = "SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER"
|
||||
}
|
||||
|
|
@ -153,16 +137,15 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
stage('checkout') {
|
||||
steps {
|
||||
container('maven') {
|
||||
git branch: 'master', url: 'https://github.com/kubesphere/devops-java-sample.git'
|
||||
git branch: 'master', url: 'https://github.com/kubesphere/devops-maven-sample.git'
|
||||
}
|
||||
}
|
||||
}
|
||||
stage('unit test') {
|
||||
steps {
|
||||
container('maven') {
|
||||
sh 'mvn clean -o -gs `pwd`/configuration/settings.xml test'
|
||||
sh 'mvn clean test'
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
stage('sonarqube analysis') {
|
||||
|
|
@ -170,7 +153,7 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
container('maven') {
|
||||
withCredentials([string(credentialsId: "$SONAR_CREDENTIAL_ID", variable: 'SONAR_TOKEN')]) {
|
||||
withSonarQubeEnv('sonar') {
|
||||
sh "mvn sonar:sonar -o -gs `pwd`/configuration/settings.xml -Dsonar.login=$SONAR_TOKEN"
|
||||
sh "mvn sonar:sonar -Dsonar.login=$SONAR_TOKEN"
|
||||
}
|
||||
|
||||
}
|
||||
|
|
@ -181,15 +164,13 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
stage('build & push') {
|
||||
steps {
|
||||
container('maven') {
|
||||
sh 'mvn -o -Dmaven.test.skip=true -gs `pwd`/configuration/settings.xml clean package'
|
||||
sh 'mvn -Dmaven.test.skip=true clean package'
|
||||
sh 'docker build -f Dockerfile-online -t $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER .'
|
||||
withCredentials([usernamePassword(passwordVariable : 'DOCKER_PASSWORD' ,usernameVariable : 'DOCKER_USERNAME' ,credentialsId : "$DOCKER_CREDENTIAL_ID" ,)]) {
|
||||
sh 'echo "$DOCKER_PASSWORD" | docker login $REGISTRY -u "$DOCKER_USERNAME" --password-stdin'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER'
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
stage('push latest') {
|
||||
|
|
@ -198,29 +179,51 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
sh 'docker tag $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:latest '
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:latest '
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
stage('deploy to dev') {
|
||||
steps {
|
||||
kubernetesDeploy(configs: 'deploy/dev-ol/**', enableConfigSubstitution: true, kubeconfigId: "$DEV_KUBECONFIG_CREDENTIAL_ID")
|
||||
container('maven') {
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: env.DEV_KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < deploy/dev-all-in-one/devops-sample.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stage('deploy to staging') {
|
||||
steps {
|
||||
input(id: 'deploy-to-staging', message: 'deploy to staging?')
|
||||
kubernetesDeploy(configs: 'deploy/prod-ol/**', enableConfigSubstitution: true, kubeconfigId: "$TEST_KUBECONFIG_CREDENTIAL_ID")
|
||||
container('maven') {
|
||||
input(id: 'deploy-to-staging', message: 'deploy to staging?')
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: env.TEST_KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < deploy/prod-all-in-one/devops-sample.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
stage('deploy to production') {
|
||||
steps {
|
||||
input(id: 'deploy-to-production', message: 'deploy to production?')
|
||||
kubernetesDeploy(configs: 'deploy/prod-ol/**', enableConfigSubstitution: true, kubeconfigId: "$PROD_KUBECONFIG_CREDENTIAL_ID")
|
||||
container('maven') {
|
||||
input(id: 'deploy-to-production', message: 'deploy to production?')
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: env.PROD_KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < deploy/prod-all-in-one/devops-sample.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
|
@ -231,33 +234,18 @@ You must create the projects as shown in the table below in advance. Make sure y
|
|||
|
||||
5. After the pipeline is created, you can view its stages and steps on the graphical editing panel as well.
|
||||
|
||||

|
||||
|
||||
### Step 7: Run the pipeline and check the results
|
||||
|
||||
1. Click **Run** to run the pipeline. The pipeline will pause when it reaches the stage **deploy to staging** as resources have been deployed to the cluster for development. You need to manually click **Proceed** twice to deploy resources to the testing cluster `host` and the production cluster `shire`.
|
||||
|
||||

|
||||
2. After a while, you can see the pipeline status shown as **Successful**.
|
||||
|
||||
2. After a while, you can see the pipeline status shown as **Success**.
|
||||
3. Check the pipeline running logs by clicking **View Logs** in the upper-right corner. For each stage, you click it to inspect logs, which can be downloaded to your local machine for further analysis.
|
||||
|
||||

|
||||
4. Once the pipeline runs successfully, click **Code Check** to check the results through SonarQube.
|
||||
|
||||
3. Check the pipeline running logs by clicking **Show Logs** in the upper-right corner. For each stage, you click it to inspect logs, which can be downloaded to your local machine for further analysis.
|
||||
5. Go to the **Projects** page, and you can view the resources deployed in different projects across the clusters by selecting a specific cluster from the drop-down list.
|
||||
|
||||

|
||||
|
||||
4. Once the pipeline runs successfully, click **Code Quality** to check the results through SonarQube.
|
||||
|
||||

|
||||
|
||||
5. Go to the **Projects** page and you can view the resources deployed in different projects across the clusters by selecting a specific cluster from the drop-down list.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,70 @@
|
|||
---
|
||||
title: "Customize Jenkins Agent"
|
||||
keywords: "KubeSphere, Kubernetes, DevOps, Jenkins, Agent"
|
||||
description: "Learn how to customize a Jenkins agent on KubeSphere."
|
||||
linkTitle: "Customize Jenkins Agent"
|
||||
Weight: 11460
|
||||
---
|
||||
|
||||
If you need to use a Jenkins agent that runs on a specific environment, for example, JDK 11, you can customize a Jenkins agent on KubeSphere.
|
||||
|
||||
This document describes how to customize a Jenkins agent on KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You have enabled [the KubeSphere DevOps System](../../../pluggable-components/devops/).
|
||||
|
||||
## Customize a Jenkins agent
|
||||
|
||||
1. Log in to the web console of KubeSphere as `admin`.
|
||||
|
||||
2. Click **Platform** in the upper-left corner, select **Cluster Management**, and click **Configmaps** under **Configuration** on the left navigation pane.
|
||||
|
||||
3. On the **Configmaps** page, enter `jenkins-casc-config` in the search box and press **Enter**.
|
||||
|
||||
4. Click `jenkins-casc-config` to go to its details page, click **More**, and select **Edit YAML**.
|
||||
|
||||
5. In the displayed dialog box, enter the following code under the `data.jenkins_user.yaml:jenkins.clouds.kubernetes.templates` section and click **OK**.
|
||||
|
||||
```yaml
|
||||
- name: "maven-jdk11" # The name of the customized Jenkins agent.
|
||||
label: "maven jdk11" # The label of the customized Jenkins agent. To specify multiple labels, use spaces to seperate them.
|
||||
inheritFrom: "maven" # The name of the existing pod template from which this customzied Jenkins agent inherits.
|
||||
containers:
|
||||
- name: "maven" # The container name specified in the existing pod template from which this customzied Jenkins agent inherits.
|
||||
image: "kubespheredev/builder-maven:v3.2.0jdk11" # This image is used for testing purposes only. You can use your own images.
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
Make sure you follow the indentation in the YAML file.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. Wait for at least 70 seconds until your changes are automatically reloaded.
|
||||
|
||||
7. To use the custom Jenkins agent, refer to the following sample Jenkinsfile to specify the label and container name of the custom Jenkins agent accordingly when creating a pipeline.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven && jdk11'
|
||||
}
|
||||
}
|
||||
stages {
|
||||
stage('Print Maven and JDK version') {
|
||||
steps {
|
||||
container('maven') {
|
||||
sh '''
|
||||
mvn -v
|
||||
java -version
|
||||
'''
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: "Build and Deploy a Go Project"
|
||||
keywords: 'Kubernetes, docker, devops, jenkins, go, KubeSphere'
|
||||
keywords: 'Kubernetes, docker, DevOps, Jenkins, Go, KubeSphere'
|
||||
description: 'Learn how to build and deploy a Go project using a KubeSphere pipeline.'
|
||||
linkTitle: "Build and Deploy a Go Project"
|
||||
weight: 11410
|
||||
|
|
@ -10,37 +10,25 @@ weight: 11410
|
|||
|
||||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account.
|
||||
- You need to create a workspace, a DevOps project, a project, and an account (`project-regular`). This account needs to be invited to the DevOps project and the project for deploying your workload with the role `operator`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project, a project, and a user (`project-regular`). This account needs to be invited to the DevOps project and the project for deploying your workload with the role `operator`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Create a Docker Hub Access Token
|
||||
|
||||
1. Log in to [Docker Hub](https://hub.docker.com/) and select **Account Settings** from the menu in the top-right corner.
|
||||
1. Log in to [Docker Hub](https://hub.docker.com/), click your account in the upper-right corner, and select **Account Settings** from the menu.
|
||||
|
||||

|
||||
2. Click **Security** in the left navigation pane and then click **New Access Token**.
|
||||
|
||||
2. Click **Security** and **New Access Token**.
|
||||
3. In the displayed dialog box, enter a token name (`go-project-token`) and click **Create**.
|
||||
|
||||

|
||||
|
||||
3. Enter the token name and click **Create**.
|
||||
|
||||

|
||||
|
||||
4. Click **Copy and Close** and remember to save the access token.
|
||||
|
||||

|
||||
4. Click **Copy and Close** and make sure you save the access token.
|
||||
|
||||
## Create Credentials
|
||||
|
||||
You need to create credentials in KubeSphere for the access token created so that the pipeline can interact with Docker Hub for imaging pushing. Besides, you also create kubeconfig credentials for the access to the Kubernetes cluster.
|
||||
|
||||
1. Log in to the web console of KubeSphere as `project-regular`. Go to your DevOps project and click **Create** in **Credentials**.
|
||||
1. Log in to the web console of KubeSphere as `project-regular`. In your DevOps project, go to **Credentials** under **DevOps Project Settings** and then click **Create** on the **Credentials** page.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, set a **Credential ID**, which will be used later in the Jenkinsfile, and select **Account Credentials** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Token/Password**. When you finish, click **OK**.
|
||||
|
||||

|
||||
2. In the displayed dialog box, set a **Name**, which is used later in the Jenkinsfile, and select **Username and password** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Password/Token**. When you finish, click **OK**.
|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
|
|
@ -48,9 +36,7 @@ For more information about how to create credentials, see [Credential Management
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Click **Create** again and select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current user account. Set a **Credential ID** and click **OK**.
|
||||
|
||||

|
||||
3. Click **Create** again and select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current user account. Set a **Name** and click **OK**.
|
||||
|
||||
## Create a Pipeline
|
||||
|
||||
|
|
@ -58,32 +44,22 @@ With the above credentials ready, you can create a pipeline using an example Jen
|
|||
|
||||
1. To create a pipeline, click **Create** on the **Pipelines** page.
|
||||
|
||||

|
||||
2. Set a name in the displayed dialog box and click **Next**.
|
||||
|
||||
2. Set a name in the pop-up window and click **Next** directly.
|
||||
|
||||

|
||||
|
||||
3. In this tutorial, you can use default values for all the fields. In **Advanced Settings**, click **Create** directly.
|
||||
|
||||

|
||||
3. In this tutorial, you can use default values for all the fields. On the **Advanced Settings** tab, click **Create**.
|
||||
|
||||
## Edit the Jenkinsfile
|
||||
|
||||
1. In the pipeline list, click this pipeline to go to its detail page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
1. In the pipeline list, click the pipeline name to go to its details page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
|
||||

|
||||
2. Copy and paste all the content below to the displayed dialog box as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, and `PROJECT_NAME` with yours. When you finish, click **OK**.
|
||||
|
||||
2. Copy and paste all the content below to the pop-up window as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, and `PROJECT_NAME` with yours. When you finish, click **OK**.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
}
|
||||
label 'go'
|
||||
}
|
||||
|
||||
|
||||
environment {
|
||||
// the address of your Docker Hub registry
|
||||
REGISTRY = 'docker.io'
|
||||
|
|
@ -91,7 +67,7 @@ With the above credentials ready, you can create a pipeline using an example Jen
|
|||
DOCKERHUB_USERNAME = 'Docker Hub Username'
|
||||
// Docker image name
|
||||
APP_NAME = 'devops-go-sample'
|
||||
// ‘dockerhubid’ is the credentials ID you created in KubeSphere with Docker Hub Access Token
|
||||
// 'dockerhubid' is the credentials ID you created in KubeSphere with Docker Hub Access Token
|
||||
DOCKERHUB_CREDENTIAL = credentials('dockerhubid')
|
||||
// the kubeconfig credentials ID you created in KubeSphere
|
||||
KUBECONFIG_CREDENTIAL_ID = 'go'
|
||||
|
|
@ -102,31 +78,37 @@ With the above credentials ready, you can create a pipeline using an example Jen
|
|||
stages {
|
||||
stage('docker login') {
|
||||
steps{
|
||||
container ('maven') {
|
||||
container ('go') {
|
||||
sh 'echo $DOCKERHUB_CREDENTIAL_PSW | docker login -u $DOCKERHUB_CREDENTIAL_USR --password-stdin'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
stage('build & push') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'git clone https://github.com/yuswift/devops-go-sample.git'
|
||||
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
|
||||
}
|
||||
}
|
||||
}
|
||||
stage ('deploy app') {
|
||||
steps {
|
||||
container('maven') {
|
||||
kubernetesDeploy(configs: 'devops-go-sample/manifest/deploy.yaml', kubeconfigId: "$KUBECONFIG_CREDENTIAL_ID")
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
stage('build & push') {
|
||||
steps {
|
||||
container ('go') {
|
||||
sh 'git clone https://github.com/yuswift/devops-go-sample.git'
|
||||
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
|
||||
}
|
||||
}
|
||||
}
|
||||
stage ('deploy app') {
|
||||
steps {
|
||||
container ('go') {
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: env.KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < devops-go-sample/manifest/deploy.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -136,25 +118,15 @@ If your pipeline runs successfully, images will be pushed to Docker Hub. If you
|
|||
|
||||
## Run the Pipeline
|
||||
|
||||
1. After you finish the Jenkinsfile, you can see graphical panels display on the dashboard. Click **Run** to run the pipeline.
|
||||
1. After you finish the Jenkinsfile, you can see graphical panels are displayed on the dashboard. Click **Run** to run the pipeline.
|
||||
|
||||

|
||||
|
||||
2. In **Activity**, you can see the status of the pipeline. It may take a while before it successfully runs.
|
||||
|
||||

|
||||
2. In **Run Records**, you can see the status of the pipeline. It may take a while before it successfully runs.
|
||||
|
||||
|
||||
## Verify Results
|
||||
|
||||
1. A **Deployment** will be created in the project specified in the Jenkinsfile if the pipeline runs successfully.
|
||||
1. A **Deployment** is created in the project specified in the Jenkinsfile if the pipeline runs successfully.
|
||||
|
||||

|
||||
|
||||
2. Check whether the image is pushed to Docker Hub as shown below:
|
||||
|
||||

|
||||
|
||||

|
||||
2. Check the image that is pushed to Docker Hub.
|
||||
|
||||
|
||||
|
|
@ -10,39 +10,27 @@ weight: 11420
|
|||
|
||||
- You need to [enable the multi-cluster feature](../../../../docs/multicluster-management/) and create a workspace with your multiple clusters.
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account.
|
||||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/) on your Host Cluster.
|
||||
- You need to use an account (for example, `project-admin`) with the role of `workspace-self-provisioner` to create a multi-cluster project and a DevOps project on the Host Cluster. This tutorial creates a multi-cluster project on the Host Cluster and one Member Cluster.
|
||||
- You need to invite an account (for example, `project-regular`) to the DevOps project and grant it the role of `operator`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/), [Multi-cluster Management](../../../multicluster-management/) and [Multi-cluster Projects](../../../project-administration/project-and-multicluster-project/#multi-cluster-projects).
|
||||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/) on your host cluster.
|
||||
- You need to use a user (for example, `project-admin`) with the role of `workspace-self-provisioner` to create a multi-cluster project and a DevOps project on the host cluster. This tutorial creates a multi-cluster project on the host cluster and one member cluster.
|
||||
- You need to invite a user (for example, `project-regular`) to the DevOps project and grant it the role of `operator`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/), [Multi-cluster Management](../../../multicluster-management/) and [Multi-cluster Projects](../../../project-administration/project-and-multicluster-project/#multi-cluster-projects).
|
||||
|
||||
## Create a Docker Hub Access Token
|
||||
|
||||
1. Log in to [Docker Hub](https://hub.docker.com/) and select **Account Settings** from the menu in the top-right corner.
|
||||
1. Log in to [Docker Hub](https://hub.docker.com/), click your account in the upper-right corner, and select **Account Settings** from the menu.
|
||||
|
||||

|
||||
2. Click **Security** in the left navigation pane and then click **New Access Token**.
|
||||
|
||||
2. Click **Security** and **New Access Token**.
|
||||
3. In the displayed dialog box, enter a token name (`go-project-token`) and click **Create**.
|
||||
|
||||

|
||||
|
||||
3. Enter the token name and click **Create**.
|
||||
|
||||

|
||||
|
||||
4. Click **Copy and Close** and remember to save the access token.
|
||||
|
||||

|
||||
4. Click **Copy and Close** and make sure you save the access token.
|
||||
|
||||
## Create Credentials
|
||||
|
||||
You need to create credentials in KubeSphere for the access token created so that the pipeline can interact with Docker Hub for pushing images. Besides, you also need to create kubeconfig credentials for the access to the Kubernetes cluster.
|
||||
|
||||
1. Log in to the web console of KubeSphere as `project-regular`. Go to your DevOps project and click **Create** in **Credentials**.
|
||||
1. Log in to the web console of KubeSphere as `project-regular`. In your DevOps project, go to **Credentials** under **DevOps Project Settings** and then click **Create** on the **Credentials** page.
|
||||
|
||||

|
||||
|
||||
2. In the dialog that appears, set a **Credential ID**, which will be used later in the Jenkinsfile, and select **Account Credentials** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Token/Password**. When you finish, click **OK**.
|
||||
|
||||

|
||||
2. In the displayed dialog box, set a **Name**, which is used later in the Jenkinsfile, and select **Username and password** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Password/Token**. When you finish, click **OK**.
|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
|
|
@ -50,9 +38,7 @@ You need to create credentials in KubeSphere for the access token created so tha
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Log out of the KubeSphere web console and log back in as `project-admin`. Go to your DevOps project and click **Create** in **Credentials**. Select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current account. Set a **Credential ID** and click **OK**.
|
||||
|
||||

|
||||
3. Log out of the KubeSphere web console and log back in as `project-admin`. Go to your DevOps project and click **Create** in **Credentials**. Select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current account. Set a **Name** and click **OK**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -62,35 +48,24 @@ You need to create credentials in KubeSphere for the access token created so tha
|
|||
|
||||
## Create a Pipeline
|
||||
|
||||
With the above credentials ready, you can use the account `project-regular` to create a pipeline with an example Jenkinsfile as below.
|
||||
With the above credentials ready, you can use the user `project-regular` to create a pipeline with an example Jenkinsfile as below.
|
||||
|
||||
1. To create a pipeline, click **Create** on the **Pipelines** page.
|
||||
|
||||

|
||||
2. Set a name in the displayed dialog box and click **Next**.
|
||||
|
||||
2. Set a name in the pop-up window and click **Next** directly.
|
||||
|
||||

|
||||
|
||||
3. In this tutorial, you can use default values for all the fields. In **Advanced Settings**, click **Create** directly.
|
||||
|
||||

|
||||
3. In this tutorial, you can use default values for all the fields. On the **Advanced Settings** tab, click **Create**.
|
||||
|
||||
## Edit the Jenkinsfile
|
||||
|
||||
1. In the pipeline list, click this pipeline to go to its detail page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
1. In the pipeline list, click this pipeline to go to its details page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
|
||||

|
||||
|
||||
2. Copy and paste all the content below to the pop-up window as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, `MULTI_CLUSTER_PROJECT_NAME`, and `MEMBER_CLUSTER_NAME` with yours. When you finish, click **OK**.
|
||||
2. Copy and paste all the content below to the displayed dialog box as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, `MULTI_CLUSTER_PROJECT_NAME`, and `MEMBER_CLUSTER_NAME` with yours. When you finish, click **OK**.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
}
|
||||
|
||||
label 'go'
|
||||
}
|
||||
|
||||
environment {
|
||||
|
|
@ -98,31 +73,30 @@ With the above credentials ready, you can use the account `project-regular` to c
|
|||
// Docker Hub username
|
||||
DOCKERHUB_USERNAME = 'Your Docker Hub username'
|
||||
APP_NAME = 'devops-go-sample'
|
||||
// ‘dockerhub-go’ is the Docker Hub credentials ID you created on the KubeSphere console
|
||||
DOCKERHUB_CREDENTIAL = credentials('dockerhub-go')
|
||||
// ‘dockerhub’ is the Docker Hub credentials ID you created on the KubeSphere console
|
||||
DOCKERHUB_CREDENTIAL = credentials('dockerhub')
|
||||
// the kubeconfig credentials ID you created on the KubeSphere console
|
||||
KUBECONFIG_CREDENTIAL_ID = 'dockerhub-go-kubeconfig'
|
||||
KUBECONFIG_CREDENTIAL_ID = 'kubeconfig'
|
||||
// mutli-cluster project name under your own workspace
|
||||
MULTI_CLUSTER_PROJECT_NAME = 'demo-multi-cluster'
|
||||
// the name of the Member Cluster where you want to deploy your app
|
||||
// in this tutorial, the apps are deployed on Host Cluster and only one Member Cluster
|
||||
// for more Member Clusters, please edit manifest/multi-cluster-deploy.yaml
|
||||
MEMBER_CLUSTER_NAME = 'Your Member Cluster name'
|
||||
// the name of the member cluster where you want to deploy your app
|
||||
// in this tutorial, the apps are deployed on host cluster and only one member cluster
|
||||
// for more member clusters, please edit manifest/multi-cluster-deploy.yaml
|
||||
MEMBER_CLUSTER_NAME = 'Your member cluster name'
|
||||
}
|
||||
|
||||
stages {
|
||||
stage('docker login') {
|
||||
steps {
|
||||
container('maven') {
|
||||
container('go') {
|
||||
sh 'echo $DOCKERHUB_CREDENTIAL_PSW | docker login -u $DOCKERHUB_CREDENTIAL_USR --password-stdin'
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
stage('build & push') {
|
||||
steps {
|
||||
container('maven') {
|
||||
container('go') {
|
||||
sh 'git clone https://github.com/yuswift/devops-go-sample.git'
|
||||
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
|
||||
|
|
@ -132,17 +106,15 @@ With the above credentials ready, you can use the account `project-regular` to c
|
|||
|
||||
stage('deploy app to multi cluster') {
|
||||
steps {
|
||||
container('maven') {
|
||||
script {
|
||||
container('go') {
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: 'dockerhub-go-kubeconfig',
|
||||
credentialsId: env.KUBECONFIG_CREDENTIAL_ID,
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < devops-go-sample/manifest/multi-cluster-deploy.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -158,5 +130,3 @@ With the above credentials ready, you can use the account `project-regular` to c
|
|||
## Run the Pipeline
|
||||
|
||||
After you save the Jenkinsfile, click **Run**. If everything goes well, you will see the Deployment workload in your multi-cluster project.
|
||||
|
||||

|
||||
|
|
@ -15,7 +15,7 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to [prepare a Nexus instance](https://help.sonatype.com/repomanager3/installation).
|
||||
- You need to have a [GitHub](https://github.com/) account.
|
||||
- You need to create a workspace, a DevOps project (for example, `demo-devops`), and an account (for example, `project-regular`). This account needs to be invited into the DevOps project with the role of `operator`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project (for example, `demo-devops`), and a user (for example, `project-regular`). This account needs to be invited into the DevOps project with the role of `operator`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
|
|
@ -29,11 +29,7 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
- `hosted`: the repository storing artifacts on Nexus.
|
||||
- `group`: a group of configured Nexus repositories.
|
||||
|
||||

|
||||
|
||||
3. You can click a repository to view its details. For example, click **maven-public** to go to its detail page and you can see its URL.
|
||||
|
||||

|
||||
3. You can click a repository to view its details. For example, click **maven-public** to go to its details page, and you can see its **URL**.
|
||||
|
||||
### Step 2: Modify `pom.xml` in your GitHub repository
|
||||
|
||||
|
|
@ -41,9 +37,7 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
|
||||
2. In your own GitHub repository of **learn-pipeline-java**, click the file `pom.xml` in the root directory.
|
||||
|
||||

|
||||
|
||||
3. Click <img src="/images/docs/devops-user-guide/examples/use-nexus-in-pipeline/github-edit-icon.png" height="18px" /> to modify the code segment of `<distributionManagement>` in the file. Set the `<id>` and use the URLs of your own Nexus repositories .
|
||||
3. Click <img src="/images/docs/devops-user-guide/examples/use-nexus-in-pipeline/github-edit-icon.png" height="18px" /> to modify the code segment of `<distributionManagement>` in the file. Set the `<id>` and use the URLs of your own Nexus repositories.
|
||||
|
||||

|
||||
|
||||
|
|
@ -53,13 +47,9 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
|
||||
1. Log in to the KubeSphere web console as `admin`, click **Platform** in the upper-left corner, and select **Cluster Management**.
|
||||
|
||||
2. Select **ConfigMaps** under **Configurations**. On the **ConfigMaps** page, select `kubesphere-devops-system` from the drop-down list and click `ks-devops-agent`.
|
||||
2. Select **ConfigMaps** under **Configuration**. On the **ConfigMaps** page, select `kubesphere-devops-worker` from the drop-down list and click `ks-devops-agent`.
|
||||
|
||||

|
||||
|
||||
3. On the detail page, click **Edit YAML** from the **More** drop-down menu.
|
||||
|
||||

|
||||
3. On the details page, click **Edit YAML** from the **More** drop-down menu.
|
||||
|
||||
4. In the displayed dialog box, scroll down, find the code segment of `<servers>`, and enter the following code:
|
||||
|
||||
|
|
@ -102,7 +92,7 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
6. When you finish, click **Update**.
|
||||
6. When you finish, click **OK**.
|
||||
|
||||
### Step 4: Create a pipeline
|
||||
|
||||
|
|
@ -110,13 +100,9 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
|
||||
2. On the **Basic Information** tab, set a name for the pipeline (for example, `nexus-pipeline`) and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. On the **Advanced Settings** tab, click **Create** to use the default settings.
|
||||
|
||||
4. Click the pipeline to go to its detail page and click **Edit Jenkinsfile**.
|
||||
|
||||

|
||||
4. Click the pipeline name to go to its details page and click **Edit Jenkinsfile**.
|
||||
|
||||
5. In the displayed dialog box, enter the Jenkinsfile as follows. When you finish, click **OK**.
|
||||
|
||||
|
|
@ -158,8 +144,6 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You need to replace the GitHub repository address with your own. In the command from the step in the stage `deploy to Nexus`, `nexus` is the name you set in `<id>` in the ConfigMap and `http://135.68.37.85:8081/repository/maven-snapshots/` is the URL of your Nexus repository.
|
||||
|
|
@ -170,15 +154,9 @@ This tutorial demonstrates how to use Nexus in pipelines on KubeSphere.
|
|||
|
||||
1. You can see all the stages and steps shown on the graphical editing panels. Click **Run** to run the pipeline.
|
||||
|
||||

|
||||
2. After a while, you can see the pipeline status shown as **Successful**. Click the **Successful** record to see its details.
|
||||
|
||||
2. After a while, you can see the pipeline status shown as **Success**. Click the **Success** record to see its details.
|
||||
|
||||

|
||||
|
||||
3. You can click **Show Logs** to view the detailed logs.
|
||||
|
||||

|
||||
3. You can click **View Logs** to view the detailed logs.
|
||||
|
||||
4. Log in to Nexus and click **Browse**. Click **maven-public** and you can see all the dependencies have been downloaded.
|
||||
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ This tutorial demonstrates how to integrate Harbor into KubeSphere pipelines.
|
|||
## Prerequisites
|
||||
|
||||
- You need to [enable the KubeSphere DevOps System](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project, and an account (`project-regular`). This account needs to be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to create a workspace, a DevOps project, and a user (`project-regular`). This account needs to be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
|
||||
## Install Harbor
|
||||
|
||||
|
|
@ -26,25 +26,15 @@ helm install harbor-release harbor/harbor --set expose.type=nodePort,externalURL
|
|||
|
||||
## Get Harbor Credentials
|
||||
|
||||
1. After Harbor is installed, visit `NodeIP:30002` and log in to the console with the default account and password (`admin/Harbor12345`). Go to **Projects** and click **NEW PROJECT**.
|
||||
1. After Harbor is installed, visit `<NodeIP>:30002` and log in to the console with the default account and password (`admin/Harbor12345`). Click **Projects** in the left navigation pane and click **NEW PROJECT** on the **Projects** page.
|
||||
|
||||

|
||||
2. In the displayed dialog box, set a name (`ks-devops-harbor`) and click **OK**.
|
||||
|
||||
2. Set a name (`ks-devops-harbor`) and click **OK**.
|
||||
3. Click the project you just created, and click **NEW ROBOT ACCOUNT** under the **Robot Accounts** tab.
|
||||
|
||||

|
||||
4. In the displayed dialog box, set a name (`robot-test`) for the robot account and click **SAVE**. Make sure you select the checkbox for pushing artifact in **Permissions**.
|
||||
|
||||
3. Click the project you just created, and select **NEW ROBOT ACCOUNT** in **Robot Accounts**.
|
||||
|
||||

|
||||
|
||||
4. Set a name (`robot-test`) for the robot account and save it.
|
||||
|
||||

|
||||
|
||||
5. Click **EXPORT TO FILE** to save the token.
|
||||
|
||||

|
||||
5. In the displayed dialog box, click **EXPORT TO FILE** to save the token.
|
||||
|
||||
## Enable Insecure Registry
|
||||
|
||||
|
|
@ -79,13 +69,9 @@ You have to configure Docker to disregard security for your Harbor registry.
|
|||
|
||||
## Create Credentials
|
||||
|
||||
1. Log in to KubeSphere as `project-regular`, go to your DevOps project and create credentials for Harbor in **Credentials** under **Project Management**.
|
||||
1. Log in to KubeSphere as `project-regular`, go to your DevOps project and create credentials for Harbor in **Credentials** under **DevOps Project Settings**.
|
||||
|
||||

|
||||
|
||||
2. On the **Create Credentials** page, set a credential ID (`robot-test`) and select **Account Credentials** for **Type**. The **Username** field must be the same as the value of `name` in the JSON file you just downloaded and enter the value of `token` in the file for **Token/Password**.
|
||||
|
||||

|
||||
2. On the **Create Credentials** page, set a credential ID (`robot-test`) and select **Username and password** for **Type**. The **Username** field must be the same as the value of `name` in the JSON file you just downloaded and enter the value of `token` in the file for **Password/Token**.
|
||||
|
||||
3. Click **OK** to save it.
|
||||
|
||||
|
|
@ -93,17 +79,11 @@ You have to configure Docker to disregard security for your Harbor registry.
|
|||
|
||||
1. Go to the **Pipelines** page and click **Create**. In the **Basic Information** tab, enter a name (`demo-pipeline`) for the pipeline and click **Next**.
|
||||
|
||||

|
||||
|
||||
2. Use default values in **Advanced Settings** and click **Create**.
|
||||
|
||||

|
||||
|
||||
## Edit the Jenkinsfile
|
||||
|
||||
1. Click the pipeline to go to its detail page and click **Edit Jenkinsfile**.
|
||||
|
||||

|
||||
1. Click the pipeline to go to its details page and click **Edit Jenkinsfile**.
|
||||
|
||||
2. Copy and paste the following contents into the Jenkinsfile. Note that you must replace the values of `REGISTRY`, `HARBOR_NAMESPACE`, `APP_NAME`, and `HARBOR_CREDENTIAL` with your own values.
|
||||
|
||||
|
|
@ -160,6 +140,5 @@ You have to configure Docker to disregard security for your Harbor registry.
|
|||
|
||||
## Run the Pipeline
|
||||
|
||||
Save the Jenkinsfile and KubeSphere automatically creates all stages and steps on the graphical editing panel. Click **Run** to run the pipeline. If everything goes well, the image will be pushed to your Harbor registry by Jenkins.
|
||||
Save the Jenkinsfile and KubeSphere automatically creates all stages and steps on the graphical editing panel. Click **Run** to run the pipeline. If everything goes well, the image is pushed to your Harbor registry by Jenkins.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: "Integrate SonarQube into Pipelines"
|
||||
keywords: 'Kubernetes, KubeSphere, devops, jenkins, sonarqube, pipeline'
|
||||
keywords: 'Kubernetes, KubeSphere, DevOps, Jenkins, SonarQube, Pipeline'
|
||||
description: 'Integrate SonarQube into your pipeline for code quality analysis.'
|
||||
linkTitle: "Integrate SonarQube into Pipelines"
|
||||
weight: 11310
|
||||
|
|
@ -79,19 +79,15 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
```bash
|
||||
$ kubectl get pod -n kubesphere-devops-system
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
ks-jenkins-68b8949bb-7zwg4 1/1 Running 0 84m
|
||||
devops-jenkins-68b8949bb-7zwg4 1/1 Running 0 84m
|
||||
s2ioperator-0 1/1 Running 1 84m
|
||||
sonarqube-postgresql-0 1/1 Running 0 5m31s
|
||||
sonarqube-sonarqube-bb595d88b-97594 1/1 Running 2 5m31s
|
||||
```
|
||||
|
||||
2. Access the SonarQube console `http://{$Node IP}:{$NodePort}` in your browser and you can see its homepage as below:
|
||||
2. Access the SonarQube console `http://<Node IP>:<NodePort>` in your browser.
|
||||
|
||||

|
||||
|
||||
3. Click **Log in** in the top-right corner and use the default account `admin/admin`.
|
||||
|
||||

|
||||
3. Click **Log in** in the upper-right corner and log in as the default account `admin/admin`.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -124,7 +120,7 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
1. Execute the following command to get the address of SonarQube Webhook.
|
||||
|
||||
```bash
|
||||
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services ks-jenkins)
|
||||
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services devops-jenkins)
|
||||
export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
echo http://$NODE_IP:$NODE_PORT/sonarqube-webhook/
|
||||
```
|
||||
|
|
@ -143,7 +139,7 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
|
||||

|
||||
|
||||
5. Enter **Name** and **Jenkins Console URL** (i.e. the SonarQube Webhook address) in the dialog that appears. Click **Create** to finish.
|
||||
5. Enter **Name** and **Jenkins Console URL** (for example, the SonarQube Webhook address) in the displayed dialog box. Click **Create** to finish.
|
||||
|
||||

|
||||
|
||||
|
|
@ -178,7 +174,7 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
1. Execute the following command to get the address of Jenkins.
|
||||
|
||||
```bash
|
||||
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services ks-jenkins)
|
||||
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services devops-jenkins)
|
||||
export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
echo http://$NODE_IP:$NODE_PORT
|
||||
```
|
||||
|
|
@ -189,9 +185,7 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
http://192.168.0.4:30180
|
||||
```
|
||||
|
||||
3. Access Jenkins with the address `http://{$Public IP}:30180`. When KubeSphere is installed, the Jenkins dashboard is also installed by default. Besides, Jenkins is configured with KubeSphere LDAP, which means you can log in to Jenkins with KubeSphere accounts (for example, `admin/P@88w0rd`) directly. For more information about configuring Jenkins, see [Jenkins System Settings](../../../devops-user-guide/how-to-use/jenkins-setting/).
|
||||
|
||||

|
||||
3. Access Jenkins with the address `http://<Node IP>:30180`. When KubeSphere is installed, the Jenkins dashboard is also installed by default. Besides, Jenkins is configured with KubeSphere LDAP, which means you can log in to Jenkins with KubeSphere accounts (for example, `admin/P@88w0rd`) directly. For more information about configuring Jenkins, see [Jenkins System Settings](../../../devops-user-guide/how-to-use/jenkins-setting/).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -199,19 +193,13 @@ To integrate SonarQube into your pipeline, you must install SonarQube Server fir
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
4. Click **Manage Jenkins** on the left.
|
||||
|
||||

|
||||
4. Click **Manage Jenkins** on the left navigation pane.
|
||||
|
||||
5. Scroll down to **Configure System** and click it.
|
||||
|
||||

|
||||
|
||||
6. Navigate to **SonarQube servers** and click **Add SonarQube**.
|
||||
|
||||

|
||||
|
||||
7. Enter **Name** and **Server URL** (`http://{$Node IP}:{$NodePort}`). Click **Add**, select **Jenkins**, and then create the credentials with the SonarQube admin token in the dialog that appears as shown in the second image below. After adding the credentials, select it from the drop-down list for **Server authentication token** and then click **Apply** to finish.
|
||||
7. Enter **Name** and **Server URL** (`http://<Node IP>:<NodePort>`). Click **Add**, select **Jenkins**, and then create the credentials with the SonarQube admin token in the displayed dialog box as shown in the second image below. After adding the credentials, select it from the drop-down list for **Server authentication token** and then click **Apply** to finish.
|
||||
|
||||

|
||||
|
||||
|
|
@ -233,14 +221,10 @@ You need to specify `sonarqubeURL` so that you can access SonarQube directly fro
|
|||
kubectl edit cm -n kubesphere-system ks-console-config
|
||||
```
|
||||
|
||||
2. Navigate to `client` and add the field `devops` with `sonarqubeURL` specified.
|
||||
2. Go to `data.client.enableKubeConfig` and add the field `devops` with `sonarqubeURL` specified under it.
|
||||
|
||||
```bash
|
||||
client:
|
||||
version:
|
||||
kubesphere: v3.0.0
|
||||
kubernetes: v1.17.9
|
||||
openpitrix: v0.3.5
|
||||
enableKubeConfig: true
|
||||
devops: # Add this field manually.
|
||||
sonarqubeURL: http://192.168.0.4:31434 # The SonarQube IP address.
|
||||
|
|
@ -253,7 +237,7 @@ You need to specify `sonarqubeURL` so that you can access SonarQube directly fro
|
|||
Execute the following commands.
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system rollout restart deploy ks-apiserver
|
||||
kubectl -n kubesphere-devops-system rollout restart deploy devops-apiserver
|
||||
```
|
||||
|
||||
```bash
|
||||
|
|
@ -286,6 +270,4 @@ You need a SonarQube token so that your pipeline can communicate with SonarQube
|
|||
|
||||
## View Results on the KubeSphere Console
|
||||
|
||||
After you [create a pipeline using the graphical editing panel](../../how-to-use/create-a-pipeline-using-graphical-editing-panel/) or [create a pipeline using a Jenkinsfile](../../how-to-use/create-a-pipeline-using-jenkinsfile/), you can view the result of code quality analysis. For example, you may see an image as below if SonarQube runs successfully.
|
||||
|
||||

|
||||
After you [create a pipeline using the graphical editing panel](../../how-to-use/create-a-pipeline-using-graphical-editing-panel/) or [create a pipeline using a Jenkinsfile](../../how-to-use/create-a-pipeline-using-jenkinsfile/), you can view the result of code quality analysis.
|
||||
|
|
|
|||
|
|
@ -1,18 +1,18 @@
|
|||
---
|
||||
title: "Choose Jenkins Agent"
|
||||
keywords: 'Kubernetes, KubeSphere, docker, devops, jenkins, agent'
|
||||
keywords: 'Kubernetes, KubeSphere, Docker, DevOps, Jenkins, Agent'
|
||||
description: 'Specify the Jenkins agent and use the built-in podTemplate for your pipeline.'
|
||||
linkTitle: "Choose Jenkins Agent"
|
||||
weight: 11250
|
||||
---
|
||||
|
||||
The `agent` section specifies where the entire Pipeline, or a specific stage, will execute in the Jenkins environment depending on where the `agent` section is placed. The section must be defined at the top-level inside the `pipeline` block, but stage-level usage is optional. For more information, see [the official documentation of Jenkins](https://www.jenkins.io/doc/book/pipeline/syntax/#agent).
|
||||
The `agent` section specifies where the entire Pipeline, or a specific stage, will execute in the Jenkins environment depending on where the `agent` section is placed. The section must be defined at the upper-level inside the `pipeline` block, but stage-level usage is optional. For more information, see [the official documentation of Jenkins](https://www.jenkins.io/doc/book/pipeline/syntax/#agent).
|
||||
|
||||
## Built-in podTemplate
|
||||
|
||||
A podTemplate is a template of a Pod that is used to create agents. Users can define a podTemplate to use in the Kubernetes plugin.
|
||||
|
||||
As a pipeline runs, every Jenkins agent Pod must have a container named `jnlp` for communications between the Jenkins master and Jenkins agent. In addition, users can add containers in the podTemplate to meet their own needs. They can choose to use their own Pod YAML to flexibly control the runtime, and the container can be switched by the `container` command. Here is an example.
|
||||
As a pipeline runs, every Jenkins agent Pod must have a container named `jnlp` for communications between the Jenkins controller and Jenkins agent. In addition, users can add containers in the podTemplate to meet their own needs. They can choose to use their own Pod YAML to flexibly control the runtime, and the container can be switched by the `container` command. Here is an example.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ This tutorial demonstrates how to create a pipeline through graphical editing pa
|
|||
|
||||
- You need to [enable the KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to have a [Docker Hub](http://www.dockerhub.com/) account.
|
||||
- You need to create a workspace, a DevOps project, and an account (`project-regular`). This account must be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to create a workspace, a DevOps project, and a user (`project-regular`). This user must be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- Set CI dedicated nodes to run the pipeline. For more information, see [Set CI Node for Dependency Cache](../set-ci-node/).
|
||||
- Configure your email server for pipeline notifications (optional). For more information, see [Set Email Server for KubeSphere Pipelines](../../how-to-use/jenkins-email/).
|
||||
- Configure SonarQube to include code analysis as part of the pipeline (optional). For more information, see [Integrate SonarQube into Pipelines](../../../devops-user-guide/how-to-integrate/sonarqube/).
|
||||
|
|
@ -40,7 +40,7 @@ This example pipeline includes the following six stages.
|
|||
|
||||
### Step 1: Create credentials
|
||||
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **Project Management**. For more information about how to create credentials, see [Credential Management](../credential-management/).
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **DevOps Project Settings**. For more information about how to create credentials, see [Credential Management](../credential-management/).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -48,38 +48,28 @@ This example pipeline includes the following six stages.
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
| Credential ID | Type | Where to use |
|
||||
| --------------- | ------------------- | ------------ |
|
||||
| dockerhub-id | Account Credentials | Docker Hub |
|
||||
| demo-kubeconfig | kubeconfig | Kubernetes |
|
||||
| Credential ID | Type | Where to use |
|
||||
| --------------- | --------------------- | ------------ |
|
||||
| dockerhub-id | Username and password | Docker Hub |
|
||||
| demo-kubeconfig | kubeconfig | Kubernetes |
|
||||
|
||||
2. You need to create an additional credential ID (`sonar-token`) for SonarQube, which is used in stage 3 (Code analysis) mentioned above. Refer to [Create SonarQube Token for New Project](../../../devops-user-guide/how-to-integrate/sonarqube/#create-sonarqube-token-for-new-project) to use the token for the **secret** field below. Click **OK** to finish.
|
||||
|
||||

|
||||
2. You need to create an additional credential ID (`sonar-token`) for SonarQube, which is used in stage 3 (Code analysis) mentioned above. Refer to [Create SonarQube Token for New Project](../../../devops-user-guide/how-to-integrate/sonarqube/#create-sonarqube-token-for-new-project) to enter your SonarQube token in the **Token** field for a credential of the **Access token** type. Click **OK** to finish.
|
||||
|
||||
3. In total, you have three credentials in the list.
|
||||
|
||||

|
||||
|
||||
### Step 2: Create a project
|
||||
|
||||
In this tutorial, the example pipeline will deploy the [sample](https://github.com/kubesphere/devops-java-sample/tree/sonarqube) app to a project. Hence, you must create the project (for example, `kubesphere-sample-dev`) in advance. The Deployment and Service of the app will be created automatically in the project once the pipeline runs successfully.
|
||||
In this tutorial, the example pipeline will deploy the [sample](https://github.com/kubesphere/devops-maven-sample/tree/sonarqube) app to a project. Hence, you must create the project (for example, `kubesphere-sample-dev`) in advance. The Deployment and Service of the app will be created automatically in the project once the pipeline runs successfully.
|
||||
|
||||
You can use the account `project-admin` to create the project. Besides, this account is also the reviewer of the CI/CD pipeline. Make sure the account `project-regular` is invited to the project with the role of `operator`. For more information, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
You can use the user `project-admin` to create the project. Besides, this user is also the reviewer of the CI/CD pipeline. Make sure the account `project-regular` is invited to the project with the role of `operator`. For more information, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
### Step 3: Create a pipeline
|
||||
|
||||
1. Make sure you have logged in to KubeSphere as `project-regular`, and then go to your DevOps project. Click **Create** on the **Pipelines** page.
|
||||
|
||||

|
||||
2. In the displayed dialog box, name it `graphical-pipeline` and click **Next**.
|
||||
|
||||
2. In the dialog that appears, name it `graphical-pipeline` and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. On the **Advanced Settings** page, click **Add Parameter** to add three string parameters as follows. These parameters will be used in the Docker command of the pipeline. Click **Create** when you finish adding.
|
||||
|
||||

|
||||
3. On the **Advanced Settings** page, click **Add** to add three string parameters as follows. These parameters will be used in the Docker command of the pipeline. Click **Create** when you finish adding.
|
||||
|
||||
| Parameter Type | Name | Value | Description |
|
||||
| -------------- | ------------------- | --------------- | ------------------------------------------------------------ |
|
||||
|
|
@ -93,30 +83,20 @@ You can use the account `project-admin` to create the project. Besides, this acc
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
4. The pipeline created appears in the list.
|
||||
|
||||

|
||||
4. The pipeline created is displayed in the list.
|
||||
|
||||
### Step 4: Edit the pipeline
|
||||
|
||||
Click the pipeline to go to its detail page. To use graphical editing panels, click **Edit Pipeline** under the tab **Pipeline**. In the dialog that appears, click **Custom Pipeline**. This pipeline consists of six stages. Follow the steps below to set each stage.
|
||||
|
||||

|
||||
Click the pipeline to go to its details page. To use graphical editing panels, click **Edit Pipeline** under the tab **Task Status**. In the displayed dialog box, click **Custom Pipeline**. This pipeline consists of six stages. Follow the steps below to set each stage.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The pipeline detail page shows **Sync Status**. It reflects the synchronization result between KubeSphere and Jenkins, and you can see the **Success** icon if the synchronization is successful. You can also click **Edit Jenkinsfile** to create a Jenkinsfile manually for your pipeline.
|
||||
- The pipeline details page shows **Sync Status**. It reflects the synchronization result between KubeSphere and Jenkins, and you can see the **Successful** icon if the synchronization is successful. You can also click **Edit Jenkinsfile** to create a Jenkinsfile manually for your pipeline.
|
||||
|
||||
- You can also click **Continuous Integration (CI)** and **Continuous Integration & Delivery (CI/CD)** to [use the built-in pipeline templates](../use-pipeline-templates/) provided by KubeSphere.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can also click **Continuous Integration (CI)** and **Continuous Integration & Delivery (CI/CD)** to [use the built-in pipeline templates](../use-pipeline-templates/) provided by KubeSphere.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
#### Stage 1: Pull source code (Checkout SCM)
|
||||
|
||||
A graphical editing panel includes two areas - **canvas** on the left and **content** on the right. It automatically generates a Jenkinsfile based on how you configure different stages and steps, which is much more user-friendly for developers.
|
||||
|
|
@ -141,10 +121,10 @@ Pipelines include [declarative pipelines](https://www.jenkins.io/doc/book/pipeli
|
|||
|
||||

|
||||
|
||||
3. Click **Add Step**. Select **git** from the list as the example code is pulled from GitHub. In the dialog that appears, fill in the required field. Click **OK** to finish.
|
||||
3. Click **Add Step**. Select **git** from the list as the example code is pulled from GitHub. In the displayed dialog box, fill in the required field. Click **OK** to finish.
|
||||
|
||||
- **URL**. Enter the GitHub repository address `https://github.com/kubesphere/devops-java-sample.git`. Note that this is an example and you need to use your own repository address.
|
||||
- **Credential ID**. You do not need to enter the Credential ID for this tutorial.
|
||||
- **URL**. Enter the GitHub repository address `https://github.com/kubesphere/devops-maven-sample.git`. Note that this is an example and you need to use your own repository address.
|
||||
- **Name**. You do not need to enter the Credential ID for this tutorial.
|
||||
- **Branch**. It defaults to the master branch if you leave it blank. Enter `sonarqube` or leave it blank if you do not need the code analysis stage.
|
||||
|
||||

|
||||
|
|
@ -166,7 +146,7 @@ Pipelines include [declarative pipelines](https://www.jenkins.io/doc/book/pipeli
|
|||
3. Click **Add Nesting Steps** to add a nested step under the `maven` container. Select **shell** from the list and enter the following command in the command line. Click **OK** to save it.
|
||||
|
||||
```shell
|
||||
mvn clean -o -gs `pwd`/configuration/settings.xml test
|
||||
mvn clean -gs `pwd`/configuration/settings.xml test
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
|
@ -175,9 +155,6 @@ Pipelines include [declarative pipelines](https://www.jenkins.io/doc/book/pipeli
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Stage 3: Code analysis (optional)
|
||||
|
||||
|
|
@ -191,7 +168,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
3. Click **Add Nesting Steps** under the `maven` container to add a nested step. Click **withCredentials** and select the SonarQube token (`sonar-token`) from the **Credential ID** list. Enter `SONAR_TOKEN` for **Text Variable**, then click **OK**.
|
||||
3. Click **Add Nesting Steps** under the `maven` container to add a nested step. Click **withCredentials** and select the SonarQube token (`sonar-token`) from the **Name** list. Enter `SONAR_TOKEN` for **Text Variable**, then click **OK**.
|
||||
|
||||

|
||||
|
||||
|
|
@ -199,7 +176,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
5. Click **withSonarQubeEnv**. In the dialog that appears, do not change the default name `sonar` and click **OK** to save it.
|
||||
5. Click **withSonarQubeEnv**. In the displayed dialog box, do not change the default name `sonar` and click **OK** to save it.
|
||||
|
||||

|
||||
|
||||
|
|
@ -210,7 +187,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
7. Click **shell** and enter the following command in the command line for the sonarqube branch and authentication. Click **OK** to finish.
|
||||
|
||||
```shell
|
||||
mvn sonar:sonar -o -gs `pwd`/configuration/settings.xml -Dsonar.login=$SONAR_TOKEN
|
||||
mvn sonar:sonar -Dsonar.login=$SONAR_TOKEN
|
||||
```
|
||||
|
||||

|
||||
|
|
@ -221,7 +198,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
9. Click **Add Nesting Steps** for the **timeout** step and select **waitForQualityGate**. Select **Start the follow-up task after the inspection** in the pop-up dialog. Click **OK** to save it.
|
||||
9. Click **Add Nesting Steps** for the **timeout** step and select **waitForQualityGate**. Select **Start the follow-up task after the inspection** in the displayed dialog box. Click **OK** to save it.
|
||||
|
||||

|
||||
|
||||
|
|
@ -237,15 +214,15 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
3. Click **Add Nesting Steps** under the `maven` container to add a nested step. Select **shell** from the list, and enter the following command in the pop-up window. Click **OK** to finish.
|
||||
3. Click **Add Nesting Steps** under the `maven` container to add a nested step. Select **shell** from the list, and enter the following command in the displayed dialog box. Click **OK** to finish.
|
||||
|
||||
```shell
|
||||
mvn -o -Dmaven.test.skip=true -gs `pwd`/configuration/settings.xml clean package
|
||||
mvn -Dmaven.test.skip=true clean package
|
||||
```
|
||||
|
||||

|
||||
|
||||
4. Click **Add Nesting Steps** again and select **shell**. Enter the following command in the command line to build a Docker image based on the [Dockerfile](https://github.com/kubesphere/devops-java-sample/blob/sonarqube/Dockerfile-online). Click **OK** to confirm.
|
||||
4. Click **Add Nesting Steps** again and select **shell**. Enter the following command in the command line to build a Docker image based on the [Dockerfile](https://github.com/kubesphere/devops-maven-sample/blob/sonarqube/Dockerfile-online). Click **OK** to confirm.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -259,9 +236,9 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
5. Click **Add Nesting Steps** again and select **withCredentials**. Fill in the following fields in the dialog. Click **OK** to confirm.
|
||||
5. Click **Add Nesting Steps** again and select **withCredentials**. Fill in the following fields in the displayed dialog box. Click **OK** to confirm.
|
||||
|
||||
- **Credential ID**: Select the Docker Hub credentials you created, such as `dockerhub-id`.
|
||||
- **Credential Name**: Select the Docker Hub credentials you created, such as `dockerhub-id`.
|
||||
- **Password Variable**: Enter `DOCKER_PASSWORD`.
|
||||
- **Username Variable**: Enter `DOCKER_USERNAME`.
|
||||
|
||||
|
|
@ -273,7 +250,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
6. Click **Add Nesting Steps** (the first one) in the **withCredentials** step created above. Select **shell** and enter the following command in the pop-up window, which is used to log in to Docker Hub. Click **OK** to confirm.
|
||||
6. Click **Add Nesting Steps** (the first one) in the **withCredentials** step created above. Select **shell** and enter the following command in the displayed dialog box, which is used to log in to Docker Hub. Click **OK** to confirm.
|
||||
|
||||
```shell
|
||||
echo "$DOCKER_PASSWORD" | docker login $REGISTRY -u "$DOCKER_USERNAME" --password-stdin
|
||||
|
|
@ -295,7 +272,7 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
2. With the **Artifacts** stage selected, click **Add Step** under **Task** and select **archiveArtifacts**. Enter `target/*.jar` in the dialog, which is used to set the archive path of artifacts in Jenkins. Click **OK** to finish.
|
||||
2. With the **Artifacts** stage selected, click **Add Step** under **Task** and select **archiveArtifacts**. Enter `target/*.jar` in the displayed dialog box, which is used to set the archive path of artifacts in Jenkins. Click **OK** to finish.
|
||||
|
||||

|
||||
|
||||
|
|
@ -311,18 +288,27 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
In KubeSphere v3.1, the account that can run a pipeline will be able to continue or terminate the pipeline if there is no reviewer specified. Pipeline creators, accounts with the role of `admin` in a project, or the account you specify will be able to continue or terminate a pipeline.
|
||||
In KubeSphere 3.2.x, the account that can run a pipeline will be able to continue or terminate the pipeline if there is no reviewer specified. Pipeline creators, accounts with the role of `admin` in a project, or the account you specify will be able to continue or terminate a pipeline.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Click **Add Step** under the **Deploy to Dev** stage again. Select **kubernetesDeploy** from the list and fill in the following fields in the dialog. Click **OK** to save it.
|
||||
3. Click **Add Step** under the **Deploy to Dev** stage again. Select **container** from the list, name it `maven`, and click **OK**.
|
||||
|
||||
- **Kubeconfig**: Select the Kubeconfig you created, such as `demo-kubeconfig`.
|
||||
- **Configuration File Path**: Enter `deploy/no-branch-dev/**`, which is the relative path of the Kubernetes resource [YAML](https://github.com/kubesphere/devops-java-sample/tree/sonarqube/deploy/no-branch-dev) file in the code repository.
|
||||
4. Click **Add Nesting Steps** in the `maven` container step. Select **withCredentials** from the list, fill in the following fields in the displayed dialog box, and click **OK**.
|
||||
|
||||

|
||||
- **Credential Name**: Select the kubeconfig credential you created, such as `demo-kubeconfig`.
|
||||
- **Kubeconfig Variable**: Enter `KUBECONFIG_CONTENT`.
|
||||
|
||||
4. If you want to receive email notifications when the pipeline runs successfully, click **Add Step** and select **mail** to add email information. Note that configuring the email server is optional, which means you can still run your pipeline if you skip this step.
|
||||
5. Click **Add Nesting Steps** in the **withCredentials** step. Select **shell** from the list, enter the following commands in the displayed dialog box, and click **OK**.
|
||||
|
||||
```shell
|
||||
mkdir ~/.kube
|
||||
echo "$KUBECONFIG_CONTENT" > ~/.kube/config
|
||||
envsubst < deploy/dev-ol/devops-sample-svc.yaml | kubectl apply -f -
|
||||
envsubst < deploy/dev-ol/devops-sample.yaml | kubectl apply -f -
|
||||
```
|
||||
|
||||
6. If you want to receive email notifications when the pipeline runs successfully, click **Add Step** and select **mail** to add email information. Note that configuring the email server is optional, which means you can still run your pipeline if you skip this step.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -330,13 +316,11 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
5. When you finish the steps above, click **Confirm** and **Save** in the bottom-right corner. You can see the pipeline now has a complete workflow with each stage clearly listed on the pipeline. When you define a pipeline using the graphical editing panel, KubeSphere automatically creates its corresponding Jenkinsfile. Click **Edit Jenkinsfile** to view the Jenkinsfile.
|
||||
7. When you finish the steps above, click **Save** in the lower-right corner. You can see the pipeline now has a complete workflow with each stage clearly listed on the pipeline. When you define a pipeline using the graphical editing panel, KubeSphere automatically creates its corresponding Jenkinsfile. Click **Edit Jenkinsfile** to view the Jenkinsfile.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
On the **Pipelines** page, you can click the three dots on the right side of the pipeline and then select **Copy Pipeline** to create a copy of it. If you need to concurrently run multiple pipelines that don't contain multiple branches, you can select all of these pipelines and then click **Run** to run them in a batch.
|
||||
On the **Pipelines** page, you can click <img src="/images/docs/common-icons/three-dots.png" width="15" /> on the right side of the pipeline and then select **Copy** to create a copy of it. If you need to concurrently run multiple pipelines that don't contain multiple branches, you can select all of these pipelines and then click **Run** to run them in a batch.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
@ -346,25 +330,21 @@ This stage uses SonarQube to test your code. You can skip this stage if you do n
|
|||
|
||||

|
||||
|
||||
2. To see the status of a pipeline, go to the **Activity** tab and click the record you want to view.
|
||||
2. To see the status of a pipeline, go to the **Run Records** tab and click the record you want to view.
|
||||
|
||||
3. Wait for a while and the pipeline stops at the stage **Deploy to Dev** if it runs successfully. As the reviewer of the pipeline, `project-admin` needs to approve it before resources are deployed to the development environment.
|
||||
|
||||

|
||||
|
||||
4. Log out of KubeSphere and log back in to the console as `project-admin`. Go to your DevOps project and click the pipeline `graphical-pipeline`. Under the **Activity** tab, click the record to be reviewed. To approve the pipeline, click **Proceed**.
|
||||
4. Log out of KubeSphere and log back in to the console as `project-admin`. Go to your DevOps project and click the pipeline `graphical-pipeline`. Under the **Run Records** tab, click the record to be reviewed. To approve the pipeline, click **Proceed**.
|
||||
|
||||
### Step 6: View pipeline details
|
||||
|
||||
1. Log in to the console as `project-regular`. Go to your DevOps project and click the pipeline `graphical-pipeline`. Under the **Activity** tab, click the record marked with **Success** under **Status**.
|
||||
1. Log in to the console as `project-regular`. Go to your DevOps project and click the pipeline `graphical-pipeline`. Under the **Run Records** tab, click the record marked with **Successful** under **Status**.
|
||||
|
||||
2. If everything runs successfully, you can see that all stages are completed.
|
||||
|
||||

|
||||
|
||||
3. Click **Show Logs** in the top-right corner to inspect all the logs. Click each stage to see detailed logs of it. You can debug any problems based on the logs which also can be downloaded locally for further analysis.
|
||||
|
||||

|
||||
3. Click **View Logs** in the upper-right corner to inspect all the logs. Click each stage to see detailed logs of it. You can debug any problems based on the logs which also can be downloaded locally for further analysis.
|
||||
|
||||
### Step 7: Download the artifact
|
||||
|
||||
|
|
@ -374,7 +354,7 @@ Click the **Artifacts** tab and then click the icon on the right to download the
|
|||
|
||||
### Step 8: View code analysis results
|
||||
|
||||
On the **Code Quality** page, view the code analysis result of this example pipeline, which is provided by SonarQube. If you do not configure SonarQube in advance, this section is not available. For more information, see [Integrate SonarQube into Pipelines](../../../devops-user-guide/how-to-integrate/sonarqube/).
|
||||
On the **Code Check** page, view the code analysis result of this example pipeline, which is provided by SonarQube. If you do not configure SonarQube in advance, this section is not available. For more information, see [Integrate SonarQube into Pipelines](../../../devops-user-guide/how-to-integrate/sonarqube/).
|
||||
|
||||

|
||||
|
||||
|
|
@ -384,14 +364,8 @@ On the **Code Quality** page, view the code analysis result of this example pipe
|
|||
|
||||
2. Go to the project (for example, `kubesphere-sample-dev` in this tutorial), click **Workloads** under **Application Workloads**, and you can see the Deployment appears in the list.
|
||||
|
||||

|
||||
|
||||
3. In **Services**, you can find the port number of the example Service is exposed through a NodePort. To access the Service, visit `<Node IP>:<NodePort>`.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to configure port forwarding rules and open the port in your security group before you access the Service.
|
||||
|
|
@ -402,7 +376,7 @@ On the **Code Quality** page, view the code analysis result of this example pipe
|
|||
|
||||

|
||||
|
||||
5. The app is named `devops-sample` as it is the value of `APP_NAME` and the tag is the value of `SNAPSHOT-$BUILD_NUMBER`. `$BUILD_NUMBER` is the serial number of a record under the **Activity** tab.
|
||||
5. The app is named `devops-sample` as it is the value of `APP_NAME` and the tag is the value of `SNAPSHOT-$BUILD_NUMBER`. `$BUILD_NUMBER` is the serial number of a record under the **Run Records** tab.
|
||||
|
||||
6. If you set the email server and add the email notification step in the final stage, you can also receive the email message.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
title: "Create a Jenkins Pipeline Using a Jenkinsfile"
|
||||
keywords: 'KubeSphere, Kubernetes, docker, spring boot, Jenkins, devops, ci/cd, pipeline'
|
||||
title: "Create a Pipeline Using a Jenkinsfile"
|
||||
keywords: 'KubeSphere, Kubernetes, Docker, Spring Boot, Jenkins, DevOps, CI/CD, Pipeline'
|
||||
description: "Learn how to create and run a pipeline by using an example Jenkinsfile."
|
||||
linkTitle: "Create a Pipeline Using a Jenkinsfile"
|
||||
weight: 11210
|
||||
|
|
@ -20,7 +20,7 @@ Two types of pipelines can be created in KubeSphere: Pipelines created based on
|
|||
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account and a [GitHub](https://github.com/) account.
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project, and an account (`project-regular`). This account needs to be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to create a workspace, a DevOps project, and a user (`project-regular`). This account needs to be invited to the DevOps project with the `operator` role. See [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to set a CI dedicated node for running pipelines. Refer to [Set a CI Node for Dependency Caching](../../how-to-use/set-ci-node/).
|
||||
- You need to install and configure SonarQube. Refer to [Integrate SonarQube into Pipeline](../../../devops-user-guide/how-to-integrate/sonarqube/). If you skip this part, there is no **SonarQube Analysis** below.
|
||||
|
||||
|
|
@ -33,9 +33,9 @@ There are eight stages as shown below in this example pipeline.
|
|||
{{< notice note >}}
|
||||
|
||||
- **Stage 1. Checkout SCM**: Check out source code from the GitHub repository.
|
||||
- **Stage 2. Unit test**: It will not proceed with the next stage unit the test is passed.
|
||||
- **Stage 2. Unit test**: It will not proceed with the next stage until the test is passed.
|
||||
- **Stage 3. SonarQube analysis**: The SonarQube code quality analysis.
|
||||
- **Stage 4.** **Build & push snapshot image**: Build the image based on selected branches in **Behavioral strategy**. Push the tag of `SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER` to Docker Hub, the `$BUILD_NUMBER` of which is the operation serial number in the pipeline's activity list.
|
||||
- **Stage 4. Build & push snapshot image**: Build the image based on selected branches in **Strategy Settings**. Push the tag of `SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER` to Docker Hub, the `$BUILD_NUMBER` of which is the operation serial number in the pipeline's activity list.
|
||||
- **Stage 5. Push the latest image**: Tag the sonarqube branch as `latest` and push it to Docker Hub.
|
||||
- **Stage 6. Deploy to dev**: Deploy the sonarqube branch to the development environment. Review is required for this stage.
|
||||
- **Stage 7. Push with tag**: Generate the tag and release it to GitHub. The tag is pushed to Docker Hub.
|
||||
|
|
@ -47,7 +47,7 @@ There are eight stages as shown below in this example pipeline.
|
|||
|
||||
### Step 1: Create credentials
|
||||
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **Project Management**. For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **DevOps Project Settings**. For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -61,9 +61,7 @@ There are eight stages as shown below in this example pipeline.
|
|||
| github-id | Account Credentials | GitHub |
|
||||
| demo-kubeconfig | kubeconfig | Kubernetes |
|
||||
|
||||
2. You need to create an additional credential ID (`sonar-token`) for SonarQube, which is used in stage 3 (SonarQube analysis) mentioned above. Refer to [Create SonarQube Token for New Project](../../../devops-user-guide/how-to-integrate/sonarqube/#create-a-sonarqube-token-for-a-new-project) to use the token for the **secret** field below. Click **OK** to finish.
|
||||
|
||||

|
||||
2. You need to create an additional credential (`sonar-token`) for SonarQube, which is used in stage 3 (SonarQube analysis) mentioned above. Refer to [Create SonarQube Token for New Project](../../../devops-user-guide/how-to-integrate/sonarqube/#create-a-sonarqube-token-for-a-new-project) to enter your SonarQube token in the **Token** field for a credential of the **Access token** type. Click **OK** to finish.
|
||||
|
||||
3. You also need to create a GitHub personal access token with the permission as shown in the below image, and then use the generated token to create Account Credentials (for example, `github-token`) for GitHub authentication in your DevOps project.
|
||||
|
||||
|
|
@ -77,17 +75,11 @@ There are eight stages as shown below in this example pipeline.
|
|||
|
||||
4. In total, you have five credentials in the list.
|
||||
|
||||

|
||||
|
||||
### Step 2: Modify the Jenkinsfile in your GitHub repository
|
||||
|
||||
1. Log in to GitHub. Fork [devops-java-sample](https://github.com/kubesphere/devops-java-sample) from the GitHub repository to your own GitHub account.
|
||||
1. Log in to GitHub. Fork [devops-maven-sample](https://github.com/kubesphere/devops-maven-sample) from the GitHub repository to your own GitHub account.
|
||||
|
||||

|
||||
|
||||
2. In your own GitHub repository of **devops-java-sample**, click the file `Jenkinsfile-online` in the root directory.
|
||||
|
||||

|
||||
2. In your own GitHub repository of **devops-maven-sample**, click the file `Jenkinsfile-online` in the root directory.
|
||||
|
||||
3. Click the edit icon on the right to edit environment variables.
|
||||
|
||||
|
|
@ -95,14 +87,14 @@ There are eight stages as shown below in this example pipeline.
|
|||
|
||||
| Items | Value | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| DOCKER\_CREDENTIAL\_ID | dockerhub-id | The **Credential ID** you set in KubeSphere for your Docker Hub account. |
|
||||
| GITHUB\_CREDENTIAL\_ID | github-id | The **Credential ID** you set in KubeSphere for your GitHub account. It is used to push tags to your GitHub repository. |
|
||||
| KUBECONFIG\_CREDENTIAL\_ID | demo-kubeconfig | The **Credential ID** you set in KubeSphere for your kubeconfig. It is used to access a running Kubernetes cluster. |
|
||||
| DOCKER\_CREDENTIAL\_ID | dockerhub-id | The **Name** you set in KubeSphere for your Docker Hub account. |
|
||||
| GITHUB\_CREDENTIAL\_ID | github-id | The **Name** you set in KubeSphere for your GitHub account. It is used to push tags to your GitHub repository. |
|
||||
| KUBECONFIG\_CREDENTIAL\_ID | demo-kubeconfig | The **Name** you set in KubeSphere for your kubeconfig. It is used to access a running Kubernetes cluster. |
|
||||
| REGISTRY | docker.io | It defaults to `docker.io`, serving as the address of pushing images. |
|
||||
| DOCKERHUB\_NAMESPACE | your-dockerhub-account | Replace it with your Docker Hub's account name. It can be the Organization name under the account. |
|
||||
| GITHUB\_ACCOUNT | your-github-account | Replace it with your GitHub account name. For example, your GitHub account name is `kubesphere` if your GitHub address is `https://github.com/kubesphere/`. It can also be the account's Organization name. |
|
||||
| APP\_NAME | devops-java-sample | The application name. |
|
||||
| SONAR\_CREDENTIAL\_ID | sonar-token | The **Credential ID** you set in KubeSphere for the SonarQube token. It is used for code quality test. |
|
||||
| APP\_NAME | devops-maven-sample | The application name. |
|
||||
| SONAR\_CREDENTIAL\_ID | sonar-token | The **Name** you set in KubeSphere for the SonarQube token. It is used for code quality test. |
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -112,15 +104,13 @@ There are eight stages as shown below in this example pipeline.
|
|||
|
||||
4. After you edit the environmental variables, click **Commit changes** at the bottom of the page, which updates the file in the SonarQube branch.
|
||||
|
||||

|
||||
|
||||
### Step 3: Create projects
|
||||
|
||||
You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere-sample-prod`, which represent the development environment and the production environment respectively. Related Deployments and Services of the app will be created automatically in these two projects once the pipeline runs successfully.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The account `project-admin` needs to be created in advance since it is the reviewer of the CI/CD Pipeline. See [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/) for more information.
|
||||
The account `project-admin` needs to be created in advance since it is the reviewer of the CI/CD Pipeline. See [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/) for more information.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
@ -131,111 +121,85 @@ The account `project-admin` needs to be created in advance since it is the revie
|
|||
| kubesphere-sample-dev | development environment |
|
||||
| kubesphere-sample-prod | production environment |
|
||||
|
||||
2. After those projects are created, they will be listed in the project list as below:
|
||||
|
||||

|
||||
2. After those projects are created, they will be listed in the project list.
|
||||
|
||||
### Step 4: Create a pipeline
|
||||
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. Go to the DevOps project `demo-devops` and click **Create** to build a new pipeline.
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. Go to the DevOps project `demo-devops` and click **Create**.
|
||||
|
||||

|
||||
2. Provide the basic information in the displayed dialog box. Name it `jenkinsfile-in-scm` and specify a code repository under **Code Repository**.
|
||||
|
||||
2. Provide the basic information in the dialog that appears. Name it `jenkinsfile-in-scm` and select a code repository.
|
||||
3. In the **GitHub** tab, select **github-token** from the drop-down list under **Credential**, and then click **OK** to select your repository.
|
||||
|
||||

|
||||
4. Choose your GitHub account. All the repositories related to this token will be listed on the right. Select **devops-maven-sample** and click **Select**. Click **Next** to continue.
|
||||
|
||||
3. In the **GitHub** tab, select **github-token** from the drop-down list, and then click **Confirm** to select your repository.
|
||||
5. In **Advanced Settings**, select the checkbox next to **Delete outdated branches**. In this tutorial, you can use the default value of **Branch Retention Period (days)** and **Maximum Branches**.
|
||||
|
||||

|
||||
Delete outdated branches means that you will discard the branch record all together. The branch record includes console output, archived artifacts and other relevant metadata of specific branches. Fewer branches mean that you can save the disk space that Jenkins is using. KubeSphere provides two options to determine when old branches are discarded:
|
||||
|
||||
4. Choose your GitHub account. All the repositories related to this token will be listed on the right. Select **devops-java-sample** and click **Select This Repository**. Click **Next** to continue.
|
||||
- Branch Retention Period (days). Branches that exceed the retention period are deleted.
|
||||
|
||||

|
||||
|
||||
5. In **Advanced Settings**, check the box next to **Discard old branch**. In this tutorial, you can use the default value of **Days to keep old branches** and **Maximum number branches to keep**.
|
||||
|
||||

|
||||
|
||||
Discarding old branches means that you will discard the branch record all together. The branch record includes console output, archived artifacts and other relevant metadata of specific branches. Fewer branches mean that you can save the disk space that Jenkins is using. KubeSphere provides two options to determine when old branches are discarded:
|
||||
|
||||
- Days to keep old branches. Branches will be discarded after a certain number of days.
|
||||
|
||||
- Maximum number of branches to keep. The oldest branches will be discarded after branches reach a certain amount.
|
||||
- Maximum Branches. The earliest branch is deleted when the number of branches exceeds the maximum number.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
**Days to keep old branches** and **Maximum number of branches to keep** apply to branches at the same time. As long as a branch meets the condition of either field, it will be discarded. For example, if you specify 2 as the number of retention days and 3 as the maximum number of branches, any branches that exceed either number will be discarded. KubeSphere repopulates these two fields with -1 by default, which means deleted branches will be discarded.
|
||||
**Branch Retention Period (days)** and **Maximum Branches** apply to branches at the same time. As long as a branch meets the condition of either field, it is deleted. For example, if you specify 2 as the retention period and 3 as the maximum number of branches, any branch that exceed either number is deleted. KubeSphere prepopulates these two fields with 7 and 5 by default respectively.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. In **Behavioral strategy**, KubeSphere offers four strategies by default. You can delete **Discover PR from Forks** as this strategy will not be used in this example. You do not need to change the setting and can use the default value directly.
|
||||
|
||||

|
||||
6. In **Strategy Settings**, KubeSphere offers four strategies by default. You can delete **Discover PRs from Forks** as this strategy will not be used in this example. You do not need to change the setting and can use the default value directly.
|
||||
|
||||
As a Jenkins pipeline runs, the Pull Request (PR) submitted by developers will also be regarded as a separate branch.
|
||||
|
||||
**Discover Branches**
|
||||
|
||||
- **Exclude branches that are also filed as PRs**. The source branch is not scanned such as the origin's master branch. These branches need to be merged.
|
||||
- **Only branches that are also filed as PRs**. Only scan the PR branch.
|
||||
- **All branches**. Pull all the branches from the repository origin.
|
||||
- **Exclude branches filed as PRs**. The source branch is not scanned such as the origin's master branch. These branches need to be merged.
|
||||
- **Include only branches filed as PRs**. Only scan the PR branch.
|
||||
- **Include all branches**. Pull all the branches from the repository origin.
|
||||
|
||||
**Discover PR from Origin**
|
||||
**Discover PRs from Origin**
|
||||
|
||||
- **Source code version of PR merged with target branch**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Source code version of PR itself**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Two pipelines are created when a PR is discovered**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
- **Pull the code with the PR merged**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Pull the code at the point of the PR**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Create two pipelines respectively**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You have to choose GitHub as your code repository to enable the settings of **Behavioral strategy** here.
|
||||
You have to choose GitHub as your code repository to enable the settings of **Strategy Settings** here.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
7. Scroll down to **Script Path**. The field specifies the Jenkinsfile path in the code repository. It indicates the repository's root directory. If the file location changes, the script path also needs to be changed. Please change it to `Jenkinsfile-online`, which is the file name of Jenkinsfile in the example repository located in the root directory.
|
||||
7. Scroll down to **Script Path**. The field specifies the Jenkinsfile path in the code repository. It indicates the repository's root directory. If the file location changes, the script path also needs to be changed. Change it to `Jenkinsfile-online`, which is the file name of Jenkinsfile in the example repository located in the root directory.
|
||||
|
||||

|
||||
|
||||
8. In **Scan Repo Trigger**, check **If not, scan regularly** and set the interval to **5 minutes**. Click **Create** to finish.
|
||||
|
||||

|
||||
8. In **Scan Trigger**, select **Scan periodically** and set the interval to **5 minutes**. Click **Create** to finish.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can set a specific interval to allow pipelines to scan remote repositories, so that any code updates or new PRs can be detected based on the strategy you set in **Behavioral strategy**.
|
||||
You can set a specific interval to allow pipelines to scan remote repositories, so that any code updates or new PRs can be detected based on the strategy you set in **Strategy Settings**.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Step 5: Run a pipeline
|
||||
|
||||
1. After a pipeline is created, it displays in the list below. Click it to go to its detail page.
|
||||
|
||||

|
||||
1. After a pipeline is created, click its name to go to its details page.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- You can click the three dots on the right side of the pipeline and then select **Copy Pipeline** to create a copy of it. If you need to concurrently run multiple pipelines that don't contain multiple branches, you can select all of these pipelines and then click **Run** to run them in a batch.
|
||||
- The pipeline detail page shows **Sync Status**. It reflects the synchronization result between KubeSphere and Jenkins, and you can see the **Success** icon if the synchronization is successful.
|
||||
- You can click <img src="/images/docs/common-icons/three-dots.png" width="15" /> on the right side of the pipeline and then select **Copy** to create a copy of it. If you need to concurrently run multiple pipelines that don't contain multiple branches, you can select all of these pipelines and then click **Run** to run them in a batch.
|
||||
- The pipeline details page shows **Sync Status**. It reflects the synchronization result between KubeSphere and Jenkins, and you can see the **Successful** icon if the synchronization is successful.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
2. Under **Activity**, three branches are being scanned. Click **Run** on the right and the pipeline runs based on the behavioral strategy you set. Select **sonarqube** from the drop-down list and add a tag number such as `v0.0.2`. Click **OK** to trigger a new activity.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Under **Run Records**, three branches are being scanned. Click **Run** on the right and the pipeline runs based on the behavioral strategy you set. Select **sonarqube** from the drop-down list and add a tag number such as `v0.0.2`. Click **OK** to trigger a new activity.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- If you do not see any activity on this page, you need to refresh your browser manually or click **Scan Repository** from the drop-down menu (the **More** button).
|
||||
- If you do not see any run records on this page, you need to refresh your browser manually or click **Scan Repository** from the drop-down menu (the **More** button).
|
||||
- The tag name is used to generate releases and images with the tag in GitHub and Docker Hub. An existing tag name cannot be used again for the field `TAG_NAME`. Otherwise, the pipeline will not be running successfully.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Wait for a while and you can see some activities stop and some fail. Click the first one to view details.
|
||||
|
||||

|
||||
3. Wait for a while, and you can see some activities stop and some fail. Click the first one to view details.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -245,8 +209,6 @@ The account `project-admin` needs to be created in advance since it is the revie
|
|||
|
||||
4. The pipeline pauses at the stage `deploy to dev`. You need to click **Proceed** manually. Note that the pipeline will be reviewed three times as `deploy to dev`, `push with tag`, and `deploy to production` are defined in the Jenkinsfile respectively.
|
||||
|
||||

|
||||
|
||||
In a development or production environment, it requires someone who has higher authority (for example, release manager) to review the pipeline, images, as well as the code analysis result. They have the authority to determine whether the pipeline can go to the next stage. In the Jenkinsfile, you use the section `input` to specify who reviews the pipeline. If you want to specify a user (for example, `project-admin`) to review it, you can add a field in the Jenkinsfile. If there are multiple users, you need to use commas to separate them as follows:
|
||||
|
||||
```groovy
|
||||
|
|
@ -257,36 +219,24 @@ The account `project-admin` needs to be created in advance since it is the revie
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
In KubeSphere v3.1, the account that can run a pipeline will be able to continue or terminate the pipeline if there is no reviewer specified. Pipeline creators, accounts with the role of `admin` in the project, or the account you specify will be able to continue or terminate the pipeline.
|
||||
In KubeSphere 3.2.x, the account that can run a pipeline will be able to continue or terminate the pipeline if there is no reviewer specified. Pipeline creators, accounts with the role of `admin` in the project, or the account you specify will be able to continue or terminate the pipeline.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Step 6: Check pipeline status
|
||||
|
||||
1. In **Task Status**, you can see how a pipeline is running. Please note that the pipeline will keep initializing for several minutes after it is just created. There are eight stages in the sample pipeline and they have been defined separately in [Jenkinsfile-online](https://github.com/kubesphere/devops-java-sample/blob/sonarqube/Jenkinsfile-online).
|
||||
1. In **Task Status**, you can see how a pipeline is running. Please note that the pipeline will keep initializing for several minutes after it is just created. There are eight stages in the sample pipeline and they have been defined separately in [Jenkinsfile-online](https://github.com/kubesphere/devops-maven-sample/blob/sonarqube/Jenkinsfile-online).
|
||||
|
||||

|
||||
|
||||
2. Check the pipeline running logs by clicking **Show Logs** in the top-right corner. You can see the dynamic log output of the pipeline, including any errors that may stop the pipeline from running. For each stage, you click it to inspect logs, which can be downloaded to your local machine for further analysis.
|
||||
|
||||

|
||||
2. Check the pipeline running logs by clicking **View Logs** in the upper-right corner. You can see the dynamic log output of the pipeline, including any errors that may stop the pipeline from running. For each stage, you click it to inspect logs, which can be downloaded to your local machine for further analysis.
|
||||
|
||||
### Step 7: Verify results
|
||||
|
||||
1. Once you successfully executed the pipeline, click **Code Quality** to check the results through SonarQube as follows.
|
||||
|
||||

|
||||
|
||||

|
||||
1. Once you successfully executed the pipeline, click **Code Check** to check the results through SonarQube as follows.
|
||||
|
||||
2. The Docker image built through the pipeline has also been successfully pushed to Docker Hub, as it is defined in the Jenkinsfile. In Docker Hub, you will find the image with the tag `v0.0.2` that is specified before the pipeline runs.
|
||||
|
||||

|
||||
|
||||
3. At the same time, a new tag and a new release have been generated in GitHub.
|
||||
|
||||

|
||||
|
||||
4. The sample application will be deployed to `kubesphere-sample-dev` and `kubesphere-sample-prod` with corresponding Deployments and Services created. Go to these two projects and here are the expected result:
|
||||
|
||||
| Environment | URL | Namespace | Deployment | Service |
|
||||
|
|
@ -294,14 +244,6 @@ The account `project-admin` needs to be created in advance since it is the revie
|
|||
| Development | `http://{$NodeIP}:{$30861}` | kubesphere-sample-dev | ks-sample-dev | ks-sample-dev |
|
||||
| Production | `http://{$NodeIP}:{$30961}` | kubesphere-sample-prod | ks-sample | ks-sample |
|
||||
|
||||
#### Deployments
|
||||
|
||||

|
||||
|
||||
#### Services
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups so that you can access the app with the URL.
|
||||
|
|
@ -310,13 +252,9 @@ The account `project-admin` needs to be created in advance since it is the revie
|
|||
|
||||
### Step 8: Access the example Service
|
||||
|
||||
1. To access the Service, log in to KubeSphere as `admin` to use the **web kubectl** from **Toolbox**. Go to the project `kubesphere-sample-dev`, and select `ks-sample-dev` in **Services** under **Application Workloads**. The endpoint can be used to access the Service.
|
||||
1. To access the Service, log in to KubeSphere as `admin` to use the **kubectl** from **Toolbox**. Go to the project `kubesphere-sample-dev`, and click `ks-sample-dev` in **Services** under **Application Workloads**. Obtain the endpoint displayed on the details page to access the Service.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
2. Use the **web kubectl** from **Toolbox** in the bottom-right corner by executing the following command:
|
||||
2. Use the **kubectl** from **Toolbox** in the lower-right corner by executing the following command:
|
||||
|
||||
```bash
|
||||
curl 10.233.120.230:8080
|
||||
|
|
|
|||
|
|
@ -10,13 +10,11 @@ Credentials are objects containing sensitive information, such as usernames and
|
|||
|
||||
A DevOps project user with necessary permissions can configure credentials for Jenkins pipelines. Once the user adds or configures these credentials in a DevOps project, they can be used in the DevOps project to interact with third-party applications.
|
||||
|
||||
Currently, you can store the following 4 types of credentials in a DevOps project:
|
||||
Currently, you can create the following 4 types of credentials in a DevOps project:
|
||||
|
||||

|
||||
|
||||
- **Account Credentials**: Username and password which can be handled as separate components or as a colon-separated string in the format `username:password`, such as accounts of GitHub, GitLab, and Docker Hub.
|
||||
- **SSH**: Username with a private key, an SSH public/private key pair.
|
||||
- **Secret Text**: Secret content in a file.
|
||||
- **Username and password**: Username and password which can be handled as separate components or as a colon-separated string in the format `username:password`, such as accounts of GitHub, GitLab, and Docker Hub.
|
||||
- **SSH key**: Username with a private key, an SSH public/private key pair.
|
||||
- **Access token**: a token with certain access.
|
||||
- **kubeconfig**: It is used to configure cross-cluster authentication. If you select this type, the dialog will auto-populate the field with the kubeconfig file of the current Kubernetes cluster.
|
||||
|
||||
This tutorial demonstrates how to create and manage credentials in a DevOps project. For more information about how credentials are used, see [Create a Pipeline Using a Jenkinsfile](../create-a-pipeline-using-jenkinsfile/) and [Create a Pipeline Using Graphical Editing Panels](../create-a-pipeline-using-graphical-editing-panel/).
|
||||
|
|
@ -24,31 +22,27 @@ This tutorial demonstrates how to create and manage credentials in a DevOps proj
|
|||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere DevOps System](../../../pluggable-components/devops/).
|
||||
- You have a workspace, a DevOps project and an account (`project-regular`) invited to the DevOps project with the `operator` role. If they are not ready yet, see [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You have a workspace, a DevOps project and a user (`project-regular`) invited to the DevOps project with the `operator` role. If they are not ready yet, see [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Create Credentials
|
||||
|
||||
Log in to the console of KubeSphere as `project-regular`. Navigate to your DevOps project, choose **Credentials** and click **Create**.
|
||||
|
||||

|
||||
Log in to the console of KubeSphere as `project-regular`. Navigate to your DevOps project, select **Credentials** and click **Create**.
|
||||
|
||||
### Create Docker Hub credentials
|
||||
|
||||
1. In the dialog that appears, provide the following information.
|
||||
1. In the displayed dialog box, provide the following information.
|
||||
|
||||

|
||||
|
||||
- **Credential ID**: Set an ID, such as `dockerhub-id`, which can be used in pipelines.
|
||||
- **Type**: Select **Account Credentials**.
|
||||
- **Username**: Your Docker Hub account (i.e Docker ID).
|
||||
- **Token/Password**: Your Docker Hub password.
|
||||
- **Name**: Set a name, such as `dockerhub-id`, which can be used in pipelines.
|
||||
- **Type**: Select **Username and password**.
|
||||
- **Username**: Your Docker Hub account (for example, Docker ID).
|
||||
- **Password/Token**: Your Docker Hub password.
|
||||
- **Description**: A brief introduction to the credentials.
|
||||
|
||||
2. Click **OK** when you finish.
|
||||
|
||||
### Create GitHub credentials
|
||||
|
||||
Similarly, follow the same steps above to create GitHub credentials. Set a different Credential ID (for example, `github-id`) and also select **Account Credentials** for **Type**. Enter your GitHub username and password for **Username** and **Token/Password** respectively.
|
||||
Similarly, follow the same steps above to create GitHub credentials. Set a different credential name (for example, `github-id`) and also select **Username and password** for **Type**. Enter your GitHub username and password for **Username** and **Password/Token** respectively.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -58,7 +52,7 @@ If there are any special characters such as `@` and `$` in your account or passw
|
|||
|
||||
### Create kubeconfig credentials
|
||||
|
||||
Similarly, follow the same steps above to create kubeconfig credentials. Set a different Credential ID (for example, `demo-kubeconfig`) and select **kubeconfig**.
|
||||
Similarly, follow the same steps above to create kubeconfig credentials. Set a different credential name (for example, `demo-kubeconfig`) and select **kubeconfig**.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
|
|
@ -68,18 +62,12 @@ A file that is used to configure access to clusters is called a kubeconfig file.
|
|||
|
||||
## View and Manage Credentials
|
||||
|
||||
1. Credentials created appear in the list as below.
|
||||
1. Credentials created are displayed in the list.
|
||||
|
||||

|
||||
|
||||
2. Click any of them to go to its detail page, where you can see account details and all the events related to the credentials.
|
||||
|
||||

|
||||
2. Click any of them to go to its details page, where you can see account details and all the events related to the credentials.
|
||||
|
||||
3. You can also edit or delete credentials on this page. Note that when you edit credentials, KubeSphere does not display the existing username or password information. The previous one will be overwritten if you enter a new username and password.
|
||||
|
||||

|
||||
|
||||
## See Also
|
||||
|
||||
[Create a Pipeline Using a Jenkinsfile](../create-a-pipeline-using-jenkinsfile/)
|
||||
|
|
|
|||
|
|
@ -8,19 +8,19 @@ weight: 11291
|
|||
|
||||
[GitLab](https://about.gitlab.com/) is an open source code repository platform that provides public and private repositories. It is a complete DevOps platform that enables professionals to perform their tasks in a project.
|
||||
|
||||
In KubeSphere v3.1, you can create a multi-branch pipeline with GitLab in your DevOps project. This tutorial demonstrates how to create a multi-branch pipeline with GitLab.
|
||||
In KubeSphere 3.1.x and later, you can create a multi-branch pipeline with GitLab in your DevOps project. This tutorial demonstrates how to create a multi-branch pipeline with GitLab.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to have a [GitLab](https://gitlab.com/users/sign_in) account and a [Docker Hub](https://hub.docker.com/) account.
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project and an account (`project-regular`). This account must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project and a user (`project-regular`). This user must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create credentials
|
||||
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **Project Management**. For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
1. Log in to the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **DevOps Project Settings**. For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -36,29 +36,19 @@ In KubeSphere v3.1, you can create a multi-branch pipeline with GitLab in your D
|
|||
|
||||
2. After creation, you can see the credentials in the list.
|
||||
|
||||

|
||||
|
||||
### Step 2: Modify the Jenkinsfile in your GitLab repository
|
||||
|
||||
1. Log in to GitLab and create a public project. Click **Import project/repository**, select **Repo by URL** to enter the URL of [devops-java-sample](https://github.com/kubesphere/devops-java-sample), select **Public** for **Visibility Level**, and then click **Create project**.
|
||||
|
||||

|
||||
|
||||

|
||||
1. Log in to GitLab and create a public project. Click **Import project/repository**, select **Repo by URL** to enter the URL of [devops-maven-sample](https://github.com/kubesphere/devops-maven-sample), select **Public** for **Visibility Level**, and then click **Create project**.
|
||||
|
||||
2. In the project just created, create a new branch from the master branch and name it `gitlab-demo`.
|
||||
|
||||

|
||||
|
||||
3. In the `gitlab-demo` branch, click the file `Jenkinsfile-online` in the root directory.
|
||||
|
||||

|
||||
|
||||
4. Click **Edit**, change `GITHUB_CREDENTIAL_ID`, `GITHUB_ACCOUNT`, and `@github.com` to `GITLAB_CREDENTIAL_ID`, `GITLAB_ACCOUNT`, and `@gitlab.com` respectively, and then edit the following items. You also need to change the value of `branch` in the `push latest` and `deploy to dev` stages to `gitlab-demo`.
|
||||
|
||||
| Item | Value | Description |
|
||||
| -------------------- | --------- | ------------------------------------------------------------ |
|
||||
| GITLAB_CREDENTIAL_ID | gitlab-id | The **Credential ID** you set in KubeSphere for your GitLab account. It is used to push tags to your GitLab repository. |
|
||||
| GITLAB_CREDENTIAL_ID | gitlab-id | The **Name** you set in KubeSphere for your GitLab account. It is used to push tags to your GitLab repository. |
|
||||
| DOCKERHUB_NAMESPACE | felixnoo | Replace it with your Docker Hub’s account name. It can be the Organization name under the account. |
|
||||
| GITLAB_ACCOUNT | felixnoo | Replace it with your GitLab account name. It can also be the account’s Group name. |
|
||||
|
||||
|
|
@ -70,8 +60,6 @@ In KubeSphere v3.1, you can create a multi-branch pipeline with GitLab in your D
|
|||
|
||||
5. Click **Commit changes** to update this file.
|
||||
|
||||

|
||||
|
||||
### Step 3: Create projects
|
||||
|
||||
You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere-sample-prod`, which represent the development environment and the production environment respectively. For more information, refer to [Create a Pipeline Using a Jenkinsfile](../create-a-pipeline-using-jenkinsfile/#step-3-create-projects).
|
||||
|
|
@ -80,23 +68,21 @@ You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere
|
|||
|
||||
1. Log in to the KubeSphere web console as `project-regular`. Go to your DevOps project and click **Create** to create a new pipeline.
|
||||
|
||||
2. Provide the basic information in the dialog that appears. Name it `gitlab-multi-branch` and select a code repository.
|
||||
2. Provide the basic information in the displayed dialog box. Name it `gitlab-multi-branch` and select a code repository.
|
||||
|
||||

|
||||
|
||||
3. In the **GitLab** tab, select the default option `https://gitlab.com` for GitLab Server, enter the username of the GitLab project owner for **Owner**, and then select the `devops-java-sample` repository from the drop-down list for **Repository Name**. Click the tick icon in the bottom-right corner and then click **Next**.
|
||||
|
||||

|
||||
3. On the **GitLab** tab, select the default option `https://gitlab.com` for **GitLab Server Address**, enter the username of the GitLab project owner for **Project Group/Owner**, and then select the `devops-maven-sample` repository from the drop-down list for **Code Repository**. Click **√** in the lower-right corner and then click **Next**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you want to use a private repository from GitLab, you need to create an access token with API and read_repository permissions on GitLab, create a credential for accessing GitLab on the Jenkins dashboard, and then add the credential in **GitLab Server** under **Configure System**. For more information about how to log in to Jenkins, refer to [Jenkins System Settings](../jenkins-setting/#log-in-to-jenkins-to-reload-configurations).
|
||||
If you want to use a private repository from GitLab, refer to the following steps:
|
||||
|
||||
- Go to **User Settings > Access Tokens** on GitLab to create an access token with API and read_repository permissions.
|
||||
- [Log in to the Jenkins dashboard](../../how-to-integrate/sonarqube/#step-5-add-the-sonarqube-server-to-jenkins), go to **Manage Jenkins > Manage Credentials** to use your GitLab token to create a Jenkins credential for accessing GitLab, and go to **Manage Jenkins > Configure System** to add the credential in **GitLab Server**.
|
||||
- In your DevOps project, select **DevOps Project Settings > Credentials** to use your GitLab token to create a credential. You have to specify the credential for **Credential** on the **GitLab** tab when creating a pipeline so that the pipeline can pull code from your private GitLab repository.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. In the **Advanced Settings** tab, scroll down to **Script Path**. Change it to `Jenkinsfile-online` and then click **Create**.
|
||||
|
||||

|
||||
4. On the **Advanced Settings** tab, scroll down to **Script Path**. Change it to `Jenkinsfile-online` and then click **Create**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -106,13 +92,9 @@ You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere
|
|||
|
||||
### Step 5: Run a pipeline
|
||||
|
||||
1. After a pipeline is created, it displays in the list. Click it to go to its detail page.
|
||||
1. After a pipeline is created, it is displayed in the list. Click its name to go to its details page.
|
||||
|
||||
2. Click **Run** on the right. In the dialog that appears, select **gitlab-demo** from the drop-down list and add a tag number such as `v0.0.2`. Click **OK** to trigger a new activity.
|
||||
|
||||

|
||||
|
||||

|
||||
2. Click **Run** on the right. In the displayed dialog box, select **gitlab-demo** from the drop-down list and add a tag number such as `v0.0.2`. Click **OK** to trigger a new run.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -122,23 +104,15 @@ You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere
|
|||
|
||||
### Step 6: Check the pipeline status
|
||||
|
||||
1. In the **Task Status** tab, you can see how a pipeline is running. Check the pipeline running logs by clicking **Show Logs** in the top-right corner.
|
||||
|
||||

|
||||
1. In the **Task Status** tab, you can see how a pipeline is running. Check the pipeline running logs by clicking **View Logs** in the upper-right corner.
|
||||
|
||||
2. You can see the dynamic log output of the pipeline, including any errors that may stop the pipeline from running. For each stage, you can click it to inspect logs, which can also be downloaded to your local machine for further analysis.
|
||||
|
||||

|
||||
|
||||
### Step 7: Verify results
|
||||
|
||||
1. The Docker image built through the pipeline has been successfully pushed to Docker Hub, as it is defined in the Jenkinsfile. In Docker Hub, you will find the image with the tag `v0.0.2` that is specified before the pipeline runs.
|
||||
|
||||

|
||||
|
||||
2. At the same time, a new tag has been generated in GitLab.
|
||||
|
||||

|
||||
2. At the same time, a new tag is generated in GitLab.
|
||||
|
||||
3. The sample application will be deployed to `kubesphere-sample-dev` and `kubesphere-sample-prod` with corresponding Deployments and Services created.
|
||||
|
||||
|
|
@ -147,10 +121,6 @@ You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere
|
|||
| Development | `http://{$NodeIP}:{$30861}` | kubesphere-sample-dev | ks-sample-dev | ks-sample-dev |
|
||||
| Production | `http://{$NodeIP}:{$30961}` | kubesphere-sample-prod | ks-sample | ks-sample |
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups so that you can access the app with the URL. For more information, refer to [Access the example Service](../create-a-pipeline-using-jenkinsfile/#step-8-access-the-example-service).
|
||||
|
|
|
|||
|
|
@ -12,27 +12,25 @@ The built-in Jenkins cannot share the same email configuration with the platform
|
|||
## Prerequisites
|
||||
|
||||
- You need to enable the [KubeSphere DevOps System](../../../pluggable-components/devops/).
|
||||
- You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
- You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
## Set the Email Server
|
||||
|
||||
1. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../../multicluster-management/) with member clusters imported, you can select a specific cluster to view its nodes. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. Go to **Workloads** under **Application Workloads**, and choose the project **kubesphere-devops-system** from the drop-down list. Click <img src="/images/docs/devops-user-guide/using-devops/jenkins-email/three-dots.png" height="15px"> on the right of **ks-jenkins** to edit its YAML.
|
||||
3. Go to **Workloads** under **Application Workloads**, and select the project **kubesphere-devops-system** from the drop-down list. Click <img src="/images/docs/common-icons/three-dots.png" height="15" /> on the right of `devops-jenkins` and select **Edit YAML** to edit its YAML.
|
||||
|
||||

|
||||
|
||||
4. Scroll down to the fields in the image below which you need to specify. Click **Update** when you finish to save changes.
|
||||
4. Scroll down to the fields in the image below which you need to specify. Click **OK** when you finish to save changes.
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
Once you modify the Email server in the `ks-jenkins` Deployment, it will restart itself. Consequently, the DevOps system will be unavailable for a few minutes. Please make such modification at an appropriate time.
|
||||
Once you modify the Email server in the `devops-jenkins` Deployment, it will restart itself. Consequently, the DevOps system will be unavailable for a few minutes. Please make such modification at an appropriate time.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||

|
||||
|
||||
| Environment Variable Name | Description |
|
||||
| ------------------------- | -------------------------------- |
|
||||
|
|
|
|||
|
|
@ -28,61 +28,17 @@ Besides, you can find the `formula.yaml` file in the repository [ks-jenkins](htt
|
|||
|
||||
It is recommended that you configure Jenkins in KubeSphere through Configuration as Code (CasC). The built-in Jenkins CasC file is stored as a [ConfigMap](../../../project-user-guide/configuration/configmaps/).
|
||||
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Log in to KubeSphere as `admin`. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../../multicluster-management/) with member clusters imported, you can select a specific cluster to edit the ConfigMap. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. From the navigation bar, select **ConfigMaps** under **Configurations**. On the **ConfigMaps** page, select `kubesphere-devops-system` from the drop-down list and click `jenkins-casc-config`.
|
||||
3. On the left navigation pane, select **ConfigMaps** under **Configuration**. On the **ConfigMaps** page, select `kubesphere-devops-system` from the drop-down list and click `jenkins-casc-config`.
|
||||
|
||||

|
||||
4. On the details page, click **Edit YAML** from the **More** drop-down list.
|
||||
|
||||
4. On the detail page, click **Edit YAML** from the **More** drop-down list.
|
||||
5. The configuration template for `jenkins-casc-config` is a YAML file under the `data.jenkins_user.yaml:` section. You can modify the container image, label, resource requests and limits, etc. in the broker (Kubernetes Jenkins agent) in the ConfigMap or add a container in the podTemplate. When you finish, click **OK**.
|
||||
|
||||

|
||||
|
||||
5. The configuration template for `jenkins-casc-config` is a YAML file as shown below. You can modify the container image, label, resource requests and limits, etc. in the broker (Kubernetes Jenkins agent) in the ConfigMap or add a container in the podTemplate. When you finish, click **Update**.
|
||||
|
||||

|
||||
|
||||
## Log in to Jenkins to Reload Configurations
|
||||
|
||||
After you modified `jenkins-casc-config`, you need to reload your updated system configuration on the **Configuration as Code** page on the Jenkins dashboard. This is because system settings configured directly through the Jenkins dashboard may be overwritten by the CasC configuration after Jenkins is rescheduled.
|
||||
|
||||
1. Execute the following command to get the address of Jenkins.
|
||||
|
||||
```bash
|
||||
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services ks-jenkins)
|
||||
export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
echo http://$NODE_IP:$NODE_PORT
|
||||
```
|
||||
|
||||
2. You can see the expected output as below, which tells you the IP address and port number of Jenkins.
|
||||
|
||||
```bash
|
||||
http://192.168.0.4:30180
|
||||
```
|
||||
|
||||
3. Access Jenkins at `http://Node IP:Port Number`. When KubeSphere is installed, the Jenkins dashboard is also installed by default. Besides, Jenkins is configured with KubeSphere LDAP, which means you can log in to Jenkins with KubeSphere accounts (for example, `admin/P@88w0rd`) directly.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to set up necessary port forwarding rules and open port `30180` to access Jenkins in your security groups depending on where your instances are deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. After you log in to the dashboard, click **Manage Jenkins** from the navigation bar.
|
||||
|
||||

|
||||
|
||||
5. Scroll down and click **Configuration as Code**.
|
||||
|
||||

|
||||
|
||||
6. To reload configurations that you have modified in the ConfigMap, click **Apply new configuration**.
|
||||
|
||||

|
||||
6. Wait for at least 70 seconds until your changes are automatically reloaded.
|
||||
|
||||
7. For more information about how to set up Jenkins via CasC, see the [Jenkins documentation](https://github.com/jenkinsci/configuration-as-code-plugin).
|
||||
|
||||
|
|
@ -90,4 +46,5 @@ After you modified `jenkins-casc-config`, you need to reload your updated system
|
|||
|
||||
In the current version, not all plugins support CasC settings. CasC will only overwrite plugin configurations that are set up through CasC.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -13,32 +13,26 @@ This tutorial demonstrates how to use Jenkins shared libraries in KubeSphere Dev
|
|||
## Prerequisites
|
||||
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project and an account (`project-regular`). This account must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project and a user (`project-regular`). This user must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to have a Jenkins shared library available. This tutorial uses the Jenkins shared library in [a GitHub repository](https://github.com/devops-ws/jenkins-shared-library) as an example.
|
||||
|
||||
## Configure a Shared Library on the Jenkins Dashboard
|
||||
|
||||
1. [Log in to the Jenkins dashboard](../jenkins-setting/#log-in-to-jenkins-to-reload-configurations) and click **Manage Jenkins** in the left navigation bar.
|
||||
1. [Log in to the Jenkins dashboard](../../how-to-integrate/sonarqube/#step-5-add-the-sonarqube-server-to-jenkins) and click **Manage Jenkins** in the left navigation pane.
|
||||
|
||||
2. Scroll down and click **Configure System**.
|
||||
|
||||

|
||||
2. Scroll down and click **Configure System**.
|
||||
|
||||
3. Scroll down to **Global Pipeline Libraries** and click **Add**.
|
||||
|
||||

|
||||
|
||||
4. Configure the fields as below.
|
||||
|
||||
- **Name**. Set a name (for example, `demo-shared-library`) for the shared library so that you can import the shared library by referring to this name in a Jenkinsfile.
|
||||
|
||||
- **Default version**. Set a branch name from the repository where you put your shared library as the default branch for importing your shared library. Enter `master` for this tutorial.
|
||||
|
||||
- Under **Retrieval method**, choose **Modern SCM**.
|
||||
- Under **Retrieval method**, select **Modern SCM**.
|
||||
|
||||
- Under **Source Code Management**, choose **Git** and enter the URL of the example repository for **Project Repository**. You have to configure **Credentials** if you use your own repository that requires the credentials for accessing it.
|
||||
|
||||

|
||||
- Under **Source Code Management**, select **Git** and enter the URL of the example repository for **Project Repository**. You have to configure **Credentials** if you use your own repository that requires the credentials for accessing it.
|
||||
|
||||
5. When you finish editing, click **Apply**.
|
||||
|
||||
|
|
@ -54,19 +48,13 @@ This tutorial demonstrates how to use Jenkins shared libraries in KubeSphere Dev
|
|||
|
||||
1. Log in to the KubeSphere web console as `project-regular`. Go to your DevOps project and click **Create** on the **Pipelines** page.
|
||||
|
||||
2. Set a name (for example, `demo-shared-library`) in the pop-up window and click **Next**.
|
||||
2. Set a name (for example, `demo-shared-library`) in the displayed dialog box and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. In **Advanced Settings**, click **Create** directly to create a pipeline with the default settings.
|
||||
|
||||

|
||||
3. On the **Advanced Settings** tab, click **Create** to create a pipeline with the default settings.
|
||||
|
||||
### Step 2: Edit the pipeline
|
||||
|
||||
1. In the pipeline list, click the pipeline to go to its detail page and click **Edit Jenkinsfile**.
|
||||
|
||||

|
||||
1. In the pipeline list, click the pipeline to go to its details page and click **Edit Jenkinsfile**.
|
||||
|
||||
2. In the displayed dialog box, enter the following example Jenkinsfile. When you finish editing, click **OK**.
|
||||
|
||||
|
|
@ -126,15 +114,9 @@ This tutorial demonstrates how to use Jenkins shared libraries in KubeSphere Dev
|
|||
|
||||
### Step 3: Run the pipeline
|
||||
|
||||
1. You can view the stage under the **Pipeline** tab. Click **Run** to run it.
|
||||
1. You can view the stage under the **Task Status** tab. Click **Run** to run it.
|
||||
|
||||

|
||||
2. After a while, the pipeline ran successfully.
|
||||
|
||||
2. After a while, the pipeline will run successfully.
|
||||
|
||||

|
||||
|
||||
3. You can click the **Success** record under **Status**, and then click **Show Logs** to view the log details.
|
||||
|
||||

|
||||
3. You can click the **Successful** record under **Run Records**, and then click **View Logs** to view the log details.
|
||||
|
||||
|
|
|
|||
|
|
@ -10,169 +10,141 @@ When you create a pipeline, you can customize its configurations through various
|
|||
|
||||
## Prerequisites
|
||||
|
||||
- You need to create a workspace, a DevOps project and an account (`project-regular`). This account must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to create a workspace, a DevOps project and a user (`project-regular`). This user must be invited to the DevOps project with the `operator` role. For more information, refer to [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/).
|
||||
- You need to [enable the KubeSphere DevOps System](../../../pluggable-components/devops/).
|
||||
|
||||
## Pipeline Settings
|
||||
|
||||
### Basic Information
|
||||
|
||||

|
||||
## Basic Information
|
||||
|
||||
On the **Basic Information** tab, you can customize the following information:
|
||||
|
||||
- **Name**. The name of the pipeline. Pipelines in the same DevOps project must have different names.
|
||||
|
||||
- **Project**. Projects will be grouped by their resources, which you can view and manage by project.
|
||||
- **DevOps Project**. The DevOps project to which the pipeline belongs.
|
||||
|
||||
- **Description**. The additional information to describe the pipeline. Description is limited to 256 characters.
|
||||
|
||||
- **Code Repository (optional)**. You can select a code repository as the code source for the pipeline. In KubeSphere v3.1, you can select GitHub, GitLab, Bitbucket, Git, and SVN as the code source.
|
||||
- **Code Repository (optional)**. You can select a code repository as the code source for the pipeline. You can select GitHub, GitLab, Bitbucket, Git, and SVN as the code source.
|
||||
|
||||
{{< tabs >}}
|
||||
|
||||
{{< tab "GitHub" >}}
|
||||
|
||||

|
||||
|
||||
If you select **GitHub**, you have to specify the token for accessing GitHub. If you have created a credential with your GitHub token in advance, you can select it from the drop-down list, or you can click **Create a credential** to create a new one. Click **Confirm** after selecting the token and you can view your repository on the right. Click the **√** icon after you finish all operations.
|
||||
If you select **GitHub**, you have to specify the credential for accessing GitHub. If you have created a credential with your GitHub token in advance, you can select it from the drop-down list, or you can click **Create Credential** to create a new one. Click **OK** after selecting the credential and you can view your repository on the right. Click the **√** icon after you finish all operations.
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "GitLab" >}}
|
||||
|
||||

|
||||
|
||||
If you select **GitLab**, you have to specify the GitLab server, owner and repository name. You also need to specify a credential if it is needed for obtaining repository codes. Click the **√** icon after you finish all operations.
|
||||
If you select **GitLab**, you have to specify the GitLab server address, project group/owner, and code repository. You also need to specify a credential if it is needed for accessing the code repository. Click the **√** icon after you finish all operations.
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "Bitbucket" >}}
|
||||
|
||||

|
||||
|
||||
If you select **Bitbucket**, you have to enter your Bitbucket server. You can create a credential with your Bitbucket username and password in advance and then select the credential from the drop-down list, or you can click **Create a credential** to create a new one. Click **Confirm** after entering the information and you can view your repository on the right. Click the **√** icon after you finish all operations.
|
||||
If you select **Bitbucket**, you have to enter your Bitbucket server address. You can create a credential with your Bitbucket username and password in advance and then select the credential from the drop-down list, or you can click **Create Credential** to create a new one. Click **OK** after entering the information, and you can view your repository on the right. Click the **√** icon after you finish all operations.
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "Git" >}}
|
||||
|
||||

|
||||
|
||||
If you select **Git**, you have to specify the repository URL. You need to specify a credential if it is needed for obtaining repository codes. You can also click **Create a credential** to create a new credential. Click the **√** icon after you finish all operations.
|
||||
If you select **Git**, you have to specify the repository URL. You need to specify a credential if it is needed for accessing the code repository. You can also click **Create Credential** to create a new credential. Click the **√** icon after you finish all operations.
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "SVN" >}}
|
||||
|
||||

|
||||
|
||||
If you select **SVN**, you have to specify the repository URL and the credential. You can also specify the branch included and excluded based on your needs. Click the **√** icon after you finish all operations.
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{</ tabs >}}
|
||||
|
||||
### Advanced Settings with A Code Repository Selected
|
||||
## Advanced Settings with Code Repository Specified
|
||||
|
||||
If you selected a code repository, you can customize the following configurations on the **Advanced Settings** tab:
|
||||
If you specify a code repository, you can customize the following configurations on the **Advanced Settings** tab:
|
||||
|
||||
**Branch Settings**
|
||||
### Branch Settings
|
||||
|
||||

|
||||
**Delete outdated branches**. Delete outdated branches automatically. The branch record is deleted all together. The branch record includes console output, archived artifacts and other relevant metadata of specific branches. Fewer branches mean that you can save the disk space that Jenkins is using. KubeSphere provides two options to determine when old branches are discarded:
|
||||
|
||||
**Discard old branch** means that the branch record will be discarded all together. The branch record includes console output, archived artifacts and other relevant metadata of specific branches. Fewer branches mean that you can save the disk space that Jenkins is using. KubeSphere provides two options to determine when old branches are discarded:
|
||||
- **Branch Retention Period (days)**. Branches that exceeds the retention period are deleted.
|
||||
|
||||
- **Days to keep old branches**. Branches will be discarded after a certain number of days.
|
||||
|
||||
- **Maximum number of branches to keep**. The oldest branches will be discarded after branches reach a certain amount.
|
||||
- **Maximum Branches**. When the number of branches exceeds the maximum number, the earliest branch is deleted.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
**Days to keep old branches** and **Maximum number of branches to keep** apply to branches at the same time. As long as a branch meets the condition of either field, it will be discarded. For example, if you specify 2 as the number of retention days and 3 as the maximum number of branches, any branches that exceed either number will be discarded. KubeSphere prepopulates these two fields with -1 by default, which means deleted branches will be discarded.
|
||||
**Branch Retention Period (days)** and **Maximum Branches** apply to branches at the same time. As long as a branch meets the condition of either field, it will be discarded. For example, if you specify 2 as the number of retention days and 3 as the maximum number of branches, any branches that exceed either number will be discarded. KubeSphere prepopulates these two fields with 7 and 5 by default respectively.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
**Behavioral strategy**
|
||||
### Strategy Settings
|
||||
|
||||

|
||||
|
||||
In **Behavioral strategy**, KubeSphere offers four strategies by default. As a Jenkins pipeline runs, the Pull Request (PR) submitted by developers will also be regarded as a separate branch.
|
||||
In **Strategy Settings**, KubeSphere offers four strategies by default. As a Jenkins pipeline runs, the Pull Request (PR) submitted by developers will also be regarded as a separate branch.
|
||||
|
||||
**Discover Branches**
|
||||
|
||||
- **Exclude branches that are also filed as PRs**. The source branch is not scanned such as the origin’s master branch. These branches need to be merged.
|
||||
- **Only branches that are also filed as PRs**. Only scan the PR branch.
|
||||
- **All branches**. Pull all the branches from the repository origin.
|
||||
- **Exclude branches filed as PRs**. The branches filed as PRs are excluded.
|
||||
- **Include only branches filed as PRs**. Only pull the branches filed as PRs.
|
||||
- **Include all branches**. Pull all the branches from the repository.
|
||||
|
||||
**Discover Tag Branches**
|
||||
**Discover Tags**
|
||||
|
||||
- **Enable discovery of Tag branch**. The branch with a specific tag will be scanned.
|
||||
- **Disable the discovery of the Tag branch**. The branch with a specific tag will not be scanned.
|
||||
- **Enable tag discovery**. The branch with a specific tag is scanned.
|
||||
- **Disable tag discovery**. The branch with a specific tag is not scanned.
|
||||
|
||||
**Discover PR from Origin**
|
||||
**Discover PRs from Origin**
|
||||
|
||||
- **Source code version of PR merged with target branch**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Source code version of PR itself**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Two pipelines are created when a PR is discovered**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
- **Pull the code with the PR merged**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Pull the code at the point of the PR**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Create two pipelines respectively**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
|
||||
**Discover PR from Forks**
|
||||
**Discover PRs from Forks**
|
||||
|
||||
- **Source code version of PR merged with target branch**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Source code version of PR itself**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Two pipelines are created when a PR is discovered**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
- **Pull the code with the PR merged**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Pull the code at the point of the PR**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Create two pipelines respectively**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
- **Contributors**. The users who make contributions to the PR.
|
||||
- **Everyone**. Every user who can access the PR.
|
||||
- **From users with Admin or Write permission**. Only from users with Admin or Write permission to the PR.
|
||||
- **Nobody**. If you select this option, no PR will be discovered despite the option you select in **Pull Strategy**.
|
||||
- **Users with the admin or write permission**. Only from users with the admin or write permission to the PR.
|
||||
- **None**. If you select this option, no PR will be discovered despite the option you select in **Pull Strategy**.
|
||||
|
||||
**Script Path**
|
||||
### Filter by Regex
|
||||
|
||||

|
||||
Select the checkbox to specify a regular expression to filter branches, PRs, and tags.
|
||||
|
||||
The field of **Script Path** specifies the Jenkinsfile path in the code repository. It indicates the repository’s root directory. If the file location changes, the script path also needs to be changed.
|
||||
### Script Path
|
||||
|
||||
**Scan Repo Trigger**
|
||||
The **Script Path** parameter specifies the Jenkinsfile path in the code repository. It indicates the repository’s root directory. If the file location changes, the script path also needs to be changed.
|
||||
|
||||

|
||||
### Scan Trigger
|
||||
|
||||
You can check **Enable regular expressions, ignoring names that do not match the provided regular expression (including branches and PRs)** to specify a regular expression as the trigger for scanning the code repository.
|
||||
Select **Scan periodically** and set the scan interval from the drop-down list.
|
||||
|
||||
You can also check **If not, scan regularly** and set the scan interval from the drop-down list.
|
||||
### Build Trigger
|
||||
|
||||
**Build Trigger**
|
||||
You can select a pipeline from the drop-down list for **Trigger on Pipeline Creation** and **Trigger on Pipeline Deletion** so that when a new pipeline is created or a pipeline is deleted, the tasks in the specified pipeline can be automatically triggered.
|
||||
|
||||

|
||||
### Clone Settings
|
||||
|
||||
You can select a pipeline from the drop-down list for **When Create Pipeline** and **When Delete Pipeline** so that when a new pipeline is created or a pipeline is deleted, the tasks in the specified pipeline can be automatically triggered.
|
||||
- **Clone Depth**. The number of commits to fetch when you clone.
|
||||
- **Clone Timeout Period (min)**. The number of minutes before which the cloning process has to complete.
|
||||
- **Enable shallow clone**. Enable the shallow clone or not. If you enable it, the codes cloned will not contain tags.
|
||||
|
||||
**Git Clone Options**
|
||||
### Webhook
|
||||
|
||||

|
||||
**Webhook** is an efficient way to allow pipelines to discover changes in the remote code repository and automatically trigger a new running. Webhook should be the primary method to trigger Jenkins automatic scanning for GitHub and Git (for example, GitLab).
|
||||
|
||||
- **clone depth**. The number of commits to fetch when you clone.
|
||||
- **Pipeline clone timeout (in minutes)**. The number of minutes before which the cloning process has to complete.
|
||||
- **Whether to enable shallow clone**. Enable the shallow clone or not. If you enable it, the codes cloned will not contain tags.
|
||||
## Advanced Settings with No Code Repository Specified
|
||||
|
||||
**Webhook Push**
|
||||
If you do not specify a code repository, you can customize the following configurations on the **Advanced Settings** tab:
|
||||
|
||||

|
||||
### Build Settings
|
||||
|
||||
**Webhook Push** is an efficient way to allow pipelines to discover changes in the remote code repository and automatically trigger a new running. Webhook should be the primary method to trigger Jenkins automatic scanning for GitHub and Git (for example, GitLab).
|
||||
**Delete outdated build records**. Determine when the build records under the branch are deleted. The build record includes the console output, archived artifacts, and other metadata related to a particular build. Keeping fewer builds saves disk space used by Jenkins. KubeSphere provides two options to determine when old builds are deleted:
|
||||
|
||||
### Advanced Settings with No Code Repository Selected
|
||||
- **Build Record Retention Period (days)**. Build records that exceed the retention period are deleted.
|
||||
|
||||
If you don't select a code repository, you can customize the following configurations on the **Advanced Settings** tab:
|
||||
|
||||
**Build Settings**
|
||||
|
||||

|
||||
|
||||
**Discard old builds** determines when the build records under the branch will be discarded. The build record includes the console output, archived artifacts, and other metadata related to a particular build. Keeping fewer builds saves disk space used by Jenkins. KubeSphere provides two options to determine when old builds are discarded:
|
||||
|
||||
- **Days to keep build**. The build will be discarded after a certain number of days.
|
||||
|
||||
- **Maximum number of builds to keep**. If the existing number of builds exceeds the maximum number, the oldest build will be discarded.
|
||||
- **Maximum Build Records**. When the number of build records exceeds the maximum number, the earliest build record is deleted.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -180,20 +152,15 @@ If you don't select a code repository, you can customize the following configura
|
|||
|
||||
{{</ notice >}}
|
||||
|
||||
- **No concurrent builds**. If you check this option, you cannot run multiple builds concurrently.
|
||||
- **No concurrent builds**. If you select this option, you cannot run multiple builds concurrently.
|
||||
|
||||
**Parametric Build**
|
||||
### Build Parameters
|
||||
|
||||

|
||||
The parameterized build process allows you to pass in one or more parameters when you start to run a pipeline. KubeSphere provides five types of parameters by default, including **String**, **Multi-line string**, **Boolean**, **Options**, and **Password**. When you parameterize a project, the build is replaced with a parameterized build, which prompts the user to enter a value for each defined parameter.
|
||||
|
||||
The parameterized build process allows you to pass in one or more parameters when you start to run a pipeline. KubeSphere provides five types of parameters by default, including **String**, **Text**, **Boolean**, **Choice**, and **Password**. When you parameterize a project, the build is replaced with a parameterized build, which prompts the user to enter a value for each defined parameter.
|
||||
### Build Trigger
|
||||
|
||||
**Build Trigger**
|
||||
|
||||

|
||||
|
||||
- **Scheduled build**. It enables builds with a specified schedule. You can click **CRON** to refer to the detailed cron syntax.
|
||||
- **Trigger a remote build (for example, using a script)**. If you need to access a predefined URL to remotely trigger the build, you have to check it and provide an authentication token so that only the user who has the token can remotely trigger the build.
|
||||
**Build periodically**. It enables builds with a specified schedule. Click **Learn More** to see the detailed CRON syntax.
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ This tutorial demonstrates how to trigger a pipeline by using a webhook.
|
|||
## Prerequisites
|
||||
|
||||
- You need to [enable the KubeSphere DevOps system](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project, and an account (`project-regular`). This account needs to be invited to the DevOps project and assigned the `operator` role. See [Create Workspaces, Projects, Accounts and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to create a workspace, a DevOps project, and a user (`project-regular`). This account needs to be invited to the DevOps project and assigned the `operator` role. See [Create Workspaces, Projects, Users and Roles](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
|
||||
- You need to create a Jenkinsfile-based pipeline from a remote code repository. For more information, see [Create a Pipeline Using a Jenkinsfile](../create-a-pipeline-using-jenkinsfile/).
|
||||
|
||||
|
|
@ -23,69 +23,45 @@ This tutorial demonstrates how to trigger a pipeline by using a webhook.
|
|||
|
||||
1. Log in to the KubeSphere web console as `project-regular`. Go to your DevOps project and click a pipeline (for example, `jenkins-in-scm`) to go to its details page.
|
||||
|
||||
2. Click **More** and select **Edit Config** in the drop-down list.
|
||||
2. Click **More** and select **Edit Settings** in the drop-down list.
|
||||
|
||||

|
||||
|
||||
3. In the displayed dialog box, scroll down to **Webhook Push** to obtain the webhook push URL.
|
||||
|
||||

|
||||
3. In the displayed dialog box, scroll down to **Webhook** to obtain the webhook push URL.
|
||||
|
||||
### Set a webhook in the GitHub repository
|
||||
|
||||
1. Log in to GitHub and go to your own repository `devops-java-sample`.
|
||||
1. Log in to GitHub and go to your own repository `devops-maven-sample`.
|
||||
|
||||
2. Click **Settings**, click **Webhooks**, and click **Add webhook**.
|
||||
|
||||

|
||||
|
||||
3. Enter the webhook push URL of the pipeline for **Payload URL** and click **Add webhook**. This tutorial selects **Just the push event** for demonstration purposes. You can make other settings based on your needs. For more information, see [the GitHub document](https://docs.github.com/en/developers/webhooks-and-events/webhooks/creating-webhooks).
|
||||
|
||||

|
||||
|
||||
4. The configured webhook is displayed on the **Webhooks** page.
|
||||
|
||||

|
||||
|
||||
## Trigger the Pipeline by Using the Webhook
|
||||
|
||||
### Submit a pull request to the repository
|
||||
|
||||
1. On the **Code** page of your own repository, click **master** and then select **sonarqube**.
|
||||
|
||||

|
||||
1. On the **Code** page of your own repository, click **master** and then select the **sonarqube** branch.
|
||||
|
||||
2. Go to `/deploy/dev-ol/` and click the file `devops-sample.yaml`.
|
||||
|
||||

|
||||
|
||||
3. Click <img src="/images/docs/devops-user-guide/using-devops/pipeline-webhook/edit-btn.png" width="20px" /> to edit the file. For example, change the value of `spec.replicas` to `3`.
|
||||
|
||||

|
||||
|
||||
4. Click **Commit changes** at the bottom of the page.
|
||||
|
||||
### Check the webhook deliveries
|
||||
|
||||
1. On the **Webhooks** page of your own repository, click the webhook.
|
||||
|
||||

|
||||
|
||||
2. Click **Recent Deliveries** and click a specific delivery record to view its details.
|
||||
|
||||

|
||||
|
||||
### Check the pipeline
|
||||
|
||||
1. Log in to the KubeSphere web console as `project-regular`. Go to your DevOps project and click the pipeline.
|
||||
|
||||
2. On the **Activity** tab, check that a new run is triggered by the pull request submitted to the `sonarqube` branch of the remote repository.
|
||||
|
||||

|
||||
2. On the **Run Records** tab, check that a new run is triggered by the pull request submitted to the `sonarqube` branch of the remote repository.
|
||||
|
||||
3. Go to the **Pods** page of the project `kubesphere-sample-dev` and check the status of the 3 Pods. If the status of the 3 Pods is running, the pipeline is running properly.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -12,29 +12,23 @@ This tutorial demonstrates how to set CI nodes so that KubeSphere schedules task
|
|||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to an account.
|
||||
You need a user granted a role including the permission of **Cluster Management**. For example, you can log in to the console as `admin` directly or create a new role with the permission and assign it to a user.
|
||||
|
||||
## Label a CI Node
|
||||
|
||||
1. Click **Platform** in the top-left corner and select **Cluster Management**.
|
||||
1. Click **Platform** in the upper-left corner and select **Cluster Management**.
|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../../multicluster-management/) with Member clusters imported, you can select a specific cluster to view its nodes. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. Navigate to **Cluster Nodes** under **Node Management**, where you can see existing nodes in the current cluster.
|
||||
3. Navigate to **Cluster Nodes** under **Nodes**, where you can see existing nodes in the current cluster.
|
||||
|
||||

|
||||
4. Select a node from the list to run CI tasks. Click the node name to go to its details page. Click **More** and select **Edit Labels**.
|
||||
|
||||
4. Choose a node from the list to run CI tasks. For example, select `node2` here and click it to go to its detail page. Click **More** and select **Edit Labels**.
|
||||
|
||||

|
||||
|
||||
5. In the dialog that appears, you can see a label with the key `node-role.kubernetes.io/worker`. Enter `ci` for its value and click **Save**.
|
||||
|
||||

|
||||
5. In the displayed dialog box, you can see a label with the key `node-role.kubernetes.io/worker`. Enter `ci` for its value and click **Save**.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can also click **Add Labels** to add new labels based on your needs.
|
||||
You can also click **Add** to add new labels based on your needs.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
|
@ -42,18 +36,12 @@ You need an account granted a role including the permission of **Cluster Managem
|
|||
|
||||
Basically, pipelines and S2I/B2I workflows will be scheduled to this node according to [node affinity](https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-affinity). If you want to make the node a dedicated one for CI tasks, which means other workloads are not allowed to be scheduled to it, you can add a [taint](https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/) to it.
|
||||
|
||||
1. Click **More** and select **Taint Management**.
|
||||
1. Click **More** and select **Edit Taints**.
|
||||
|
||||

|
||||
|
||||
2. Click **Add Taint** and enter a key `node.kubernetes.io/ci` without specifying a value. You can choose `NoSchedule` or `PreferNoSchedule` based on your needs.
|
||||
|
||||

|
||||
2. Click **Add Taint** and enter a key `node.kubernetes.io/ci` without specifying a value. You can choose `Prevent scheduling`, `Prevent scheduling if possible`, or `Prevent scheduling and evict existing Pods` based on your needs.
|
||||
|
||||
3. Click **Save**. KubeSphere will schedule tasks according to the taint you set. You can go back to work on your DevOps pipeline now.
|
||||
|
||||

|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
This tutorial also covers the operation related to node management. For detailed information, see [Node Management](../../../cluster-administration/nodes/).
|
||||
|
|
|
|||
|
|
@ -6,9 +6,9 @@ linkTitle: "Use Pipeline Templates"
|
|||
weight: 11290
|
||||
---
|
||||
|
||||
KubeSphere offers a graphical editing panel where the stages and steps of a Jenkins pipeline can be defined through interactive operations. In KubeSphere v3.1, two built-in pipeline templates are provided as frameworks of continuous integration (CI) and continuous delivery (CD).
|
||||
KubeSphere offers a graphical editing panel where the stages and steps of a Jenkins pipeline can be defined through interactive operations. In KubeSphere 3.2.1, two built-in pipeline templates are provided as frameworks of continuous integration (CI) and continuous delivery (CD).
|
||||
|
||||
When you have a pipeline created in your DevOps project on KubeSphere, you can click the pipeline to go to its detail page, and then click **Edit Pipeline** to select a pipeline template based on your needs. This document illustrates the concept of these two pipeline templates.
|
||||
When you have a pipeline created in your DevOps project on KubeSphere, you can click the pipeline to go to its details page, and then click **Edit Pipeline** to select a pipeline template based on your needs. This document illustrates the concept of these two pipeline templates.
|
||||
|
||||
## CI Pipeline Template
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue