mirror of
https://github.com/kubesphere/website.git
synced 2025-12-30 17:52:56 +00:00
Resolve conflicts
Signed-off-by: kaige <154599029@qq.com>
This commit is contained in:
commit
80d6dbeebb
|
|
@ -388,7 +388,7 @@ section {
|
|||
z-index: 2;
|
||||
width: 20px;
|
||||
height: 20px;
|
||||
background-image: url('/images/docs/copy-code.svg');
|
||||
background-image: url('/images/docs/copy.png');
|
||||
background-repeat: no-repeat;
|
||||
background-size: cover;
|
||||
cursor: pointer;
|
||||
|
|
|
|||
|
|
@ -1 +1,6 @@
|
|||
baseURL = "https://kubesphere.io"
|
||||
|
||||
[params]
|
||||
|
||||
addGoogleAnalytics = true
|
||||
addGoogleTag = true
|
||||
|
|
@ -93,7 +93,7 @@ section4:
|
|||
content: Provide unified authentication with fine-grained roles and three-tier authorization system, and support AD/LDAP authentication
|
||||
|
||||
features:
|
||||
- name: Application Store
|
||||
- name: App Store
|
||||
icon: /images/home/store.svg
|
||||
content: Provide an application store for Helm-based applications, and offer application lifecycle management
|
||||
link: "/docs/pluggable-components/app-store/"
|
||||
|
|
|
|||
|
|
@ -0,0 +1,8 @@
|
|||
---
|
||||
title: KubeSphere Api Documents
|
||||
description: KubeSphere Api Documents
|
||||
keywords: KubeSphere, KubeSphere Documents, Kubernetes
|
||||
|
||||
swaggerUrl: json/crd.json
|
||||
---
|
||||
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
---
|
||||
title: KubeSphere Api Documents
|
||||
description: KubeSphere Api Documents
|
||||
keywords: KubeSphere, KubeSphere Documents, Kubernetes
|
||||
|
||||
swaggerUrl: json/kubesphere.json
|
||||
---
|
||||
|
|
@ -8,13 +8,15 @@ author: 'Willqy, Feynman, Sherlock'
|
|||
snapshot: 'https://ap3.qingstor.com/kubesphere-website/docs/tidb-architecture.png'
|
||||
---
|
||||
|
||||
In a world where Kubernetes has become the de facto standard to build application services that span multiple containers, running a cloud-native distributed database represents an important part of the experience of using Kubernetes. In this connection, [TiDB](https://github.com/pingcap/tidb), as an open-source NewSQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads, has come to my awareness. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability. It strives to provide users with a one-stop database solution that covers OLTP (Online Transactional Processing), OLAP (Online Analytical Processing), and HTAP services. TiDB is suitable for various use cases that require high availability and strong consistency with large-scale data.
|
||||

|
||||
|
||||
In a world where Kubernetes has become the de facto standard to build application services that span multiple containers, running a cloud-native distributed database represents an important part of the experience of using Kubernetes. In this connection, [TiDB](https://github.com/pingcap/tidb), an open-source NewSQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads, has come to my awareness. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability. It strives to provide users with a one-stop database solution that covers OLTP (Online Transactional Processing), OLAP (Online Analytical Processing), and HTAP services. TiDB is suitable for various use cases that require high availability and strong consistency with large-scale data.
|
||||
|
||||

|
||||
|
||||
Among others, [TiDB Operator](https://github.com/pingcap/tidb-operator) is an automatic operation system for TiDB clusters in Kubernetes. It provides a full management life-cycle for TiDB including deployment, upgrades, scaling, backup, fail-over, and configuration changes. With TiDB Operator, TiDB can run seamlessly in Kubernetes clusters deployed on public or private cloud.
|
||||
|
||||
In addition to TiDB, I am also a KubeSphere user. [KubeSphere](https://kubesphere.io/) is a distributed operating system managing cloud-native applications with [Kubernetes](https://kubernetes.io/) as its kernel, providing a plug-and-play architecture for the seamless integration of third-party applications to boost its ecosystem. [KubeSphere can be run anywhere](https://kubesphere.io/docs/introduction/what-is-kubesphere/#run-kubesphere-everywhere) as it is highly pluggable without any hacking into Kubernetes.
|
||||
In addition to TiDB, I am also a KubeSphere user. [KubeSphere](https://kubesphere.io/) is an open-source distributed operating system managing cloud-native applications with [Kubernetes](https://kubernetes.io/) as its kernel, providing a plug-and-play architecture for the seamless integration of third-party applications to boost its ecosystem. [KubeSphere can be run anywhere](https://kubesphere.io/docs/introduction/what-is-kubesphere/#run-kubesphere-everywhere) as it is highly pluggable without any hacking into Kubernetes.
|
||||
|
||||

|
||||
|
||||
|
|
@ -28,15 +30,19 @@ Therefore, I select QingCloud Kubernetes Engine (QKE) to prepare the environment
|
|||
|
||||
1. Log in the [web console of QingCloud](https://console.qingcloud.com/). Simply select KubeSphere (QKE) from the menu and create a Kubernetes cluster with KubeSphere installed. The platform allows you to install different components of KubeSphere. Here, we need to enable [OpenPitrix](https://github.com/openpitrix/openpitrix), which powers the app management feature in KubeSphere.
|
||||
|
||||

|
||||
{{< notice note >}}
|
||||
KubeSphere can be installed on any infrastructure. I just use QingCloud Platform as an example. See [KubeSphere Documentation](https://kubesphere.io/docs/) for more details.
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
2. The cluster will be up and running in around 10 minutes. In this example, I select 3 working nodes to make sure I have enough resources for the deployment later. You can also customize configurations based on your needs. When the cluster is ready, log in the web console of KubeSphere with the default account and password (`admin/P@88w0rd`). Here is the cluster **Overview** page:
|
||||
|
||||

|
||||
|
||||
3. Use the built-in tool Kubectl from the Toolkit in the bottom right corner to execute the following command to install TiDB Operator CRD:
|
||||
3. Use the built-in **Web Kubectl** from the Toolkit in the bottom right corner to execute the following command to install TiDB Operator CRD:
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.1.6/manifests/crd.yaml
|
||||
|
|
@ -56,7 +62,7 @@ kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.1.6/
|
|||
|
||||

|
||||
|
||||
## Deploying tidb-operator
|
||||
## Deploying TiDB-operator
|
||||
|
||||
1. Like I mentioned above, we need to create a project (i.e. namespace) first to run the TiBD cluster.
|
||||
|
||||
|
|
@ -94,7 +100,7 @@ kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.1.6/
|
|||
|
||||

|
||||
|
||||
## Deploying tidb-cluster
|
||||
## Deploying TiDB-cluster
|
||||
|
||||
The process of deploying tidb-cluster is basically the same as that of tidb-operator shown above.
|
||||
|
||||
|
|
@ -140,7 +146,7 @@ Now that we have our apps ready, we may need to focus more on observability. Kub
|
|||
|
||||

|
||||
|
||||
2. tidb, tikv and pd are all stateful applications which can be found in **StatefulSets**. Note that tikv and tidb will be created automatically and it may take a while before displaying in the list.
|
||||
2. TiDB, TiKV and pd are all stateful applications which can be found in **StatefulSets**. Note that TiKV and TiDB will be created automatically and it may take a while before displaying in the list.
|
||||
|
||||

|
||||
|
||||
|
|
@ -152,7 +158,7 @@ Now that we have our apps ready, we may need to focus more on observability. Kub
|
|||
|
||||

|
||||
|
||||
5. Relevant Pods are also listed. As you can see, tidb-cluster contains three pd Pods, two tidb Pods and 3 tikv Pods.
|
||||
5. Relevant Pods are also listed. As you can see, tidb-cluster contains three pd Pods, two TiDB Pods and 3 TiKV Pods.
|
||||
|
||||

|
||||
|
||||
|
|
@ -160,7 +166,7 @@ Now that we have our apps ready, we may need to focus more on observability. Kub
|
|||
|
||||

|
||||
|
||||
7. Volume usage is also monitored. Here is an example of tikv:
|
||||
7. Volume usage is also monitored. Here is an example of TiKV:
|
||||
|
||||

|
||||
|
||||
|
|
@ -208,7 +214,7 @@ mysql> show databases;
|
|||
mysql>
|
||||
```
|
||||
|
||||
4. Besides, tidb integrates Prometheus and Grafana to monitor performance of the database cluster. As we can see above, Grafana is being exposed through `NodePort`. After you configure necessary port forwarding rules and open its port in security groups on QingCloud Platform, you can access the Grafana UI to view metrics.
|
||||
4. Besides, TiDB integrates Prometheus and Grafana to monitor performance of the database cluster. As we can see above, Grafana is being exposed through `NodePort`. After you configure necessary port forwarding rules and open its port in security groups on QingCloud Platform, you can access the Grafana UI to view metrics.
|
||||
|
||||

|
||||
|
||||
|
|
@ -218,10 +224,12 @@ I hope you guys all have successfully deploy TiDB. Both TiDB and KubeSphere are
|
|||
|
||||
## References
|
||||
|
||||
https://docs.pingcap.com/tidb-in-kubernetes/stable/get-started
|
||||
**KubeSphere GitHub**: https://github.com/kubesphere/kubesphere
|
||||
|
||||
https://docs.pingcap.com/tidb-in-kubernetes/stable/tidb-operator-overview
|
||||
**TiDB GitHub**: https://github.com/pingcap/TiDB
|
||||
|
||||
https://kubesphere.io/docs/introduction/what-is-kubesphere/
|
||||
**TiDB Operator Documentation**: https://docs.pingcap.com/tidb-in-kubernetes/stable/tidb-operator-overview
|
||||
|
||||
https://kubesphere.io/docs/
|
||||
**KubeSphere Introduction**: https://kubesphere.io/docs/introduction/what-is-kubesphere/
|
||||
|
||||
**KubeSphere Documentation**: https://kubesphere.io/docs/
|
||||
|
|
@ -0,0 +1,139 @@
|
|||
---
|
||||
title: 'Kubernetes Multi-cluster Deployment: Federation and KubeSphere'
|
||||
keywords: Kubernetes, KubeSphere, Multi-cluster, Container
|
||||
description: KubeSphere v3.0 supports the management of multiple clusters, isolated management of resources, and federated deployments.
|
||||
tag: 'KubeSphere, Multi-cluster'
|
||||
createTime: '2020-07-20'
|
||||
author: 'Jeff, Feynman, Sherlock'
|
||||
snapshot: 'https://ap3.qingstor.com/kubesphere-website/docs/kubesphere-architecture.png'
|
||||
---
|
||||
|
||||
## Scenarios for Multi-cluster Deployment
|
||||
|
||||
As the container technology and Kubernetes see a surge in popularity among their users, it is not uncommon for enterprises to run multiple clusters for their business. In general, here are the main scenarios where multiple clusters can be adopted.
|
||||
|
||||
### High Availability
|
||||
|
||||
You can deploy workloads on multiple clusters by using a global VIP or DNS to send requests to corresponding backend clusters. When a cluster malfunctions or fails to handle requests, the VIP or DNS records can be transferred to a health cluster.
|
||||
|
||||

|
||||
|
||||
### Low Latency
|
||||
|
||||
When clusters are deployed in various regions, user requests can be forwarded to the nearest cluster, greatly reducing network latency. For example, we have three Kubernetes clusters deployed in New York, Houston and Los Angeles respectively. For users in California, their requests can be forwarded to Los Angeles. This will reduce the network latency due to geographical distance, providing the most consistent user experience possible for users in different areas.
|
||||
|
||||
### Failure Isolation
|
||||
|
||||
Generally, it is much easier for multiple small clusters to isolate failures than a large cluster. In case of outages, network failures, insufficient resources or other possible resulting issues, the failure can be isolated within a certain cluster without spreading to others.
|
||||
|
||||
### Business Isolation
|
||||
|
||||
Although Kubernetes provides namespaces as a solution to app isolation, this method only represents the isolation in logic. This is because different namespaces are connected through the network, which means the issue of resource preemption still exists. To achieve further isolation, you need to create additional network isolation policies or set resource quotas. Using multiple clusters can achieve complete physical isolation that is more secure and reliable than the isolation through namespaces. For example, this is extremely effective when different departments within an enterprise use multiple clusters for the deployment of development, testing or production environments.
|
||||
|
||||

|
||||
|
||||
### Avoid Vendor Lock-in
|
||||
|
||||
Kubernetes has become the de facto standard in container orchestration. Against this backdrop, many enterprises avoid putting all eggs in one basket as they deploy clusters by using services of different cloud providers. That means they can transfer and scale their business anytime between clusters. However, it is not that easy for them to transfer their business in terms of costs, as different cloud providers feature varied Kubernetes services, including storage and network interface.
|
||||
|
||||
## Multi-cluster Deployment
|
||||
|
||||
The application of multi-cluster deployment offers solutions to a variety of problems as we can see from the scenarios above. Nevertheless, it brings more complexity for operation and maintenance. For a single cluster, app deployment and upgrade are quite straightforward as you can directly update yaml of the cluster. For multiple clusters, you can update them one by one, but how can you guarantee the application load status is the same across different clusters? How to implement service discovery among different clusters? How to achieve load balancing across clusters? The answer given by the community is Federation.
|
||||
|
||||
### Federation v1
|
||||
|
||||

|
||||
|
||||
There are two versions of Federation with the original v1 already deprecated. In v1, the general architecture is very similar to that of Kubernetes. As shown above, Federation API Server is used for the management of different clusters. It receives the request to create the deployment of multiple clusters as Federation Controller Manager deploys workloads on each cluster.
|
||||
|
||||

|
||||
|
||||
In terms of API, federated resources are scheduled through annotations, ensuring great compatibility with the original Kubernetes API. As such, the original code can be reused and existing deployment files of users can be easily transferred without any major change. However, this also prevents users from taking further advantage of Federation for API evolution. At the same time, a corresponding controller is needed for each federated resource so that they can be scheduled to different clusters. Originally, Federation only supported a limited number of resource type.
|
||||
|
||||
### Federation v2
|
||||
|
||||

|
||||
|
||||
The community developed Federation v2 (KubeFed) on the basis of v1. KubeFed has defined its own API standards through CRDs while deprecating the annotation method used before. The architecture has changed significantly as well, discarding Federated API Server and etcd that need to be deployed independently. The control plane of KubeFed adopts the popular implementation of CRD + Controller, which can be directly installed on existing Kubernetes clusters without any additional deployment.
|
||||
|
||||
KubeFed mainly defines four resource types:
|
||||
|
||||
- **Cluster Configuration** defines the register information needed for the control plane to add member clusters, including cluster name, APIServer address and the credential to create deployments.
|
||||
|
||||
- **Type Configuration** defines the resource type that KubeFed should handle. Each Type Configuration is a CRD object that contains three configuration items:
|
||||
|
||||
- **Template.** Templates define the representation of a common resource to be handled. If the object does not have a corresponding definition on the cluster where it will be deployed, the deployment will fail. In the following example of FederatedDeployment, the template contains all the information needed to create the deployment.
|
||||
- **Placement**. Placements define the name of the cluster that a resource object will appear in, with two methods available (`clusters` and `clusterSelector`).
|
||||
- **Override**. Overrides define per-cluster, field-level variation that apply to the template, allowing you to customize configurations. In the example below, the number of replicas defined in `template` is 1, while `overrides` shows the replica number of cluster gondor will be 4 when it is deployed instead of 1 in `template`. A subset of the syntax of [Jsonpatch](http://jsonpatch.com/) is achieved in `overrides`, which means, theoretically, all the content in `template` can be overridden.
|
||||
|
||||

|
||||
|
||||
- **Schedule** defines how apps are deployed across clusters, mainly related to ReplicaSets and Deployments. The maximum and minimum number of replicas of the load on a cluster can be defined through Schedule, which is similar to the annotation method in v1.
|
||||
- **MultiClusterDNS** makes it possible for service discovery across clusters. Service discovery across multiple clusters is much more complicated than in a single cluster. ServiceDNSRecord, IngressDNSRecord and DNSEndpoint objects are used in KubeFed to implement service discovery across multiple clusters (DNS needed as well).
|
||||
|
||||
In general, KubeFed has provided solutions to many problems in v1. With CRDs, federated resources can be scaled to a large extent. Basically, all Kubernetes resources can be deployed across multiple clusters, including the CRD resources defined by users themselves.
|
||||
|
||||
However, KubeFed also has some issues to be resolved:
|
||||
|
||||
- **Single point of failure**. The control plane of KubeFed is achieved through CRD + Controller. High availability can be implemented for the controller itself, but the whole control plane will malfunction if Kubernetes it runs on fails. This was also [discussed in the community](https://github.com/kubernetes-sigs/kubefed/issues/636) before. Currently, KubeFed uses the push/reconcile method. When federated resources are created, the controller of the control plane will send the resource object to clusters accordingly. After that, the control plane is not responsible for how the member cluster handles resources. Therefore, existing application workloads will not be affected when KubeFed control plane fails.
|
||||
- **Maturity**. The KubeFed community is not as active as the Kubernetes community. Its iteration cycle is too slow and many features are still in the beta stage.
|
||||
- **Abstraction**. KubeFed defines resources to be managed through Type Configurations. Different Type Configurations only vary in their templates. The advantage is that the logic can be unified so that they can be quickly achieved. In KubeFed, the corresponding Controllers of Type Configuration resources are all created through [templates](https://github.com/kubernetes-sigs/kubefed/blob/master/pkg/controller/federatedtypeconfig/controller.go). That said, the shortcoming is quite obvious as customized features are not supported for special Types. For instance, for a FederatedDeployment object, KubeFed only needs to create a deployment object accordingly based on template and override, which will be deployed on the cluster specified in placement. As for whether the corresponding Pod is created based on the deployment and how the Pod runs, you can only check the information in the related cluster. The community has realized this issue and is working on it. A [proposal](https://github.com/kubernetes-sigs/kubefed/pull/1237) has already been raised.
|
||||
|
||||
## Multi-cluster Feature in KubeSphere
|
||||
|
||||
Resource federation is what the community has proposed to solve the issue of deployments across multiple clusters. For many enterprise users, the deployment of multiple clusters is not necessary. What is more important is that they need to be able to manage the resources across multiple clusters at the same time and in the same place.
|
||||
|
||||
[KubeSphere](https://github.com/kubesphere) supports the management of multiple clusters, isolated management of resources, and federated deployments. In addition, it also features multi-dimensional queries (monitoring, logging, events and auditing) of resources such as clusters and apps, as well as alerts and notifications through various channels. Apps can be deployed on multiple clusters with CI/CD pipelines.
|
||||
|
||||

|
||||
|
||||
KubeSphere 3.0 supports unified management of user access for the multi-cluster feature based on KubeFed, RBAC and Open Policy Agent. With the multi-tenant architecture, it is very convenient for business departments, development teams and Ops teams to manage resources isolatedly in a unified console according to their needs.
|
||||
|
||||

|
||||
|
||||
### Architecture
|
||||
|
||||

|
||||
|
||||
The overall multi-cluster architecture of [KubeSphere](https://kubesphere.io/) is shown above. The cluster where the control plane is located is called Host cluster. The cluster managed by the Host cluster is called Member cluster, which is essentially a Kubernetes cluster with KubeSphere installed. The Host cluster needs to be able to access the kube-apiserver of Member clusters. Besides, there is no requirement for the network connectivity between Member clusters. The Host cluster is independent of the member clusters managed by it, which do not know the existence of the Host cluster. The advantage of the logic is that when the Host cluster malfunctions, Member clusters will not be affected and deployed workloads can continue to run as well.
|
||||
|
||||
In addition, the Host cluster also serves as an entry for API requests. It will forward all resource requests for member clusters to them. In this way, not only can requests be aggregated, but also authentication and authorization can be implemented in a unified fashion.
|
||||
|
||||
### Authorization and Authentication
|
||||
|
||||
It can be seen from the architecture that the Host cluster is responsible for the synchronization of identity and access information of clusters, which is achieved by federated resources of KubeFed. When FederatedUser, FederatedRole, or FederatedRoleBinding is created on the Host cluster, KubeFed will push User, Role, or Rolebinding to Member clusters. Any access change will only be applied to the Host cluster, which will then be synchronized to Member clusters. This is to ensure the integrity of each Member cluster. In this regard, the identity and access data stored in Member clusters enable them to implement authentication and authorization independently without any reliance on the Host cluster. In the multi-cluster architecture of KubeSphere, the Host cluster acts as a resource coordinator instead of a dictator, since it delegates power to Member clusters as much as possible.
|
||||
|
||||
### Cluster Connectivity
|
||||
|
||||
The multi-cluster feature of KubeSphere only entails the access of the Host cluster to the Kubernetes APIServer of Member clusters. There is no requirement for network connectivity at the cluster level. KubeSphere provides two methods for the connection of Host and Member clusters:
|
||||
|
||||
- **Direct connection**. If the kube-apiserver address of Member clusters is accessible on any node of the Host cluster, you can adopt this method. Member clusters only need to provide the cluster kubeconfig. This method applies to most public cloud Kubernetes services or the scenario where the Host cluster and Member clusters are in the same network.
|
||||
|
||||
- **Agent connection**. In case Member clusters are in a private network with the kube-apiserver address unable to be exposed, KubeSphere provides [Tower](https://github.com/kubesphere/tower) for agent connection. Specifically, the Host cluster will run a proxy service. When a new cluster joins, the Host cluster will generate all credential information. Besides, the agent running on Member clusters will connect to the proxy service running on the Host cluster. A reverse proxy will be created after the handshake succeeds. As the kube-apiserver address of Member clusters will change in agent connection, the Host cluster needs to create a new kubeconfig for Member clusters. This is very convenient as the underlying details can be hidden. In either direct connection or agent connection, the control plane is provided with a kubeconfig that can be used directly.
|
||||
|
||||

|
||||
|
||||
### API Forwarding
|
||||
|
||||
In the multi-cluster architecture of KubeSphere, the Host cluster serves as a cluster entry. All API requests are directly sent to the Host cluster first, which will decide where these requests go next. To provide the best compatibility possible with the original API in the multi-cluster environment, the API request whose path begins with `/apis/clusters/{cluster}` will be forwarded to the cluster `{cluster}`, with `/clusters/{cluster}` removed. The advantage is that there is no difference between the request the cluster receives this way with other requests, with no additional configuration or operation needed.
|
||||
|
||||

|
||||
|
||||
For example:
|
||||
|
||||

|
||||
|
||||
The request above will be forwarded to a cluster named rohan and be handled as:
|
||||
|
||||

|
||||
|
||||
## Summary
|
||||
|
||||
The topic of multi-cluster deployment is far more complicated than we think. The fact that the Federation solution provided by the community has not been officially released after two versions is a typical example. As we often put it, there is no Silver Bullet in software engineering. It is impossible for multi-cluster tools such as KubeFed and KubeSphere to solve all the issues. We need to find the solution that best suits us based on the specific business scenario. It is believed that these tools will become more mature over time, which can be applied in more scenarios.
|
||||
|
||||
## References
|
||||
|
||||
1. KubeFed: https://github.com/kubernetes-sigs/kubefed
|
||||
2. KubeSphere Website: https://kubesphere.io/
|
||||
3. Kubernetes Federation Evolution: https://kubernetes.io/blog/2018/12/12/kubernetes-federation-evolution/
|
||||
4. KubeSphere GitHub: https://github.com/kubesphere
|
||||
|
|
@ -15,9 +15,9 @@ section2:
|
|||
icon2: 'images/contribution/37.png'
|
||||
children:
|
||||
- content: 'Download KubeSphere'
|
||||
link: 'https://kubesphere.io/docs/installation/intro/'
|
||||
link: '../../../docs/quick-start/all-in-one-on-linux/'
|
||||
- content: 'Quickstart'
|
||||
link: 'https://kubesphere.io/docs/quick-start/admin-quick-start/'
|
||||
link: '../../../docs/quick-start/create-workspace-and-project/'
|
||||
- content: 'Tutorial Videos'
|
||||
link: '../videos'
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ section3:
|
|||
- name: 'Apps'
|
||||
icon: '/images/contribution/apps.svg'
|
||||
iconActive: '/images/contribution/apps-active.svg'
|
||||
content: 'App charts for the built-in Application Store'
|
||||
content: 'App charts for the built-in App Store'
|
||||
link: 'https://github.com/kubesphere/community/tree/master/sig-apps'
|
||||
linkContent: 'Join SIG - Apps →'
|
||||
children:
|
||||
|
|
@ -92,7 +92,7 @@ section3:
|
|||
- icon: '/images/contribution/calicq2.jpg'
|
||||
- icon: '/images/contribution/calicq3.jpg'
|
||||
|
||||
- name: 'Application Store'
|
||||
- name: 'App Store'
|
||||
icon: '/images/contribution/app-store.svg'
|
||||
iconActive: '/images/contribution/app-store-active.svg'
|
||||
content: 'App Store, App template management'
|
||||
|
|
|
|||
|
|
@ -1,9 +1,9 @@
|
|||
---
|
||||
title: "Accecc Control and Account Management"
|
||||
description: "Accecc Control and Account Management"
|
||||
title: "Access Control and Account Management"
|
||||
description: "Access Control and Account Management"
|
||||
layout: "single"
|
||||
|
||||
linkTitle: "Accecc Control and Account Management"
|
||||
linkTitle: "Access Control and Account Management"
|
||||
weight: 4500
|
||||
|
||||
icon: "/images/docs/docs.svg"
|
||||
|
|
|
|||
|
|
@ -34,10 +34,6 @@ The following metrics have been deprecated and removed.
|
|||
|cluster_workspace_count|
|
||||
|cluster_account_count|
|
||||
|cluster_devops_project_count|
|
||||
|workspace_namespace_count|
|
||||
|workspace_devops_project_count|
|
||||
|workspace_member_count|
|
||||
|workspace_role_count|
|
||||
|coredns_up_sum|
|
||||
|coredns_cache_hits|
|
||||
|coredns_cache_misses|
|
||||
|
|
@ -53,6 +49,15 @@ The following metrics have been deprecated and removed.
|
|||
|prometheus_up_sum|
|
||||
|prometheus_tsdb_head_samples_appended_rate|
|
||||
|
||||
New metrics are introduced in KubeSphere 3.0.0.
|
||||
|
||||
|New Metrics|
|
||||
|---|
|
||||
|kubesphere_workspace_count|
|
||||
|kubesphere_user_count|
|
||||
|kubesphere_cluser_count|
|
||||
|kubesphere_app_template_count|
|
||||
|
||||
## Response Fields
|
||||
|
||||
In KubeSphere 3.0.0, the response fields `metrics_level`, `status` and `errorType` are removed.
|
||||
|
|
|
|||
|
|
@ -1,23 +1,14 @@
|
|||
---
|
||||
title: "Application Store"
|
||||
title: "App Store"
|
||||
description: "Getting started with KubeSphere DevOps project"
|
||||
layout: "single"
|
||||
|
||||
linkTitle: "Application Store"
|
||||
|
||||
linkTitle: "App Store"
|
||||
weight: 4600
|
||||
|
||||
icon: "/images/docs/docs.svg"
|
||||
|
||||
---
|
||||
|
||||
## Installing KubeSphere and Kubernetes on Linux
|
||||
|
||||
In this chapter, we will demonstrate how to use KubeKey to provision a new Kubernetes and KubeSphere cluster based on different infrastructures. Kubekey can help you to quickly build a production-ready cluster architecture on a set of machines from zero to one. It also helps you to easily scale the cluster and install pluggable components on existing architecture.
|
||||
|
||||
## Most Popular Pages
|
||||
|
||||
Below you will find some of the most common and helpful pages from this chapter. We highly recommend you to review them at first.
|
||||
|
||||
{{< popularPage icon="/images/docs/bitmap.jpg" title="Install KubeSphere on AWS EC2" description="Provisioning a new Kubernetes and KubeSphere cluster based on AWS" link="" >}}
|
||||
|
||||
{{< popularPage icon="/images/docs/bitmap.jpg" title="Install KubeSphere on AWS EC2" description="Provisioning a new Kubernetes and KubeSphere cluster based on AWS" link="" >}}
|
||||
TBD
|
||||
|
|
|
|||
|
|
@ -0,0 +1,162 @@
|
|||
---
|
||||
title: "App Lifecycle Management"
|
||||
keywords: 'kubernetes, kubesphere, app-store'
|
||||
description: 'App Lifecycle Management'
|
||||
|
||||
|
||||
weight: 2240
|
||||
---
|
||||
|
||||
KubeSphere integrates open-source project [OpenPitrix](https://github.com/openpitrix/openpitrix) to set up the App Store which provide the full lifecycle of application management. App Store supports two kinds of application deployment as follows:
|
||||
|
||||
> - **Application template** provides a way for developers and ISVs to share applications with users in a workspace. It also supports importing third-party application repositories within workspace.
|
||||
> - **Composing application** means users can quickly compose multiple microservices into a complete application through the one-stop console.
|
||||
|
||||

|
||||
|
||||
## Objective
|
||||
|
||||
In this tutorial, we will walk you through how to use [EMQ X](https://www.emqx.io/) as a demo application to demonstrate the **global application store** and **application lifecycle management** including upload / submit / review / test / release / upgrade / delete application templates.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to install [App Store (OpenPitrix)](../../pluggable-components/app-store).
|
||||
- You need to create a workspace and a project, see [Create Workspace, Project, Account and Role](../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create Customized Role and Account
|
||||
|
||||
In this step, we will create two accounts, i.e., `isv` for ISVs and `reviewer` for app technical reviewers.
|
||||
|
||||
1.1. First of all, we need to create a role for app reviewers. Log in KubeSphere console with the account `admin`, go to **Platform → Access Control → Account Roles**, then click **Create** and name it `app-review`, choose **App Templates Management** and **App Templates View** in the authorization settings list, then click **Create**.
|
||||
|
||||

|
||||
|
||||
1.2. Create an account `reviewer`, and grant the role of **app-review** to it.
|
||||
|
||||
1.3. Similarly, create an account `isv`, and grant the role of **platform-regular** to it.
|
||||
|
||||

|
||||
|
||||
1.4. Invite the accounts that we created above to an existing workspace such as `demo-workspace`, and grant them the role of `workspace-admin`.
|
||||
|
||||
### Step 2: Upload and Submit Application
|
||||
|
||||
2.1. Log in KubeSphere with `isv`, enter the workspace. We are going to upload the EMQ X app to this workspace. First please download [EMQ X chart v1.0.0](https://github.com/kubesphere/tutorial/raw/master/tutorial%205%20-%20app-store/emqx-v1.0.0-rc.1.tgz) and click **Upload Template** by choosing **App Templates**.
|
||||
|
||||
> Note we are going to upload a newer version of EMQ X to demo the upgrade feature later on.
|
||||
|
||||

|
||||
|
||||
2.2. Click **Upload**, then click **Upload Helm Chart Package** to upload the chart.
|
||||
|
||||

|
||||
|
||||
2.3. Click **OK**. Now download [EMQ Icon](https://github.com/kubesphere/tutorial/raw/master/tutorial%205%20-%20app-store/emqx-logo.png) and click **Upload icon** to upload App logo. Click **OK** when you are done.
|
||||
|
||||

|
||||
|
||||
2.4. At this point, you will be able to see the status displays `draft`, which means this app is under developing. The uploaded app is visible for all members in the same workspace.
|
||||
|
||||

|
||||
|
||||
2.5. Enter app template detailed page by clicking on EMQ X from the list. You can edit the basic information of this app by clicking **Edit Info**.
|
||||
|
||||

|
||||
|
||||
2.6. You can customize the app's basic information by filling in the table as the following screenshot.
|
||||
|
||||

|
||||
|
||||
2.7. Save your changes, then you can test this application by deploying to Kubernetes. Click on the **Test Deploy** button.
|
||||
|
||||

|
||||
|
||||
2.8. Select cluster and project that you want to deploy into, check app config then click **Deploy**.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
2.9. Wait for a few minutes, then switch to the tab **Deployed Instances**. You will find EMQ X App has been deployed successfully.
|
||||
|
||||

|
||||
|
||||
2.10. At this point, you can click `Submit Review` to submit this application to `reviewer`.
|
||||
|
||||

|
||||
|
||||
2.11. As shown in the following graph, the app status has been changed to `Submitted`. Now app reviewer can review it.
|
||||
|
||||

|
||||
|
||||
### Step 3: Review Application
|
||||
|
||||
3.1. Log out, then use `reviewer` account to log in KubeSphere. Navigate to **Platform → App Store Management → App Review**.
|
||||
|
||||

|
||||
|
||||
3.2. Click **Review** by clicking the vertical three dots at the end of app item in the list, then you start to review the app's basic information, introduction, chart file and updated logs from the pop-up windows.
|
||||
|
||||

|
||||
|
||||
3.3. It is the reviewer's responsibility to judge if the app satisfies the criteria of the Global App Store or not, if yes, then click `Pass`; otherwise, `Reject` it.
|
||||
|
||||
### Step 4: Release Application to Store
|
||||
|
||||
4.1. Log out and switch to use `isv` to log in KubeSphere. Now `isv` can release the EMQ X application to the global application store which means all users in this platform can find and deploy this application.
|
||||
|
||||
4.2. Enter the demo workspace and navigate to the EMQ X app from the template list. Enter the detailed page and expand the version list, then click **Release to Store**, choose **OK** in the pop-up windows.
|
||||
|
||||

|
||||
|
||||
4.3. At this point, EMQ X has been released to application store.
|
||||
|
||||

|
||||
|
||||
4.4. Go to **App Store** in the top menu, you will see the app in the list.
|
||||
|
||||

|
||||
|
||||
4.5. At this point, we can use any role of users to access EMQ X application. Click into the application detailed page to go through its basic information. You can click **Deploy** button to deploy the application to Kubernetes.
|
||||
|
||||

|
||||
|
||||
### Step 5: Create Application Category
|
||||
|
||||
Depending on the business needs, `Reviewer` can create multiple categories for different types of applications. It is similar as tag and can be used in application store to filter applications, e.g. Big data, Middleware, IoT, etc.
|
||||
|
||||
As for EMQ X application, we can create a category and name it `IOT`. First switch back to the user `Reviewer`, go to **Platform → App Store Management → App Categories**
|
||||
|
||||

|
||||
|
||||
Then click **Uncategorized** and find EMQ X, change its category to `IOT` and save it.
|
||||
|
||||
> Note usually reviewer should create necessary categories in advance according to the requirements of the store. Then ISVs categorize their applications as appropriate before submitting for review.
|
||||
|
||||

|
||||
|
||||
### Step 6: Add New Version
|
||||
|
||||
6.1. KubeSphere supports adding new versions of existing applications for users to quickly upgrade. Let's continue to use `isv` account and enter the EMQ X template page in the workspace.
|
||||
|
||||

|
||||
|
||||
6.2. Download [EMQ X v4.0.2](https://github.com/kubesphere/tutorial/raw/master/tutorial%205%20-%20app-store/emqx-v4.0.2.tgz), then click on the **New Version** on the right, upload the package that you just downloaded.
|
||||
|
||||

|
||||
|
||||
6.3. Click **OK** when you upload successfully.
|
||||
|
||||

|
||||
|
||||
6.4. At this point, you can test the new version and submit it to `Reviewer`. This process is similar to the one for the first version.
|
||||
|
||||

|
||||
|
||||
6.5. After you submit the new version, the rest of process regarding review and release are also similar to the first version that we demonstrated above.
|
||||
|
||||
### Step 7: Upgrade
|
||||
|
||||
After the new version has been released to application store, all users can upgrade from this application.
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
---
|
||||
title: "Memcached App"
|
||||
keywords: 'Kubernetes, KubeSphere, Memcached, app-store'
|
||||
description: 'How to use built-in Memcached Object Storage'
|
||||
|
||||
|
||||
weight: 2242
|
||||
---
|
||||
[Memcached](https://memcached.org/) is designed for large data caches. Its API is available for most popular languages. This guide will show you one-click deployment for Memcached in Kubenetes .
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere App Store](../../pluggable-components/app-store)
|
||||
- You have completed the tutorial in [Create Workspace, Project, Account and Role](../../quick-start/create-workspace-and-project/). Now switch to use `project-regular` account to log in and enter into `demo-peoject`.
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Common steps
|
||||
|
||||
1. Choose Memcached template `From App Store`.
|
||||
|
||||

|
||||
|
||||
2. Check app info and click `Deploy` button.
|
||||
|
||||

|
||||
|
||||
3. Select app version and deployment location, then go to **Next → Deploy**
|
||||
|
||||

|
||||
|
||||
4. Wait for a few minutes, then you will see the application memcached showing active on the application list.
|
||||
|
||||

|
||||
|
||||
5. Click into Memcached application, and then enter into its workload page and get the pod IP.
|
||||
|
||||

|
||||
|
||||
6. Because Memcached service type is headless, we should connect it inside cluster with pod IP got previously and default port `11211`.
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,50 @@
|
|||
---
|
||||
title: "PostgreSQL App"
|
||||
keywords: 'Kubernetes, KubeSphere, PostgreSQL, app-store'
|
||||
description: 'How to use built-in PostgreSQL'
|
||||
|
||||
|
||||
weight: 2242
|
||||
---
|
||||
[PostgreSQL](https://www.postgresql.org/) is a powerful, open source object-relational database system which is famous for reliability, feature robustness, and performance. This guide will show you one-click deployment for PostgreSQL in Kubenetes .
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere App Store](../../pluggable-components/app-store)
|
||||
- You have completed the tutorial in [Create Workspace, Project, Account and Role](../../quick-start/create-workspace-and-project/). Now switch to use `project-regular` account to log in and enter into `demo-peoject`.
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Common steps
|
||||
|
||||
1. Choose PostgreSQL template `From App Store`.
|
||||
|
||||

|
||||
|
||||
2. Check app info and click `Deploy` button.
|
||||
|
||||

|
||||
|
||||
3. Select app version and deployment location, then go to **Next → Deploy**
|
||||
|
||||

|
||||
|
||||
4. Wait for a few minutes, then you will see the application postgresql showing active on the application list.
|
||||
|
||||

|
||||
|
||||
5. Click into PostgreSQL application, and then enter into its service page.
|
||||
|
||||

|
||||
|
||||
6. In this page, make sure its deployment and Pod are running, then click **More → Edit Internet Access**, and select **NodePort** in the dropdown list, click **OK** to save it.
|
||||
|
||||

|
||||
|
||||
7.Go to **App Template → Configuration Files** and get rootUsername and rootPassword from `values.yaml`.
|
||||
|
||||

|
||||
|
||||
8. In this step, we can connect PostgreSQL db outside cluster using host: ${Node IP}, port: ${NODEPORT}, with the rootUsername and rootPassword we got previously.
|
||||
|
||||

|
||||
|
|
@ -6,59 +6,78 @@ description: 'How to deploy RabbitMQ on KubeSphere through App Store'
|
|||
link title: "Deploy RabbitMQ"
|
||||
weight: 251
|
||||
---
|
||||
[RabbitMQ](https://www.rabbitmq.com/) is the most widely deployed open source message broker. and it's lightweight and easy to deploy on premises and in the cloud. It supports multiple messaging protocols. RabbitMQ can be deployed in distributed and federated configurations to meet high-scale, high-availability requirements.
|
||||
This tutorial walks you through an example of how to deploy RabbitMQ on KubeSphere.
|
||||
[RabbitMQ](https://www.rabbitmq.com/) is the most widely deployed open-source message broker. It is lightweight and easy to deploy on premises and in the cloud. It supports multiple messaging protocols. RabbitMQ can be deployed in distributed and federated configurations to meet high-scale, high-availability requirements.
|
||||
|
||||
This tutorial walks you through an example of how to deploy RabbitMQ from the App Store of KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/). RabbitMQ will be deployed from the App Store.
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-operator` and work in the project `test-project` in the workspace `test-workspace`.
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy RabbitMQ from App Store
|
||||
|
||||
Please make sure you are landing on the **Overview** page of the project `test-project`.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top left corner.
|
||||
|
||||
1. Go to **App Store**.
|
||||

|
||||
|
||||

|
||||
2. Find RabbitMQ and click **Deploy** on the **App Info** page.
|
||||
|
||||
2. Find **RabbitMQ** and click **Deploy**.
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
3. Set a name and select an app version. Make sure RabbitMQ is deployed in `demo-project` and click **Next**.
|
||||
|
||||
3. Make sure RabbitMQ is deployed in `test-project` and click **Next**.
|
||||

|
||||
|
||||

|
||||
4. In **App Config**, you can use the default configuration directly or customize the configuration either by specifying fields in a form or editing the YAML file. Record the value of **Root Username** and the value of **Root Password**, which will be used later for login. Click **Deploy** to continue.
|
||||
|
||||
4. Use the default configuration or change the account and password as you want. then click **Deploy**.
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
To see the manifest file, toggle the **YAML** switch.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Wait until RabbitMQ is up and running.
|
||||
|
||||

|
||||

|
||||
|
||||
### Step 2: Access RabbitMQ Dashboard
|
||||
|
||||
1. Go to **Services**.and click **rabbiitmq-service-name**.
|
||||
To access RabbitMQ outside the cluster, you need to expose the app through NodePort first.
|
||||
|
||||

|
||||
1. Go to **Services** and click the service name of RabbitMQ.
|
||||
|
||||
2. Click **More** and click **Edit Internet Access**.
|
||||

|
||||
|
||||

|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||
3. Select **NodePort** and click **Ok**. [Learn More](https://v2-1.docs.kubesphere.io/docs/project-setting/project-gateway/)
|
||||

|
||||

|
||||
|
||||
4. Through <font color=green>{$NodeIP} : {$Nodeport}</font> to access RabbitMQ management.
|
||||

|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](../../../project-administration/project-gateway/).
|
||||
|
||||
5. Log in RabbitMQ management.
|
||||

|
||||

|
||||
|
||||
6. If you want to learn more information about RabbitMQ please refer to https://www.rabbitmq.com/documentation.html.
|
||||
4. Under **Service Ports**, you can see ports are exposed.
|
||||
|
||||

|
||||
|
||||
5. Access RabbitMQ **management** through `{$NodeIP}:{$Nodeport}`. Note that the username and password are those you set in **Step 1**.
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. For more information about RabbitMQ, refer to [the official documentation of RabbitMQ](https://www.rabbitmq.com/documentation.html).
|
||||
|
|
@ -6,67 +6,83 @@ description: 'How to deploy Tomcat on KubeSphere through App Store'
|
|||
link title: "Deploy Tomcat"
|
||||
weight: 261
|
||||
---
|
||||
[Apache Tomcat](https://tomcat.apache.org/index.html) software powers numerous large-scale, mission-critical web applications across a diverse range of industries and organizations.
|
||||
This tutorial walks you through an example of how to deploy Tomcat on KubeSphere.
|
||||
[Apache Tomcat](https://tomcat.apache.org/index.html) powers numerous large-scale, mission-critical web applications across a diverse range of industries and organizations. Tomcat provides a pure Java HTTP web server environment in which Java code can run.
|
||||
|
||||
This tutorial walks you through an example of deploying Tomcat from the App Store of KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/). Tomcat will be deployed from the App Store.
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-operator` and work in the project `test-project` in the workspace `test-workspace`.
|
||||
- Please make sure you [enable the OpenPitrix system](https://kubesphere.io/docs/pluggable-components/app-store/).
|
||||
- You need to create a workspace, a project, and a user account for this tutorial. The account needs to be a platform regular user and to be invited as the project operator with the `operator` role. In this tutorial, you log in as `project-regular` and work in the project `demo-project` in the workspace `demo-workspace`. For more information, see [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project/).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Tomcat from App Store
|
||||
|
||||
Please make sure you are landing on the **Overview** page of the project `test-project`.
|
||||
1. On the **Overview** page of the project `demo-project`, click **App Store** in the top left corner.
|
||||
|
||||
1. Go to **App Store**.
|
||||

|
||||
|
||||

|
||||
2. Find Tomcat and click **Deploy** on the **App Info** page.
|
||||
|
||||
2. Find **Tomcat** and click **Deploy**.
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
3. Set a name and select an app version. Make sure Tomcat is deployed in `demo-project` and click **Next**.
|
||||
|
||||
3. Make sure Tomcat is deployed in `test-project` and click **Next**.
|
||||

|
||||
|
||||

|
||||
4. In **App Config**, you can use the default configuration or customize the configuration by editing the YAML file directly. Click **Deploy** to continue.
|
||||
|
||||
4. Use the default configuration and click **Deploy**.
|
||||
|
||||

|
||||

|
||||
|
||||
5. Wait until Tomcat is up and running.
|
||||
|
||||

|
||||

|
||||
|
||||
### Step 2: Access Tomcat Terminal
|
||||
|
||||
1. Go to **Services** and click **tomcat-service-name**.
|
||||
1. Go to **Services** and click the service name of Tomcat.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Expand pods information and click **terminal**. You can now use the feature.
|
||||

|
||||

|
||||
2. Under **Pods**, expand the menu to see container details, and then click the **Terminal** icon.
|
||||
|
||||
3. You can view the deployed projects in `/usr/local/tomcat/webapps`.
|
||||

|
||||

|
||||
|
||||
### Step 3: Access the Tomcat project in the browser
|
||||
3. You can view deployed projects in `/usr/local/tomcat/webapps`.
|
||||
|
||||
1. Go to **Services** and click **tomcat-service-name**.
|
||||

|
||||
|
||||
2. Click **More** and click **Edit Internet Access**.
|
||||

|
||||
### Step 3: Access Tomcat Project from Browser
|
||||
|
||||
3. Select **NodePort** and click **Ok**. [Learn More](https://v2-1.docs.kubesphere.io/docs/project-setting/project-gateway/)
|
||||

|
||||
To access Tomcat projects outside the cluster, you need to expose the app through NodePort first.
|
||||
|
||||
4. Through <font color=green>{$NodeIP} : {$Nodeport} / {$Project path}</font> to access the tomcat project in browser.
|
||||

|
||||

|
||||
1. Go to **Services** and click the service name of Tomcat.
|
||||
|
||||
5. If you want to learn more information about Tomcat please refer to https://tomcat.apache.org/index.html.
|
||||

|
||||
|
||||
2. Click **More** and select **Edit Internet Access** from the drop-down menu.
|
||||
|
||||

|
||||
|
||||
3. Select **NodePort** for **Access Method** and click **OK**. For more information, see [Project Gateway](https://deploy-preview-492--kubesphere-v3.netlify.app/docs/project-administration/project-gateway/).
|
||||
|
||||

|
||||
|
||||
4. Under **Service Ports**, you can see the port is exposed.
|
||||
|
||||

|
||||
|
||||
5. Access the sample Tomcat project through `{$NodeIP}:{$Nodeport}` in your browser.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You may need to open the port in your security groups and configure related port forwarding rules depending on your where your Kubernetes cluster is deployed.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
6. For more information about Tomcat, refer to [the official documentation of Tomcat](https://tomcat.apache.org/index.html).
|
||||
|
|
@ -13,15 +13,19 @@ icon: "/images/docs/docs.svg"
|
|||
|
||||
In KubeSphere, you set a cluster's configuration and configure its features using the interactive web console or the built-in native command-line tool kubectl. As a cluster administrator, you are responsible for a series of tasks, including cordoning and adding labels to nodes, controlling cluster visibility, monitoring cluster status, setting cluster-wide alerting and notification rules, as well as configuring storage and log collection solutions.
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
Multi-cluster management is not covered in this chapter. For more information about this feature, see [Multi-cluster Management](../multicluster-management/).
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## [Persistent Volume and Storage Class](../cluster-administration/persistent-volume-and-storage-class/)
|
||||
|
||||
Learn basic concepts of PVs, PVCs and storage classes, and demonstrates how to manage storage classes and PVCs in KubeSphere.
|
||||
|
||||
## [Node Management](../cluster-administration/nodes/)
|
||||
|
||||
Monitor node status and learn how to add node label or taints.
|
||||
Monitor node status and learn how to add node label or taints.
|
||||
|
||||
## [Cluster Status Monitoring](../cluster-administration/cluster-status-monitoring/)
|
||||
|
||||
|
|
@ -29,7 +33,7 @@ Monitor how a cluster is functioning based on different metrics, including physi
|
|||
|
||||
## [Application Resources Monitoring](../cluster-administration/application-resources-monitoring/)
|
||||
|
||||
Monitor application resources across the cluster, such as the number of Deployments and CPU usage of different projects.
|
||||
Monitor application resources across the cluster, such as the number of Deployments and CPU usage of different projects.
|
||||
|
||||
## Cluster-wide Alerting and Notification
|
||||
|
||||
|
|
@ -73,3 +77,10 @@ Learn how to add Fluentd to receive logs, events or auditing logs.
|
|||
|
||||
Customize your email address settings to receive notifications of any alert.
|
||||
|
||||
## [Customizing Platform Information](../cluster-administration/platform-settings/customize-basic-information/)
|
||||
|
||||
Customize platform settings such as logo, title etc.
|
||||
|
||||
## [Cluster Shutdown and Restart](../cluster-administration/shuting-down-and-restart-cluster-cracefully/)
|
||||
|
||||
Learn how to gracefully shutting down your cluster and how to restart it.
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ weight: 400
|
|||
|
||||
In addition to monitoring data at the physical resource level, cluster administrators also need to keep a close track of application resources across the platform, such as the number of projects and DevOps projects, as well as the number of workloads and services of a specific type. Application resource monitoring provides a summary of resource usage and application-level trends of the platform.
|
||||
|
||||
## Prerequisites
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Clusters Management**. For example, you can log in the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
|
||||
|
|
@ -17,25 +17,26 @@ You need an account granted a role including the authorization of **Clusters Man
|
|||
|
||||
1. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management) with member clusters imported, you can select a specific cluster to view its application resources. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||

|
||||

|
||||
|
||||
3. Choose **Application Resources** under **Monitoring & Alerting** to see the overview of application resource monitoring, including the summary of the usage of all resources in the cluster, as shown in the following figure.
|
||||
|
||||

|
||||

|
||||
|
||||
4. Among them, **Cluster Resources Usage** and **Application Resources Usage** retain the monitoring data of the last 7 days and support custom time range queries.
|
||||
|
||||

|
||||

|
||||
|
||||
5. Click a specific resource to view detailed usage and trends of it during a certain time period, such as **CPU** under **Cluster Resources Usage**. The detail page allows you to view specific monitoring data by project. The highly-interactive dashboard enables users to customize the time range, displaying the exact resource usage at a given time point.
|
||||
|
||||

|
||||

|
||||
|
||||
## Usage Ranking
|
||||
|
||||
**Usage Ranking** supports the sorting of project resource usage, so that platform administrators can understand the resource usage of each project in the current cluster, including **CPU Usage**, **Memory Usage**, **Pod Count**, as well as **Outbound Traffic** and **Inbound Traffic**. You can sort projects in ascending or descending order by one of the indicators in the drop-down list.
|
||||

|
||||
**Usage Ranking** supports the sorting of project resource usage, so that platform administrators can understand the resource usage of each project in the current cluster, including **CPU Usage**, **Memory Usage**, **Pod Count**, as well as **Outbound Traffic** and **Inbound Traffic**. You can sort projects in ascending or descending order by one of the indicators in the drop-down list. This feature is very useful for quickly locating your application (Pod) that is consuming heavy CPU or memory.
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -15,23 +15,25 @@ Before adding a log receiver, you need to enable any of the `logging`, `events`
|
|||
|
||||
1. To add a log receiver:
|
||||
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
|
||||

|
||||

|
||||
|
||||
2. Choose ***Elasticsearch*** and fill in the Elasticsearch service address and port like below:
|
||||
|
||||

|
||||

|
||||
|
||||
3. Elasticsearch appears in the receiver list of ***Log Collections*** page and its status becomes ***Collecting***.
|
||||
|
||||

|
||||

|
||||
|
||||
4. Verify whether Elasticsearch is receiving logs sent from Fluent Bit:
|
||||
|
||||
- Click ***Log Search*** in the ***Toolbox*** in the bottom right corner.
|
||||
- You can search logs in the logging console that appears.
|
||||
- Click ***Log Search*** in the ***Toolbox*** in the bottom right corner.
|
||||
- You can search logs in the logging console that appears.
|
||||
|
||||
You can read [Log Query](../../../../toolbox/log-query/) to learn how to use the tool.
|
||||
|
|
|
|||
|
|
@ -125,31 +125,30 @@ EOF
|
|||
|
||||
1. To add a log receiver:
|
||||
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
|
||||

|
||||

|
||||
|
||||
2. Choose ***Fluentd*** and fill in the Fluentd service address and port like below:
|
||||
|
||||

|
||||

|
||||
|
||||
3. Fluentd appears in the receiver list of ***Log Collections*** UI and its status shows ***Collecting***.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
4. Verify whether Fluentd is receiving logs sent from Fluent Bit:
|
||||
|
||||
- Click ***Application Workloads*** in the ***Cluster Management*** UI.
|
||||
- Select ***Workloads*** and then select the `default` namespace in the ***Workload*** - ***Deployments*** tab
|
||||
- Click the ***fluentd*** item and then click the ***fluentd-xxxxxxxxx-xxxxx*** pod
|
||||
- Click the ***fluentd*** container
|
||||
- In the ***fluentd*** container page, select the ***Container Logs*** tab
|
||||
- Click ***Application Workloads*** in the ***Cluster Management*** UI.
|
||||
- Select ***Workloads*** and then select the `default` namespace in the ***Workload*** - ***Deployments*** tab
|
||||
- Click the ***fluentd*** item and then click the ***fluentd-xxxxxxxxx-xxxxx*** pod
|
||||
- Click the ***fluentd*** container
|
||||
- In the ***fluentd*** container page, select the ***Container Logs*** tab
|
||||
|
||||
You'll see logs begin to scroll up continuously.
|
||||
You'll see logs begin to scroll up continuously.
|
||||
|
||||

|
||||

|
||||
|
|
@ -10,8 +10,8 @@ KubeSphere supports using Elasticsearch, Kafka and Fluentd as log receivers.
|
|||
This doc will demonstrate:
|
||||
|
||||
- Deploy [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) and then create a Kafka cluster and a Kafka topic by creating `Kafka` and `KafkaTopic` CRDs.
|
||||
- Add Kafka log receiver to receive logs sent from Fluent Bit
|
||||
- Verify whether the Kafka cluster is receiving logs using [Kafkacat](https://github.com/edenhill/kafkacat)
|
||||
- Add Kafka log receiver to receive logs sent from Fluent Bit.
|
||||
- Verify whether the Kafka cluster is receiving logs using [Kafkacat](https://github.com/edenhill/kafkacat).
|
||||
|
||||
## Prerequisite
|
||||
|
||||
|
|
@ -29,105 +29,104 @@ You can use [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-op
|
|||
|
||||
1. Install [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) to the `default` namespace:
|
||||
|
||||
```bash
|
||||
helm repo add strimzi https://strimzi.io/charts/
|
||||
helm install --name kafka-operator -n default strimzi/strimzi-kafka-operator
|
||||
```
|
||||
```bash
|
||||
helm repo add strimzi https://strimzi.io/charts/
|
||||
helm install --name kafka-operator -n default strimzi/strimzi-kafka-operator
|
||||
```
|
||||
|
||||
2. Create a Kafka cluster and a Kafka topic in the `default` namespace:
|
||||
|
||||
To deploy a Kafka cluster and create a Kafka topic, you simply need to open the ***kubectl*** console in ***KubeSphere Toolbox*** and run the following command:
|
||||
To deploy a Kafka cluster and create a Kafka topic, you simply need to open the ***kubectl*** console in ***KubeSphere Toolbox*** and run the following command:
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
The following will create Kafka and Zookeeper clusters with storage type `ephemeral` which is `emptydir` for demo purpose. You should use other storage types for production, please refer to [kafka-persistent](https://github.com/strimzi/strimzi-kafka-operator/blob/0.19.0/examples/kafka/kafka-persistent.yaml).
|
||||
{{</ notice >}}
|
||||
|
||||
The following will create Kafka and Zookeeper clusters with storage type `ephemeral` which is `emptydir` for demo purpose. You should use other storage types for production, please refer to [kafka-persistent](https://github.com/strimzi/strimzi-kafka-operator/blob/0.19.0/examples/kafka/kafka-persistent.yaml)
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```yaml
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: Kafka
|
||||
metadata:
|
||||
name: my-cluster
|
||||
namespace: default
|
||||
spec:
|
||||
kafka:
|
||||
version: 2.5.0
|
||||
replicas: 3
|
||||
listeners:
|
||||
plain: {}
|
||||
tls: {}
|
||||
config:
|
||||
offsets.topic.replication.factor: 3
|
||||
transaction.state.log.replication.factor: 3
|
||||
transaction.state.log.min.isr: 2
|
||||
log.message.format.version: '2.5'
|
||||
storage:
|
||||
type: ephemeral
|
||||
zookeeper:
|
||||
replicas: 3
|
||||
storage:
|
||||
type: ephemeral
|
||||
entityOperator:
|
||||
topicOperator: {}
|
||||
userOperator: {}
|
||||
---
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: KafkaTopic
|
||||
metadata:
|
||||
name: my-topic
|
||||
namespace: default
|
||||
labels:
|
||||
strimzi.io/cluster: my-cluster
|
||||
spec:
|
||||
partitions: 3
|
||||
replicas: 3
|
||||
config:
|
||||
retention.ms: 7200000
|
||||
segment.bytes: 1073741824
|
||||
EOF
|
||||
```
|
||||
```yaml
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: Kafka
|
||||
metadata:
|
||||
name: my-cluster
|
||||
namespace: default
|
||||
spec:
|
||||
kafka:
|
||||
version: 2.5.0
|
||||
replicas: 3
|
||||
listeners:
|
||||
plain: {}
|
||||
tls: {}
|
||||
config:
|
||||
offsets.topic.replication.factor: 3
|
||||
transaction.state.log.replication.factor: 3
|
||||
transaction.state.log.min.isr: 2
|
||||
log.message.format.version: '2.5'
|
||||
storage:
|
||||
type: ephemeral
|
||||
zookeeper:
|
||||
replicas: 3
|
||||
storage:
|
||||
type: ephemeral
|
||||
entityOperator:
|
||||
topicOperator: {}
|
||||
userOperator: {}
|
||||
---
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: KafkaTopic
|
||||
metadata:
|
||||
name: my-topic
|
||||
namespace: default
|
||||
labels:
|
||||
strimzi.io/cluster: my-cluster
|
||||
spec:
|
||||
partitions: 3
|
||||
replicas: 3
|
||||
config:
|
||||
retention.ms: 7200000
|
||||
segment.bytes: 1073741824
|
||||
EOF
|
||||
```
|
||||
|
||||
3. Run the following command to wait for Kafka and Zookeeper pods are all up and runing:
|
||||
|
||||
```bash
|
||||
kubectl -n default get pod
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
my-cluster-entity-operator-f977bf457-s7ns2 3/3 Running 0 69m
|
||||
my-cluster-kafka-0 2/2 Running 0 69m
|
||||
my-cluster-kafka-1 2/2 Running 0 69m
|
||||
my-cluster-kafka-2 2/2 Running 0 69m
|
||||
my-cluster-zookeeper-0 1/1 Running 0 71m
|
||||
my-cluster-zookeeper-1 1/1 Running 1 71m
|
||||
my-cluster-zookeeper-2 1/1 Running 1 71m
|
||||
strimzi-cluster-operator-7d6cd6bdf7-9cf6t 1/1 Running 0 104m
|
||||
```
|
||||
```bash
|
||||
kubectl -n default get pod
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
my-cluster-entity-operator-f977bf457-s7ns2 3/3 Running 0 69m
|
||||
my-cluster-kafka-0 2/2 Running 0 69m
|
||||
my-cluster-kafka-1 2/2 Running 0 69m
|
||||
my-cluster-kafka-2 2/2 Running 0 69m
|
||||
my-cluster-zookeeper-0 1/1 Running 0 71m
|
||||
my-cluster-zookeeper-1 1/1 Running 1 71m
|
||||
my-cluster-zookeeper-2 1/1 Running 1 71m
|
||||
strimzi-cluster-operator-7d6cd6bdf7-9cf6t 1/1 Running 0 104m
|
||||
```
|
||||
|
||||
Then run the follwing command to find out metadata of kafka cluster
|
||||
Then run the follwing command to find out metadata of kafka cluster
|
||||
|
||||
```bash
|
||||
kafkacat -L -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092
|
||||
```
|
||||
```bash
|
||||
kafkacat -L -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092
|
||||
```
|
||||
|
||||
4. Add Kafka as logs receiver:
|
||||
Click ***Add Log Collector*** and then select ***Kafka***, input Kafka broker address and port like below:
|
||||
|
||||
```bash
|
||||
my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc 9092
|
||||
```
|
||||
Click ***Add Log Collector*** and then select ***Kafka***, input Kafka broker address and port like below:
|
||||
|
||||

|
||||
```bash
|
||||
my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc 9092
|
||||
```
|
||||
|
||||

|
||||
|
||||
5. Run the following command to verify whether the Kafka cluster is receiving logs sent from Fluent Bit:
|
||||
|
||||
```bash
|
||||
# Start a util container
|
||||
kubectl run --rm utils -it --generator=run-pod/v1 --image arunvelsriram/utils bash
|
||||
# Install Kafkacat in the util container
|
||||
apt-get install kafkacat
|
||||
# Run the following command to consume log messages from kafka topic: my-topic
|
||||
kafkacat -C -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092 -t my-topic
|
||||
```
|
||||
```bash
|
||||
# Start a util container
|
||||
kubectl run --rm utils -it --generator=run-pod/v1 --image arunvelsriram/utils bash
|
||||
# Install Kafkacat in the util container
|
||||
apt-get install kafkacat
|
||||
# Run the following command to consume log messages from kafka topic: my-topic
|
||||
kafkacat -C -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092 -t my-topic
|
||||
```
|
||||
|
|
|
|||
|
|
@ -34,7 +34,7 @@ To add a log receiver:
|
|||
|
||||
### Add Elasticsearch as log receiver
|
||||
|
||||
A default Elasticsearch receiver will be added with its service address set to an Elasticsearch cluster if logging/events/auditing is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md)
|
||||
A default Elasticsearch receiver will be added with its service address set to an Elasticsearch cluster if logging/events/auditing is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md).
|
||||
|
||||
An internal Elasticsearch cluster will be deployed into K8s cluster if neither ***externalElasticsearchUrl*** nor ***externalElasticsearchPort*** are specified in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md) when logging/events/auditing is enabled.
|
||||
|
||||
|
|
@ -72,15 +72,15 @@ To turn a log receiver on or off:
|
|||
- Click a log receiver and enter the receiver details page.
|
||||
- Click ***More*** -> ***Change Status***
|
||||
|
||||

|
||||

|
||||
|
||||
- You can select ***Activate*** or ***Close*** to turn the log receiver on or off
|
||||
|
||||

|
||||

|
||||
|
||||
- Log receiver's status will be changed to ***Close*** if you turn it off, otherwise the status will be ***Collecting***
|
||||
|
||||

|
||||

|
||||
|
||||
## Modify or delete a log receiver
|
||||
|
||||
|
|
@ -89,6 +89,6 @@ You can modify a log receiver or delete it:
|
|||
- Click a log receiver and enter the receiver details page.
|
||||
- You can edit a log receiver by clicking ***Edit*** or ***Edit Yaml***
|
||||
|
||||

|
||||

|
||||
|
||||
- Log receiver can be deleted by clicking ***Delete Log Collector***
|
||||
|
|
|
|||
|
|
@ -18,9 +18,9 @@ This guide demonstrates email notification settings (customized settings support
|
|||
## Hands-on Lab
|
||||
|
||||
1. Log in the web console with one account granted the role `platform-admin`.
|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
3. Select a cluster from the list and enter it (If you do not enable the [multi-cluster feature](../../../multicluster-management/), you will directly go to the **Overview** page).
|
||||
4. Select **Mail Server** under **Cluster Settings**. In the page, provide your mail server configuration and SMTP authentication information as follows:
|
||||
|
|
@ -28,6 +28,6 @@ This guide demonstrates email notification settings (customized settings support
|
|||
- **Use SSL Secure Connection**: SSL can be used to encrypt mails, thereby improving the security of information transmitted by mails. Usually you have to configure the certificate for the mail server.
|
||||
- SMTP authentication information: Fill in **SMTP User**, **SMTP Password**, **Sender Email Address**, etc. as below
|
||||
|
||||

|
||||

|
||||
|
||||
5. After you complete the above settings, click **Save**. You can send a test email to verify the success of the server configuration.
|
||||
5. After you complete the above settings, click **Save**. You can send a test email to verify the success of the server configuration.
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@ You need an account granted a role including the authorization of **Clusters Man
|
|||
## Cluster Status Monitoring
|
||||
|
||||
1. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
<<<<<<< HEAD
|
||||

|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management) with member clusters imported, you can select a specific cluster to view its application resources. If you have not enabled the feature, refer to the next step directly.
|
||||
|
|
@ -24,10 +25,23 @@ You need an account granted a role including the authorization of **Clusters Man
|
|||
3. Choose **Cluster Status** under **Monitoring & Alerting** to see the overview of cluster status monitoring, including **Cluster Node Status**, **Components Status**, **Cluster Resources Usage**, **ETCD Monitoring**, and **Service Component Monitoring**, as shown in the following figure.
|
||||
|
||||

|
||||
=======
|
||||
|
||||

|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management) with member clusters imported, you can select a specific cluster to view its application resources. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||

|
||||
|
||||
3. Choose **Cluster Status** under **Monitoring & Alerting** to see the overview of cluster status monitoring, including **Cluster Node Status**, **Components Status**, **Cluster Resources Usage**, **ETCD Monitoring**, and **Service Component Monitoring**, as shown in the following figure.
|
||||
|
||||

|
||||
>>>>>>> 5f1e339a014d6bf1d77bcedbb4f723ea0a7e556d
|
||||
|
||||
### Cluster Node Status
|
||||
|
||||
1. **Cluster Node Status** displays the status of all nodes, separately marking the active ones. You can go to the **Cluster Nodes** page shown below to view the real-time resource usage of all nodes by clicking **Node Online Status**.
|
||||
<<<<<<< HEAD
|
||||

|
||||
|
||||
2. In **Cluster Nodes**, click the node name to view usage details in **Running Status**, including the information of CPU, Memory, Pod, Local Storage in the current node, and its health status.
|
||||
|
|
@ -38,16 +52,29 @@ You need an account granted a role including the authorization of **Clusters Man
|
|||

|
||||
|
||||
{{< notice tip >}}
|
||||
=======
|
||||
|
||||

|
||||
|
||||
2. In **Cluster Nodes**, click the node name to view usage details in **Running Status**, including the information of CPU, Memory, Pod, Local Storage in the current node, and its health status.
|
||||
|
||||

|
||||
|
||||
3. Click the tab **Monitoring** to view how the node is functioning during a certain period based on different metrics, including **CPU Utilization, CPU Load Average, Memory Utilization, Disk Utilization, inode Utilization, IOPS, DISK Throughput, and Network Bandwidth**, as shown in the following figure.
|
||||
|
||||

|
||||
>>>>>>> 5f1e339a014d6bf1d77bcedbb4f723ea0a7e556d
|
||||
|
||||
{{< notice tip >}}
|
||||
You can customize the time range from the drop-down list in the top right corner to view historical data.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
### Component Status
|
||||
|
||||
KubeSphere monitors the health status of various service components in the cluster. When a key component malfunctions, the system may become unavailable. The monitoring mechanism of KubeSphere ensures the platform can notify tenants of any occurring issues in case of a component failure, so that they can quickly locate the problem and take corresponding action.
|
||||
|
||||
1. On the **Cluster Status Monitoring** page, click components (the part in the green box below) under **Components Status** to view the status of service components.
|
||||
<<<<<<< HEAD
|
||||

|
||||
|
||||
2. You can see all the components are listed in this part. Components marked in green are those functioning normally while those marked in orange require special attention as it signals potential issues.
|
||||
|
|
@ -55,10 +82,18 @@ KubeSphere monitors the health status of various service components in the clust
|
|||

|
||||
|
||||
{{< notice tip >}}
|
||||
=======
|
||||
|
||||

|
||||
|
||||
2. You can see all the components are listed in this part. Components marked in green are those functioning normally while those marked in orange require special attention as it signals potential issues.
|
||||
|
||||

|
||||
>>>>>>> 5f1e339a014d6bf1d77bcedbb4f723ea0a7e556d
|
||||
|
||||
{{< notice tip >}}
|
||||
Components marked in orange may turn to green after a period of time, the reasons of which may be different, such as image pulling retries or pod recreations. You can click the component to see its service details.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
### Cluster Resources Usage
|
||||
|
||||
|
|
@ -151,6 +186,11 @@ ETCD monitoring helps you to make better use of ETCD, especially to locate perfo
|
|||
|
||||

|
||||
|
||||
<<<<<<< HEAD
|
||||
=======
|
||||

|
||||
|
||||
>>>>>>> 5f1e339a014d6bf1d77bcedbb4f723ea0a7e556d
|
||||
## APIServer Monitoring
|
||||
|
||||
[API Server](https://kubernetes.io/docs/concepts/overview/kubernetes-api/) is the hub for the interaction of all components in a Kubernetes cluster. The following table lists the main indicators monitored for the APIServer.
|
||||
|
|
|
|||
|
|
@ -17,19 +17,21 @@ You have created a node-level alert policy and received alert notifications of i
|
|||
|
||||
### Task 1: View Alert Message
|
||||
|
||||
1. Log in the console with one account granted the role `platform-admin`.
|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
1. Log in the console with one account granted the role `platform-admin`.
|
||||
|
||||

|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
|
||||

|
||||
|
||||
3. Select a cluster from the list and enter it (If you do not enable the [multi-cluster feature](../../../multicluster-management/), you will directly go to the **Overview** page).
|
||||
|
||||
4. Navigate to **Alerting Messages** under **Monitoring & Alerting**, and you can see alert messages in the list. In the example of [Alert Policy (Node Level)](../alerting-policy/), you set one node as the monitoring target, and its memory utilization rate is higher than the threshold of `50%`, so you can see an alert message of it.
|
||||
|
||||

|
||||

|
||||
|
||||
5. Click the alert message to enter the detail page. In **Alerting Detail**, you can see the graph of memory utilization rate of the node over time, which has been continuously higher than the threshold of `50%` set in the alert rule, so the alert was triggered.
|
||||
|
||||

|
||||

|
||||
|
||||
### Task 2: View Alert Policy
|
||||
|
||||
|
|
@ -41,9 +43,9 @@ Switch to **Alerting Policy** to view the alert policy corresponding to this ale
|
|||
|
||||
1. Switch to **Recent Notification**. It can be seen that 3 notifications have been received, because the notification rule was set with a repetition period of `Alert once every 5 minutes` and retransmission of `Resend up to 3 times`.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Log in your email to see alert notification mails sent by the KubeSphere mail server. You have received a total of 3 emails.
|
||||
2. Log in your email to see alert notification mails sent by the KubeSphere mail server. You have received a total of 3 emails.
|
||||
|
||||
### Task 4: Add Comment
|
||||
|
||||
|
|
|
|||
|
|
@ -20,19 +20,22 @@ KubeSphere provides alert policies for nodes and workloads. This guide demonstra
|
|||
|
||||
### Task 1: Create an Alert Policy
|
||||
|
||||
1. Log in the console with one account granted the role `platform-admin`.
|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
1. Log in the console with one account granted the role `platform-admin`.
|
||||
|
||||

|
||||
2. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
|
||||

|
||||
|
||||
3. Select a cluster from the list and enter it (If you do not enable the [multi-cluster feature](../../../multicluster-management/), you will directly go to the **Overview** page).
|
||||
|
||||
4. Navigate to **Alerting Policies** under **Monitoring & Alerting**, and click **Create**.
|
||||
|
||||

|
||||

|
||||
|
||||
### Task 2: Provide Basic Information
|
||||
|
||||
In the dialog that appears, fill in the basic information as follows. Click **Next** after you finish.
|
||||
|
||||
- **Name**: a concise and clear name as its unique identifier, such as `alert-demo`.
|
||||
- **Alias**: to help you distinguish alert policies better. Chinese is supported.
|
||||
- **Description**: a brief introduction to the alert policy.
|
||||
|
|
@ -41,7 +44,8 @@ In the dialog that appears, fill in the basic information as follows. Click **Ne
|
|||
|
||||
### Task 3: Select Monitoring Targets
|
||||
|
||||
Select several nodes in the node list as the monitoring targets. Here a node is selected for the convenience of demonstration. Click **Next** when you finish.
|
||||
Select several nodes in the node list or use Node Selector to choose a group of nodes as the monitoring targets. Here a node is selected for the convenience of demonstration. Click **Next** when you finish.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
|
@ -54,7 +58,7 @@ You can sort nodes in the node list from the drop-down menu through the followin
|
|||
|
||||
1. Click **Add Rule** to begin to create an alerting rule. The rule defines parameters such as metric type, check period, consecutive times, metric threshold and alert level to provide rich configurations. The check period (the second field under **Rule**) means the time interval between 2 consecutive checks of the metric. For example, `2 minutes/period` means the metric is checked every two minutes. The consecutive times (the third field under **Rule**) means the number of consecutive times that the metric meets the threshold when checked. An alert is only triggered when the actual time is equal to or is greater than the number of consecutive times set in the alert policy.
|
||||
|
||||

|
||||

|
||||
|
||||
2. In this example, set those parameters to `memory utilization rate`, `1 minute/period`, `2 consecutive times`, `>` and `50%`, and `Major Alert` in turn. It means KubeSphere checks the memory utilization rate every minute, and a major alert is triggered if it is larger than 50% for 2 consecutive times.
|
||||
|
||||
|
|
@ -62,21 +66,23 @@ You can sort nodes in the node list from the drop-down menu through the followin
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
- You can create node-level alert policies for the following metrics:
|
||||
- CPU: `cpu utilization rate`, `cpu load average 1 minute`, `cpu load average 5 minutes`, `cpu load average 15 minutes`
|
||||
- Memory: `memory utilization rate`, `memory available`
|
||||
- Disk: `inode utilization rate`, `disk space available`, `local disk space utilization rate`, `disk write throughput`, `disk read throughput`, `disk read iops`, `disk write iops`
|
||||
- Network: `network data transmitting rate`, `network data receiving rate`
|
||||
- Pod: `pod abnormal ratio`, `pod utilization rate`
|
||||
You can create node-level alert policies for the following metrics:
|
||||
|
||||
- CPU: `cpu utilization rate`, `cpu load average 1 minute`, `cpu load average 5 minutes`, `cpu load average 15 minutes`
|
||||
- Memory: `memory utilization rate`, `memory available`
|
||||
- Disk: `inode utilization rate`, `disk space available`, `local disk space utilization rate`, `disk write throughput`, `disk read throughput`, `disk read iops`, `disk write iops`
|
||||
- Network: `network data transmitting rate`, `network data receiving rate`
|
||||
- Pod: `pod abnormal ratio`, `pod utilization rate`
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Task 5: Set Notification Rule
|
||||
|
||||
1. **Effective Notification Time Range** is used to set sending time of notification emails, such as `09:00 ~ 19:00`. **Notification Channel** currently only supports **Email**. You can add email addresses of members to be notified to **Notification List**.
|
||||
1. **Customize Repetition Rules** defines sending period and retransmission times of notification emails. If alerts have not been resolved, the notification will be sent repeatedly after a certain period of time. Different repetition rules can also be set for different levels of alerts. Since the alert level set in the previous step is `Major Alert`, select `Alert once every 5 miniutes` (sending period) in the second field for **Major Alert** and `Resend up to 3 times` in the third field (retransmission times). Refer to the following image to set notification rules:
|
||||
|
||||

|
||||
2. **Customize Repetition Rules** defines sending period and retransmission times of notification emails. If alerts have not been resolved, the notification will be sent repeatedly after a certain period of time. Different repetition rules can also be set for different levels of alerts. Since the alert level set in the previous step is `Major Alert`, select `Alert once every 5 miniutes` (sending period) in the second field for **Major Alert** and `Resend up to 3 times` in the third field (retransmission times). Refer to the following image to set notification rules:
|
||||
|
||||

|
||||
|
||||
3. Click **Create**, and you can see that the alert policy is successfully created.
|
||||
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ Starting from v3.0, KubeSphere adds popular alert rules in the open source commu
|
|||
|
||||
## Use Alertmanager to manage K8s events alerts
|
||||
|
||||
Alertmanager can be used to manage alerts sent from sources other than Prometheus. In KubeSphere v3.0 and above, user can use it to manage alerts triggered by K8s events. For more details, please refer to [kube-events](https://github.com/kubesphere/kube-events)
|
||||
Alertmanager can be used to manage alerts sent from sources other than Prometheus. In KubeSphere v3.0 and above, user can use it to manage alerts triggered by K8s events. For more details, please refer to [kube-events](https://github.com/kubesphere/kube-events).
|
||||
|
||||
## Use Alertmanager to manage KubeSphere auditing alerts
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ linkTitle: "Notification Manager"
|
|||
weight: 2020
|
||||
---
|
||||
|
||||
[Notification Manager](https://github.com/kubesphere/notification-manager) manages notifications in KubeSphere. It receives alerts or notifications from different senders and then send notifications to different users.
|
||||
[Notification Manager](https://github.com/kubesphere/notification-manager) manages notifications in KubeSphere. It receives alerts or notifications from different senders and then sends notifications to different users.
|
||||
|
||||
Supported senders includes:
|
||||
|
||||
|
|
|
|||
|
|
@ -21,30 +21,28 @@ Cluster nodes are only accessible to cluster administrators. Some node metrics a
|
|||
|
||||
1. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management) with member clusters imported, you can select a specific cluster to view its nodes. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||

|
||||

|
||||
|
||||
3. Choose **Cluster Nodes** under **Nodes**, where you can see detailed information of node status.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Name**: The node name and subnet IP address.
|
||||
- **Status**: The current status of a node, indicating whether a node is available or not.
|
||||
- **Role**: The role of a node, indicating whether a node is a worker or master.
|
||||
- **CPU**: The real-time CPU usage of a node.
|
||||
- **Memory**: The real-time memory usage of a node.
|
||||
- **Pods**: The real-time usage of Pods on a node.
|
||||
- **Allocated CPU**: This metric is calculated based on the total CPU requests of Pods on a node. It represents the amount of CPU reserved for workloads on this node, even if workloads are using fewer CPU resources. This figure is vital to the Kubernetes scheduler (kube-scheduler), which favors nodes with lower allocated CPU resources when scheduling a Pod in most cases. For more details, refer to [Managing Resources for Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
|
||||
- **Allocated Memory**: This metric is calculated based on the total memory requests of Pods on a node. It represents the amount of memory reserved for workloads on this node, even if workloads are using fewer memory resources.
|
||||
|
||||
{{< notice note >}}
|
||||
- **Name**: The node name and subnet IP address.
|
||||
- **Status**: The current status of a node, indicating whether a node is available or not.
|
||||
- **Role**: The role of a node, indicating whether a node is a worker or master.
|
||||
- **CPU**: The real-time CPU usage of a node.
|
||||
- **Memory**: The real-time memory usage of a node.
|
||||
- **Pods**: The real-time usage of Pods on a node.
|
||||
- **Allocated CPU**: This metric is calculated based on the total CPU requests of Pods on a node. It represents the amount of CPU reserved for workloads on this node, even if workloads are using fewer CPU resources. This figure is vital to the Kubernetes scheduler (kube-scheduler), which favors nodes with lower allocated CPU resources when scheduling a Pod in most cases. For more details, refer to [Managing Resources for Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
|
||||
- **Allocated Memory**: This metric is calculated based on the total memory requests of Pods on a node. It represents the amount of memory reserved for workloads on this node, even if workloads are using fewer memory resources.
|
||||
|
||||
{{< notice note >}}
|
||||
**CPU** and **Allocated CPU** are different most times, so are **Memory** and **Allocated Memory**, which is normal. As a cluster administrator, you need to focus on both metrics instead of just one. It's always a good practice to set resource requests and limits for each node to match their real usage. Over-allocating resources can lead to low cluster utilization, while under-allocating may result in high pressure on a cluster, leaving the cluster unhealthy.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Node Management
|
||||
|
||||
|
|
@ -55,22 +53,20 @@ Click a node from the list and you can go to its detail page.
|
|||
- **Cordon/Uncordon**: Marking a node as unschedulable is very useful during a node reboot or other maintenance. The Kubernetes scheduler will not schedule new Pods to this node if it's been marked unschedulable. Besides, this does not affect existing workloads already on the node. In KubeSphere, you mark a node as unschedulable by clicking **Cordon** on the node detail page. The node will be schedulable if you click the button (**Uncordon**) again.
|
||||
- **Labels**: Node labels can be very useful when you want to assign Pods to specific nodes. Label a node first (e.g. label GPU nodes with `node-role.kubernetes.io/gpu-node`), and then add the label in **Advanced Settings** [when you create a workload](../../project-user-guide/application-workloads/deployments/#step-5-configure-advanced-settings) so that you can allow Pods to run on GPU nodes explicitly. To add node labels, click **More** and select **Edit Labels**.
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
- **Taints**: Taints allow a node to repel a set of pods. You add or remove node taints on the node detail page. To add or delete taints, click **More** and select **Taint Management** from the drop-down menu.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
Be careful when you add taints as they may cause unexpected behavior, leading to services unavailable. For more information, see [Taints and Tolerations](https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/).
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Add and Remove Nodes
|
||||
|
||||
Currently, you cannot add or remove nodes directly from the KubeSphere console, but you can do it by using [KubeKey](https://github.com/kubesphere/kubekey). For more information, see [Add New Nodes](../../installing-on-linux/cluster-operation/add-new-nodes/) and [Remove Nodes](../../installing-on-linux/cluster-operation/remove-nodes/).
|
||||
Currently, you cannot add or remove nodes directly from the KubeSphere console, but you can do it by using [KubeKey](https://github.com/kubesphere/kubekey). For more information, see [Add New Nodes](../../installing-on-linux/cluster-operation/add-new-nodes/) and [Remove Nodes](../../installing-on-linux/cluster-operation/remove-nodes/).
|
||||
|
|
|
|||
|
|
@ -0,0 +1,180 @@
|
|||
---
|
||||
title: "Persistent Volume and Storage Class"
|
||||
keywords: "storage, volume, pv, pvc, storage class, csi, Ceph RBD, Glusterfs, QingCloud, "
|
||||
description: "Persistent Volume and Storage Class Management"
|
||||
|
||||
linkTitle: "Persistent Volume and Storage Class"
|
||||
weight: 100
|
||||
---
|
||||
|
||||
This tutorial describes the basic concepts of PVs, PVCs and storage classes and demonstrates how a cluster administrator can manage storage classes and persistent volumes in KubeSphere.
|
||||
|
||||
## Introduction
|
||||
|
||||
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. PVs are volume plugins like Volumes, but have a lifecycle independent of any individual Pod that uses the PV. PVs can be provisioned either [statically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#static) or [dynamically](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#dynamic).
|
||||
|
||||
A PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources.
|
||||
|
||||
KubeSphere supports [dynamic volume provisioning](https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/) based on storage classes to create PVs.
|
||||
|
||||
A [StorageClass](https://kubernetes.io/docs/concepts/storage/storage-classes) provides a way for administrators to describe the classes of storage they offer. Different classes might map to quality-of-service levels, or to backup policies, or to arbitrary policies determined by the cluster administrators. Each StorageClass has a provisioner that determines what volume plugin is used for provisioning PVs. This field must be specified. For which value to use, please read [the official Kubernetes documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner) or check with your storage administrator.
|
||||
|
||||
The table below summarizes common volume plugins for various provisioners (storage systems).
|
||||
|
||||
| Type | Description |
|
||||
| -------------------- | ------------------------------------------------------------ |
|
||||
| In-tree | Built-in and run as part of Kubernetes, such as [RBD](https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd) and [Glusterfs](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs). For more plugins of this kind, see [Provisioner](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner). |
|
||||
| External-provisioner | Deployed independently from Kubernetes, but works like an in-tree plugin, such as [nfs-client](https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client). For more plugins of this kind, see [External Storage](https://github.com/kubernetes-retired/external-storage). |
|
||||
| CSI | Container Storage Interface, a standard for exposing storage resources to workloads on COs (e.g. Kubernetes), such as [QingCloud-csi](https://github.com/yunify/qingcloud-csi) and [Ceph-CSI](https://github.com/ceph/ceph-csi). For more plugins of this kind, see [Drivers](https://kubernetes-csi.github.io/docs/drivers.html). |
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You need an account granted a role including the authorization of **Clusters Management**. For example, you can log in the console as `admin` directly or create a new role with the authorization and assign it to an account.
|
||||
|
||||
## Manage Storage Class
|
||||
|
||||
1. Click **Platform** in the top left corner and select **Clusters Management**.
|
||||

|
||||
|
||||
2. If you have enabled the [multi-cluster feature](../../multicluster-management) with member clusters imported, you can select a specific cluster. If you have not enabled the feature, refer to the next step directly.
|
||||
|
||||
3. On the **Cluster Management** page, navigate to **Storage Classes** under **Storage**, where you can create, update and delete a storage class.
|
||||

|
||||
|
||||
4. To create a storage class, click **Create** and enter the basic information in the pop-up window. When you finish, click **Next**.
|
||||

|
||||
|
||||
5. In KubeSphere, you can create storage classes for `QingCloud-CSI`, `Glusterfs` and `Ceph RBD` directly. Alternatively, you can also create customized storage classes for other storage systems based on your needs. Select a type and click **Next**.
|
||||

|
||||
|
||||

|
||||
|
||||
### Common Settings
|
||||
|
||||
Some settings are commonly used and shared among storage classes. You can find them as dashboard properties on the console, which are also indicated by fields or annotations in the StorageClass manifest. You can see the manifest file in YAML format by enabling **Edit Mode** in the top right corner.
|
||||
Here are property descriptions of some commonly used fields in KubeSphere.
|
||||
|
||||
| Property | Description |
|
||||
| :---- | :---- |
|
||||
| Allow Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. When it is set to `true`, PVs can be configured to be expandable. For more information, see [Allow Volume Expansion](https://kubernetes.io/docs/concepts/storage/storage-classes/#allow-volume-expansion). |
|
||||
| Reclaiming Policy | Specified by `reclaimPolicy` in the manifest. It can be set to `Delete` or `Retain` (default). For more information, see [Reclaim Policy](https://kubernetes.io/docs/concepts/storage/storage-classes/#reclaim-policy). |
|
||||
| Storage System | Specified by `provisioner` in the manifest. It determines what volume plugin is used for provisioning PVs. For more information, see [Provisioner](https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner). |
|
||||
| Supported Access Mode | Specified by `metadata.annotations[storageclass.kubesphere.io/supported-access-modes]` in the manifest. It tells KubeSphere which [access mode](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes) is supported. |
|
||||
|
||||
For other settings, you need to provide different information for different storage plugins, which, in the manifest, are always indicated under the field `parameters`. They will be described in detail in the sections below. You can also refer to [Parameters](https://kubernetes.io/docs/concepts/storage/storage-classes/#parameters) in the official documentation of Kubernetes.
|
||||
|
||||
### QingCloud CSI
|
||||
|
||||
QingCloud CSI is a CSI plugin on Kubernetes for the volume of QingCloud. Storage classes of QingCloud CSI can be created on the KubeSphere console.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
- QingCloud CSI can be used on both public cloud and private cloud of QingCloud. Therefore, make sure KubeSphere has been installed on either of them so that you can use cloud volumes.
|
||||
- QingCloud CSI Plugin has been installed on your KubeSphere cluster. See [QingCloud-CSI Installation](https://github.com/yunify/qingcloud-csi#installation) for more information.
|
||||
|
||||
#### Settings
|
||||
|
||||

|
||||
|
||||
| Property | Description |
|
||||
| :---- | :---- |
|
||||
| type | On the QingCloud platform, 0 represents high performance volumes. 2 represents high capacity volumes. 3 represents super high performance volumes. 5 represents Enterprise Server SAN. 6 represents NeonSan HDD. 100 represents standard volumes. 200 represents enterprise SSD. |
|
||||
| maxSize | The volume size upper limit. |
|
||||
| stepSize | The volume size increment. |
|
||||
| minSize | The volume size lower limit. |
|
||||
| fsType | Filesystem type of the volume: ext3, ext4 (default), xfs. |
|
||||
| tags | The ID of QingCloud Tag resource, split by commas. |
|
||||
|
||||
More storage class parameters can be seen in [QingCloud-CSI user guide](https://github.com/yunify/qingcloud-csi/blob/master/docs/user-guide.md#set-storage-class).
|
||||
|
||||
### Glusterfs
|
||||
|
||||
Glusterfs is an in-tree storage plugin on Kubernetes, which means you don't need to install a volume plugin additionally.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
The Glusterfs storage system has already been installed. See [GlusterFS Installation Documentation](https://www.gluster.org/install/) for more information.
|
||||
|
||||
#### Settings
|
||||
|
||||
| Property | Description |
|
||||
| :---- | :---- |
|
||||
| resturl | The Gluster REST service/Heketi service url which provision gluster volumes on demand. |
|
||||
| clusterid | The ID of the cluster which will be used by Heketi when provisioning the volume. |
|
||||
| restauthenabled | Gluster REST service authentication boolean that enables authentication to the REST server. |
|
||||
| restuser | The Glusterfs REST service/Heketi user who has access to create volumes in the Glusterfs Trusted Pool. |
|
||||
| secretNamespace, secretName | The Identification of Secret instance that contains user password to use when talking to Gluster REST service. |
|
||||
| gidMin, gidMax | The minimum and maximum value of GID range for the StorageClass. |
|
||||
| volumetype | The volume type and its parameters can be configured with this optional value. |
|
||||
|
||||
For more information about StorageClass parameters, see [Glusterfs in Kubernetes Documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs).
|
||||
|
||||
### Ceph RBD
|
||||
|
||||
Ceph RBD is also an in-tree storage plugin on Kubernetes. The volume plugin is already in Kubernetes,
|
||||
but the storage server must be installed before you create the storage class of Ceph RBD.
|
||||
|
||||
As **hyperkube** images were [deprecated since 1.17](https://github.com/kubernetes/kubernetes/pull/85094), in-tree Ceph RBD may not work without **hyperkube**.
|
||||
Nevertheless, you can use [rbd provisioner](https://github.com/kubernetes-incubator/external-storage/tree/master/ceph/rbd) as a substitute, whose format is the same as in-tree Ceph RBD. The only different parameter is `provisioner` (i.e **Storage System** on the KubeSphere console). If you want to use rbd-provisioner, the value of `provisioner` must be `ceph.com/rbd` (Input this value in **Storage System** in the image below). If you use in-tree Ceph RBD, the value must be `kubernetes.io/rbd`.
|
||||
|
||||

|
||||
|
||||
#### Prerequisites
|
||||
|
||||
- The Ceph server has already been installed. See [Ceph Installation Documentation](https://docs.ceph.com/en/latest/install/) for more information.
|
||||
- Install the plugin if you choose to use rbd-provisioner. Community developers provide [charts for rbd provisioner](https://github.com/kubesphere/helm-charts/tree/master/src/test/rbd-provisioner) that you can use to install rbd-provisioner by helm.
|
||||
|
||||
#### Settings
|
||||
|
||||
| Property | Description |
|
||||
| :---- | :---- |
|
||||
| monitors| The Ceph monitors, comma delimited. |
|
||||
| adminId| The Ceph client ID that is capable of creating images in the pool. |
|
||||
| adminSecretName| The Secret Name for `adminId`. |
|
||||
| adminSecretNamespace| The namespace for `adminSecretName`. |
|
||||
| pool | The Ceph RBD pool. |
|
||||
| userId | The Ceph client ID that is used to map the RBD image. |
|
||||
| userSecretName | The name of Ceph Secret for `userId` to map RBD image. |
|
||||
| userSecretNamespace | The namespace for `userSecretName`. |
|
||||
| fsType | The fsType that is supported by Kubernetes. |
|
||||
| imageFormat | The Ceph RBD image format, `1` or `2`. |
|
||||
| imageFeatures| This parameter is optional and should only be used if you set `imageFormat` to `2`. |
|
||||
|
||||
For more information about StorageClass parameters, see [Ceph RBD in Kubernetes Documentation](https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd).
|
||||
|
||||
### Custom Storage Class
|
||||
|
||||
You can create custom storage classes for your storage systems if they are not directly supported by KubeSphere. The following example shows you how to create a storage class for NFS on the KubeSphere console.
|
||||
|
||||
#### NFS Introduction
|
||||
|
||||
NFS (Net File System) is widely used on Kubernetes with the external-provisioner volume plugin
|
||||
[nfs-client](https://github.com/kubernetes-retired/external-storage/tree/master/nfs-client). You can create the storage class of nfs-client by clicking **Custom** in the image below.
|
||||
|
||||

|
||||
|
||||
#### Prerequisites
|
||||
|
||||
- An available NFS server.
|
||||
- The volume plugin nfs-client has already been installed. Community developers provide [charts for nfs-client](https://github.com/kubesphere/helm-charts/tree/master/src/main/nfs-client-provisioner) that you can use to install nfs-client by helm.
|
||||
|
||||
#### Common Settings
|
||||
|
||||

|
||||
|
||||
| Property | Description |
|
||||
| :---- | :---- |
|
||||
| Storage System | Specified by `provisioner` in the manifest. If you install the storage class by [charts for nfs-client](https://github.com/kubesphere/helm-charts/tree/master/src/main/nfs-client-provisioner), it can be `cluster.local/nfs-client-nfs-client-provisioner`. |
|
||||
| Allow Volume Expansion | Specified by `allowVolumeExpansion` in the manifest. Select `No`. |
|
||||
| Reclaiming Policy | Specified by `reclaimPolicy` in the manifest. The value is `Delete` by default. |
|
||||
| Supported Access Mode | Specified by `.metadata.annotations.storageclass.kubesphere.io/supported-access-modes` in the manifest. `ReadWriteOnce`, `ReadOnlyMany` and `ReadWriteMany` all are selected by default. |
|
||||
|
||||
#### Parameters
|
||||
|
||||
| Key| Description | Value |
|
||||
| :---- | :---- | :----|
|
||||
| archiveOnDelete | Archive pvc when deleting | `true` |
|
||||
|
||||
## Manage Volumes
|
||||
|
||||
Once the storage class is created, you can create volumes with it. You can list, create, update and delete volumes in **Volumes** under **Storage** on the KubeSphere console. For more details, please see [Volume Management](../../project-user-guide/storage/volumes/).
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
---
|
||||
title: "Customizing Platform Information"
|
||||
keywords: 'KubeSphere, Kubernetes, customize, platform'
|
||||
description: 'How to Customizing KubeSphere Platform Information.'
|
||||
|
||||
linkTitle: "Customizing Platform Information"
|
||||
weight: 4270
|
||||
---
|
||||
|
||||
TBD
|
||||
|
|
@ -1,8 +0,0 @@
|
|||
---
|
||||
title: "StorageClass"
|
||||
keywords: "kubernetes, docker, kubesphere, jenkins, istio, prometheus"
|
||||
description: "Kubernetes and KubeSphere node management"
|
||||
|
||||
linkTitle: "StorageClass"
|
||||
weight: 100
|
||||
---
|
||||
|
|
@ -15,38 +15,38 @@ As you install the DevOps component, Jenkins is automatically deployed. KubeSphe
|
|||
|
||||
## Using DevOps
|
||||
|
||||
[DevOps Project Management](../devops-user-guide/how-to-use/devops-project-management/)
|
||||
### [DevOps Project Management](../devops-user-guide/how-to-use/devops-project-management/)
|
||||
|
||||
Create and manage DevOps projects, as well as roles and members in them.
|
||||
|
||||
[Create a Pipeline Using Jenkinsfile](../devops-user-guide/how-to-use/create-a-pipeline-using-jenkinsfile/)
|
||||
### [Create a Pipeline Using Jenkinsfile](../devops-user-guide/how-to-use/create-a-pipeline-using-jenkinsfile/)
|
||||
|
||||
Learn how to create and run a pipeline by using an example Jenkinsfile.
|
||||
|
||||
[Create a Pipeline Using Graphical Editing Panel](../devops-user-guide/how-to-use/create-a-pipeline-using-graphical-editing-panel/)
|
||||
### [Create a Pipeline Using Graphical Editing Panel](../devops-user-guide/how-to-use/create-a-pipeline-using-graphical-editing-panel/)
|
||||
|
||||
Learn how to create and run a pipeline by using the graphical editing panel of KubeSphere.
|
||||
|
||||
[Choose Jenkins Agent](../devops-user-guide/how-to-use/choose-jenkins-agent/)
|
||||
### [Choose Jenkins Agent](../devops-user-guide/how-to-use/choose-jenkins-agent/)
|
||||
|
||||
Specify the Jenkins agent and use the built-in podTemplate for your pipeline.
|
||||
|
||||
[Credential Management](../devops-user-guide/how-to-use/credential-management/)
|
||||
### [Credential Management](../devops-user-guide/how-to-use/credential-management/)
|
||||
|
||||
Create credentials so that your pipelines can communicate with third-party applications or websites.
|
||||
|
||||
[Set CI Node for Dependency Cathe](../devops-user-guide/how-to-use/set-ci-node/)
|
||||
### [Set CI Node for Dependency Cathe](../devops-user-guide/how-to-use/set-ci-node/)
|
||||
|
||||
Configure a node or a group of nodes specifically for continuous integration (CI) to speed up the building process in a pipeline.
|
||||
|
||||
[Set Email Server for KubeSphere Pipelines](../devops-user-guide/how-to-use/jenkins-email/)
|
||||
### [Set Email Server for KubeSphere Pipelines](../devops-user-guide/how-to-use/jenkins-email/)
|
||||
|
||||
Set the email server to receive notifications of your Jenkins pipelines.
|
||||
|
||||
[Jenkins System Settings](../devops-user-guide/how-to-use/jenkins-setting/)
|
||||
### [Jenkins System Settings](../devops-user-guide/how-to-use/jenkins-setting/)
|
||||
|
||||
Learn how to customize your Jenkins settings.
|
||||
|
||||
## Tool Integration
|
||||
|
||||
[Integrate SonarQube into Pipeline](../devops-user-guide/how-to-integrate/sonarqube/)
|
||||
### [Integrate SonarQube into Pipeline](../devops-user-guide/how-to-integrate/sonarqube/)
|
||||
|
|
@ -0,0 +1,177 @@
|
|||
---
|
||||
title: "How to build and deploy a maven project"
|
||||
keywords: 'kubernetes, docker, devops, jenkins, maven'
|
||||
description: ''
|
||||
linkTitle: "Build And Deploy A Maven Project"
|
||||
weight: 200
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to [enable KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to create [DockerHub](http://www.dockerhub.com/) account.
|
||||
- You need to create a workspace, a DevOps project, and a user account, and this account needs to be invited into the DevOps project as the role of maintainer.
|
||||
|
||||
## Workflow for Maven Project
|
||||
|
||||

|
||||
|
||||
As is shown in the graph, there is the workflow for a maven project in KubeSphere DevOps.
|
||||
|
||||
It uses the pipeline of Jenkins to build and deploy the maven project in KubeSphere DevOps. All steps are defined in the pipeline.
|
||||
|
||||
When running, Jenkins Master create the pod to run the pipeline. Kubernetes creates the pod as the agent of Jenkins Master and will be destoryed after pipeline finished. The main process is to clone code, build & push image, and deploy the workload.
|
||||
|
||||
## Default Configurations in Jenkins
|
||||
|
||||
### Maven Version
|
||||
|
||||
Executing the following command in the maven builder container to get version info.
|
||||
|
||||
```bash
|
||||
mvn --version
|
||||
|
||||
Apache Maven 3.5.3 (3383c37e1f9e9b3bc3df5050c29c8aff9f295297; 2018-02-24T19:49:05Z)
|
||||
Maven home: /opt/apache-maven-3.5.3
|
||||
Java version: 1.8.0_232, vendor: Oracle Corporation
|
||||
Java home: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.i386/jre
|
||||
Default locale: en_US, platform encoding: UTF-8
|
||||
```
|
||||
|
||||
### Maven Cache
|
||||
|
||||
Jenkins Agent mounts the directories by Docker Volume on the node. So, the pipeline can cache some spicial directory, such as `/root/.m2`, which is used for the maven building.
|
||||
|
||||
`/root/.m2` is the default cache directory for maven tools in KubeSphere DevOps. The dependency packages are e downloaded and cached and there won't be network request if it's used next time.
|
||||
|
||||
### Global Maven Setting in Jenkins Agent
|
||||
|
||||
The default maven settings file path is maven and the configuration file path is `/opt/apache-maven-3.5.3/conf/settings.xml` .
|
||||
|
||||
Executing the following command to get the content of Maven Setting.
|
||||
|
||||
```bash
|
||||
kubectl get cm -n kubesphere-devops-system ks-devops-agent -o yaml
|
||||
```
|
||||
|
||||
### Network of Maven Pod
|
||||
|
||||
The Pod labeled maven uses the docker-in-docker network to run the pipeline. That is, the `/var/run/docker.sock` in the node is mounted into the maven container.
|
||||
|
||||
## An example of a maven pipeline
|
||||
|
||||
### Prepare for the Maven Project
|
||||
|
||||
- ensure build the maven project successfully on the development device.
|
||||
- add the Dockerfile file into the project repo for building the image, refer to https://github.com/kubesphere/devops-java-sample/blob/master/Dockerfile-online
|
||||
- add the yaml file into the project repo for deploy the workload, refer to https://github.com/kubesphere/devops-java-sample/tree/master/deploy/dev-ol. If there are different environments, you need to prepare multiple deployment files.
|
||||
|
||||
### Create the Credentials
|
||||
|
||||
- dockerhub-id. A *Account Credentials* for registry, e.g DockerHub.
|
||||
- demo-kuebconfig. A *Kubeconfig Credential* for deploying workloads.
|
||||
|
||||
For details, please refer to the [Credentials Management](../../how-to-use/credential-management/).
|
||||
|
||||

|
||||
|
||||
### Create the Project for Workloads
|
||||
|
||||
In this demo, all of workload are deployed under kubesphere-sample-dev. So, you need to create namespaces `kubesphere-sample-dev` in advance.
|
||||
|
||||

|
||||
|
||||
### Create the Pipeline for the Maven Project
|
||||
|
||||
At First, create a *DevOps Project* and a *Pipeline* refer to [Create a Pipeline - using Graphical Editing Panel](../../how-to-use/create-a-pipeline-using-graphical-editing-panel) .
|
||||
|
||||
Secondly, click *Edit Jenkinsfile* button under your pipeline.
|
||||
|
||||

|
||||
|
||||
Paste the following text into the pop-up window and save it.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
}
|
||||
}
|
||||
|
||||
parameters {
|
||||
string(name:'TAG_NAME',defaultValue: '',description:'')
|
||||
}
|
||||
|
||||
environment {
|
||||
DOCKER_CREDENTIAL_ID = 'dockerhub-id'
|
||||
KUBECONFIG_CREDENTIAL_ID = 'demo-kubeconfig'
|
||||
REGISTRY = 'docker.io'
|
||||
// need to replace by yourself dockerhub namespace
|
||||
DOCKERHUB_NAMESPACE = 'shaowenchen'
|
||||
APP_NAME = 'devops-java-sample'
|
||||
BRANCH_NAME = 'dev'
|
||||
}
|
||||
|
||||
stages {
|
||||
stage ('checkout scm') {
|
||||
steps {
|
||||
git branch: 'master', url: "https://github.com/kubesphere/devops-java-sample.git"
|
||||
}
|
||||
}
|
||||
|
||||
stage ('unit test') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'mvn clean -o -gs `pwd`/configuration/settings.xml test'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
stage ('build & push') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'mvn -o -Dmaven.test.skip=true -gs `pwd`/configuration/settings.xml clean package'
|
||||
sh 'docker build -f Dockerfile-online -t $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER .'
|
||||
withCredentials([usernamePassword(passwordVariable : 'DOCKER_PASSWORD' ,usernameVariable : 'DOCKER_USERNAME' ,credentialsId : "$DOCKER_CREDENTIAL_ID" ,)]) {
|
||||
sh 'echo "$DOCKER_PASSWORD" | docker login $REGISTRY -u "$DOCKER_USERNAME" --password-stdin'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_NAMESPACE/$APP_NAME:SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
stage('deploy to dev') {
|
||||
steps {
|
||||
kubernetesDeploy(configs: 'deploy/dev-ol/**', enableConfigSubstitution: true, kubeconfigId: "$KUBECONFIG_CREDENTIAL_ID")
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
After saving, you will get this.
|
||||
|
||||

|
||||
|
||||
### Run and test
|
||||
|
||||
Click `run` and type `TAG_NAME` to run the pipeline.
|
||||
|
||||

|
||||
|
||||
After the run is complete, you can see the following figure.
|
||||
|
||||

|
||||
|
||||
Under the project of `kubesphere-sample-dev`, there are new workloads created.
|
||||
|
||||

|
||||
|
||||
You can view the access address of the service through service.
|
||||
|
||||

|
||||
|
||||
## Summary
|
||||
|
||||
This document is not a getting started document. It introduces some configurations for building maven projects on the KubeSphere DevOps Platform. At the same time, a example flow of the maven project is provided. In your case, you are free to add new steps to improve the pipeline.
|
||||
|
|
@ -0,0 +1,160 @@
|
|||
---
|
||||
title: "Build and Deploy a Go Project"
|
||||
keywords: 'Kubernetes, docker, devops, jenkins, go, KubeSphere'
|
||||
description: 'This tutorial demonstrates how to build and deploy a Go project.'
|
||||
linkTitle: "Build and Deploy a Go Project"
|
||||
weight: 200
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to [enable KubeSphere DevOps System](../../../../docs/pluggable-components/devops/).
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account.
|
||||
- You need to create a workspace, a DevOps project, a project, and an account (`project-regular`). This account needs to be invited to the DevOps project and the project with the role `operator`. For more information, see [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project).
|
||||
|
||||
## Create Docker Hub Access Token
|
||||
|
||||
1. Sign in [Docker Hub](https://hub.docker.com/) and select **Account Settings** from the menu in the top right corner.
|
||||
|
||||

|
||||
|
||||
2. Click **Security** and **New Access Token**.
|
||||
|
||||

|
||||
|
||||
3. Enter the token name and click **Create**.
|
||||
|
||||

|
||||
|
||||
4. Click **Copy and Close** and remember to save the access token.
|
||||
|
||||

|
||||
|
||||
## Create Credentials
|
||||
|
||||
You need to create credentials in KubeSphere for the access token created so that the pipeline can interact with Docker Hub for imaging pushing. Besides, you also create kubeconfig credentials for the access to the Kubernetes cluster.
|
||||
|
||||
1. Log in the web console of KubeSphere as `project-regular`. Go to your DevOps project and click **Create** in **Credentials**.
|
||||
|
||||

|
||||
|
||||
2. In the dialogue that appears, set a **Credential ID**, which will be used later in the Jenkinsfile, and select **Account Credentials** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Token/Password**. When you finish, click **OK**.
|
||||
|
||||

|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Click **Create** again and select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current user account. Set a **Credential ID** and click **OK**.
|
||||
|
||||

|
||||
|
||||
## Create a Pipeline
|
||||
|
||||
With the above credentials ready, you can create a pipeline using an example Jenkinsfile as below.
|
||||
|
||||
1. To create a pipeline, click **Create** on the **Pipelines** page.
|
||||
|
||||

|
||||
|
||||
2. Set a name in the pop-up window and click **Next** directly.
|
||||
|
||||

|
||||
|
||||
3. In this tutorial, you can use default values for all the fields. In **Advanced Settings**, click **Create** directly.
|
||||
|
||||

|
||||
|
||||
## Edit Jenkinsfile
|
||||
|
||||
1. In the pipeline list, click this pipeline to go to its detail page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
|
||||

|
||||
|
||||
2. Copy and paste all the content below to the pop-up window as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, and `PROJECT_NAME` with yours. When you finish, click **OK**.
|
||||
|
||||
```groovy
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
}
|
||||
}
|
||||
|
||||
environment {
|
||||
// the address of your harbor registry
|
||||
REGISTRY = 'docker.io'
|
||||
// your docker hub username
|
||||
DOCKERHUB_USERNAME = 'yuswift'
|
||||
// docker image name
|
||||
APP_NAME = 'devops-go-sample'
|
||||
// ‘dockerhubid’ is the credential id you created in KubeSphere for docker access token
|
||||
DOCKERHUB_CREDENTIAL = credentials('dockerhubid')
|
||||
//the kubeconfig credential id you created in KubeSphere
|
||||
KUBECONFIG_CREDENTIAL_ID = 'go'
|
||||
// the name of the project you created in KubeSphere, not the DevOps project name
|
||||
PROJECT_NAME = 'devops-go'
|
||||
}
|
||||
|
||||
stages {
|
||||
stage('docker login') {
|
||||
steps{
|
||||
container ('maven') {
|
||||
sh 'echo $DOCKERHUB_CREDENTIAL_PSW | docker login -u $DOCKERHUB_CREDENTIAL_USR --password-stdin'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
stage('build & push') {
|
||||
steps {
|
||||
container ('maven') {
|
||||
sh 'git clone https://github.com/yuswift/devops-go-sample.git'
|
||||
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
|
||||
}
|
||||
}
|
||||
}
|
||||
stage ('deploy app') {
|
||||
steps {
|
||||
container('maven') {
|
||||
kubernetesDeploy(configs: 'devops-go-sample/manifest/deploy.yaml', kubeconfigId: "$KUBECONFIG_CREDENTIAL_ID")
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If your pipeline runs successfully, images will be pushed to Docker Hub. If you are using Harbor, you cannot pass the parameter to `docker login -u` via the Jenkins credential with environment variables. This is because every Harbor robot account username contains a `$` character, which will be converted to `$$` by Jenkins when used by environment variables. [Learn more](https://number1.co.za/rancher-cannot-use-harbor-robot-account-imagepullbackoff-pull-access-denied/).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
## Run Pipeline
|
||||
|
||||
1. After you finish the Jenkinsfile, you can see graphical panels display on the dashboard. Click **Run** to run the pipeline.
|
||||
|
||||

|
||||
|
||||
2. In **Activity**, you can see the status of the pipeline. It may take a while before it successfully runs.
|
||||
|
||||

|
||||
|
||||
|
||||
## Verify Results
|
||||
|
||||
1. A **Deployment** will be created in the project specified in the Jenkinsfile if the pipeline runs successfully.
|
||||
|
||||

|
||||
|
||||
2. Check whether the image is pushed to Docker Hub as shown below:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
|
@ -0,0 +1,155 @@
|
|||
---
|
||||
title: "Deploy Apps in a Multi-cluster Project Using Jenkinsfile"
|
||||
keywords: 'Kubernetes, KubeSphere, docker, devops, jenkins, multi-cluster'
|
||||
description: 'This tutorial demonstrates how to deploy apps in a multi-cluster project using a Jenkinsfile.'
|
||||
linkTitle: "Deploy Apps in a Multi-cluster Project Using Jenkinsfile"
|
||||
weight: 300
|
||||
---
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to [enable the multi-cluster feature](../../../../docs/multicluster-management/).
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account.
|
||||
- You need to [enable KubeSphere DevOps System](../../../../docs/pluggable-components/devops/) on your host cluster.
|
||||
- You need to create a workspace with multiple clusters, a DevOps project on your **host** cluster, a multi-cluster project (in this tutorial, this multi-cluster project is created on the host cluster and one member cluster), and an account (`project-regular`). This account needs to be invited to the DevOps project and the multi-cluster project with the role `operator`. For more information, see [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project), [Multi-cluster Management](../../../multicluster-management) and [Multi-cluster Projects](../../../project-administration/project-and-multicluster-project/#multi-cluster-projects).
|
||||
|
||||
## Create Docker Hub Access Token
|
||||
|
||||
1. Sign in [Docker Hub](https://hub.docker.com/) and select **Account Settings** from the menu in the top right corner.
|
||||
|
||||

|
||||
|
||||
2. Click **Security** and **New Access Token**.
|
||||
|
||||

|
||||
|
||||
3. Enter the token name and click **Create**.
|
||||
|
||||

|
||||
|
||||
4. Click **Copy and Close** and remember to save the access token.
|
||||
|
||||

|
||||
|
||||
## Create Credentials
|
||||
|
||||
You need to create credentials in KubeSphere for the access token created so that the pipeline can interact with Docker Hub for imaging pushing. Besides, you also need to create kubeconfig credentials for the access to the Kubernetes cluster.
|
||||
|
||||
1. Log in the web console of KubeSphere as `project-regular`. Go to your DevOps project and click **Create** in **Credentials**.
|
||||
|
||||

|
||||
|
||||
2. In the dialogue that appears, set a **Credential ID**, which will be used later in the Jenkinsfile, and select **Account Credentials** for **Type**. Enter your Docker Hub account name for **Username** and the access token just created for **Token/Password**. When you finish, click **OK**.
|
||||
|
||||

|
||||
|
||||
{{< notice tip >}}
|
||||
|
||||
For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Click **Create** again and select **kubeconfig** for **Type**. Note that KubeSphere automatically populates the **Content** field, which is the kubeconfig of the current user account. Set a **Credential ID** and click **OK**.
|
||||
|
||||

|
||||
|
||||
## Create a Pipeline
|
||||
|
||||
With the above credentials ready, you can create a pipeline using an example Jenkinsfile as below.
|
||||
|
||||
1. To create a pipeline, click **Create** on the **Pipelines** page.
|
||||
|
||||

|
||||
|
||||
2. Set a name in the pop-up window and click **Next** directly.
|
||||
|
||||

|
||||
|
||||
3. In this tutorial, you can use default values for all the fields. In **Advanced Settings**, click **Create** directly.
|
||||
|
||||

|
||||
|
||||
## Edit Jenkinsfile
|
||||
|
||||
1. In the pipeline list, click this pipeline to go to its detail page. Click **Edit Jenkinsfile** to define a Jenkinsfile and your pipeline runs based on it.
|
||||
|
||||

|
||||
|
||||
2. Copy and paste all the content below to the pop-up window as an example Jenkinsfile for your pipeline. You must replace the value of `DOCKERHUB_USERNAME`, `DOCKERHUB_CREDENTIAL`, `KUBECONFIG_CREDENTIAL_ID`, `MULTI_CLUSTER_PROJECT_NAME`, and `MEMBER_CLUSTER_NAME` with yours. When you finish, click **OK**.
|
||||
|
||||
```
|
||||
pipeline {
|
||||
agent {
|
||||
node {
|
||||
label 'maven'
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
environment {
|
||||
REGISTRY = 'docker.io'
|
||||
// username of dockerhub
|
||||
DOCKERHUB_USERNAME = 'yuswift'
|
||||
APP_NAME = 'devops-go-sample'
|
||||
// ‘dockerhubid’ is the dockerhub credential id you created on ks console
|
||||
DOCKERHUB_CREDENTIAL = credentials('dockerhubid')
|
||||
// the kubeconfig credential id you created on ks console
|
||||
KUBECONFIG_CREDENTIAL_ID = 'multi-cluster'
|
||||
// mutli-cluster project name under your own workspace
|
||||
MULTI_CLUSTER_PROJECT_NAME = 'devops-with-go'
|
||||
// the member cluster name you want to deploy app on
|
||||
// in this tutorial, you are assumed to deploy app on host and only one member cluster
|
||||
// for more member clusters, please edit manifest/multi-cluster-deploy.yaml
|
||||
MEMBER_CLUSTER_NAME = 'c9'
|
||||
}
|
||||
|
||||
stages {
|
||||
stage('docker login') {
|
||||
steps {
|
||||
container('maven') {
|
||||
sh 'echo $DOCKERHUB_CREDENTIAL_PSW | docker login -u $DOCKERHUB_CREDENTIAL_USR --password-stdin'
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
stage('build & push') {
|
||||
steps {
|
||||
container('maven') {
|
||||
sh 'git clone https://github.com/yuswift/devops-go-sample.git'
|
||||
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
|
||||
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
stage('deploy app to multi cluster') {
|
||||
steps {
|
||||
container('maven') {
|
||||
script {
|
||||
withCredentials([
|
||||
kubeconfigFile(
|
||||
credentialsId: 'multi-cluster',
|
||||
variable: 'KUBECONFIG')
|
||||
]) {
|
||||
sh 'envsubst < devops-go-sample/manifest/multi-cluster-deploy.yaml | kubectl apply -f -'
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If your pipeline runs successfully, images will be pushed to Docker Hub. If you are using Harbor, you cannot pass the parameter to `docker login -u` via the Jenkins credential with environment variables. This is because every Harbor robot account username contains a `$` character, which will be converted to `$$` by Jenkins when used by environment variables. [Learn more](https://number1.co.za/rancher-cannot-use-harbor-robot-account-imagepullbackoff-pull-access-denied/).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
## Run Pipeline
|
||||
|
||||
After you save the Jenkinsfile, click **Run**. If everything goes well, you will see the Deployment workload in your multi-cluster project.
|
||||
|
||||

|
||||
|
|
@ -225,7 +225,7 @@ kubectl -n kubesphere-system rollout restart deploy ks-apiserver
|
|||
kubectl -n kubesphere-system rollout restart deploy ks-console
|
||||
```
|
||||
|
||||
## Create SonarQube Token for New Projetct
|
||||
## Create SonarQube Token for New Project
|
||||
|
||||
You need a SonarQube token so that your pipeline can communicate with SonarQube as it runs.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,217 +1,231 @@
|
|||
---
|
||||
title: "Create a pipeline using jenkinsfile"
|
||||
keywords: 'kubesphere, kubernetes, docker, spring boot, jenkins, devops, ci/cd, pipeline'
|
||||
description: "Create a pipeline using jenkinsfile"
|
||||
linkTitle: "Create a pipeline using jenkinsfile"
|
||||
title: "Create a Pipeline Using a Jenkinsfile"
|
||||
keywords: 'KubeSphere, Kubernetes, docker, spring boot, Jenkins, devops, ci/cd, pipeline'
|
||||
description: "How to create a pipeline using a Jenkinsfile."
|
||||
linkTitle: "Create a Pipeline Using a Jenkinsfile"
|
||||
weight: 200
|
||||
---
|
||||
|
||||
## Objective
|
||||
A Jenkinsfile is a text file that contains the definition of a Jenkins pipeline and is checked into source control. As it stores the entire workflow as code, it underpins the code review and iteration process of a pipeline. For more information, see [the official documentation of Jenkins](https://www.jenkins.io/doc/book/pipeline/jenkinsfile/).
|
||||
|
||||
In this tutorial, we will show you how to create a pipeline based on the Jenkinsfile from a GitHub repository. Using the pipeline, we will deploy a demo application to a development environment and a production environment respectively. Meanwhile, we will demo a branch that is used to test dependency caching capability. In this demo, it takes a relatively long time to finish the pipeline for the first time. However, it runs very faster since then. It proves the cache works well since this branch pulls lots of dependency from internet initially.
|
||||
This tutorial demonstrates how to create a pipeline based on a Jenkinsfile from a GitHub repository. Using the pipeline, you deploy an example application to a development environment and a production environment respectively, which is accessible externally.
|
||||
|
||||
> Note:
|
||||
> KubeSphere supports two kinds of pipeline, i.e., Jenkinsfile in SCM which is introduced in this document and [Create a Pipeline - using Graphical Editing Panel](../create-a-pipeline-using-graphical-editing-panel). Jenkinsfile in SCM requires an internal Jenkinsfile in Source Control Management (SCM). In another word, Jenkfinsfile serves as a part of SCM. KubeSphere DevOps system will automatically build a CI/CD pipeline depending on existing Jenkinsfile of the code repository. You can define workflow like Stage, Step and Job in the pipeline.
|
||||
{{< notice note >}}
|
||||
|
||||
Two types of pipelines can be created in KubeSphere: Pipelines created based on a Jenkinsfile in SCM, which is introduced in this tutorial, and [pipelines created through the graphical editing panel](../create-a-pipeline-using-graphical-editing-panel). The Jenkinsfile in SCM requires an internal Jenkinsfile in Source Control Management (SCM). In other words, the Jenkfinsfile serves as part of SCM. The KubeSphere DevOps system automatically builds a CI/CD pipeline based on the existing Jenkinsfile of the code repository. You can define workflows such as `stage` and `step`.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to have a DokcerHub account and a GitHub account.
|
||||
- You need to create a workspace, a DevOps project, and a **project-regular** user account, and this account needs to be invited into a DevOps project.
|
||||
- Set CI dedicated node for building pipeline, please refer to [Set CI Node for Dependency Cache](../../how-to-use/set-ci-node/).
|
||||
- You need to install and configure sonarqube, please refer to [How to integrate SonarQube in Pipeline
|
||||
](../../../how-to-integrate/sonarqube/) . Or you can skip this part, There is no **Sonarqube Analysis** below.
|
||||
- You need to have a [Docker Hub](https://hub.docker.com/) account and a [GitHub](https://github.com/) account.
|
||||
- You need to [enable KubeSphere DevOps system](../../../pluggable-components/devops/).
|
||||
- You need to create a workspace, a DevOps project, and an account (`project-regular`). This account needs to be invited to the DevOps project with the `operator` role. See [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project/) if they are not ready.
|
||||
- You need to set a CI dedicated node for running pipelines. Refer to [Set CI Node for Dependency Cache](../../how-to-use/set-ci-node/).
|
||||
- You need to install and configure SonarQube. Refer to [Integrate SonarQube into Pipeline](../../../devops-user-guide/how-to-integrate/sonarqube/). If you skip this part, there is no **SonarQube Analysis** below.
|
||||
|
||||
## Pipeline Overview
|
||||
|
||||
There are eight stages as shown below in the pipeline that is going to demonstrate.
|
||||
There are eight stages as shown below in this example pipeline.
|
||||
|
||||

|
||||
|
||||
> Note:
|
||||
{{< notice note >}}
|
||||
|
||||
> - **Stage 1. Checkout SCM**: Checkout source code from GitHub repository.
|
||||
> - **Stage 2. Unit test**: It will continue to execute next stage after unit test passed.
|
||||
> - **Stage 3. SonarQube analysis**:Process sonarQube code quality analysis.
|
||||
> - **Stage 4.** **Build & push snapshot image**: Build the image based on selected branches in the behavioral strategy. Push the tag of `SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER` to DockerHub, among which, the `$BUILD_NUMBER` is the operation serial number in the pipeline's activity list.
|
||||
> - **Stage 5. Push the latest image**: Tag the sonarqube branch as latest and push it to DockerHub.
|
||||
> - **Stage 6. Deploy to dev**: Deploy sonarqube branch to Dev environment. verification is needed for this stage.
|
||||
> - **Stage 7. Push with tag**: Generate tag and released to GitHub. Then push the tag to DockerHub.
|
||||
> - **Stage 8. Deploy to production**: Deploy the released tag to the Production environment.
|
||||
- **Stage 1. Checkout SCM**: Check out source code from the GitHub repository.
|
||||
- **Stage 2. Unit test**: It will not proceed with the next stage unit the test is passed.
|
||||
- **Stage 3. SonarQube analysis**: The SonarQube code quality analysis.
|
||||
- **Stage 4.** **Build & push snapshot image**: Build the image based on selected branches in **Behavioral strategy**. Push the tag of `SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER` to Docker Hub, the `$BUILD_NUMBER` of which is the operation serial number in the pipeline's activity list.
|
||||
- **Stage 5. Push the latest image**: Tag the sonarqube branch as `latest` and push it to Docker Hub.
|
||||
- **Stage 6. Deploy to dev**: Deploy the sonarqube branch to the development environment. Review is required for this stage.
|
||||
- **Stage 7. Push with tag**: Generate the tag and release it to GitHub. The tag is pushed to Docker Hub.
|
||||
- **Stage 8. Deploy to production**: Deploy the released tag to the production environment.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create Credentials
|
||||
|
||||
> Note: If there are special characters in your account or password, please encode it using https://www.urlencoder.org/, then paste the encoded result into credentials below.
|
||||
1. Log in the KubeSphere console as `project-regular`. Go to your DevOps project and create the following credentials in **Credentials** under **Project Management**. For more information about how to create credentials, see [Credential Management](../../../devops-user-guide/how-to-use/credential-management/).
|
||||
|
||||
1.1. Log in KubeSphere with the account `project-regular`, enter into the created DevOps project and create the following three credentials under **Project Management → Credentials**:
|
||||
{{< notice note >}}
|
||||
|
||||
If there are any special characters such as `@` and `$` in your account or password, they can cause errors as a pipeline runs because they may not be recognized. In this case, you need to encode your account or password on some third-party websites first, such as [urlencoder](https://www.urlencoder.org/). After that, copy and paste the output for your credential information.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|Credential ID| Type | Where to use |
|
||||
| --- | --- | --- |
|
||||
| dockerhub-id | Account Credentials | DockerHub |
|
||||
| dockerhub-id | Account Credentials | Docker Hub |
|
||||
| github-id | Account Credentials | GitHub |
|
||||
| demo-kubeconfig | kubeconfig | Kubernetes |
|
||||
|
||||
1.2. We need to create an additional credential `sonar-token` for SonarQube token, which is used in stage 3 (SonarQube analysis) mentioned above. Refer to [Access SonarQube Console and Create Token](../../how-to-integrate/sonarqube/) to copy the token and paste here. Then press **OK** button.
|
||||
2. You need to create an additional credential ID (`sonar-token`) for SonarQube, which is used in stage 3 (SonarQube analysis) mentioned above. Refer to [Create SonarQube Token for New Project](../../../devops-user-guide/how-to-integrate/sonarqube/#create-sonarqube-token-for-new-project) to use the token for the **secret** field below. Click **OK** to finish.
|
||||
|
||||
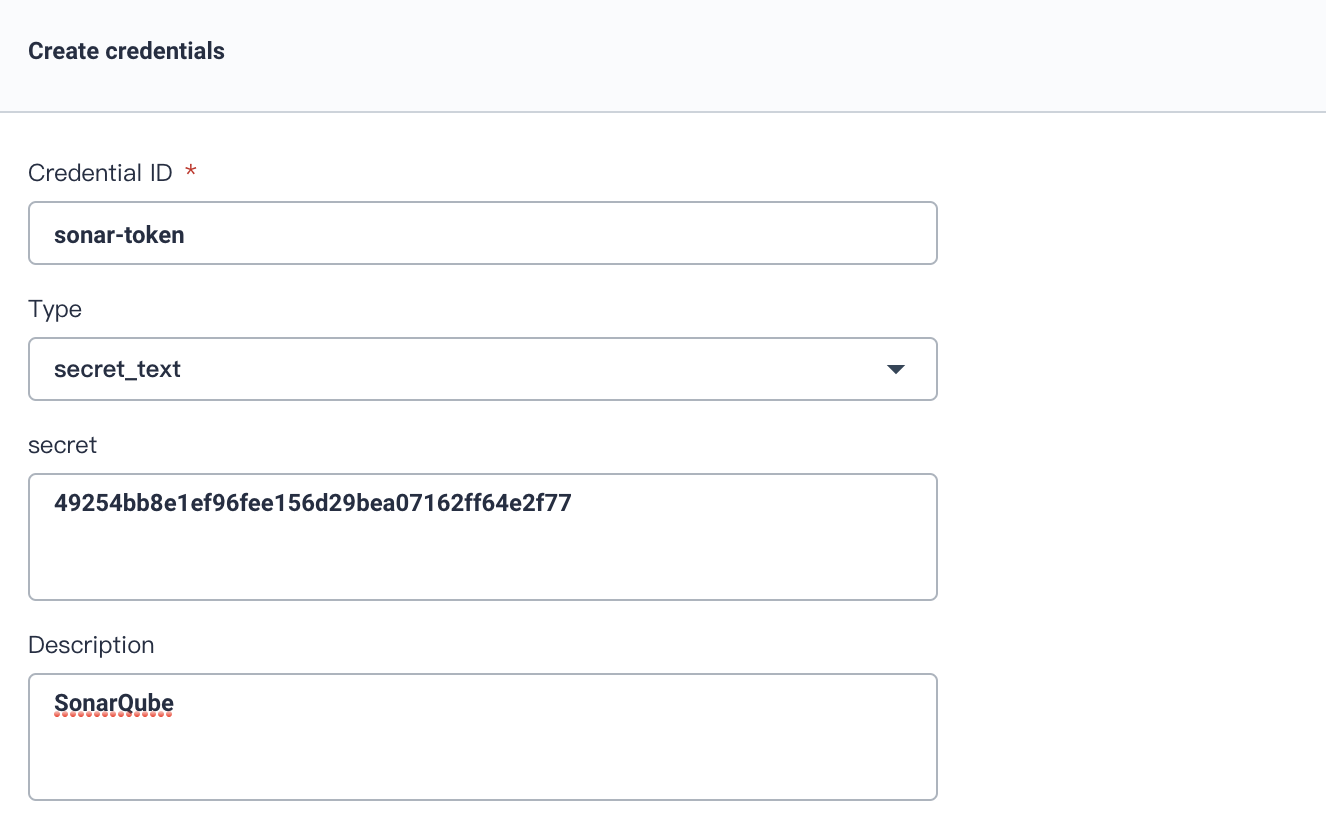
|
||||

|
||||
|
||||
In total, we have created four credentials in this step.
|
||||
3. In total, you have four credentials in the list.
|
||||
|
||||
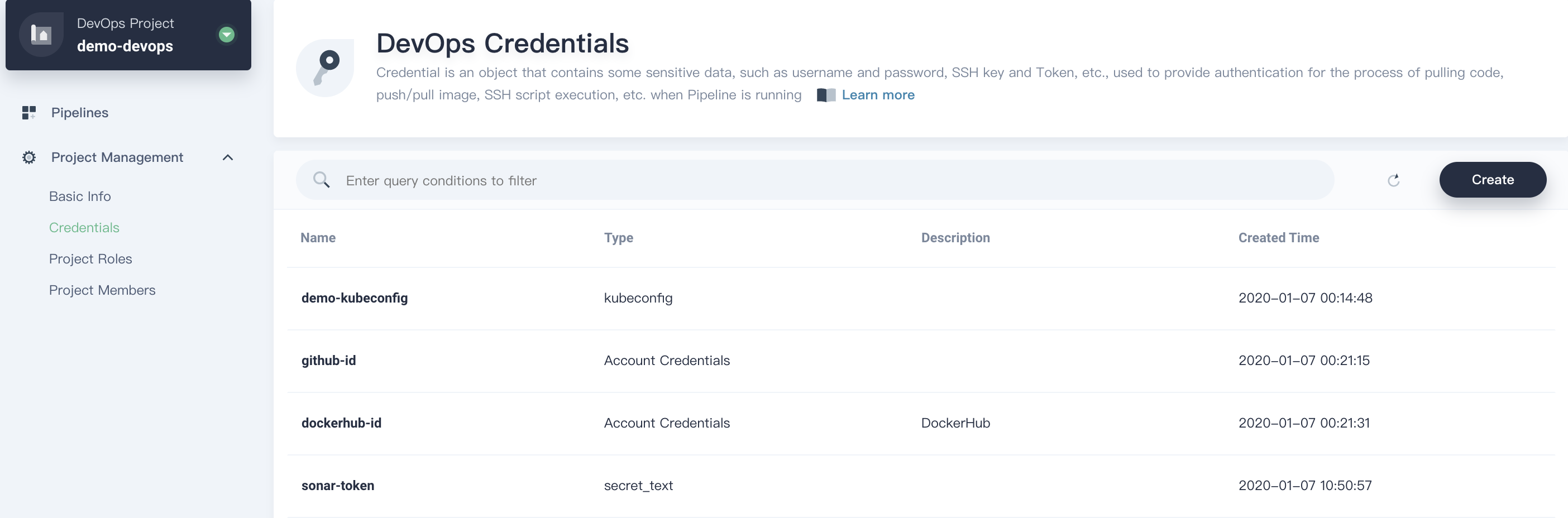
|
||||

|
||||
|
||||
### Step 2: Modify Jenkinsfile in Repository
|
||||
### Step 2: Modify Jenkinsfile in GitHub Repository
|
||||
|
||||
#### Fork Project
|
||||
1. Log in GitHub. Fork [devops-java-sample](https://github.com/kubesphere/devops-java-sample) from the GitHub repository to your own GitHub account.
|
||||
|
||||
Log in GitHub. Fork the [devops-java-sample](https://github.com/kubesphere/devops-java-sample) from GitHub repository to your own GitHub.
|
||||

|
||||
|
||||

|
||||
2. In your own GitHub repository of **devops-java-sample**, click the file `Jenkinsfile-online` in the root directory.
|
||||
|
||||
#### Edit Jenkinsfile
|
||||

|
||||
|
||||
2.1. After forking the repository to your own GitHub, open the file **Jenkinsfile-online** under root directory.
|
||||
3. Click the edit icon on the right to edit environment variables.
|
||||
|
||||

|
||||

|
||||
|
||||
2.2. Click the editing logo in GitHub UI to edit the values of environment variables.
|
||||
|
||||

|
||||
|
||||
| Editing Items | Value | Description |
|
||||
| Items | Value | Description |
|
||||
| :--- | :--- | :--- |
|
||||
| DOCKER\_CREDENTIAL\_ID | dockerhub-id | Fill in DockerHub's credential ID to log in your DockerHub. |
|
||||
| GITHUB\_CREDENTIAL\_ID | github-id | Fill in the GitHub credential ID to push the tag to GitHub repository. |
|
||||
| KUBECONFIG\_CREDENTIAL\_ID | demo-kubeconfig | kubeconfig credential ID is used to access to the running Kubernetes cluster. |
|
||||
| REGISTRY | docker.io | Set the web name of docker.io by default for pushing images. |
|
||||
| DOCKERHUB\_NAMESPACE | your-dockerhub-account | Replace it to your DockerHub's account name. (It can be the Organization name under the account.) |
|
||||
| GITHUB\_ACCOUNT | your-github-account | Change your GitHub account name, such as `https://github.com/kubesphere/`. Fill in `kubesphere` which can also be the account's Organization name. |
|
||||
| APP\_NAME | devops-java-sample | Application name |
|
||||
| SONAR\_CREDENTIAL\_ID | sonar-token | Fill in the SonarQube token credential ID for code quality test. |
|
||||
| DOCKER\_CREDENTIAL\_ID | dockerhub-id | The **Credential ID** you set in KubeSphere for your Docker Hub account. |
|
||||
| GITHUB\_CREDENTIAL\_ID | github-id | The **Credential ID** you set in KubeSphere for your GitHub account. It is used to push tags to your GitHub repository. |
|
||||
| KUBECONFIG\_CREDENTIAL\_ID | demo-kubeconfig | The **Credential ID** you set in KubeSphere for your kubeconfig. It is used to access a running Kubernetes cluster. |
|
||||
| REGISTRY | docker.io | It defaults to `docker.io`, serving as the address of pushing images. |
|
||||
| DOCKERHUB\_NAMESPACE | your-dockerhub-account | Replace it with your Docker Hub's account name. It can be the Organization name under the account. |
|
||||
| GITHUB\_ACCOUNT | your-github-account | Replace it with your GitHub account name. For example, your GitHub account name is `kubesphere` if your GitHub address is `https://github.com/kubesphere/`. It can also be the account's Organization name. |
|
||||
| APP\_NAME | devops-java-sample | The application name. |
|
||||
| SONAR\_CREDENTIAL\_ID | sonar-token | The **Credential ID** you set in KubeSphere for the SonarQube token. It is used for code quality test. |
|
||||
|
||||
**Note: The command parameter `-o` of Jenkinsfile's `mvn` indicates that the offline mode is on. This tutorial has downloaded relevant dependencies to save time and to adapt to network interference in certain environments. The offline mode is on by default.**
|
||||
{{< notice note >}}
|
||||
|
||||
2.3. After editing the environmental variables, click **Commit changes** at the top of GitHub page, then submit the updates to the sonarqube branch.
|
||||
The command parameter `-o` of Jenkinsfile's `mvn` indicates that the offline mode is enabled. Relevant dependencies have already been downloaded in this tutorial to save time and to adapt to network interference in certain environments. The offline mode is on by default.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. After you edit the environmental variables, click **Commit changes** at the bottom of the page, which updates the file in the SonarQube branch.
|
||||
|
||||

|
||||
|
||||
### Step 3: Create Projects
|
||||
|
||||
In this step, we will create two projects, i.e. `kubesphere-sample-dev` and `kubesphere-sample-prod`, which are development environment and production environment respectively.
|
||||
You need to create two projects, such as `kubesphere-sample-dev` and `kubesphere-sample-prod`, which represent the development environment and the production environment respectively. Related Deployments and Services of the app will be created automatically in these two projects once the pipeline runs successfully.
|
||||
|
||||
#### Create The First Project
|
||||
{{< notice note >}}
|
||||
|
||||
> Tip:The account `project-admin` should be created in advance since it is used as the reviewer of the CI/CD Pipeline.
|
||||
The account `project-admin` needs to be created in advance since it is the reviewer of the CI/CD Pipeline. See [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project/) for more information.
|
||||
|
||||
3.1. Use the account `project-admin` to log in KubeSphere. Click **Create** button, then choose **Create a resource project**. Fill in basic information for the project. Click **Next** after complete.
|
||||
{{</ notice >}}
|
||||
|
||||
- Name: `kubesphere-sample-dev`.
|
||||
- Alias: `development environment`.
|
||||
1. Use the account `project-admin` to log in KubeSphere. In the same workspace where you create the DevOps project, create two projects as below. Make sure you invite `project-regular` to these two projects with the role of `operator`.
|
||||
|
||||
| Project Name | Alias |
|
||||
| ---------------------- | ----------------------- |
|
||||
| kubesphere-sample-dev | development environment |
|
||||
| kubesphere-sample-prod | production environment |
|
||||
|
||||
3.2. Leave the default values at Advanced Settings. Click **Create**.
|
||||
2. Check the project list. You have two projects and one DevOps project as below:
|
||||
|
||||
3.3. Now invite `project-regular` user into `kubesphere-sample-dev`. Choose **Project Settings → Project Members**. Click **Invite Member** to invite `project-regular` and grant this account the role of `operator`.
|
||||
|
||||
#### Create the Second Project
|
||||
|
||||
Similarly, create a project named `kubesphere-sample-prod` following the steps above. This project is the production environment. Then invite `project-regular` to the project of `kubesphere-sample-prod`, and grant it the role of `operator` as well.
|
||||
|
||||
> Note: When the CI/CD pipeline succeeded. You will see the demo application's Deployment and Service have been deployed to `kubesphere-sample-dev` and `kubesphere-sample-prod.` respectively.
|
||||
|
||||
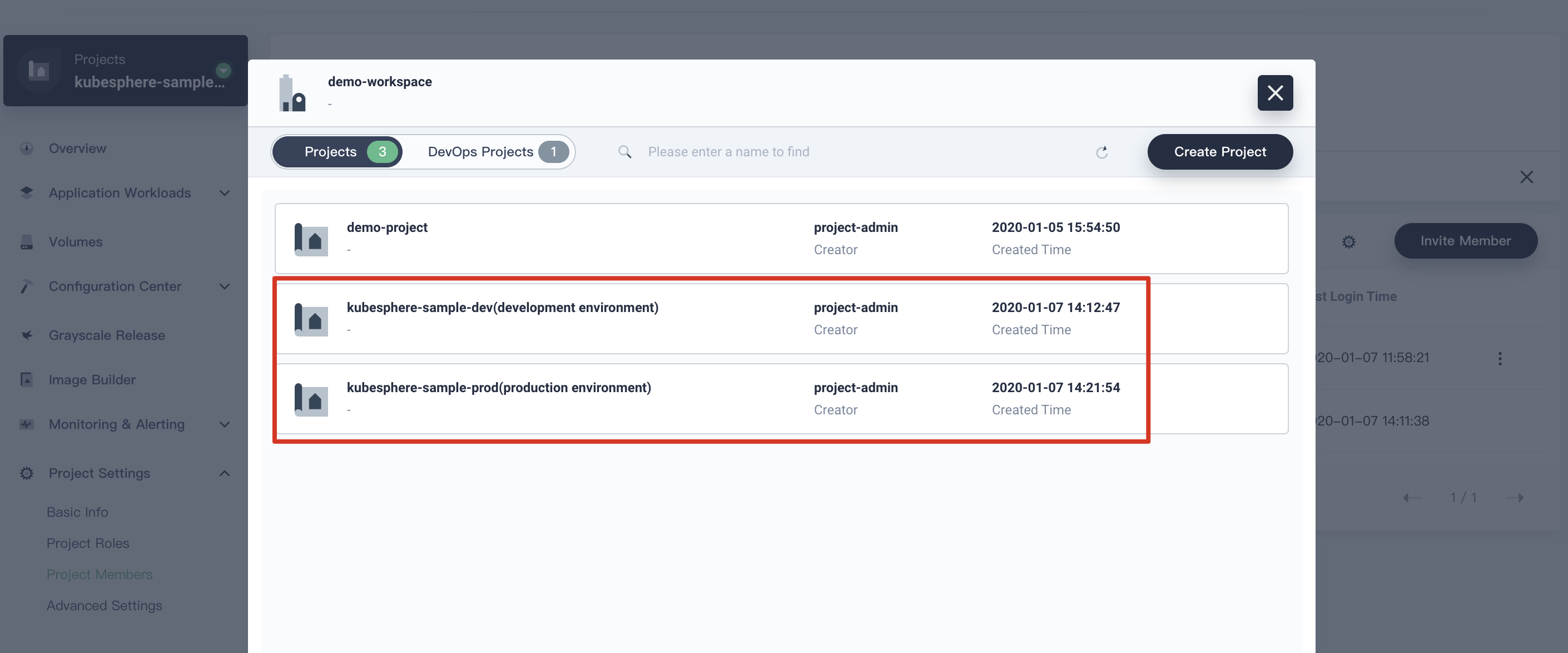
|
||||

|
||||
|
||||
### Step 4: Create a Pipeline
|
||||
|
||||
#### Fill in Basic Information
|
||||
1. Log out of KubeSphere and log back in as `project-regular`. Go to the DevOps project `demo-devops` and click **Create** to build a new pipeline.
|
||||
|
||||
4.1. Switch the login user to `project-regular`. Enter into the DevOps project `demo-devops`. click **Create** to build a new pipeline.
|
||||

|
||||
|
||||
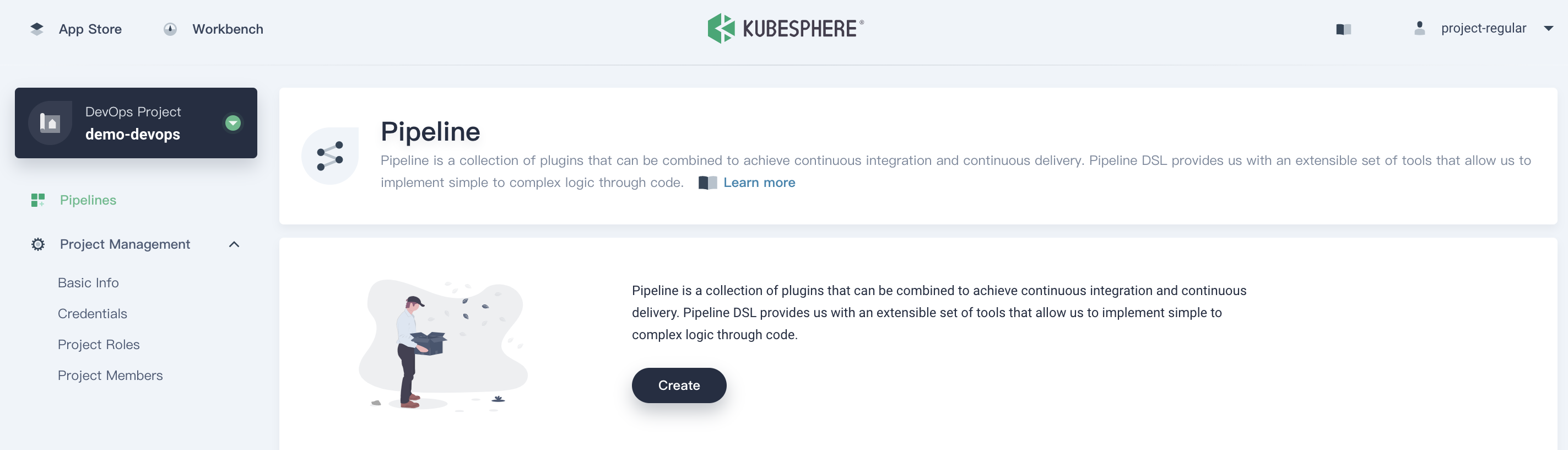
|
||||
2. Provide the basic information in the dialogue that appears. Name it `jenkinsfile-in-scm` and select a code repository.
|
||||
|
||||
4.2. Fill in the pipeline's basic information in the pop-up window, name it `jenkinsfile-in-scm`, click **Code Repository**.
|
||||

|
||||
|
||||
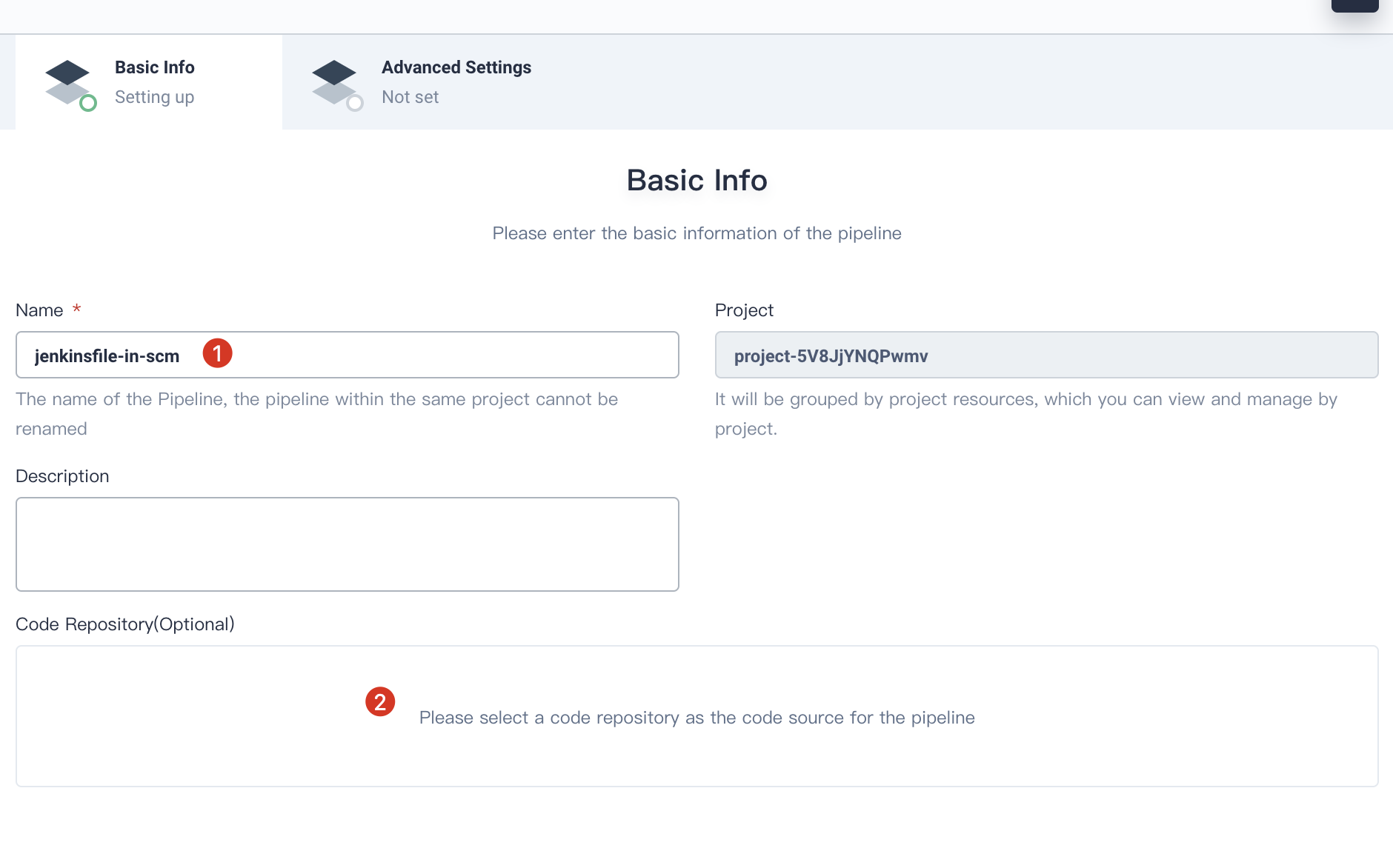
|
||||
3. In the tab **GitHub**, click **Get Token** to generate a new GitHub token if you do not have one. Paste the token to the box and click **Confirm**.
|
||||
|
||||
#### Add Repository
|
||||

|
||||
|
||||
4.3. Click **Get Token** to generate a new GitHub token if you do not have one. Then paste the token to the edit box.
|
||||

|
||||
|
||||
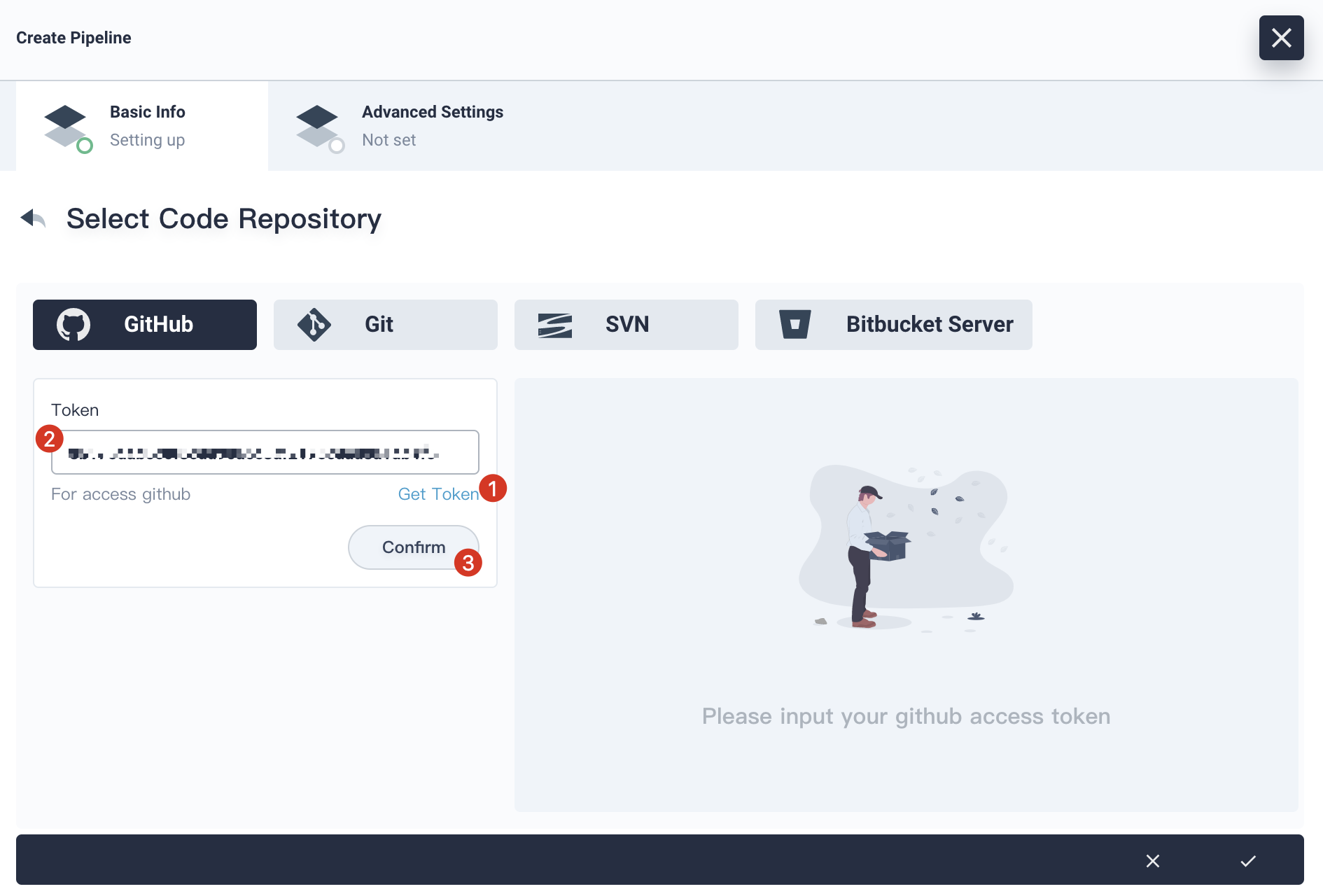
|
||||
4. Choose your GitHub account. All the repositories related to this token will be listed on the right. Select **devops-java-sample** and click **Select this repo**. Click **Next** to continue.
|
||||
|
||||
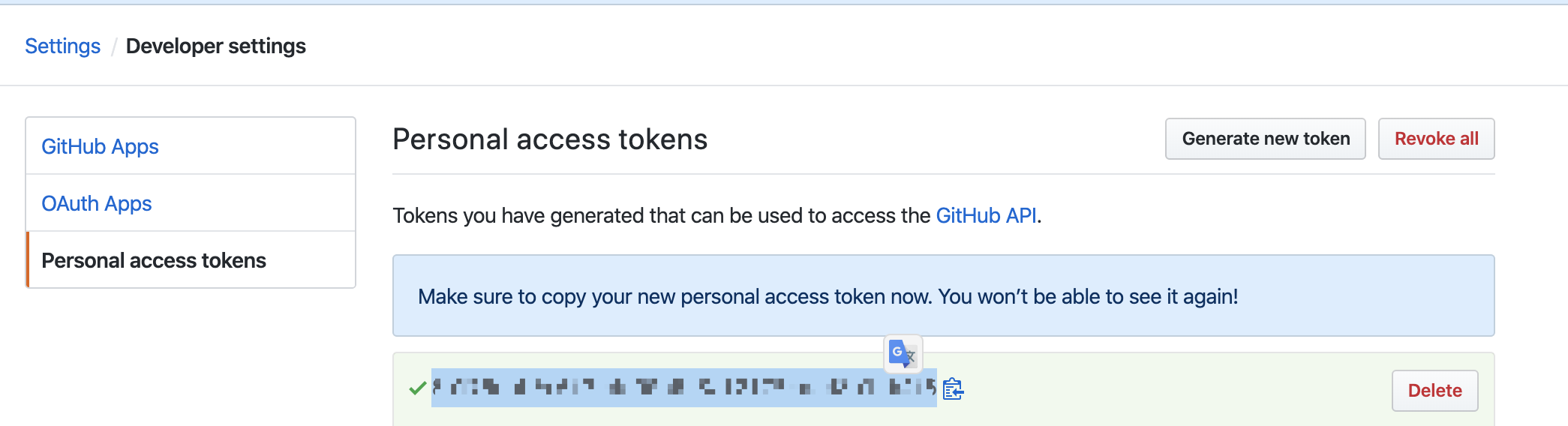
|
||||

|
||||
|
||||
4.4. Click **Confirm**, choose your account. All the code repositories related to this token will be listed on the right. Select **devops-java-sample** and click **Select this repo**, then click **Next**.
|
||||
5. In **Advanced Settings**, check the box next to **Discard old branch**. In this tutorial, you can use the default value of **Days to keep old branches** and **Maximum number branches to keep**.
|
||||
|
||||
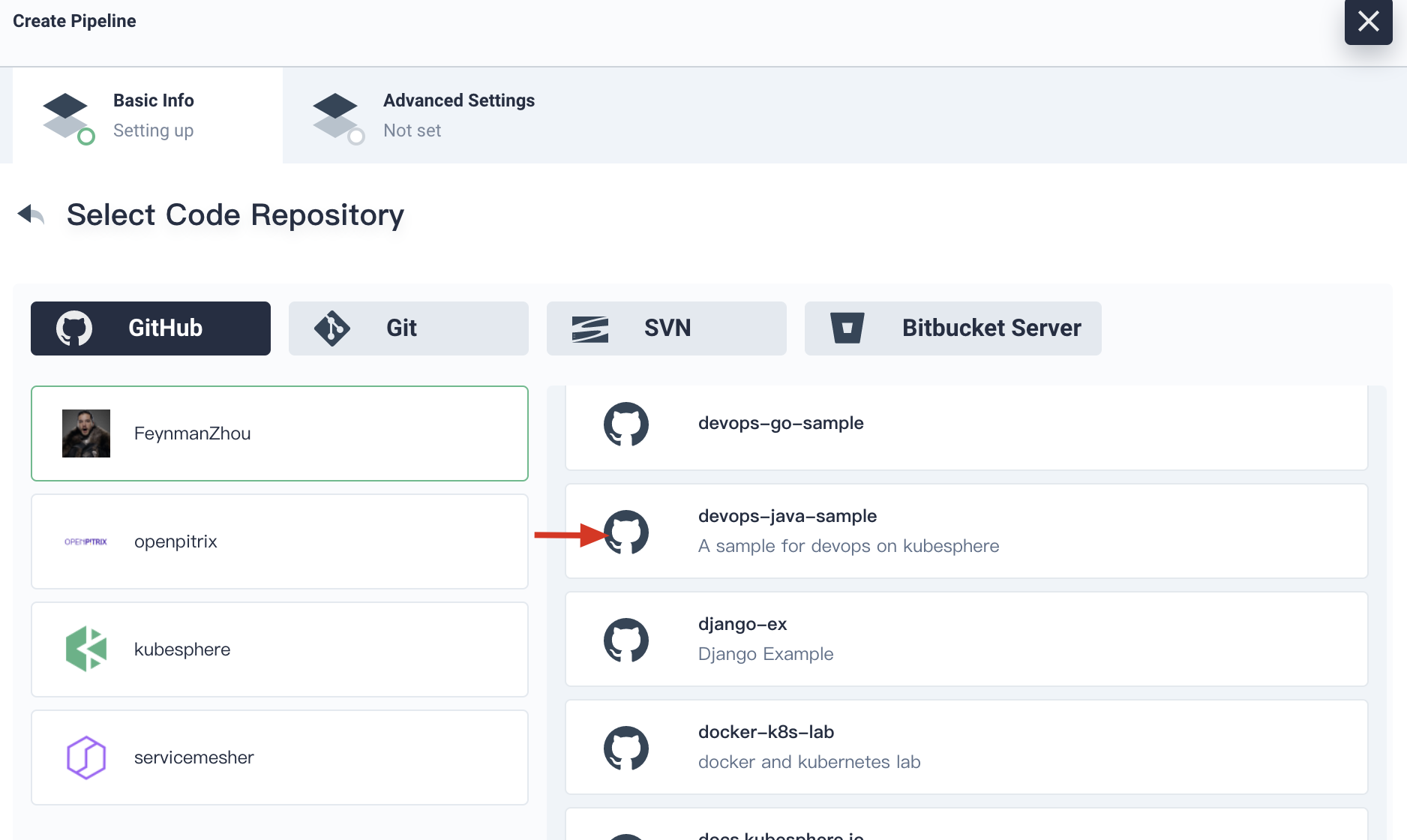
|
||||

|
||||
|
||||
#### Advanced Settings
|
||||
Discarding old branches means that you will discard the branch record all together. The branch record includes console output, archived artifacts and other relevant metadata of specific branches. Fewer branches mean that you can save the disk space that Jenkins is using. KubeSphere provides two options to determine when old branches are discarded:
|
||||
|
||||
Now we are on the advanced setting page.
|
||||
- **Days to keep old branches**. Branches will be discarded after a certain number of days.
|
||||
- **Maximum number of branches to keep**. The oldest branches will be discarded after branches reach a certain amount.
|
||||
|
||||
<!--
|
||||
> Note:
|
||||
> The branches can be controlled by both of the preservation days and the branch number. If the branch has expired the preservation dates or exceeded the limitation number, the branch should be discarded. For example, if the preservation day is 2 and the branch number is 3, any branches that do not meet the requirements should be discarded. Set both of the limitation to -1 by default means not to delete branched automatically.
|
||||
>
|
||||
> Discarding old branches means that you will discard the branch record all together. The branch record includes console output, archive artifacts and other relevant data. Keeping less branches saves Jenkins' disk space. We provide two options to determine when to discard old branches:
|
||||
>
|
||||
> - Days for preserving the branches: If branch reaches the days, it must be discarded.
|
||||
> - Number of branches: If there is a significant number of branches, the oldest branches should be discarded. -->
|
||||
{{< notice note >}}
|
||||
|
||||
4.5. In the behavioral strategy, KubeSphere pipeline has set three strategies by default. Since this demo has not applied the strategy of **Discover PR from Forks,**, this strategy can be deleted.
|
||||
**Days to keep old branches** and **Maximum number of branches to keep** apply to branches at the same time. As long as a branch meets the condition of either field, it will be discarded. For example, if you specify 2 as the number of retention days and 3 as the maximum number of branches, any branches that exceed either number will be discarded. KubeSphere repopulates these two fields with -1 by default, which means deleted branches will be discarded.
|
||||
|
||||
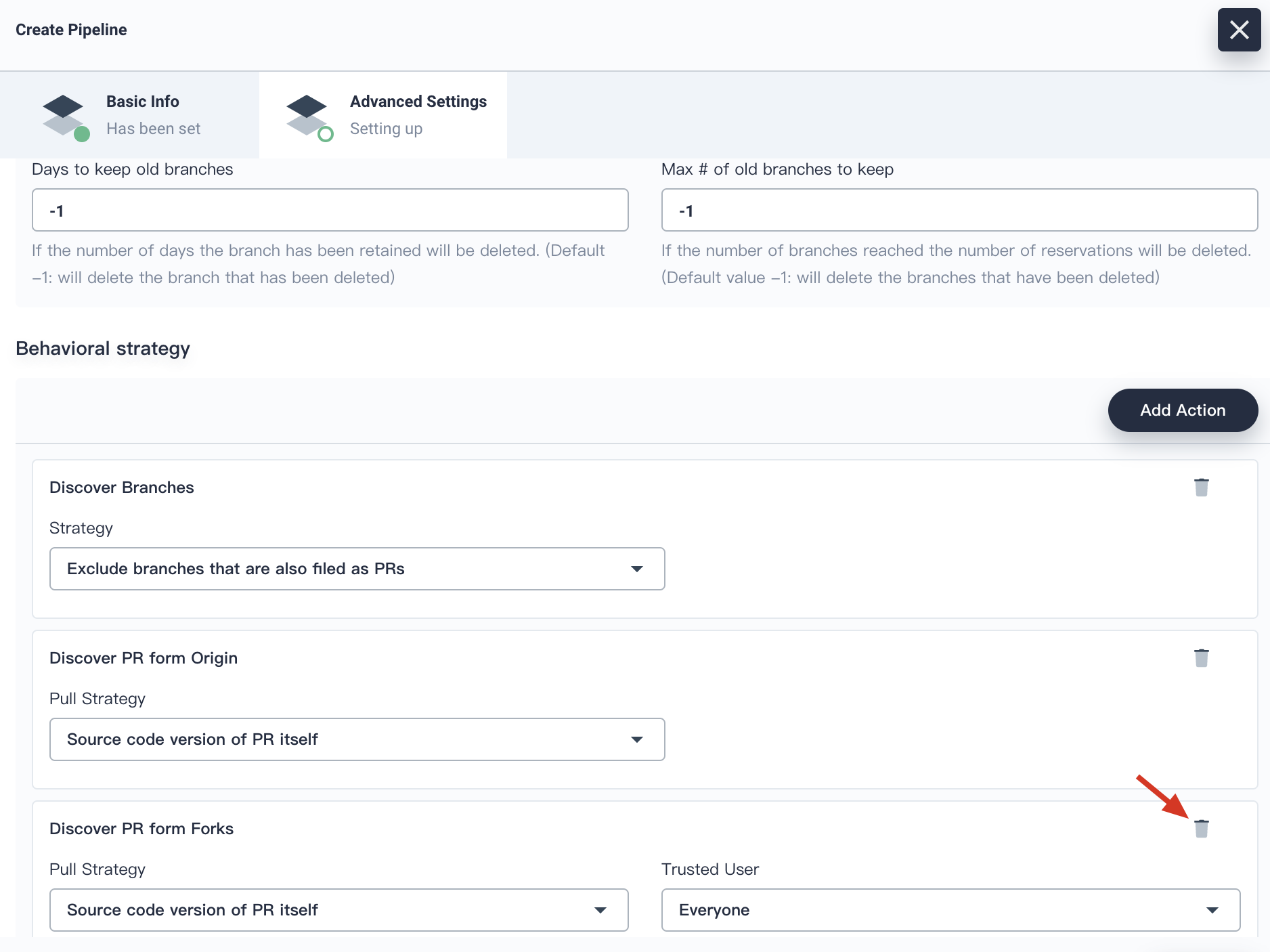
|
||||
{{</ notice >}}
|
||||
|
||||
<!-- > Note:
|
||||
> There types of discovering strategies are supported. When the Jenkins pipeline is activated, the Pull Request (PR) submitted by the developer will also be regarded as a separate branch.
|
||||
> Discover the branch:
|
||||
> - Exclude the branch as PR: Select this option means that CI will not scan the source branch as such Origin's master branch. These branches needs to be merged.
|
||||
> - Only the branched submitted as PR: Only scan the PR branch.
|
||||
> - All the branches: extract all the branches from the repository origin.
|
||||
>
|
||||
> Discover PR from the origin repository:
|
||||
> - The source code after PR merges with the branch: Once discovery operation is based on the source codes derived from merging the PR and the target branch. It is also based on the running pipeline.
|
||||
> - PR's source code edition: Once discovery operation is based on the pipeline build by PR's source codes.
|
||||
> - There will be two pipelines when the PR is found. One pipeline applies PR's source code and the other one uses the source code from merging the PR with the target branch: This is twice discovery operation. -->
|
||||
6. In **Behavioral strategy**, KubeSphere offers three strategies by default. You can delete **Discover PR from Forks** as this strategy will not be used in this example. You do not need to change the setting and can use the default value directly.
|
||||
|
||||
4.6. The path is **Jenkinsfile** by default. Please change it to `Jenkinsfile-online`, which is the file name of Jenkinsfile in the repository located in root directory.
|
||||

|
||||
|
||||
> Note: Script path is the Jenkinsfile path in the code repository. It indicates the repository's root directory. If the file location changes, the script path should also be changed.
|
||||
As a Jenkins pipeline runs, the Pull Request (PR) submitted by developers will also be regarded as a separate branch.
|
||||
|
||||

|
||||
**Discover Branches**
|
||||
|
||||
4.7. **Scan Repo Trigger** can be customized according to the team's development preference. We set it to `5 minutes`. Click **Create** when complete advanced settings.
|
||||
- **Exclude branches that are also filed as PRs**. The source branch is not scanned such as the origin's master branch. These branches need to be merged.
|
||||
- **Only branches that are also filed as PRs**. Only scan the PR branch.
|
||||
- **All branches**. Pull all the branches from the repository origin.
|
||||
|
||||
<!-- > Note: Regular scaning is to set a cycle to require the pipeline scan remote repositories regularly. According to the **Behaviour Strategy **to check whether there is a code update or a new PR.
|
||||
>
|
||||
> Webhook Push:
|
||||
> Webhook is a high-efficiency way to detect the changes in the remote repository and automatically activate new operations. Webhook should play the main role in scanning Jenkins for GitHub and Git (like Gitlab). Please refer to the cycle time setting in the previous step. In this sample, you can run the pipeline manually. If you need to set automatic scanning for remote branches and active the operation, please refer to Setting automatic scanning - GitHub SCM.
|
||||
> -->
|
||||
**Discover PR from Origin**
|
||||
|
||||
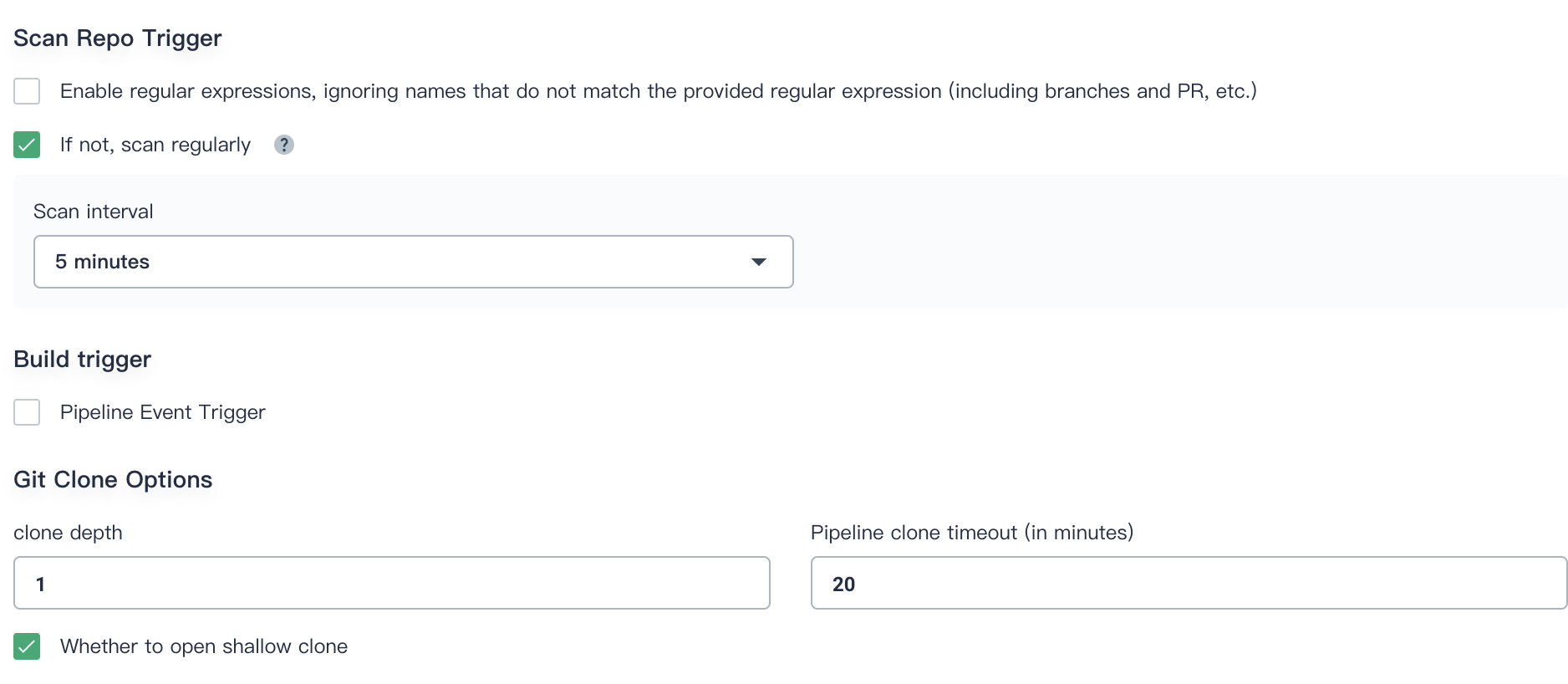
|
||||
- **Source code version of PR merged with target branch**. A pipeline is created and runs based on the source code after the PR is merged into the target branch.
|
||||
- **Source code version of PR itself**. A pipeline is created and runs based on the source code of the PR itself.
|
||||
- **Two pipelines are created when a PR is discovered**. KubeSphere creates two pipelines, one based on the source code after the PR is merged into the target branch, and the other based on the source code of the PR itself.
|
||||
|
||||
#### Run the Pipeline
|
||||
7. Scroll down to **Script Path**. The field specifies the Jenkinsfile path in the code repository. It indicates the repository's root directory. If the file location changes, the script path also needs to be changed. Please change it to `Jenkinsfile-online`, which is the file name of Jenkinsfile in the example repository located in the root directory.
|
||||
|
||||
Refresh browser manually or you may need to click `Scan Repository`, then you can find two activities triggered. Or you may want to trigger them manually as the following instructions.
|
||||

|
||||
|
||||
4.8. Click **Run** on the right. According to the **Behavioral Strategy**, it will load the branches that have Jenkinsfile. Set the value of branch as `sonarqube`. Since there is no default value in the Jenkinsfile file, put in a tag number in the **TAG_NAME** such as `v0.0.1`. Click **OK** to trigger a new activity.
|
||||
8. In **Scan Repo Trigger**, check **If not, scan regularly** and set the interval to **5 minutes**. Click **Create** to finish.
|
||||
|
||||
> Note: TAG\_NAME is used to generate release and images with tag in GitHub and DockerHub. Please notice that `TAG_NAME` should not duplicate the existing `tag` name in the code repository. Otherwise the pipeline can not run.
|
||||

|
||||
|
||||

|
||||
{{< notice note >}}
|
||||
|
||||
At this point, the pipeline for the sonarqube branch is running.
|
||||
You can set a specific interval to allow pipelines to scan remote repositories, so that any code updates or new PRs can be detected based on the strategy you set in **Behavioral strategy**.
|
||||
|
||||
> Note: Click **Branch** to switch to the branch list and review which branches are running. The branch here is determined by the **Behavioral Strategy.**
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
### Step 5: Run a Pipeline
|
||||
|
||||
#### Review Pipeline
|
||||
1. After a pipeline is created, it displays in the list below. Click it to go to its detail page.
|
||||
|
||||
When the pipeline runs to the step of `input`
|
||||
it will pause. You need to click **Continue** manually. Please note that there are three stages defined in the Jenkinsfile-online. Therefore, the pipeline will be reviewed three times in the three stages of `deploy to dev, push with tag, deploy to production`.
|
||||

|
||||
|
||||
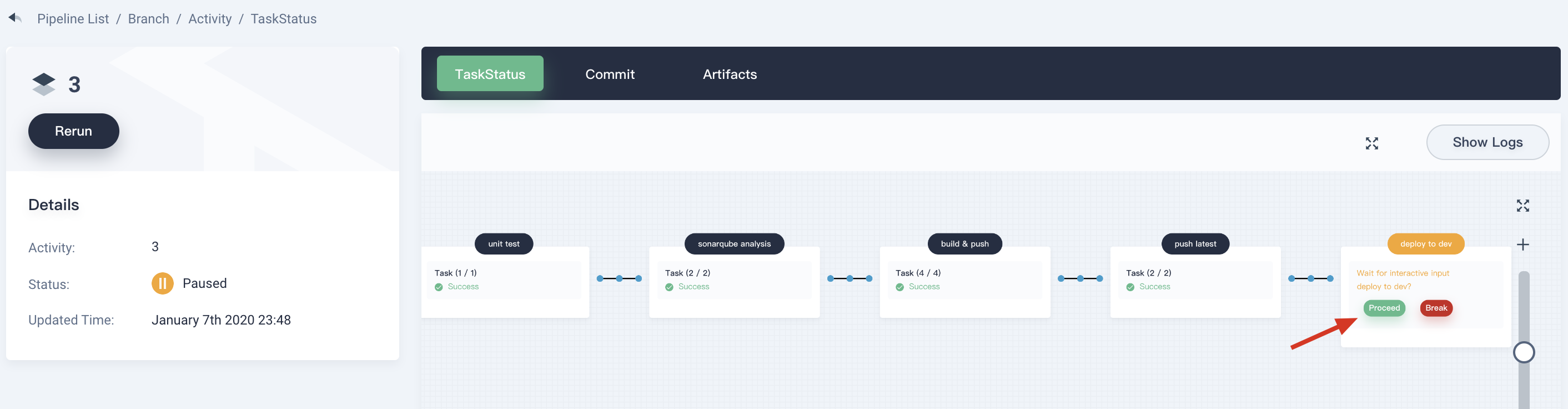
|
||||
2. Under **Activity**, three branches are being scanned. Click **Run** on the right and the pipeline runs based on the behavioral strategy you set. Select **sonarqube** from the drop-down list and add a tag number such as `v0.0.2`. Click **OK** to trigger a new activity.
|
||||
|
||||
> Note: In real development or production scenario, it requires someone who has higher authority (e.g. release manager) to review the pipeline and the image, as well as the code analysis result. They have the authority to determine whether to approve push and deploy. In Jenkinsfile, the `input` step supports you to specify who to review the pipeline. If you want to specify a user `project-admin` to review, you can add a field in the Jenkinsfile. If there are multiple users, you need to use commas to separate them as follows:
|
||||

|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- If you do need see any activity on this page, you need to refresh your browser manually or click **Scan Repository** from the drop-down menu (the **More** button).
|
||||
- The tag name is used to generate releases and images with the tag in GitHub and Docker Hub. An existing tag name cannot be used again for the field TAG_NAME. Otherwise, the pipeline will not be running successfully.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
3. Wait for a while and you can see some activities stop and some fail. Click the first one to view details.
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
Activity failures may be caused by different factors. In this example, only the Jenkinsfile of the branch sonarqube is changed as you edit the environment variables in it in the steps above. On the contrary, these variables in the dependency and master branch remain changed (namely, wrong GitHub and Docker Hub account), resulting in the failure. You can click it and inspect its logs to see details. Other reasons for failures may be network issues, incorrect coding in the Jenkinsfile and so on.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. The pipeline pauses at the stage `deploy to dev`. You need to click **Proceed** manually. Note that the pipeline will be reviewed three times as `deploy to dev`, `push with tag`, and `deploy to production` are defined in the Jenkinsfile respectively.
|
||||
|
||||

|
||||
|
||||
In a development or production environment, it requires someone who has higher authority (e.g. release manager) to review the pipeline, images, as well as the code analysis result. They have the authority to determine whether the pipeline can go to the next stage. In the Jenkinsfile, you use the section `input` to specify who reviews the pipeline. If you want to specify a user (e.g. `project-admin`) to review it, you can add a field in the Jenkinsfile. If there are multiple users, you need to use commas to separate them as follows:
|
||||
|
||||
```groovy
|
||||
···
|
||||
|
|
@ -219,71 +233,83 @@ input(id: 'release-image-with-tag', message: 'release image with tag?', submitte
|
|||
···
|
||||
```
|
||||
|
||||
### Step 5: Check Pipeline Status
|
||||
### Step 6: Check Pipeline Status
|
||||
|
||||
5.1. Click into **Activity → sonarqube → Task Status**, you can see the pipeline running status. Please note that the pipeline will keep initializing for several minutes when the creation just completed. There are eight stages in the sample pipeline and they have been defined individually in [Jenkinsfile-online](https://github.com/kubesphere/devops-java-sample/blob/sonarqube/Jenkinsfile-online).
|
||||
1. In **Task Status**, you can see how a pipeline is running. Please note that the pipeline will keep initializing for several minutes after it is just created. There are eight stages in the sample pipeline and they have been defined separately in [Jenkinsfile-online](https://github.com/kubesphere/devops-java-sample/blob/sonarqube/Jenkinsfile-online).
|
||||
|
||||
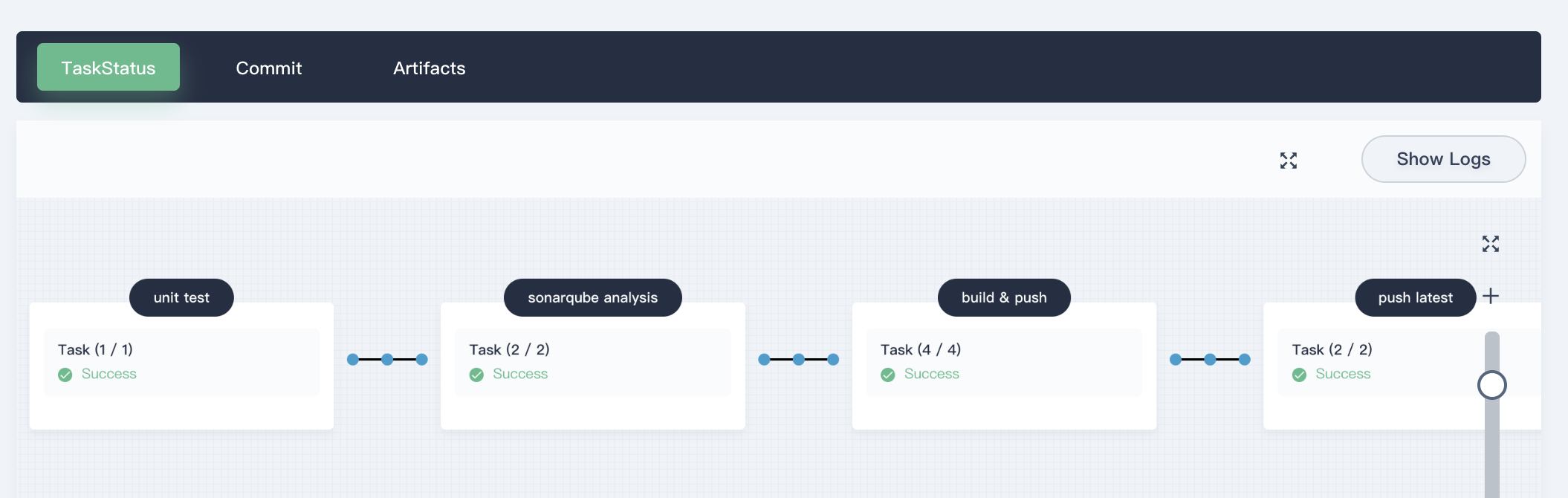
|
||||

|
||||
|
||||
5.2. Check the pipeline running logs by clicking **Show Logs** at the top right corner. The page shows dynamic logs outputs, operating status and time etc.
|
||||
2. Check the pipeline running logs by clicking **Show Logs** in the top right corner. You can see the dynamic log output of the pipeline, including any errors that may stop the pipeline from running. For each stage, you click it to inspect logs, which can be downloaded to your local machine for further analysis.
|
||||
|
||||
For each step, click specific stage on the left to inspect the logs. The logs can be downloaded to local for further analysis.
|
||||

|
||||
|
||||
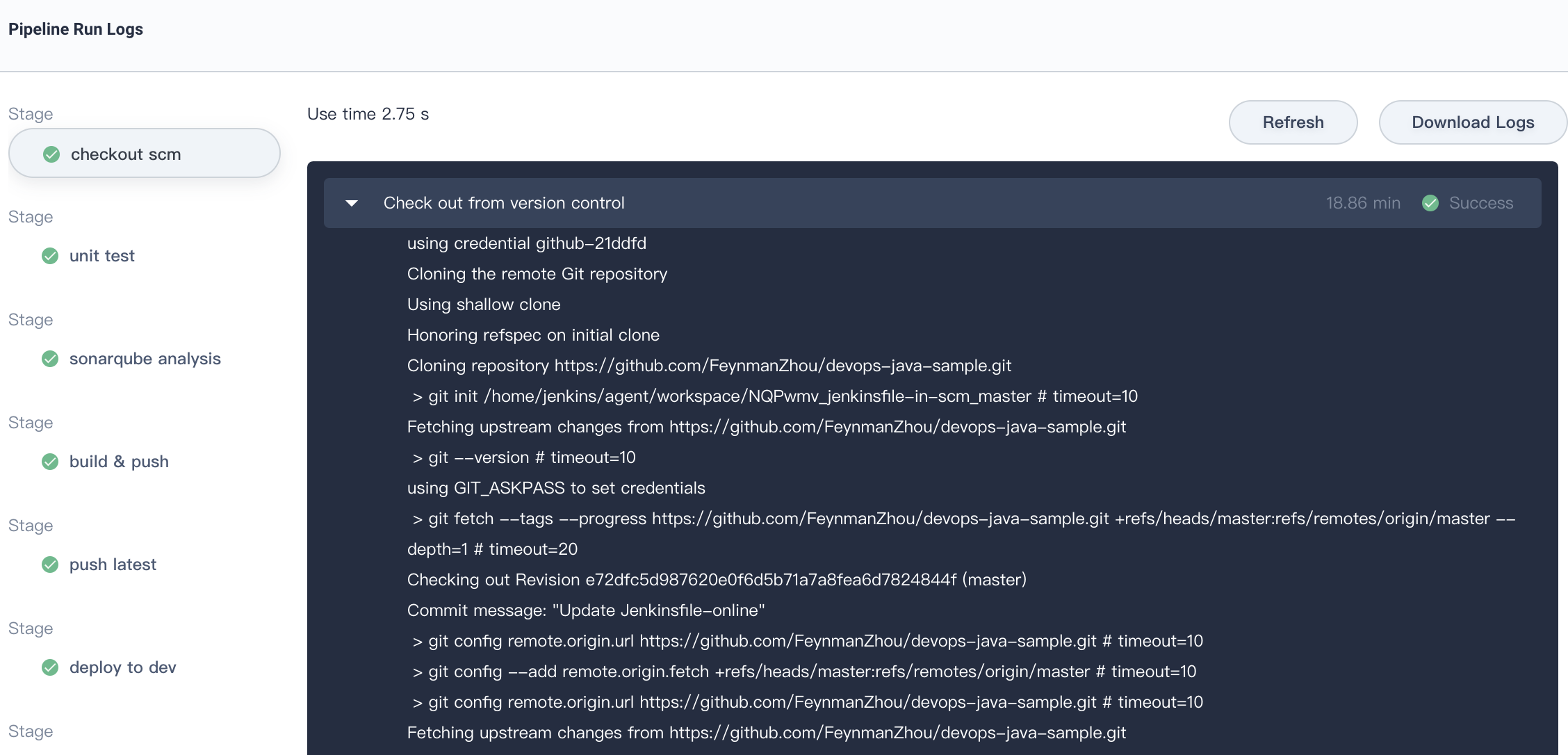
|
||||
### Step 7: Verify Results
|
||||
|
||||
### Step 6: Verify Pipeline Running Results
|
||||
1. Once you successfully executed the pipeline, click **Code Quality** to check the results through SonarQube as follows.
|
||||
|
||||
6.1. Once you successfully executed the pipeline, click `Code Quality` to check the results through SonarQube as the follows (reference only).
|
||||

|
||||
|
||||
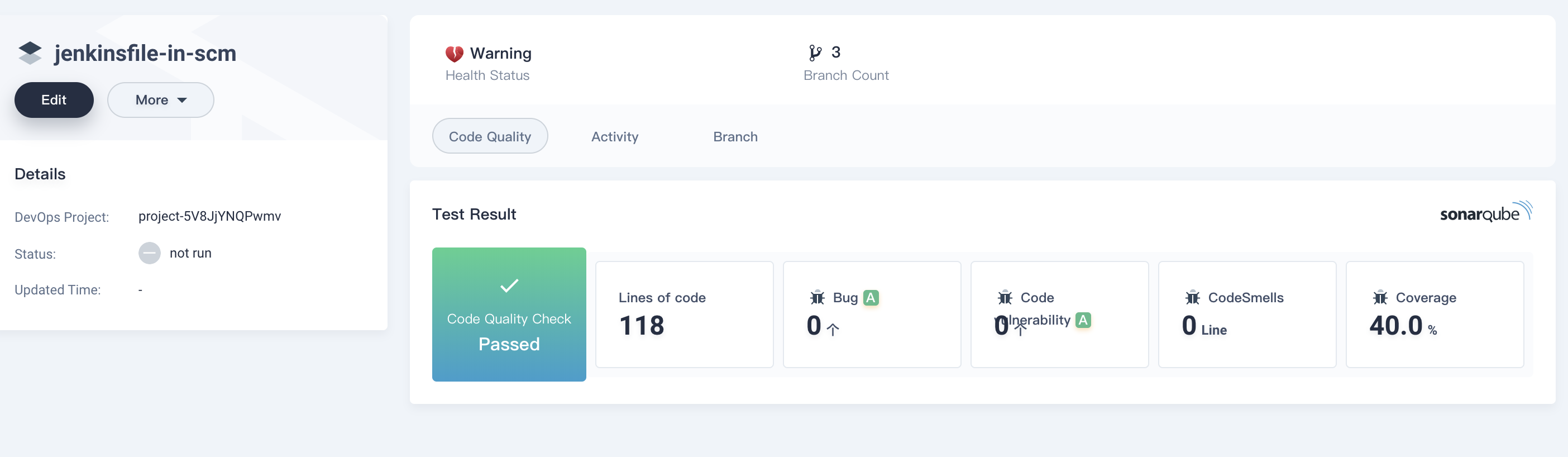
|
||||

|
||||
|
||||
6.2. The Docker image built by the pipeline has been successfully pushed to DockerHub, since we defined `push to DockerHub` stage in Jenkinsfile-online. In DockerHub you will find the image with tag v0.0.1 that we configured before running the pipeline, also you will find the images with tags`SNAPSHOT-sonarqube-6`(SNAPSHOT-branch-serial number) and `latest` have been pushed to DockerHub.
|
||||
2. The Docker image built through the pipeline has also been successfully pushed to Docker Hub, as it is defined in the Jenkinsfile. In Docker Hub, you will find the image with the tag `v0.0.2` that is specified before the pipeline runs.
|
||||
|
||||

|
||||

|
||||
|
||||
At the same time, a new tag and a new release have been generated in GitHub.
|
||||
3. At the same time, a new tag and a new release have been generated in GitHub.
|
||||
|
||||
|
||||

|
||||
|
||||
The sample application will be deployed to `kubesphere-sample-dev` and `kubesphere-sample-prod` as deployment and service.
|
||||
4. The sample application will be deployed to `kubesphere-sample-dev` and `kubesphere-sample-prod` with corresponding Deployments and Services created. Go to these two projects and here are the expected result:
|
||||
|
||||
| Environment | URL | Namespace | Deployment | Service |
|
||||
| :--- | :--- | :--- | :--- | :--- |
|
||||
| Dev | `http://{NodeIP}:{$30861}` | kubesphere-sample-dev | ks-sample-dev | ks-sample-dev |
|
||||
| Development | `http://{NodeIP}:{$30861}` | kubesphere-sample-dev | ks-sample-dev | ks-sample-dev |
|
||||
| Production | `http://{$NodeIP}:{$30961}` | kubesphere-sample-prod | ks-sample | ks-sample |
|
||||
|
||||
6.3. Enter into these two projects, you can find the application's resources have been deployed to Kubernetes successully. For example, lets verify the Deployments and Services under project `kubesphere-sample-dev`:
|
||||
|
||||
#### Deployments
|
||||
|
||||

|
||||

|
||||
|
||||
#### Services
|
||||
|
||||
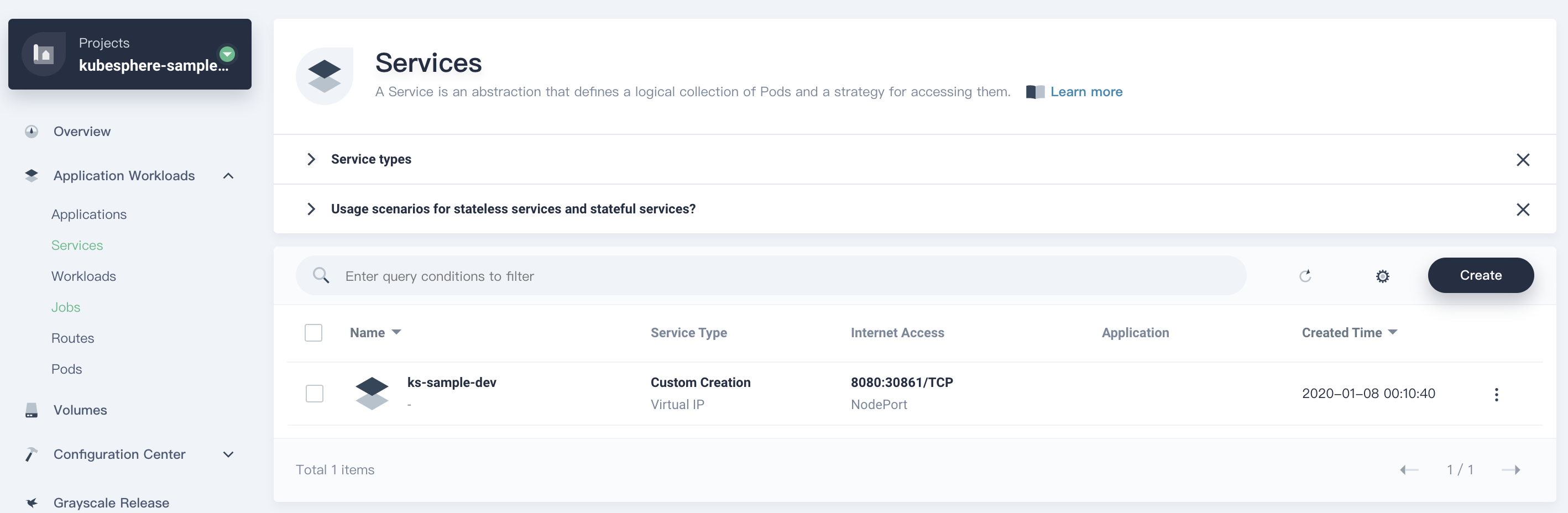
|
||||

|
||||
|
||||
### Step 7: Visit Sample Service
|
||||
{{< notice note >}}
|
||||
|
||||
7.1. You can switch to use `admin` account to open **web kubectl** from **Toolbox**. Enter into project `kubesphere-sample-dev`, select **Application Workloads → Services** and click into `ks-sample-dev` service.
|
||||
You may need to open the port in your security groups so that you can access the app with the URL.
|
||||
|
||||

|
||||
{{</ notice >}}
|
||||
|
||||
7.2. Open **web kubectl** from **Toolbox**, try to access as the following:
|
||||
### Step 8: Access Sample Service
|
||||
|
||||
> Note: curl Endpoints or {$Virtual IP}:{$Port} or {$Node IP}:{$NodePort}
|
||||
1. To access the service, log in KubeSphere as `admin` to use the **web kubectl** from **Toolbox**. Go to the project `kubesphere-sample-dev`, and select `ks-sample-dev` in **Services** under **Application Workloads**. The endpoint can be used to access the service.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
2. Use the **web kubectl** from **Toolbox** in the bottom right corner by executing the following command:
|
||||
|
||||
```bash
|
||||
$ curl 10.10.128.169:8080
|
||||
```
|
||||
|
||||
3. Expected output:
|
||||
|
||||
```bash
|
||||
$ curl 10.233.102.188:8080
|
||||
Really appreciate your star, that's the power of our life.
|
||||
```
|
||||
|
||||
7.3. Similarly, you can test the service in project `kubesphere-sample-pro`
|
||||
{{< notice note >}}
|
||||
|
||||
> Note: curl Endpoints or {$Virtual IP}:{$Port} or {$Node IP}:{$NodePort}
|
||||
Use `curl` endpoints or {$Virtual IP}:{$Port} or {$Node IP}:{$NodePort}
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
4. Similarly, you can test the service in the project `kubesphere-sample-prod` and you will see the same result.
|
||||
|
||||
```bash
|
||||
$ curl 10.233.102.188:8080
|
||||
$ curl 10.10.128.170:8080
|
||||
Really appreciate your star, that's the power of our life.
|
||||
```
|
||||
|
||||
Configurations! You are familiar with KubeSphere DevOps pipeline, and you can continue to learn how to build CI/CD pipeline with a graphical panel and visualize your workflow in the next tutorial.
|
||||
|
|
@ -39,9 +39,9 @@ Make sure your environment where existing Kubernetes clusters run meets the prer
|
|||
|
||||
## Installing on Hosted Kubernetes
|
||||
|
||||
### [Deploy KubeSphere on Oracle OKE](../installing-on-kubernetes/hosted-kubernetes/install-kubesphere-on-oke/)
|
||||
### [Deploy KubeSphere on AKS](../installing-on-kubernetes/hosted-kubernetes/install-kubesphere-on-aks/)
|
||||
|
||||
Learn how to deploy KubeSphere on Oracle Cloud Infrastructure Container Engine for Kubernetes.
|
||||
Learn how to deploy KubeSphere on Azure Kubernetes Service.
|
||||
|
||||
### [Deploy KubeSphere on AWS EKS](../installing-on-kubernetes/hosted-kubernetes/install-kubesphere-on-eks/)
|
||||
|
||||
|
|
@ -55,14 +55,14 @@ Learn how to deploy KubeSphere on DigitalOcean.
|
|||
|
||||
Learn how to deploy KubeSphere on Google Kubernetes Engine.
|
||||
|
||||
### [Deploy KubeSphere on AKS](../installing-on-kubernetes/hosted-kubernetes/install-kubesphere-on-aks/)
|
||||
|
||||
Learn how to deploy KubeSphere on Azure Kubernetes Service.
|
||||
|
||||
### [Deploy KubeSphere on Huawei CCE](../installing-on-kubernetes/hosted-kubernetes/install-ks-on-huawei-cce/)
|
||||
|
||||
Learn how to deploy KubeSphere on Huawei Cloud Container Engine.
|
||||
|
||||
### [Deploy KubeSphere on Oracle OKE](../installing-on-kubernetes/hosted-kubernetes/install-kubesphere-on-oke/)
|
||||
|
||||
Learn how to deploy KubeSphere on Oracle Cloud Infrastructure Container Engine for Kubernetes.
|
||||
|
||||
## Installing on On-premises Kubernetes
|
||||
|
||||
### [Air-gapped Installation](../installing-on-kubernetes/on-prem-kubernetes/install-ks-on-linux-airgapped/)
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ title: "Deploy KubeSphere on Huawei CCE"
|
|||
keywords: "KubeSphere, Kubernetes, installation, huawei, cce"
|
||||
description: "How to install KubeSphere on Huawei CCE."
|
||||
|
||||
weight: 2275
|
||||
weight: 2270
|
||||
---
|
||||
|
||||
This guide walks you through the steps of deploying KubeSphere on [Huaiwei CCE](https://support.huaweicloud.com/en-us/qs-cce/cce_qs_0001.html).
|
||||
|
|
@ -14,7 +14,7 @@ This guide walks you through the steps of deploying KubeSphere on [Huaiwei CCE](
|
|||
|
||||
First, create a Kubernetes cluster based on the requirements below.
|
||||
|
||||
- KubeSphere 3.0.0 supports Kubernetes `1.15.x`, `1.16.x`, `1.17.x`, and `1.18.x` by default. Select a version and create the cluster, e.g. `v1.15.11` or `v1.17.9`.
|
||||
- KubeSphere 3.0.0 supports Kubernetes `1.15.x`, `1.16.x`, `1.17.x`, and `1.18.x`. Select a version and create the cluster, e.g. `v1.15.11` or `v1.17.9`.
|
||||
- Ensure the cloud computing network for your Kubernetes cluster works, or use an elastic IP when you use “Auto Create” or “Select Existing”. You can also configure the network after the cluster is created. Refer to Configure [NAT Gateway](https://support.huaweicloud.com/en-us/productdesc-natgateway/en-us_topic_0086739762.html).
|
||||
- Select `s3.xlarge.2` `4-core|8GB` for nodes and add more if necessary (3 and more nodes are required for a production environment).
|
||||
|
||||
|
|
@ -23,7 +23,7 @@ First, create a Kubernetes cluster based on the requirements below.
|
|||
- Go to `Resource Management` > `Cluster Management` > `Basic Information` > `Network`, and bind `Public apiserver`.
|
||||
- Select `kubectl` on the right column, go to `Download kubectl configuration file`, and click `Click here to download`, then you will get a public key for kubectl.
|
||||
|
||||

|
||||

|
||||
|
||||
After you get the configuration file for kubectl, use kubectl command lines to verify the connection to the cluster.
|
||||
|
||||
|
|
@ -41,7 +41,7 @@ Server Version: version.Info{Major:"1", Minor:"17+", GitVersion:"v1.17.9-r0-CCE2
|
|||
|
||||
Huawei CCE built-in Everest CSI provides StorageClass `csi-disk` which uses SATA (normal I/O) by default, but the actual disk that is used for Kubernetes clusters is either SAS (high I/O) or SSD (extremely high I/O). Therefore, it is suggested that you create an extra StorageClass and set it as default. Refer to the official document - [Use kubectl to create a cloud storage](https://support.huaweicloud.com/en-us/usermanual-cce/cce_01_0044.html).
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
Below is an example to create a SAS (high I/O) for its corresponding StorageClass.
|
||||
|
||||
|
|
@ -76,38 +76,36 @@ For how to set up or cancel a default StorageClass, refer to Kubernetes official
|
|||
Use [ks-installer](https://github.com/kubesphere/ks-installer) to deploy KubeSphere on an existing Kubernetes cluster. Execute the following commands directly for a minimal installation:
|
||||
|
||||
```bash
|
||||
$ kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
```bash
|
||||
$ kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
Go to `Workload` > `Pod`, and check the running status of the pod in `kubesphere-system` of its namespace to understand the minimal deployment of KubeSphere. Check `ks-console-xxxx` of the namespace to understand the availability of KubeSphere console.
|
||||
|
||||

|
||||

|
||||
|
||||
### Expose KubeSphere Console
|
||||
|
||||
Check the running status of Pod in `kubesphere-system` namespace and make sure the basic components of KubeSphere are running. Then expose KubeSphere console.
|
||||
Check the running status of Pods in `kubesphere-system` namespace and make sure the basic components of KubeSphere are running. Then expose KubeSphere console.
|
||||
|
||||
Go to `Resource Management` > `Network` and choose the service in `ks-console`. It is suggested that you choose `LoadBalancer` (Public IP is required). The configuration is shown below.
|
||||
|
||||

|
||||

|
||||
|
||||
Default settings are OK for other detailed configurations. You can also set it based on your needs.
|
||||
|
||||

|
||||

|
||||
|
||||
After you set LoadBalancer for KubeSphere console, you can visit it via the given address. Go to KubeSphere login page and use the default account (username `admin` and pw `P@88w0rd`) to log in.
|
||||
|
||||

|
||||

|
||||
|
||||
## Enable Pluggable Components (Optional)
|
||||
|
||||
The example above demonstrates the process of a default minimal installation. To enable other components in KubeSphere, see [Enable Pluggable Components](../../../pluggable-components/) for more details.
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
Before you use Istio-based features of KubeSphere, you have to delete `applications.app.k8s.io` built in Huawei CCE due to the CRD conflict. You can run the command `kubectl delete crd applications.app.k8s.io` directly to delete it.
|
||||
|
||||
|
|
@ -115,4 +113,4 @@ Before you use Istio-based features of KubeSphere, you have to delete `applicati
|
|||
|
||||
After your component is installed, go to the **Cluster Management** page, and you will see the interface below. You can check the status of your component in **Components**.
|
||||
|
||||

|
||||

|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ title: "Deploy KubeSphere on AKS"
|
|||
keywords: "KubeSphere, Kubernetes, Installation, Azure, AKS"
|
||||
description: "How to deploy KubeSphere on AKS"
|
||||
|
||||
weight: 2270
|
||||
weight: 2247
|
||||
---
|
||||
|
||||
This guide walks you through the steps of deploying KubeSphere on [Azure Kubernetes Service](https://docs.microsoft.com/en-us/azure/aks/).
|
||||
|
|
@ -13,6 +13,7 @@ This guide walks you through the steps of deploying KubeSphere on [Azure Kuberne
|
|||
Azure can help you implement infrastructure as code by providing resource deployment automation options. Commonly adopted tools include [ARM templates](https://docs.microsoft.com/en-us/azure/azure-resource-manager/templates/overview) and [Azure CLI](https://docs.microsoft.com/en-us/cli/azure/what-is-azure-cli?view=azure-cli-latest). In this guide, we will use Azure CLI to create all the resources that are needed for the installation of KubeSphere.
|
||||
|
||||
### Use Azure Cloud Shell
|
||||
|
||||
You don't have to install Azure CLI on your machine as Azure provides a web-based terminal. Click the Cloud Shell button on the menu bar at the upper right corner in Azure portal.
|
||||
|
||||

|
||||
|
|
@ -20,25 +21,28 @@ You don't have to install Azure CLI on your machine as Azure provides a web-base
|
|||
Select **Bash** Shell.
|
||||
|
||||

|
||||
|
||||
### Create a Resource Group
|
||||
|
||||
An Azure resource group is a logical group in which Azure resources are deployed and managed. The following example creates a resource group named `KubeSphereRG` in the location `westus`.
|
||||
An Azure resource group is a logical group in which Azure resources are deployed and managed. The following example creates a resource group named `KubeSphereRG` in the location `westus`.
|
||||
|
||||
```bash
|
||||
az group create --name KubeSphereRG --location westus
|
||||
```
|
||||
|
||||
### Create an AKS Cluster
|
||||
|
||||
Use the command `az aks create` to create an AKS cluster. The following example creates a cluster named `KuberSphereCluster` with three nodes. This will take several minutes to complete.
|
||||
|
||||
```bash
|
||||
az aks create --resource-group KubeSphereRG --name KuberSphereCluster --node-count 3 --enable-addons monitoring --generate-ssh-keys
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
You can use `--node-vm-size` or `-s` option to change the size of Kubernetes nodes. Default: Standard_DS2_v2 (2vCPU, 7GB memory). For more options, see [az aks create](https://docs.microsoft.com/en-us/cli/azure/aks?view=azure-cli-latest#az-aks-create).
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
### Connect to the Cluster
|
||||
|
||||
|
|
@ -53,12 +57,14 @@ kebesphere@Azure:~$ kubectl get nodes
|
|||
NAME STATUS ROLES AGE VERSION
|
||||
aks-nodepool1-23754246-vmss000000 Ready agent 38m v1.16.13
|
||||
```
|
||||
|
||||
### Check Azure Resources in the Portal
|
||||
|
||||
After you execute all the commands above, you can see there are 2 Resource Groups created in Azure Portal.
|
||||
|
||||

|
||||
|
||||
Azure Kubernetes Services itself will be placed in KubeSphereRG.
|
||||
Azure Kubernetes Services itself will be placed in KubeSphereRG.
|
||||
|
||||

|
||||
|
||||
|
|
@ -67,13 +73,15 @@ All the other Resources will be placed in MC_KubeSphereRG_KuberSphereCluster_wes
|
|||

|
||||
|
||||
## Deploy KubeSphere on AKS
|
||||
To start deploying KubeSphere, use the following command.
|
||||
|
||||
To start deploying KubeSphere, use the following commands.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
```bash
|
||||
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
You can inspect the logs of installation through the following command:
|
||||
|
||||
```bash
|
||||
|
|
@ -83,10 +91,13 @@ kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=
|
|||
## Access KubeSphere Console
|
||||
|
||||
To access KubeSphere console from a public IP address, you need to change the service type to `LoadBalancer`.
|
||||
|
||||
```bash
|
||||
kubectl edit service ks-console -n kubesphere-system
|
||||
```
|
||||
|
||||
Find the following section and change the type to `LoadBalancer`.
|
||||
|
||||
```bash
|
||||
spec:
|
||||
clusterIP: 10.0.78.113
|
||||
|
|
@ -106,12 +117,15 @@ spec:
|
|||
status:
|
||||
loadBalancer: {}
|
||||
```
|
||||
|
||||
After saving the configuration of ks-console service, you can use the following command to get the public IP address (under `EXTERNAL-IP`). Use the IP address to access the console with the default account and password (`admin/P@88w0rd`).
|
||||
|
||||
```bash
|
||||
kebesphere@Azure:~$ kubectl get svc/ks-console -n kubesphere-system
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
ks-console LoadBalancer 10.0.181.93 13.86.xxx.xxx 80:30194/TCP 13m 6379/TCP 10m
|
||||
```
|
||||
|
||||
## Enable Pluggable Components (Optional)
|
||||
|
||||
The example above demonstrates the process of a default minimal installation. For pluggable components, you can enable them either before or after the installation. See [Enable Pluggable Components](../../../pluggable-components/) for details.
|
||||
The example above demonstrates the process of a default minimal installation. For pluggable components, you can enable them either before or after the installation. See [Enable Pluggable Components](../../../pluggable-components/) for details.
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ weight: 2265
|
|||
|
||||

|
||||
|
||||
This guide walks you through the steps of deploying KubeSphere on [ DigitalOcean Kubernetes](https://www.digitalocean.com/products/kubernetes/).
|
||||
This guide walks you through the steps of deploying KubeSphere on [DigitalOcean Kubernetes](https://www.digitalocean.com/products/kubernetes/).
|
||||
|
||||
## Prepare a DOKS Cluster
|
||||
|
||||
|
|
@ -17,6 +17,7 @@ A Kubernetes cluster in DO is a prerequisite for installing KubeSphere. Go to yo
|
|||

|
||||
|
||||
You need to select:
|
||||
|
||||
1. Kubernetes version (e.g. *1.18.6-do.0*)
|
||||
2. Datacenter region (e.g. *Frankfurt*)
|
||||
3. VPC network (e.g. *default-fra1*)
|
||||
|
|
@ -25,13 +26,13 @@ You need to select:
|
|||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
- Supported Kubernetes versions for KubeSphere 3.0.0: 1.15.x, 1.16.x, 1.17.x, 1.18.x.
|
||||
- 2 nodes are included in this example. You can add more nodes based on your own needs especially in a production environment.
|
||||
- The machine type Standard / 4 GB / 2 vCPUs is for minimal installation. If you plan to enable several pluggable components or use the cluster for production, you can upgrade your nodes to a more powerfull type (such as CPU-Optimized / 8 GB / 4 vCPUs). It seems that DigitalOcean provisions the master nodes based on the type of the worker nodes, and for Standard ones the API server can become unresponsive quite fast.
|
||||
- The machine type Standard / 4 GB / 2 vCPUs is for minimal installation. If you plan to enable several pluggable components or use the cluster for production, you can upgrade your nodes to a more powerfull type (such as CPU-Optimized / 8 GB / 4 vCPUs). It seems that DigitalOcean provisions the master nodes based on the type of the worker nodes, and for Standard ones the API server can become unresponsive quite soon.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
When the cluster is ready, you can download the config file for kubectl.
|
||||
|
||||
|
|
@ -41,13 +42,11 @@ When the cluster is ready, you can download the config file for kubectl.
|
|||
|
||||
Now that the cluster is ready, you can install KubeSphere following the steps below:
|
||||
|
||||
- Install KubeSphere using kubectl. The following command is only for the default minimal installation.
|
||||
- Install KubeSphere using kubectl. The following commands are only for the default minimal installation.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
|
||||
```bash
|
||||
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -7,19 +7,22 @@ weight: 2265
|
|||
---
|
||||
|
||||
This guide walks you through the steps of deploying KubeSphere on [AWS EKS](https://docs.aws.amazon.com/eks/latest/userguide/what-is-eks.html).
|
||||
|
||||
## Install the AWS CLI
|
||||
Amazon EKS does not have a web terminal like GKE, so we must install the AWS CLI first. Below is an example for macOS and please refer to [Getting Started EKS](https://docs.aws.amazon.com/eks/latest/userguide/getting-started-console.html) for other operating systems.
|
||||
|
||||
First we need to install the AWS CLI. Below is an example for macOS and please refer to [Getting Started EKS](https://docs.aws.amazon.com/eks/latest/userguide/getting-started-console.html) for other operating systems.
|
||||
|
||||
```shell
|
||||
pip3 install awscli --upgrade --user
|
||||
```
|
||||
|
||||
Check the installation with `aws --version`.
|
||||

|
||||
|
||||
## Prepare an EKS Cluster
|
||||
|
||||
1. A standard Kubernetes cluster in AWS is a prerequisite of installing KubeSphere. Go to the navigation menu and refer to the image below to create a cluster.
|
||||
|
||||

|
||||

|
||||
|
||||
2. On the **Configure cluster** page, fill in the following fields:
|
||||

|
||||
|
|
@ -52,11 +55,11 @@ Check the installation with `aws --version`.
|
|||
|
||||
- Private: Enables only private access to your cluster's Kubernetes API server endpoint. Kubernetes API requests that originate from within your cluster's VPC use the private VPC endpoint.
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
If you created a VPC without outbound internet access, then you must enable private access.
|
||||
If you created a VPC without outbound internet access, then you must enable private access.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Public and private: Enables public and private access.
|
||||
|
||||
|
|
@ -77,8 +80,8 @@ Check the installation with `aws --version`.
|
|||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- Supported Kubernetes versions for KubeSphere 3.0.0: 1.15.x, 1.16.x, 1.17.x, 1.18.x.
|
||||
- Ubuntu is used for the operating system here as an example. For more information on supported systems, see [Overview](../../../installing-on-kubernetes/introduction/overview/).
|
||||
- 3 nodes are included in this example. You can add more nodes based on your own needs especially in a production environment.
|
||||
- The machine type t3.medium (2 vCPU, 4GB memory) is for minimal installation. If you want to enable pluggable components or use the cluster for production, please select a machine type with more resources.
|
||||
- For other settings, you can change them as well based on your own needs or use the default value.
|
||||
|
|
@ -88,83 +91,83 @@ Check the installation with `aws --version`.
|
|||
8. When the EKS cluster is ready, you can connect to the cluster with kubectl.
|
||||
|
||||
## Configure kubectl
|
||||
|
||||
We will use the kubectl command-line utility for communicating with the cluster API server. First, get the kubeconfig of the EKS cluster created just now.
|
||||
|
||||
1. Configure your AWS CLI credentials.
|
||||
|
||||
```shell
|
||||
$ aws configure
|
||||
AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE
|
||||
AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
|
||||
Default region name [None]: region-code
|
||||
Default output format [None]: json
|
||||
```
|
||||
```shell
|
||||
$ aws configure
|
||||
AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE
|
||||
AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
|
||||
Default region name [None]: region-code
|
||||
Default output format [None]: json
|
||||
```
|
||||
|
||||
2. Create your kubeconfig file with the AWS CLI.
|
||||
|
||||
```shell
|
||||
aws eks --region us-west-2 update-kubeconfig --name cluster_name
|
||||
```
|
||||
- By default, the resulting configuration file is created at the default kubeconfig path (`.kube/config`) in your home directory or merged with an existing kubeconfig at that location. You can specify another path with the `--kubeconfig` option.
|
||||
```shell
|
||||
aws eks --region us-west-2 update-kubeconfig --name cluster_name
|
||||
```
|
||||
|
||||
- You can specify an IAM role ARN with the `--role-arn` option to use for authentication when you issue kubectl commands. Otherwise, the IAM entity in your default AWS CLI or SDK credential chain is used. You can view your default AWS CLI or SDK identity by running the `aws sts get-caller-identity` command.
|
||||
- By default, the resulting configuration file is created at the default kubeconfig path (`.kube/config`) in your home directory or merged with an existing kubeconfig at that location. You can specify another path with the `--kubeconfig` option.
|
||||
|
||||
For more information, see the help page with the `aws eks update-kubeconfig help` command or see [update-kubeconfig](https://docs.aws.amazon.com/cli/latest/reference/eks/update-kubeconfig.html) in the *AWS CLI Command Reference*.
|
||||
- You can specify an IAM role ARN with the `--role-arn` option to use for authentication when you issue kubectl commands. Otherwise, the IAM entity in your default AWS CLI or SDK credential chain is used. You can view your default AWS CLI or SDK identity by running the `aws sts get-caller-identity` command.
|
||||
|
||||
For more information, see the help page with the `aws eks update-kubeconfig help` command or see [update-kubeconfig](https://docs.aws.amazon.com/cli/latest/reference/eks/update-kubeconfig.html) in the *AWS CLI Command Reference*.
|
||||
|
||||
3. Test your configuration.
|
||||
|
||||
```shell
|
||||
kubectl get svc
|
||||
```
|
||||
```shell
|
||||
kubectl get svc
|
||||
```
|
||||
|
||||
## Install KubeSphere on EKS
|
||||
|
||||
- Install KubeSphere using kubectl. The following command is only for the default minimal installation.
|
||||
- Install KubeSphere using kubectl. The following commands are only for the default minimal installation.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||

|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
- Create a local **cluster-configuration.yaml** file.
|
||||
```shell
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||

|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
- Inspect the logs of installation:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
- When the installation finishes, you can see the following message:
|
||||
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
#####################################################
|
||||
https://kubesphere.io 2020-xx-xx xx:xx:xx
|
||||
```
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
#####################################################
|
||||
https://kubesphere.io 2020-xx-xx xx:xx:xx
|
||||
```
|
||||
|
||||
## Access KubeSphere Console
|
||||
|
||||
Now that KubeSphere is installed, you can access the web console of KubeSphere by following the step below.
|
||||
|
||||
- Check the service of KubeSphere console through the following command.
|
||||
```shell
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
|
||||
- Edit the configuration of the service **ks-console** by executing `kubectl edit ks-console` and change `type` from `NodePort` to `LoadBalancer`. Save the file when you finish.
|
||||
```shell
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
|
||||
- Edit the configuration of the service **ks-console** by executing `kubectl edit ks-console` and change `type` from `NodePort` to `LoadBalancer`. Save the file when you finish.
|
||||

|
||||
|
||||
- Run `kubectl get svc -n kubesphere-system` and get your external IP.
|
||||
|
|
@ -174,7 +177,7 @@ kubectl get svc -n kubesphere-system
|
|||
|
||||
- Log in the console with the default account and password (`admin/P@88w0rd`). In the cluster overview page, you can see the dashboard as shown in the following image.
|
||||
|
||||

|
||||

|
||||
|
||||
## Enable Pluggable Components (Optional)
|
||||
|
||||
|
|
@ -183,4 +186,3 @@ The example above demonstrates the process of a default minimal installation. To
|
|||
## Reference
|
||||
|
||||
[Getting started with the AWS Management Console](https://docs.aws.amazon.com/eks/latest/userguide/getting-started-console.html)
|
||||
|
||||
|
|
|
|||
|
|
@ -14,99 +14,94 @@ This guide walks you through the steps of deploying KubeSphere on [Google Kubern
|
|||
|
||||
- A standard Kubernetes cluster in GKE is a prerequisite of installing KubeSphere. Go to the navigation menu and refer to the image below to create a cluster.
|
||||
|
||||

|
||||

|
||||
|
||||
- In **Cluster basics**, select a Master version. The static version `1.15.12-gke.2` is used here as an example.
|
||||
|
||||

|
||||

|
||||
|
||||
- In **default-pool** under **Node Pools**, define 3 nodes in this cluster.
|
||||
|
||||

|
||||

|
||||
|
||||
- Go to **Nodes**, select the image type and set the Machine Configuration as below. When you finish, click **Create**.
|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
- Supported Kubernetes versions for KubeSphere 3.0.0: 1.15.x, 1.16.x, 1.17.x, 1.18.x.
|
||||
- Ubuntu is used for the operating system here as an example. For more information on supported systems, see Overview.
|
||||
- 3 nodes are included in this example. You can add more nodes based on your own needs especially in a production environment.
|
||||
- The machine type e2-medium (2 vCPU, 4GB memory) is for minimal installation. If you want to enable pluggable components or use the cluster for production, please select a machine type with more resources.
|
||||
- For other settings, you can change them as well based on your own needs or use the default value.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- When the GKE cluster is ready, you can connect to the cluster with Cloud Shell.
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
## Install KubeSphere on GKE
|
||||
|
||||
- Install KubeSphere using kubectl. The following command is only for the default minimal installation.
|
||||
- Install KubeSphere using kubectl. The following commands are only for the default minimal installation.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
- Inspect the logs of installation:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
- When the installation finishes, you can see the following message:
|
||||
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
Console: http://10.128.0.44:30880
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
#####################################################
|
||||
https://kubesphere.io 2020-xx-xx xx:xx:xx
|
||||
```
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
Console: http://10.128.0.44:30880
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
#####################################################
|
||||
https://kubesphere.io 2020-xx-xx xx:xx:xx
|
||||
```
|
||||
|
||||
## Access KubeSphere Console
|
||||
|
||||
Now that KubeSphere is installed, you can access the web console of KubeSphere by following the step below.
|
||||
Now that KubeSphere is installed, you can access the web console of KubeSphere by following the steps below.
|
||||
|
||||
- In **Services & Ingress**, select the service **ks-console**.
|
||||
|
||||

|
||||

|
||||
|
||||
- In **Service details**, click **Edit** and change the type from `NodePort` to `LoadBalancer`. Save the file when you finish.
|
||||
|
||||

|
||||

|
||||
|
||||
- Access the web console of KubeSphere using the endpoint generated by GKE.
|
||||
|
||||

|
||||
|
||||

|
||||
{{< notice tip >}}
|
||||
|
||||
{{< notice tip >}}
|
||||
Instead of changing the service type to `LoadBalancer`, you can also access KubeSphere console via `NodeIP:NodePort` (service type set to `NodePort`). You may need to open port `30880` in firewall rules.
|
||||
|
||||
Instead of changing the service type to `LoadBalancer`, you can also access KubeSphere console via `NodeIP:NodePort` (service type set to `NodePort`). You may need to open port `30880` in firewall rules.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Log in the console with the default account and password (`admin/P@88w0rd`). In the cluster overview page, you can see the dashboard as shown in the following image.
|
||||
|
||||

|
||||

|
||||
|
||||
## Enable Pluggable Components (Optional)
|
||||
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ title: "Deploy KubeSphere on Oracle OKE"
|
|||
keywords: 'Kubernetes, KubeSphere, OKE, Installation, Oracle-cloud'
|
||||
description: 'How to install KubeSphere on Oracle OKE'
|
||||
|
||||
weight: 2247
|
||||
weight: 2275
|
||||
---
|
||||
|
||||
This guide walks you through the steps of deploying KubeSphere on [Oracle Kubernetes Engine](https://www.oracle.com/cloud/compute/container-engine-kubernetes.html).
|
||||
|
|
@ -12,97 +12,95 @@ This guide walks you through the steps of deploying KubeSphere on [Oracle Kubern
|
|||
|
||||
- A standard Kubernetes cluster in OKE is a prerequisite of installing KubeSphere. Go to the navigation menu and refer to the image below to create a cluster.
|
||||
|
||||

|
||||

|
||||
|
||||
- In the pop-up window, select **Quick Create** and click **Launch Workflow**.
|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
In this example, **Quick Create** is used for demonstration which will automatically create all the resources necessary for a cluster in Oracle Cloud. If you select **Custom Create**, you need to create all the resources (such as VCN and LB Subnets) yourself.
|
||||
In this example, **Quick Create** is used for demonstration which will automatically create all the resources necessary for a cluster in Oracle Cloud. If you select **Custom Create**, you need to create all the resources (such as VCN and LB Subnets) by yourself.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Next, you need to set the cluster with basic information. Here is an example for your reference. When you finish, click **Next**.
|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
- Supported Kubernetes versions for KubeSphere 3.0.0: 1.15.x, 1.16.x, 1.17.x, 1.18.x.
|
||||
- It is recommended that you should select **Public** for **Visibility Type**, which will assign a public IP address for every node. The IP address can be used later to access the web console of KubeSphere.
|
||||
- In Oracle Cloud, a Shape is a template that determines the number of CPUs, amount of memory, and other resources that are allocated to an instance. `VM.Standard.E2.2 (2 CPUs and 16G Memory)` is used in this example. For more information, see [Standard Shapes](https://docs.cloud.oracle.com/en-us/iaas/Content/Compute/References/computeshapes.htm#vmshapes__vm-standard).
|
||||
- 3 nodes are included in this example. You can add more nodes based on your own needs especially in a production environment.
|
||||
- Supported Kubernetes versions for KubeSphere 3.0.0: 1.15.x, 1.16.x, 1.17.x, 1.18.x.
|
||||
- It is recommended that you should select **Public** for **Visibility Type**, which will assign a public IP address for every node. The IP address can be used later to access the web console of KubeSphere.
|
||||
- In Oracle Cloud, a Shape is a template that determines the number of CPUs, amount of memory, and other resources that are allocated to an instance. `VM.Standard.E2.2 (2 CPUs and 16G Memory)` is used in this example. For more information, see [Standard Shapes](https://docs.cloud.oracle.com/en-us/iaas/Content/Compute/References/computeshapes.htm#vmshapes__vm-standard).
|
||||
- 3 nodes are included in this example. You can add more nodes based on your own needs especially in a production environment.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Review cluster information and click **Create Cluster** if no adjustment is needed.
|
||||
|
||||

|
||||

|
||||
|
||||
- After the cluster is created, click **Close**.
|
||||
|
||||

|
||||

|
||||
|
||||
- Make sure the Cluster Status is **Active** and click **Access Cluster**.
|
||||
|
||||

|
||||

|
||||
|
||||
- In the pop-up window, select **Cloud Shell Access** to access the cluster. Click **Launch Cloud Shell** and copy the code provided by Oracle Cloud.
|
||||
|
||||

|
||||

|
||||
|
||||
- In Cloud Shell, paste the command so that we can execute the installation command later.
|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice warning >}}
|
||||
{{< notice warning >}}
|
||||
|
||||
If you do not copy and execute the command above, you cannot proceed with the steps below.
|
||||
If you do not copy and execute the command above, you cannot proceed with the steps below.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Install KubeSphere on OKE
|
||||
|
||||
- Install KubeSphere using kubectl. The following command is only for the default minimal installation.
|
||||
- Install KubeSphere using kubectl. The following commands are only for the default minimal installation.
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
- Inspect the logs of installation:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
- When the installation finishes, you can see the following message:
|
||||
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
```bash
|
||||
#####################################################
|
||||
### Welcome to KubeSphere! ###
|
||||
#####################################################
|
||||
|
||||
Console: http://10.0.10.2:30880
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
Console: http://10.0.10.2:30880
|
||||
Account: admin
|
||||
Password: P@88w0rd
|
||||
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
NOTES:
|
||||
1. After logging into the console, please check the
|
||||
monitoring status of service components in
|
||||
the "Cluster Management". If any service is not
|
||||
ready, please wait patiently until all components
|
||||
are ready.
|
||||
2. Please modify the default password after login.
|
||||
|
||||
#####################################################
|
||||
https://kubesphere.io 20xx-xx-xx xx:xx:xx
|
||||
```
|
||||
#####################################################
|
||||
https://kubesphere.io 20xx-xx-xx xx:xx:xx
|
||||
```
|
||||
|
||||
## Access KubeSphere Console
|
||||
|
||||
|
|
@ -110,43 +108,42 @@ Now that KubeSphere is installed, you can access the web console of KubeSphere e
|
|||
|
||||
- Check the service of KubeSphere console through the following command:
|
||||
|
||||
```bash
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
```bash
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
|
||||
- The output may look as below. You can change the type to `LoadBalancer` so that the external IP address can be exposed.
|
||||
|
||||

|
||||

|
||||
|
||||
{{< notice tip >}}
|
||||
{{< notice tip >}}
|
||||
|
||||
It can be seen above that the service `ks-console` is being exposed through NodePort, which means you can access the console directly via `NodeIP:NodePort` (the public IP address of any node is applicable). You may need to open port `30880` in firewall rules.
|
||||
It can be seen above that the service `ks-console` is being exposed through NodePort, which means you can access the console directly via `NodeIP:NodePort` (the public IP address of any node is applicable). You may need to open port `30880` in firewall rules.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Execute the command to edit the service configuration.
|
||||
|
||||
```bash
|
||||
kubectl edit svc ks-console -o yaml -n kubesphere-system
|
||||
```
|
||||
```bash
|
||||
kubectl edit svc ks-console -o yaml -n kubesphere-system
|
||||
```
|
||||
|
||||
- Navigate to `type` and change `NodePort` to `LoadBalancer`. Save the configuration after you finish.
|
||||
|
||||

|
||||

|
||||
|
||||
- Execute the following command again and you can see the IP address displayed as below.
|
||||
|
||||
```bash
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
```bash
|
||||
kubectl get svc -n kubesphere-system
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
- Log in the console through the external IP address with the default account and password (`admin/P@88w0rd`). In the cluster overview page, you can see the dashboard shown below:
|
||||
|
||||

|
||||

|
||||
|
||||
## Enable Pluggable Components (Optional)
|
||||
|
||||
The example above demonstrates the process of a default minimal installation. To enable other components in KubeSphere, see [Enable Pluggable Components](../../../pluggable-components/) for more details.
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ As part of KubeSphere's commitment to provide a plug-and-play architecture for u
|
|||
|
||||
This section gives you an overview of the general steps of installing KubeSphere on Kubernetes. For more information about the specific way of installation in different environments, see Installing on Hosted Kubernetes and Installing on On-premises Kubernetes.
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
|
||||
Please read [Prerequisites](../prerequisites/) before you install KubeSphere on existing Kubernetes clusters.
|
||||
|
||||
|
|
@ -27,18 +27,10 @@ After you make sure your existing Kubernetes cluster meets all the requirements,
|
|||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
```
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If your server has trouble accessing GitHub, you can copy the content in [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml) and [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) respectively and past it to local files. You then can use `kubectl apply -f` for the local files to install KubeSphere.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
- Inspect the logs of installation:
|
||||
|
||||
```bash
|
||||
|
|
@ -61,10 +53,8 @@ If you start with a default minimal installation, refer to [Enable Pluggable Com
|
|||
|
||||
{{< notice tip >}}
|
||||
|
||||
- Pluggable components can be enabled either before or after the installation. Please refer to the example file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/blob/master/deploy/cluster-configuration.yaml) for more details.
|
||||
- Pluggable components can be enabled either before or after the installation. Please refer to the example file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/blob/release-3.0/deploy/cluster-configuration.yaml) for more details.
|
||||
- Make sure there is enough CPU and memory available in your cluster.
|
||||
- It is highly recommended that you install these pluggable components to discover the full-stack features and capabilities provided by KubeSphere.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ weight: 2000
|
|||
icon: "/images/docs/docs.svg"
|
||||
---
|
||||
|
||||
This chapter demonstrates how to use KubeKey to provision a production-ready Kubernetes and KubeSphere cluster on Linux in different environments. You can also use KubeKey to easily scale up and down your cluster and set various storage classes based on your needs.
|
||||
This chapter demonstrates how to use KubeKey to provision a production-ready Kubernetes and KubeSphere cluster on Linux in different environments. You can also use KubeKey to easily scale out and in your cluster and set various storage classes based on your needs.
|
||||
|
||||
## Introduction
|
||||
|
||||
|
|
@ -53,11 +53,11 @@ Learn how to create a high-availability cluster on QingCloud platform.
|
|||
|
||||
### [Add New Nodes](../installing-on-linux/cluster-operation/add-new-nodes/)
|
||||
|
||||
Add more nodes to scale up your cluster.
|
||||
Add more nodes to scale out your cluster.
|
||||
|
||||
### [Remove Nodes](../installing-on-linux/cluster-operation/remove-nodes/)
|
||||
|
||||
Cordon a node and even delete a node to scale down your cluster.
|
||||
Cordon a node and even delete a node to scale in your cluster.
|
||||
|
||||
## Uninstalling
|
||||
|
||||
|
|
@ -69,7 +69,7 @@ Remove KubeSphere and Kubernetes from your machines.
|
|||
|
||||
### [Configure Booster for Installation](../installing-on-linux/faq/configure-booster/)
|
||||
|
||||
Set a registry mirror to speed up downloads during installation.
|
||||
Set a registry mirror to speed up image downloads during installation.
|
||||
|
||||
## Most Popular Pages
|
||||
|
||||
|
|
|
|||
|
|
@ -36,12 +36,35 @@ If you plan to install KubeSphere on [QingCloud](https://www.qingcloud.com/), [Q
|
|||
### Chart Config
|
||||
```yaml
|
||||
config:
|
||||
qy_access_key_id: "MBKTPXWCIRIEDQYQKXYL" # <--ToBeReplaced-->
|
||||
qy_secret_access_key: "cqEnHYZhdVCVif9qCUge3LNUXG1Cb9VzKY2RnBdX" # <--ToBeReplaced ->
|
||||
zone: "pek3a" # <--ToBeReplaced-->
|
||||
qy_access_key_id: "MBKTPXWCIRIEDQYQKXYL" # Replace it with your own key id.
|
||||
qy_secret_access_key: "cqEnHYZhdVCVif9qCUge3LNUXG1Cb9VzKY2RnBdX" # Replace it with your own access key.
|
||||
zone: "pek3a" # Lowercase letters only.
|
||||
sc:
|
||||
isDefaultClass: true
|
||||
isDefaultClass: true # Set it as the default storage class.
|
||||
```
|
||||
You need to create this file of chart configurations and input the values above manually.
|
||||
|
||||
#### Key
|
||||
|
||||
To get values for `qy_access_key_id` and `qy_secret_access_key`, log in the web console of [QingCloud](https://console.qingcloud.com/login) and refer to the image below to create a key first. Download the key after it is created, which is stored in a csv file.
|
||||
|
||||

|
||||
|
||||
#### Zone
|
||||
|
||||
The field `zone` specifies where your cloud volumes are deployed. On QingCloud Platform, you must select a zone before you create volumes.
|
||||
|
||||

|
||||
|
||||
Make sure the value you specify for `zone` matches the region ID below:
|
||||
|
||||
| Zone | Region ID |
|
||||
| ------------------------------------------- | ----------------------- |
|
||||
| Shanghai1-A/Shanghai1-B | sh1a/sh1b |
|
||||
| Beijing3-A/Beijing3-B/Beijing3-C/Beijing3-D | pek3a/pek3b/pek3c/pek3d |
|
||||
| Guangdong2-A/Guangdong2-B | gd2a/gd2b |
|
||||
| Asia-Pacific 2-A | ap2a |
|
||||
|
||||
If you want to configure more values, see [chart configuration for QingCloud CSI](https://github.com/kubesphere/helm-charts/tree/master/src/test/csi-qingcloud#configuration).
|
||||
|
||||
### Add-on Config
|
||||
|
|
|
|||
|
|
@ -464,7 +464,7 @@ spec:
|
|||
enabled: false
|
||||
notification: # It supports notification management in multi-tenant Kubernetes clusters. It allows you to set AlertManager as its sender, and receivers include Email, Wechat Work, and Slack.
|
||||
enabled: false
|
||||
openpitrix: # Whether to install KubeSphere Application Store. It provides an application store for Helm-based applications, and offer application lifecycle management
|
||||
openpitrix: # Whether to install KubeSphere App Store. It provides an application store for Helm-based applications, and offer application lifecycle management
|
||||
enabled: false
|
||||
servicemesh: # Whether to install KubeSphere Service Mesh (Istio-based). It provides fine-grained traffic management, observability and tracing, and offer visualization for traffic topology
|
||||
enabled: false
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Multi-cluster management requires Kubesphere to be installed on the target clust
|
|||
|
||||
## Agent Connection
|
||||
|
||||
The component [Tower](https://github.com/kubesphere/tower) of KubeSphere is used for agent connection. Tower is a tool for network connection between clusters through the agent. If the H Cluster cannot access the M Cluster directly, you can expose the proxy service address of the H cluster. This enables the M Cluster to connect to the H cluster through the agent. This method is applicable when the M Cluster is in a private environment (e.g. IDC) and the H Cluster is able to expose the proxy service. The agent connection is also applicable when your clusters are distributed across different cloud providers.
|
||||
The component [Tower](https://github.com/kubesphere/tower) of KubeSphere is used for agent connection. Tower is a tool for network connection between clusters through the agent. If the Host Cluster (hereafter referred to as H Cluster) cannot access the Member Cluster (hereafter referred to as M Cluster) directly, you can expose the proxy service address of the H cluster. This enables the M Cluster to connect to the H cluster through the agent. This method is applicable when the M Cluster is in a private environment (e.g. IDC) and the H Cluster is able to expose the proxy service. The agent connection is also applicable when your clusters are distributed across different cloud providers.
|
||||
|
||||
### Prepare a Host Cluster
|
||||
|
||||
|
|
@ -28,13 +28,13 @@ If you already have a standalone KubeSphere installed, you can set the value of
|
|||
|
||||
- Option A - Use Web Console:
|
||||
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
|
||||
- Option B - Use Kubectl:
|
||||
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
|
||||
Scroll down and set the value of `clusterRole` to `host`, then click **Update** (if you use the web console) to make it effective:
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ multicluster:
|
|||
|
||||
{{< tab "KubeSphere has not been installed" >}}
|
||||
|
||||
There is no big difference if you define a host cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
There is no big difference than installing a standalone KubeSphere if you define a host cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
|
||||
```yaml
|
||||
multicluster:
|
||||
|
|
@ -93,40 +93,40 @@ Note: Generally, there is always a LoadBalancer solution in the public cloud, an
|
|||
|
||||
1. If you cannot see a corresponding address displayed (the EXTERNAL-IP is pending), you need to manually set the proxy address. For example, you have an available public IP address `139.198.120.120`, and the port `8080` of this IP address has been forwarded to the port `30721` of the cluster. Execute the following command to check the service.
|
||||
|
||||
```shell
|
||||
kubectl -n kubesphere-system get svc
|
||||
```
|
||||
```shell
|
||||
kubectl -n kubesphere-system get svc
|
||||
```
|
||||
|
||||
```shell
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
tower LoadBalancer 10.233.63.191 <pending> 8080:30721/TCP 16h
|
||||
```
|
||||
```shell
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
tower LoadBalancer 10.233.63.191 <pending> 8080:30721/TCP 16h
|
||||
```
|
||||
|
||||
2. Add the value of `proxyPublishAddress` to the configuration file of ks-installer and input the public IP address and port number as follows.
|
||||
|
||||
- Option A - Use Web Console:
|
||||
- Option A - Use Web Console:
|
||||
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
|
||||
- Option B - Use Kubectl:
|
||||
- Option B - Use Kubectl:
|
||||
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit clusterconfiguration ks-installer
|
||||
```
|
||||
```bash
|
||||
kubectl -n kubesphere-system edit clusterconfiguration ks-installer
|
||||
```
|
||||
|
||||
Navigate to `multicluster` and add a new line for `proxyPublishAddress` to define the IP address so access tower.
|
||||
Navigate to `multicluster` and add a new line for `proxyPublishAddress` to define the IP address so access tower.
|
||||
|
||||
```yaml
|
||||
multicluster:
|
||||
clusterRole: host
|
||||
proxyPublishAddress: http://139.198.120.120:8080 # Add this line to set the address to access tower
|
||||
```
|
||||
```yaml
|
||||
multicluster:
|
||||
clusterRole: host
|
||||
proxyPublishAddress: http://139.198.120.120:8080 # Add this line to set the address to access tower
|
||||
```
|
||||
|
||||
3. Save the configuration and restart `ks-apiserver`.
|
||||
3. Save the configuration and wait for a while, or you can manually restart `ks-apiserver` to make the change effective immediately using the following command.
|
||||
|
||||
```shell
|
||||
kubectl -n kubesphere-system rollout restart deployment ks-apiserver
|
||||
```
|
||||
```shell
|
||||
kubectl -n kubesphere-system rollout restart deployment ks-apiserver
|
||||
```
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
|
|
@ -154,13 +154,13 @@ If you already have a standalone KubeSphere installed, you can set the value of
|
|||
|
||||
- Option A - Use Web Console:
|
||||
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
|
||||
- Option B - Use Kubectl:
|
||||
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
|
||||
Input the corresponding `jwtSecret` shown above:
|
||||
|
||||
|
|
@ -180,7 +180,7 @@ multicluster:
|
|||
|
||||
{{< tab "KubeSphere has not been installed" >}}
|
||||
|
||||
There is no big difference if you define a member cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
There is no big difference than installing a standalone KubeSphere if you define a member cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
|
||||
```yaml
|
||||
authentication:
|
||||
|
|
@ -198,23 +198,18 @@ multicluster:
|
|||
|
||||
{{</ tabs >}}
|
||||
|
||||
|
||||
### Import Cluster
|
||||
|
||||
1. Open the H Cluster dashboard and click **Add Cluster**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Enter the basic information of the cluster to be imported and click **Next**.
|
||||

|
||||
|
||||

|
||||
3. In **Connection Method**, select **Cluster connection agent** and click **Import**. It will show the agent deployment generated by the H Cluster in the console.
|
||||

|
||||
|
||||
3. In **Connection Method**, select **Cluster connection agent** and click **Import**.
|
||||
|
||||

|
||||
|
||||
4. Create an `agent.yaml` file in the M Cluster based on the instruction, then copy and paste the deployment to the file. Execute `kubectl create -f agent.yaml` on the node and wait for the agent to be up and running. Please make sure the proxy address is accessible to the M Cluster.
|
||||
4. Create an `agent.yaml` file in the M Cluster based on the instruction, then copy and paste the agent deployment to the file. Execute `kubectl create -f agent.yaml` on the node and wait for the agent to be up and running. Please make sure the proxy address is accessible to the M Cluster.
|
||||
|
||||
5. You can see the cluster you have imported in the H Cluster when the cluster agent is up and running.
|
||||
|
||||

|
||||

|
||||
|
|
|
|||
|
|
@ -28,13 +28,13 @@ If you already have a standalone KubeSphere installed, you can set the value of
|
|||
|
||||
- Option A - Use Web Console:
|
||||
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
|
||||
- Option B - Use Kubectl:
|
||||
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
|
||||
Scroll down and set the value of `clusterRole` to `host`, then click **Update** (if you use the web console) to make it effective:
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ multicluster:
|
|||
|
||||
{{< tab "KubeSphere has not been installed" >}}
|
||||
|
||||
There is no big difference if you define a host cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
There is no big difference than installing a standalone KubeSphere if you define a host cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
|
||||
```yaml
|
||||
multicluster:
|
||||
|
|
@ -86,13 +86,13 @@ If you already have a standalone KubeSphere installed, you can set the value of
|
|||
|
||||
- Option A - Use Web Console:
|
||||
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
Use `admin` account to log in the console and go to **CRDs** on the **Cluster Management** page. Enter the keyword `ClusterConfiguration` and go to its detail page. Edit the YAML of `ks-installer`, which is similar to [Enable Pluggable Components](../../../pluggable-components/).
|
||||
|
||||
- Option B - Use Kubectl:
|
||||
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
```shell
|
||||
kubectl edit cc ks-installer -n kubesphere-system
|
||||
```
|
||||
|
||||
Input the corresponding `jwtSecret` shown above:
|
||||
|
||||
|
|
@ -112,7 +112,7 @@ multicluster:
|
|||
|
||||
{{< tab "KubeSphere has not been installed" >}}
|
||||
|
||||
There is no big difference if you define a member cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
There is no big difference than installing a standalone KubeSphere if you define a member cluster before installation. Please note that the `clusterRole` in `config-sample.yaml` or `cluster-configuration.yaml` has to be set as follows:
|
||||
|
||||
```yaml
|
||||
authentication:
|
||||
|
|
@ -139,23 +139,18 @@ kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=
|
|||
### Import Cluster
|
||||
|
||||
1. Open the H Cluster dashboard and click **Add Cluster**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Enter the basic information of the cluster to be imported and click **Next**.
|
||||
|
||||

|
||||

|
||||
|
||||
3. In **Connection Method**, select **Direct Connection to Kubernetes cluster**.
|
||||
|
||||
4. [Retrieve the KubeConfig](../retrieve-kubeconfig), copy the KubeConfig of the Member Cluster and paste it into the box.
|
||||
|
||||
{{< notice tip >}}
|
||||
Please make sure the `server` address in KubeConfig is accessible on any node of the H Cluster. For `KubeSphere API Server` address, you can fill in the KubeSphere APIServer address or leave it blank.
|
||||
{{</ notice >}}
|
||||
|
||||

|
||||
{{< notice tip >}}
|
||||
Please make sure the `server` address in KubeConfig is accessible on any node of the H Cluster.
|
||||
{{</ notice >}}
|
||||

|
||||
|
||||
5. Click **Import** and wait for cluster initialization to finish.
|
||||
|
||||

|
||||

|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ weight: 3545
|
|||
|
||||
Alerting and Notification are two important building blocks of observability, closely related monitoring and logging. The alerting system in KubeSphere, coupled with the proactive failure notification system, allows users to know activities of interest based on alert policies. When a predefined threshold of a certain metric is reached, an alert will be sent to preconfigured recipients, the notification method of which can be set by yourself, including Email, WeChat Work and Slack. With a highly functional alerting and notification system in place, you can quickly identify and resolve potential issues in advance before they affect your business.
|
||||
|
||||
For more information, see Alerting Policy and Message.
|
||||
For more information, see [Alerting Policy](../../project-user-guide/alerting/alerting-policy) and [Alerting Message](../../project-user-guide/alerting/alerting-message).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -23,99 +23,92 @@ It is recommended that you enable Alerting and Notification together so that use
|
|||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Alerting and Notification in this mode (e.g. for testing purpose), refer to the following section to see how Alerting and Notification can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `alerting` and `notification` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) for cluster setting. If you want to install Alerting and Notification, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional components Alerting and Notification need to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/kubesphere-installer.yaml). After that, to enable Alerting and Notification, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `alerting` and `notification` and enable them by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `alerting` and `notification` and enable them by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Alerting and Notification after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `alerting` and `notification` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
alerting:
|
||||
enabled: true # Change "false" to "true"
|
||||
notification:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -15,99 +15,92 @@ Internally, KubeSphere App Store can serve as a place for different teams to sha
|
|||
|
||||

|
||||
|
||||
For more information, see App Store.
|
||||
For more information, see [App Store](../../application-store/).
|
||||
|
||||
## Enable App Store before Installation
|
||||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable App Store in this mode (e.g. for testing purpose), refer to the following section to see how App Store can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `openpitrix` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install App Store, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component App Store needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable App Store, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `openpitrix` and enable App Store by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `openpitrix` and enable App Store by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable App Store after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `openpitrix` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
openpitrix:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -7,157 +7,144 @@ linkTitle: "KubeSphere Auditing Logs"
|
|||
weight: 3525
|
||||
---
|
||||
|
||||
## What are KubeSphere Auditing Logs?
|
||||
## What are KubeSphere Auditing Logs
|
||||
|
||||
KubeSphere Auditing Log System provides a security-relevant chronological set of records documenting the sequence of activities related to individual users, managers, or other components of the system. Each request to KubeSphere generates an event that is then written to a webhook and processed according to a certain rule.
|
||||
|
||||
For more information, see Logging, Events, and Auditing.
|
||||
For more information, see [Auditing Log Query](../../toolbox/auditing/auditing-query).
|
||||
|
||||
## Enable Auditing Logs before Installation
|
||||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Auditing in this mode (e.g. for testing purpose), refer to the following section to see how Auditing can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `auditing` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, KubeKey will install Elasticsearch internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following values in **config-sample.yaml** if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, KubeKey will install Elasticsearch internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following value in **config-sample.yaml** if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install Auditing, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component Auditing needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable Auditing, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `auditing` and enable Auditing by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `auditing` and enable Auditing by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, ks-installer will install Elasticsearch internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following values in **cluster-configuration.yaml** if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, ks-installer will install Elasticsearch internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following value in **cluster-configuration.yaml** if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
{{</ notice >}}
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Auditing Logs after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `auditing` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
auditing:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, Elasticsearch will be installed internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following values in this yaml file if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, Elasticsearch will be installed internally if Auditing is enabled. For a production environment, it is highly recommended that you set the following value in this yaml file if you want to enable Auditing, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
@ -183,7 +170,7 @@ kubectl get pod -n kubesphere-logging-system
|
|||
|
||||
The output may look as follows if the component runs successfully:
|
||||
|
||||
```bash
|
||||
```yaml
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
elasticsearch-logging-curator-elasticsearch-curator-159872n9g9g 0/1 Completed 0 2d10h
|
||||
elasticsearch-logging-curator-elasticsearch-curator-159880tzb7x 0/1 Completed 0 34h
|
||||
|
|
|
|||
|
|
@ -13,99 +13,92 @@ KubeSphere DevOps System is designed for CI/CD workflows in Kubernetes. Based on
|
|||
|
||||
The DevOps system offers an enabling environment for users as apps can be automatically released to the same platform. It is also compatible with third-party private image registries (e.g. Harbor) and code repositories (e.g. GitLab/GitHub/SVN/BitBucket). As such, it creates excellent user experiences by providing users with comprehensive, visualized CI/CD pipelines which are extremely useful in air-gapped environments.
|
||||
|
||||
For more information, see DevOps Administration.
|
||||
For more information, see [DevOps User Guide](../../devops-user-guide/).
|
||||
|
||||
## Enable DevOps before Installation
|
||||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable DevOps in this mode (e.g. for testing purpose), refer to the following section to see how DevOps can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `devops` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install DevOps, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component DevOps needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable DevOps, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `devops` and enable DevOps by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `devops` and enable DevOps by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable DevOps after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `devops` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
devops:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -11,153 +11,140 @@ weight: 3530
|
|||
|
||||
KubeSphere events allow users to keep track of what is happening inside a cluster, such as node scheduling status and image pulling result. They will be accurately recorded with the specific reason, status and message displayed in the web console. To query events, users can quickly launch the web Toolkit and enter related information in the search bar with different filters (e.g keyword and project) available. Events can also be archived to third-party tools, such as Elasticsearch, Kafka or Fluentd.
|
||||
|
||||
For more information, see Logging, Events and Auditing.
|
||||
For more information, see [Events Query](../../toolbox/events-query).
|
||||
|
||||
## Enable Events before Installation
|
||||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Events in this mode (e.g. for testing purpose), refer to the following section to see how Events can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `events` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, KubeKey will install Elasticsearch internally if Events is enabled. For a production environment, it is highly recommended that you set the following values in **config-sample.yaml** if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, KubeKey will install Elasticsearch internally if Events is enabled. For a production environment, it is highly recommended that you set the following value in **config-sample.yaml** if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) for cluster setting. If you want to install Events, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component Events needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/kubesphere-installer.yaml). After that, to enable Events, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `events` and enable Events by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `events` and enable Events by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, ks-installer will install Elasticsearch internally if Events is enabled. For a production environment, it is highly recommended that you set the following values in **cluster-configuration.yaml** if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, ks-installer will install Elasticsearch internally if Events is enabled. For a production environment, it is highly recommended that you set the following value in **cluster-configuration.yaml** if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
{{</ notice >}}
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Events after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `events` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
events:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, Elasticsearch will be installed internally if Events is enabled. For a production environment, it is highly recommended that you set the following values in this yaml file if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, Elasticsearch will be installed internally if Events is enabled. For a production environment, it is highly recommended that you set the following value in this yaml file if you want to enable Events, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -7,13 +7,22 @@ linkTitle: "Logging"
|
|||
weight: 3535
|
||||
---
|
||||
|
||||
## How to change the log store to external elasticsearch and shut down the internal elasticsearch?
|
||||
- [How to change the log store to external elasticsearch and shut down the internal elasticsearch](#how-to-change-the-log-store-to-external-elasticsearch-and-shut-down-the-internal-elasticsearch)
|
||||
- [How to change the log store to elasticsearch with X-Pack Security enabled](#how-to-change-the-log-store-to-elasticsearch-with-x-pack-security-enabled)
|
||||
- [How to modify log data retention days](#how-to-modify-log-data-retention-days)
|
||||
- [Cannot find out logs from workloads on some nodes in Toolbox](#cannot-find-out-logs-from-workloads-on-some-nodes-in-toolbox)
|
||||
- [The log view page in Toolbox gets stuck in loading](#the-log-view-page-in-toolbox-gets-stuck-in-loading)
|
||||
- [Toolbox shows no log record today](#toolbox-shows-no-log-record-today)
|
||||
- [Internal Server Error when viewing logs in Toolbox](#internal-server-error-when-viewing-logs-in-toolbox)
|
||||
- [How to make KubeSphere only collect logs from specified workloads](#how-to-make-kubesphere-only-collect-logs-from-specified-workloads)
|
||||
|
||||
## How to change the log store to external elasticsearch and shut down the internal elasticsearch
|
||||
|
||||
If you are using KubeSphere internal elasticsearch and want to change it to your external alternate, follow the guide below. Otherwise, if you haven't enabled logging system yet, go to [Enable Logging](../../logging/) to setup external elasticsearch directly.
|
||||
|
||||
First, update KubeKey config.
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl edit cc -n kubesphere-system ks-installer
|
||||
```
|
||||
|
||||
|
|
@ -21,51 +30,51 @@ kubectl edit cc -n kubesphere-system ks-installer
|
|||
|
||||
- Set `es.externalElasticsearchUrl` to the address of your elasticsearch and `es.externalElasticsearchPort` to its port number.
|
||||
|
||||
```shell
|
||||
apiVersion: installer.kubesphere.io/v1alpha1
|
||||
kind: ClusterConfiguration
|
||||
metadata:
|
||||
name: ks-installer
|
||||
namespace: kubesphere-system
|
||||
...
|
||||
spec:
|
||||
...
|
||||
common:
|
||||
es:
|
||||
# elasticsearchDataReplicas: 1
|
||||
# elasticsearchDataVolumeSize: 20Gi
|
||||
# elasticsearchMasterReplicas: 1
|
||||
# elasticsearchMasterVolumeSize: 4Gi
|
||||
elkPrefix: logstash
|
||||
logMaxAge: 7
|
||||
externalElasticsearchUrl: <192.168.0.2>
|
||||
externalElasticsearchPort: <9200>
|
||||
...
|
||||
status:
|
||||
...
|
||||
# logging:
|
||||
# enabledTime: 2020-08-10T02:05:13UTC
|
||||
# status: enabled
|
||||
...
|
||||
```
|
||||
```yaml
|
||||
apiVersion: installer.kubesphere.io/v1alpha1
|
||||
kind: ClusterConfiguration
|
||||
metadata:
|
||||
name: ks-installer
|
||||
namespace: kubesphere-system
|
||||
...
|
||||
spec:
|
||||
...
|
||||
common:
|
||||
es:
|
||||
# elasticsearchDataReplicas: 1
|
||||
# elasticsearchDataVolumeSize: 20Gi
|
||||
# elasticsearchMasterReplicas: 1
|
||||
# elasticsearchMasterVolumeSize: 4Gi
|
||||
elkPrefix: logstash
|
||||
logMaxAge: 7
|
||||
externalElasticsearchUrl: <192.168.0.2>
|
||||
externalElasticsearchPort: <9200>
|
||||
...
|
||||
status:
|
||||
...
|
||||
# logging:
|
||||
# enabledTime: 2020-08-10T02:05:13UTC
|
||||
# status: enabled
|
||||
...
|
||||
```
|
||||
|
||||
Second, rerun ks-installer.
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl rollout restart deploy -n kubesphere-system ks-installer
|
||||
```
|
||||
|
||||
Finally, to remove the internal elasticsearch, run the following command. Please make sure you have backed up data in the internal elasticsearch.
|
||||
|
||||
```shell
|
||||
```bash
|
||||
helm uninstall -n kubesphere-logging-system elasticsearch-logging
|
||||
```
|
||||
|
||||
## How to change the log store to elasticsearch with X-Pack Security enabled?
|
||||
## How to change the log store to elasticsearch with X-Pack Security enabled
|
||||
|
||||
Currently, KubeSphere doesn't support integration with elasticsearch having X-Pack Security enabled. This feature is coming soon.
|
||||
|
||||
## How to modify log data retention days?
|
||||
## How to modify log data retention days
|
||||
|
||||
You need update KubeKey config and rerun ks-installer.
|
||||
|
||||
|
|
@ -77,53 +86,53 @@ kubectl edit cc -n kubesphere-system ks-installer
|
|||
|
||||
- Set `es.logMaxAge` to the desired days (7 by default)
|
||||
|
||||
```shell
|
||||
apiVersion: installer.kubesphere.io/v1alpha1
|
||||
kind: ClusterConfiguration
|
||||
metadata:
|
||||
name: ks-installer
|
||||
namespace: kubesphere-system
|
||||
...
|
||||
spec:
|
||||
...
|
||||
common:
|
||||
es:
|
||||
...
|
||||
logMaxAge: <7>
|
||||
...
|
||||
status:
|
||||
...
|
||||
# logging:
|
||||
# enabledTime: 2020-08-10T02:05:13UTC
|
||||
# status: enabled
|
||||
...
|
||||
```
|
||||
```yaml
|
||||
apiVersion: installer.kubesphere.io/v1alpha1
|
||||
kind: ClusterConfiguration
|
||||
metadata:
|
||||
name: ks-installer
|
||||
namespace: kubesphere-system
|
||||
...
|
||||
spec:
|
||||
...
|
||||
common:
|
||||
es:
|
||||
...
|
||||
logMaxAge: <7>
|
||||
...
|
||||
status:
|
||||
...
|
||||
# logging:
|
||||
# enabledTime: 2020-08-10T02:05:13UTC
|
||||
# status: enabled
|
||||
...
|
||||
```
|
||||
|
||||
- Rerun ks-installer
|
||||
Rerun ks-installer
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl rollout restart deploy -n kubesphere-system ks-installer
|
||||
```
|
||||
|
||||
## Cannot find out logs from workloads on some nodes in Toolbox.
|
||||
## Cannot find out logs from workloads on some nodes in Toolbox
|
||||
|
||||
If you adopt [Multi-node installation](../../installing-on-linux/introduction/multioverview/) and are using symbolic links for docker root directory, make sure all nodes follow the exactly same symbolic links. Logging agents are deployed in DaemonSet onto nodes. Any discrepancy in container log paths may cause failure of collection on that node.
|
||||
If you adopt [Multi-node installation](../../../installing-on-linux/introduction/multioverview/) and are using symbolic links for docker root directory, make sure all nodes follow the exactly same symbolic links. Logging agents are deployed in DaemonSet onto nodes. Any discrepancy in container log paths may cause failure of collection on that node.
|
||||
|
||||
To find out the docker root directory path on nodes, you can run the following command. Make sure the same value applies to all nodes.
|
||||
|
||||
```
|
||||
```bash
|
||||
docker info -f '{{.DockerRootDir}}'
|
||||
```
|
||||
|
||||
## The log view page in Toolbox gets stuck in loading.
|
||||
## The log view page in Toolbox gets stuck in loading
|
||||
|
||||
If you observe log searching gets stuck in loading, please check the storage system you are using. For example, a malconfigured NFS storage system may cause this issue.
|
||||
|
||||
## Toolbox shows no log record today
|
||||
|
||||
Please check if your log volume exceeds the storage capacity limit of elasticsearch. If so, increase elasticsearch disk volume.
|
||||
Please check if your log volume exceeds the storage capacity limit of elasticsearch. If so, increase elasticsearch disk volume.
|
||||
|
||||
## Internal Server Error when viewing logs in Toolbox
|
||||
## Internal Server Error when viewing logs in Toolbox
|
||||
|
||||
If you observe Internal Server Error in the Toolbox, there may be several reasons leading to this issue:
|
||||
|
||||
|
|
@ -131,14 +140,14 @@ If you observe Internal Server Error in the Toolbox, there may be several reason
|
|||
- Invalid elasticsearch host and port
|
||||
- Elasticsearch health status is red
|
||||
|
||||
## How to make KubeSphere only collect logs from specified workloads?
|
||||
## How to make KubeSphere only collect logs from specified workloads
|
||||
|
||||
KubeSphere logging agent is powered by Fluent Bit. You need update Fluent Bit config to exclude certain workload logs. To modify Fluent Bit input config, run the following command:
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl edit input -n kubesphere-logging-system tail
|
||||
```
|
||||
|
||||
Update the field `Input.Spec.Tail.ExcludePath`. For example, set the path to `/var/log/containers/*_kube*-system_*.log` to exclude any log from system components.
|
||||
|
||||
Read the project [Fluent Bit Operator](https://github.com/kubesphere/fluentbit-operator) for more information.
|
||||
Read the project [Fluent Bit Operator](https://github.com/kubesphere/fluentbit-operator) for more information.
|
||||
|
|
|
|||
|
|
@ -7,25 +7,34 @@ linkTitle: "Monitoring"
|
|||
weight: 3540
|
||||
---
|
||||
|
||||
## How to access KubeSphere Prometheus console?
|
||||
- [How to access KubeSphere Prometheus console](#how-to-access-kubesphere-prometheus-console)
|
||||
- [Host port 9100 conflict caused by node exporter](#host-port-9100-conflict-caused-by-node-exporter)
|
||||
- [Conflicts with preexisting prometheus operator](#conflicts-with-preexisting-prometheus-operator)
|
||||
- [How to modify monitoring data retention days](#how-to-modify-monitoring-data-retention-days)
|
||||
- [No monitoring data for kube-scheduler and kube-controller-manager](#no-monitoring-data-for-kube-scheduler-and-kube-controller-manager)
|
||||
- [No monitoring data for the last few minutes](#no-monitoring-data-for-the-last-few-minutes)
|
||||
- [No monitoring data for both nodes and the control plane](#no-monitoring-data-for-both-nodes-and-the-control-plane)
|
||||
- [Prometheus produces error log: opening storage failed, no such file or directory](#prometheus-produces-error-log-opening-storage-failed-no-such-file-or-directory)
|
||||
|
||||
## How to access KubeSphere Prometheus console
|
||||
|
||||
KubeSphere monitoring engine is powered by Prometheus. For debugging purpose, you may want to access the built-in Prometheus service via NodePort. To do so, run the following command to edit the service type:
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl edit svc -n kubesphere-monitoring-system prometheus-k8s
|
||||
```
|
||||
```
|
||||
|
||||
## Host port 9100 conflict caused by node exporter
|
||||
|
||||
If you have processes occupying host port 9100, node exporter under `kubesphere-monitoring-system` will be crashing. To resolve the conflict, you need to either terminate the process or change node exporter to another available port.
|
||||
|
||||
To adopt another host port, for example `29100`, run the following command and replace all `9100` to `29100` (5 places require change).
|
||||
|
||||
```shell
|
||||
|
||||
```bash
|
||||
kubectl edit ds -n kubesphere-monitoring-system node-exporter
|
||||
```
|
||||
|
||||
```shell
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: DaemonSet
|
||||
metadata:
|
||||
|
|
@ -60,21 +69,21 @@ If you have processes occupying host port 9100, node exporter under `kubesphere-
|
|||
|
||||
If you have deployed Prometheus Operator on your own, make sure the Prometheus Operator gets removed before you installing KubeSphere. Otherwise, there may be conflicts that KubeSphere built-in prometheus operator selects duplicate ServiceMonitor objects.
|
||||
|
||||
## How to modify monitoring data retention days?
|
||||
## How to modify monitoring data retention days
|
||||
|
||||
Run the following command to edit the max retention days. Find out the field `retention` and update it to the desired days (7 by default).
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl edit prometheuses -n kubesphere-monitoring-system k8s
|
||||
```
|
||||
|
||||
## No monitoring data for kube-scheduler / kube-controller-manager
|
||||
## No monitoring data for kube-scheduler and kube-controller-manager
|
||||
|
||||
First, please make sure the flag `--bind-address` is set to `0.0.0.0` (default) rather than `127.0.0.1`. Prometheus may need reachability to theses components from other hosts.
|
||||
|
||||
Second, please check the presence of endpoint objects for kube-scheduler and kube-controller-manager. If they are missing, please create them manually by creating services selecting target pods.
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl get ep -n kube-system | grep -E 'kube-scheduler|kube-controller-manager'
|
||||
```
|
||||
|
||||
|
|
@ -92,13 +101,13 @@ Chinese readers may refer to [the discussion](https://kubesphere.com.cn/forum/d/
|
|||
|
||||
If the Prometheus pod under kubesphere-monitoring-system is crashing and produces the following error log, your Prometheus data may be corrupt and need manual deletion to recover.
|
||||
|
||||
```
|
||||
```shell
|
||||
level=error ts=2020-10-14T17:43:30.485Z caller=main.go:764 err="opening storage failed: block dir: \"/prometheus/01EM0016F8FB33J63RNHFMHK3\": open /prometheus/01EM0016F8FB33J63RNHFMHK3/meta.json: no such file or directory"
|
||||
```
|
||||
```
|
||||
|
||||
Exec into the Prometheus pod (if possible), and remove the block dir `/prometheus/01EM0016F8FB33J63RNHFMHK3`:
|
||||
|
||||
```shell
|
||||
```bash
|
||||
kubectl exec -it -n kubesphere-monitoring-system prometheus-k8s-0 -c prometheus sh
|
||||
|
||||
rm -rf 01EM0016F8FB33J63RNHFMHK3/
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ weight: 3535
|
|||
|
||||
KubeSphere provides a powerful, holistic and easy-to-use logging system for log collection, query and management. It covers logs at varied levels, including tenants, infrastructure resources, and applications. Users can search logs from different dimensions, such as project, workload, Pod and keyword. Compared with Kibana, the tenant-based logging system of KubeSphere features better isolation and security among tenants as each tenant can only view his or her own logs. Apart from KubeSphere's own logging system, the container platform also allows users to add third-party log collectors, such as Elasticsearch, Kafka and Fluentd.
|
||||
|
||||
For more information, see Logging, Events and Auditing.
|
||||
For more information, see [Log Query](../../toolbox/log-query).
|
||||
|
||||
## Enable Logging before Installation
|
||||
|
||||
|
|
@ -21,148 +21,134 @@ When you install KubeSphere on Linux, you need to create a configuration file, w
|
|||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Logging in this mode (e.g. for testing purpose), refer to the following section to see how Logging can be installed after installation.
|
||||
{{</ notice >}}
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
If you adopt [Multi-node installation](../../installing-on-linux/introduction/multioverview/) and are using symbolic links for docker root directory, make sure all nodes follow the exactly same symbolic links. Logging agents are deployed in DaemonSet onto nodes. Any discrepancy in container log path may cause failure of collection on that node.
|
||||
|
||||
{{</ notice >}}
|
||||
{{< notice warning >}}
|
||||
If you adopt [Multi-node installation](../../installing-on-linux/introduction/multioverview/) and are using symbolic links for docker root directory, make sure all nodes follow the exactly same symbolic links. Logging agents are deployed in DaemonSet onto nodes. Any discrepancy in container log path may cause failure of collection on that node.
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `logging` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, KubeKey will install Elasticsearch internally if Logging is enabled. For a production environment, it is highly recommended that you set the following values in **config-sample.yaml** if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, KubeKey will install Elasticsearch internally if Logging is enabled. For a production environment, it is highly recommended that you set the following value in **config-sample.yaml** if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, KubeKey will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install Logging, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component Logging needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable Logging, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `logging` and enable Logging by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `logging` and enable Logging by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, ks-installer will install Elasticsearch internally if Logging is enabled. For a production environment, it is highly recommended that you set the following values in **cluster-configuration.yaml** if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, ks-installer will install Elasticsearch internally if Logging is enabled. For a production environment, it is highly recommended that you set the following value in **cluster-configuration.yaml** if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information before installation, ks-installer will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
{{</ notice >}}
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Logging after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `logging` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
logging:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
{{< notice note >}}
|
||||
By default, Elasticsearch will be installed internally if Logging is enabled. For a production environment, it is highly recommended that you set the following values in this yaml file if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
{{</ notice >}}
|
||||
|
||||
By default, Elasticsearch will be installed internally if Logging is enabled. For a production environment, it is highly recommended that you set the following value in this yaml file if you want to enable Logging, especially `externalElasticsearchUrl` and `externalElasticsearchPort`. Once you provide the following information, KubeSphere will integrate your external Elasticsearch directly instead of installing an internal one.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```bash
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
```yaml
|
||||
es: # Storage backend for logging, tracing, events and auditing.
|
||||
elasticsearchMasterReplicas: 1 # total number of master nodes, it's not allowed to use even number
|
||||
elasticsearchDataReplicas: 1 # total number of data nodes
|
||||
elasticsearchMasterVolumeSize: 4Gi # Volume size of Elasticsearch master nodes
|
||||
elasticsearchDataVolumeSize: 20Gi # Volume size of Elasticsearch data nodes
|
||||
logMaxAge: 7 # Log retention time in built-in Elasticsearch, it is 7 days by default.
|
||||
elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log
|
||||
externalElasticsearchUrl: # The URL of external Elasticsearch
|
||||
externalElasticsearchPort: # The port of external Elasticsearch
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -24,93 +24,86 @@ For more information, see [Network Policies](https://kubernetes.io/docs/concepts
|
|||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Network Policy in this mode (e.g. for testing purpose), refer to the following section to see how Network Policy can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `networkpolicy` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) for cluster setting. If you want to install Network Policy, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component Network Polict needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/kubesphere-installer.yaml). After that, to enable Network Policy, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://raw.githubusercontent.com/kubesphere/ks-installer/master/deploy/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `networkpolicy` and enable Network Policy by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `networkpolicy` and enable Network Policy by changing `false` to `true` for `enabled`. Save the file after you finish..
|
||||
|
||||
```bash
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Network Policy after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `networkpolicy` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
networkpolicy:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -11,99 +11,92 @@ weight: 3540
|
|||
|
||||
On the basis of [Istio](https://istio.io/), KubeSphere Service Mesh visualizes microservices governance and traffic management. It features a powerful toolkit including **circuit breaking, blue-green deployment, canary release, traffic mirroring, distributed tracing, observability and traffic control**. Developers can easily get started with Service Mesh without any code hacking, with the learning curve of Istio greatly reduced. All features of KubeSphere Service Mesh are designed to meet users' demand for their business.
|
||||
|
||||
For more information, see related sections in Project Administration and Usage.
|
||||
For more information, see [Grayscale Release](../../project-user-guide/grayscale-release/overview).
|
||||
|
||||
## Enable Service Mesh before Installation
|
||||
|
||||
### Installing on Linux
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
```bash
|
||||
vi config-sample.yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable Service Mesh in this mode (e.g. for testing purpose), refer to the following section to see how Service Mesh can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, navigate to `servicemesh` and change `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
```bash
|
||||
./kk create cluster -f config-sample.yaml
|
||||
```
|
||||
|
||||
### **Installing on Kubernetes**
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install Service Mesh, do not use `kubectl apply -f` directly for this file.
|
||||
The process of installing KubeSphere on Kubernetes is same as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/) except the optional component Service Mesh needs to be enabled first in the [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml).
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable Service Mesh, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and open it for editing.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, navigate to `servicemesh` and enable Service Mesh by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
2. In this local cluster-configuration.yaml file, navigate to `servicemesh` and enable Service Mesh by changing `false` to `true` for `enabled`. Save the file after you finish.
|
||||
|
||||
```bash
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
4. Execute the following command to start installation:
|
||||
3. Execute the following commands to start installation:
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```bash
|
||||
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml
|
||||
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
## Enable Service Mesh after Installation
|
||||
|
||||
1. Log in the console as `admin`. Click **Platform** in the top-left corner and select **Clusters Management**.
|
||||
|
||||

|
||||

|
||||
|
||||
2. Click **CRDs** and enter `clusterconfiguration` in the search bar. Click the result to view its detailed page.
|
||||
|
||||
{{< notice info >}}
|
||||
|
||||
{{< notice info >}}
|
||||
A Custom Resource Definition (CRD) allows users to create a new type of resources without adding another API server. They can use these resources like any other native Kubernetes objects.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
3. In **Resource List**, click the three dots on the right of `ks-installer` and select **Edit YAML**.
|
||||
|
||||

|
||||

|
||||
|
||||
4. In this yaml file, navigate to `servicemesh` and change `false` to `true` for `enabled`. After you finish, click **Update** in the bottom-right corner to save the configuration.
|
||||
|
||||
```bash
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
```yaml
|
||||
servicemesh:
|
||||
enabled: true # Change "false" to "true"
|
||||
```
|
||||
|
||||
5. You can use the web kubectl to check the installation process by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
```bash
|
||||
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
|
||||
```
|
||||
|
||||
{{< notice tip >}}
|
||||
You can find the web kubectl tool by clicking the hammer icon in the bottom-right corner of the console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Verify the Installation of Component
|
||||
|
||||
|
|
|
|||
|
|
@ -1,10 +0,0 @@
|
|||
---
|
||||
title: "Application Template"
|
||||
keywords: 'kubernetes, chart, helm, KubeSphere, application'
|
||||
description: 'Application Template'
|
||||
|
||||
linkTitle: "Application Template"
|
||||
weight: 2210
|
||||
---
|
||||
|
||||
TBD
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
---
|
||||
linkTitle: "Application"
|
||||
weight: 2079
|
||||
|
||||
_build:
|
||||
render: false
|
||||
---
|
||||
|
||||
TBD
|
||||
|
|
@ -0,0 +1,53 @@
|
|||
---
|
||||
title: "Deploy Applications from App Store"
|
||||
keywords: 'kubernetes, chart, helm, KubeSphere, application'
|
||||
description: 'Deploy Applications from App Store'
|
||||
|
||||
|
||||
weight: 2209
|
||||
---
|
||||
|
||||
The application template is the storage, delivery, and management approach for the application in KubeSphere. The application template is built on the [Helm](https://helm.sh/) packaging specification and delivered through a unified public or private application repository. The application can be composed of one or more Kubernetes workloads and services according to the application's characteristics.
|
||||
|
||||
Application templates visualize and provide deployment and management capabilities in KubeSphere, enabling users to quickly deploy applications to pointed projects based on application templates. The application template can serve as a middleware and business system created by the enterprise, which could be shared between the teams. It can also be used as the basis for constructing industry delivery standards, delivery processes and paths according to industry characteristics.
|
||||
|
||||
Before using an application template, you need to add an application repository in advance. KubeSphere built an application repository service based on [OpenPitrix](https://openpitrix.io). Before using the application template, you need to upload the Helm application package to the object storage, then add an application repository in KubeSphere. It will automatically loads all the applications as App template under this repository, as described in [Add Application Repository](../deploy-app-from-repo).
|
||||
|
||||

|
||||
|
||||
In addition, application templates can also be combined with OpenPitrix's application lifecycle management capabilities to support docking ISV, and regular users through application uploading, application review, deployment testing, application publishing, application version management and more, finnaly build a public or private application store where offers application services for KubeSphere. Companies can also build industry-wide public or internal application stores to enable standardized one-click delivery of applications, see [OpenPitrix Official Documentation](https://openpitrix.io/docs/v0.4/zh-CN/manual-guide/introduction).
|
||||
|
||||
## Application List
|
||||
|
||||
In all projects, an **application** portal is provided, which serves as an entry point for the application template. Once the application is deployed, it can also be used as a list of applications to manage all applications under the current project.
|
||||
|
||||

|
||||
|
||||
Click **Deploy New Application** to go to the **App Templates** page.
|
||||
|
||||
## Application Template
|
||||
|
||||
### Add a sample repository
|
||||
|
||||
As mentioned earlier, before using an application template, the cluster admin needs to pre-add the available application repository so that users can access and deploy the application in the application template.
|
||||
|
||||
This document provides a sample application repository just for demonstration. Users can upload application packages in the object storage and add application repositories as needed.
|
||||
|
||||
1. Sign in with the cluster admin account to the KubeSphere and go into the target workspace, then choose **App Management → App Repos** to enter the list page.
|
||||
|
||||

|
||||
|
||||
2. Click **Add Repo** button.
|
||||
|
||||
3. Fill in the basic information in the pop-up window, select https for the URL, fill in the blank with `https://helm-chart-repo.pek3a.qingstor.com/kubernetes-charts/`, then click the **Validate** button. After the validation is passed, click **OK** to complete it.
|
||||
|
||||

|
||||

|
||||
|
||||
### Access the application templates
|
||||
|
||||
Log out and switch to sign in with project-regular account, the normal user of the project and go into the target project, then choose **Application Workloads → Applications → Deploy New Application → From App Templates → docs-demo-repo**, you can see that all the applications in the sample application repository have been imported into the application template, then you will be able to browse or search for the desired app for one-click deployment to the desired project.
|
||||
|
||||

|
||||
|
||||

|
||||
|
|
@ -0,0 +1,91 @@
|
|||
---
|
||||
title: "Deploy Applications from App Repository"
|
||||
keywords: 'kubernetes, chart, helm, KubeSphere, application'
|
||||
description: 'Deploy Applications from App Repository'
|
||||
|
||||
|
||||
weight: 2211
|
||||
---
|
||||
|
||||
## Objective
|
||||
|
||||
This tutorial shows you how to quickly deploy a [Grafana](https://grafana.com/) application using templates from KubeSphere application store sponsored by [OpenPitrix](https://github.com/openpitrix/openpitirx). The demonstration includes importing application repository, sharing and deploying apps within a workspace.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere App Store](../../pluggable-components/app-store)
|
||||
- You have completed the tutorial in [Create Workspace, Project, Account and Role](../../quick-start/create-workspace-and-project/)
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Add an Application Repository
|
||||
|
||||
> Note: The application repository can be hosted by either object storage, e.g. [QingStor Object Storage](https://www.qingcloud.com/products/qingstor/), [AWS S3](https://aws.amazon.com/what-is-cloud-object-storage/), or by [GitHub Repository](https://github.com/). The packages are composed of Helm Chart template files of the applications. Therefore, before adding an application repository to KubeSphere, you need to create an object storage bucket and upload Helm packages in advance. This tutorial prepares a demo repository based on QingStor Object Storage.
|
||||
|
||||
1.1. Sign in with `ws-admin` account, click **View Workspace** and navigate to **Workspace Settings → App Repos**, then click **Create App Repository**.
|
||||
|
||||

|
||||
|
||||
1.2. Fill in the basic information, name it `demo-repo` and input the URL `https://helm-chart-repo.pek3a.qingstor.com/kubernetes-charts/`. You can validate if this URL is available, and choose **OK** when you have done.
|
||||
|
||||
> Note: It will automatically import all of the applications from the Helm repository into KubeSphere. You can browse those app templates in each project.
|
||||
|
||||

|
||||
|
||||
### Step 2: Browse App Templates
|
||||
|
||||
2.1. Switch to use `project-regular` account to log in, then enter into `demo-project`.
|
||||
|
||||
2.2. Click **Application Workloads → Applications**, click **Deploy New Application**.
|
||||
|
||||

|
||||
|
||||
2.3. Choose **From App Templates** and select `demo-repo` from the dropdown list.
|
||||
|
||||

|
||||
|
||||
2.4. Search `Grafana` and click into Grafana App. We will demonstrate deploying Grafana to Kubernetes as an example.
|
||||
|
||||
> Note: The applications of this demo repository are synchronized from the Google Helm repo. Some applications may not be able to be deployed successfully, since the helm charts were maintained by different organizations.
|
||||
|
||||
### Step 3: Deploy Grafana Application
|
||||
|
||||
3.1. Click **Deploy** on the right. Generally you do not need to change any configuration, just click **Deploy**.
|
||||
|
||||

|
||||
|
||||
3.2. Wait for two minutes, then you will see the application `grafana` showing `active` on the application list.
|
||||
|
||||

|
||||
|
||||
### Step 4: Expose Grafana Service
|
||||
|
||||
4.1. Click into Grafana application, and then enter into its service page.
|
||||
|
||||

|
||||
|
||||
4.2. In this page, make sure its deployment and Pod are running, then click **More → Edit Internet Access**, and select **NodePort** in the dropdown list, click **OK** to save it.
|
||||
|
||||

|
||||
|
||||
4.3. At this point, you will be able to access Grafana service from outside of the cluster.
|
||||
|
||||

|
||||
|
||||
### Step 5: Access the Grafana Service
|
||||
|
||||
In this step, we can access Grafana service using `${Node IP}:${NODEPORT}`, e.g. `http://192.168.0.54:31407`, or click the button **Click to visit** to access the Grafana dashboard.
|
||||
|
||||
5.1. Note you have to obtain the account and password from the grafana secret in advance. Navigate to **Configuration Center → Secrets**, click into **grafana-l47bmc** with Type Default.
|
||||
|
||||

|
||||
|
||||
5.2. Click the eye button to display the secret information, then copy and paste the values of **admin-user** and **admin-password** respectively.
|
||||
|
||||

|
||||
|
||||
5.3. Open the Grafana login page, sign in with the **admin** account.
|
||||
|
||||

|
||||
|
||||

|
||||
|
|
@ -0,0 +1,62 @@
|
|||
---
|
||||
title: "Deploy Applications from App Template"
|
||||
keywords: 'kubernetes, chart, helm, KubeSphere, application'
|
||||
description: 'Deploy Applications from App Template'
|
||||
|
||||
|
||||
weight: 2210
|
||||
---
|
||||
|
||||
## Objective
|
||||
|
||||
This tutorial shows you a simple example about how to quickly deploy a [Nginx](https://nginx.org/) application using templates from KubeSphere application store sponsored by [OpenPitrix](https://github.com/openpitrix/openpitirx). The demonstration includes one-click deploying apps within a workspace and exposing service by NodePort.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You have enabled [KubeSphere App Store](../../pluggable-components/app-store)
|
||||
- You have completed the tutorial in [Create Workspace, Project, Account and Role](../../quick-start/create-workspace-and-project/)
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Browse App Templates
|
||||
|
||||
1.1. Switch to use `project-regular` account to log in, then enter into `demo-project`.
|
||||
|
||||
1.2. Click **Application Workloads → Applications**, click **Deploy New Application**.
|
||||
|
||||

|
||||
|
||||
1.3. Choose **From App Store** and enter into app store.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
1.4. Search `Nginx` and click into Nginx App. We will demonstrate how to one-click deploying Nginx to Kubernetes.
|
||||
|
||||
### Step 2: One-click Deploy Nginx Application
|
||||
|
||||
2.1. Click **Deploy** on the right. Generally you do not need to change any configuration, just click **Deploy**.
|
||||
|
||||

|
||||
|
||||
2.2. Wait for two minutes, then you will see the application `nginx` showing `active` on the application list.
|
||||
|
||||

|
||||
|
||||
### Step 3: Expose Nginx Web Service
|
||||
|
||||
3.1. Click into Nginx application, and then enter into its service page.
|
||||
|
||||

|
||||
|
||||
3.2. In this page, make sure its deployment and Pod are running, then click **More → Edit Internet Access**, and select **NodePort** in the dropdown list, click **OK** to save it.
|
||||
|
||||

|
||||
|
||||
3.3. At this point, you will be able to access Nginx web service from outside of the cluster.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
|
@ -1,10 +1,100 @@
|
|||
---
|
||||
title: "Blue-green Deployment"
|
||||
keywords: 'KubeSphere, kubernetes, docker, helm, jenkins, istio, prometheus'
|
||||
description: 'Blue-green Deployment'
|
||||
keywords: 'KubeSphere, Kubernetes, service mesh, istio, release, blue-green deployment'
|
||||
description: 'How to implement blue-green deployment for an app.'
|
||||
|
||||
linkTitle: "Blue-green Deployment"
|
||||
weight: 2130
|
||||
---
|
||||
|
||||
TBD
|
||||
|
||||
The blue-green release provides a zero downtime deployment, which means the new version can be deployed with the old one preserved. At any time, only one of the versions is active serving all the traffic, while the other one remains idle. If there is a problem with running, you can quickly roll back to the old version.
|
||||
|
||||

|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to enable [KubeSphere Service Mesh](../../../pluggable-components/service-mesh/).
|
||||
- You need to create a workspace, a project and an account (`project-regular`). Please refer to [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project) if they are not ready yet.
|
||||
- You need to sign in with the `project-admin` account and invite `project-regular` to the corresponding project. Please refer to [these steps to invite a member](../../../quick-start/create-workspace-and-project#task-3-create-a-project).
|
||||
- You need to enable **Application Governance** and have an available app so that you can implement the blue-green deployment for it. The sample app used in this tutorial is Bookinfo. For more information, see [Deploy Bookinfo and Manage Traffic](../../../quick-start/deploy-bookinfo-to-k8s/).
|
||||
|
||||
## Create Blue-green Deployment Job
|
||||
|
||||
1. Log in KubeSphere as `project-regular`. Under **Categories**, click **Create Job** on the right of **Blue-green Deployment**.
|
||||
|
||||

|
||||
|
||||
2. Set a name for it and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. Select your app from the drop-down list and the service for which you want to implement the blue-green deployment. If you also use the sample app Bookinfo, select **reviews** and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. On the **Grayscale Release Version** page, add another version of it (e.g `v2`) as shown in the image below and click **Next**:
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The image version is `v2` in the screenshot.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. To allow the app version `v2` to take over all the traffic, select **Take over all traffic** and click **Create**.
|
||||
|
||||
|
||||

|
||||
|
||||
6. The blue-green deployment job created displays under the tab **Job Status**. Click it to view details.
|
||||
|
||||

|
||||
|
||||
7. Wait for a while and you can see all the traffic go to the version `v2`:
|
||||
|
||||

|
||||
|
||||
8. The new **Deployment** is created as well.
|
||||
|
||||

|
||||
|
||||
9. Besides, you can directly get the virtual service to identify the weight by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl -n demo-project get virtualservice -o yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- When you execute the command above, replace `demo-project` with your own project (i.e. namespace) name.
|
||||
- If you want to execute the command from the web kubectl on the KubeSphere console, you need to use the account `admin`.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
10. Expected output:
|
||||
|
||||
```yaml
|
||||
...
|
||||
spec:
|
||||
hosts:
|
||||
- reviews
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: reviews
|
||||
port:
|
||||
number: 9080
|
||||
subset: v2
|
||||
weight: 100
|
||||
...
|
||||
```
|
||||
|
||||
## Take a Job Offline
|
||||
|
||||
After you implement the blue-green deployment, and the result meets your expectation, you can take the task offline with the version `v1` removed by clicking **Job offline**.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -1,10 +1,108 @@
|
|||
---
|
||||
title: "Canary Release"
|
||||
keywords: 'KubeSphere, kubernetes, docker, helm, jenkins, istio, prometheus'
|
||||
description: 'Canary Release'
|
||||
keywords: 'KubeSphere, Kubernetes, canary release, istio, service mesh'
|
||||
description: 'How to implement the canary release for an app.'
|
||||
|
||||
linkTitle: "Canary Release"
|
||||
weight: 2130
|
||||
---
|
||||
|
||||
TBD
|
||||
On the back of [Istio](https://istio.io/), KubeSphere provides users with necessary control to deploy canary services. In a canary release, you introduce a new version of a service and test it by sending a small percentage of traffic to it. At the same time, the old version is responsible for handling the rest of the traffic. If everything goes well, you can gradually increase the traffic sent to the new version, while simultaneously phasing out the old version. In the case of any occurring issues, KubeSphere allows you to roll back to the previous version as you change the traffic percentage.
|
||||
|
||||
This method serves as an efficient way to test performance and reliability of a service. It can help detect potential problems in the actual environment while not affecting the overall system stability.
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to enable [KubeSphere Service Mesh](../../../pluggable-components/service-mesh/).
|
||||
- You need to create a workspace, a project and an account (`project-regular`). Please refer to [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project) if they are not ready yet.
|
||||
- You need to sign in with the `project-admin` account and invite `project-regular` to the corresponding project. Please refer to [these steps to invite a member](../../../quick-start/create-workspace-and-project#task-3-create-a-project).
|
||||
- You need to enable **Application Governance** and have an available app so that you can implement the canary release for it. The sample app used in this tutorial is Bookinfo. For more information, see [Deploy Bookinfo and Manage Traffic](../../../quick-start/deploy-bookinfo-to-k8s/).
|
||||
|
||||
## Create Canary Release Job
|
||||
|
||||
1. Log in KubeSphere as `project-regular`. Under **Categories**, click **Create Job** on the right of **Canary Release**.
|
||||
|
||||

|
||||
|
||||
2. Set a name for it and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. Select your app from the drop-down list and the service for which you want to implement the canary release. If you also use the sample app Bookinfo, select **reviews** and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. On the **Grayscale Release Version** page, add another version of it (e.g `v2`) as shown in the image below and click **Next**:
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The image version is `v2` in the screenshot.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. You send traffic to these two versions (`v1` and `v2`) either by a specific percentage or by the request content such as `Http Header`, `Cookie` and `URI`. Select **Forward by traffic ratio** and drag the icon in the middle to change the percentage of traffic sent to these two versions respectively (e.g. set 50% for either one). When you finish, click **Create**.
|
||||
|
||||

|
||||
|
||||
6. The canary release job created displays under the tab **Job Status**. Click it to view details.
|
||||
|
||||

|
||||
|
||||
7. Wait for a while and you can see half of the traffic go to each of them:
|
||||
|
||||

|
||||
|
||||
8. The new **Deployment** is created as well.
|
||||
|
||||

|
||||
|
||||
9. Besides, you can directly get the virtual service to identify the weight by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl -n demo-project get virtualservice -o yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- When you execute the command above, replace `demo-project` with your own project (i.e. namespace) name.
|
||||
- If you want to execute the command from the web kubectl on the KubeSphere console, you need to use the account `admin`.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
10. Expected output:
|
||||
|
||||
```yaml
|
||||
...
|
||||
spec:
|
||||
hosts:
|
||||
- reviews
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: reviews
|
||||
port:
|
||||
number: 9080
|
||||
subset: v1
|
||||
weight: 50
|
||||
- destination:
|
||||
host: reviews
|
||||
port:
|
||||
number: 9080
|
||||
subset: v2
|
||||
weight: 50
|
||||
...
|
||||
```
|
||||
## Take a Job Offline
|
||||
|
||||
1. After you implement the canary release, and the result meets your expectation, you can select **Take Over** from the menu, sending all the traffic to the new version.
|
||||
|
||||

|
||||
|
||||
2. To remove the old version with the new version handling all the traffic, click **Job offline**.
|
||||
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -1,10 +1,107 @@
|
|||
---
|
||||
title: "Traffic Mirroring"
|
||||
keywords: 'KubeSphere, kubernetes, docker, helm, jenkins, istio, prometheus'
|
||||
keywords: 'KubeSphere, Kubernetes, traffic mirroring, istio'
|
||||
description: 'Traffic Mirroring'
|
||||
|
||||
linkTitle: "Traffic Mirroring"
|
||||
weight: 2130
|
||||
---
|
||||
|
||||
TBD
|
||||
Traffic mirroring, also called shadowing, is a powerful, risk-free method of testing your app versions as it sends a copy of live traffic to a service that is being mirrored. Namely, you implement a similar setup for acceptance test so that problems can be detected in advance. As mirrored traffic happens out of band of the critical request path for the primary service, your end users will not be affected during the whole process.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to enable [KubeSphere Service Mesh](../../../pluggable-components/service-mesh/).
|
||||
- You need to create a workspace, a project and an account (`project-regular`). Please refer to [Create Workspace, Project, Account and Role](../../../quick-start/create-workspace-and-project) if they are not ready yet.
|
||||
- You need to sign in with the `project-admin` account and invite `project-regular` to the corresponding project. Please refer to [these steps to invite a member](../../../quick-start/create-workspace-and-project#task-3-create-a-project).
|
||||
- You need to enable **Application Governance** and have an available app so that you can mirror the traffic of it. The sample app used in this tutorial is Bookinfo. For more information, see [Deploy Bookinfo and Manage Traffic](../../../quick-start/deploy-bookinfo-to-k8s/).
|
||||
|
||||
## Create Traffic Mirroring Job
|
||||
|
||||
1. Log in KubeSphere as `project-regular`. Under **Categories**, click **Create Job** on the right of **Traffic Mirroring**.
|
||||
|
||||

|
||||
|
||||
2. Set a name for it and click **Next**.
|
||||
|
||||

|
||||
|
||||
3. Select your app from the drop-down list and the service of which you want to mirror the traffic. If you also use the sample app Bookinfo, select **reviews** and click **Next**.
|
||||
|
||||

|
||||
|
||||
4. On the **Grayscale Release Version** page, add another version of it (e.g. `v2`) as shown in the image below and click **Next**:
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The image version is `v2` in the screenshot.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
5. Click **Create** in the final step.
|
||||
|
||||

|
||||
|
||||
6. The traffic mirroring job created displays under the tab **Job Status**. Click it to view details.
|
||||
|
||||

|
||||
|
||||
7. You can see the traffic is being mirrored to `v2` with real-time traffic displaying in the line chart.
|
||||
|
||||

|
||||
|
||||
8. The new **Deployment** is created as well.
|
||||
|
||||

|
||||
|
||||
9. Besides, you can directly get the virtual service to view `mirror` and `weight` by executing the following command:
|
||||
|
||||
```bash
|
||||
kubectl -n demo-project get virtualservice -o yaml
|
||||
```
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- When you execute the command above, replace `demo-project` with your own project (i.e. namespace) name.
|
||||
- If you want to execute the command from the web kubectl on the KubeSphere console, you need to use the account `admin`.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
10. Expected output:
|
||||
|
||||
```
|
||||
...
|
||||
spec:
|
||||
hosts:
|
||||
- reviews
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: reviews
|
||||
port:
|
||||
number: 9080
|
||||
subset: v1
|
||||
weight: 100
|
||||
mirror:
|
||||
host: reviews
|
||||
port:
|
||||
number: 9080
|
||||
subset: v2
|
||||
...
|
||||
```
|
||||
|
||||
This route rule sends 100% of the traffic to `v1`. The last stanza specifies that you want to mirror to the service `reviews v2`. When traffic gets mirrored, the requests are sent to the mirrored service with their Host/Authority headers appended with `-shadow`. For example, `cluster-1` becomes `cluster-1-shadow`.
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
These requests are mirrored as “fire and forget”, which means that the responses are discarded. You can specify the `weight` field to mirror a fraction of the traffic, instead of mirroring all requests. If this field is absent, for compatibility with older versions, all traffic will be mirrored. For more information, see [Mirroring](https://istio.io/v1.5/pt-br/docs/tasks/traffic-management/mirroring/).
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
## Take a Job Offline
|
||||
|
||||
You can remove the traffic mirroring job by clicking **Job offline**, which does not affect the current app version.
|
||||
|
||||

|
||||
|
|
@ -7,4 +7,25 @@ linkTitle: "Volume Snapshots"
|
|||
weight: 2130
|
||||
---
|
||||
|
||||
TBD
|
||||
## Introduction
|
||||
Many storage systems provide the ability to create a "snapshot" of a persistent volume.
|
||||
A snapshot represents a point-in-time copy of a volume.
|
||||
A snapshot can be used either to provision a new volume (pre-populated with the snapshot data)
|
||||
or to restore the existing volume to a previous state (represented by the snapshot).
|
||||
|
||||
On KubeSphere, requirements for Volume Snapshot are:
|
||||
- With 1.17+ Kubernetes
|
||||
- Underlying storage plugin supports Snapshot
|
||||
|
||||
## Create Volume Snapshot
|
||||
Volume Snapshot could be created from an existing volume on the volume detail page.
|
||||

|
||||
|
||||
The created Volume Snapshot will be listed in the volume snapshot page.
|
||||

|
||||
|
||||
## Apply Volume Snapshot
|
||||
Volume Snapshot could be applied to create volume from the snapshot.
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -1,10 +1,46 @@
|
|||
---
|
||||
title: "Volumes"
|
||||
keywords: 'kubernetes, docker, helm, jenkins, istio, prometheus'
|
||||
keywords: 'kubernetes, docker, persistent volume, persistent volume claim, volume clone, volume snapshot, volume expanding'
|
||||
description: 'Create Volumes (PVCs)'
|
||||
|
||||
linkTitle: "Volumes"
|
||||
weight: 2110
|
||||
---
|
||||
|
||||
TBD
|
||||
## Introduction
|
||||
In this section, volumes always refer to PersistentVolumeClaim(PVC) of Kubernetes.
|
||||
|
||||
## Create Volume
|
||||
### Method
|
||||
There are two methods to create volume:
|
||||
- Create empty volume by StorageClass
|
||||
- Create volume from VolumeSnapshot
|
||||
|
||||

|
||||
|
||||
## Attach Volume onto Workloads
|
||||
Take attaching volume onto deployment for example, in the `Mount Volume` step of *Create Deployment*,
|
||||
volumes cloud be attached on containers' path.
|
||||

|
||||
|
||||
## Volume Features
|
||||
Volume Features include:
|
||||
- Clone Volume
|
||||
- Create Volume Snapshot
|
||||
- Expand Volume
|
||||
|
||||
KubeSphere can get supported features of underlying storage plugin called `Storage Capability`.
|
||||
The console display only supported features in `Volume Detail Page`.
|
||||
For more information about `Storage Capability`, see [Design Documentation](https://github.com/kubesphere/community/blob/master/sig-storage/concepts-and-designs/storage-capability-interface.md)
|
||||
|
||||

|
||||
|
||||
**Node**: Some in-tree or special CSI plugins may not be covered by **Storage Capability**.
|
||||
If Kubesphere did not display the right features in your cluster, you could adjust according to [method](https://github.com/kubesphere/kubesphere/issues/2986).
|
||||
|
||||
## Volume Monitoring
|
||||
KubeSphere gets metric data of PVC with FileSystem mode from Kubelet to monitor volumes including capacity usage and inode usage.
|
||||

|
||||
|
||||
For more information about Volume Monitoring illustrations, see [Research on Volume Monitoring](https://github.com/kubesphere/kubesphere/issues/2921).
|
||||
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@ This tutorial demonstrates how to enable pluggable components of KubeSphere both
|
|||
| openpitrix | KubeSphere App Store | Provide an app store for Helm-based applications and allow users to manage apps throughout the entire lifecycle. |
|
||||
| servicemesh | KubeSphere Service Mesh (Istio-based) | Provide fine-grained traffic management, observability and tracing, and visualized traffic topology. |
|
||||
|
||||
For more information about each component, see Overview of Enable Pluggable Components.
|
||||
For more information about each component, see [Overview of Enable Pluggable Components](../../pluggable-components/).
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
|
|
@ -36,7 +36,7 @@ For more information about each component, see Overview of Enable Pluggable Comp
|
|||
|
||||
### **Installing on Linux**
|
||||
|
||||
When you install KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
When you implement multi-node installation of KubeSphere on Linux, you need to create a configuration file, which lists all KubeSphere components.
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Linux](../../installing-on-linux/introduction/multioverview/), you create a default file **config-sample.yaml**. Modify the file by executing the following command:
|
||||
|
||||
|
|
@ -46,11 +46,11 @@ vi config-sample.yaml
|
|||
|
||||
{{< notice note >}}
|
||||
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable pluggable components in this mode (e.g. for testing purpose), refer to the following section to see how pluggable components can be installed after installation.
|
||||
If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/), you do not need to create a config-sample.yaml file as you can create a cluster directly. Generally, the all-in-one mode is for users who are new to KubeSphere and look to get familiar with the system. If you want to enable pluggable components in this mode (e.g. for testing purpose), refer to the [following section](#enable-pluggable-components-after-installation) to see how pluggable components can be installed after installation.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
2. In this file, enable the pluggable components you want to install by changing `false` to `true` for `enabled`. Here is [an example file](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md) for your reference. Save the file after you finish.
|
||||
2. In this file, enable the pluggable components you want to install by changing `false` to `true` for `enabled`. Here is [an example file](https://github.com/kubesphere/kubekey/blob/release-1.0/docs/config-example.md) for your reference. Save the file after you finish.
|
||||
3. Create a cluster using the configuration file:
|
||||
|
||||
```bash
|
||||
|
|
@ -59,22 +59,27 @@ If you adopt [All-in-one Installation](../../quick-start/all-in-one-on-linux/),
|
|||
|
||||
### Installing on Kubernetes
|
||||
|
||||
When you install KubeSphere on Kubernetes, you need to download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) for cluster setting. If you want to install pluggable components, do not use `kubectl apply -f` directly for this file.
|
||||
When you install KubeSphere on Kubernetes, you need to execute `kubectl apply -f` first for the installer file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml) as stated in the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/). After that, follow the steps below to enable pluggable components:
|
||||
|
||||
1. In the tutorial of [Installing KubeSphere on Kubernetes](../../installing-on-kubernetes/introduction/overview/), you execute `kubectl apply -f` first for the file [kubesphere-installer.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/kubesphere-installer.yaml). After that, to enable pluggable components, create a local file cluster-configuration.yaml.
|
||||
1. Download the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and copy and paste the content of it to a local `cluster-configuration.yaml` file.
|
||||
|
||||
```bash
|
||||
vi cluster-configuration.yaml
|
||||
```
|
||||
|
||||
2. Copy all the content in the file [cluster-configuration.yaml](https://github.com/kubesphere/ks-installer/releases/download/v3.0.0/cluster-configuration.yaml) and paste it to the local file just created.
|
||||
3. In this local cluster-configuration.yaml file, enable the pluggable components you want to install by changing `false` to `true` for `enabled`. Here is [an example file](https://github.com/kubesphere/ks-installer/blob/master/deploy/cluster-configuration.yaml) for your reference. Save the file after you finish.
|
||||
4. Execute the following command to start installation:
|
||||
2. To enable the pluggable component you want to install, change `false` to `true` for `enabled` under the component in this file.
|
||||
3. Save this local file and execute the following command to apply it.
|
||||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
You must apply the `kubesphere-installer.yaml` file first before you apply the file `cluster-configuration.yaml`. Wrong execution order or the failure to apply either file can result in installation failure.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
Whether you install KubeSphere on Linux or on Kubernetes, you can check the status of the components you have enabled in the web console of KubeSphere after installation. Go to **Components**, and you can see an image below:
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -1,15 +1,15 @@
|
|||
---
|
||||
title: "Compose and Deploy Wordpress"
|
||||
keywords: 'KubeSphere, Kubernetes, app, Wordpress'
|
||||
title: "Compose and Deploy WordPress"
|
||||
keywords: 'KubeSphere, Kubernetes, app, WordPress'
|
||||
description: 'Compose and deploy Wordpress.'
|
||||
|
||||
linkTitle: "Compose and Deploy Wordpress"
|
||||
linkTitle: "Compose and Deploy WordPress"
|
||||
weight: 3050
|
||||
---
|
||||
|
||||
## WordPress Introduction
|
||||
|
||||
WordPress is a free and open-source content management system written in PHP, allowing users to build their own websites. A complete Wordpress application includes the following Kubernetes objects with MySQL serving as the backend database.
|
||||
WordPress is a free and open-source content management system written in PHP, allowing users to build their own websites. A complete WordPress application includes the following Kubernetes objects with MySQL serving as the backend database.
|
||||
|
||||
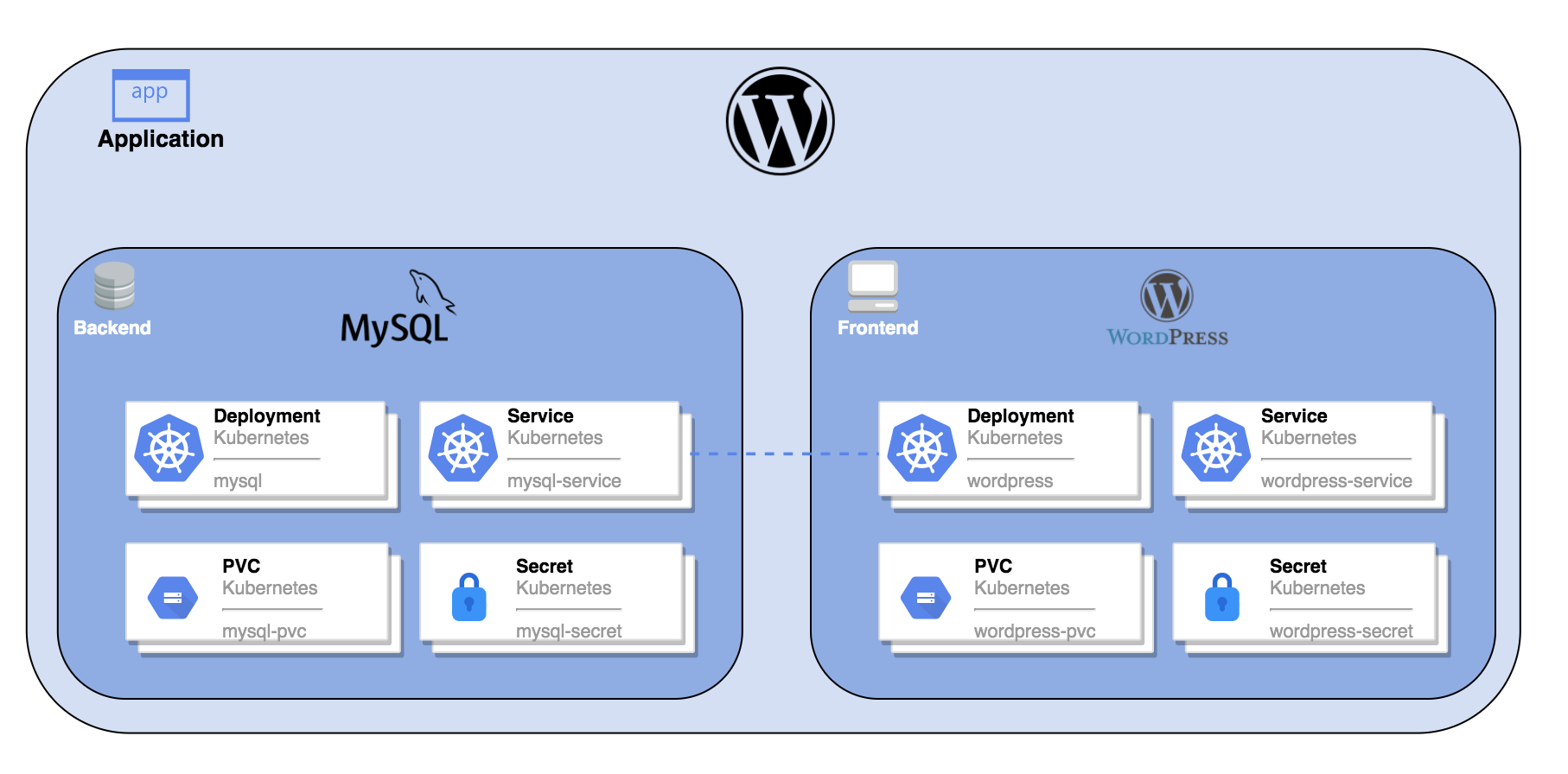
|
||||
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@ KubeSphere v3.0.0 is compatible with Kubernetes 1.15.x, 1.16.x, 1.17.x and 1.18.
|
|||
- If your KubeSphere v2.1.x is installed on Kubernetes 1.14.x, you have to upgrade Kubernetes (to 1.15.x+) and KubeSphere (to v3.0.0 ) at the same time.
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
There are some significant API changes in Kubernetes 1.16.x compared with prior versions 1.14.x and 1.15.x. Please refer to [Deprecated APIs Removed In 1.16: Here’s What You Need To Know](https://kubernetes.io/blog/2019/07/18/api-deprecations-in-1-16/) for more details. So if you plan to upgrade from Kubernetes 1.14.x/1.15.x to 1.16.x+, you have to migrate some of your workloads after upgrading.
|
||||
|
||||
{{</ notice >}}
|
||||
|
|
@ -23,6 +24,7 @@ There are some significant API changes in Kubernetes 1.16.x compared with prior
|
|||
## Before Upgrade
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
- You are supposed to implement a simulation for the upgrade in a testing environment first. After the upgrade is successful in the testing environment and all applications are running normally, upgrade it in your production environment.
|
||||
- During the upgrade process, there may be a short interruption of applications (especially for those single-replica Pod). Please arrange a reasonable period of time for upgrade.
|
||||
- It is recommended to back up ETCD and stateful applications before upgrading in a production environment. You can use [Velero](https://velero.io/) to implement backup and migrate Kubernetes resources and persistent volumes.
|
||||
|
|
@ -31,8 +33,8 @@ There are some significant API changes in Kubernetes 1.16.x compared with prior
|
|||
|
||||
## How
|
||||
|
||||
A brand-new installer [KubeKey](https://github.com/kubesphere/kubekey) is introduced in KubeSphere v3.0.0, with which you can install or upgrade Kubernetes and KubeSphere. More details about upgrading with [KubeKey](https://github.com/kubesphere/kubekey) will be covered in [Upgrade with KubeKey](../upgrade-with-kubekey/).
|
||||
A brand-new installer [KubeKey](https://github.com/kubesphere/kubekey) is introduced in KubeSphere v3.0.0, with which you can install or upgrade Kubernetes and KubeSphere. More details about upgrading with KubeKey will be covered in [Upgrade with KubeKey](../upgrade-with-kubekey/).
|
||||
|
||||
## KubeKey or ks-installer?
|
||||
## KubeKey or ks-installer
|
||||
|
||||
[ks-installer](https://github.com/kubesphere/ks-installer/tree/master) was the main installation tool as of KubeSphere v2. For users whose Kubernetes clusters were NOT deployed via [KubeSphere Installer](https://v2-1.docs.kubesphere.io/docs/installation/all-in-one/#step-2-download-installer-package), they should choose ks-installer to upgrade KubeSphere. For example, if your Kubernetes is hosted by cloud vendors or self provisioned, please refer to [Upgrade with ks-installer](../upgrade-with-ks-installer).
|
||||
|
|
|
|||
|
|
@ -13,15 +13,15 @@ ks-installer is recommended for users whose Kubernetes clusters were not set up
|
|||
|
||||
- You need to have a KubeSphere cluster running version 2.1.1.
|
||||
|
||||
{{< notice warning >}}
|
||||
{{< notice warning >}}
|
||||
If your KubeSphere version is v2.1.0 or earlier, please upgrade to v2.1.1 first.
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Make sure you read [Release Notes For 3.0.0](../../release/release-v300/) carefully.
|
||||
|
||||
{{< notice warning >}}
|
||||
{{< notice warning >}}
|
||||
In v3.0.0, KubeSphere refactors many of its components such as Fluent Bit Operator and IAM. Make sure you back up any important components in case you heavily customized them but not from console.
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
## Step 1: Download YAML files
|
||||
|
||||
|
|
@ -47,4 +47,4 @@ kubectl apply -f kubesphere-installer.yaml
|
|||
|
||||
```bash
|
||||
kubectl apply -f cluster-configuration.yaml
|
||||
```
|
||||
```
|
||||
|
|
|
|||
|
|
@ -12,11 +12,9 @@ KubeKey is recommended for users whose KubeSphere and Kubernetes were both deplo
|
|||
|
||||
- You need to have a KubeSphere cluster running version 2.1.1.
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
{{< notice warning >}}
|
||||
If your KubeSphere version is v2.1.0 or earlier, please upgrade to v2.1.1 first.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Download KubeKey.
|
||||
|
||||
|
|
@ -31,7 +29,6 @@ wget https://github.com/kubesphere/kubekey/releases/download/v1.0.0/kubekey-v1.0
|
|||
```
|
||||
|
||||
{{</ tab >}}
|
||||
|
||||
{{< tab "For users with poor network connections to GitHub" >}}
|
||||
|
||||
Download KubeKey using the following command:
|
||||
|
|
@ -39,8 +36,8 @@ Download KubeKey using the following command:
|
|||
```bash
|
||||
wget -c https://kubesphere.io/download/kubekey-v1.0.0-linux-amd64.tar.gz -O - | tar -xz
|
||||
```
|
||||
{{</ tab >}}
|
||||
|
||||
{{</ tab >}}
|
||||
{{</ tabs >}}
|
||||
|
||||
Make `kk` executable:
|
||||
|
|
@ -51,15 +48,12 @@ chmod +x kk
|
|||
|
||||
- Make sure you read [Release Notes For 3.0.0](../../release/release-v300/) carefully.
|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
{{< notice warning >}}
|
||||
In v3.0.0, KubeSphere refactors many of its components such as Fluent Bit Operator and IAM. Make sure you back up any important components in case you heavily customized them but not from console.
|
||||
|
||||
{{</ notice >}}
|
||||
{{</ notice >}}
|
||||
|
||||
- Make your upgrade plan. Two upgrading scenarios are documented below.
|
||||
|
||||
|
||||
## Upgrade KubeSphere and Kubernetes
|
||||
|
||||
Upgrading steps are different for single-node clusters (all-in-one) and multi-node clusters.
|
||||
|
|
|
|||
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: "Import Helm Repository"
|
||||
keywords: "kubernetes, helm, kubesphere, application"
|
||||
description: "Import Helm Repository into KubeSphere"
|
||||
|
||||
linkTitle: "Import Helm Repository"
|
||||
weight: 100
|
||||
---
|
||||
|
||||
KubeSphere builds application repository services on [OpenPitrix](https://openpitrix.io), the open source cross-cloud application management platform from [QingCloud](https://www.qingcloud.com), which supports for Kubernetes applications based on Helm Chart. In an application repository, each application is a base package repository and if you want to use OpenPitrix for application management, you need to create the repository first. You can store packages to an HTTP/HTTPS server, a [minio](https://docs.min.io/), or an S3 object storage. The application repository is an external storage independent of OpenPitrix, which can be [minio](https://docs.min.io/), QingCloud's QingStor object storage, or AWS object storage, in which the contents are the configuration packages of the application developed by developers. and indexed files. After registering the repository, the stored application configuration packages are automatically indexed as deployable applications.
|
||||
|
||||
## Preparing the application repository
|
||||
|
||||
The [official Helm documentation](https://helm.sh/docs/topics/chart_repository/#hosting-chart-repositories) already provides several ways to create application repositories, But in this document, we recommend that you use the official KubeSphere helm repo.
|
||||
|
||||
- [KubeSphere Official Application Repository](https://charts.kubesphere.io/)
|
||||
|
||||
## Adding application repositories
|
||||
|
||||
1. Create a Workspace, and then in the Workspace, go to `App Managements → App repos` and click `Add Repo`.
|
||||
|
||||

|
||||
|
||||
2. In the Add Repository window, fill in the URL with `https://charts.kubesphere.io/main`, and then create the repository after verification.
|
||||
|
||||
- Repository Name: Give a simple and clear name to the repository, which is easy for users to browse and search.
|
||||
- Type: Helm Chart type application is supported.
|
||||
- URL: The following three protocols are supported
|
||||
- The URL is S3 styled, e.g. `s3.<zone-id>.qingstor.com/<bucket-name>/` to access the QingStor service using the S3 interface.
|
||||
- HTTP: readable, not writable, only supports fetching applications from this application repository (object storage) and deploying to the runtime environment, e.g., enter `http://docs-repo.gd2.qingstor.com`. This example contains a sample Nginx application that will be automatically imported into the platform after creation, and can be done in the application template Deployment.
|
||||
- HTTPS: readable, not writable, supports only getting applications from this application repository, supports deployment to a runtime environment.
|
||||
|
||||
- Description information: a brief description of the main features of the application repository to give users a better understanding of the application repository.
|
||||
|
||||
3. If the validation is passed, click the **OK** button to complete the addition of the application repository. Once the repository is added, KubeSphere will automatically load all the application templates under the repository.
|
||||
|
||||
> Note that the example repository added above is a mirror of Google's Helm repository (we will be developing a commercial version of the application repository for enterprise use in the future), and some of these applications may not be successfully deployed.
|
||||
|
||||
In an on-premises private cloud scenario, you can build your own repository based on [Helm](https://helm.sh), and develop and upload applications to your repository that meet your business needs, and then deploy them for distribution based on KubeSphere.
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
---
|
||||
title: "Import Helm Repository"
|
||||
keywords: "kubernetes, helm, kubesphere, application"
|
||||
description: "Import Helm Repository into KubeSphere"
|
||||
|
||||
linkTitle: "Import Helm Repository"
|
||||
weight: 100
|
||||
---
|
||||
|
||||
TBD
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
---
|
||||
title: "Upload Helm-based Application"
|
||||
keywords: "kubernetes, helm, kubesphere, openpitrix, application"
|
||||
description: "Upload Helm-based Application"
|
||||
|
||||
linkTitle: "Upload Helm-based Application"
|
||||
weight: 50
|
||||
---
|
||||
|
||||
TBD
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
---
|
||||
title: "Upload Helm-based Application"
|
||||
keywords: "kubernetes, helm, kubesphere, openpitrix, application"
|
||||
description: "Upload Helm-based Application"
|
||||
|
||||
linkTitle: "Upload Helm-based Application"
|
||||
weight: 50
|
||||
---
|
||||
|
||||
KubeSphere provides full lifecycle management for applications. You can upload or create new app templates and test them quickly. In addition, you can publish your apps to App Store so that other users can deploy with one click. You can upload [Helm Chart](https://helm.sh/) to develop app templates.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to create a workspace and `project-admin` account. Please refer to the [Getting Started with Multi-tenant Management](../../../quick-start/create-workspace-and-project) if not yet.
|
||||
- You need to sign in with `project-admin` account.
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
Go to the workspace, open `Apps Management` and go to `App Templates`, then click the `Create` button.
|
||||
|
||||

|
||||
|
||||
Click the `Upload` button.
|
||||
|
||||

|
||||
|
||||
Assuming you've already developed a Helm chart locally, or you can download the [Helm package](/files/application-templates/nginx-0.1.0.tgz) here.
|
||||
|
||||

|
||||
|
||||
Select the Helm chart file you have finished developing locally and click `OK` to proceed to the next step.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Now that you have successfully uploaded a Helm package, you can click on its name to go to its detail page.
|
||||
|
||||

|
||||
|
||||
On the versions list tab, you can click on the corresponding version to test the deployment.
|
||||
|
||||

|
||||
|
|
@ -26,7 +26,7 @@ section3:
|
|||
tip: Apply now →
|
||||
partnerType:
|
||||
- title: "App Providers"
|
||||
content: "KubeSphere Application Store is a great place to showcase your applications. KubeSphere brings your applications to tens of thousands of users, allowing them to deploy your App to Kubernetes with one click."
|
||||
content: "KubeSphere App Store is a great place to showcase your applications. KubeSphere brings your applications to tens of thousands of users, allowing them to deploy your App to Kubernetes with one click."
|
||||
link: "request"
|
||||
|
||||
- title: "Technology"
|
||||
|
|
|
|||
|
|
@ -1,4 +0,0 @@
|
|||
---
|
||||
title: "reason"
|
||||
|
||||
---
|
||||
|
|
@ -21,19 +21,19 @@ section3:
|
|||
tip: Request now →
|
||||
partnerType:
|
||||
- title: "App Providers"
|
||||
content: "KubeSphere Application Store is a great place to showcase your application, KubeSphere bring your applications to tens of thousands of users, making them deploy your App to Kubernetes with one click."
|
||||
content: "KubeSphere App Store is a great place to showcase your application, KubeSphere bring your applications to tens of thousands of users, making them deploy your App to Kubernetes with one click."
|
||||
link: ""
|
||||
|
||||
- title: "Consulting"
|
||||
content: "KubeSphere Application Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere Application Store now!"
|
||||
content: "KubeSphere App Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere App Store now!"
|
||||
link: ""
|
||||
|
||||
- title: "Cloud Providers"
|
||||
content: "KubeSphere Application Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere Application Store now!"
|
||||
content: "KubeSphere App Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere App Store now!"
|
||||
link: ""
|
||||
|
||||
- title: "Go-To-Market"
|
||||
content: "KubeSphere Application Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere Application Store now!"
|
||||
content: "KubeSphere App Store is a great place to showcase your application, users can quickly deploy your application to Kubernetes using KubeSphere. Submit your application to KubeSphere App Store now!"
|
||||
link: ""
|
||||
|
||||
section4:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,8 @@
|
|||
---
|
||||
title: KubeSphere Api Documents
|
||||
description: KubeSphere Api Documents
|
||||
keywords: KubeSphere, KubeSphere Documents, Kubernetes
|
||||
|
||||
swaggerUrl: json/crd.json
|
||||
---
|
||||
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
---
|
||||
title: KubeSphere Api Documents
|
||||
description: KubeSphere Api Documents
|
||||
keywords: KubeSphere, KubeSphere Documents, Kubernetes
|
||||
|
||||
swaggerUrl: json/kubesphere.json
|
||||
---
|
||||
|
|
@ -0,0 +1,235 @@
|
|||
---
|
||||
title: 'KubeSphere 部署 TiDB 云原生分布式数据库'
|
||||
tag: 'TiDB, Kubernetes, KubeSphere, TiKV, prometheus'
|
||||
createTime: '2020-10-29'
|
||||
author: 'Will, FeynmanZhou, Yaqiong Liu'
|
||||
snapshot: 'https://ap3.qingstor.com/kubesphere-website/docs/20201028212049.png'
|
||||
---
|
||||
|
||||

|
||||
|
||||
## TiDB 简介
|
||||
|
||||
[TiDB](https://pingcap.com/) 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
|
||||
|
||||

|
||||
|
||||
|
||||
## KubeSphere 简介
|
||||
|
||||
[KubeSphere](https://kubesphere.io) 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,完全开源,支持多云与多集群管理,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。
|
||||
|
||||

|
||||
|
||||
## 部署环境准备
|
||||
|
||||
KubeSphere 是由青云 QingCloud 开源的容器平台,**支持在任何基础设施上安装部署**。在青云公有云上支持一键部署 KubeSphere(QKE)。
|
||||
|
||||
下面以在青云云平台快速启用 KubeSphere 容器平台为例部署 TiDB 分布式数据库,至少需要准备 3 个可调度的 node 节点。你也可以在任何 Kubernetes 集群或 Linux 系统上安装 KubeSphere,可以参考 [KubeSphere 官方文档](https://kubesphere.io/docs)。
|
||||
|
||||
1. 登录青云控制台:[https://console.qingcloud.com/](https://console.qingcloud.com/),点击左侧容器平台,选择 KubeSphere,点击创建并选择合适的集群规格:
|
||||
|
||||

|
||||
|
||||
2. 创建完成后登录到 KubeSphere 平台界面:
|
||||
|
||||
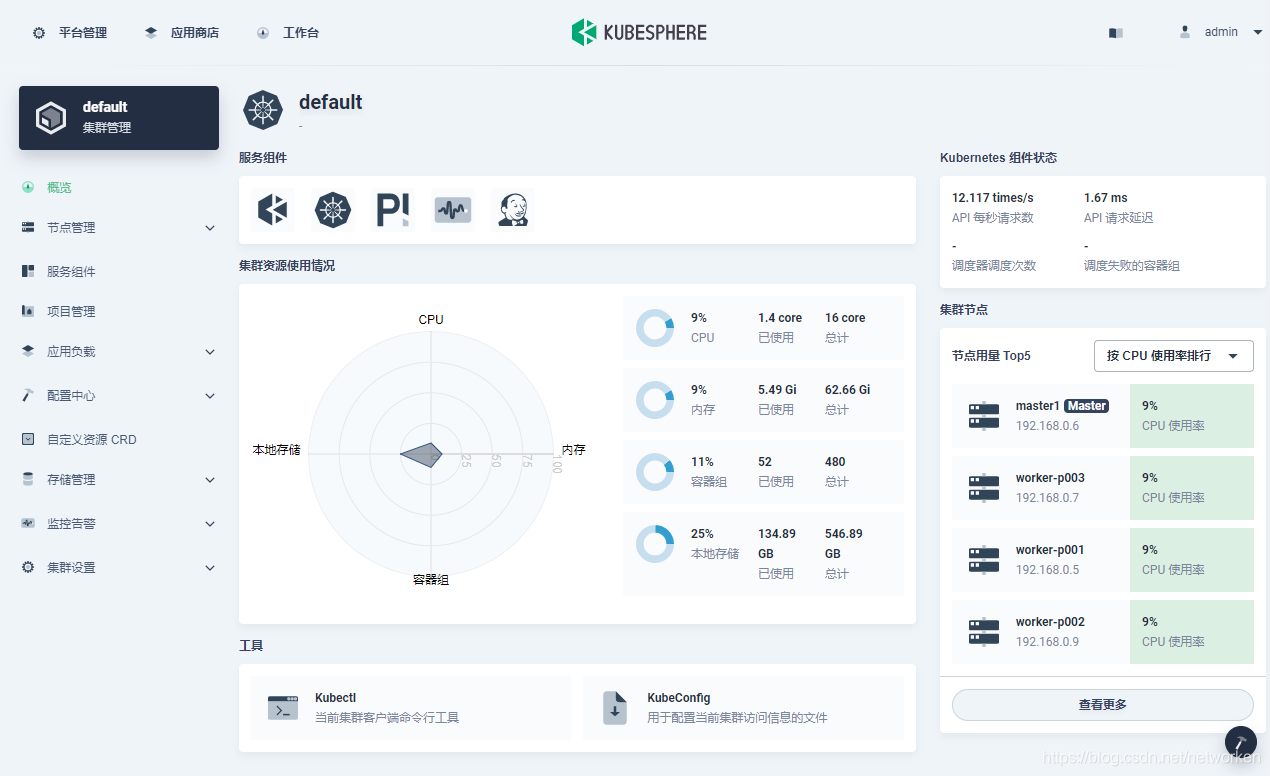
|
||||
|
||||
3. 点击下方的 Web Kubectl 集群客户端命令行工具,连接到 Kubectl 命令行界面。执行以下命令安装 TiDB Operator CRD:
|
||||
|
||||
```shell
|
||||
kubectl apply -f https://raw.githubusercontent.com/pingcap/TiDB-Operator/v1.1.6/manifests/crd.yaml
|
||||
```
|
||||
|
||||
4. 执行后的返回结果如下:
|
||||
|
||||
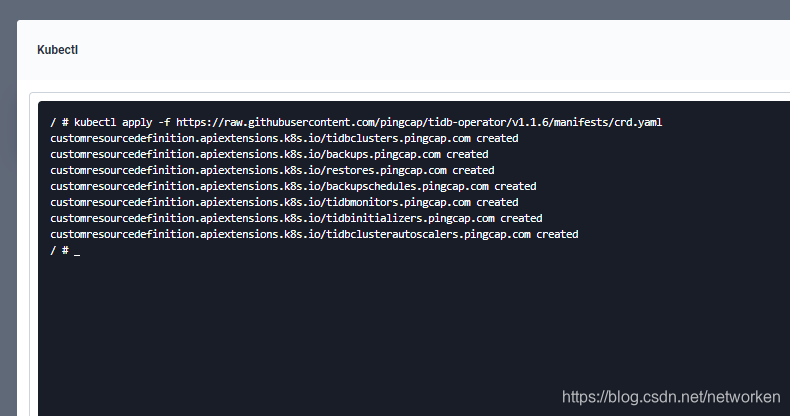
|
||||
|
||||
5. 点击左上角平台管理,选择访问控制,新建企业空间,这里命名为 `dev-workspace`
|
||||
|
||||
|
||||
|
||||
6. 进入企业空间,选择应用仓库,添加一个 TiDB 的应用仓库:
|
||||
|
||||

|
||||
|
||||
7. 将 PingCap 官方 Helm 仓库添加到 KubeSphere 容器平台,Helm 仓库地址如下:
|
||||
|
||||
```shell
|
||||
https://charts.pingcap.org
|
||||
```
|
||||
|
||||
8. 添加方式如下:
|
||||
|
||||
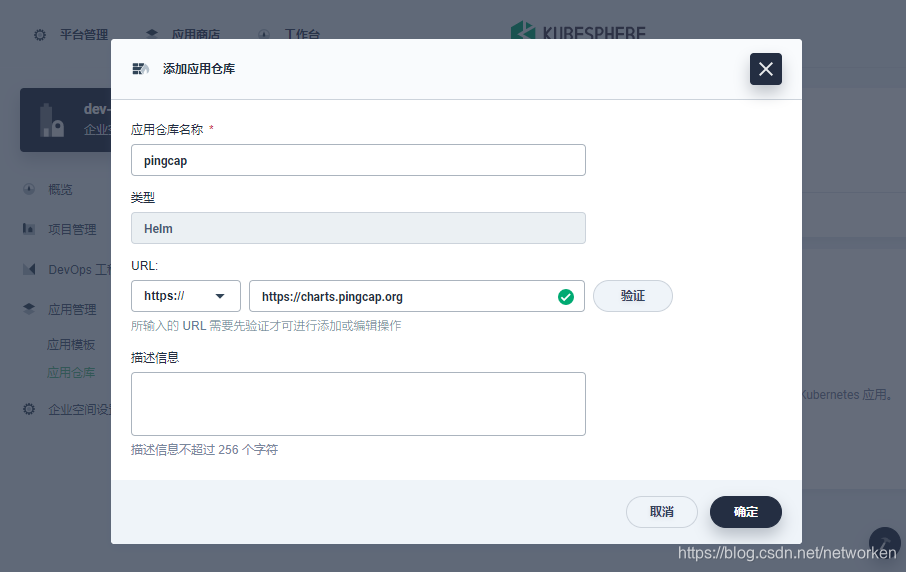
|
||||
|
||||
## 部署 TiDB-Operator
|
||||
|
||||
1. 首选创建一个项目(Namespace)用于运行 TiDB 集群:
|
||||
|
||||
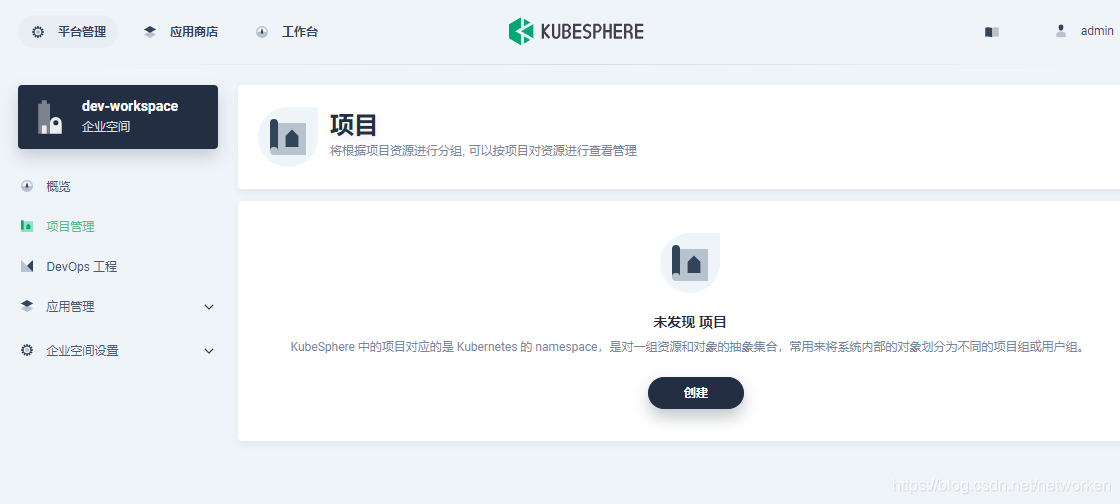
|
||||
|
||||
2. 创建完成后点击进入项目,选择应用,部署新应用
|
||||
|
||||
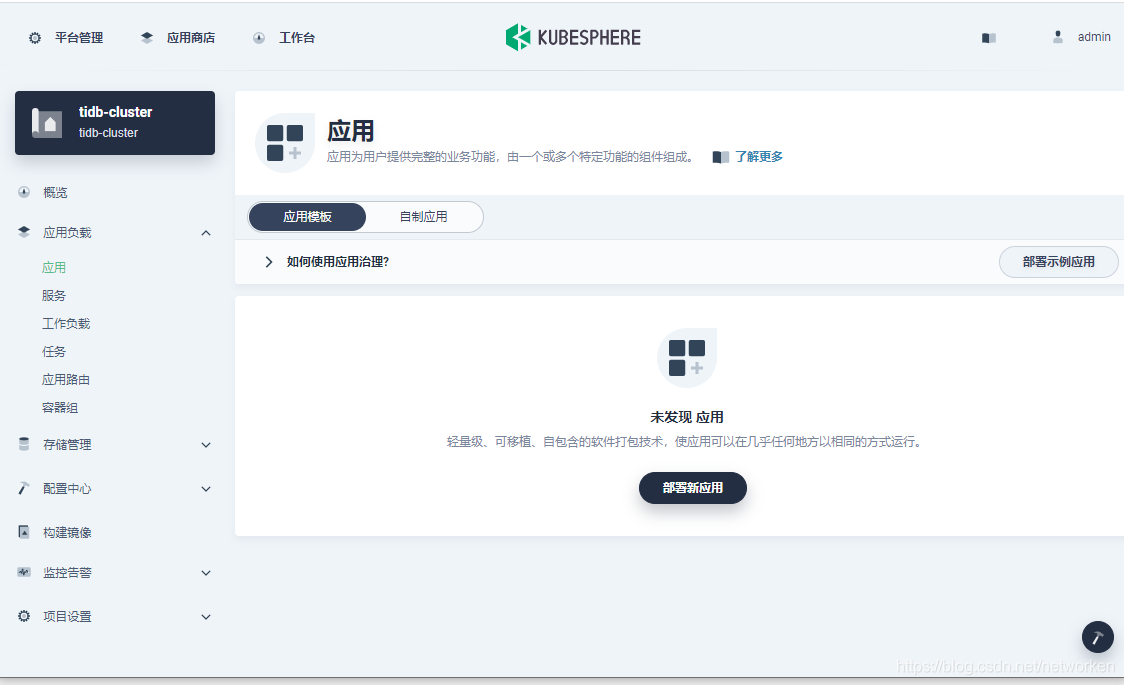
|
||||
|
||||
3. 选择来自应用模板:
|
||||
|
||||
|
||||
|
||||
|
||||
4. 选择 `pingcap`,该仓库包含了多个 helm chart,当前主要部署 `TiDB-Operator` 和`tidb-cluster`。
|
||||
|
||||
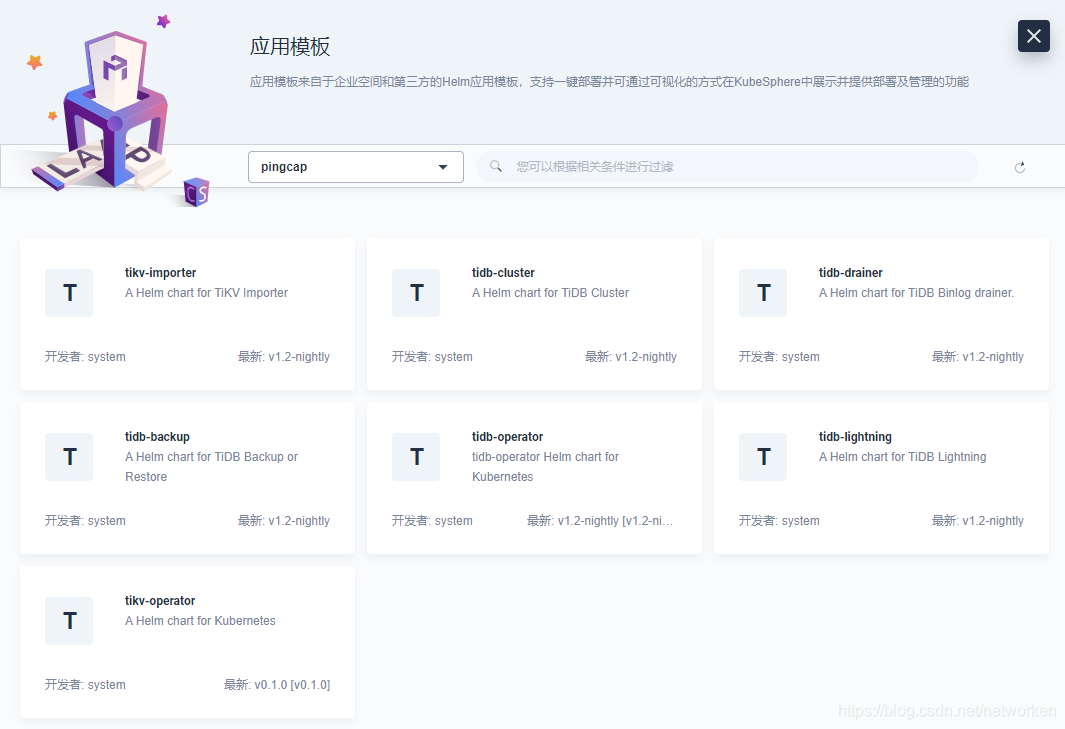
|
||||
|
||||
5. 点击 `TiDB-Operator` 进入 Chart 详情页,点击配置文件可查看或下载默认的 `values.yaml`,选择版本,点击部署:
|
||||
|
||||
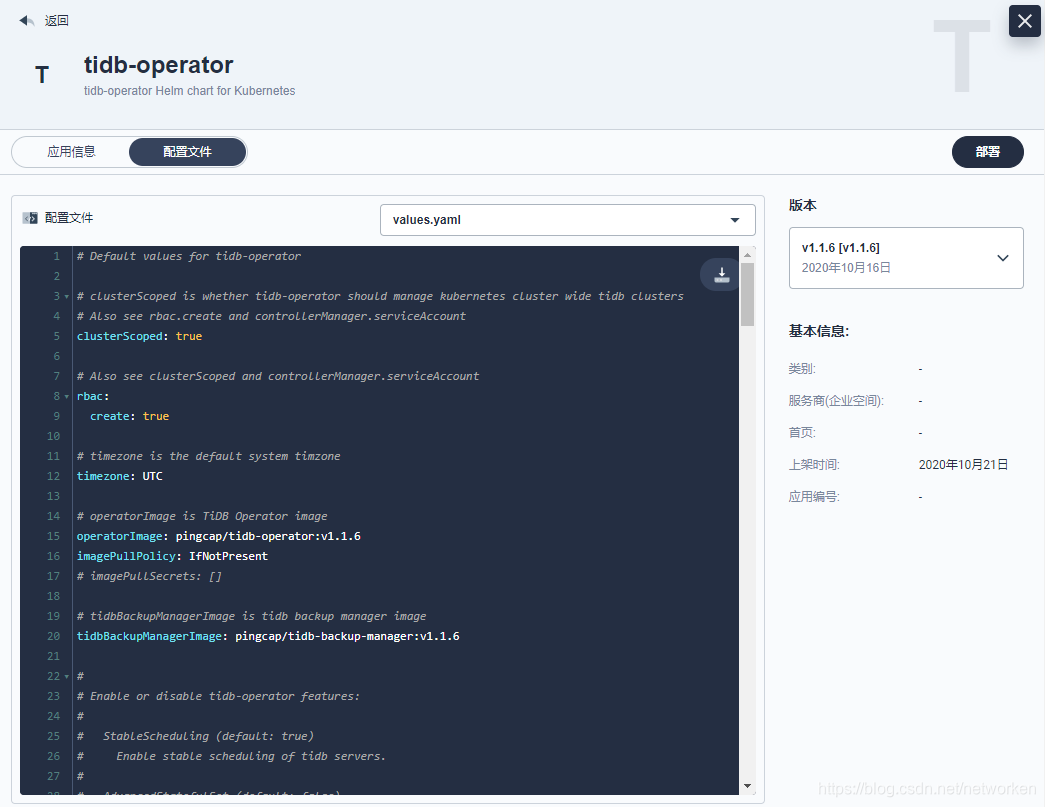
|
||||
|
||||
6. 配置应用名称并选择应用版本,确认应用部署位置:
|
||||
|
||||
|
||||
|
||||
7. 继续下一步,该步骤可以在界面直接编辑 `values.yaml` 文件,自定义配置,当前保留默认即可:
|
||||
|
||||
|
||||
|
||||
8. 点击部署,等待应用状态变为活跃:
|
||||
|
||||
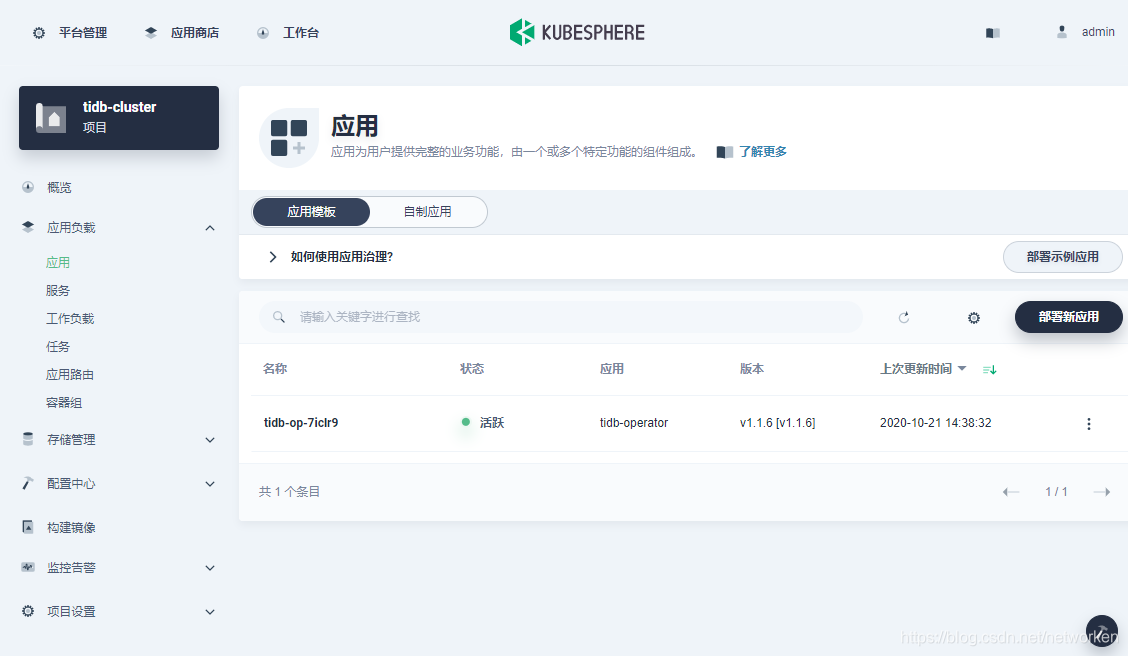
|
||||
|
||||
9. 点击工作负载(Deployment),查看 TiDB-Operator 部署了 2 个 Deployment 类型资源:
|
||||
|
||||
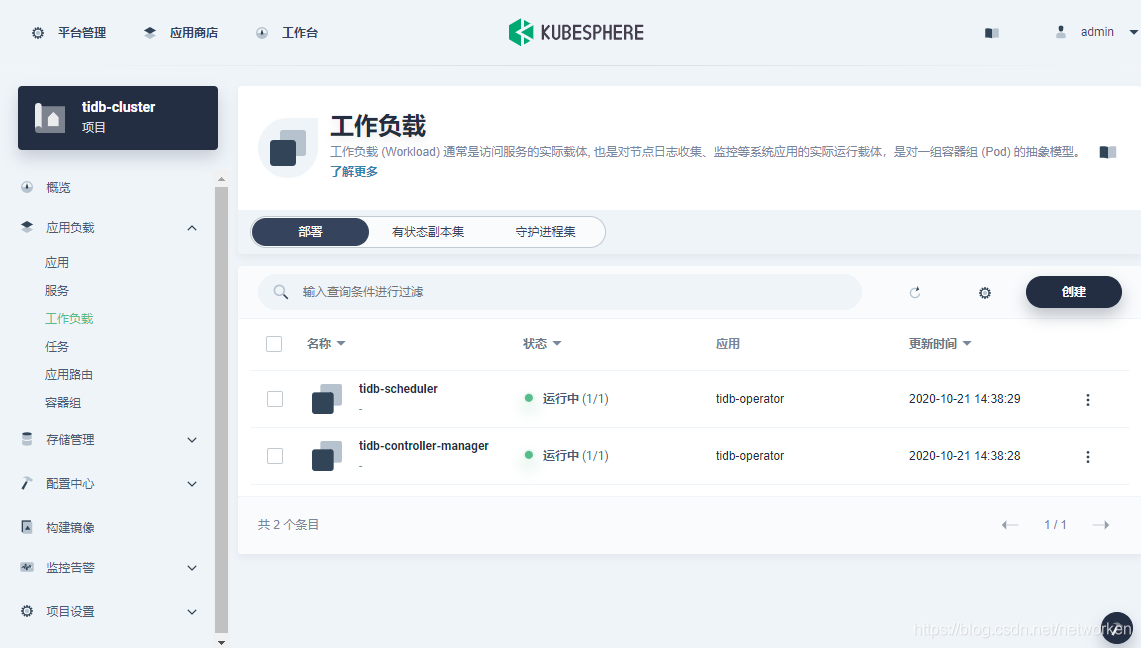
|
||||
|
||||
|
||||
## 部署 TiDB-Cluster
|
||||
|
||||
1. TiDB-Operator 部署完成后,可以继续部署 TiDB-Cluster。与部署 TiDB-Operator 操作相同,选择左侧应用,点击 tidb-cluster:
|
||||
|
||||
|
||||
|
||||
2. 切换到配置文件,选择版本,下载 `values.yaml`到本地:
|
||||
|
||||
|
||||
|
||||
3. TiDB Cluster 中部分组件需要持久存储卷,青云公有云平台提供了以下几种类型的 StorageClass:
|
||||
|
||||
```shell
|
||||
/ # kubectl get sc
|
||||
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
|
||||
csi-high-capacity-legacy csi-qingcloud Delete Immediate true 101m
|
||||
csi-high-perf csi-qingcloud Delete Immediate true 101m
|
||||
csi-ssd-enterprise csi-qingcloud Delete Immediate true 101m
|
||||
csi-standard (default) csi-qingcloud Delete Immediate true 101m
|
||||
csi-super-high-perf csi-qingcloud Delete Immediate true 101m
|
||||
```
|
||||
|
||||
4. 这里选择 csi-standard 类型,`values.yaml` 中的 `StorageClassName` 字段默认配置为 `local-storage`。因此,在下载的 yaml 文件中直接替换所有的 `local-storage` 字段为 `csi-standard`。在最后一步使用修改后的 `values.yaml` 覆盖应用配置文本框中的内容,当然也可以手动编辑配置文件逐个替换:
|
||||
|
||||
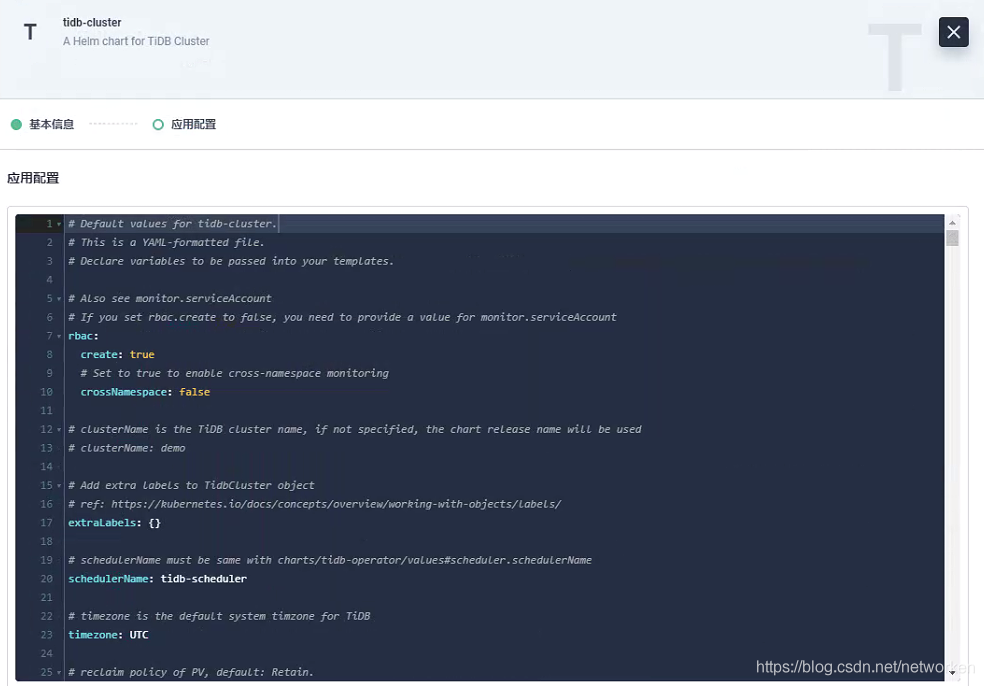
|
||||
|
||||
5. 这里仅修改 `storageClassName` 字段用于引用外部持久存储,如果需要将 tidb、tikv或 pd 组件调度到独立节点,可参考 nodeAffinity 相关参数进行修改。点击部署,将 tidb cluster 部署到容器平台,最终在应用列表中可以看到如下 2 个应用:
|
||||
|
||||
|
||||
|
||||
## 查看 TiDB 集群监控
|
||||
|
||||
1. TiDB 集群部署后需要一定时间完成初始化,选择工作负载,查看 Deployment 无状态应用:
|
||||
|
||||
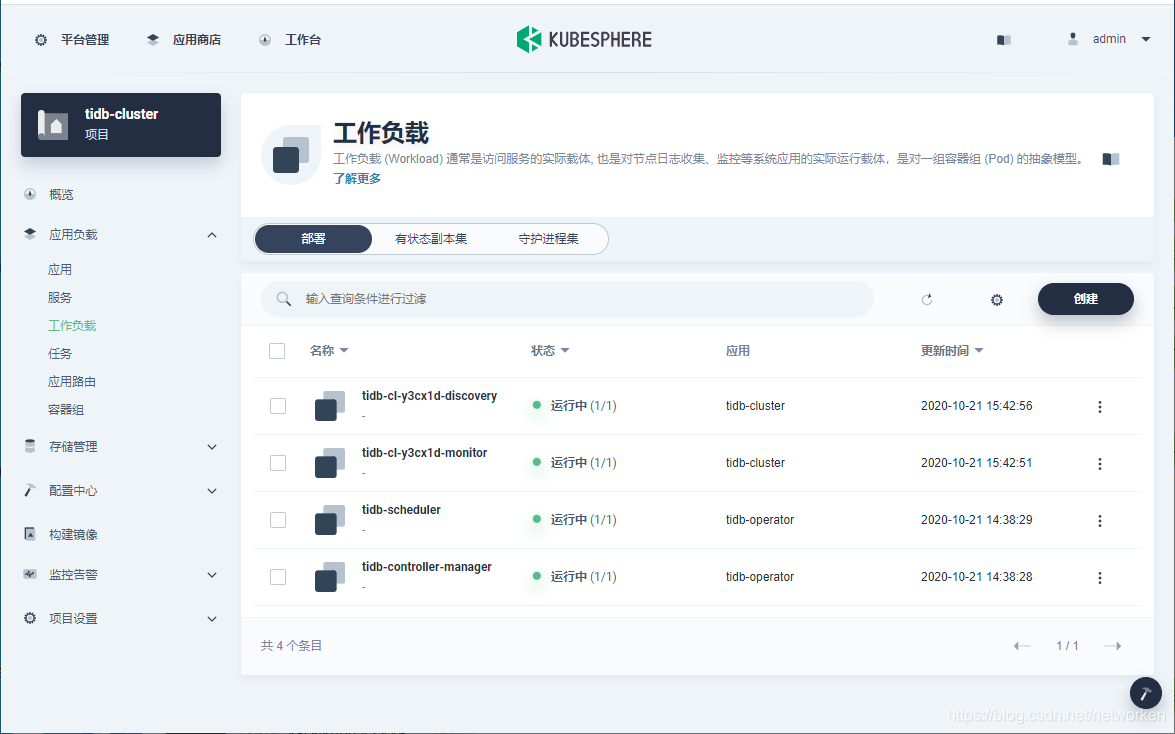
|
||||
|
||||
2. 查看有状态副本集(StatefulSets),其中 tidb、tikv 和 pd 等组件都为有状态应用:
|
||||
|
||||

|
||||
|
||||
3. 在 KubeSphere 监控面板查看 tidb 负载情况,可以看到 CPU、内存、网络流出速率有明显的变化:
|
||||
|
||||
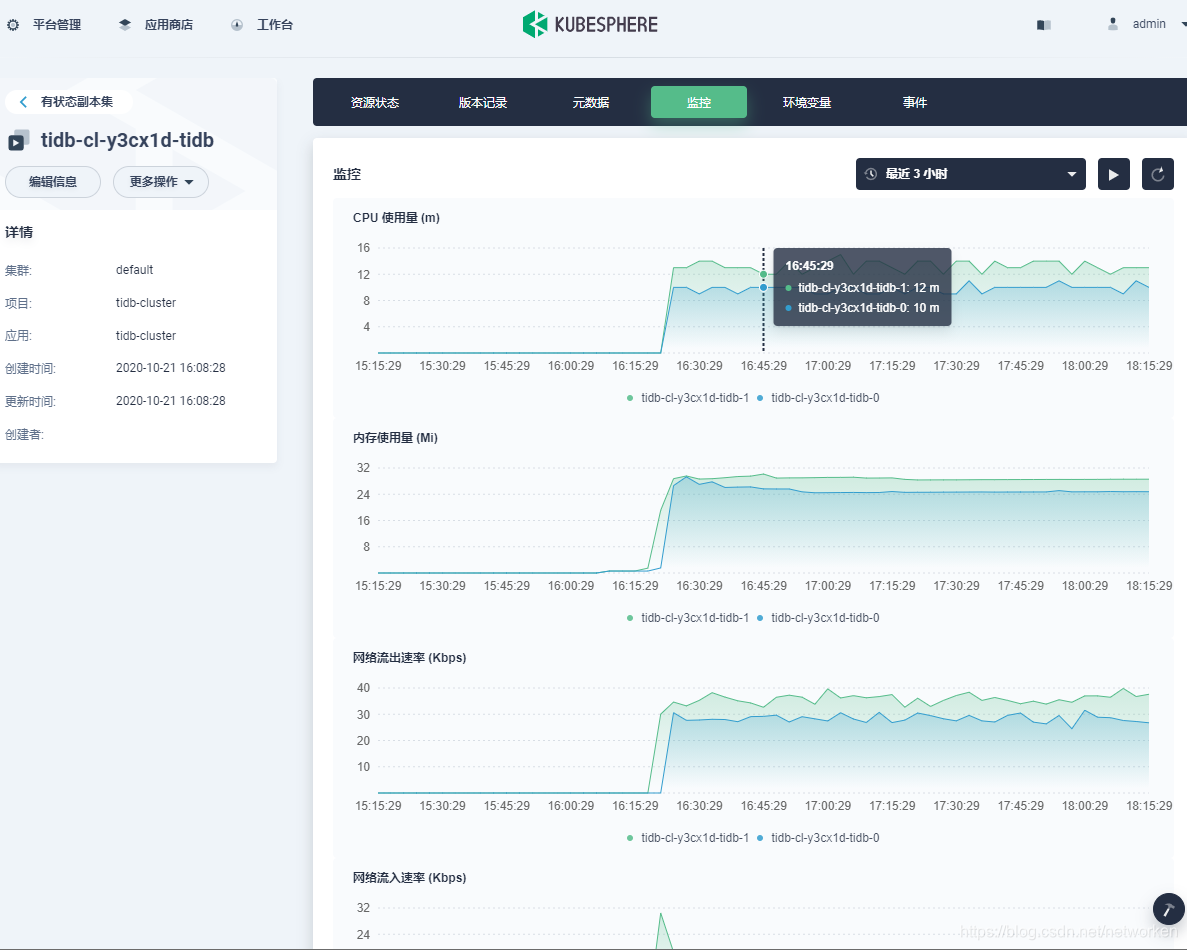
|
||||
|
||||
4. 在 KubeSphere 监控面板查看 TiKV 负载情况:
|
||||
|
||||
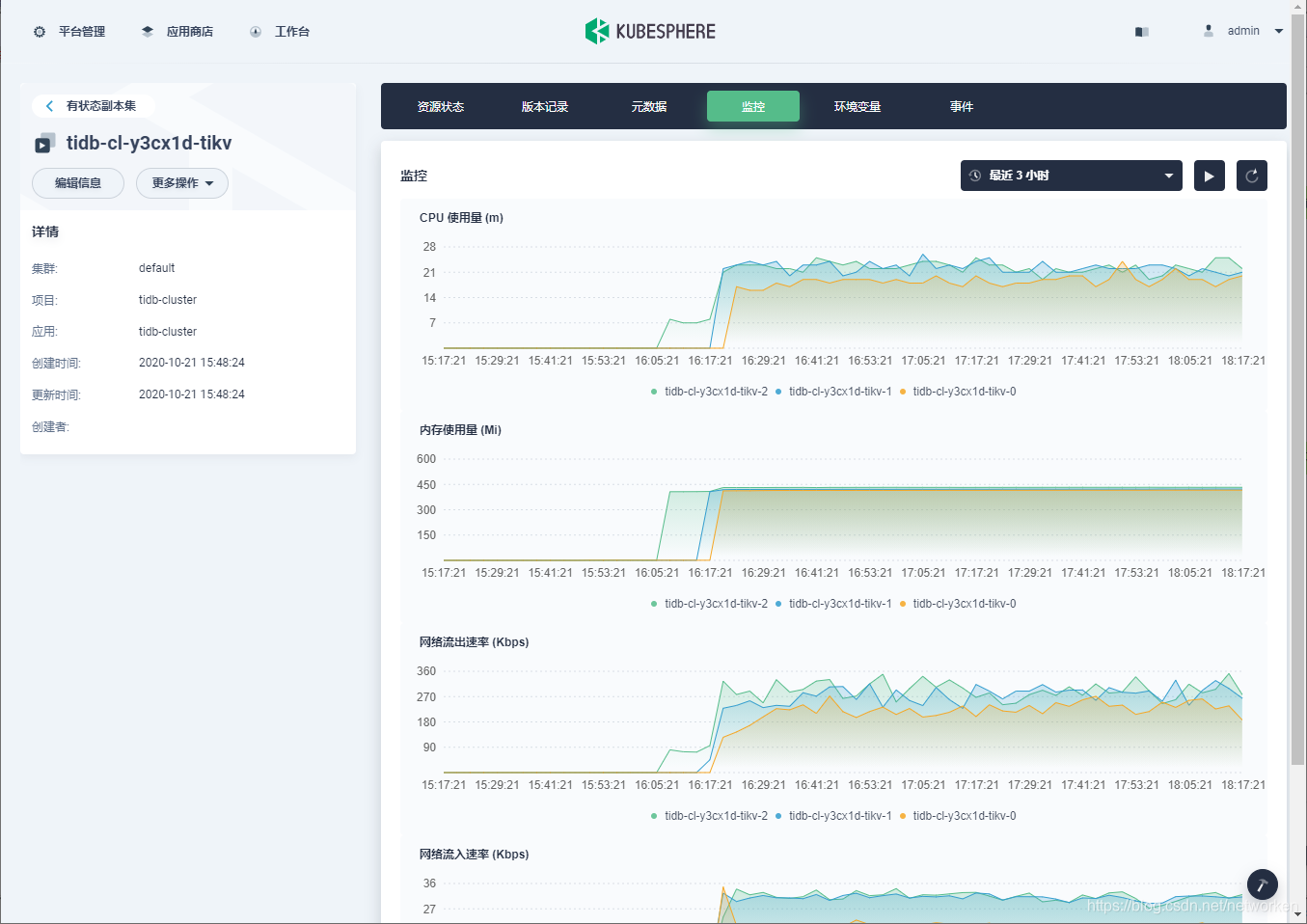
|
||||
|
||||
|
||||
5. 查看容器组(Pod)列表,tidb 集群包含了 3 个 pd、2 个 tidb 以及 3 个 tikv 组件:
|
||||
|
||||

|
||||
|
||||
6. 点击存储管理,查看存储卷,其中 tikv 和 pd 这 2 个组件使用了持久化存储:
|
||||
|
||||

|
||||
|
||||
7. 查看某个存储卷用量信息,以 tikv 为例,可以看到当前存储的存储容量和剩余容量等监控数据。
|
||||
|
||||
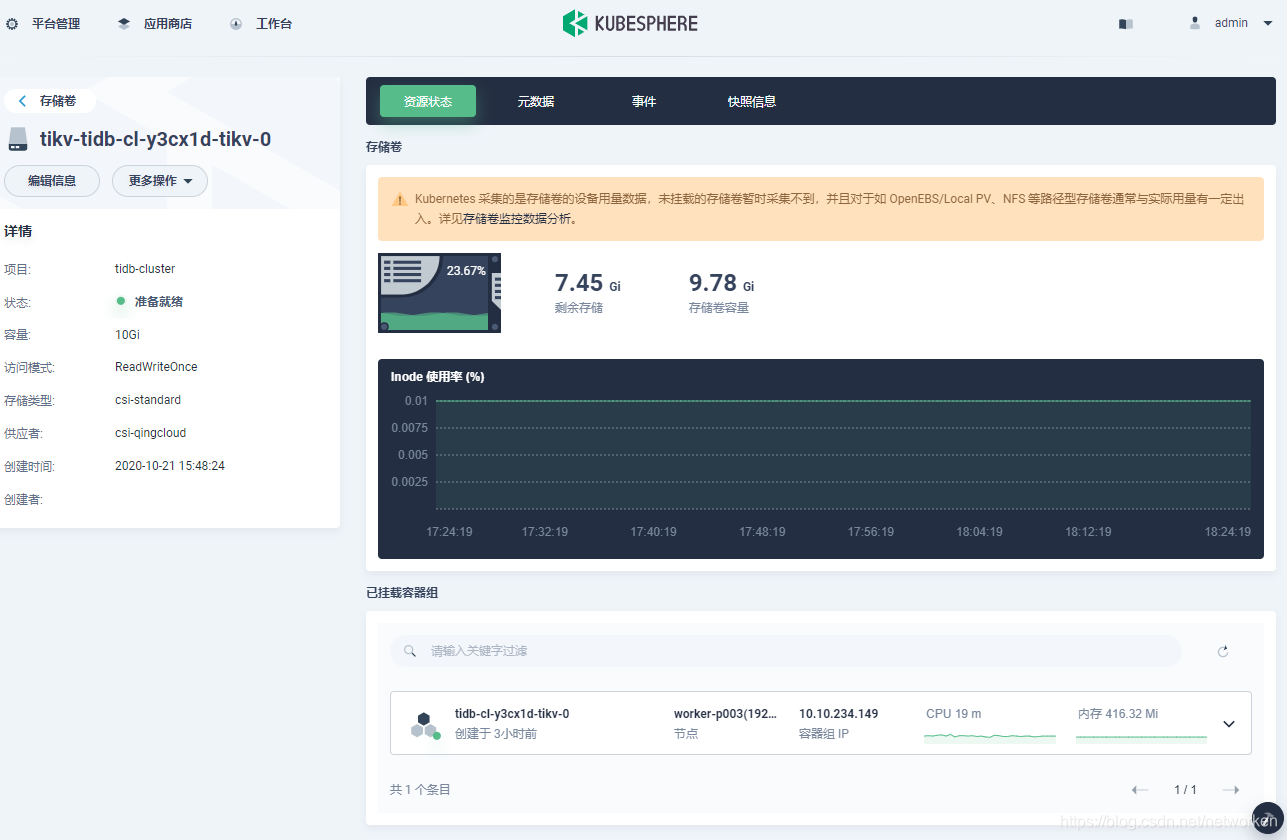
|
||||
|
||||
8. 在 KubeSphere 项目首页查看 tidb-cluster 项目中资源用量排行:
|
||||
|
||||
|
||||
|
||||
## 访问 TiDB 集群
|
||||
|
||||
1. 点击左侧服务,查看 TiDB 集群创建和暴露的服务信息。
|
||||
|
||||
|
||||
|
||||
2. 其中 TiDB 服务 4000 端口绑定的服务类型为nodeport,直接可以在集群外通过 nodeIP 访问。测试使用 MySQL 客户端连接数据库。
|
||||
|
||||
```shell
|
||||
[root@k8s-master1 ~]# docker run -it --rm mysql bash
|
||||
|
||||
[root@0d7cf9d2173e:/# mysql -h 192.168.1.102 -P 32682 -u root
|
||||
Welcome to the MySQL monitor. Commands end with ; or \g.
|
||||
Your MySQL connection id is 201
|
||||
Server version: 5.7.25-TiDB-v4.0.6 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
|
||||
|
||||
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
|
||||
|
||||
Oracle is a registered trademark of Oracle Corporation and/or its
|
||||
affiliates. Other names may be trademarks of their respective
|
||||
owners.
|
||||
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
mysql> show databases;
|
||||
+--------------------+
|
||||
| Database |
|
||||
+--------------------+
|
||||
| INFORMATION_SCHEMA |
|
||||
| METRICS_SCHEMA |
|
||||
| PERFORMANCE_SCHEMA |
|
||||
| mysql |
|
||||
| test |
|
||||
+--------------------+
|
||||
5 rows in set (0.01 sec)
|
||||
|
||||
mysql>
|
||||
```
|
||||
|
||||
## 查看 Grafana 监控面板
|
||||
|
||||
另外,TiDB 自带了 Prometheus 和 Grafana,用于数据库集群的性能监控,可以看到Grafana 界面的 Serivce 3000 端口同样绑定了 NodePort 端口。访问 Grafana UI,查看某个指标:
|
||||
|
||||
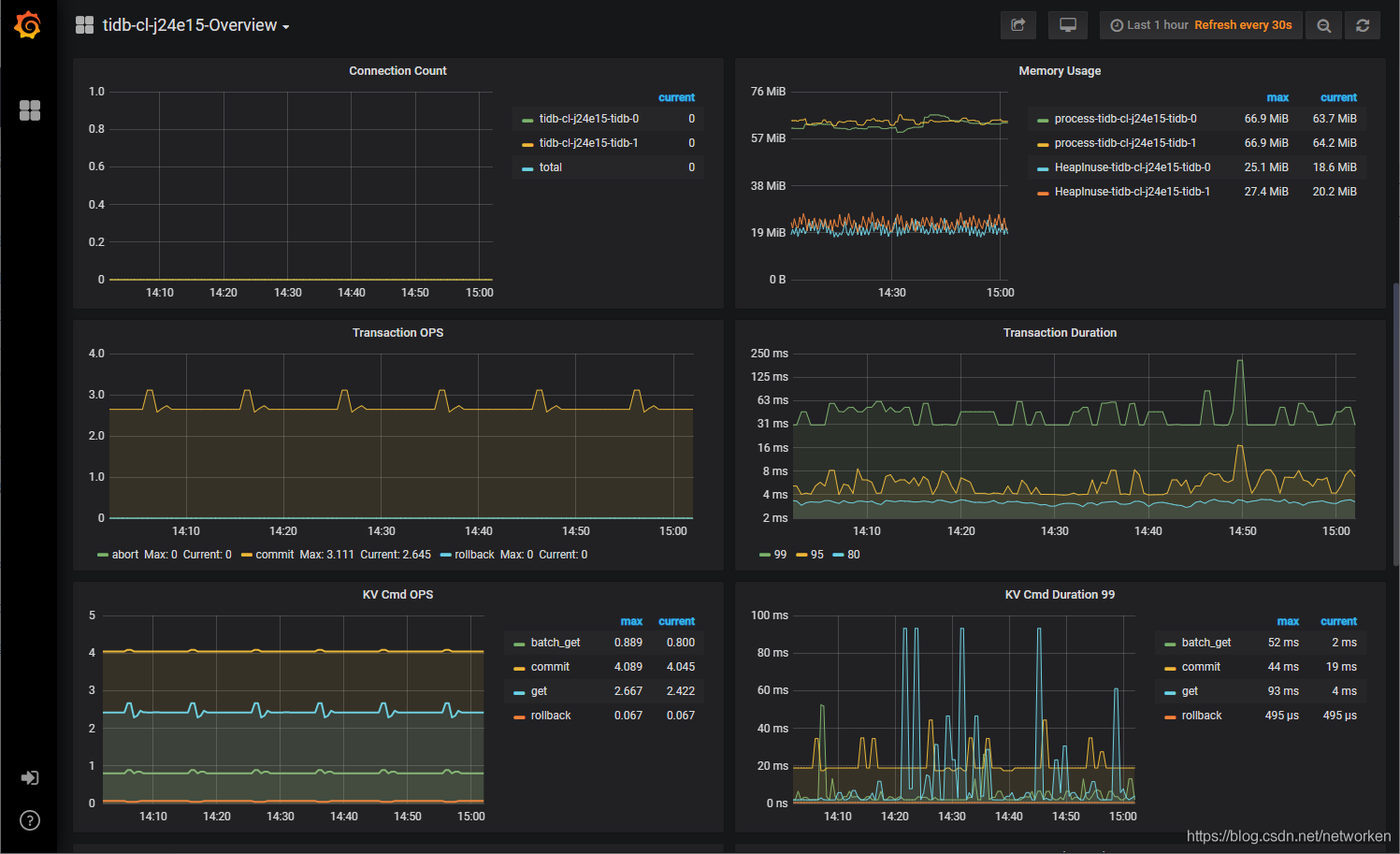
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
KubeSphere 容器平台对于云原生应用部署非常友好,对于还不熟悉 Kubernetes 的应用开发者而又希望通过在界面简单配置完成 TiDB 集群的部署,可以参考以上步骤快速上手。我们将在下一期的文章中,为大家分享另一种部署玩法:将 TiDB 应用上架到 KubeSphere 应用商店实现真正的一键部署。
|
||||
|
||||
另外,TiDB 还可以结合 KubeSphere 的多集群联邦功能,部署 TiDB 应用时可一键分发 TiDB 不同的组件副本到不同基础设施环境的多个 Kubernetes 集群,实现跨集群、跨区域的高可用。如果大家感兴趣,我们将在后续的文章中为大家分享 TiDB 在 KubeSphere 实现多集群联邦的混合云部署架构。
|
||||
|
||||
## 参考
|
||||
|
||||
**KubeSphere GitHub**: https://github.com/kubesphere/kubesphere
|
||||
|
||||
**TiDB GitHub**: https://github.com/pingcap/TiDB
|
||||
|
||||
**TiDB Operator 快速入门**: https://github.com/pingcap/docs-TiDB-Operator/blob/master/zh/get-started.md
|
||||
|
||||
**TiDB-Operator 文档**: https://docs.pingcap.com/tidb-in-kubernetes/stable/TiDB-Operator-overview
|
||||
|
||||
**KubeSphere Introduction**: https://kubesphere.io/docs/introduction/what-is-kubesphere/
|
||||
|
||||
**KubeSphere Documentation**: https://kubesphere.io/docs/
|
||||
|
|
@ -6,7 +6,7 @@ css: scss/case-detail.scss
|
|||
|
||||
section1:
|
||||
title: VNG
|
||||
content: VNG Coporation 是越南领先的互联网科技公司。在 2014 年,我们被评为越南唯一一家估值 10 亿美元的创业公司。VNG 推出了许多重要产品,比如 Zalo、ZaloPay 和 Zing 等,吸引了数亿用户。
|
||||
content: VNG Corporation 是越南领先的互联网科技公司。在 2014 年,我们被评为越南唯一一家估值 10 亿美元的创业公司。VNG 推出了许多重要产品,比如 Zalo、ZaloPay 和 Zing 等,吸引了数亿用户。
|
||||
image: https://pek3b.qingstor.com/kubesphere-docs/png/20200619222719.png
|
||||
|
||||
section2:
|
||||
|
|
|
|||
|
|
@ -15,9 +15,9 @@ section2:
|
|||
icon2: 'images/contribution/37.png'
|
||||
children:
|
||||
- content: 'Download KubeSphere'
|
||||
link: 'https://kubesphere.io/docs/installation/intro/'
|
||||
link: '../../../zh/docs/quick-start/all-in-one-on-linux/'
|
||||
- content: 'Quickstart'
|
||||
link: 'https://kubesphere.io/docs/quick-start/admin-quick-start/'
|
||||
link: '../../../zh/docs/quick-start/create-workspace-and-project/'
|
||||
- content: 'Tutorial Videos'
|
||||
link: '../videos'
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ section3:
|
|||
- name: 'Apps'
|
||||
icon: '/images/contribution/apps.svg'
|
||||
iconActive: '/images/contribution/apps-active.svg'
|
||||
content: 'App charts for the built-in Application Store'
|
||||
content: 'App charts for the built-in App Store'
|
||||
link: 'https://github.com/kubesphere/community/tree/master/sig-apps'
|
||||
linkContent: 'Join SIG - Apps →'
|
||||
children:
|
||||
|
|
@ -92,7 +92,7 @@ section3:
|
|||
- icon: '/images/contribution/calicq2.jpg'
|
||||
- icon: '/images/contribution/calicq3.jpg'
|
||||
|
||||
- name: 'Application Store'
|
||||
- name: 'App Store'
|
||||
icon: '/images/contribution/app-store.svg'
|
||||
iconActive: '/images/contribution/app-store-active.svg'
|
||||
content: 'App Store, App template management'
|
||||
|
|
|
|||
|
|
@ -0,0 +1,11 @@
|
|||
---
|
||||
title: "账户管理和权限控制"
|
||||
description: "账户管理和权限控制"
|
||||
layout: "single"
|
||||
|
||||
linkTitle: "账户管理和权限控制"
|
||||
weight: 4500
|
||||
|
||||
icon: "/images/docs/docs.svg"
|
||||
|
||||
---
|
||||
|
|
@ -0,0 +1,129 @@
|
|||
---
|
||||
title: "OAuth2 Identity Provider"
|
||||
keywords: 'kubernetes, kubesphere, OAuth2, Identity Provider'
|
||||
description: 'OAuth2 Identity Provider'
|
||||
|
||||
weight: 2240
|
||||
---
|
||||
|
||||
## 概览
|
||||
|
||||
KubeSphere 可以通过标准的 OAuth2 协议对接外部的 OAuth2 Provider,通过外部 OAuth2 Server 完成账户认证后可以关联登录到 KubeSphere。
|
||||
完整的认证流程如下:
|
||||
|
||||

|
||||
|
||||
## GitHubIdentityProvider
|
||||
|
||||
KubeSphere 默认提供了 GitHubIdentityProvider 做为 OAuth2 认证插件的开发示例,配置及使用方式如下:
|
||||
|
||||
### 参数配置
|
||||
|
||||
IdentityProvider 的参数通过 kubesphere-system 项目下 kubesphere-config 这个 ConfigMap 进行配置
|
||||
|
||||
通过 `kubectl -n kubesphere-system edit cm kubesphere-config` 进行编辑,配置示例:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
data:
|
||||
kubesphere.yaml: |
|
||||
authentication:
|
||||
authenticateRateLimiterMaxTries: 10
|
||||
authenticateRateLimiterDuration: 10m0s
|
||||
loginHistoryRetentionPeriod: 7d
|
||||
maximumClockSkew: 10s
|
||||
multipleLogin: true
|
||||
kubectlImage: kubesphere/kubectl:v1.0.0
|
||||
jwtSecret: "jwt secret"
|
||||
oauthOptions:
|
||||
accessTokenMaxAge: 1h
|
||||
accessTokenInactivityTimeout: 30m
|
||||
identityProviders:
|
||||
- name: github
|
||||
type: GitHubIdentityProvider
|
||||
mappingMethod: mixed
|
||||
provider:
|
||||
clientID: 'Iv1.547165ce1cf2f590'
|
||||
clientSecret: 'c53e80ab92d48ab12f4e7f1f6976d1bdc996e0d7'
|
||||
endpoint:
|
||||
authURL: 'https://github.com/login/oauth/authorize'
|
||||
tokenURL: 'https://github.com/login/oauth/access_token'
|
||||
redirectURL: 'https://ks-console/oauth/redirect'
|
||||
scopes:
|
||||
- user
|
||||
...
|
||||
```
|
||||
|
||||
在 `authentication.oauthOptions.identityProviders` 下增加 GitHubIdentityProvider 的配置块,参数示意:
|
||||
|
||||
| 字段 | 说明 |
|
||||
|-----------|-------------|
|
||||
| name | IdentityProvider 的唯一名称 |
|
||||
| type | IdentityProvider 插件的类型,GitHubIdentityProvider 是一种默认实现的类型 |
|
||||
| mappingMethod | 账户关联配置,详细说明: https://github.com/kubesphere/kubesphere/blob/master/pkg/apiserver/authentication/oauth/oauth_options.go#L37-L44 |
|
||||
| clientID | OAuth2 client ID |
|
||||
| clientSecret | OAuth2 client secret |
|
||||
| authURL | OAuth2 endpoint |
|
||||
| tokenURL | OAuth2 endpoint |
|
||||
| redirectURL | 重定向到 ks-console 的跳转路径`https://ks-console/oauth/redirect` |
|
||||
|
||||
重启 ks-apiserver 以更新配置: `kubectl -n kubesphere-system rollout restart deploy ks-apiserver`,重启完成后打开前端页面可以看到通过 `通过 github 登录` 按钮
|
||||
|
||||

|
||||
|
||||
### 通过 Github 账户登录 KubeSphere
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
账户登录到 KubeSphere 之后就可以被添加、邀请到启用空间中[参与项目协同](https://kubesphere.io/docs/workspaces-administration/role-and-member-management) 。
|
||||
|
||||
## OAuth2 插件开发
|
||||
|
||||
OAuth2 作为一个开放协议,解决了 API 认证授权的问题,进行账户接入还需要对用户信息接口和字段进行适配,您可以参照 [GitHubIdentityProvider](https://github.com/kubesphere/kubesphere/blob/master/pkg/apiserver/authentication/identityprovider/github/github.go) 、 [AliyunIDaasProvider](https://github.com/kubesphere/kubesphere/blob/master/pkg/apiserver/authentication/identityprovider/aliyunidaas/idaas.go) 这两个插件进行开发,以接入您私有的账户体系。
|
||||
|
||||
插件开发流程:
|
||||
|
||||
### 实现 `OAuthProvider` 接口
|
||||
|
||||
```go
|
||||
type OAuthProvider interface {
|
||||
Type() string
|
||||
Setup(options *oauth.DynamicOptions) (OAuthProvider, error)
|
||||
IdentityExchange(code string) (Identity, error)
|
||||
}
|
||||
```
|
||||
|
||||
插件通过 kubesphere-config 中 `authentication.oauthOptions.identityProviders` 部分进行配置,其中 provider 是动态配置, 也就是插件中的 `*oauth.DynamicOptions`。
|
||||
|
||||
### 插件注册
|
||||
|
||||
注册插件
|
||||
|
||||
`pkg/apiserver/authentication/identityprovider/github/github.go`
|
||||
|
||||
```go
|
||||
func init() {
|
||||
identityprovider.RegisterOAuthProvider(&Github{})
|
||||
}
|
||||
```
|
||||
|
||||
启用插件
|
||||
|
||||
`/pkg/apiserver/authentication/options/authenticate_options.go`
|
||||
|
||||
```go
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/spf13/pflag"
|
||||
_ "kubesphere.io/kubesphere/pkg/apiserver/authentication/identityprovider/aliyunidaas"
|
||||
_ "kubesphere.io/kubesphere/pkg/apiserver/authentication/identityprovider/github"
|
||||
"kubesphere.io/kubesphere/pkg/apiserver/authentication/oauth"
|
||||
"time"
|
||||
)
|
||||
```
|
||||
|
||||
### 构建镜像
|
||||
|
||||
[构建 ks-apiserver 的镜像](https://github.com/kubesphere/community/blob/104bab42f67094930f2ca87c603b7c6365cd092a/developer-guide/development/quickstart.md) 后部署到您的集群中,参照 GitHubIdentityProvider 的使用流程启用您新开发的插件。
|
||||
|
|
@ -1,9 +1,9 @@
|
|||
---
|
||||
title: "Application Store"
|
||||
title: "App Store"
|
||||
description: "Getting started with KubeSphere DevOps project"
|
||||
layout: "single"
|
||||
|
||||
linkTitle: "Application Store"
|
||||
linkTitle: "App Store"
|
||||
weight: 4500
|
||||
|
||||
icon: "/images/docs/docs.svg"
|
||||
|
|
|
|||
|
|
@ -0,0 +1,7 @@
|
|||
---
|
||||
linkTitle: "Cluster Settings"
|
||||
weight: 4180
|
||||
|
||||
_build:
|
||||
render: false
|
||||
---
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
---
|
||||
title: "Cluster Visibility and Authorization"
|
||||
keywords: "Cluster Visibility, Cluster Management"
|
||||
description: "Cluster Visibility"
|
||||
|
||||
linkTitle: "Cluster Visibility and Authorization"
|
||||
weight: 200
|
||||
---
|
||||
|
||||
## Objective
|
||||
This guide demonstrates how to set up cluster visibility. You can limit which clusters workspace can use with cluster visibility settings.
|
||||
|
||||
## Prerequisites
|
||||
* You need to enable [Multi-cluster Management](/docs/multicluster-management/enable-multicluster/direct-connection/).
|
||||
* You need to create at least one workspace.
|
||||
|
||||
## Set cluster visibility
|
||||
|
||||
In KubeSphere, clusters can be authorized to multiple workspaces, and workspaces can also be associated with multiple clusters.
|
||||
|
||||
### Set up available clusters when creating workspace
|
||||
|
||||
1. Log in to an account that has permission to create a workspace, such as `ws-manager`.
|
||||
2. Open the **Platform** menu to enter the **Access Control** page, and then enter the **Workspaces** list page from the sidebar.
|
||||
3. Click the **Create** button.
|
||||
4. Fill in the form and click the **Next** button.
|
||||
5. Then you can see a list of clusters, and you can check to set which clusters workspace can use.
|
||||

|
||||
6. After the workspace is created, the members of the workspace can use the resources in the associated cluster.
|
||||

|
||||
|
||||
{{< notice warning >}}
|
||||
|
||||
Please try not to create resources on the host cluster to avoid excessive loads, which can lead to a decrease in the stability across clusters.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Set cluster visibility after the workspace is created
|
||||
|
||||
After the workspace is created, you can also add or cancel the cluster authorization. Please follow the steps below to adjust the visibility of a cluster.
|
||||
|
||||
1. Log in to an account that has permission to manage clusters, such as `cluster-manager`.
|
||||
2. Open the **Platform** menu to enter the **Clusters Management** page, and then Click a cluster to enter the Single **Cluster Management** page.
|
||||
3. Expand the **Cluster Settings** sidebar and click on the **Cluster Visibility** menu.
|
||||
4. You can see the list of authorized workspaces.
|
||||
5. Click the **Edit Visibility** button to set the cluster authorization scope by adjusting the position of the workspace in the **Authorized/Unauthorized** list.
|
||||

|
||||

|
||||
|
||||
### Public cluster
|
||||
|
||||
You can check **Set as public cluster** when setting cluster visibility.
|
||||
|
||||
A public cluster means all platform users can access the cluster, in which they are able to create and schedule resources.
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
---
|
||||
linkTitle: "Log collection"
|
||||
weight: 2000
|
||||
|
||||
_build:
|
||||
render: false
|
||||
---
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: "Add Elasticsearch as receiver (aka Collector)"
|
||||
keywords: 'kubernetes, log, elasticsearch, pod, container, fluentbit, output'
|
||||
description: 'Add Elasticsearch as log receiver to receive container logs'
|
||||
|
||||
linkTitle: "Add Elasticsearch as Receiver"
|
||||
weight: 2200
|
||||
---
|
||||
KubeSphere supports using Elasticsearch, Kafka and Fluentd as log receivers.
|
||||
This doc will demonstrate how to add an Elasticsearch receiver.
|
||||
|
||||
## Prerequisite
|
||||
|
||||
Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components following [Enable Pluggable Components](https://kubesphere.io/docs/pluggable-components/). The `logging` component is enabled as an example in this doc.
|
||||
|
||||
1. To add a log receiver:
|
||||
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
|
||||

|
||||
|
||||
2. Choose ***Elasticsearch*** and fill in the Elasticsearch service address and port like below:
|
||||
|
||||

|
||||
|
||||
3. Elasticsearch appears in the receiver list of ***Log Collections*** page and its status becomes ***Collecting***.
|
||||
|
||||

|
||||
|
||||
4. Verify whether Elasticsearch is receiving logs sent from Fluent Bit:
|
||||
|
||||
- Click ***Log Search*** in the ***Toolbox*** in the bottom right corner.
|
||||
- You can search logs in the logging console that appears.
|
||||
|
|
@ -0,0 +1,155 @@
|
|||
---
|
||||
title: "Add Fluentd as Receiver (aka Collector)"
|
||||
keywords: 'kubernetes, log, fluentd, pod, container, fluentbit, output'
|
||||
description: 'KubeSphere Installation Overview'
|
||||
|
||||
linkTitle: "Add Fluentd as Receiver"
|
||||
weight: 2400
|
||||
---
|
||||
KubeSphere supports using Elasticsearch, Kafka and Fluentd as log receivers.
|
||||
This doc will demonstrate:
|
||||
|
||||
- How to deploy Fluentd as deployment and create corresponding service and configmap.
|
||||
- How to add Fluentd as a log receiver to receive logs sent from Fluent Bit and then output to stdout.
|
||||
- How to verify if Fluentd receives logs successfully.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components following [Enable Pluggable Components](https://kubesphere.io/docs/pluggable-components/). The `logging` component is enabled as an example in this doc.
|
||||
- To configure log collection, you should use an account of ***platform-admin*** role.
|
||||
|
||||
## Step 1: Deploy Fluentd as a deployment
|
||||
|
||||
Usually, Fluentd is deployed as a daemonset in K8s to collect container logs on each node. KubeSphere chooses Fluent Bit for this purpose because of its low memory footprint. Besides, Fluentd features numerous output plugins. Hence, KubeSphere chooses to deploy Fluentd as a deployment to forward logs it receives from Fluent Bit to more destinations such as S3, MongoDB, Cassandra, MySQL, syslog and Splunk.
|
||||
|
||||
To deploy Fluentd as a deployment, you simply need to open the ***kubectl*** console in ***KubeSphere Toolbox*** and run the following command:
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- The following command will deploy Fluentd deployment, service and configmap into the `default` namespace and add a filter to Fluentd configmap to exclude logs from the `default` namespace to avoid Fluent Bit and Fluentd loop logs collection.
|
||||
- You'll need to change all these `default` to the namespace you selected if you want to deploy to a different namespace.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```yaml
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: fluentd-config
|
||||
namespace: default
|
||||
data:
|
||||
fluent.conf: |-
|
||||
# Receive logs sent from Fluent Bit on port 24224
|
||||
<source>
|
||||
@type forward
|
||||
port 24224
|
||||
</source>
|
||||
|
||||
# Because this will send logs Fluentd received to stdout,
|
||||
# to avoid Fluent Bit and Fluentd loop logs collection,
|
||||
# add a filter here to avoid sending logs from the default namespace to stdout again
|
||||
<filter **>
|
||||
@type grep
|
||||
<exclude>
|
||||
key $.kubernetes.namespace_name
|
||||
pattern /^default$/
|
||||
</exclude>
|
||||
</filter>
|
||||
|
||||
# Send received logs to stdout for demo/test purpose only
|
||||
# Various output plugins are supported to output logs to S3, MongoDB, Cassandra, MySQL, syslog and Splunk etc.
|
||||
<match **>
|
||||
@type stdout
|
||||
</match>
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: fluentd
|
||||
name: fluentd
|
||||
namespace: default
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: fluentd
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: fluentd
|
||||
spec:
|
||||
containers:
|
||||
- image: fluentd:v1.9.1-1.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
name: fluentd
|
||||
ports:
|
||||
- containerPort: 24224
|
||||
name: forward
|
||||
protocol: TCP
|
||||
- containerPort: 5140
|
||||
name: syslog
|
||||
protocol: TCP
|
||||
volumeMounts:
|
||||
- mountPath: /fluentd/etc
|
||||
name: config
|
||||
readOnly: true
|
||||
volumes:
|
||||
- configMap:
|
||||
defaultMode: 420
|
||||
name: fluentd-config
|
||||
name: config
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: fluentd-svc
|
||||
name: fluentd-svc
|
||||
namespace: default
|
||||
spec:
|
||||
ports:
|
||||
- name: forward
|
||||
port: 24224
|
||||
protocol: TCP
|
||||
targetPort: forward
|
||||
selector:
|
||||
app: fluentd
|
||||
sessionAffinity: None
|
||||
type: ClusterIP
|
||||
EOF
|
||||
```
|
||||
|
||||
## Step 2: Add Fluentd as log receiver (aka collector)
|
||||
|
||||
1. To add a log receiver:
|
||||
|
||||
- Login KubeSphere with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
|
||||

|
||||
|
||||
2. Choose ***Fluentd*** and fill in the Fluentd service address and port like below:
|
||||
|
||||

|
||||
|
||||
3. Fluentd appears in the receiver list of ***Log Collections*** UI and its status shows ***Collecting***.
|
||||
|
||||

|
||||
|
||||
|
||||
4. Verify whether Fluentd is receiving logs sent from Fluent Bit:
|
||||
|
||||
- Click ***Application Workloads*** in the ***Cluster Management*** UI.
|
||||
- Select ***Workloads*** and then select the `default` namespace in the ***Workload*** - ***Deployments*** tab
|
||||
- Click the ***fluentd*** item and then click the ***fluentd-xxxxxxxxx-xxxxx*** pod
|
||||
- Click the ***fluentd*** container
|
||||
- In the ***fluentd*** container page, select the ***Container Logs*** tab
|
||||
|
||||
You'll see logs begin to scroll up continuously.
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,133 @@
|
|||
---
|
||||
title: "Add Kafka as Receiver (aka Collector)"
|
||||
keywords: 'kubernetes, log, kafka, pod, container, fluentbit, output'
|
||||
description: 'KubeSphere Installation Overview'
|
||||
|
||||
linkTitle: "Add Kafka as Receiver"
|
||||
weight: 2300
|
||||
---
|
||||
KubeSphere supports using Elasticsearch, Kafka and Fluentd as log receivers.
|
||||
This doc will demonstrate:
|
||||
|
||||
- Deploy [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) and then create a Kafka cluster and a Kafka topic by creating `Kafka` and `KafkaTopic` CRDs.
|
||||
- Add Kafka log receiver to receive logs sent from Fluent Bit
|
||||
- Verify whether the Kafka cluster is receiving logs using [Kafkacat](https://github.com/edenhill/kafkacat)
|
||||
|
||||
## Prerequisite
|
||||
|
||||
Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components following [Enable Pluggable Components](https://kubesphere.io/docs/pluggable-components/). The `logging` component is enabled as an example in this doc.
|
||||
|
||||
## Step 1: Create a Kafka cluster and a Kafka topic
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
If you already have a Kafka cluster, you can start from Step 2.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
You can use [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) to create a Kafka cluster and a Kafka topic
|
||||
|
||||
1. Install [strimzi-kafka-operator](https://github.com/strimzi/strimzi-kafka-operator) to the `default` namespace:
|
||||
|
||||
```bash
|
||||
helm repo add strimzi https://strimzi.io/charts/
|
||||
helm install --name kafka-operator -n default strimzi/strimzi-kafka-operator
|
||||
```
|
||||
|
||||
2. Create a Kafka cluster and a Kafka topic in the `default` namespace:
|
||||
|
||||
To deploy a Kafka cluster and create a Kafka topic, you simply need to open the ***kubectl*** console in ***KubeSphere Toolbox*** and run the following command:
|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
The following will create Kafka and Zookeeper clusters with storage type `ephemeral` which is `emptydir` for demo purpose. You should use other storage types for production, please refer to [kafka-persistent](https://github.com/strimzi/strimzi-kafka-operator/blob/0.19.0/examples/kafka/kafka-persistent.yaml)
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
```yaml
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: Kafka
|
||||
metadata:
|
||||
name: my-cluster
|
||||
namespace: default
|
||||
spec:
|
||||
kafka:
|
||||
version: 2.5.0
|
||||
replicas: 3
|
||||
listeners:
|
||||
plain: {}
|
||||
tls: {}
|
||||
config:
|
||||
offsets.topic.replication.factor: 3
|
||||
transaction.state.log.replication.factor: 3
|
||||
transaction.state.log.min.isr: 2
|
||||
log.message.format.version: '2.5'
|
||||
storage:
|
||||
type: ephemeral
|
||||
zookeeper:
|
||||
replicas: 3
|
||||
storage:
|
||||
type: ephemeral
|
||||
entityOperator:
|
||||
topicOperator: {}
|
||||
userOperator: {}
|
||||
---
|
||||
apiVersion: kafka.strimzi.io/v1beta1
|
||||
kind: KafkaTopic
|
||||
metadata:
|
||||
name: my-topic
|
||||
namespace: default
|
||||
labels:
|
||||
strimzi.io/cluster: my-cluster
|
||||
spec:
|
||||
partitions: 3
|
||||
replicas: 3
|
||||
config:
|
||||
retention.ms: 7200000
|
||||
segment.bytes: 1073741824
|
||||
EOF
|
||||
```
|
||||
|
||||
3. Run the following command to wait for Kafka and Zookeeper pods are all up and runing:
|
||||
|
||||
```bash
|
||||
kubectl -n default get pod
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
my-cluster-entity-operator-f977bf457-s7ns2 3/3 Running 0 69m
|
||||
my-cluster-kafka-0 2/2 Running 0 69m
|
||||
my-cluster-kafka-1 2/2 Running 0 69m
|
||||
my-cluster-kafka-2 2/2 Running 0 69m
|
||||
my-cluster-zookeeper-0 1/1 Running 0 71m
|
||||
my-cluster-zookeeper-1 1/1 Running 1 71m
|
||||
my-cluster-zookeeper-2 1/1 Running 1 71m
|
||||
strimzi-cluster-operator-7d6cd6bdf7-9cf6t 1/1 Running 0 104m
|
||||
```
|
||||
|
||||
Then run the follwing command to find out metadata of kafka cluster
|
||||
|
||||
```bash
|
||||
kafkacat -L -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092
|
||||
```
|
||||
|
||||
4. Add Kafka as logs receiver:
|
||||
Click ***Add Log Collector*** and then select ***Kafka***, input Kafka broker address and port like below:
|
||||
|
||||
```bash
|
||||
my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc 9092
|
||||
my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc 9092
|
||||
```
|
||||
|
||||

|
||||
|
||||
5. Run the following command to verify whether the Kafka cluster is receiving logs sent from Fluent Bit:
|
||||
|
||||
```bash
|
||||
# Start a util container
|
||||
kubectl run --rm utils -it --generator=run-pod/v1 --image arunvelsriram/utils bash
|
||||
# Install Kafkacat in the util container
|
||||
apt-get install kafkacat
|
||||
# Run the following command to consume log messages from kafka topic: my-topic
|
||||
kafkacat -C -b my-cluster-kafka-0.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-1.my-cluster-kafka-brokers.default.svc:9092,my-cluster-kafka-2.my-cluster-kafka-brokers.default.svc:9092 -t my-topic
|
||||
```
|
||||
|
|
@ -0,0 +1,94 @@
|
|||
---
|
||||
title: "Introduction"
|
||||
keywords: 'kubernetes, log, elasticsearch, kafka, fluentd, pod, container, fluentbit, output'
|
||||
description: 'Add log receivers to receive container logs'
|
||||
|
||||
linkTitle: "Introduction"
|
||||
weight: 2100
|
||||
---
|
||||
|
||||
KubeSphere provides a flexible log collection configuration method. Powered by [FluentBit Operator](https://github.com/kubesphere/fluentbit-operator/), users can add/modify/delete/enable/disable Elasticsearch, Kafka and Fluentd receivers with ease. Once a receiver is added, logs will be sent to this receiver.
|
||||
|
||||
## Prerequisite
|
||||
|
||||
Before adding a log receiver, you need to enable any of the `logging`, `events` or `auditing` components following [Enable Pluggable Components](https://kubesphere.io/docs/pluggable-components/).
|
||||
|
||||
## Add Log Receiver (aka Collector) for container logs
|
||||
|
||||
To add a log receiver:
|
||||
|
||||
- Login with an account of ***platform-admin*** role
|
||||
- Click ***Platform*** -> ***Clusters Management***
|
||||
- Select a cluster if multiple clusters exist
|
||||
- Click ***Cluster Settings*** -> ***Log Collections***
|
||||
- Log receivers can be added by clicking ***Add Log Collector***
|
||||
|
||||

|
||||
|
||||
{{< notice note >}}
|
||||
|
||||
- At most one receiver can be added for each receiver type.
|
||||
- Different types of receivers can be added simultaneously.
|
||||
|
||||
{{</ notice >}}
|
||||
|
||||
### Add Elasticsearch as log receiver
|
||||
|
||||
A default Elasticsearch receiver will be added with its service address set to an Elasticsearch cluster if logging/events/auditing is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md)
|
||||
|
||||
An internal Elasticsearch cluster will be deployed into K8s cluster if neither ***externalElasticsearchUrl*** nor ***externalElasticsearchPort*** are specified in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md) when logging/events/auditing is enabled.
|
||||
|
||||
Configuring an external Elasticsearch cluster is recommended for production usage, the internal Elasticsearch cluster is for test/development/demo purpose only.
|
||||
|
||||
Log searching relies on the internal/external Elasticsearch cluster configured.
|
||||
|
||||
Please refer to [Add Elasticsearch as receiver](../add-es-as-receiver) to add a new Elasticsearch log receiver if the default one is deleted.
|
||||
|
||||
### Add Kafka as log receiver
|
||||
|
||||
Kafka is often used to receive logs and serve as a broker to other processing systems like Spark. [Add Kafka as receiver](../add-kafka-as-receiver) demonstrates how to add Kafka to receive Kubernetes logs.
|
||||
|
||||
### Add Fluentd as log receiver
|
||||
|
||||
If you need to output logs to more places other than Elasticsearch or Kafka, you'll need to add Fluentd as a log receiver. Fluentd has numerous output plugins which can forward logs to various destinations like S3, MongoDB, Cassandra, MySQL, syslog, Splunk etc. [Add Fluentd as receiver](../add-fluentd-as-receiver) demonstrates how to add Fluentd to receive Kubernetes logs.
|
||||
|
||||
## Add Log Receiver (aka Collector) for events/auditing logs
|
||||
|
||||
Starting from KubeSphere v3.0.0, K8s events logs and K8s/KubeSphere auditing logs can be archived in the same way as container logs. There will be ***Events*** or ***Auditing*** tab in the ***Log Collections*** page if ***events*** or ***auditing*** component is enabled in [ClusterConfiguration](https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md). Log receivers for K8s events or K8s/KubeSphere auditing can be configured after switching to the corresponding tab.
|
||||
|
||||

|
||||
|
||||
Container logs, K8s events and K8s/KubeSphere auditing logs should be stored in different Elasticsearch indices to be searched in KubeSphere, the index prefixes are:
|
||||
|
||||
- ***ks-logstash-log*** for container logs
|
||||
- ***ks-logstash-events*** for K8s events
|
||||
- ***ks-logstash-auditing*** for K8s/KubeSphere auditing
|
||||
|
||||
## Turn a log receiver on or off
|
||||
|
||||
KubeSphere supports turning a log receiver on or off without adding/deleting it.
|
||||
To turn a log receiver on or off:
|
||||
|
||||
- Click a log receiver and enter the receiver details page.
|
||||
- Click ***More*** -> ***Change Status***
|
||||
|
||||

|
||||
|
||||
- You can select ***Activate*** or ***Close*** to turn the log receiver on or off
|
||||
|
||||

|
||||
|
||||
- Log receiver's status will be changed to ***Close*** if you turn it off, otherwise the status will be ***Collecting***
|
||||
|
||||

|
||||
|
||||
## Modify or delete a log receiver
|
||||
|
||||
You can modify a log receiver or delete it:
|
||||
|
||||
- Click a log receiver and enter the receiver details page.
|
||||
- You can edit a log receiver by clicking ***Edit*** or ***Edit Yaml***
|
||||
|
||||

|
||||
|
||||
- Log receiver can be deleted by clicking ***Delete Log Collector***
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue