mirror of
https://github.com/kubesphere/website.git
synced 2025-12-26 00:12:48 +00:00
Merge pull request #30 from FeynmanZhou/master
update projects, kubecon page in Resources
This commit is contained in:
commit
0ec0919ca4
|
|
@ -48,7 +48,7 @@ section3:
|
|||
- content: Support multi-cloud and multi-cluster Kubernetes management, avoiding vendor lock-in (coming soon)
|
||||
|
||||
- name: Developers
|
||||
content: Liberate YAML developers, enabling developers focus on business
|
||||
content: Liberate developers from complicated YAML, enabling them focus on business
|
||||
icon: /images/home/74.png
|
||||
children:
|
||||
- content: Create smooth user experience and reduce the learning curve of the cloud native stack
|
||||
|
|
@ -162,9 +162,10 @@ section6:
|
|||
- icon: /images/home/section6-powersmart.jpg
|
||||
- icon: /images/home/section6-wisdom-world.jpg
|
||||
- icon: /images/home/section6-sina.jpg
|
||||
- icon: /images/home/section6-softtek.jpg
|
||||
- icon: /images/home/section6-webank.jpg
|
||||
- icon: /images/home/section6-vng.jpg
|
||||
- icon: /images/home/section6-99kvm.jpg
|
||||
|
||||
btnContent: Case Studies
|
||||
btnLink:
|
||||
link:
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: "page1"
|
||||
title: "KubeSphere Presentations on KubeCon"
|
||||
|
||||
|
||||
css: "scss/conferences.scss"
|
||||
|
|
@ -8,42 +8,25 @@ viewDetail: View Details
|
|||
|
||||
list:
|
||||
- name: KubeCon
|
||||
content: KUBECON_DESC
|
||||
content: Kubecon is an annual conference hosted by the Cloud Native Computing Foundation. We have given these presentations in KubeCon 2019.
|
||||
icon: images/conferences/kubecon.svg
|
||||
bg: images/conferences/kubecon-bg.svg
|
||||
children:
|
||||
- name: 'Multi-tenant Management: Creating Accounts, Roles, Workspaces, Projects and DevOps Projects'
|
||||
summary: ObjectiveIn this quickstart, as a cluster admin, you will learn how to create workspaces, roles and user accounts, and then invite new users…
|
||||
author: xxx
|
||||
link: admin-quick-start
|
||||
image:
|
||||
- name: 'Cloud Native Observability: Log Management'
|
||||
summary: As logs often contain very valuable information, log management represents an important part of cloud native observability.
|
||||
author: Benjamin Huo, Dan Ma
|
||||
link: logging
|
||||
image: https://pek3b.qingstor.com/kubesphere-docs/png/20200607224942.png
|
||||
|
||||
- name: Managing Canary Release of Microservice Application on Kubernetes with Istio
|
||||
summary: Istio’s service mesh is able to manage traffic distribution with complete independence from deployment scaling, which enables a simpler, yet…
|
||||
author: xxx
|
||||
- name: 'Porter: An Open Source Load Balancer for Kubernetes in a Bare Metal Environment'
|
||||
summary: Porter allows you to create Kubernetes services of type LoadBalancer in bare metal cluster, which makes you enjoy the consistent experience with the cloud.
|
||||
author: Xuetao Song
|
||||
link: canary-release
|
||||
image:
|
||||
|
||||
- name: Deploying a Grafana Application to Kubernetes Using Application Template
|
||||
summary: ObjectiveThis tutorial shows you how to quickly deploy a Grafana application in KubeSphere via App Template, demonstrating the basic…
|
||||
author: xxx
|
||||
link: app-template
|
||||
image:
|
||||
image: https://pek3b.qingstor.com/kubesphere-docs/png/20190930095713.png
|
||||
|
||||
- name: QCon International Software Development Conference
|
||||
content: QCON_DESC
|
||||
icon: images/conferences/qcon.svg
|
||||
bg: images/conferences/qcon-bg.svg
|
||||
children:
|
||||
- name: Creating a CI/CD Pipeline to Deploy Spring Boot App to Kubernetes
|
||||
summary: ObjectiveThis tutorial shows you how to create a CI/CD Pipeline within DevOps project, which is intended for deploying a Spring Boot sample…
|
||||
author: xxx
|
||||
link: cicd-jenkinsfile
|
||||
image:
|
||||
|
||||
- name: Creating Horizontal Pod Autoscaler for Deployment
|
||||
summary: The Horizontal Pod Autoscaler automatically scales the number of pods in a deployment based on observed CPU utilization or Memory usage. The…
|
||||
author: xxx
|
||||
link: hpa
|
||||
image:
|
||||
---
|
||||
---
|
||||
|
|
|
|||
|
|
@ -1,145 +0,0 @@
|
|||
---
|
||||
title: 'Multi-tenant Management: Creating Accounts, Roles, Workspaces, Projects and DevOps Projects'
|
||||
author: 'xxx'
|
||||
date: '2019-06-24'
|
||||
---
|
||||
|
||||
## Objective
|
||||
|
||||
In this quickstart, as a cluster admin, you will learn how to create workspaces, roles and user accounts, and then invite new users into the workspace to create their projects and DevOps projects. This tutorial is used to help beginners to become familiar with multi-tenant management.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to [install KubeSphere](https://kubesphere.io/en/install).
|
||||
- You need a default admin account.
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
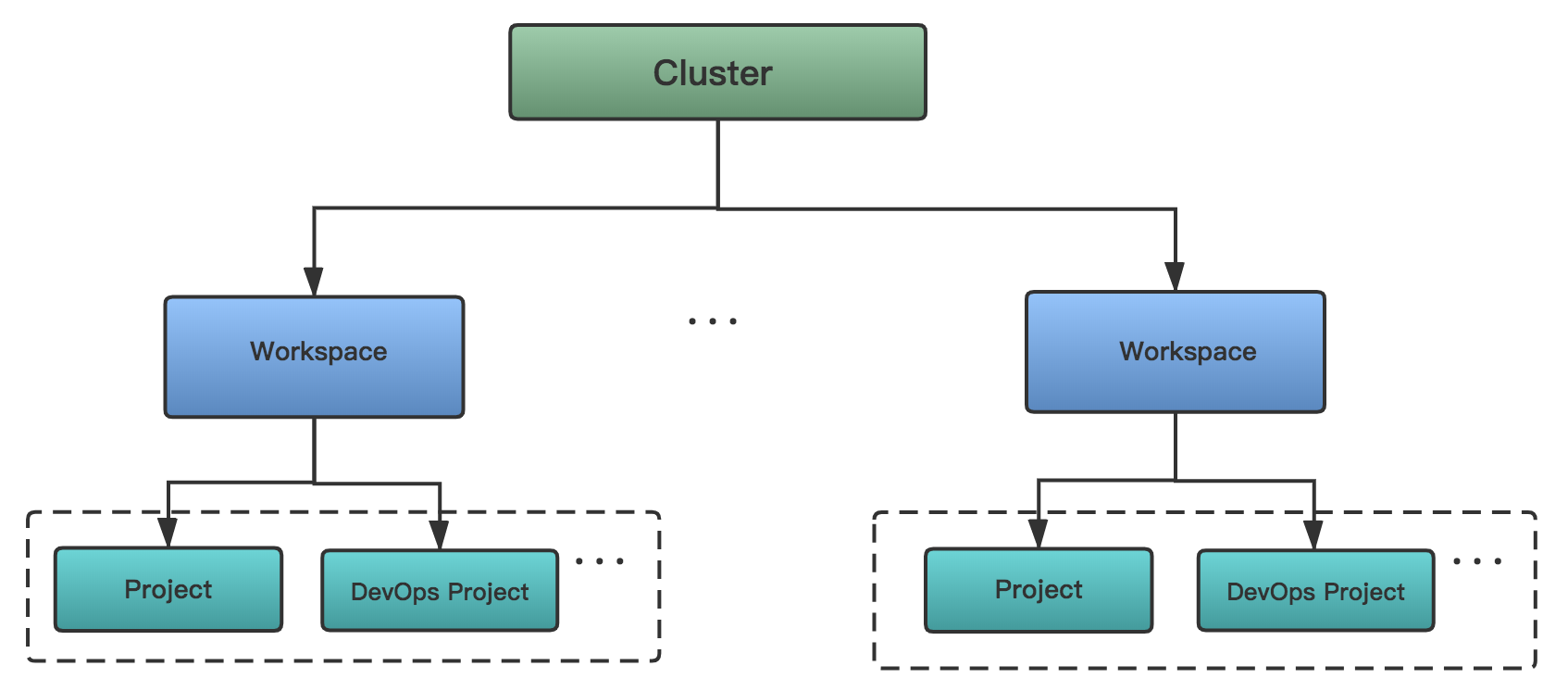
Generally, the hierarchy relationship of Cluster, Workspace, Project and DevOps Project showing as the following graph, and there are common built-in roles existed in these orgnizations within each level.
|
||||
|
||||
|
||||
|
||||
### Cluster Admin
|
||||
|
||||
The role of cluster-admin is able to create accounts for other users and assign roles to them. There are three common roles in cluster level, it also supports customizing new roles.
|
||||
|
||||
| Built-in Roles | Responsibility |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------- |
|
||||
| cluster-admin | Have the highest privileges for the cluster, can manage any resources |
|
||||
| workspaces-manager | The workspace managers, can manage all of the resources, e.g. projects, DevOps projects, members and roles |
|
||||
| cluster-regular | The regular users in the cluster, they are not authorized until they have been invited to the workspace |
|
||||
|
||||
#### Step 1: Create roles and accounts
|
||||
|
||||
First, we will create a new role (user-manager), grants account management and role management authority to this role, then we will create an account and grant the user-manager role to this account.
|
||||
|
||||
| Account Name | Cluster Role | Responsibility |
|
||||
| ------------ | ------------ | --------------------------------- |
|
||||
| user-manager | user-manager | Manage cluster accounts and roles |
|
||||
|
||||
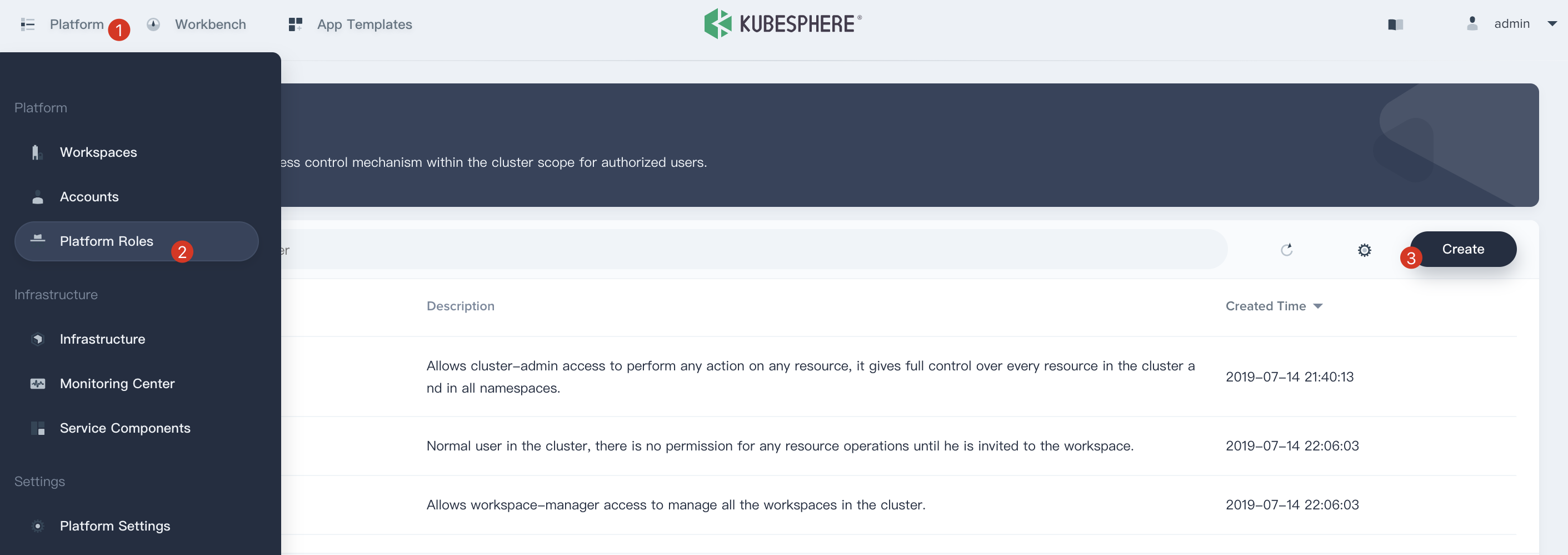
1.1 To get started, login KubeSphere with the `admin` account, click **Platform** and then navigate to **Platform Roles** page, click **Create** to create a role which is used to manage all accounts and roles.
|
||||
|
||||
|
||||
|
||||
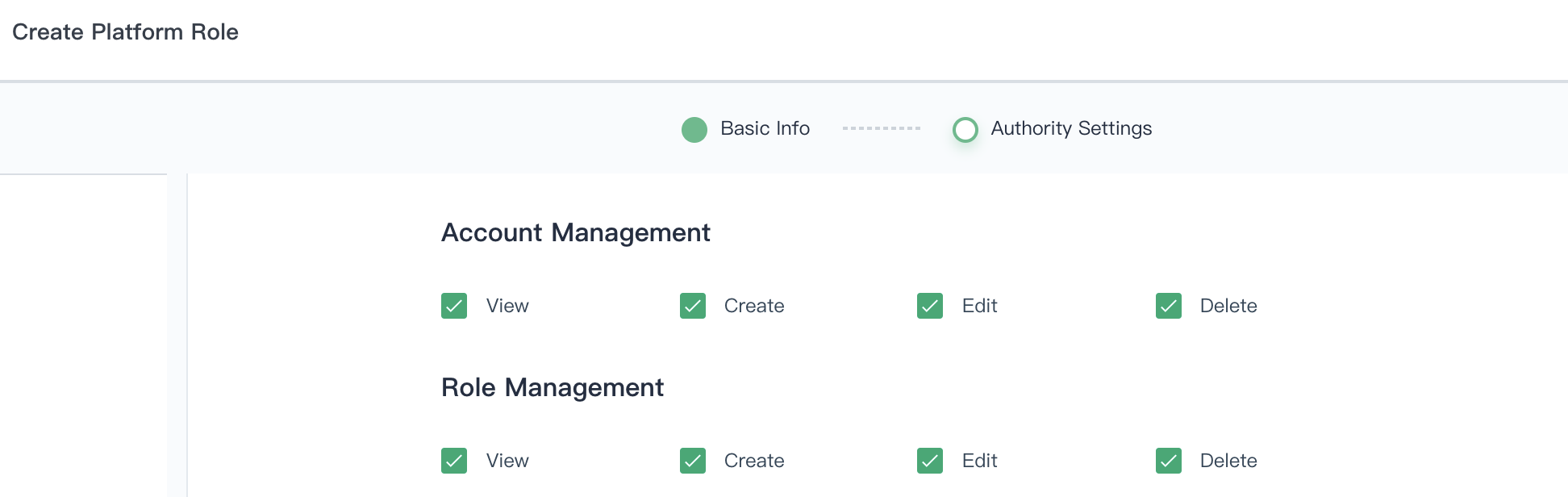
1.2. Fill in the basic information and authority settings of the role, e.g. `Name : user-manager`.
|
||||
|
||||
1.3. Check all the boxes for both **Account Management** and **Role Management**, then click **Create**.
|
||||
|
||||
|
||||
|
||||
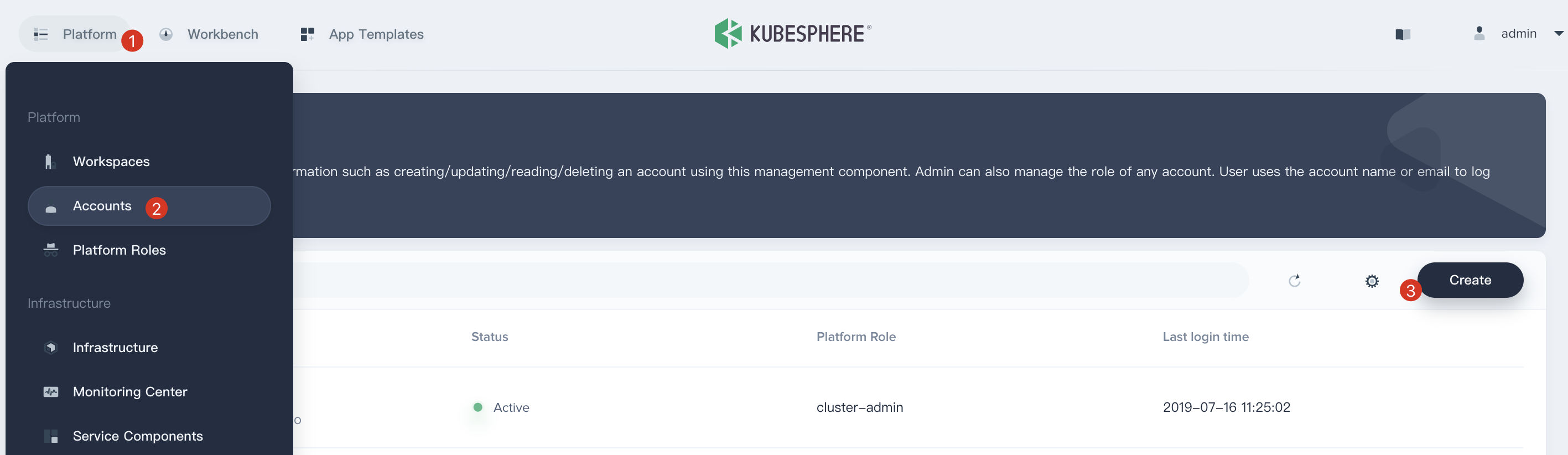
1.4. Click **Platform**, then navigate to **Accounts** page and click **Create** to create an account.
|
||||
|
||||
|
||||
|
||||
1.5. Fill in the basic information, notice that select `user-manger` as its role.
|
||||
|
||||
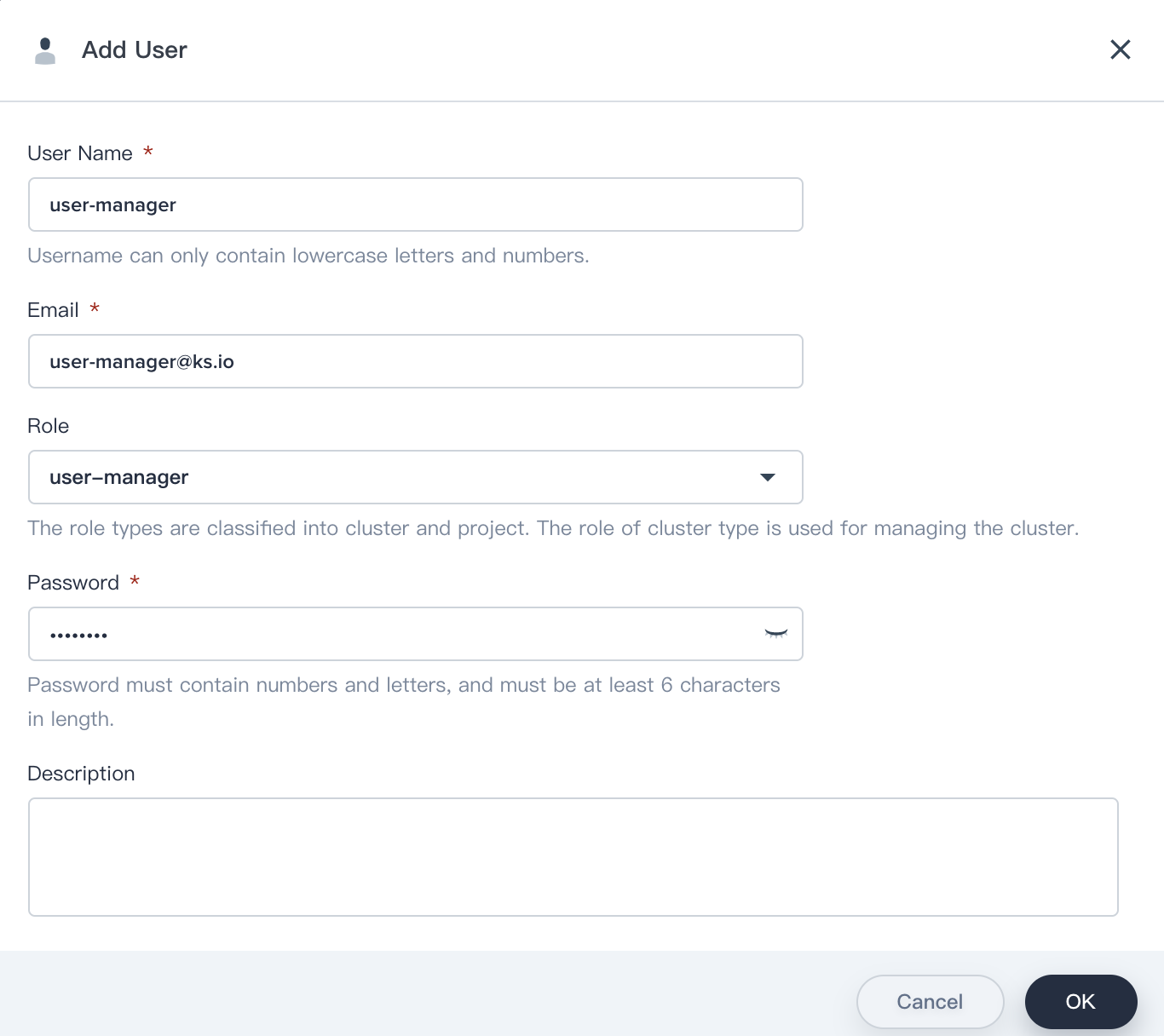
|
||||
|
||||
1.6. Log out and Sign in with the `user-manager` account, then navigate to **Account** and create 4 accounts according to the following table. Please reference the above steps to create these 4 accounts.
|
||||
|
||||
| Account Name | Cluster Role | Responsibility |
|
||||
| --------------- | ------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| ws-manager | workspaces-manager | Create and manage all workspaces |
|
||||
| ws-admin | cluster-regular | Manage all resources under the specified workspace<br> (This example is used to invite new members to join the workspace.) |
|
||||
| project-admin | cluster-regular | Create and manage projects, DevOps projects, invite new members |
|
||||
| project-regular | cluster-regular | The regular user will be invited to the project and DevOps project by the project-admin, <br> we use this account to create workloads, pipelines and other resources under the specified project |
|
||||
|
||||
1.7. Verify the 4 accounts that we created in step 1.6.
|
||||
|
||||

|
||||
|
||||
### Workspace Admin
|
||||
|
||||
#### Step 2: Create a Workspace
|
||||
|
||||
Workspace is the base of implementing the multi-tenant mechanism, it's also the base unit for projects and DevOps projects managment.
|
||||
|
||||
2.1. Sign in with `ws-manager` that we created in Step 1, then click **Workspace** and click **Create Workspace**, name it as demo-workspace and appoint `ws-admin` as Workspace Manager, who has the highest administrative authority of the workspace.
|
||||
|
||||
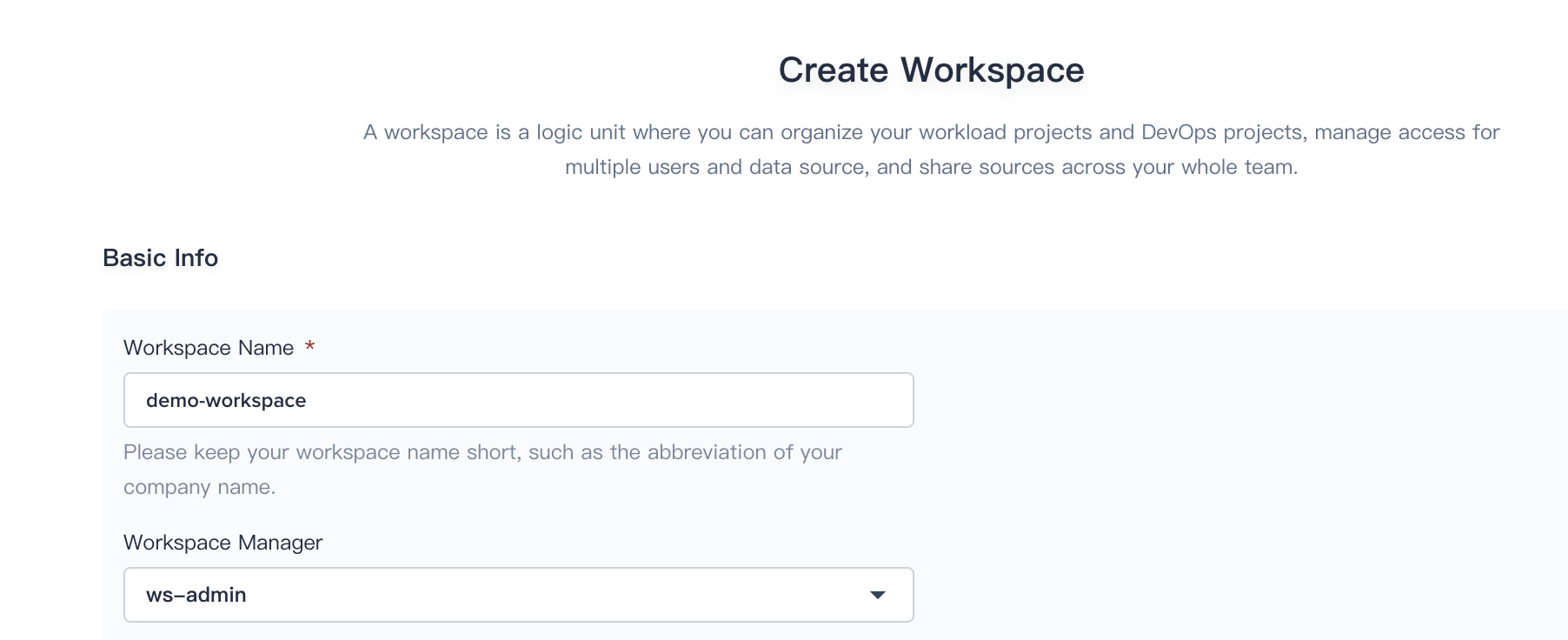
|
||||
|
||||
2.2. Logout and sign in with `ws-admin` after `demo-workspace` has been created. Then click **View Workspace**, select **Worksapce Management → Members Management** and click **Invite Member**.
|
||||
|
||||
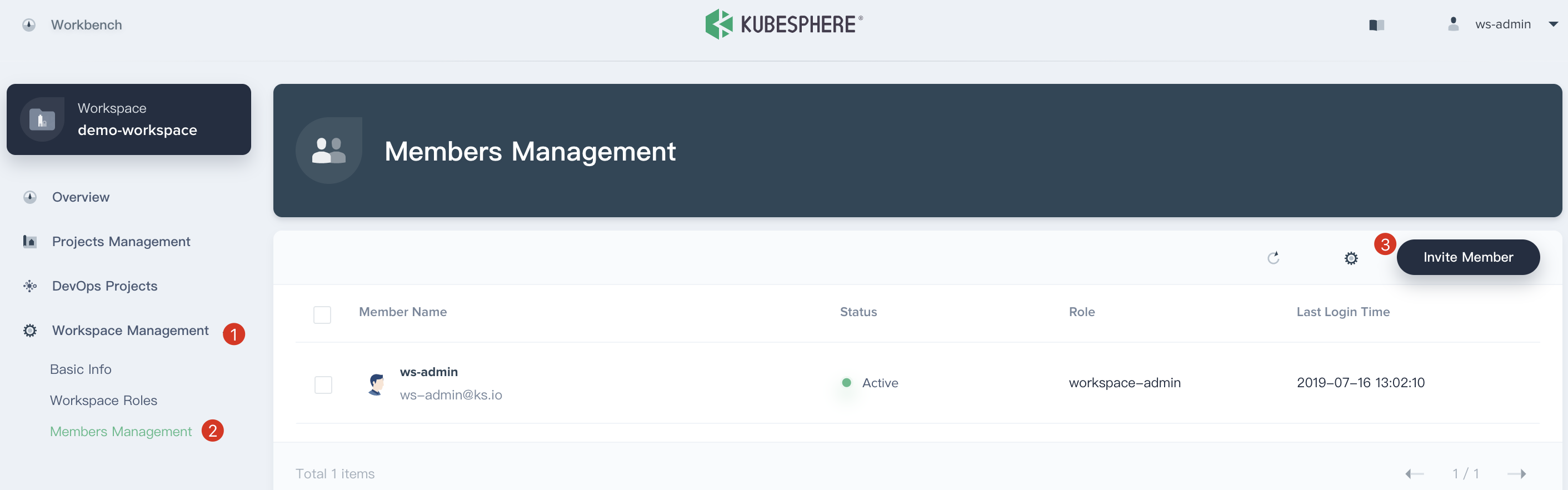
|
||||
|
||||
2.3. Invite both `project-admin` and `project-regular` and grant them `workspace-regular` accordingly, click **OK** to save it. Now there are 3 members in the `demo-workspace`.
|
||||
|
||||
| User Name | Role in the Workspace | Responsibility |
|
||||
| --------------- | --------------------- | ------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| ws-admin | workspace-admin | Manage all resources under the workspace<br> (We use this account to invite new members into the workspace) |
|
||||
| project-admin | workspace-regular | Create and manage projects, DevOps projects, and invite new members to join |
|
||||
| project-regular | workspace-viewer | Will be invited by project-admin to join the project and DevOps project. <br> we use this account to create workloads, pipelines, etc |
|
||||
|
||||
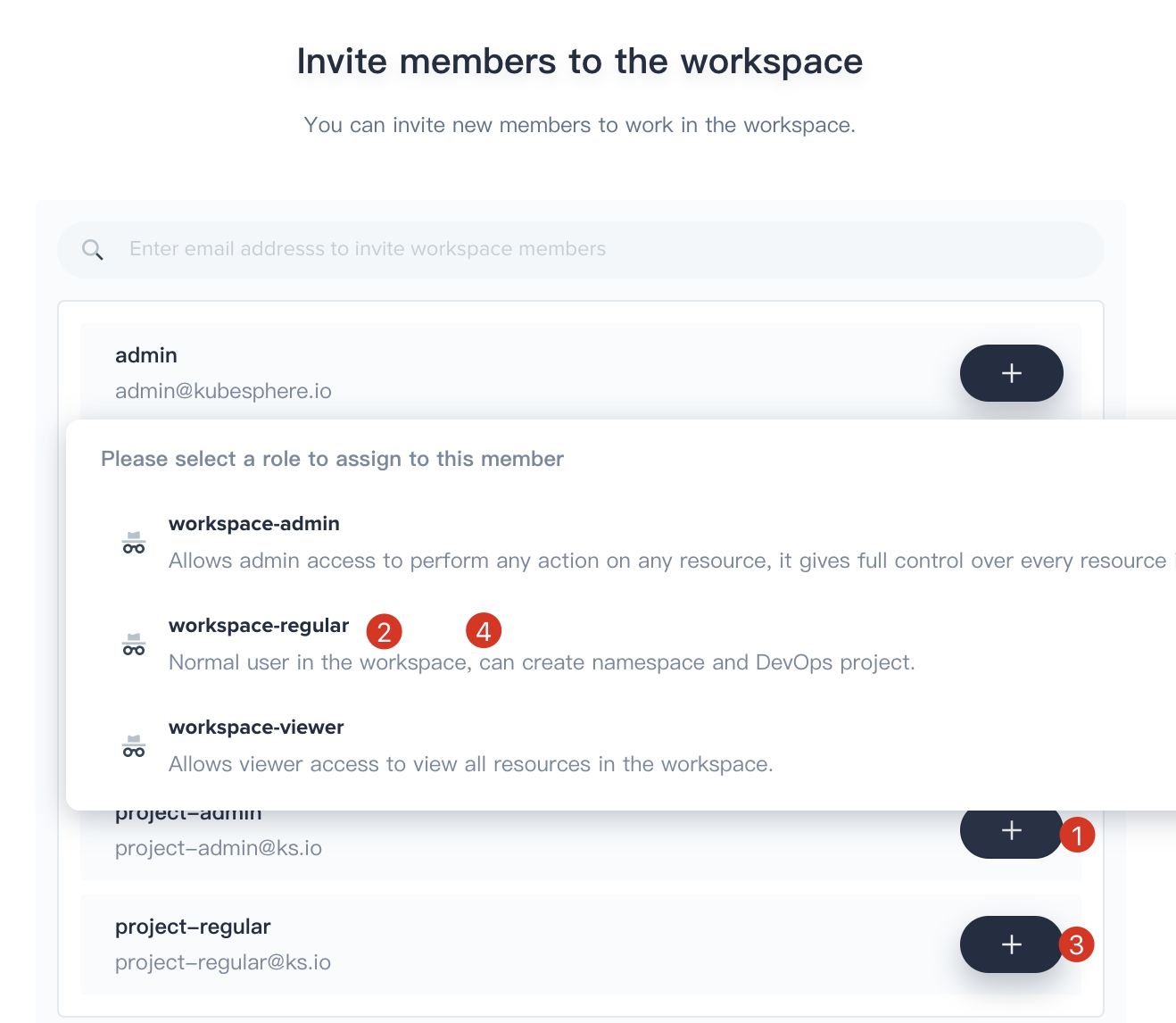
|
||||
|
||||
### Project Admin and DevOps Admin
|
||||
|
||||
#### Step 3: Create a Project
|
||||
|
||||
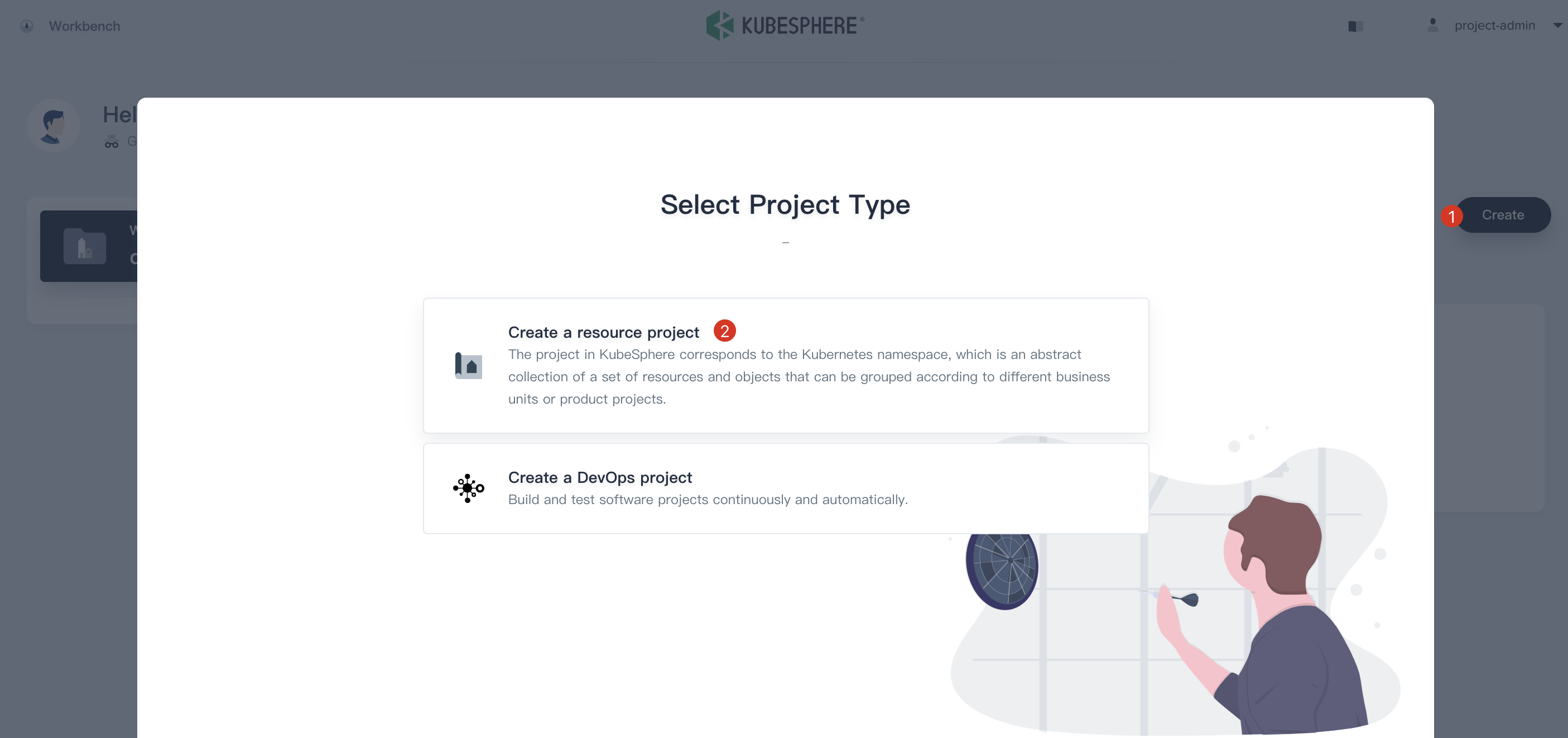
3.1. Sign in with `project-admin` that we created in Step 1, then click **Create** and select **Create a resource project**.
|
||||
|
||||
|
||||
|
||||
3.2. Name it as `demo-project` and keep the advanced settings as the default values, then click **Create**.
|
||||
|
||||
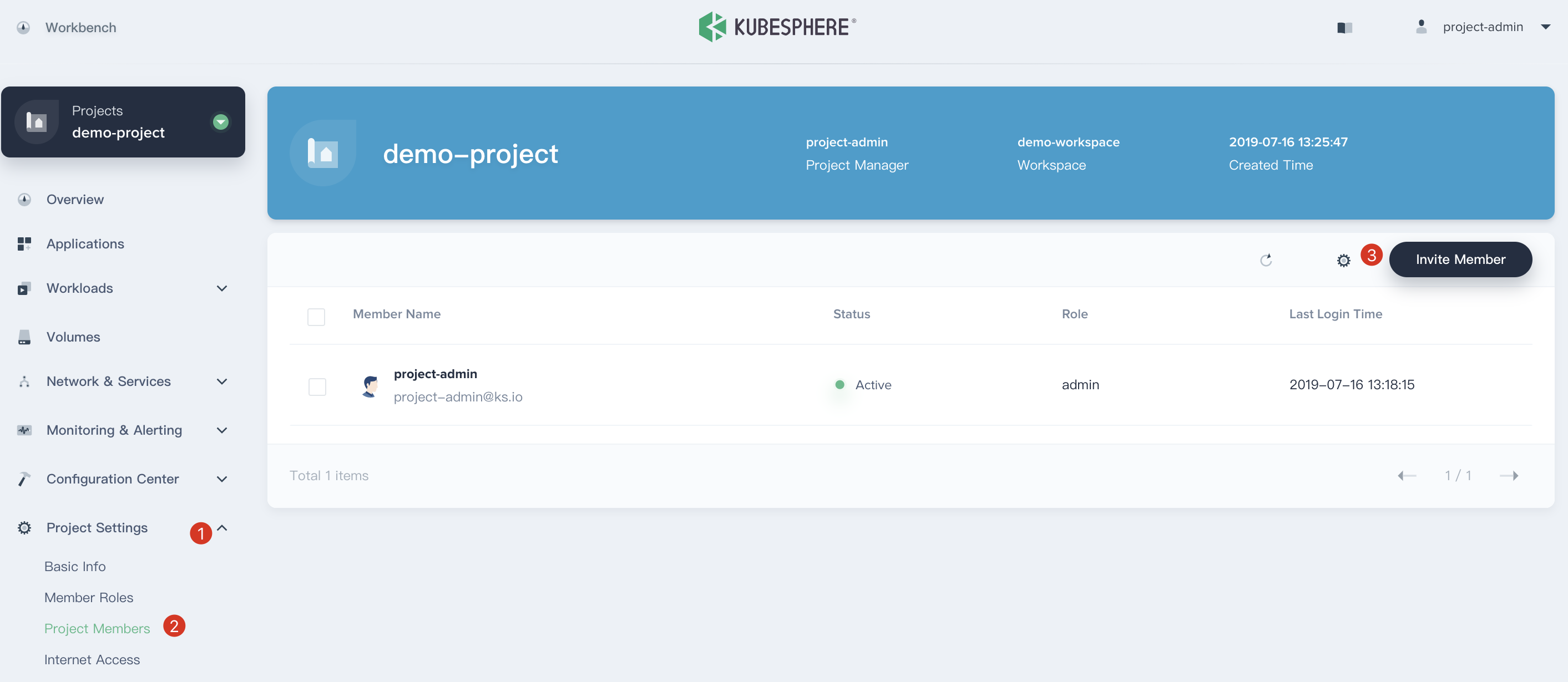
3.3. Choosing **Project Settings → Project Members** and click **Invite Member**.
|
||||
|
||||
|
||||
|
||||
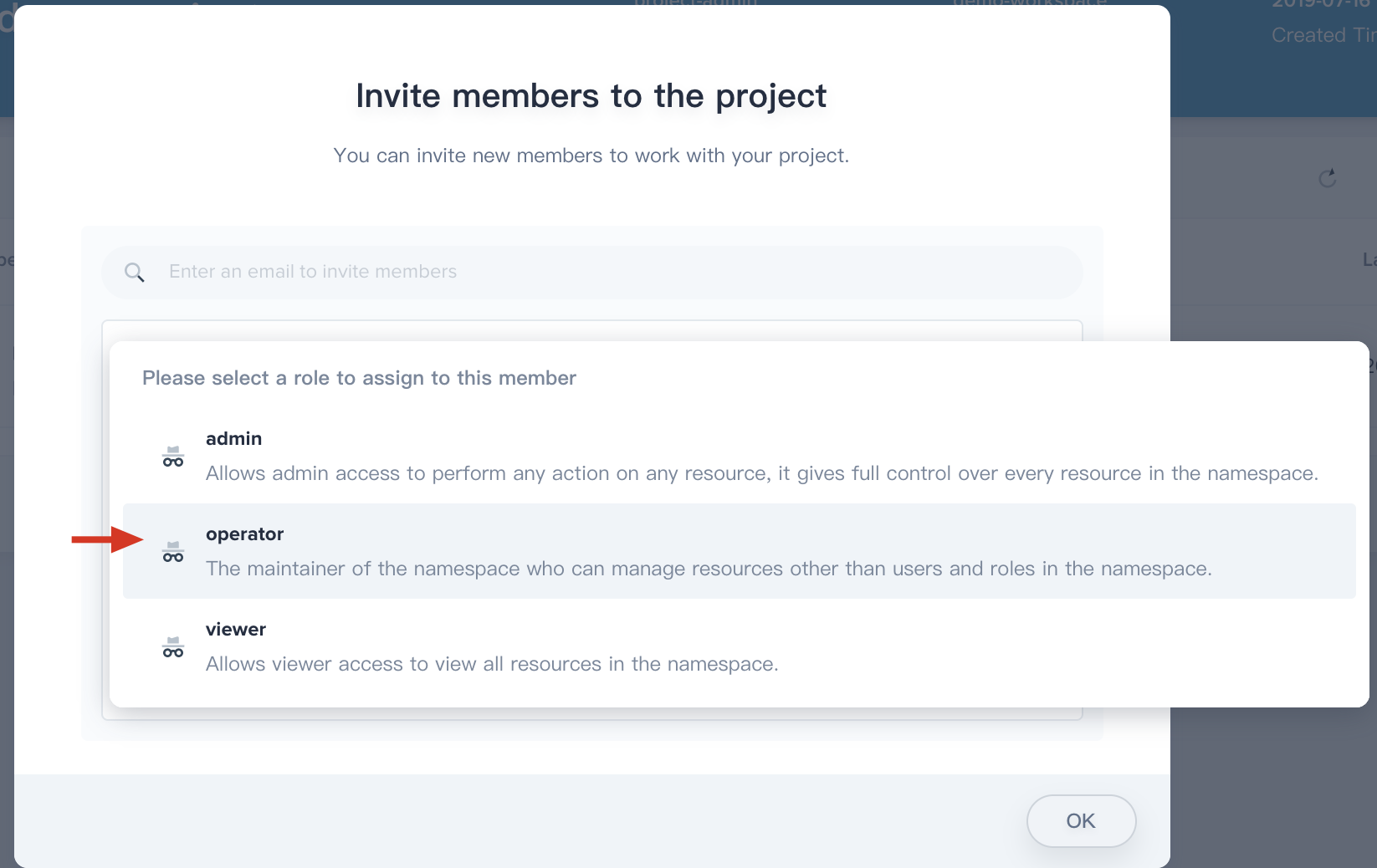
3.4. Invite `project-regular` to this project and grant this user **operator** accordingly.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
#### Step 4: Set the Gateway
|
||||
|
||||
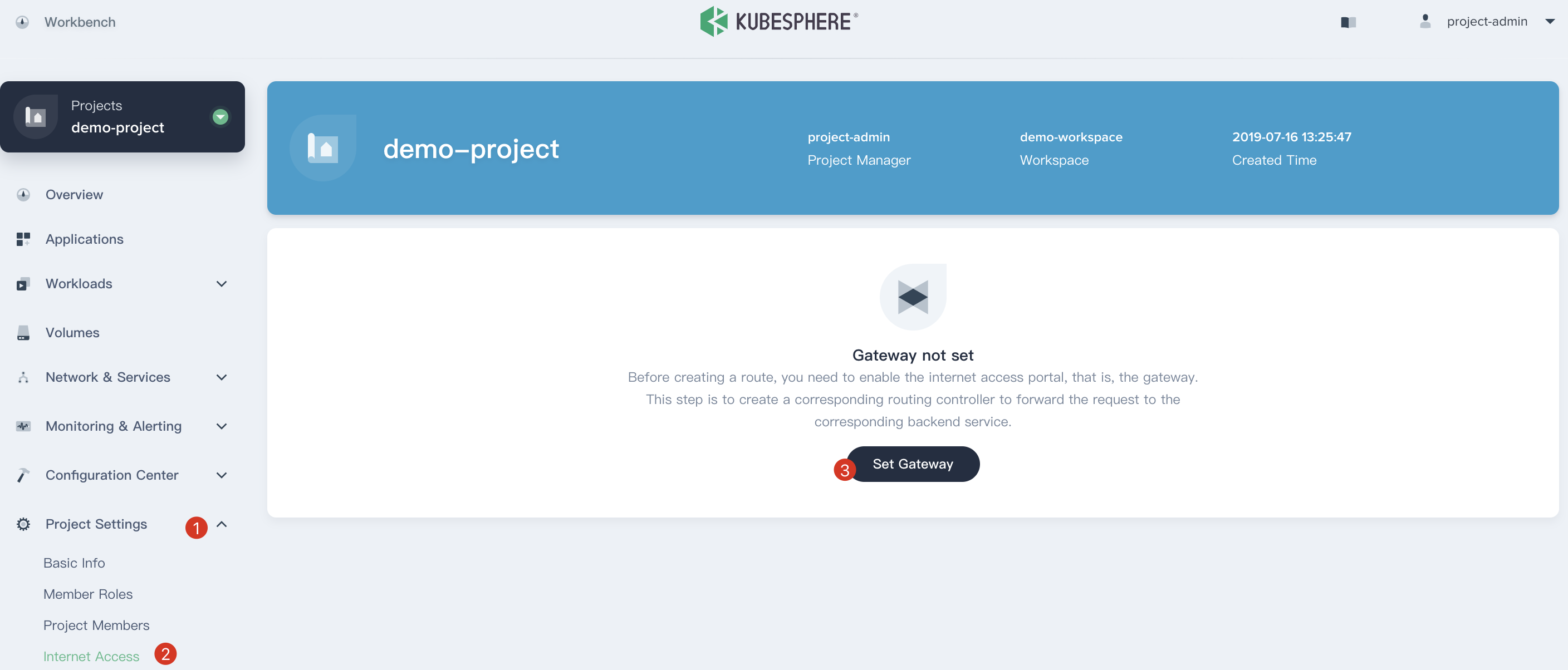
Before creating a route, you need to enable a gateway for this project.
|
||||
|
||||
4.1. We still use `project-admin`, Choose **Project Settings → Internet Access** and click **Set Gateway**.
|
||||
|
||||
|
||||
|
||||
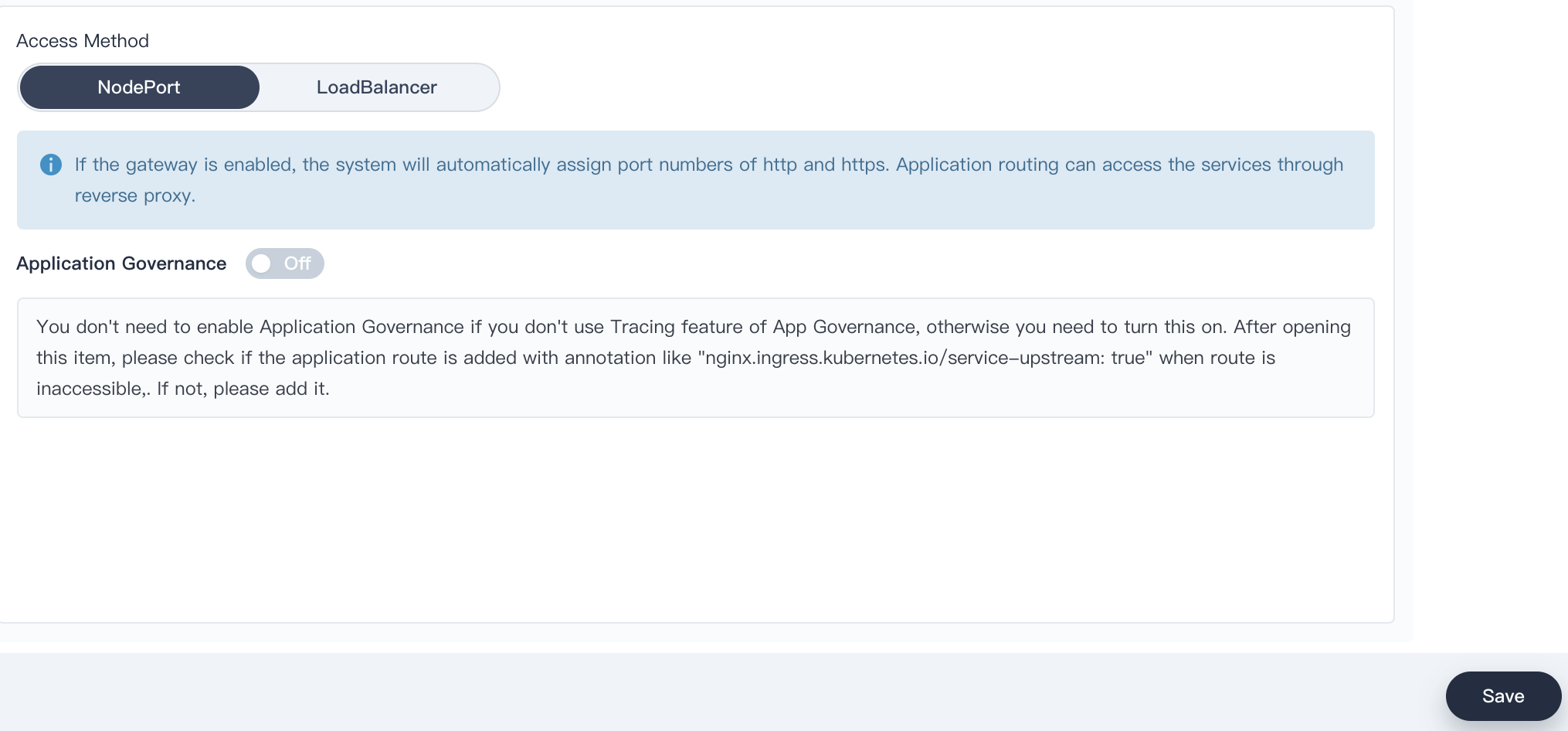
4.2. Keep the access method as `NodePort` and click `Save`.
|
||||
|
||||
|
||||
|
||||
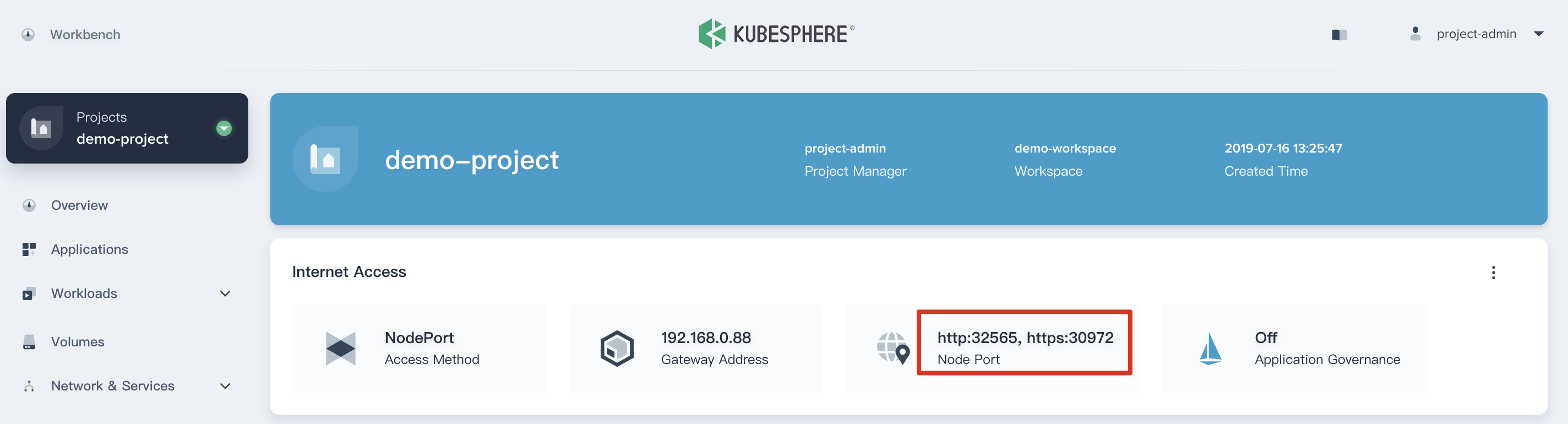
4.3. Now we are able to see the Gateway Address (192.168.0.88), the NodePort of http and https respectively.
|
||||
|
||||
|
||||
|
||||
#### Step 5: Create DevOps Project
|
||||
|
||||
5.1. In this step, click **Projects** and click `Create Project` button, then select **Create a DevOps project**.
|
||||
|
||||
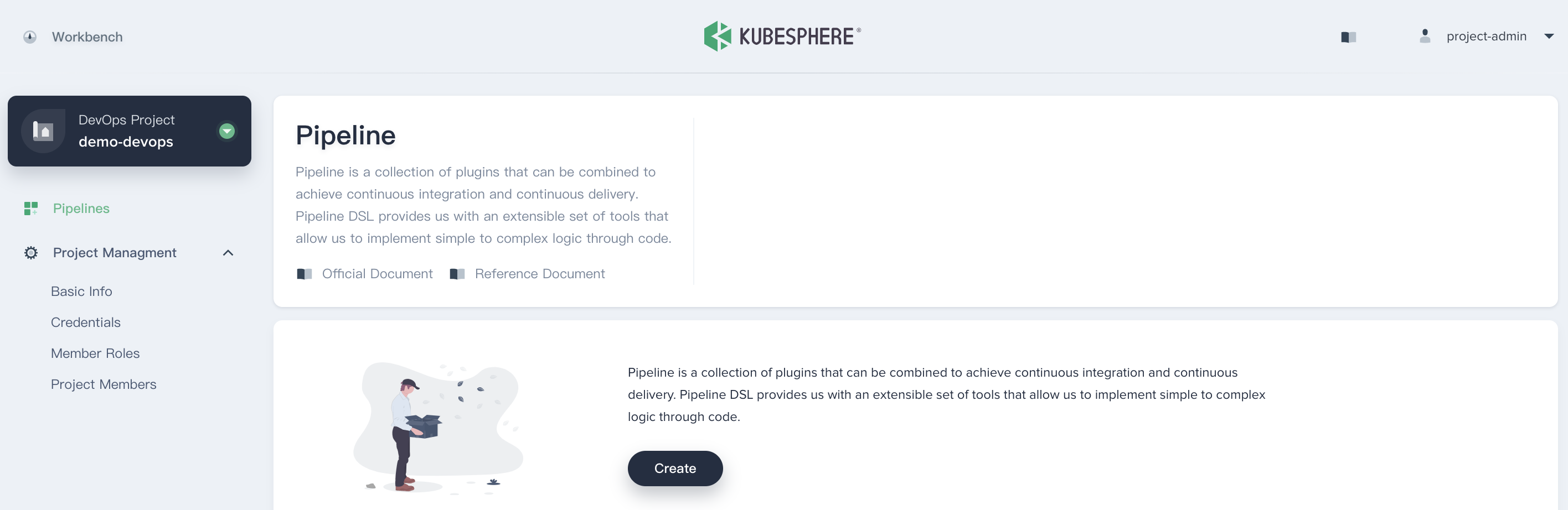
5.2. Fill in the basic information, e.g. `demo-devops`, then click **Create** button, it will jump to `demo-devops` page.
|
||||
|
||||
|
||||
|
||||
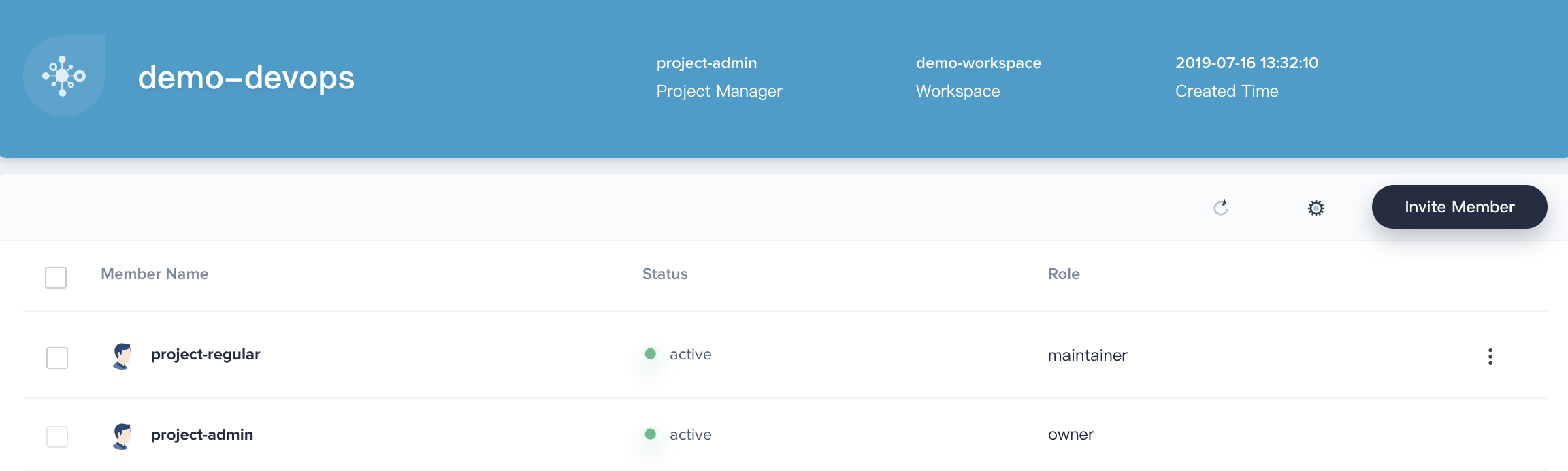
5.3. Similarly, navigate to **Project Management → Project Members**, then click **Invite Member** and grant `project-regular` as the role of `maintainer`, which is used to create pipeline, credentials, etc.
|
||||
|
||||
|
||||
|
||||
<!-- ## Next Step
|
||||
|
||||
Tutorial 2 - [Expose your App: Create a Service and Ingress](ingress-demo.md). -->
|
||||
|
|
@ -1,87 +0,0 @@
|
|||
---
|
||||
title: 'Deploying a Grafana Application to Kubernetes Using Application Template'
|
||||
|
||||
author: 'xxx'
|
||||
---
|
||||
|
||||
## Objective
|
||||
|
||||
This tutorial shows you how to quickly deploy a [Grafana](https://grafana.com/) application in KubeSphere via App Template, demonstrating the basic functionality of the application repository, application templates, and application management.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You've completed all steps in [Tutorial 1](admin-quick-start.md).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Add a Application Repository
|
||||
|
||||
> Note: The application repository can be either the Object Storage, e.g. [QingStor Object Storage](https://www.qingcloud.com/products/qingstor/), [AWS S3](https://aws.amazon.com/cn/what-is-cloud-object-storage/), or [GitHub Repository](https://github.com/). The packages are composed of Helm Chart template files of the applications. Therefore, before adding an application repository to KubeSphere, you need to create an object storage and upload Helm packages in advance. This tutorial prepares a demo repository based on QingStor Object Storage.
|
||||
|
||||
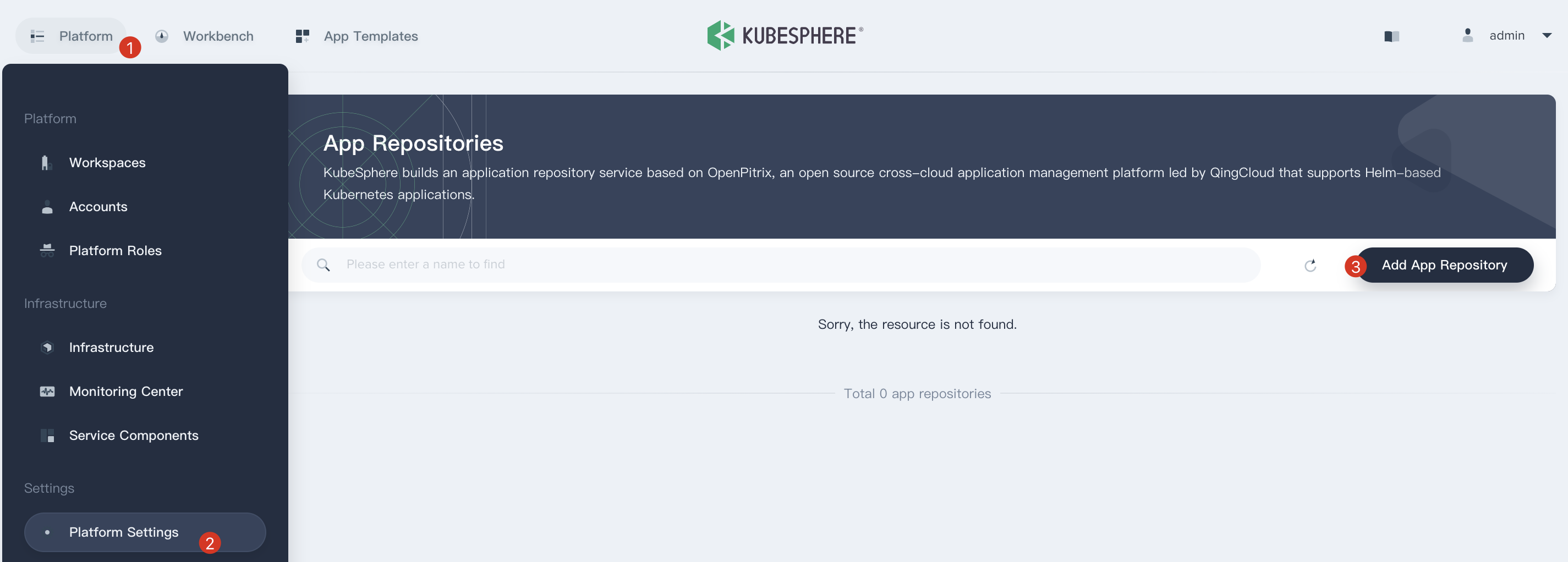
1.1. Sign in with `admin` account and navigate to **Platform → Platform Settings → App Repositories**, then Click **Add App Repository**.
|
||||
|
||||
|
||||
|
||||
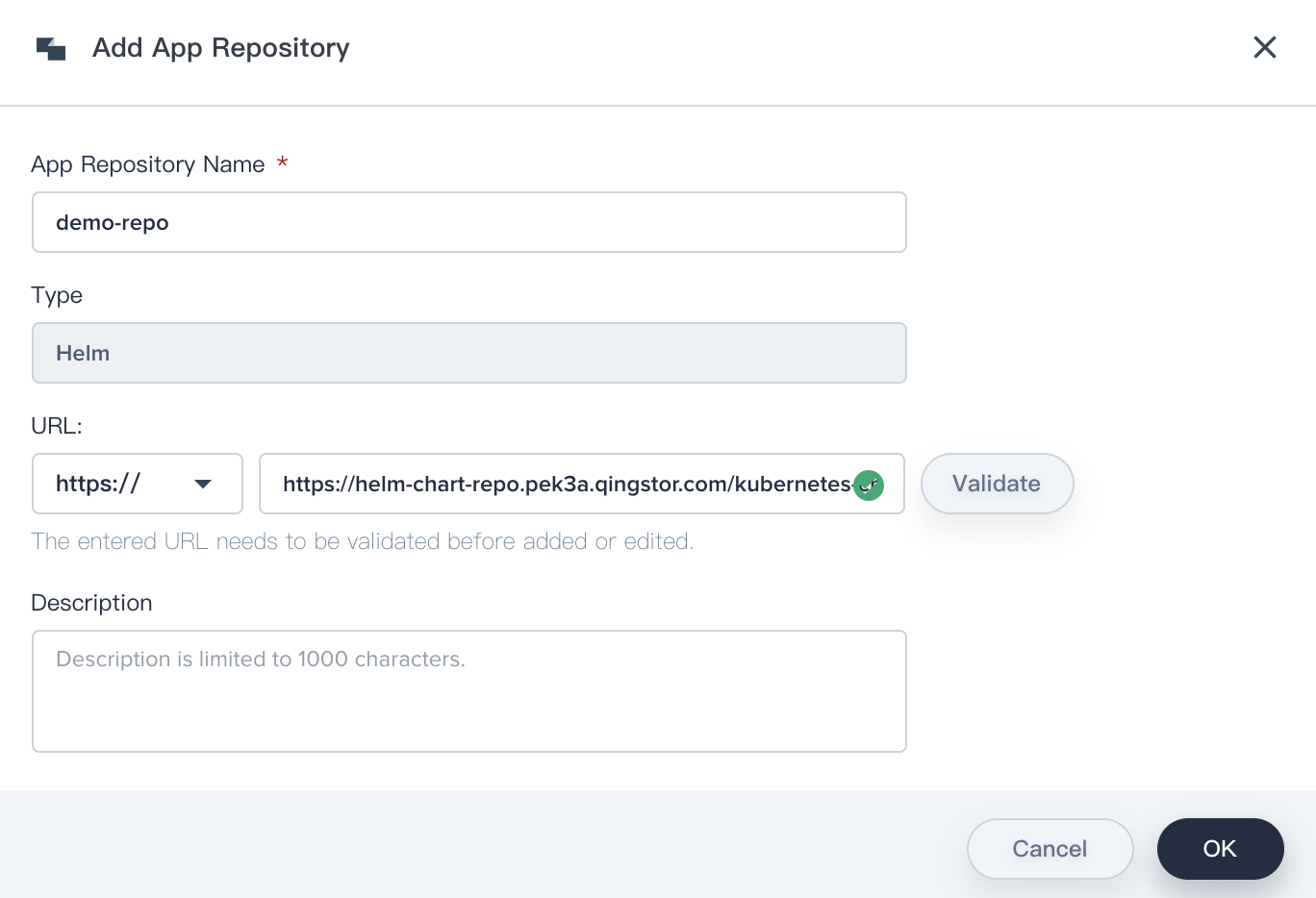
1.2. Fill in the basic information, name it as demo-repo and input the URL with `https://helm-chart-repo.pek3a.qingstor.com/kubernetes-charts/`, you can validate if this URL is available, choose **OK** when you've done.
|
||||
|
||||
|
||||
|
||||
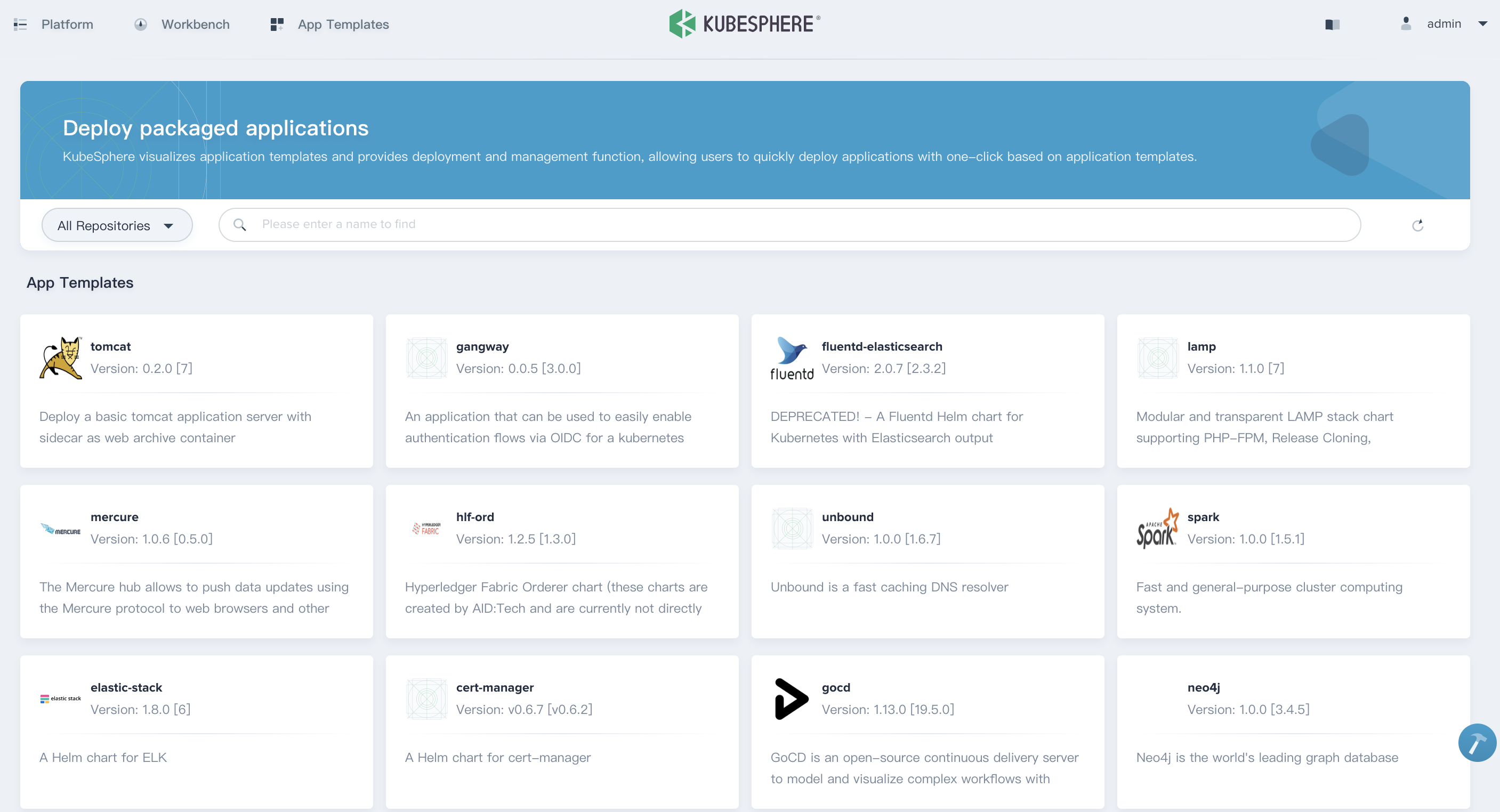
1.3. Click **App Templates** on the top of this page, it will automatically import all of the applications from the demo repository.
|
||||
|
||||
|
||||
|
||||
### Step 2: Deploy the Grafana Application
|
||||
|
||||
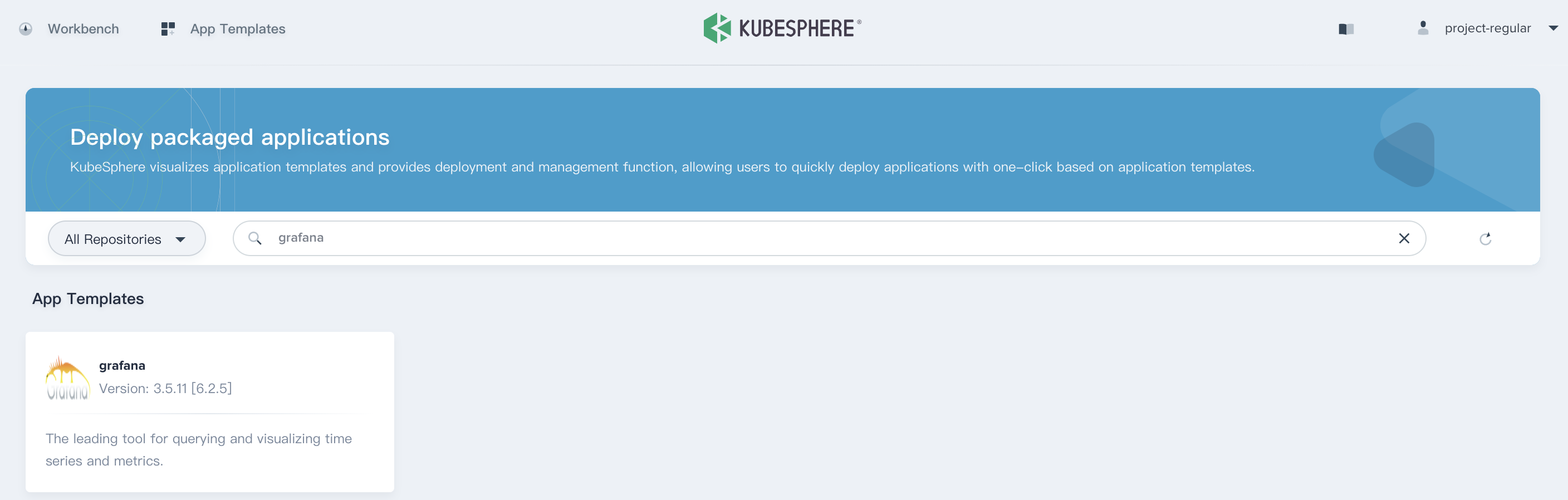
2.1. When you've already added the repository, you can logout and sign in with `project-regular` account. Then select **App Templates** on the top of this page, input "grafana" in the search box to find the application.
|
||||
|
||||
|
||||
|
||||
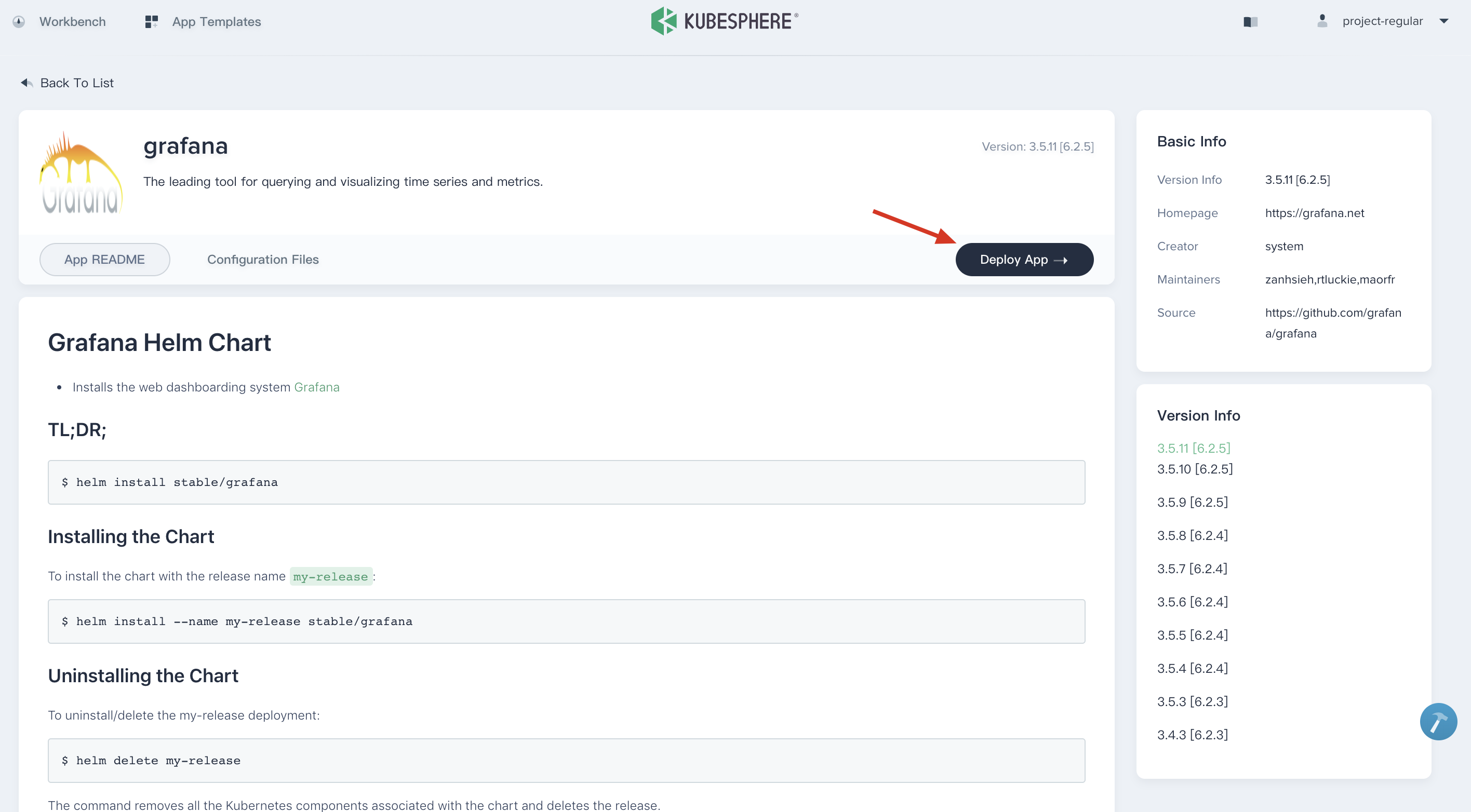
2.2. Click into grafana, **Deploy App** and fill in the basic information.
|
||||
|
||||
|
||||
|
||||
2.3. **Name** can be customized by yourself, choose the corresponding Workspace (e.g. `demo-workspace`) and Project (e.g. `demo-project`) as the environment. Then choose **Deploy** to deploy Grafana to KubeSphere.
|
||||
|
||||
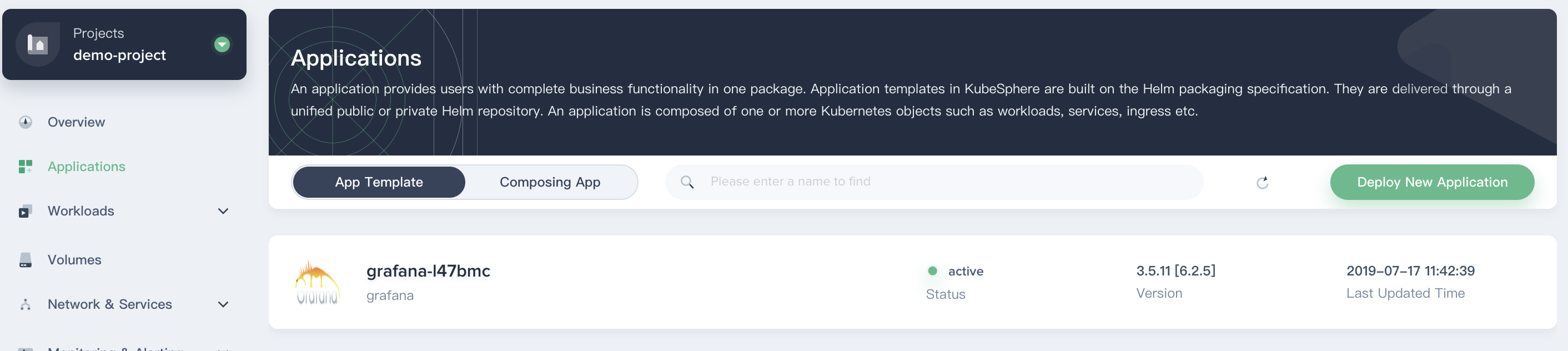
2.4. Back to the `demo-project` and choose **Applications**, then you can see the application `grafana` showing `active` from the application list.
|
||||
|
||||
|
||||
|
||||
### Step 3: View App Details
|
||||
|
||||
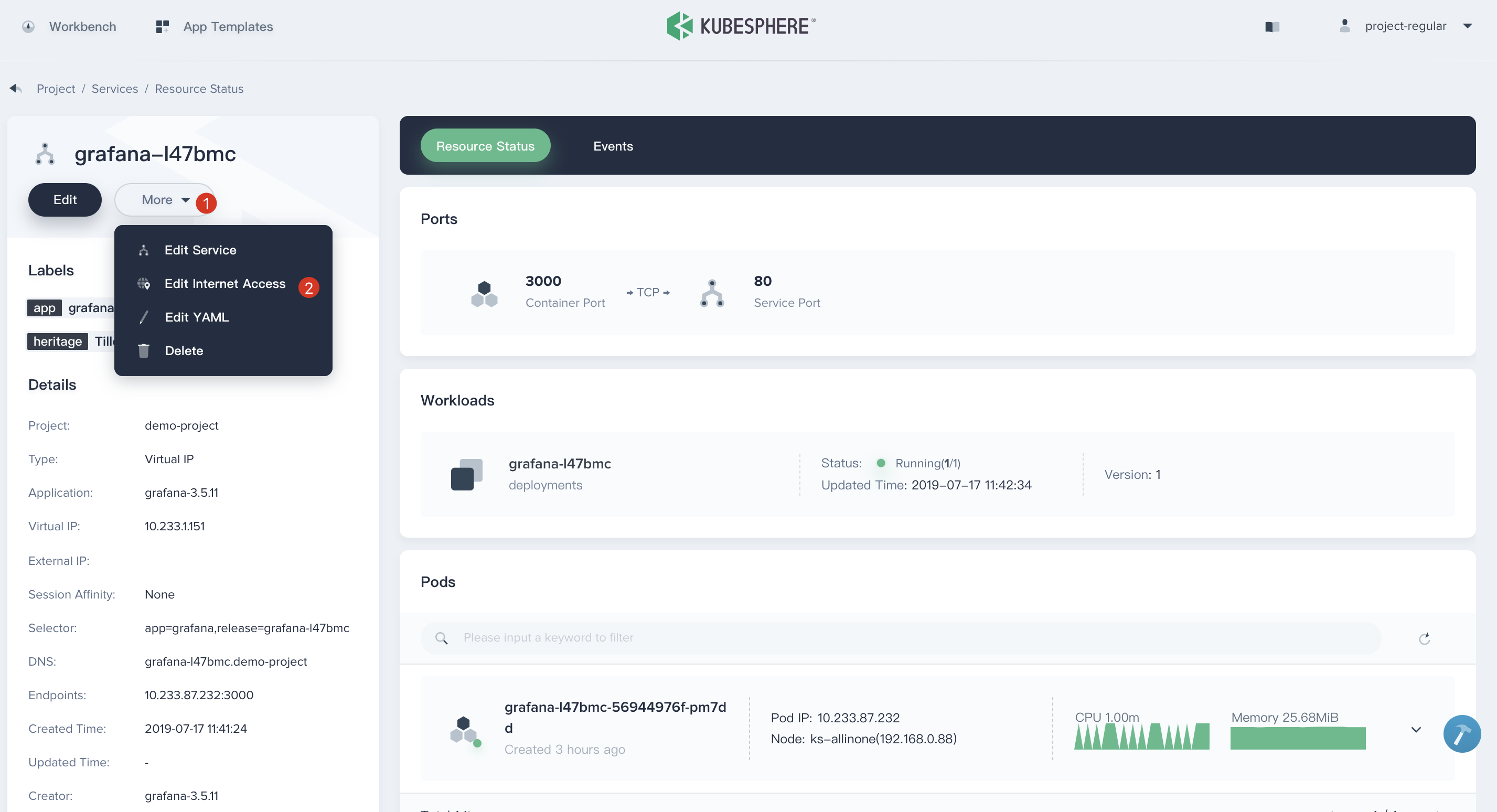
3.1. Click into `grafana` application, you will be able to see its Services and Workloads in `Resource Status` page, as well as Environmental Variables and App Template information.
|
||||
|
||||

|
||||
|
||||
3.2. Next we are going to expose this service outside of the cluster via NodePort. Enter into its service e.g. `grafana-l47bmc`, then click **More → Edit Internet Access**.
|
||||
|
||||
|
||||
|
||||
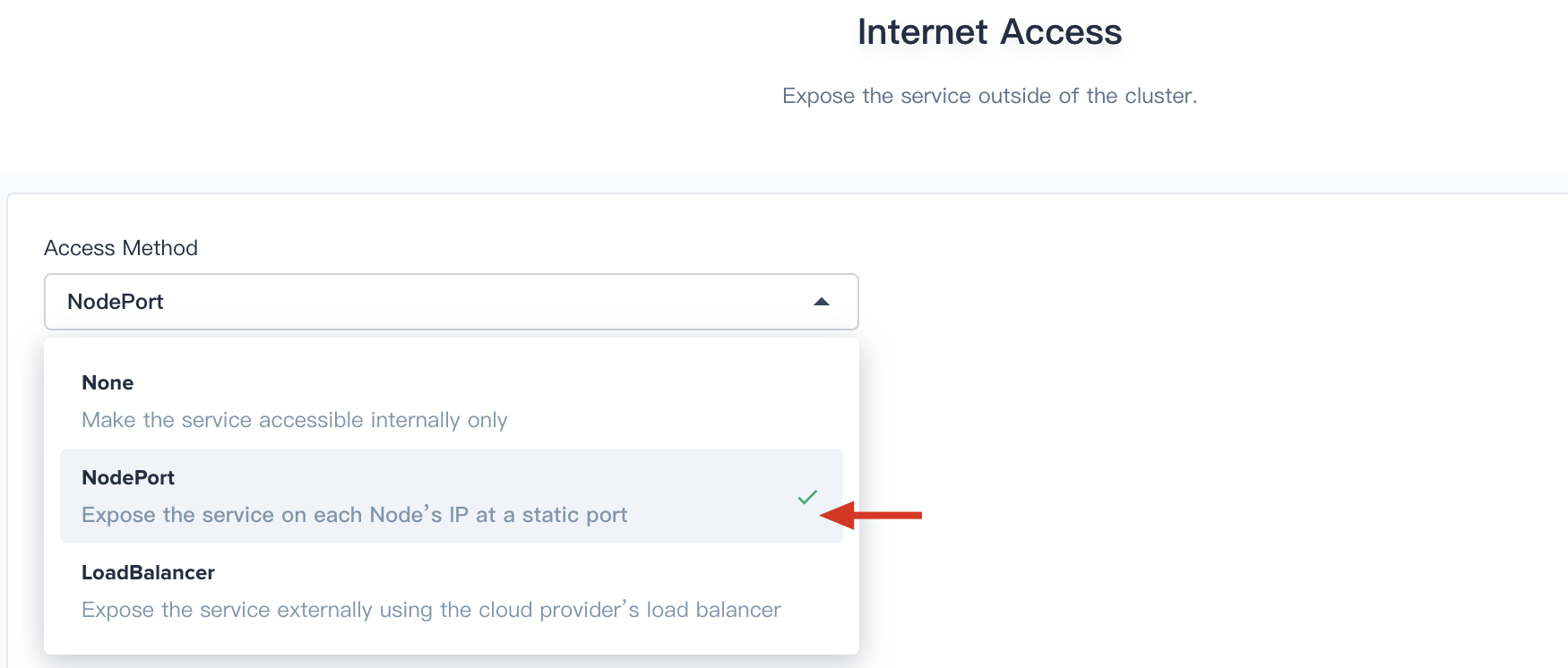
3.3. Select `NodePort` from the drop down list.
|
||||
|
||||
|
||||
|
||||
3.4. Therefore it will generate a Node Port, for example, here is `31126` that we can access this service using `<$NodeIP>:<$NodePort>`.
|
||||
|
||||

|
||||
|
||||
### Step 4: Access the Grafana Service
|
||||
|
||||
At this point, you will be able to access the Nginx service via `${Node IP}:${NODEPORT}`, e.g. `http://192.168.0.88:31126`, or click the button **Click to visit** to access the Grafana dashboard.
|
||||
|
||||
4.1. Note that you have to obtain the account and password from the grafana secret in advance. Navigate to **Configuration Center → Secrets**, click into **grafana-l47bmc (Type: Default)**.
|
||||
|
||||
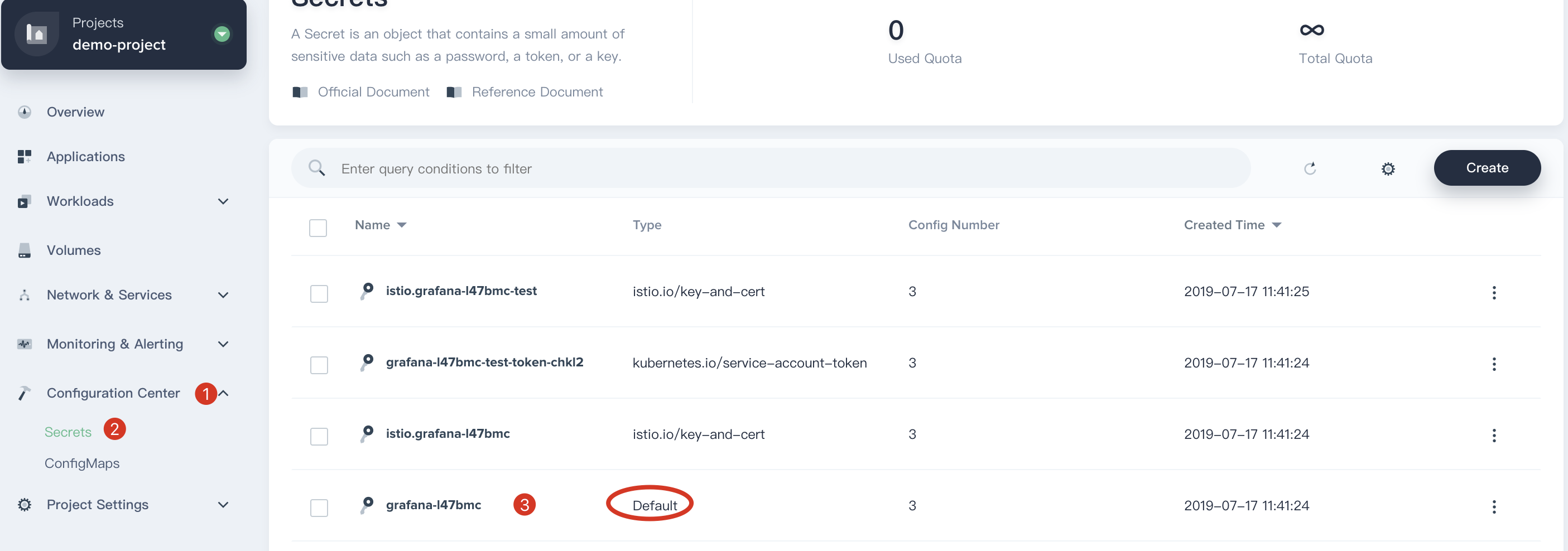
|
||||
|
||||
4.2. Click the button to display the secret information, then copy and paste the value of **admin-user** and **admin-password**.
|
||||
|
||||

|
||||
|
||||
4.3. Open the Grafana log in page, sign in with the **admin** account.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Next Step
|
||||
|
||||
Tutorial 7 - [Create Horizontal Pod Autoscaler for Deployment](hpa.md).
|
||||
|
|
@ -1,146 +0,0 @@
|
|||
---
|
||||
title: 'Managing Canary Release of Microservice Application on Kubernetes with Istio'
|
||||
|
||||
author: 'xxx'
|
||||
---
|
||||
|
||||
Istio’s service mesh is able to manage traffic distribution with complete independence from deployment scaling, which enables a simpler, yet significantly more functional way to realize canary release and rollout. It allows users to introduce a new version of a service by first testing it using a small percentage of user traffic, and then if all goes well, increase, possibly gradually in increments, the percentage while simultaneously phasing out the old version.
|
||||
|
||||
KubeSphere provides three kind of grayscale strategies based on Istio, including blue-green deployment, canary release and traffic mirroring. Without modifying the source code, KubeSphere can realize grayscale, traffic governance, tracing, traffic monitoring and other service mesh features.
|
||||
|
||||
## What is Bookinfo Application
|
||||
|
||||
The Bookinfo application is broken into four separate microservices (There are 3 versions of the reviews microservice):
|
||||
|
||||
- productpage. The productpage microservice calls the details and reviews microservices to populate the page.
|
||||
- details. The details microservice contains book information.
|
||||
- reviews. The reviews microservice contains book reviews. It also calls the ratings microservice.
|
||||
- ratings. The ratings microservice contains book ranking information that accompanies a book review.
|
||||
|
||||
The end-to-end architecture of the application is shown below, see [Bookinfo Application](https://istio.io/docs/examples/bookinfo/) for more details.
|
||||
|
||||
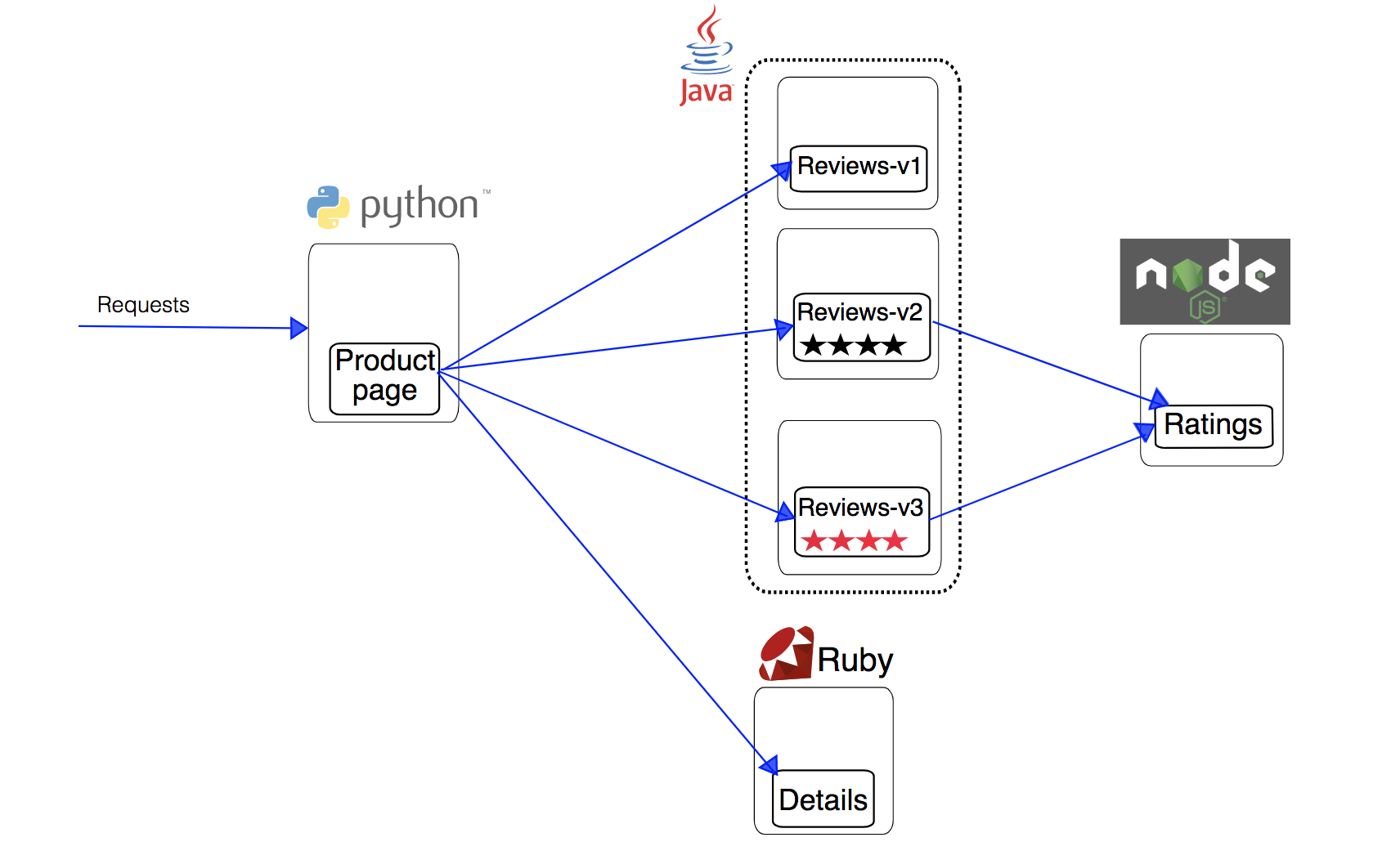
|
||||
|
||||
## Objective
|
||||
|
||||
In this tutorial, we're going to deploy a Bookinfo sample application composed of four separate microservices used to demonstrate the canary release, tracing and traffic monitoring using Istio on KubeSphere.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You've completed all steps in [Tutorial 1](admin-quick-start.md).
|
||||
- You need to turn on the **Application Governance** to enable the tracing feature. (Choose **Project Settings → Internet Access → Edit Gateway → Turn it On**)
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Deploy Bookinfo Application
|
||||
|
||||
1.1. Sign in with `project-regular` account and enter into the `demo-project`, navigate to **Application**, click on the **Deploy New Application** then choose **Deploy sample app Bookinfo**.
|
||||
|
||||
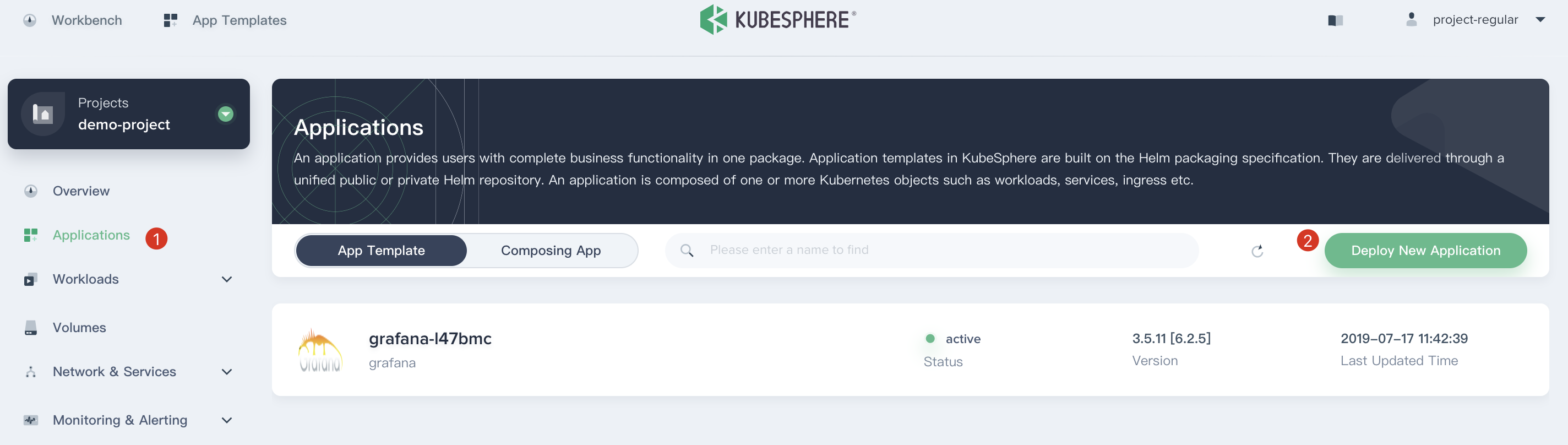
|
||||
|
||||
|
||||
|
||||
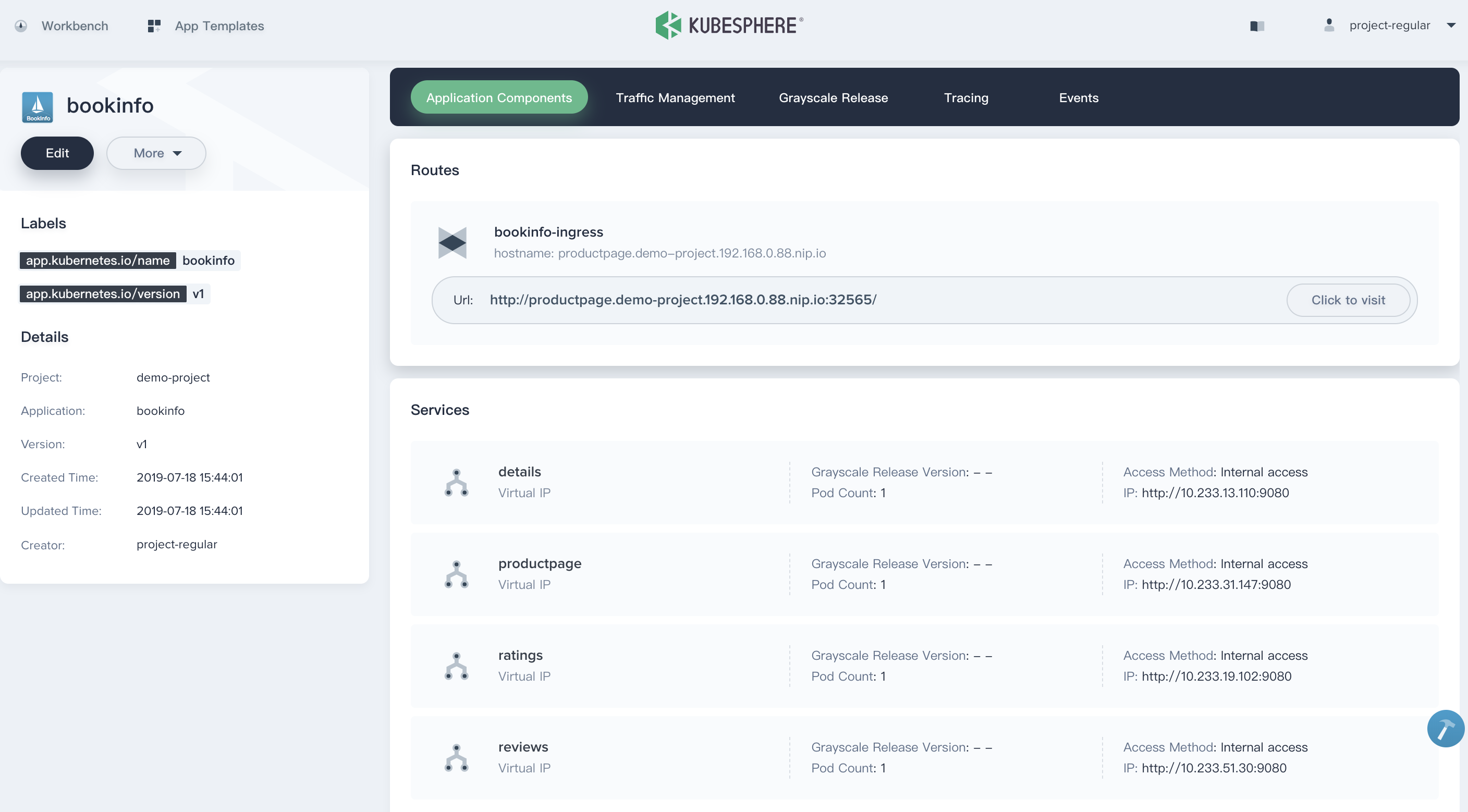
1.2. Click **Create** in the pop-up window, then Bookinfo application has been deployed successfully, application components are listed in this following page, as well as the routes and hostname.
|
||||
|
||||
|
||||
|
||||
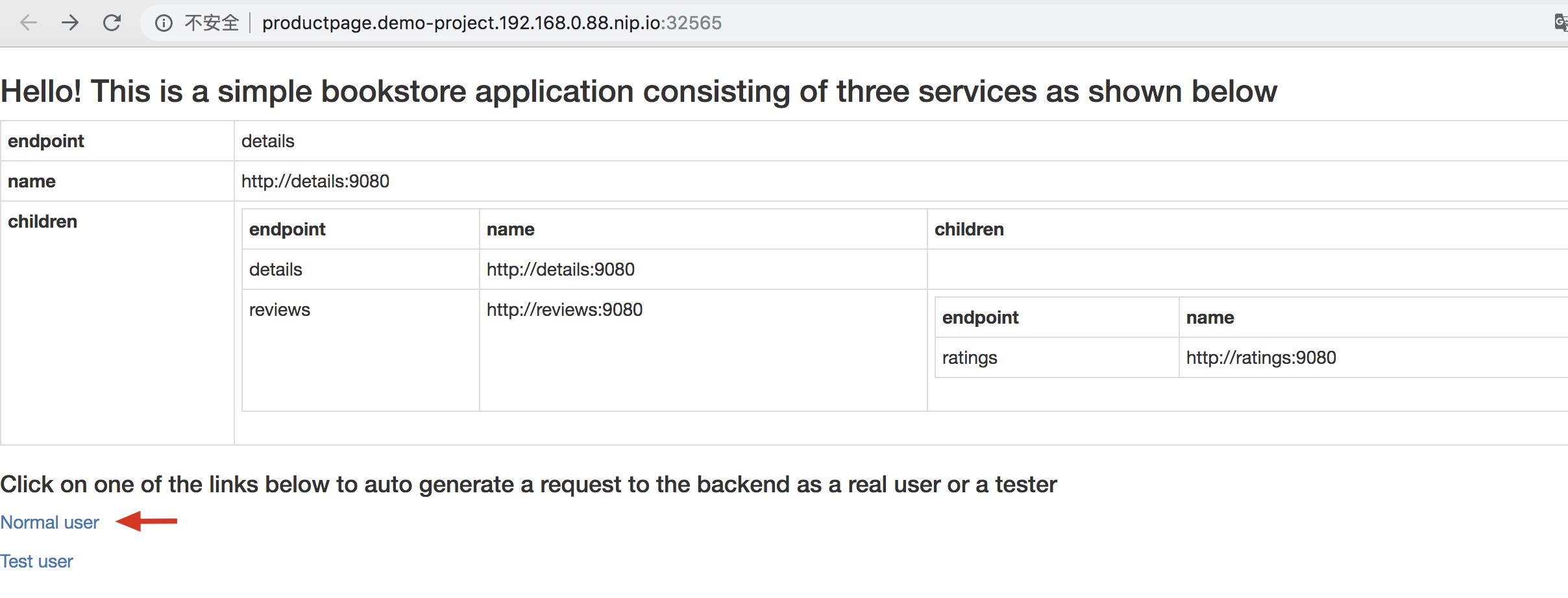
1.3. Next you can access the Bookinfo homepage as following screenshot via **Click to visit** button. Click on the **Normal user** to enter into the summary page.
|
||||
|
||||
|
||||
|
||||
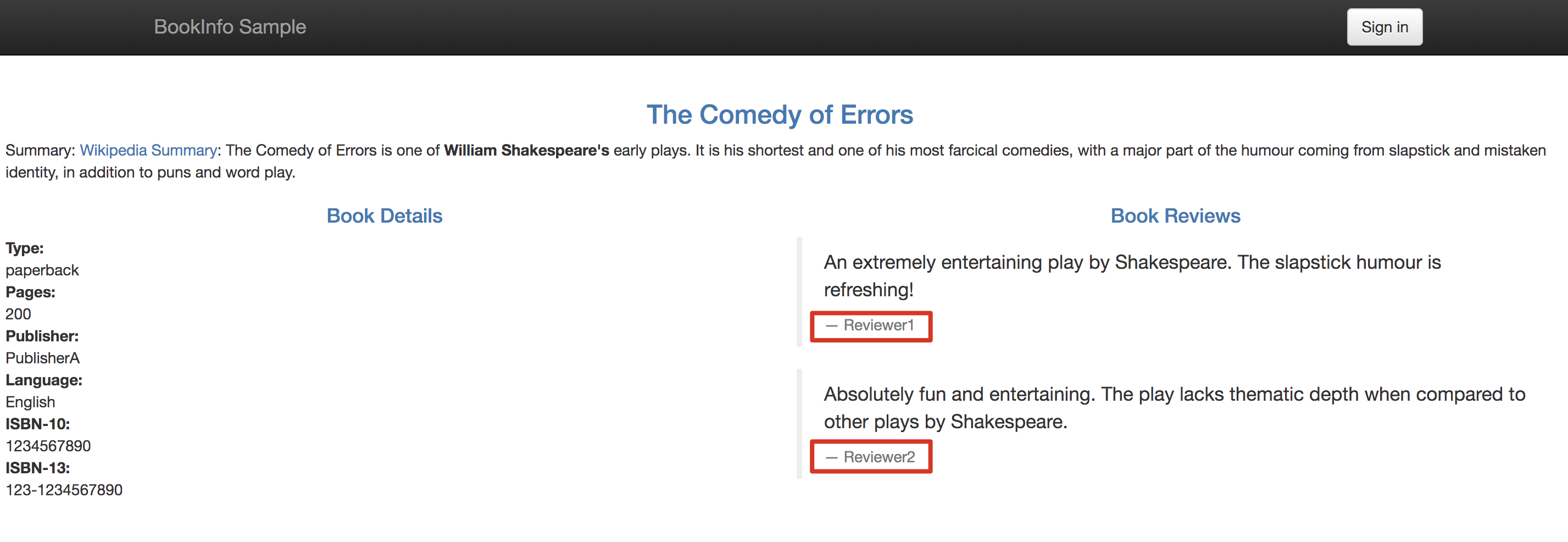
1.4. Notice that at this point it only shows **- Reviewer1** and **- Reviewer2** without any stars at the Book Reviews section, this is the initial status of this section.
|
||||
|
||||
|
||||
|
||||
### Step 2: Create Canary Release for reviews service
|
||||
|
||||
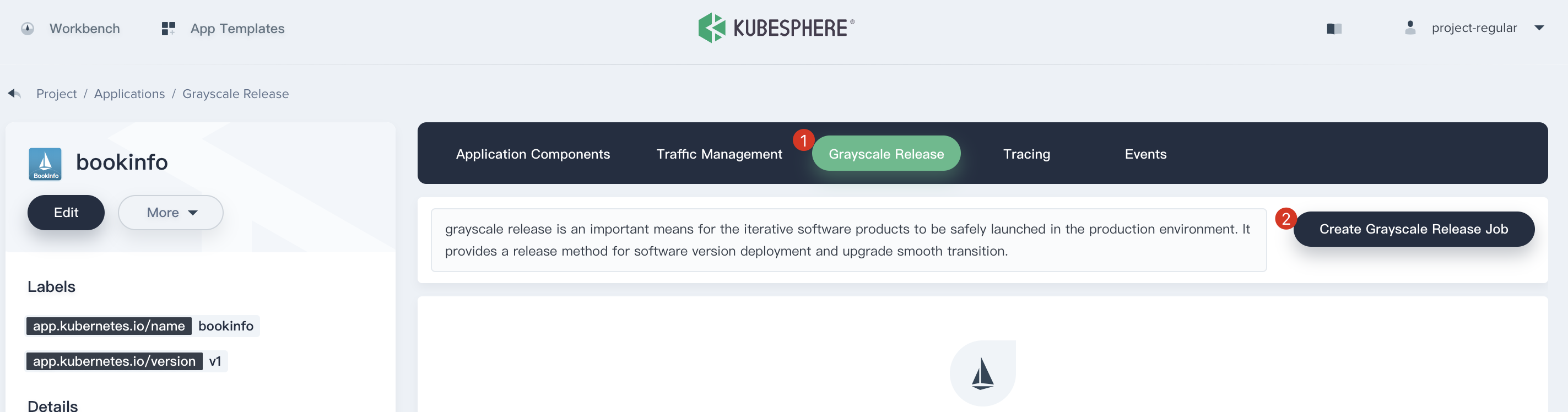
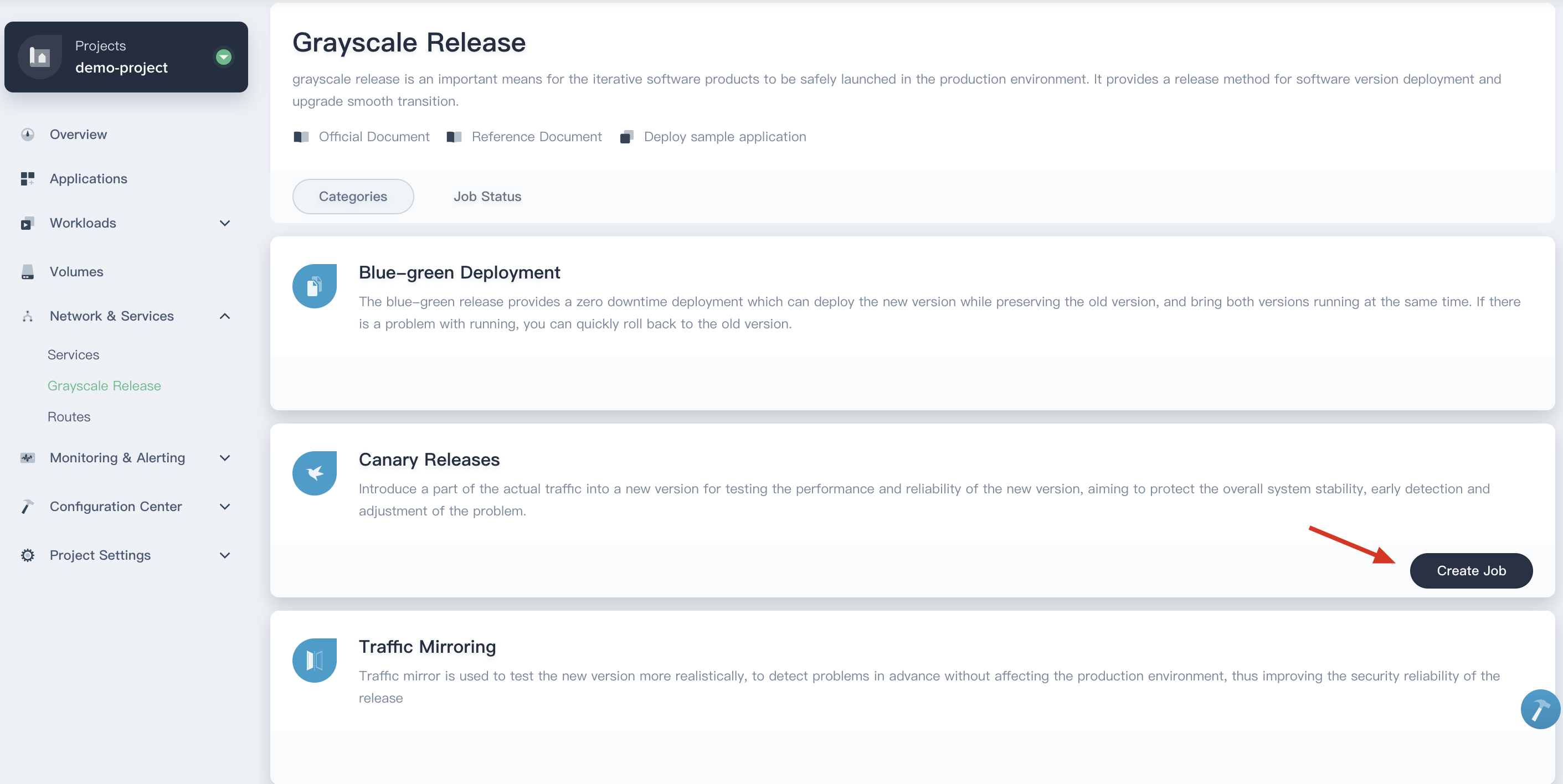
2.1. Back to KubeSphere console, choose **Grayscale Release** and click on the **Create Canary Release Job**, then select **Canary Release** and click **Create Job**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
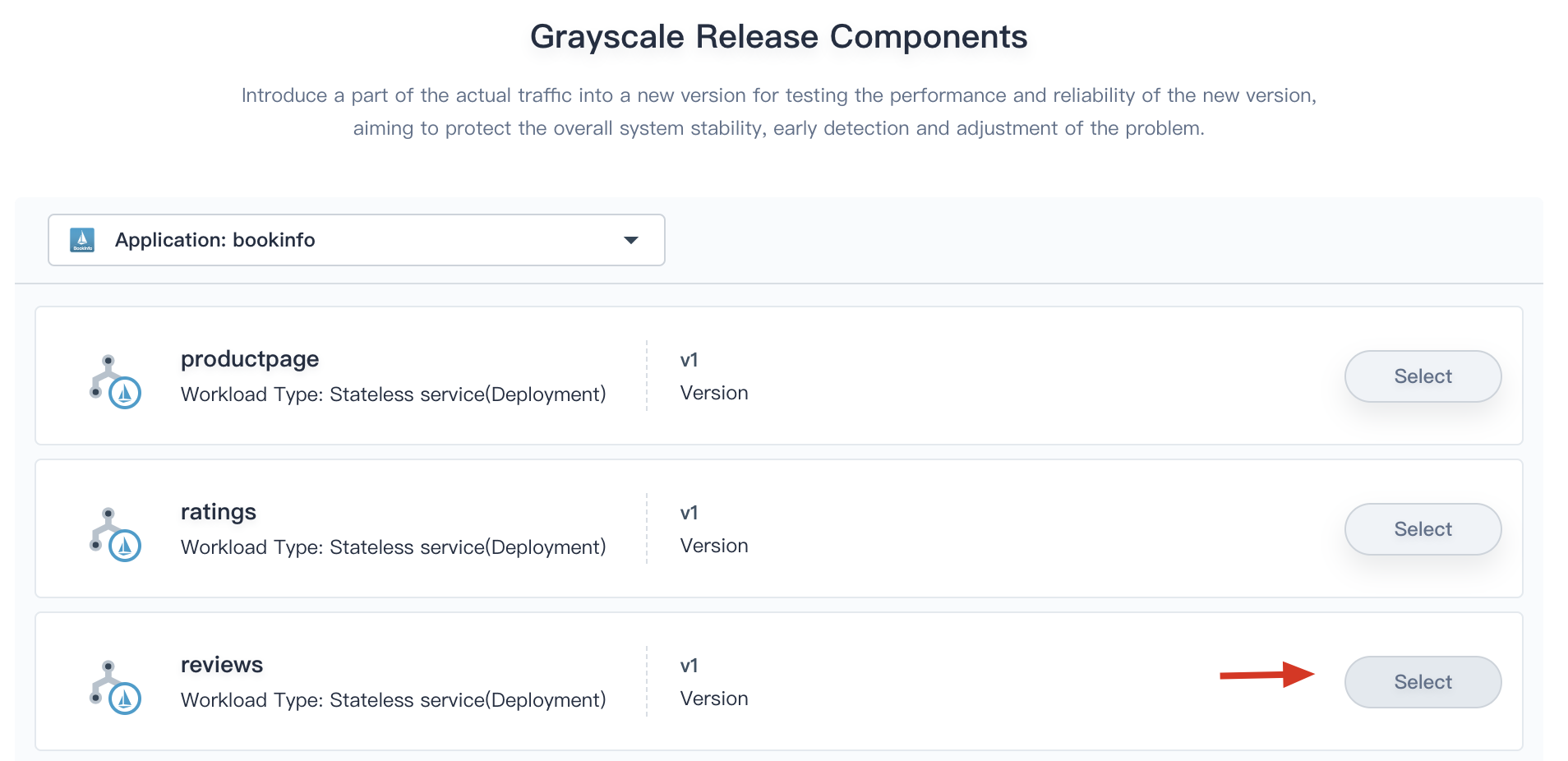
2.2. Fill in the basic information, e.g. `canary-release`, click **Next** and select **reviews** as the canary service, then click **Next**.
|
||||
|
||||
|
||||
|
||||
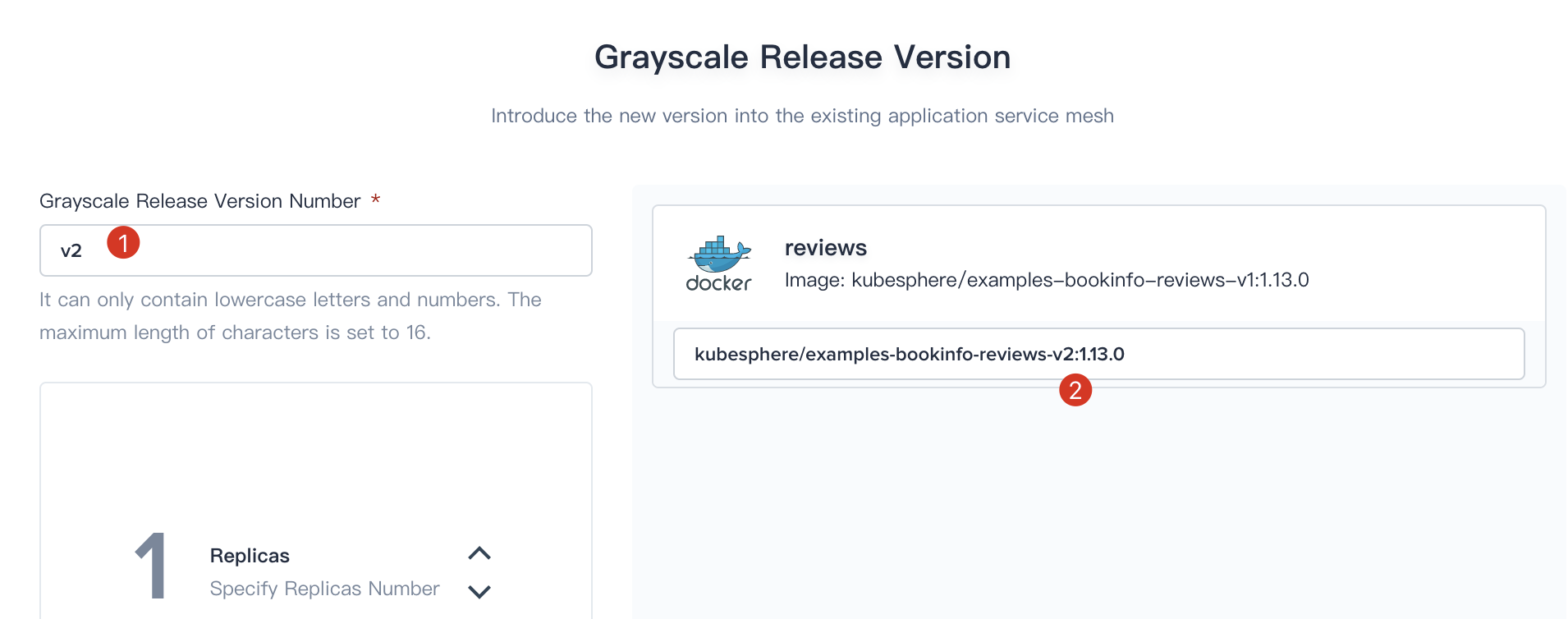
2.3. Enter `v2` as **Grayscale Release Version Number** and fill in the new image blank with `kubesphere/examples-bookinfo-reviews-v2:1.13.0` (i.e. Modify v1 to v2), then click **Next**.
|
||||
|
||||
|
||||
|
||||
2.4. The canary release supports **Forward by traffic ratio** and **Forward by request content**, in this tutorial we choose adjust the traffic ratio to manage traffic distribution between v1 and v2. Drag the slider to adjust v2 takes up 30% traffic, and v2 takes up 70%.
|
||||
|
||||

|
||||
|
||||
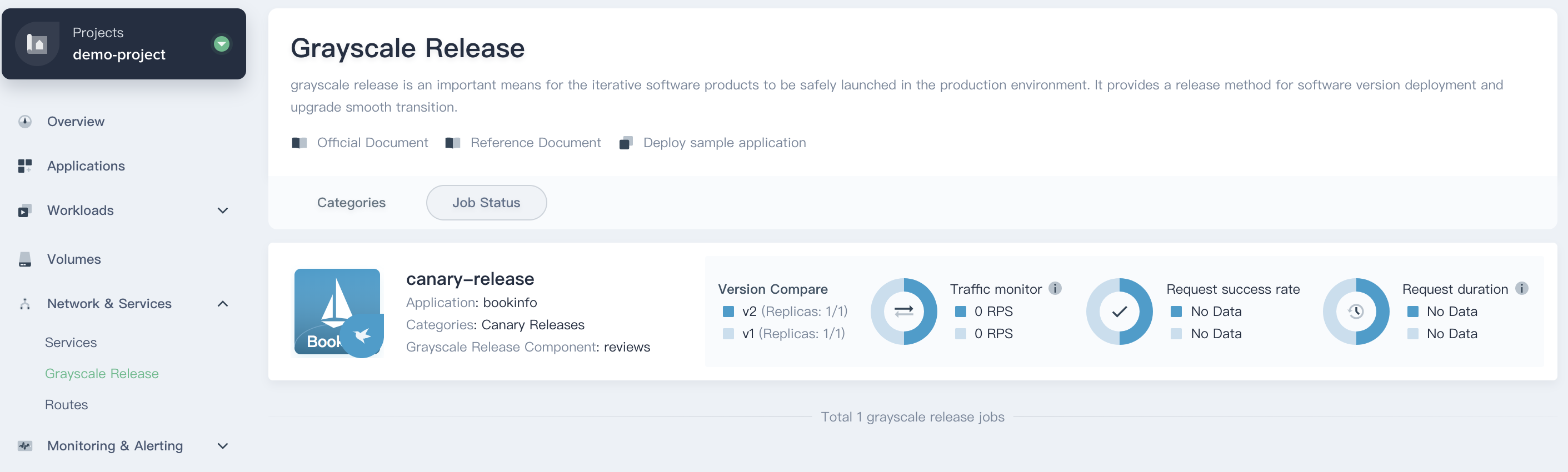
2.5. Click **Create** when you've completed configuration, then you're able to see the `canary-release` has been created successfully.
|
||||
|
||||
|
||||
|
||||
### Step 3: Verify the Canary Release
|
||||
|
||||
When you visit the Bookinfo website again and refresh your browser repeatedly, you'll be able to see that the Bookinfo reviews section will switch between v1 and v2 at a random rate of about 30% and 70% respectively.
|
||||
|
||||
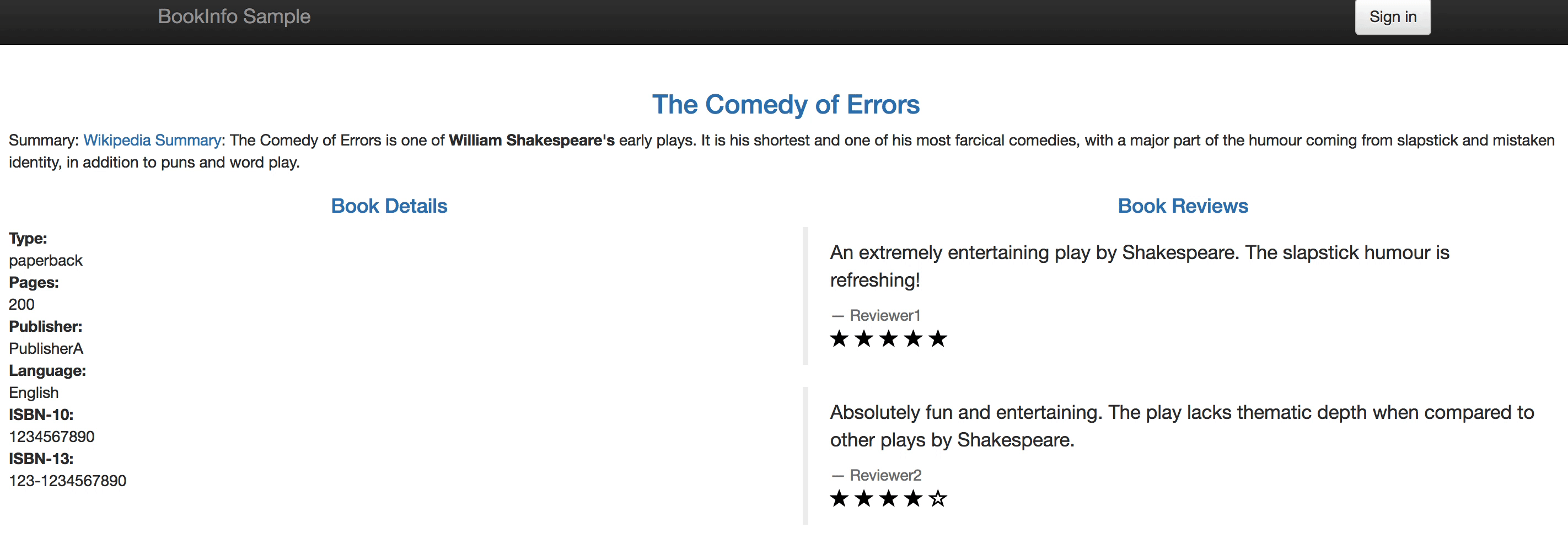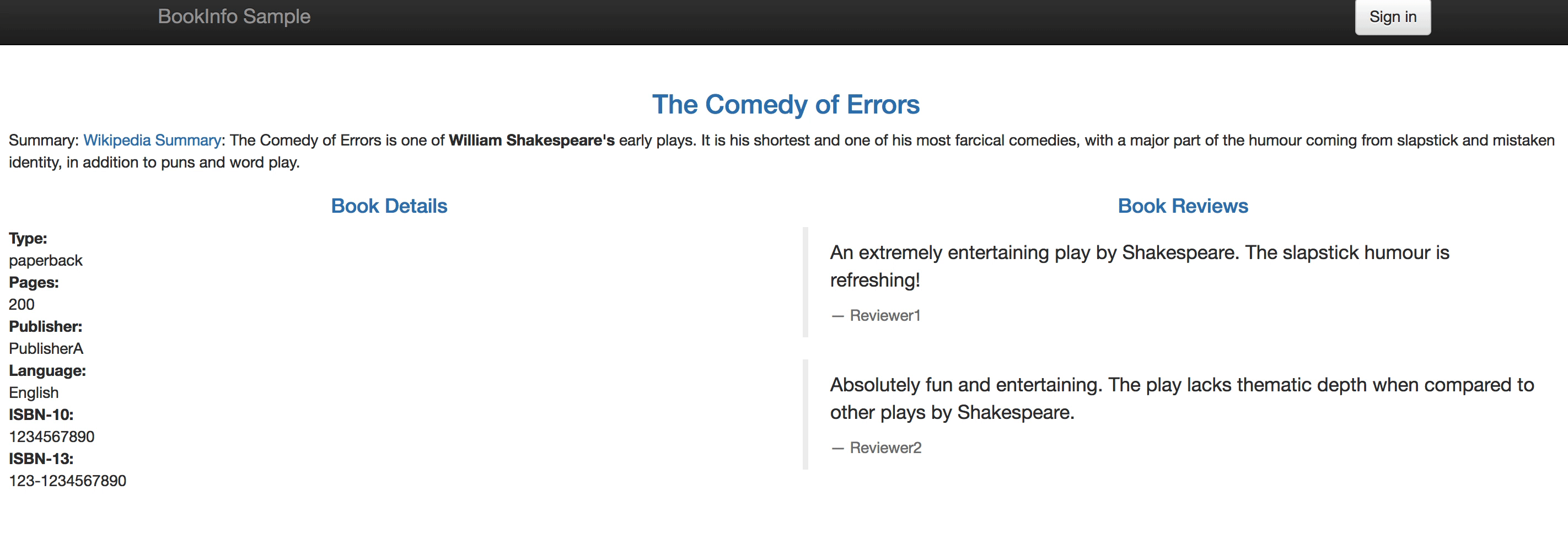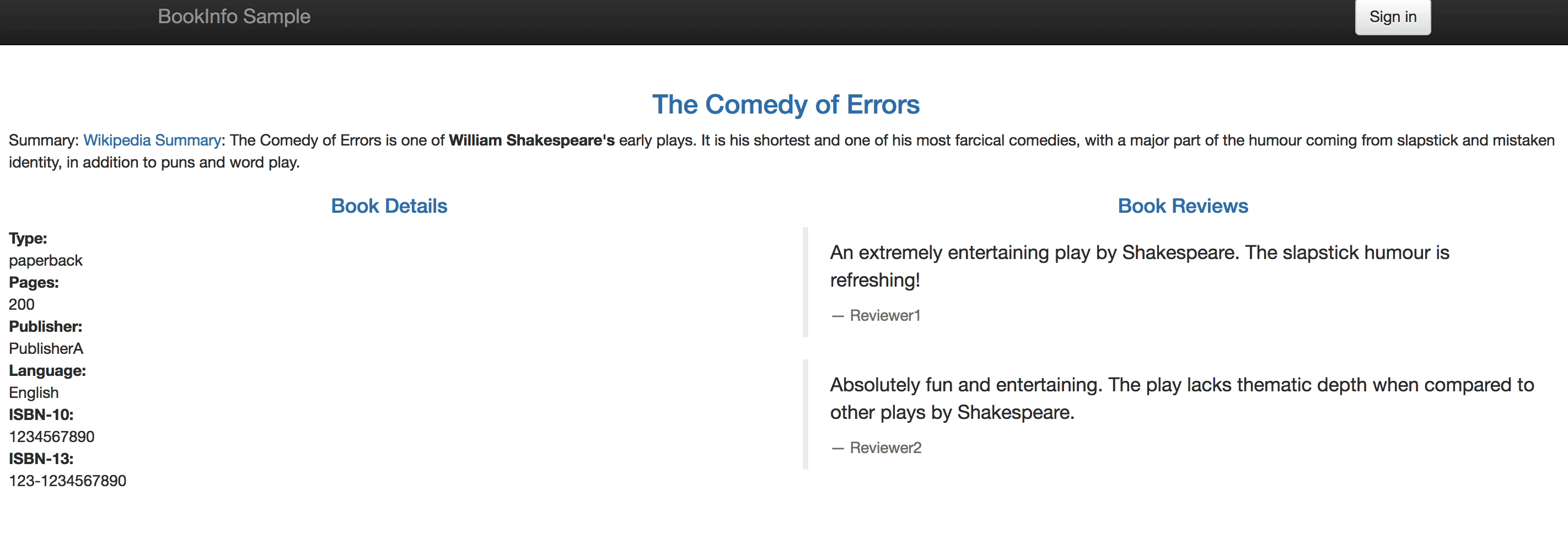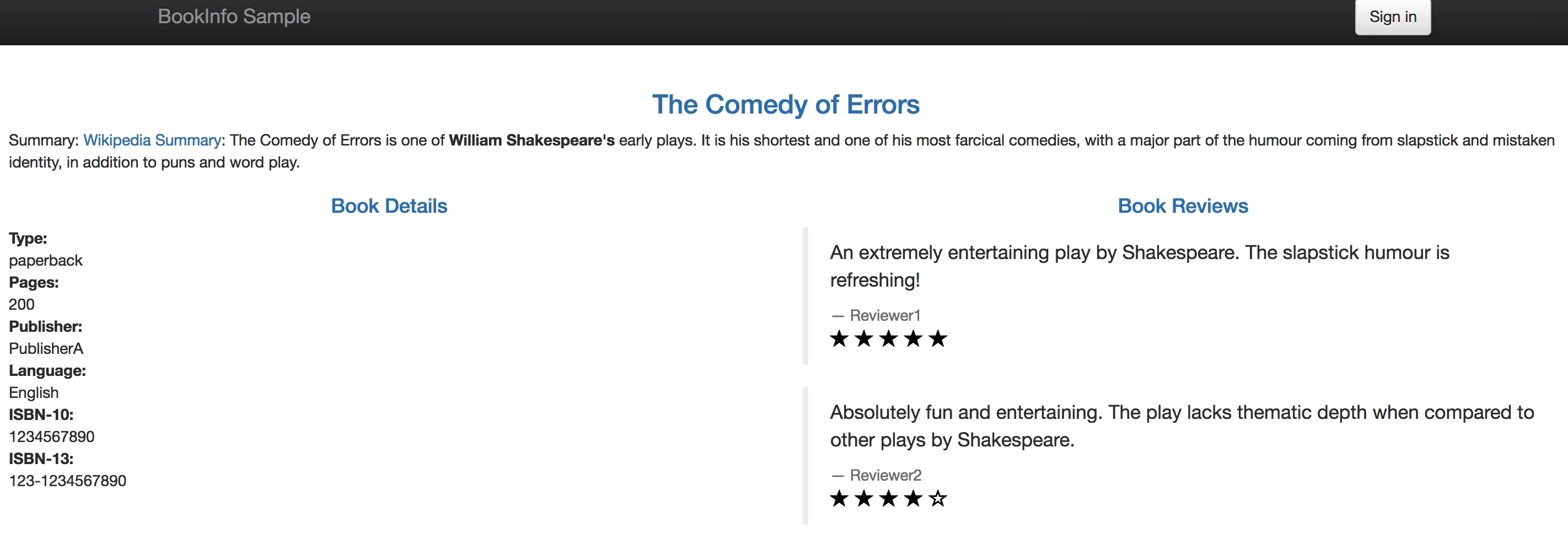
|
||||
|
||||
### Step 4: Inspect the Traffic Topology Graph
|
||||
|
||||
4.1. Connect to your SSH Client, use the following command to introduce real traffic to simulate the access to a bookinfo application every 0.5 seconds.
|
||||
|
||||
```
|
||||
$ curl http://productpage.demo-project.192.168.0.88.nip.io:32565/productpage?u=normal
|
||||
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0< 74 5183 74 3842 0 0 73957 0 --:--:-- --:--:-- --:--:-- 73884<!DOCTYPE html>
|
||||
···
|
||||
```
|
||||
|
||||
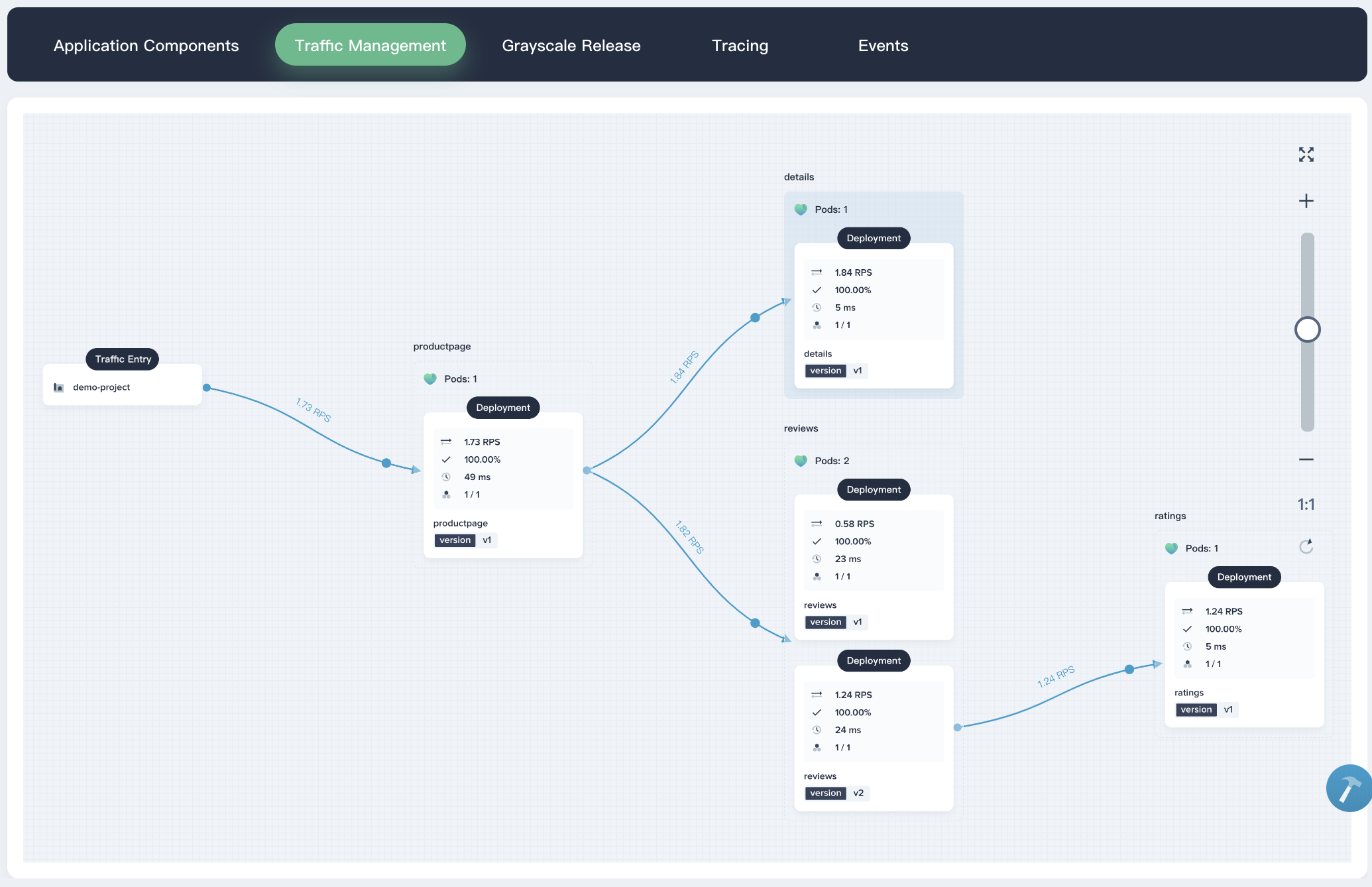
4.2. From the traffic management diagram, you can easily see the service invocation and dependencies, health, performance between different microservices.
|
||||
|
||||
|
||||
|
||||
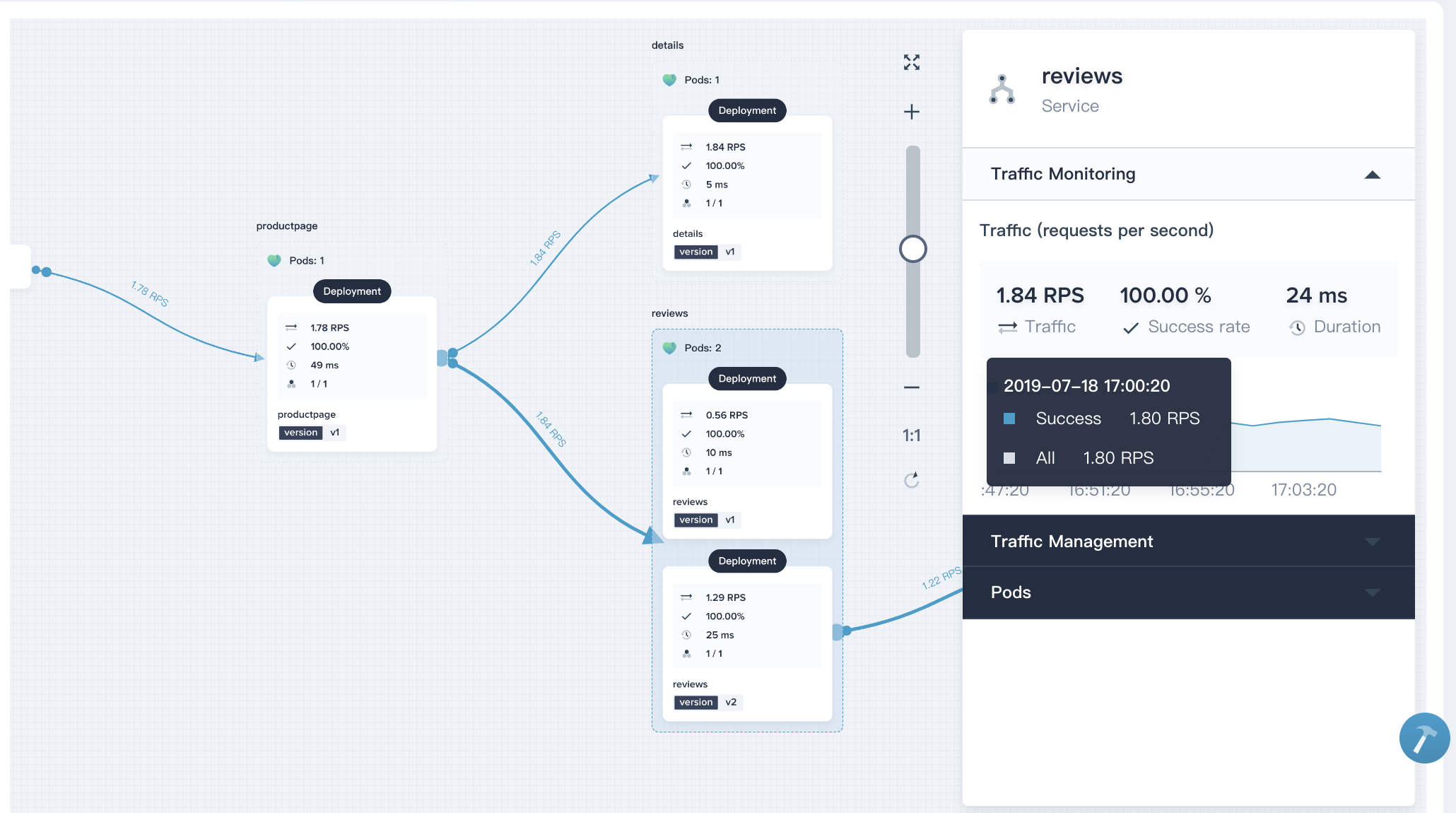
4.3. Click on the reviews card, the traffic monitoring graph will come out, including real-time data of **Success rate**, **Traffic** and **Duration**.
|
||||
|
||||
|
||||
|
||||
### Step 5: Inspect the Tracing Details
|
||||
|
||||
KubeSphere provides distributed tracing feature based on [Jaeger](https://www.jaegertracing.io/), which is used for monitoring and troubleshooting microservices-based distributed application.
|
||||
|
||||
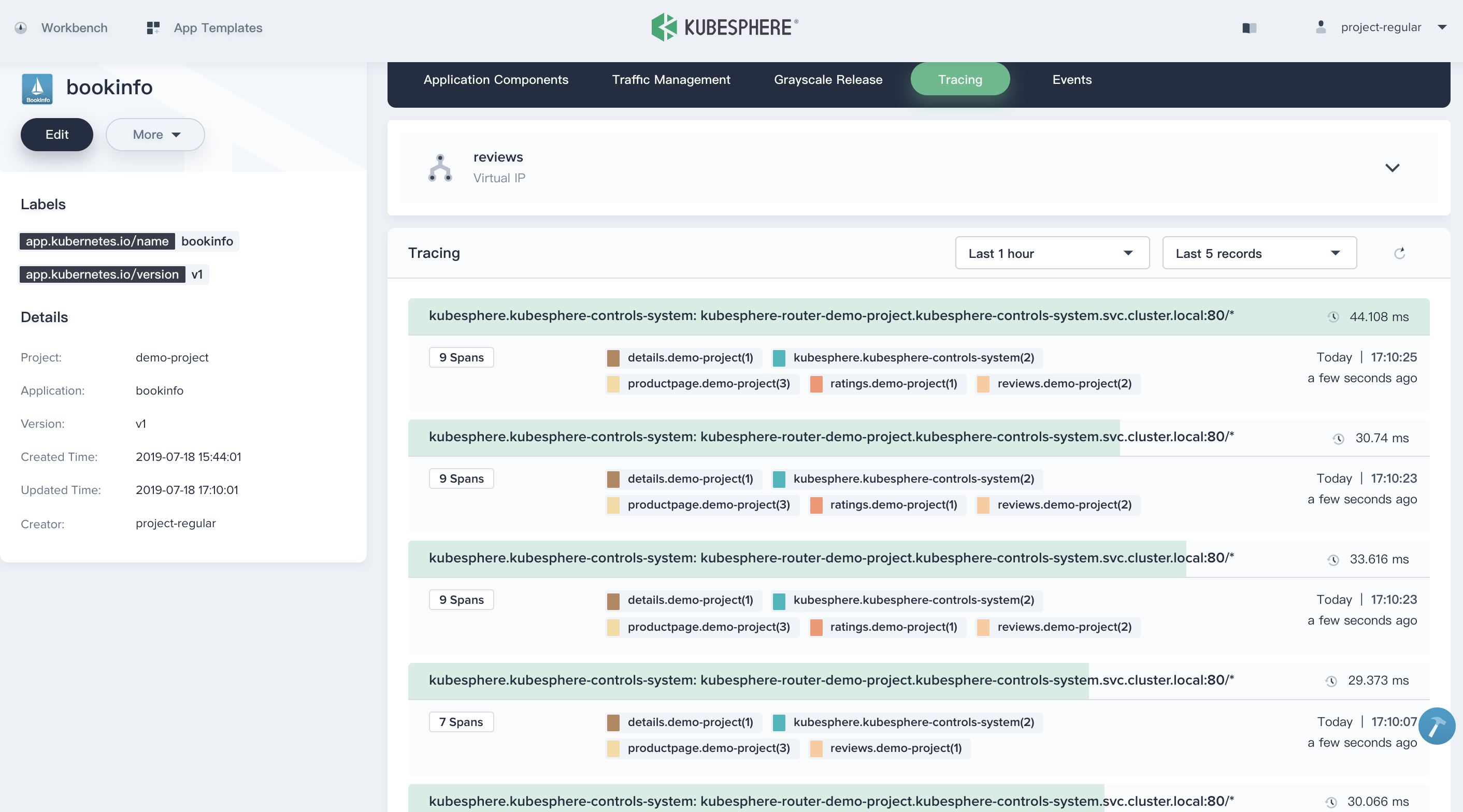
5.1. Choose **Tracing** tab, you can clearly see all phases and internal calls of a request, as well as the period in each phase.
|
||||
|
||||
|
||||
|
||||
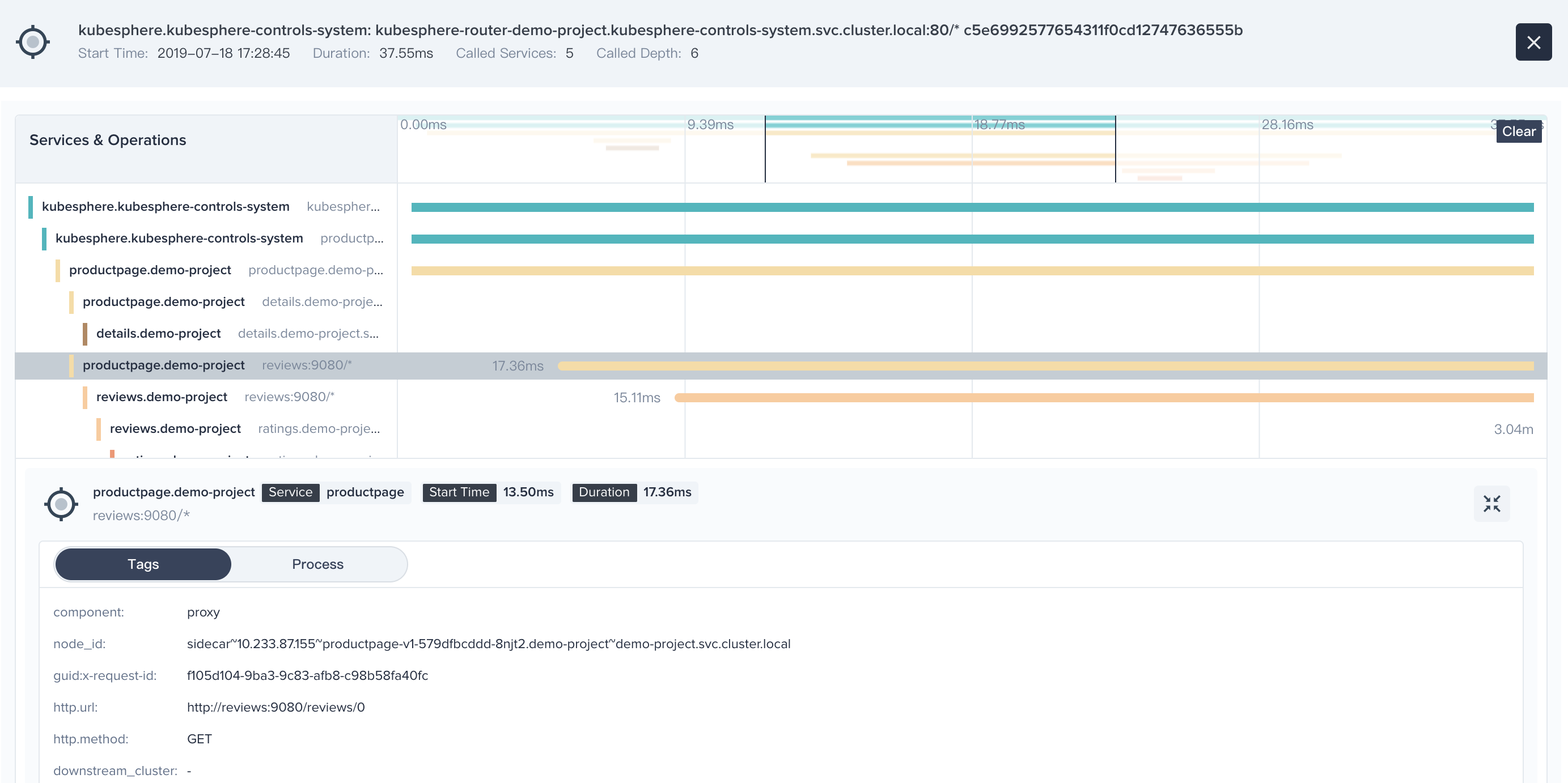
5.2. Click into any one item, you can even drill down to see the request details and this request is being processed by which machine (or container).
|
||||
|
||||
|
||||
|
||||
### Step 6: Take over all traffic
|
||||
|
||||
6.1. As mentioned previously, when the canary version (v2) is released, it could be used to send 70% of traffic to the canary version. Publishers can test the new version online and collect user feedback.
|
||||
|
||||
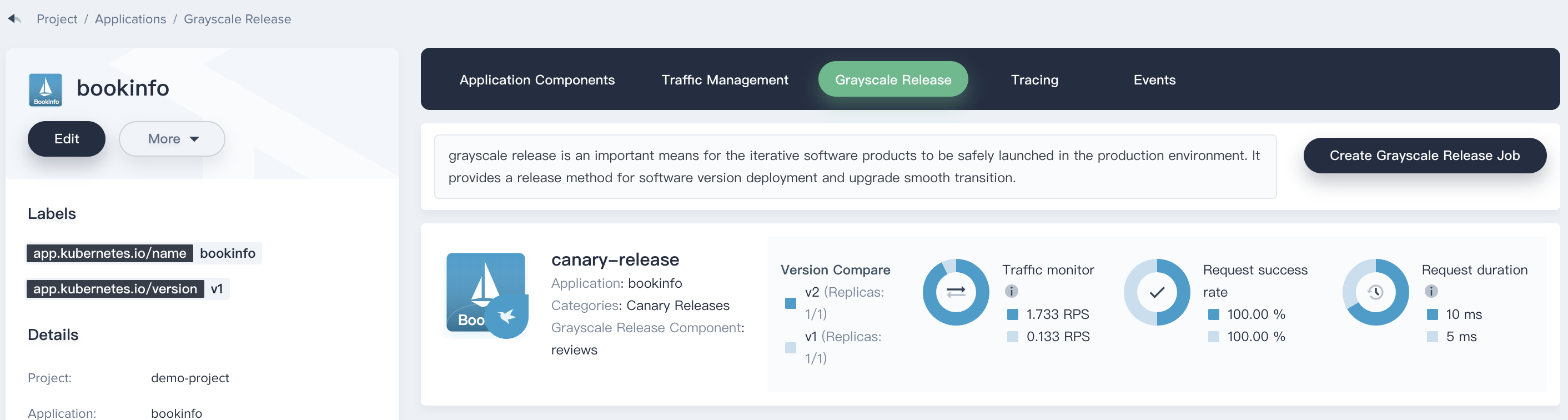
Switch to **Grayscale Release** tab, click into `canary-release`.
|
||||
|
||||
|
||||
|
||||
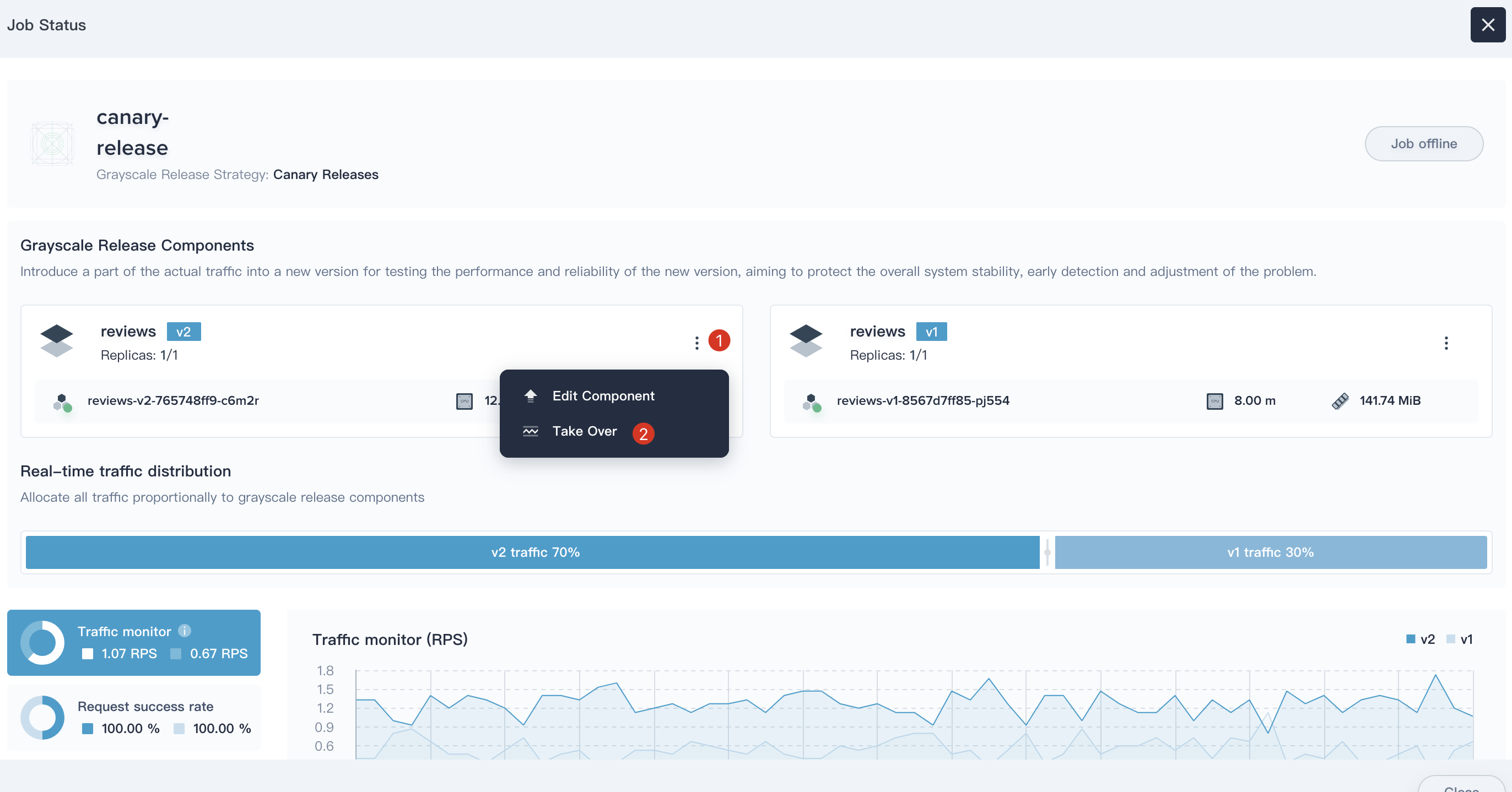
6.2. Click **···** and select **Take Over** at `reviews-v2`, then 100% of traffic will be sent to the new version (v2).
|
||||
|
||||
> Note: If anything goes wrong along the way, we can abort and rollback to the previous version (v1) in time.
|
||||
|
||||
|
||||
|
||||
6.3. Open the bookinfo page again and refresh the browsers several times, we can find that it only shows the v2 (ratings with black stars) in reviews module.
|
||||
|
||||

|
||||
|
||||
### Step 7: Take Down the Old Version
|
||||
|
||||
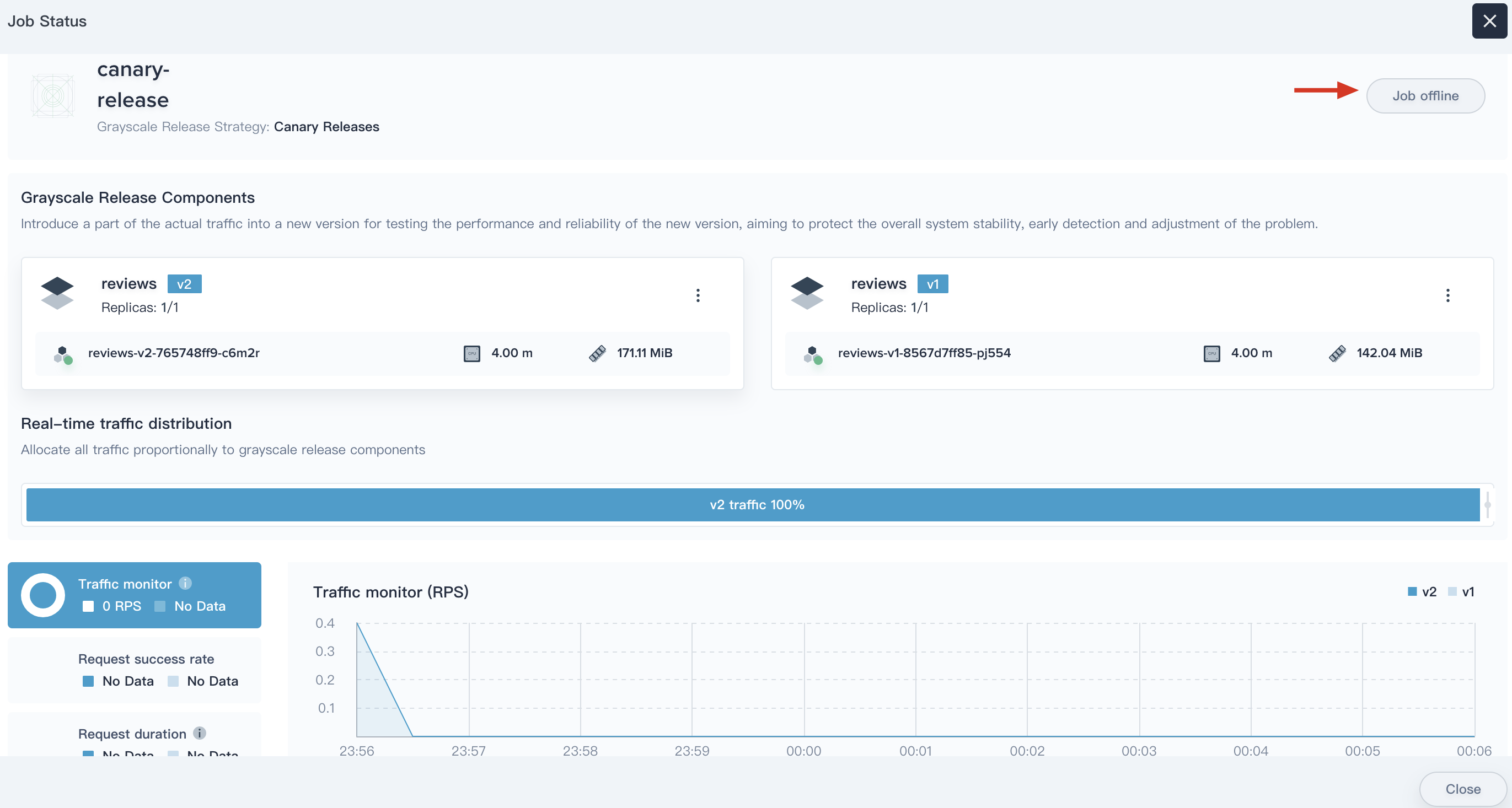
When the new version v2 jas been totally released online and takes over all the traffic, also the testing results and online users feedback are confirmed to be correct, you can take down the old version and remove the resources of v1.
|
||||
|
||||
Click on the **Job Offline** button to take down the old version,
|
||||
|
||||
|
||||
|
||||
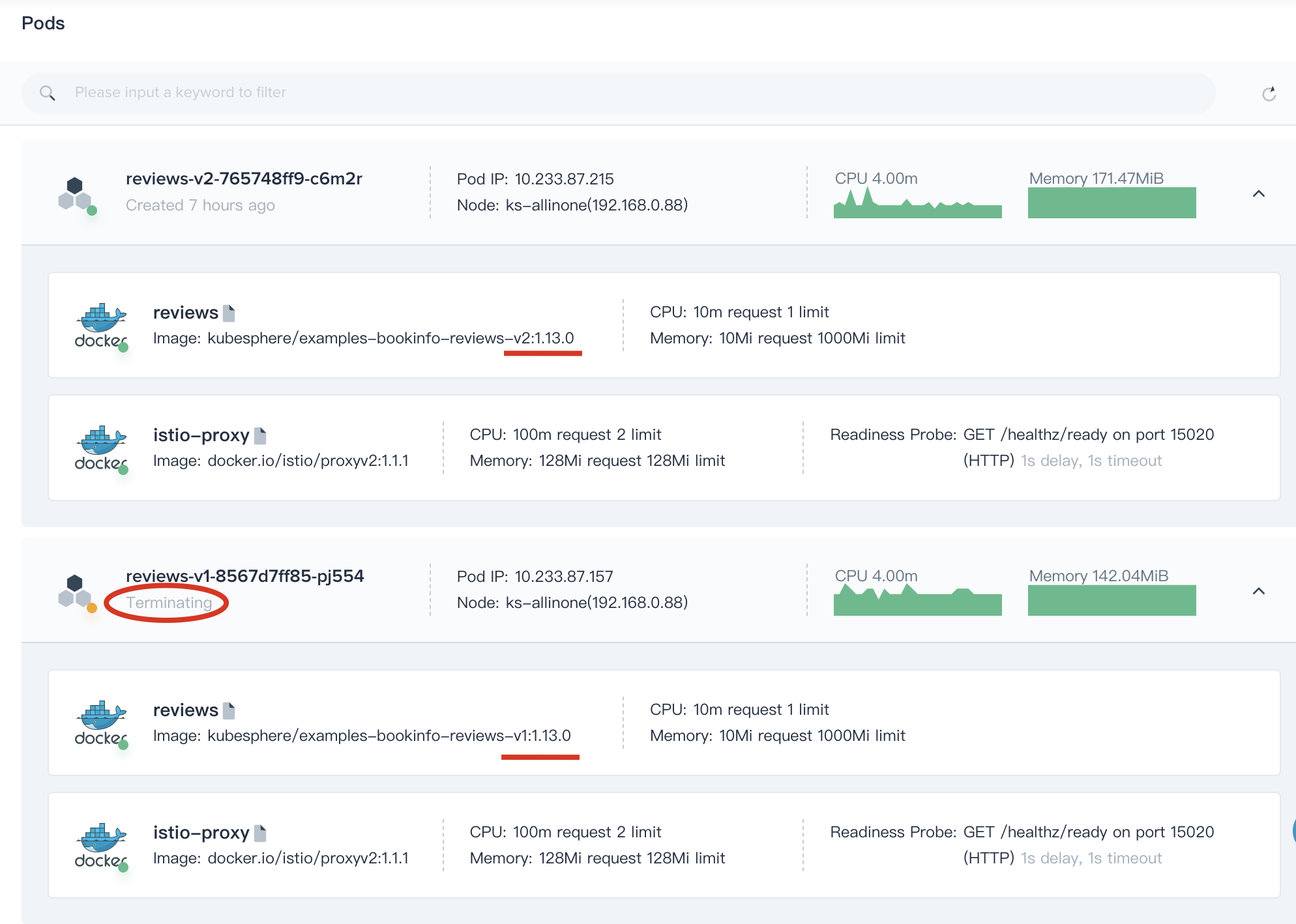
> Notice: If take down a specific version of the component, the associated workloads and istio related configuration resources will be removed simultaneously, it turns out that v1 is being replaced by v2.
|
||||
|
||||
|
||||
|
|
@ -1,37 +0,0 @@
|
|||
---
|
||||
title: 'Creating a CI/CD Pipeline to Deploy Spring Boot App to Kubernetes'
|
||||
|
||||
author: 'xxx'
|
||||
---
|
||||
|
||||
## Objective
|
||||
|
||||
This tutorial shows you how to create a CI/CD Pipeline within DevOps project, which is intended for deploying a Spring Boot sample application to Kubernetes.
|
||||
|
||||
## Overview
|
||||
|
||||
Based on the existing Jenkinsfile in the sample GitHub repository, we can create a pipeline to build and complete the stages and steps (e.g. unit test, sonarqube analysis), which totally consists of eight stages as shown below.
|
||||
|
||||
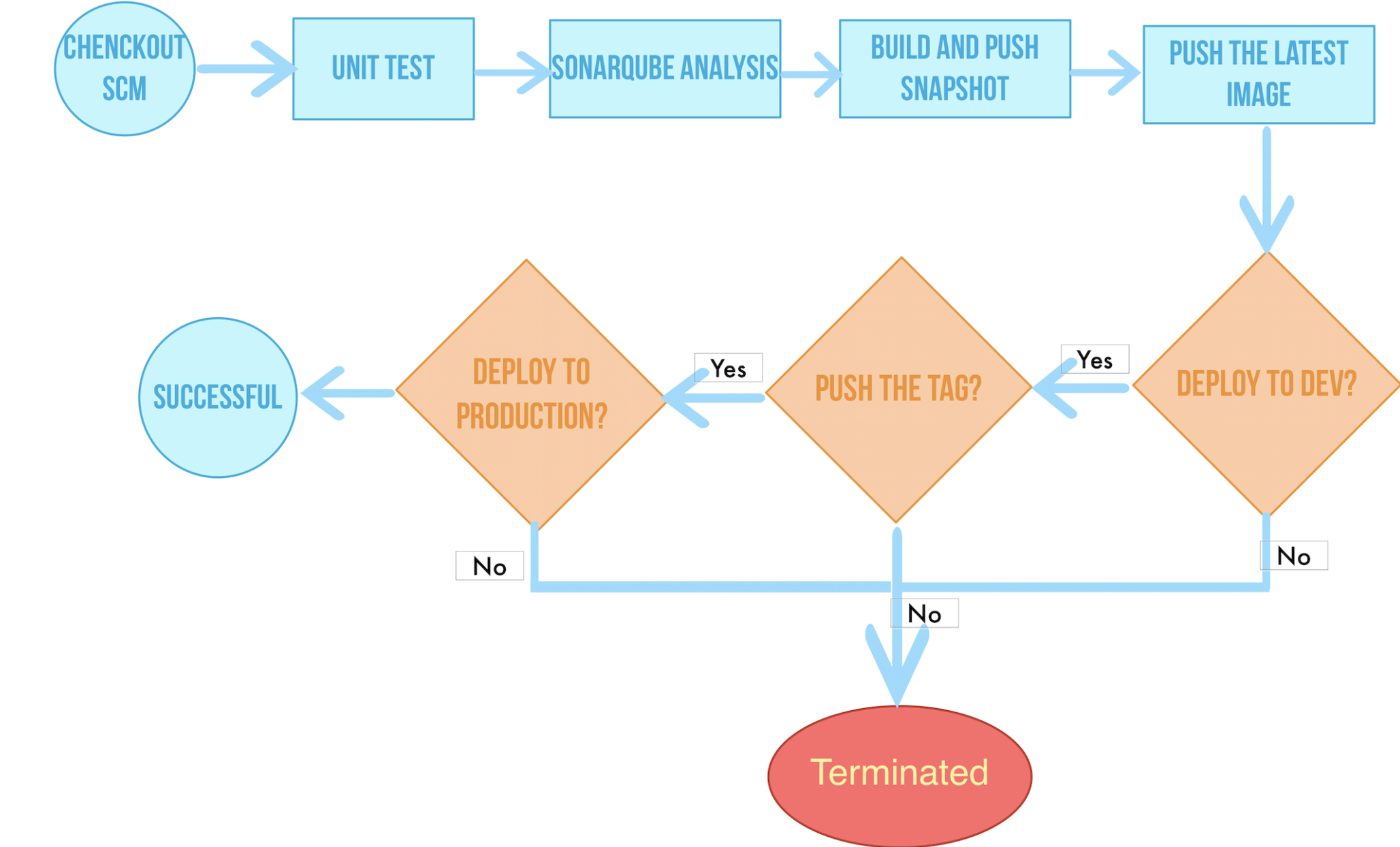
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You've completed all steps in [Tutorial 1](admin-quick-start.md).
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create Credentials
|
||||
|
||||
To get started, we need to create 3 credentials, i.e. DockerHub、GitHub and kubeconfig.
|
||||
|
||||
1.1. Sign in with `project-regular` account and enter into the `demo-devops`, navigate to **Credentials**, then click on the **Create Credentials**.
|
||||
|
||||
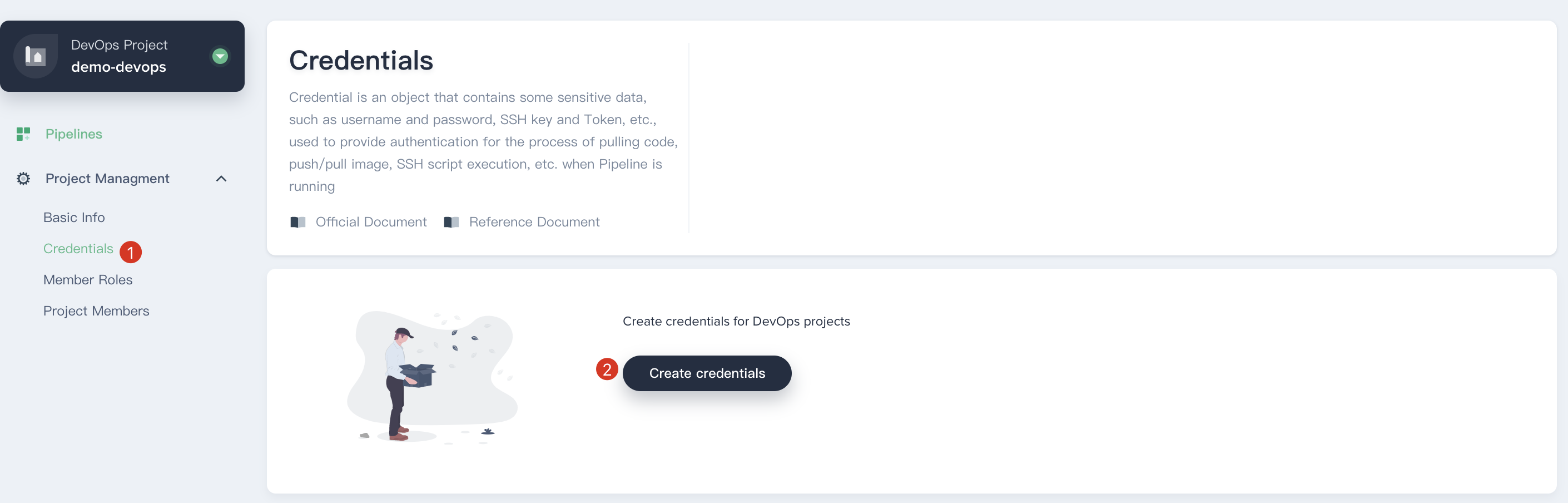
|
||||
|
||||
| Credential ID | Type | Username/Password/Secret | Content |
|
||||
| --------------- | ------------------- | -------------------------------------------------------------------- | ------- |
|
||||
| dockerhub-id | Account Credentials | Enter your personal DockerHub account information | \| |
|
||||
| github-id | Account Credentials | Enter your personal GitHub account information | \| |
|
||||
| kube-config |
|
||||
| demo-kubeconfig | kubeconfig | \|It will be automatically filled with the kubeconfig of the cluster |
|
||||
| sonar-token | secret_text | You can get secret by creating SonarQube token | \ |
|
||||
|
|
@ -1,161 +0,0 @@
|
|||
---
|
||||
title: 'Creating Horizontal Pod Autoscaler for Deployment'
|
||||
|
||||
author: 'xxx'
|
||||
---
|
||||
|
||||
The Horizontal Pod Autoscaler automatically scales the number of pods in a deployment based on observed CPU utilization or Memory usage. The controller periodically adjusts the number of replicas in a deployment to match the observed average CPU utilization to the target value specified by user.
|
||||
|
||||
## How does the HPA work
|
||||
|
||||
The Horizontal Pod Autoscaler is implemented as a control loop, with a period controlled by the controller manager’s HPA sync-period flag (with a default value of 15 seconds). For per-pod resource metrics (like CPU), the controller fetches the metrics from the resource metrics API for each pod targeted by the Horizontal Pod Autoscaler. See [Horizontal Pod Autoscaler](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) for more details.
|
||||
|
||||
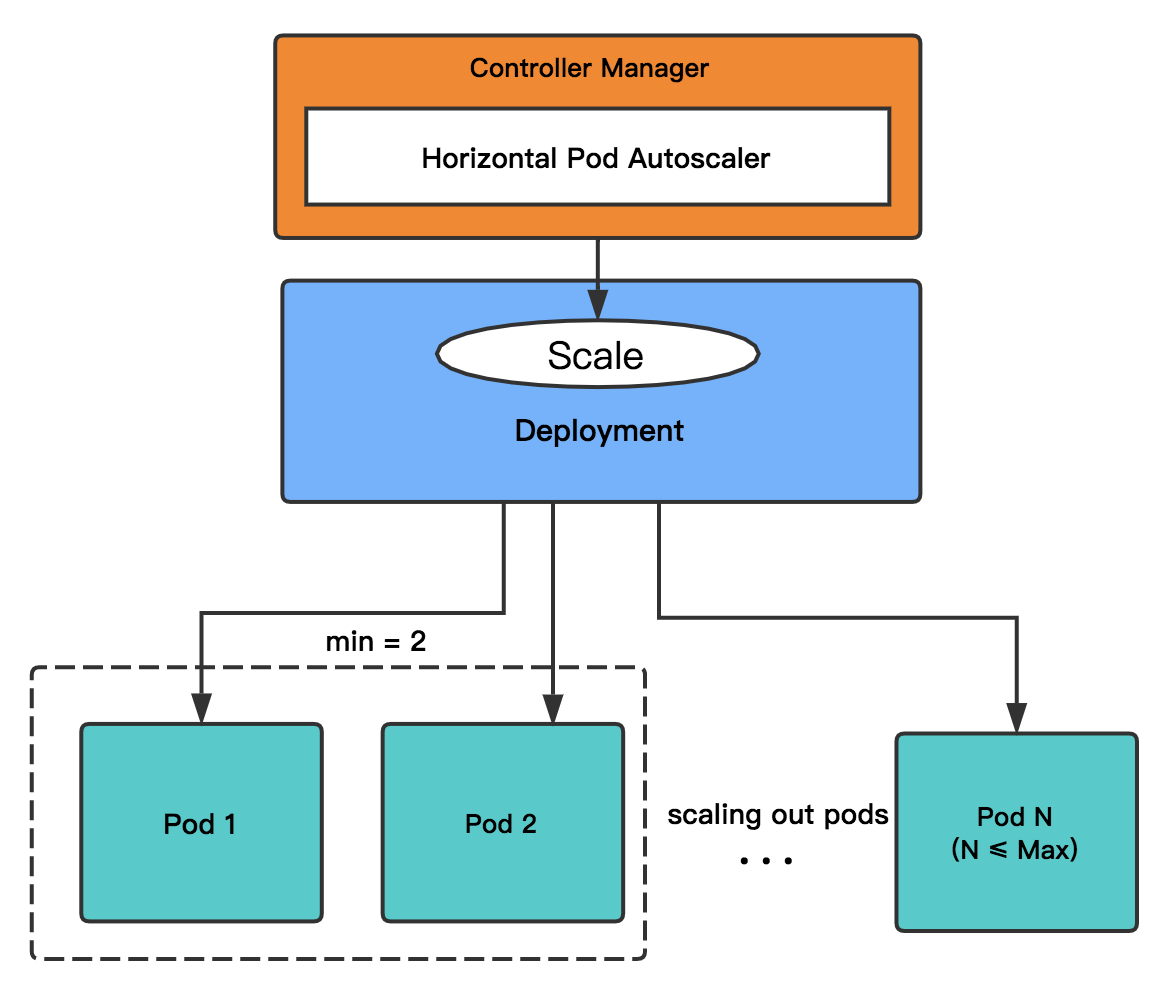
|
||||
|
||||
## Objective
|
||||
|
||||
This document walks you through an example of configuring Horizontal Pod Autoscaler for the hpa-example deployment.
|
||||
|
||||
We will create a deployment to send an infinite loop of queries to the hpa example application, demonstrating its autoscaling function and the HPA Principle.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- You need to create a workspace and project, see the [Tutorial 1](admin-quick-start.md) if not yet.
|
||||
- You need to sign in with `project-regular` and enter into the corresponding project.
|
||||
|
||||
## Hands-on Lab
|
||||
|
||||
### Step 1: Create a Deployment
|
||||
|
||||
1.1. Enter into `demo-project`, then select **Workload → Deployments** and click **Create Deployment** button.
|
||||
|
||||
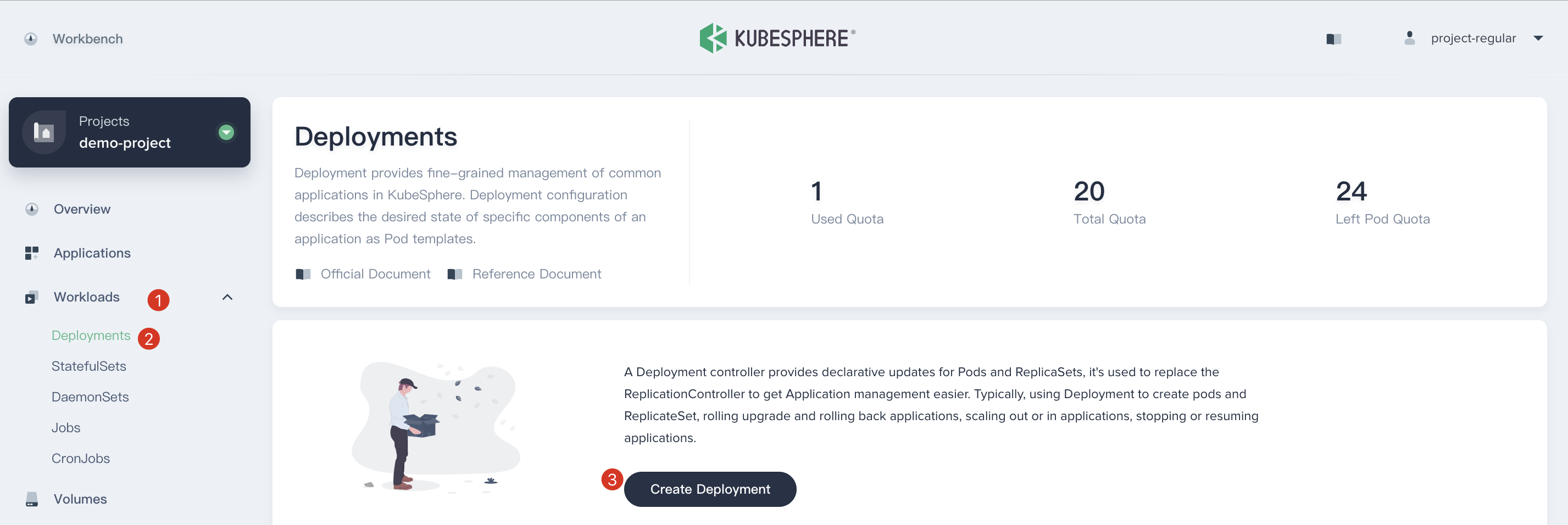
|
||||
|
||||
1.2. Fill in the basic information in the pop-up window. e.g. `Name: hpa-example`, then click **Next** when you've done.
|
||||
|
||||
### Step 2: Configure the HPA
|
||||
|
||||
2.1. Choose **Horizontal Pod Autoscaling**, and fill in the table as following:
|
||||
|
||||
- Min Replicas Number: 2
|
||||
- Max Replicas Number: 10
|
||||
- CPU Request Target(%): 50 (represents the percent of target CPU utilization)
|
||||
|
||||
Then click on the **Add Container** button.
|
||||
|
||||
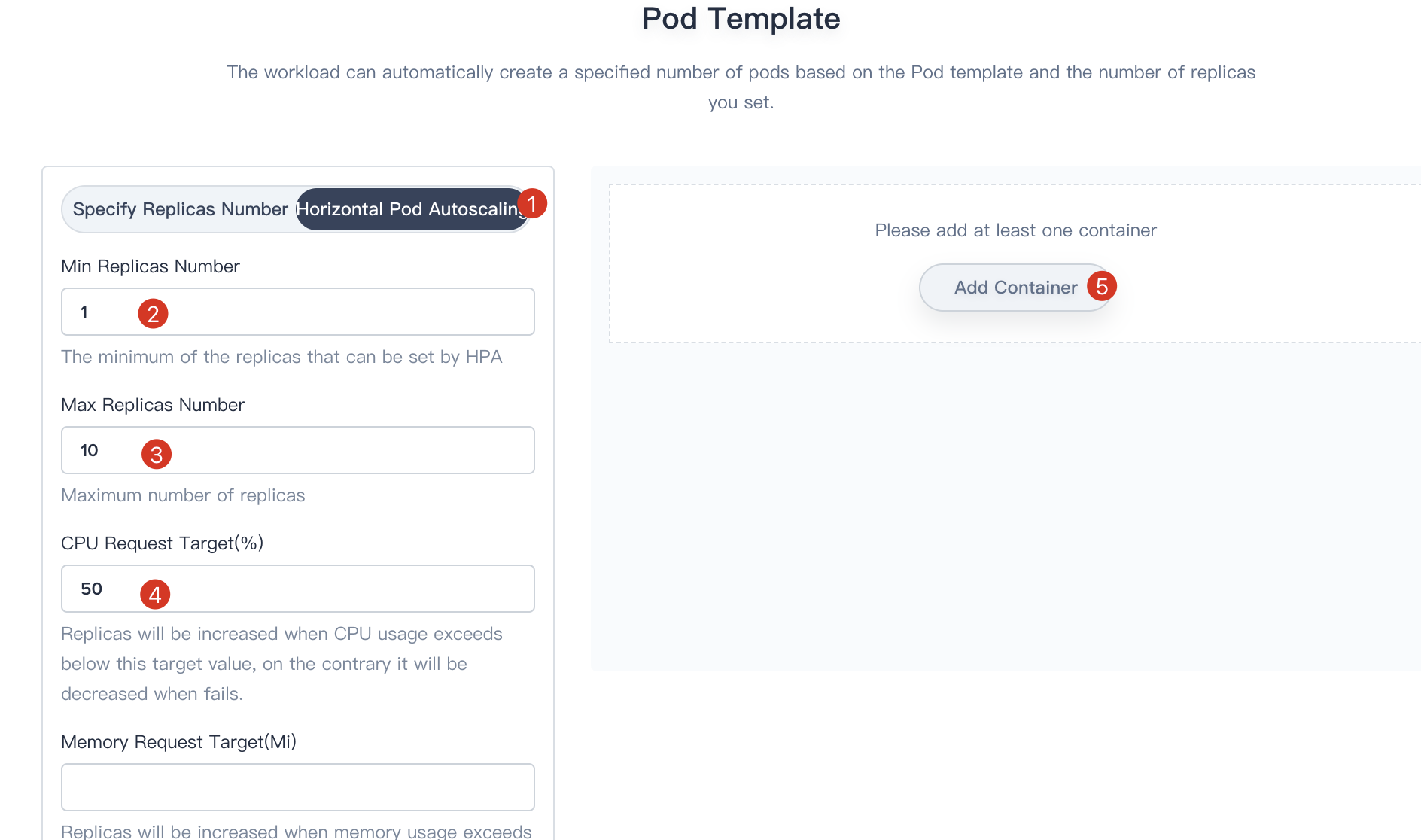
|
||||
|
||||
2.2. Fill in the Pod Template with following values, then click **Save** to save these settings.
|
||||
|
||||
- Image: `mirrorgooglecontainers/hpa-example`
|
||||
- Service Settings
|
||||
- Name: port
|
||||
- port: 80 (TCP protocol by default)
|
||||
|
||||
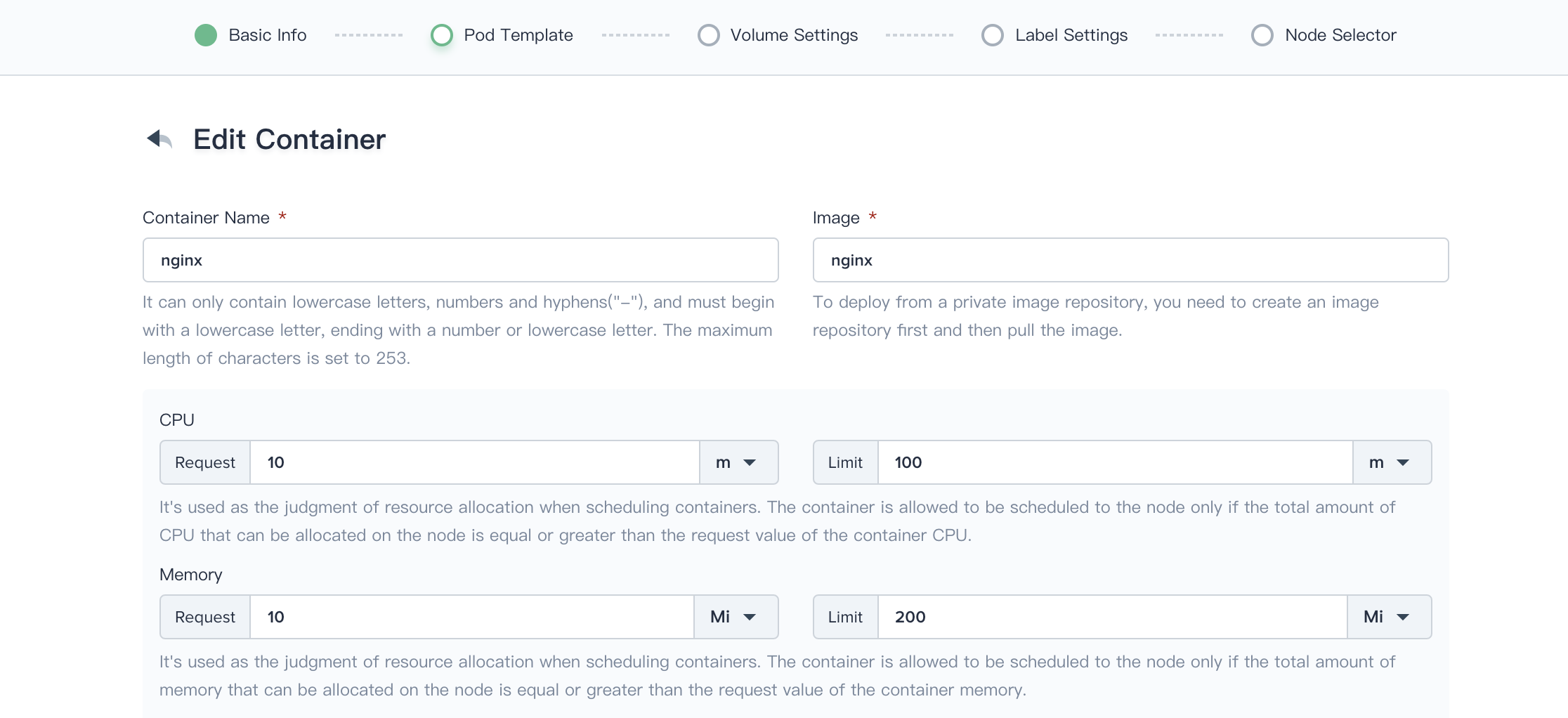
|
||||
|
||||
2.3. Skip the Volume and Label Settings, click the **Create** button directly. Now the hpa-example deployment has been created successfully.
|
||||
|
||||
|
||||
|
||||
### Step 3: Create a Service
|
||||
|
||||
3.1. Choose **Network & Services → Services** on the left menu, then click on the **Create Service** button.
|
||||
|
||||
|
||||
|
||||
3.2. Fill in the basic information, e.g. `name : hpa-example`, then click **Next**.
|
||||
|
||||
3.3. Choose the first item `Virtual IP: Access the service through the internal IP of the cluster` for the service Settings.
|
||||
|
||||
3.4. In Selector blanks, click **Specify Workload** and select the `hpa-example` as the backend workload. Then choose **Save** and fill in the Ports blanks.
|
||||
|
||||
- Ports:
|
||||
- Name: port
|
||||
- Protocol: TCP
|
||||
- Port: 80
|
||||
- Target port: 80
|
||||
|
||||
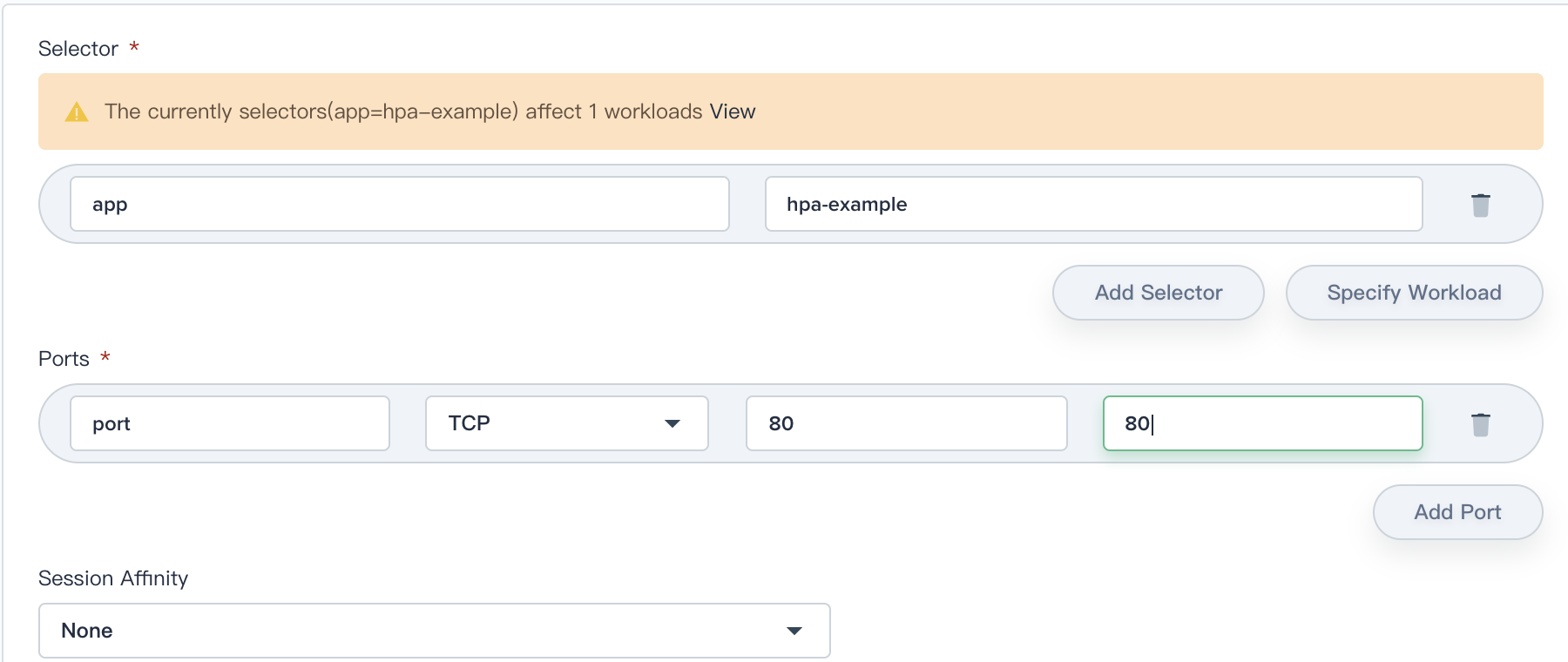
|
||||
|
||||
Click **Next → Create** to complete the creation. Now the hpa-example service has been created successfully.
|
||||
|
||||
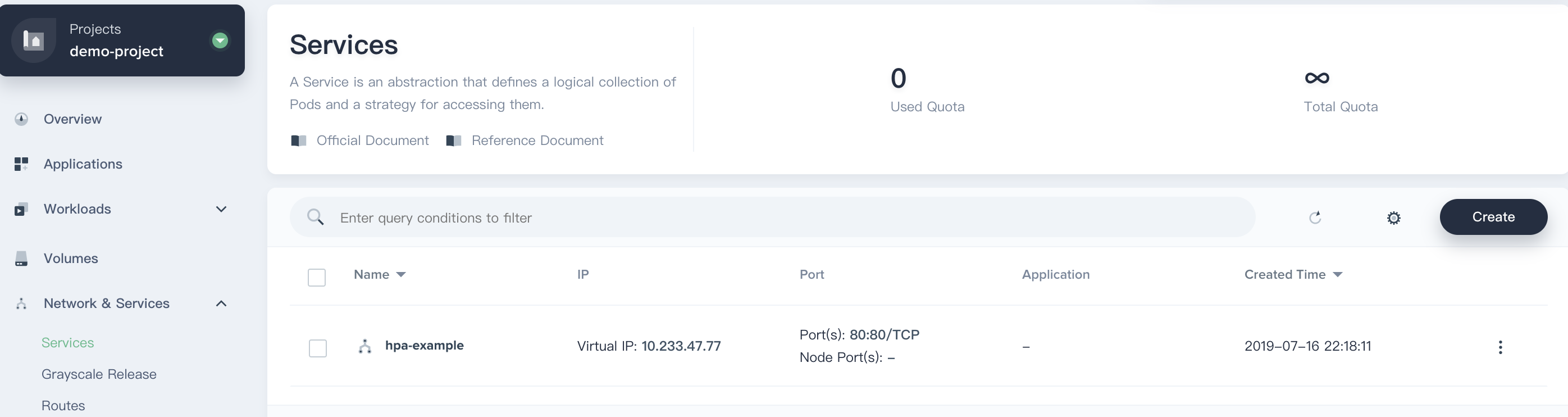
|
||||
|
||||
### Step 4: Create Load-generator
|
||||
|
||||
4.1. In the current project, redirect to **Workload → Deployments**. Click **Create** button and fill in the basic information in the pop-up window, e.g. `Name : load-generator`. Click **Next** when you've done.
|
||||
|
||||
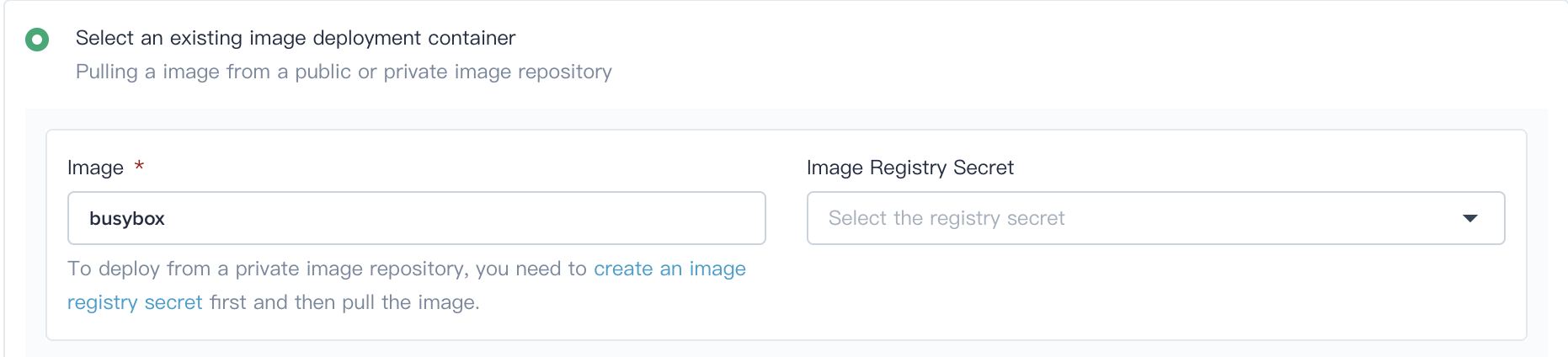
4.2. Click on **Add Container** button, and fill in the Pod template as following:
|
||||
|
||||
- Image: busybox
|
||||
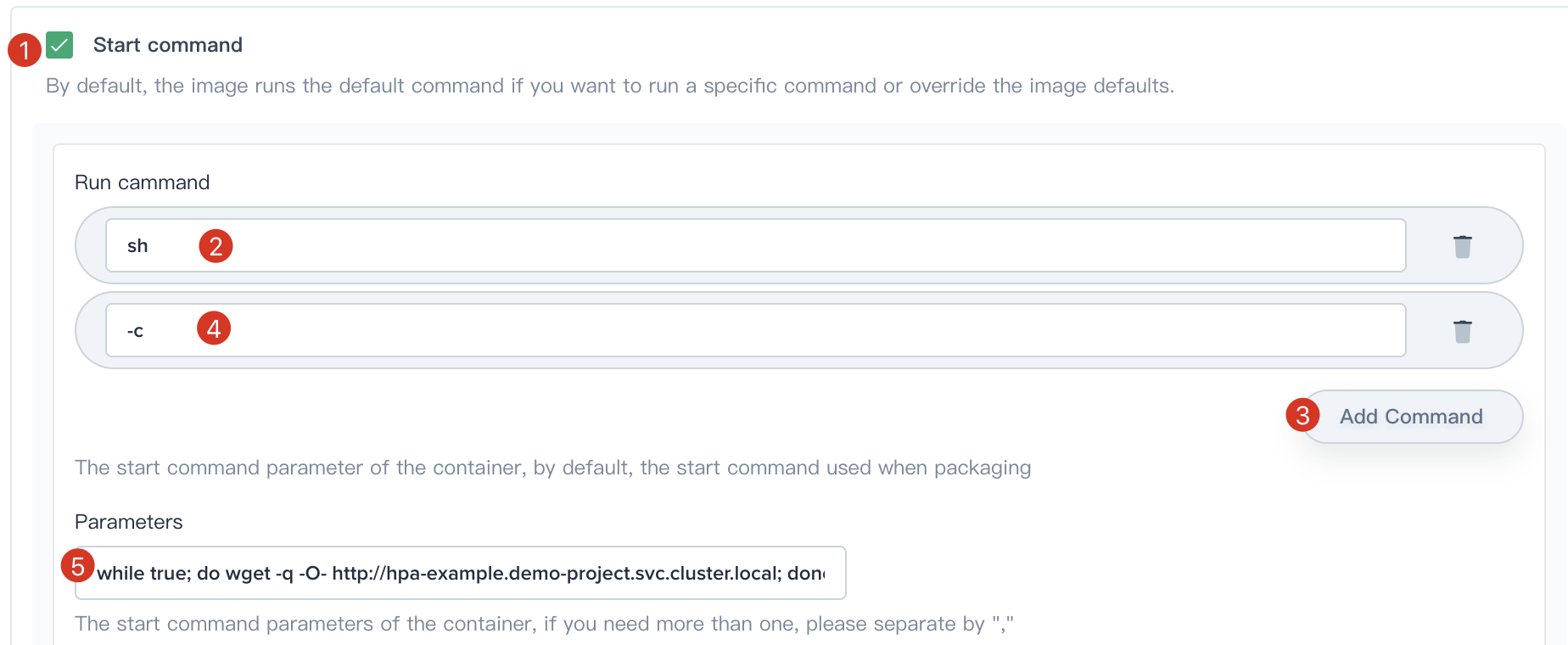
- Scroll down to **Start command**, add commands and parameters as following:
|
||||
|
||||
```
|
||||
# Commands
|
||||
sh
|
||||
-c
|
||||
|
||||
# Parameters (Note: the http service address like http://{$service name}.{$project name}.svc.cluster.local)
|
||||
while true; do wget -q -O- http://hpa-example.demo-project.svc.cluster.local; done
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Click on the **Save** button when you've done, then click **Next**.
|
||||
|
||||
4.3. Click **Next → Create** to complete creation.
|
||||
|
||||
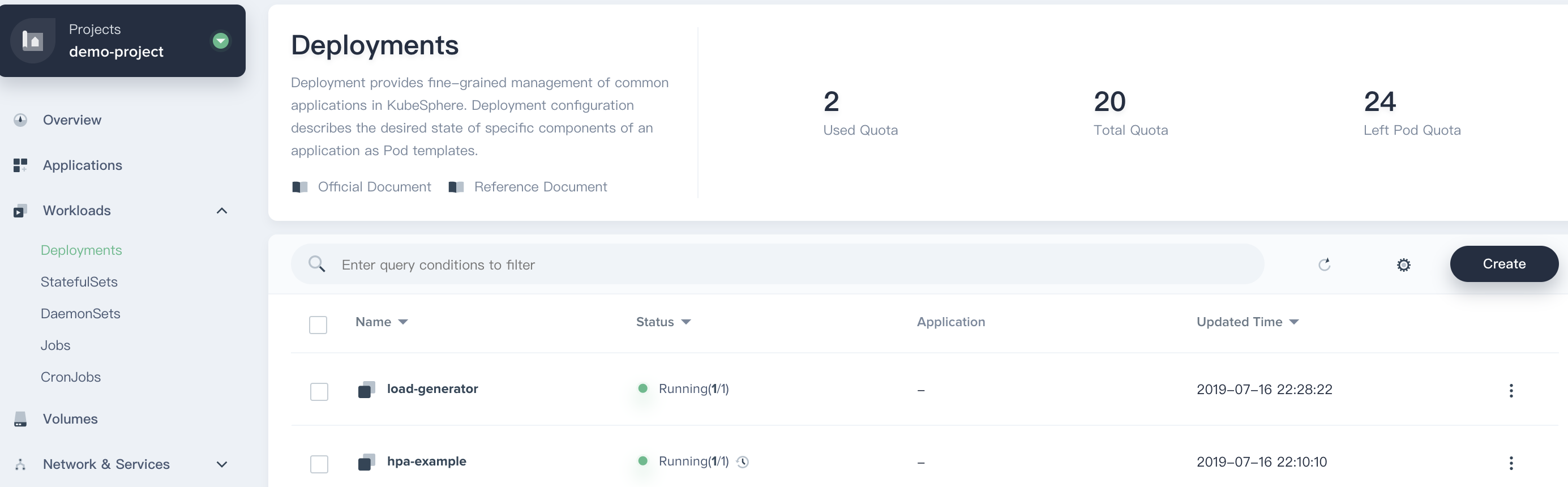
So far, we've created 2 deployments (i.e. hpa-example and load-generator) and 1 service (i.e. hpa-example).
|
||||
|
||||
|
||||
|
||||
### Step 5: Verify the HPA
|
||||
|
||||
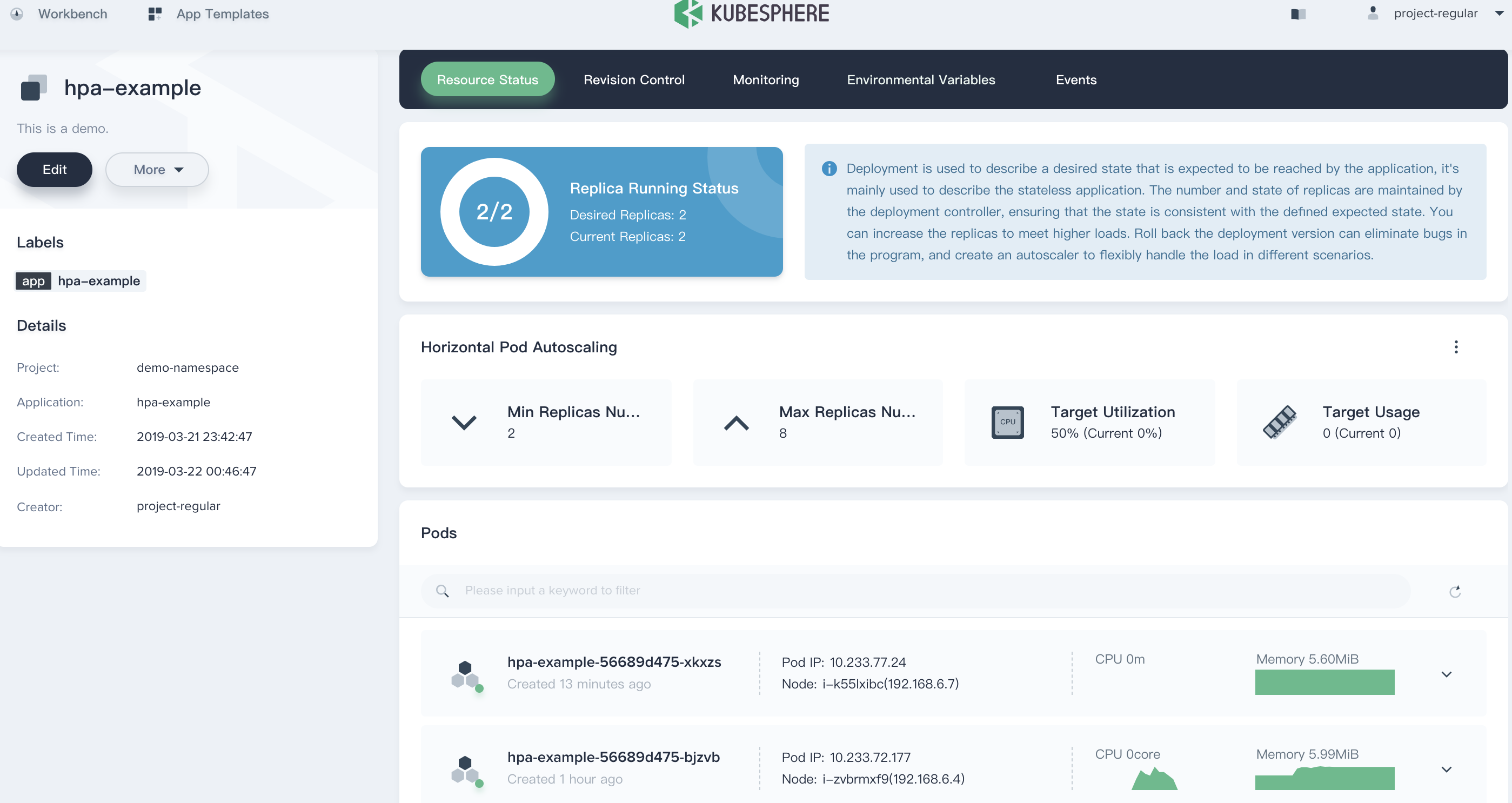
5.1. Click into `hpa-example` and inspect the changes, please pay attention to the HPA status and the CPU utilization, as well as the Pods monitoring graphs.
|
||||
|
||||
|
||||
|
||||
### Step 6: Verify the Auto Scaling
|
||||
|
||||
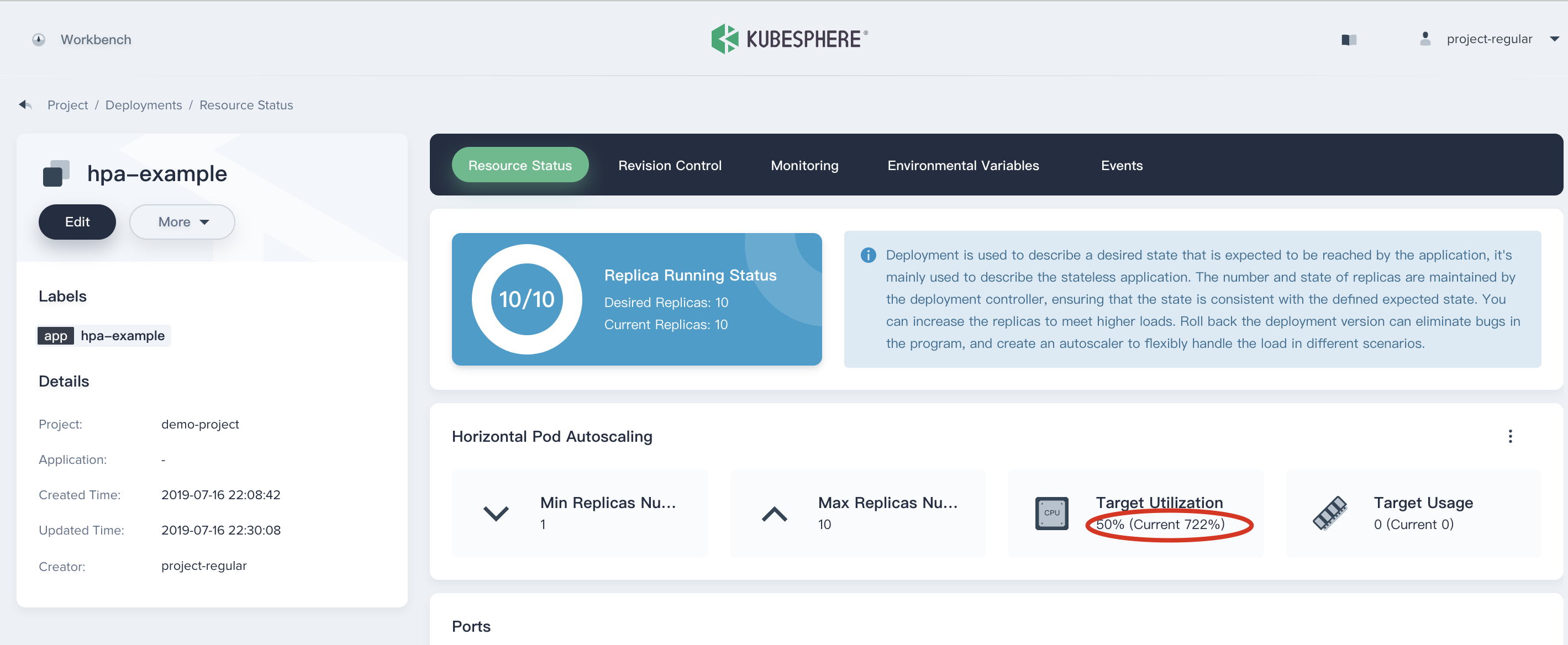
6.1. When all of the load-generator pods are successfully created and begin to access the hpe-example service, as shown in the following figure, the CPU utilization is significantly increased after refreshing the page, currently rising to `722%`, and the desired replicas and current replicas is rising to `10/10`.
|
||||
|
||||
|
||||
|
||||
> Note: Since the Horizontal Pod Autoscaler is working right now, the load-generator looply requests the hpa-example service to make the CPU utilization rised rapidly. After the HPA starts working, it makes the backend of the service increases fast to handle a large number of requests together. Also the replicas of hpa-example continues to increase follow with the CPU utilization increases, which demonstrates the working principle of HPA.
|
||||
|
||||
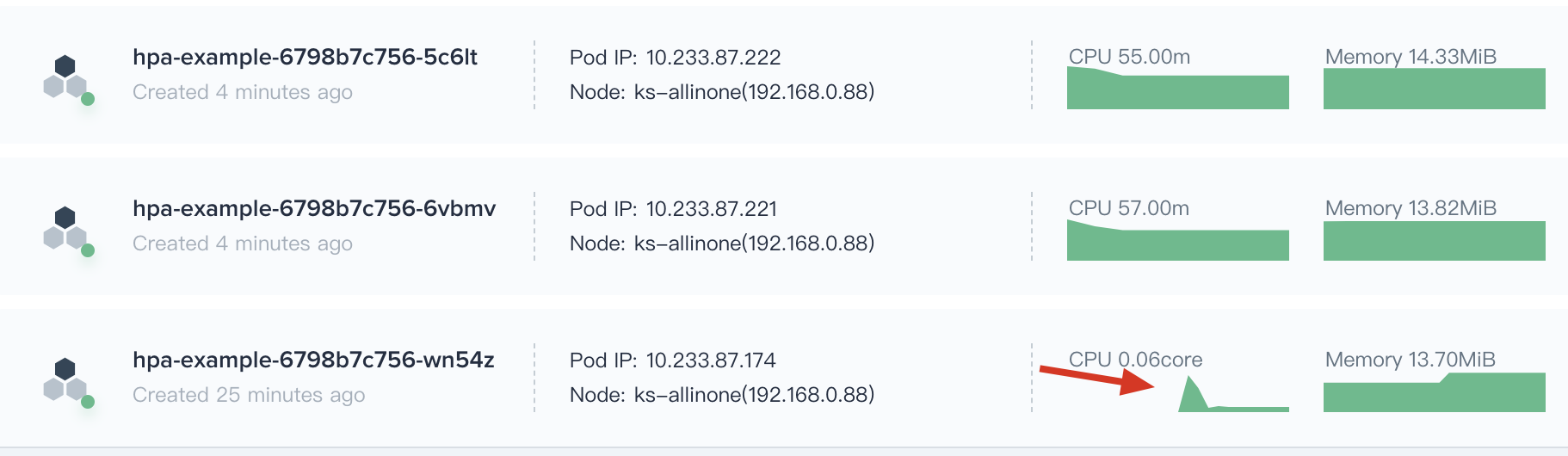
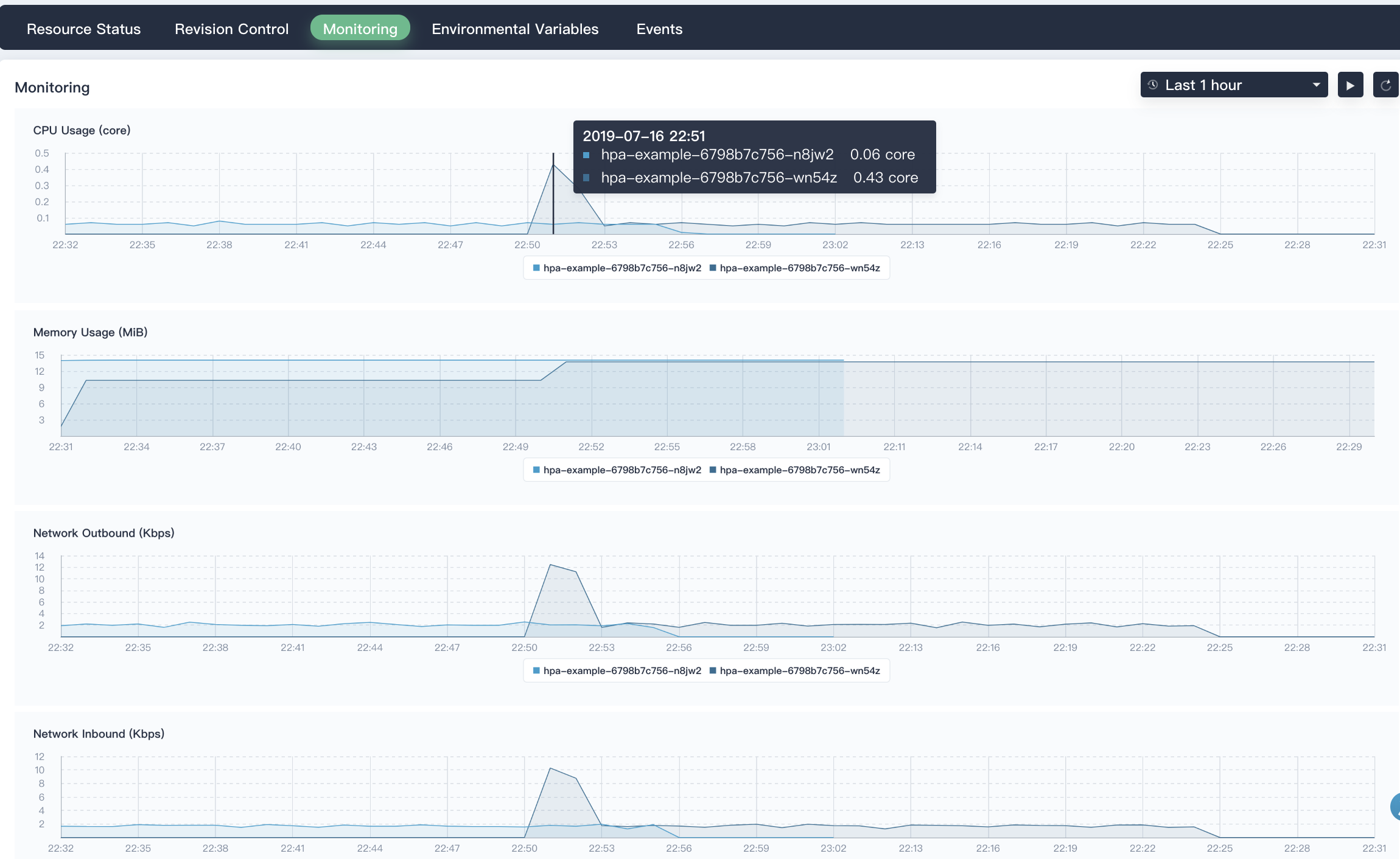
6.2. In the monitoring graph, it can be seen that the CPU usage of the first Pod that we originally created, showing a significant upward trend. When HPA started working, the CPU usage has a significant decreased trend, finally it tends to be smooth. Accordingly, the CPU usage is increasing on the newly created Pods.
|
||||
|
||||
|
||||
|
||||
### Step 7: Stop the Load Generation
|
||||
|
||||
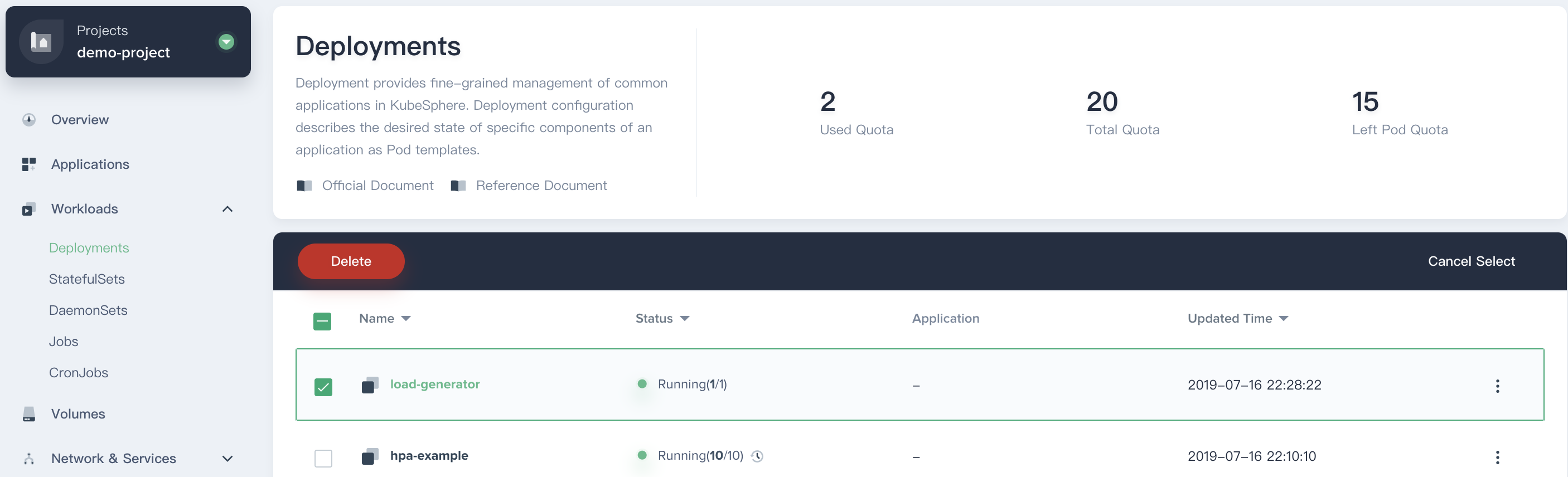
7.1. Redirect to **Workload → Deployments** and delete `load-generator` to cease the load increasing.
|
||||
|
||||
|
||||
|
||||
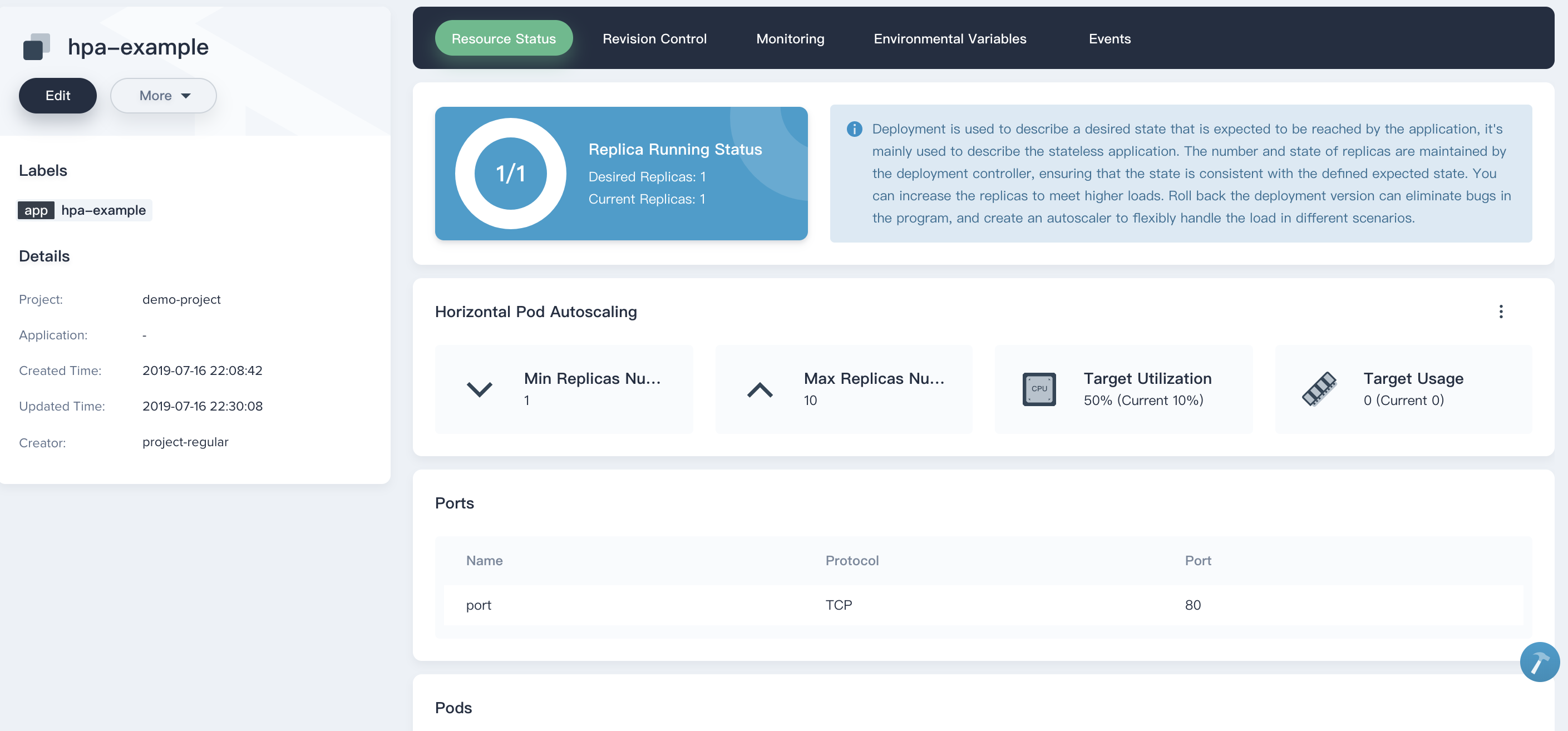
7.2. Inspect the status of the `hpa-example` again, you'll find that its current CPU utilization has slowly dropped to 10% in a few minutes, eventually the HPA has reduced its deployment replicas to 1 (initial value). The trend reflected by the monitoring curve can also help us to further understand the working principle of HPA;
|
||||
|
||||
|
||||
|
||||
7.3. It enables user to inspect the monitoring graph of Deloyment, see the CPU utilization and Network inbound/outbound trend, they just match with the HPA example.
|
||||
|
||||
|
||||
|
||||
## Modify HPA Settings
|
||||
|
||||
If you need to modify the settings of the HPA, you can click into the deployment, and click **More → Horizontal Pod Autoscaler**.
|
||||
|
||||
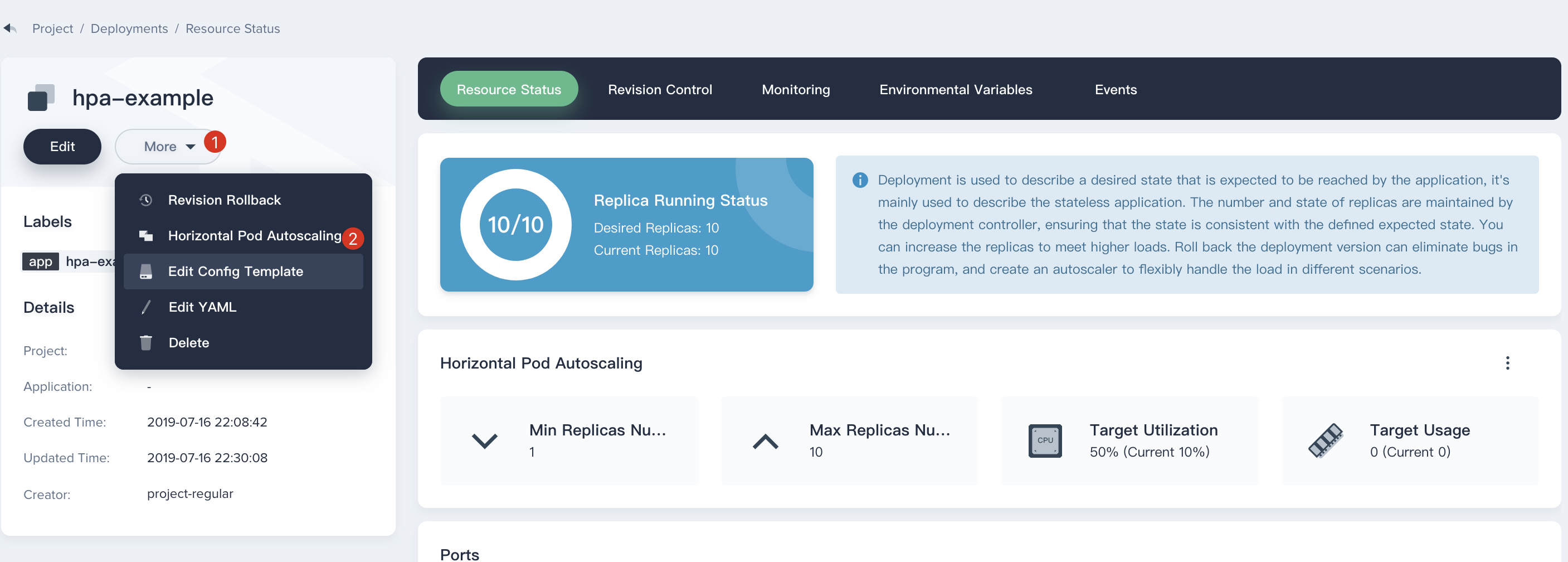
|
||||
|
||||
## Cancel HPA
|
||||
|
||||
Click **···** button on the right and **Cancel** if you don't need HPA within this deployment.
|
||||
|
||||
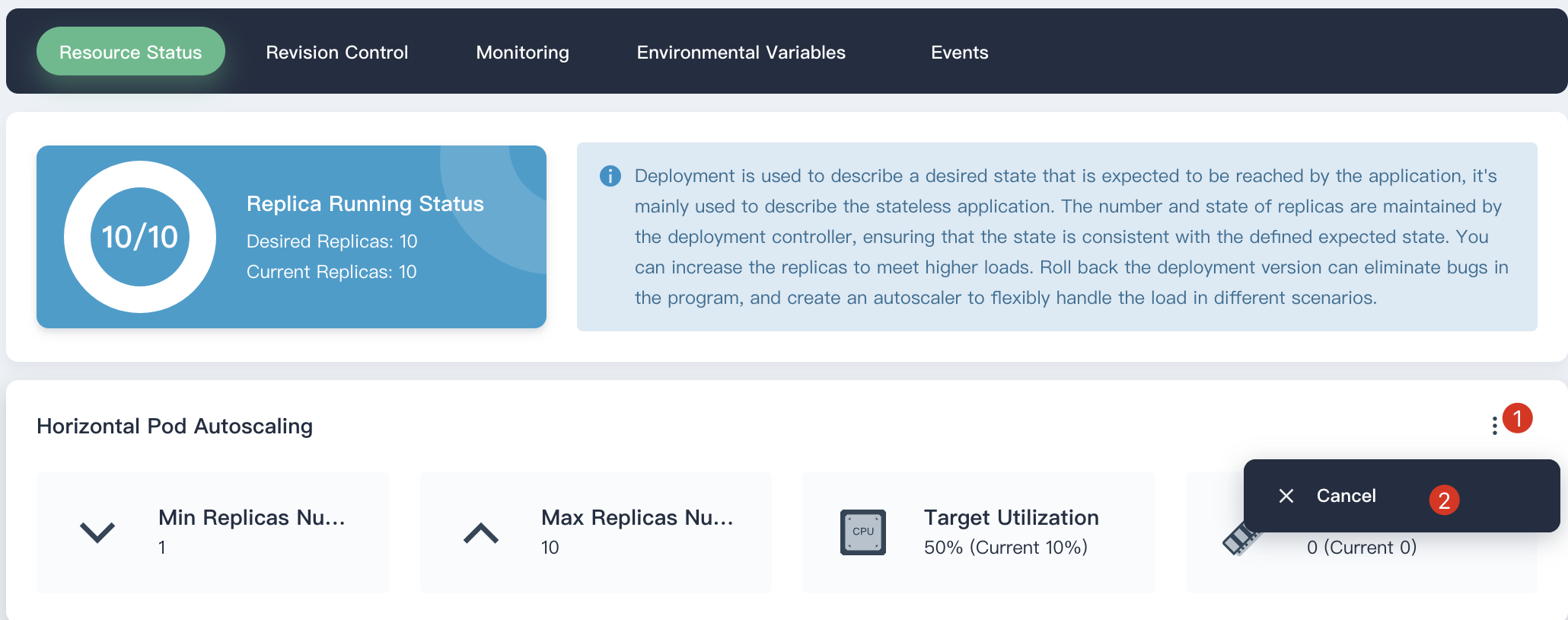
|
||||
|
||||
## Next Step
|
||||
|
||||
Tutorial 8 - [Source-to-Image: Build Reproducible Images from Source Code](s2i.md).
|
||||
|
|
@ -0,0 +1,109 @@
|
|||
---
|
||||
title: 'Cloud Native Observability: Log Management'
|
||||
author: 'Benjamin Huo, Dan Ma'
|
||||
date: '2019-06-25'
|
||||
---
|
||||
|
||||
As logs often contain very valuable information, log management represents an important part of cloud native observability. Logs feature a standard output (stdout) in containers and Kubernetes, which is different from physical machines or virtual machines. This means the collection, analysis and management of logs at the platform level can be carried out in a unified fashion, which demonstrates the unique value of logs. This article introduces a major solution to log management (EFK) in the cloud native area, FluentBit Operator developed by the KubeSphere team and some practices of KubeSphere in multi-tenant log management. Besides, the article also elaborates on an open source tool Loki, a low-cost and extensible application inspired by Prometheus and developed specifically for the log management of Kubernetes.
|
||||
|
||||
## What is Observability
|
||||
|
||||
Cloud native technologies have emerged in recent years with Kubernetes as a standout among them. Against this background, observability has come to people’s awareness as a new concept. The Cloud Native Computing Foundation (CNCF) has put observability as a separate category in its Landscape. In a narrow sense, observability mainly entails monitoring, logging and tracking. Broadly speaking, it covers alert, event and audit. Emerging open source software has sprung out in flocks in the area, such as Prometheus, Grafana, Fluentd, Loki and Jaeger.
|
||||
|
||||
|
||||
|
||||
|
||||
As an essential part of observability, logs play an important role in development, operation and maintenance, test and audit. The famous Twelve-Factor App mentions that “Logs provide visibility into the behavior of a running app. A twelve-factor app never concerns itself with routing or storage of its output stream. It should not attempt to write to or manage logfiles. Instead, each running process writes its event stream, unbuffered, to stdout. In staging or production deploys, each process' stream will be captured by the execution environment, collated together with all other streams from the app, and routed to one or more final destinations for viewing and long-term archival.”
|
||||
|
||||
In the environment of physical or virtual machines, logs are generally exported as files and managed by users. This makes it difficult for centralized management and analysis. On the contrary, container technologies, such as Kubernetes and Docker, can export logs directly to stdout, providing great convenience for the centralized management and analysis of logs.
|
||||
|
||||
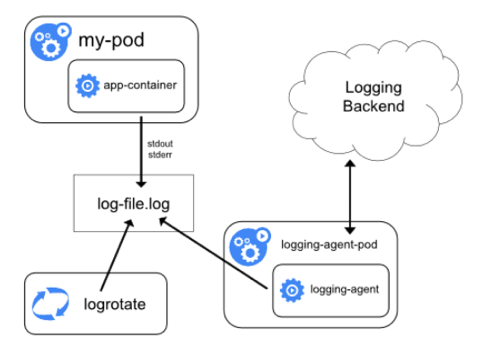
The general logging architecture offered by the official website of Kubernetes is shown below, including logging agent, backend services and frontend console. Mature solutions (e.g. ELK/EFK) and the open source tool Loki launched in 2018 in the cloud native area share a similar architecture. More details will be provided below on the contribution of ELK/EFK, [Loki](https://github.com/grafana/loki) and [KubeSphere](https://github.com/kubesphere/kubesphere) in this regard.
|
||||
|
||||
|
||||
|
||||
## Meet the New Member: ELK to EFK, Fluentd to Fluent Bit
|
||||
|
||||
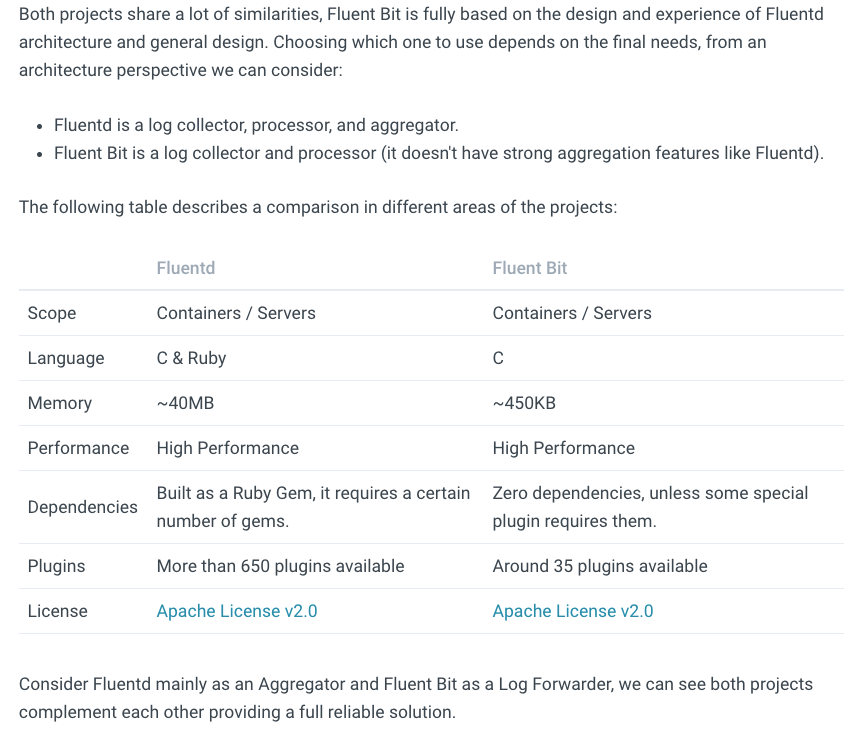
ELK, the abbreviation for Elasticsearch, Logstash and Kibana, is currently the mainstream open source logging solution. Fluentd, written in a mix of C and Ruby, became a graduated project of CNCF in April 2019. This easy-to-use data collector for unified logging layer features efficiency and flexibility, as it has gradually replaced Logstash written in Java as an important member of EFK, the new logging solution. Fluentd has also gained widespread cognition and application in the cloud native field. Furthermore, Google has modified Fluentd to use it as the Agent in its cloud logging service. That said, the development team of Fluentd did not mark time and released a much more lightweight product Fluent Bit, which is completely written in C. Here is a comparison of them:
|
||||
|
||||
|
||||
|
||||
It can be seen that Fluent Bit turns out to be a better log collector as it uses fewer resources than Fluentd. On the other hand, Fluentd is equipped with more plugins and it is more appropriate to be used as a log aggregator.
|
||||
|
||||
|
||||
|
||||
## FluentBit Operator and its Application in KubeSphere
|
||||
|
||||
Fluent Bit also has its own problems though it is more lightweight and efficient: after the configuration file is changed, the new configuration cannot be loaded automatically. Please refer to the official website in Github: [#PR 842](https://github.com/fluent/fluent-bit/pull/842) and [#issue 365](https://github.com/fluent/fluent-bit/issues/365).
|
||||
|
||||
To solve the problems above, the KubeSphere development team has developed [FluentBit Operator](https://github.com/kubesphere/fluentbit-operator) and applied it to KubeSphere as the log collector. Here is how FluentBit Operator works:
|
||||
|
||||
1. Include the FluentBit Controller process in the main Container of FluentBit Pod to control the start and stop of the FluentBit main process;
|
||||
|
||||
2. Add the ConfigMap Reload Sidecar Container to monitor the change in ConfigMap in which the FluentBit configuration file is located. When a change happens, call the reload interface of FluentBit Controller: [http://localhost:24444/api/config.reload](http://localhost:24444/api/config.reload).
|
||||
|
||||
3. FluentBit Controller will restart the main process of FluentBit to load the new configuration file.
|
||||
|
||||
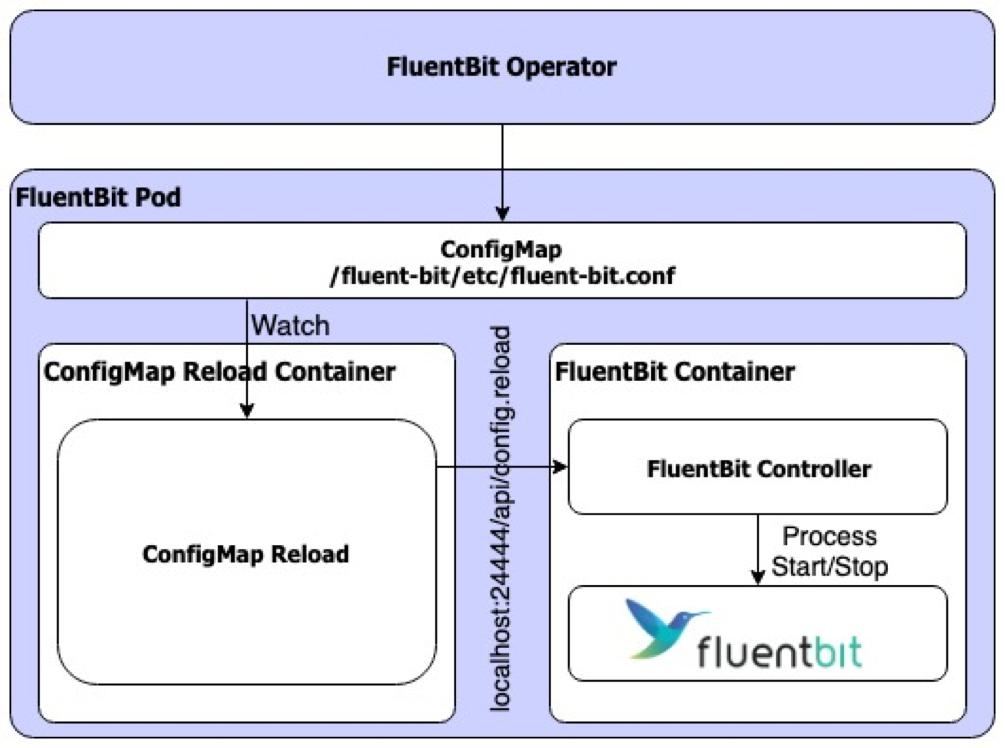
|
||||
|
||||
### FluentBit Operator Architecture
|
||||
|
||||
In KubeSphere, Elasticsearch serves as the backend logging service, with Fluent Bit as the log collector. The KubeSphere Logging Console controls the configuration of Fluent Bit in FluentBit CRD through FluentBit Operator. Alternatively, users can also change the FluentBit configuration through kubectl edit fluentbit fluent-bit in a native way of Kubernetes.
|
||||
|
||||
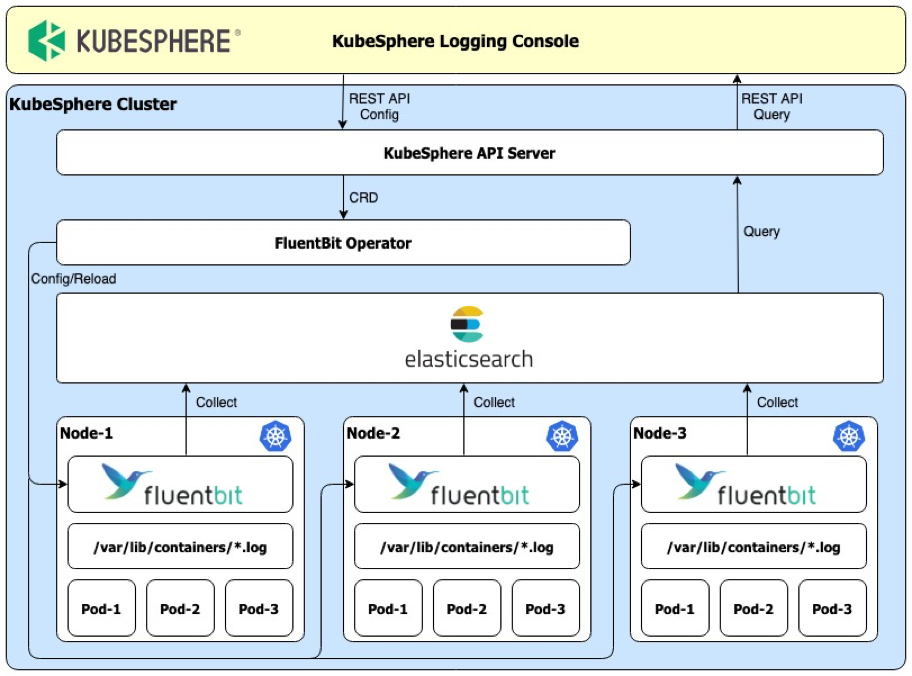
|
||||
|
||||
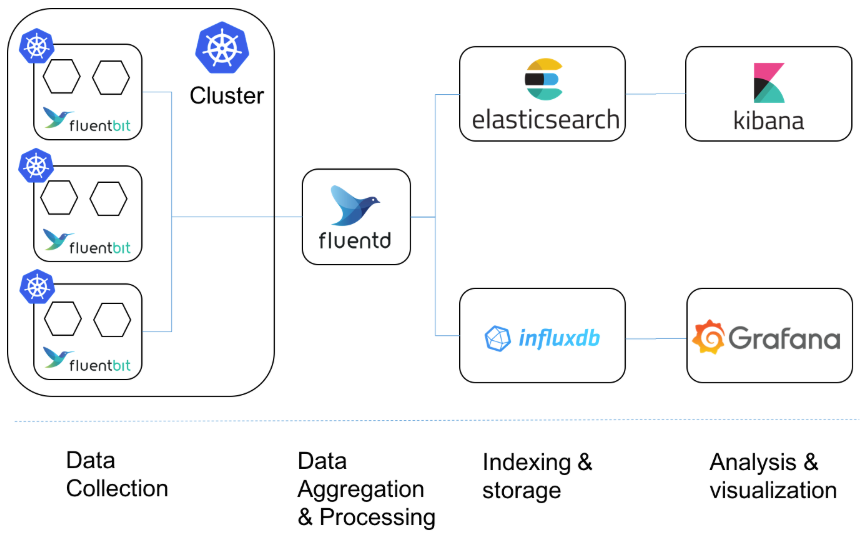
**KubeSphere Log System Architecture**
|
||||
|
||||
FluentBit Operator provides great flexibility for KubeSphere in the addition/deletion/suspension/configuration of log receivers through the console.
|
||||
|
||||
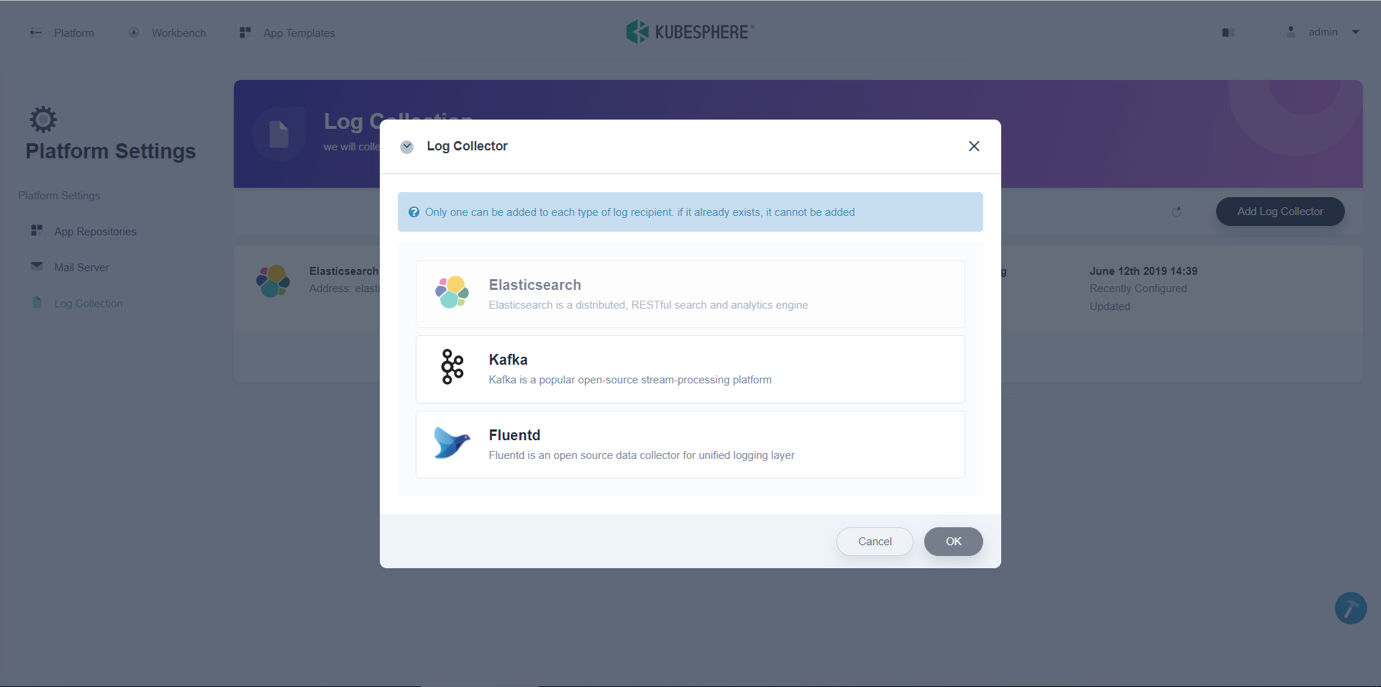
|
||||
|
||||
**KubeSphere Log Configuration Interface**
|
||||
|
||||
|
||||
|
||||
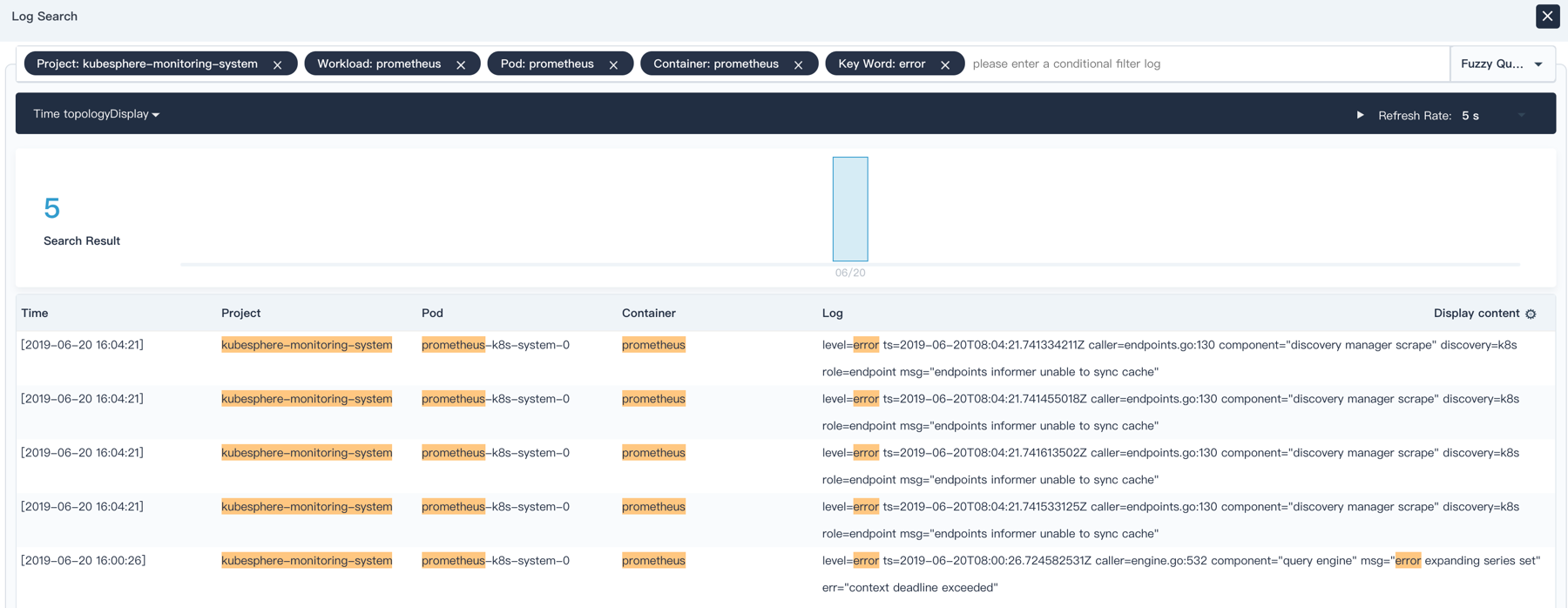
**KubeSphere Log Search Interface**
|
||||
|
||||
## Multi-Tenant Log Management
|
||||
|
||||
The Kubernetes community has paid much attention to the feature of multi-tenancy, with a wide range of solutions available to use, such as soft multi-tenancy and hard multi-tenancy. The specific approach to log management also differs. In Loki, multi-tenancy is supported through the Tenant ID while KubeSphere achieves tenant isolation through workspaces. Now, let’s take a quick look at some practices of KubeShpere in multi-tenant log management (In KubeSphere v2.1, great enhancements were made in its logging function, such as a better support of Chinese log search and automatic sidecar injection for the collection of logs in the disk).
|
||||
|
||||
It can be seen below that KubeSphere boasts a 3-tier multi-tenant architecture based on RBAC, with different roles in Cluster, Workspace and Project respectively.
|
||||
|
||||
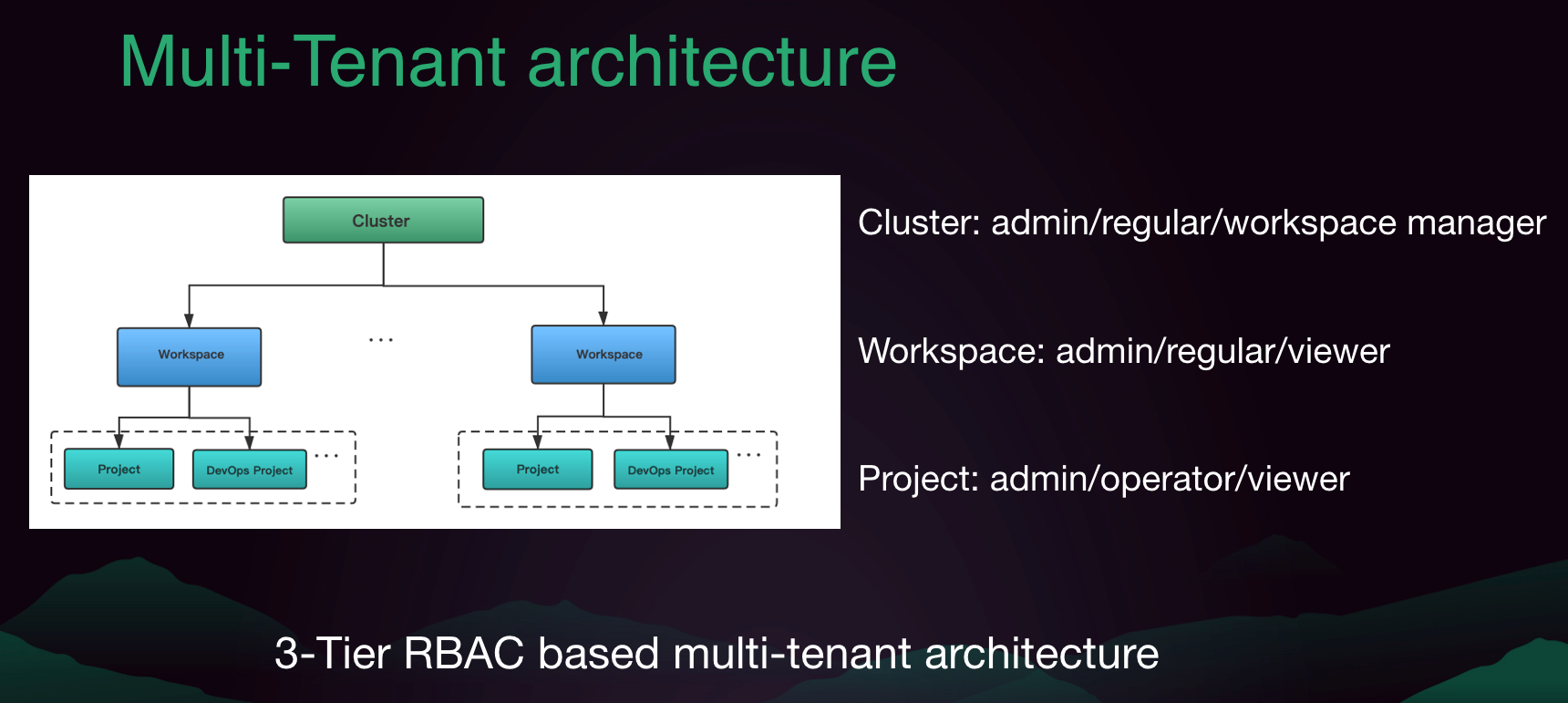
|
||||
|
||||
The authentication and authorization of API Gateway is needed before the log data (or other services) can be accessed.
|
||||
|
||||
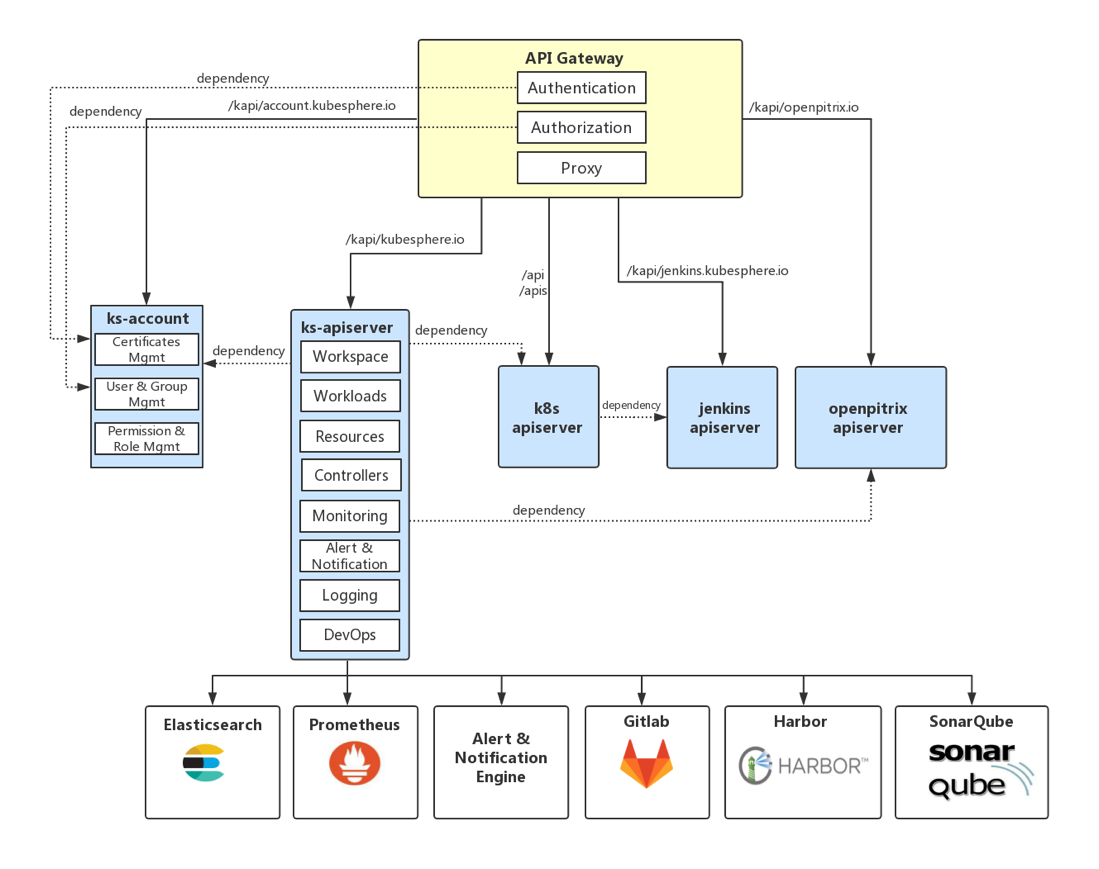
|
||||
|
||||
|
||||
The entire logging solution in KubeSphere is shown as below:
|
||||
|
||||
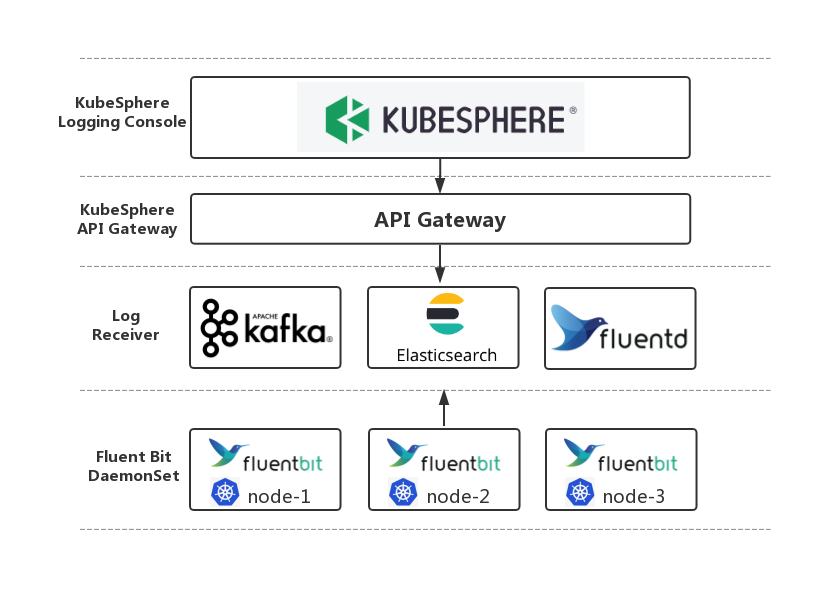
|
||||
|
||||
## Loki: Born for Cloud Natives, Designed for Logs
|
||||
Although ELF/EFK is a popular logging solution, it also has a well-known weakness: it takes up excessive resources (both memory and disk storage). This is because Elasticsearch features a full-text index of the data for a rapid search. However, this is not necessary for log data in most cases. Besides, as Elasticsearch is developed in Java, the programming language Go in the cloud native field runs better than Elasticsearch in both efficiency and resource usage.
|
||||
|
||||
The cloud native industry has waited so long for a log management application written in Go before Loki finally comes to satisfy the need. 10 months after its release in December, 2018, the number of Star in Github had topped 7,000. Loki is created by Grafana Labs, the same development team of Grafana which boasts developers of the famous cloud native monitoring application Prometheus and provides the monitoring service Cortex in cloud. As Loki is a product inspired by Prometheus, they share plenty of similar characteristics: they are closely integrated into Kubernetes and share the same Label; the query language of Loki (LogQL) has similar grammar with Prometheus; and their query functions are also alike. The log data of Loki can also be directly checked and searched in Grafana. In addition, Loki share many components with Cortex, making it very easy for horizontal scaling.
|
||||
|
||||
The most prominent feature of Loki is that it takes up few resources with a low storage cost. In this regard, Loki is designed this way to solve the problem of using excessive resources of Elasticsearch. It compresses and stores the stream data of logs by simply indexing metadata (such as labels). When a user searches the log text through the label to narrow down the range, stream data will be decompressed and filtered through a grep-like mechanism. As it can be seen below, the components include the agent Promtail for data collection, Distributor for data reception, Ingester for caches and batch writing, and Querier for data query. All these components can be horizontally scaled with high availability according to the load condition.
|
||||
|
||||
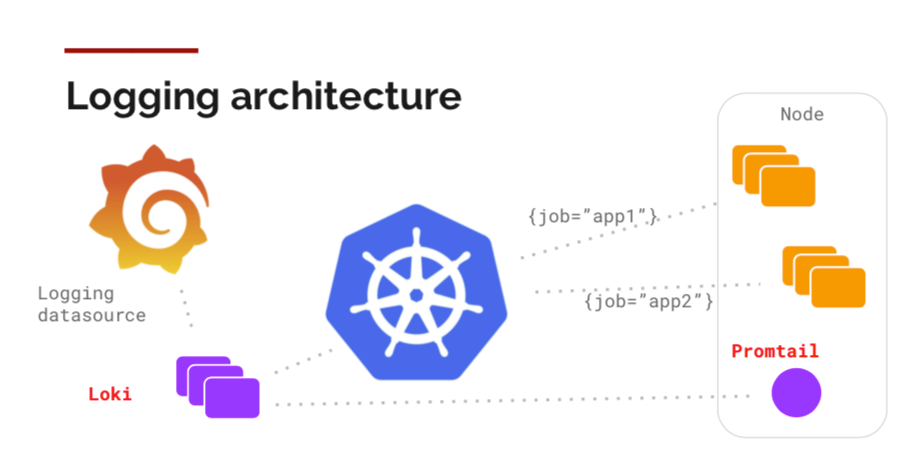
|
||||
|
||||
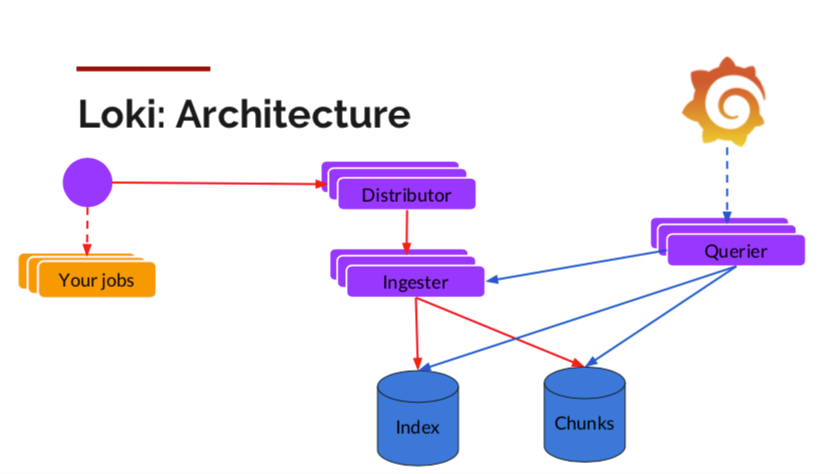
|
||||
Loki Architecture (Source: official blog of Grafana Labs)
|
||||
|
||||
With Loki, the data of Index and chunks are stored in different media as shown below. The Index can be stored in Cassandra and BoltDB while the chunks can be saved in a local disk, through cloud object storage or Minio that supports the S3 protocol. That means a large number of log data can be stored at a low cost on the one hand and the need of users for rapid log search can be met on the other.
|
||||
|
||||
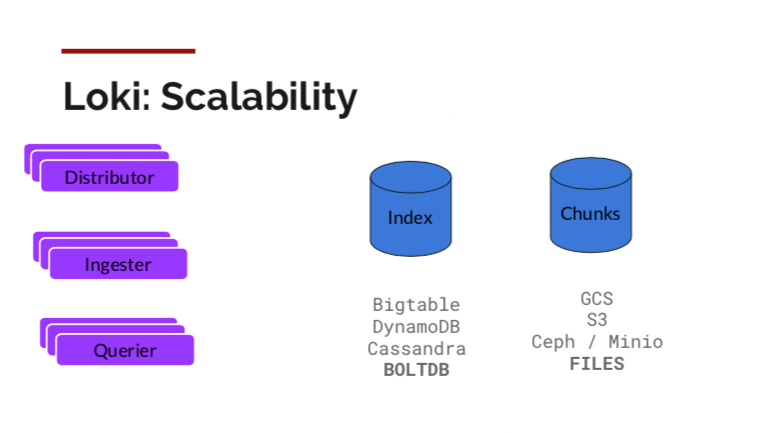
|
||||
|
||||
Loki Storage (Source: official blog of Grafana Labs)
|
||||
|
||||
As a logging solution that answers the call of the cloud native times, Loki has quickly come to the spotlight as it features low cost, great scalability and high availability, and close integration with Kubernetes and Prometheus. It is expected to be on a par with Prometheus as the preferred solution to cloud native log management.
|
||||
|
||||
## Prospect
|
||||
|
||||
The way Kubernetes is structured makes it possible for the centralized management of logs. In this connection, an increasing number of outstanding log management methods have empowered users to better dig out the value of log data, with greater observability achieved. As an open source platform based on Kubernetes, KubeSphere will work to improve the existing logging solutions of Kubernetes (e.g. multi-cluster log management and log alert). On top of that, it will also pay close and continuous attention to Loki, the log aggregation system inspired by Prometheus, and strives to be an active player in its development. This is how it works to integrate the most cutting-edge technology of log management into KubeSphere for users around the world.
|
||||
|
||||
## Relevant Information
|
||||
|
||||
In KubeCon held in Shanghai, June 2019, a keynote speech [Effective Logging In Multi Tenant Kubernetes Environment](https://static.sched.com/hosted_files/kccncosschn19eng/39/Effective%20Logging%20in%20Multi-Tenant%20Kubernetes%20Environment.pdf) was shared on multi-tenant log management. Please see relevant PPT in the [official website of CNCF](https://kccncosschn19eng.sched.com/event/NroE/effective-logging-in-multi-tenant-kubernetes-environment-benjamin-huo-dan-ma-beijing-yunify-technology-co-ltd).
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
---
|
||||
title: 'Porter: An Open Source Load Balancer for Kubernetes in a Bare Metal Environment'
|
||||
type: 'KubeCon'
|
||||
author: 'Song Xuetao'
|
||||
createTime: '2019-06-24'
|
||||
snapshot: 'https://pek3b.qingstor.com/kubesphere-docs/png/20190930095713.png'
|
||||
---
|
||||
|
||||
We know that we can use the service of LoadBalancer in the Kubernetes cluster to expose backend workloads externally. Cloud providers often offer cloud LB plugins, which requires the cluster to be deployed on a specific IaaS platform. However, many enterprise users often deploy the Kubernetes cluster on bare metal, especially when it is used for the production environment. For the local bare metal cluster, Kubernetes does not provide LB implementation. Porter is an open source load balancer designed specifically for the bare metal Kubernetes cluster, which serves as an excellent solution to this problem.
|
||||
|
||||
## Kubernetes Service Introduction
|
||||
In the Kubernetes cluster, network represents a very basic and important part. For large-scale nodes and containers, it entails very complicated and delicate design if it is to ensure the connectivity and efficiency in the network. What’s more, IP addresses and ports need to be automatically assigned and managed in the network, with a user-friendly approach in place for the direct and quick access to applications in need.
|
||||
|
||||
Kubernetes has made great efforts in this connection. With CNI, Service, DNS and Ingress, it has solved the problem of service discovery and load balancing, providing an easier way in usage and configuration. Among them, Service underlies Kubernetes microservices. And services are made possible through kube-proxy in Kubernetes. This component runs on each node, monitoring the change in the service object in API Server and achieving network forwarding by managing iptables. Users can create different forms of Services such as those based on Label Selector, Headless or ExternalName. Kube-proxy will create a virtual IP (or cluster IP) for the service for the internal access of the cluster.
|
||||
## Three Methods to Expose Services
|
||||
If the access is required outside the cluster, or to expose the service to users, Kubernetes Service provides two methods: NodePort and LoadBalancer. Besides, Ingress is also a very common option to expose services.
|
||||
### NodePort
|
||||
If the service type is set to NodePort, kube-proxy will apply for a port for the service which is above 3000 (by default). Iptables rules will be configured for all the hosts in the cluster. In this way, users can access the service through any node in the cluster with the assigned port. Please see the image below:
|
||||
|
||||

|
||||
|
||||
NodePort is the most convenient way to expose services while it also has obvious shortcomings:
|
||||
|
||||
1. The real IP is not visible in Pod through the access based on SNAT.
|
||||
2. A host in the cluster is used as a jumper server to access the backend service, which means all the traffic will go to the server first. This can easily lead to performance bottlenecks and a single point of failure, making it difficult to be used in the production environment.
|
||||
3. Generally, NodePort uses large port numbers which are hard to remember.
|
||||
|
||||
Initially, NodePort is not designed for the exposure of services in the production environment which is why large port numbers are used by default.
|
||||
### LoadBalancer
|
||||
LoadBalancer is a preferred solution by Kubernetes to service exposure. However, this cannot be done without the load balancer offered by cloud providers, which means the Kubernetes cluster has to be deployed in the cloud. Here is how LoadBalancer works:
|
||||
|
||||

|
||||
|
||||
The LoadBalancer service is achieved through the LB plugin offered by cloud providers. The package Kubernetes.io/cloud-provider will choose the appropriate backend service and expose it to the LB plugin, which creates a load balancer accordingly. That means network traffic will be distributed in the cloud service, avoiding a single point of failure and performance bottlenecks that may occur in NodePort. As mentioned above, LoadBalancer is a preferred solution by Kubernetes to service exposure, but it is only limited to the Kubernetes service offered by cloud providers. For the Kubernetes cluster that is deployed in a bare metal environment or in a non-cloud environment, this approach may not be applicable.
|
||||
### Ingress
|
||||
Kubernetes itself does not provide the way to expose services through Ingress. Rather, Ingress exposes multiple services simultaneously with the help of applications just like a router. This plugin identifies different services through domains and uses annotations to control the way services are exposed externally. Here is how it works:
|
||||
|
||||

|
||||
|
||||
Ingress is the most used method in a business environment than NodePort and LoadBalancer. The reasons include:
|
||||
|
||||
1. Compared with the load balancing way of kube-proxy, Ingress Controller is more capable (e.g. traffic control and security strategy).
|
||||
2. It is more direct to identify services through domains; large port numbers in NodePort are also not needed for Ingress.
|
||||
|
||||
Nevertheless, the following problems need to be solved for Ingress:
|
||||
|
||||
1. Ingress is used more often for L7, with limited support for L4.
|
||||
2. All the traffic will go to Ingress Controller, which requires a LB to expose Ingress Controller.
|
||||
|
||||
For the first problem, Ingress can be used for L4 but the configuration of Ingress is too complicated for L4 applications. The best practice is to use LB directly for exposure. For the second problem, Ingress Controller can be exposed in a test environment with NodePort (or hostnetwork), while a single point of failure and performance bottlenecks may happen inevitably and the HA feature of Ingress-controller has not been properly used.
|
||||
|
||||
## Porter Introduction
|
||||
|
||||
Porter is an open source cloud native load balancing plugin designed by the KubeSphere development team based on Border Gateway Protocol (BGP). It meanly features:
|
||||
|
||||
1. ECMP routing load balancing
|
||||
2. BGP dynamic routing configuration
|
||||
3. VIP management
|
||||
|
||||
All Porter codes are open source and documents are available in [GitHub](https://github.com/kubesphere/porter). You are welcome to star and use it.
|
||||
## How to Install Porter
|
||||
|
||||
Porter has been deployed and tested in two environments so far as below. You can see more details in GitHub about the deployment, test and process by clicking the link below. It is recommended to have a try:
|
||||
|
||||
- [Deploy Porter on Bare Metal Kubernetes Cluster](https://github.com/kubesphere/porter/blob/master/doc/deploy_baremetal.md)
|
||||
- [Test in the QingCloud Platform Using a Simulated Router](https://github.com/kubesphere/porter/blob/master/doc/zh/simulate_with_bird.md)
|
||||
|
||||
## Principle
|
||||
|
||||
### ECMP
|
||||
|
||||
Equal-Cost Multi-Path (ECMP) means the package forwarding to a same destination can occur along multiple paths of equal cost. When the device supports ECMP, the three-layer traffic that is sent to the target IP or network segment can be distributed by different paths, achieving network load balancing. Besides, once a certain path malfunctions, other paths can finish the forwarding process instead, serving as the routing redundant backup. Please refer to the image below:
|
||||

|
||||
|
||||
With the help of the virtual router, ECMP can select the next hop (Pod) according to Hash algorithm from the existing routing paths for a certain IP (the corresponding VIP of the service). This is how load balancing is achieved. As virtual routers support ECMP in general, Porter only needs to check the Kubernetes API server and deliver the corresponding information of backend Pod of a service to the router.
|
||||
|
||||
### BGP
|
||||
A Pod may be scheduled to other nodes in Kubernetes. For a router, the next hop of a service VIP is not fixed as the equal-cost routing information will often be updated. Calico, for example, uses BGP (Border Gateway Protocol) to advertise routes. BGP is a commonly used essential decentralized protocol to exchange routing information among autonomous systems on the Internet. Unlike other routing protocols, BGP uses L4 to ensure the update security of routing information. As BGP is decentralized, it is very easy to establish a routing layer of high availability to ensure network continuity.
|
||||

|
||||
|
||||
The image above briefly demonstrates how BGP works in Porter. At the bottom left, it is a two-node Kubernetes cluster with two routers (Leaf1 and Leaf2) above it. These two routers are connected to two kernel switches (Spine layer). Users are on the right side, whose routers are Border1 and Border2 (also connected to Spine). The three layers of users and Kubernetes server are reachable. Services are created in the Kubernetes cluster and Porter is also used. A VIP (or other manually assigned IP) 1.1.1.1 is assigned by Porter, which sends the information to Leaf1 and Leaf2 through BGP. The next hop to access 1.1.1.1 can be Node1 or Node2. Meanwhile, the Leaf layer also sends the message to the Spine layer, which also knows the next hop to access 1.1.1.1 can be Leaf1 or Leaf2 based on its BGP. According to the same logic, the routing information will also be updated on Border, meaning the path for users to access 1.1.1.1 is complete. At the same time, as each layer in the image features HA, a total of 16 (`2*2*2*2`) paths are available to use for external access. Traffic can be distributed across the network and any downtime that occurs in the router in any layer will not affect user’s access.
|
||||
|
||||
## Architecture
|
||||
|
||||

|
||||
|
||||
Porter has two components: a core controller and an agent deployed on each node. The main functions of the controller include:
|
||||
1. Monitor cluster Services and corresponding endpoints; acquire the Scheduling information of Pods
|
||||
2. VIP storage and assignment
|
||||
3. Establish BGP and advertise routes
|
||||
|
||||

|
||||
|
||||
The image above shows the working principle of Porter's core controller.
|
||||
|
||||
Agent is a lightweight component to monitor VIP resources and add Iptables rules for external access to the VIP. By default, the kernel Forward table will drop any external access to VIP.
|
||||
|
||||
## Designed for Cloud Natives
|
||||
|
||||
All resources in Porter are CRD, including VIP, BGPPeer and BGPConfig. Users who are used to Kubectl will find Porter very easy to use. For advanced users who want to customize Porter, Kubernetes API can be called directly for tailor-made development. The core controller of Porter will soon support high availability (HA).
|
||||
|
||||
## Cautions
|
||||
|
||||
The VIP traffic of user access will go to a node in the Kubernetes cluster under BGP. This is because the routes advertised by Porter are also nodes instead of Pod IP which is inaccessible externally. The path from a node to a pod is maintained by kube-proxy as below:
|
||||
|
||||

|
||||
|
||||
The traffic will be sent to a pod randomly after the SNAT process. As Port will adjust routes based on the dynamic change of Service Endpoints to make sure a pod is available in a node for the next hop, we can change kube-proxy which is set by default. You can set ExternalTrafficPolicy=local in a Service and the result is shown as follows:
|
||||
|
||||

|
||||
|
||||
There are two advantages in this method:
|
||||
|
||||
1. SourceIP will not go through the process of NAT
|
||||
2. Traffic will go locally, reducing a hop in the network
|
||||
|
||||
## Future Plans
|
||||
|
||||
1. Support of other simple routing protocols
|
||||
2. More convenient VIP management
|
||||
3. Policy support of BGP
|
||||
4. Integration into KubeSphere with UI provided
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -9,26 +9,82 @@ groups:
|
|||
children:
|
||||
- title: KubeSphere
|
||||
icon: 'images/kubesphere.svg'
|
||||
link: ''
|
||||
description: 基于 Kubernetes 之上构建的以应用为中心的多租户容器平台,支持部署运行在任何基础设施之上,提供简单易用的操作界面以及向导式 UI,旨在解决 Kubernetes 的存储、网络、安全与易用性等痛点。
|
||||
|
||||
- name: App Management
|
||||
link: 'https://github.com/kubesphere/kubesphere'
|
||||
description: KubeSphere is a distributed operating system managing cloud native applications with Kubernetes as its kernel, and provides plug-and-play architecture for the seamless integration of third-party applications to boost its ecosystem.
|
||||
|
||||
- name: Application Management
|
||||
children:
|
||||
- title: OpenPitrix
|
||||
icon: ''
|
||||
link: ''
|
||||
description: 开源的多云应用管理平台,用来在多云环境下打包、部署和管理不同类型的应用,包括传统应用、微服务应用以及 Serverless 应用等,其中云平台包括 AWS、Kubernetes、QingCloud、VMWare。
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200607231502.png'
|
||||
link: 'https://github.com/openpitrix/openpitrix'
|
||||
description: OpenPitrix is an open source multi-cloud application management platform. It is useful in packing, deploying and managing applications of different kinds (e.g. traditional, microservice and serverless) in multiple cloud platforms, including AWS, Kubernetes, QingCloud and VMWare.
|
||||
|
||||
- name: Service Proxy
|
||||
children:
|
||||
- title: Porter LB
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608102707.png'
|
||||
link: 'https://porterlb.io'
|
||||
description: Porter is an open source load balancer designed for bare metal Kubernetes clusters. It’s implemented by physical switch, and uses BGP and ECMP to achieve the best performance and high availability.
|
||||
|
||||
- name: Installer
|
||||
children:
|
||||
- title: KubeKey
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608103108.png'
|
||||
link: 'https://github.com/kubesphere/kubekey'
|
||||
description: KubeKey is the next-gen installer for Kubernetes and KubeSphere. KubeKey changes from ansible-based technology to Go, supports installing Kubernetes and KubeSphere separately or as a whole easily, efficiently and flexibly.
|
||||
|
||||
- name: Logging
|
||||
children:
|
||||
- title: Fluentbit Operator
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608104816.png'
|
||||
link: 'https://github.com/kubesphere/fluentbit-operator'
|
||||
description: The Fluent Bit Operator for Kubernetes facilitates the deployment of Fluent Bit and provides great flexibility in building logging layer based on Fluent Bit, provides Fluent Bit management, custom configuration, and dynamic reloading.
|
||||
|
||||
- name: Notification
|
||||
children:
|
||||
- title: Notification Manager
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608105148.png'
|
||||
link: 'https://github.com/kubesphere/notification-manager'
|
||||
description: Notification Manager manages notifications in multi-tenant K8s environment. It receives alerts or notifications from different senders and then send notifications to various tenant receivers based on alerts/notifications' tenant label like "namespace".
|
||||
|
||||
- name: Events
|
||||
children:
|
||||
- title: Kube-events
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608111002.png'
|
||||
link: 'https://github.com/kubesphere/kube-events'
|
||||
description: Kube-events revolves around Kubernetes Event, covering multi-dimensional processing of them, such as emitting events to sinks, issuing notifications and generating alerts. And in some of these dimensions, configurable filtering rules are provided to meet different business needs.
|
||||
|
||||
- name: Alert
|
||||
children:
|
||||
- title: Alerting System
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608111200.png'
|
||||
link: 'https://github.com/kubesphere/alert'
|
||||
description: Alert is an enterprise-grade general-purpose high-performance alerting system.
|
||||
|
||||
- name: CI/CD
|
||||
children:
|
||||
- title: S2i-operator
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608111455.png'
|
||||
link: 'https://github.com/kubesphere/s2ioperator'
|
||||
description: Source-to-image(S2I)-Operator is a Kubernetes Custom Resource Defintion (CRD) controller that provides easy Kubernetes-style resources for declaring CI/CD-style pipelines. S2I Operator create a ready-to-run images by injecting source code into a container image and letting the container prepare that source code for execution.
|
||||
|
||||
- name: Design
|
||||
children:
|
||||
- title: kube-design
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608114816.png'
|
||||
link: 'https://github.com/kubesphere/kube-design'
|
||||
description: Kube Design is a set of React component libraries created for KubeSphere console. If you want to develop KubeSphere console, this library will be pretty useful in customizing front end.
|
||||
|
||||
- name: Storage Plugins
|
||||
children:
|
||||
- title: QingStor-CSI
|
||||
icon: ''
|
||||
link: ''
|
||||
description: QingStor CSI 插件实现 CSI 接口,使容器编排平台(如 Kubernetes)能够使用 NeonSAN 分布式存储的资源。目前,QingStor CSI 插件实现了存储卷管理和快照管理功能,并在 Kubernetes v1.12 环境中通过了 CSI Sanity 测试。
|
||||
|
||||
- title: QingCloud-CSI
|
||||
icon: ''
|
||||
link: ''
|
||||
description: QingCloud CSI 插件实现了 CSI 接口,并使容器管理平台能够使用 QingCloud 云平台的块存储资源。目前,QingCloud CSI 插件已经在 Kubernetes v1.14/v1.15 环境中通过了 CSI 测试。
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608111848.png'
|
||||
link: 'https://github.com/yunify/qingstor-csi'
|
||||
description: QingStor CSI plugin implements an interface between Container Storage Interface (CSI) enabled Container Orchestrator (CO) and the storage of NeonSAN, which has passed CSI sanity test.
|
||||
|
||||
---
|
||||
- title: QingCloud-CSI
|
||||
icon: 'https://pek3b.qingstor.com/kubesphere-docs/png/20200608112327.png'
|
||||
link: 'https://github.com/yunify/qingcloud-csi'
|
||||
description: QingCloud CSI plugin implements an interface between Container Storage Interface (CSI) enabled Container Orchestrator (CO) and the storage of QingCloud. Currently, QingCloud CSI disk plugin has been developed and manages disk volume in QingCloud platform.
|
||||
|
||||
---
|
||||
|
|
|
|||
|
|
@ -19,12 +19,10 @@
|
|||
- id: introduction10
|
||||
translation: Open Source Community
|
||||
- id: introduction11
|
||||
translation: KubeSphere is committed to the open source contribution of cloud native technology, enriching the ecology of the open source community
|
||||
translation: KubeSphere is committed to the open source contribution of cloud native technology, enriching the ecosystem of the open source community.
|
||||
- id: introduction12
|
||||
translation: Goto Github
|
||||
translation: Go to GitHub
|
||||
- id: email is required
|
||||
translation: email is required!
|
||||
- id: Please enter a valid email address.
|
||||
translation: Please enter a valid email address!
|
||||
|
||||
|
||||
|
|
|
|||
{kind=link}
|
Before Width: | Height: | Size: 7.6 KiB After Width: | Height: | Size: 7.6 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 31 KiB |
Loading…
Reference in New Issue